基于Java多线程处理数据
基于Java多线程处理数据
- 背景
- 代码实现
背景
在日常工作中,有一个同步企微客户-学员关系接口的定时任务在执行中随着数据量的不断增长,定时任务的执行结束时间也出现了当天执行不完的情况,影响到了正常业务的运行。基于这种情况,在对该定时任务的业务逻辑代码分析验证后得出是调用企微客户-学员关系接口时耗时引起的,但是查阅企微接口文档,又不支持批量调用,只能逐个调用。那么这种情况下既然批量调用接口不支持,那么可以采用多线程并发调用的方式来降低定时任务整体的执行时间,于是就需要用到线程池来进行多线程操作。
代码实现
在这里我将会使用spring自带的线程池类 ThreadPoolTaskExecutor 来进行处理, ThreadPoolTaskExecutor 是对 ThreadPoolExecutor 进行了封装处理,源代码中可以看到

而线程池类ThreadPoolExecutor 是JDK的线程池类,继承 AbstractExecutorService ,
public class ThreadPoolExecutor extends AbstractExecutorService {
AbstractExecutorService 实现 ExecutorService,
public abstract class AbstractExecutorService implements ExecutorService {
ExecutorService 继承 Executor
public interface ExecutorService extends Executor {
下面开始初始化线程池类 ThreadPoolTaskExecutor,配置类 ThreadPoolConfig 代码如下
/*** 线程池配置***/@Configurationpublic class ThreadPoolConfig{// 核心线程池大小private int corePoolSize = 50;// 最大可创建的线程数private int maxPoolSize = 200;// 队列最大长度private int queueCapacity = 1000;// 线程池维护线程所允许的空闲时间private int keepAliveSeconds = 300;@Bean(name = "threadPoolTaskExecutor")public ThreadPoolTaskExecutor threadPoolTaskExecutor(){ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();executor.setMaxPoolSize(maxPoolSize);executor.setCorePoolSize(corePoolSize);executor.setQueueCapacity(queueCapacity);executor.setKeepAliveSeconds(keepAliveSeconds);// 线程池对拒绝任务(无线程可用)的处理策略executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());return executor;}}
补充同步企微客户-学员关系定时任务 SyncWechatWorkCustomerLinkDetailHandler 代码如下
@Component@JobHandler("syncWechatWorkCustomerLinkDetailHandler")public class SyncWechatWorkCustomerLinkDetailHandler extends IJobHandler {@Autowiredprivate IWechatCustomerLinkDetailService wechatCustomerLinkDetailService;@Overridepublic ReturnT<String> execute(String params) throws Exception {wechatCustomerLinkDetailService.syncWechatWorkCustomerLinkDetail(params);return ReturnT.SUCCESS;}}
业务处理实现类 syncWechatWorkCustomerLinkDetail 代码如下
@Overridepublic void syncWechatWorkCustomerLinkDetail(String params) {XxlJobLogger.log("补充任务开始执行...[{}]",params);//查询条件对象WechatCustomerLinkDetail searchparam = new WechatCustomerLinkDetail();if (StringUtils.isNotEmpty(params)) {Long[] ids = Convert.toLongArray(params);//根据ids查询数据searchparam.setLinkIds(ids);}// 分页查询企微获客助手客户链接int pageNo = 0;int pageSize = 200;while(true){pageNo++;XxlJobLogger.log("第【{}】页数据开始补充...",pageNo);PageHelper.startPage(pageNo, pageSize);PageHelper.orderBy("id asc");List<WechatCustomerLinkDetail> list = wechatCustomerLinkDetailMapper.selectWechatCustomerLinkDetailList(searchparam);PageHelper.clearPage();if (CollUtil.isEmpty(list) ) {break;}//开始补充数据multiThreadProcessData(list);XxlJobLogger.log("第【{}】页数据补充完成...",pageNo);}}
多线程处理列表中的数据类 multiThreadProcessData 代码如下
/*** 使用多线程处理列表中的数据* @param list 待处理的微信客户链接详情列表*/public void multiThreadProcessData(List<WechatCustomerLinkDetail> list) {// 将大集合分割为多个小集合,以便多线程处理List<List<WechatCustomerLinkDetail>> partitionData = partitionData(list, 10);// 获取线程池执行器ThreadPoolTaskExecutor executor = SpringUtils.getBean("threadPoolTaskExecutor");// 创建计数器,用于线程同步CountDownLatch latch = new CountDownLatch(partitionData.size());for (List<WechatCustomerLinkDetail> details : partitionData) {// 提交任务给线程池执行,每个任务负责处理一个分割后的列表executor.execute(() -> {try {for (WechatCustomerLinkDetail detail : details) {//打印线程名称//System.out.println("name========"+Thread.currentThread().getName());// 对每个详情进行处理,填充微信用户名称信息 这里就是业务逻辑处理的地方fillWechatUserNameInfo(detail);}} catch (Exception e) {// 捕获异常并打印,避免线程异常中断e.printStackTrace();} finally {// 处理完成后,计数器减一,用于线程同步latch.countDown();}});}// 等待所有任务完成try {latch.await();} catch (InterruptedException e) {// 线程被中断,打印异常信息e.printStackTrace();}}
分割数据列表 partitionData 代码
/*** 分割数据列表成多个小块。* @param dataList 待分割的数据列表,包含微信客户链接详情。* @param partitionSize 每个分区的大小。* @return 分割后的数据列表,每个元素是一个分区,分区内部保持原有顺序。*/private List<List<WechatCustomerLinkDetail>> partitionData(List<WechatCustomerLinkDetail> dataList, int partitionSize) {List<List<WechatCustomerLinkDetail>> partitions = new ArrayList<>();// 总数据量int size = dataList.size();// 每个分区的实际大小,整除操作保证每个分区大小尽量均匀int batchSize = size / partitionSize;// 遍历分区数量次,为每个分区添加数据for (int i = 0; i < partitionSize; i++) {// 当前分区的起始索引int fromIndex = i * batchSize;// 当前分区的结束索引,如果是最后一个分区,则包含所有剩余数据int toIndex = (i == partitionSize - 1) ? size : fromIndex + batchSize;// 将当前分区的数据添加到分区列表中partitions.add(dataList.subList(fromIndex, toIndex));}return partitions;}
到这里整个基于多线程处理数据的代码就整理完了,代码结构并不复杂,主要是注意数据查询以及服务器最大线程数相关数据,防止线程不够用的情况。
相关文章:
基于Java多线程处理数据
基于Java多线程处理数据 背景代码实现 背景 在日常工作中,有一个同步企微客户-学员关系接口的定时任务在执行中随着数据量的不断增长,定时任务的执行结束时间也出现了当天执行不完的情况,影响到了正常业务的运行。基于这种情况,在…...

日常知识点之遇到问题结构体按位构造协议时和期望不一致,研究记录一下
遇到一个问题,在做业务的时候,涉及到协议相关,按位进行设计,用结构体来模拟协议时,发现内存存储和实际目的不一致,知道是大小端以及计算机底层存储逻辑相关,所以研究了一下。 1:简单…...

spring mvc 文件下载
在web中下载的方式大多基于servlet,在web.xml中配置下载路径,这里再介绍json(转成base64字符串)和blob的使用方式 servlet WEB-INF/web.xml <!--url映射--> <servlet-mapping><servlet-name>DowloadServlet</servlet-name>&l…...

Qt WebEngine基于WebEngineScript注入js脚本
在之前的文章中,我们介绍了Qt WebEngine注入js的用法,及runJavaScript()的用法,该方法主要是用在页面加载完成后,为了和网页做一些交互时使用。有时候需要监听网页加载完成的一些状态或信息,则需要网页加载前注入js来实…...
案例分享-国外UI设计界面赏析
国外UI设计倾向于简洁的布局和清晰的排版,减少视觉干扰,提升用户体验。通过合理的色彩搭配和图标设计,营造舒适愉悦的使用氛围。 设计师不拘泥于传统框架,勇于尝试新元素和理念,使界面独特有趣。同时,强调以…...
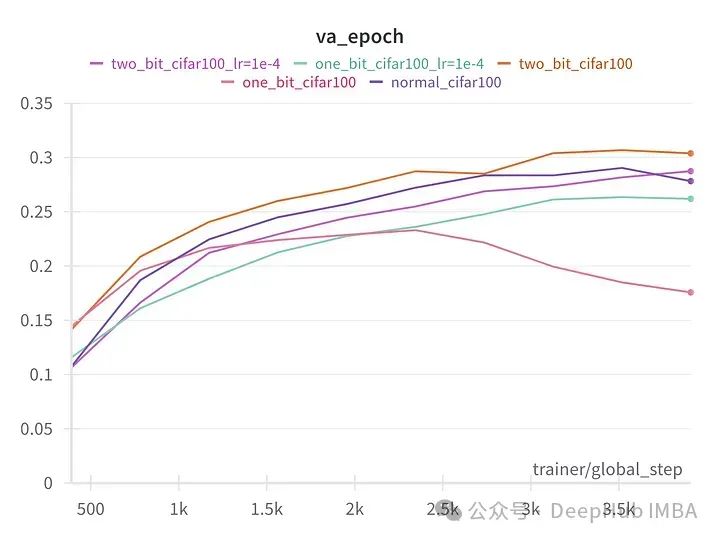
用PyTorch 从零开始构建 BitNet 1.58bit
我们手动实现BitNet的编写,并进行的一系列小实验证实,看看1.58bit 模型是否与全精度的大型语言模型相媲美! 什么是量化以及为什么需要它? 量化是用更少的比特数表示浮点数的过程。当两个数字使用不同的比特数进行量化时…...

信创安全 | 新一代内网安全方案—零信任沙盒
在当今数字化时代,访问安全和数据安全成为企业面临的重要挑战。传统的边界防御已经无法满足日益复杂的内网办公环境,层出不穷的攻击手段已经让市场单一的防御手段黔驴技穷。当企业面临越来越复杂的网络威胁和数据泄密风险时,更需要一种综合的…...
)
Redis的回收策略(淘汰策略)
volatile-lru :从已设置过期时间的数据集( server.db[i].expires )中挑选最近最少使用的数据淘汰 volatile-ttl : 从已设置过期时间的数据集( server.db[i].expires ) 中挑选将要过期的数据淘汰 volatile…...

Electron-builder 打包
项目比较简单,仅使用了 Electron 原生js 安装 electron-builder npm install electron-builder --dev配置 package.json 中的打包命令 {"script":{// ..."dev": "electron .","pack": "electron-builder"} }添…...

笔试练习day3
目录 BC149 简写单词题目解析代码 dd爱框框题目解析解析代码方法一暴力解法方法二同向双指针(滑动窗口) 除2!题目解析解法模拟贪心堆 感谢各位大佬对我的支持,如果我的文章对你有用,欢迎点击以下链接 🐒🐒🐒 个人主页 🥸…...

企业想要将大模型技术应用到企业管理中需具备什么条件?
#企业 #企业管理 #大模型 企业想要将大模型技术应用到企业管理中,需要考虑以下几个关键条件: 1.明确的需求定位:企业应首先诊断自身的业务场景、数据、算法、基础设施预算以及战略等能力,明确大模型能够为企业带来的具体赋…...

go 事件机制(观察者设计模式)
背景: 公司目前有个业务,收到数据后,要分发给所有的客户端或者是业务模块,类似消息通知这样的需求,自然而然就想到了事件,观察者比较简单就自己实现以下,确保最小功能使用支持即可,其…...

RISC-V竞赛|第二届 RISC-V 软件移植及优化锦标赛报名正式开始!
目录 赛事背景 赛道方向 适配夺旗赛 优化竞速赛 比赛赛题(总奖金池8万元!) 🔥竞速赛 - OceanBase 移植与优化 比赛赛程(暂定) 赛事说明 「赛事背景」 为了推动 RISC-V 软件生态更快地发展࿰…...

【VTK】ubuntu手动编译VTK9.3 Generating qmltypes file 失败
环境 硬件:Jetson Xavier NX 套件 系统:Ubuntu 20.04 软件 :QT5.15.6 解决 0、问题 最近在Jetson Xavier NX 套件上编译VTK库,因为想要配合QQuick使用,所以cmake配置时勾选了VTK_MODULE_ENABLE_VTK_GUISupportQtQu…...

学习java的日子 Day64 学生管理系统 web2.0 web版本
MVC设计模式 概念 - 代码的分层 MVC:项目分层的思想 字母表示层理解MModle模型层业务的具体实现VView视图层展示数据CController控制器层控制业务流程(跳转) 1.细化理解层数 Controller:控制器层,用于存放Servlet&…...

【第14章】Spring Cloud之Gateway路由断言(IP黑名单)
文章目录 前言一、内置路由断言1. 案例(Weight)2. 更多断言 二、自定义路由断言1. 黑名单断言2. 全局异常处理3. 应用配置4. 单元测试 总结 前言 Spring Cloud Gateway可以让我们根据请求内容精确匹配到对应路由服务,官方已经内置了很多路由断言,我们也…...

3、pnpm yarn npm
项目里实际上就只有这些依赖 node module 里却有很多的包 原因: 比如说vue,vue内部有依赖了其余的包。工具又依赖了别的依赖 造成的问题:我可以直接去用这个包,但是这个包在package.json中却没有看到-----幽灵依赖 那如果说别…...

❄️5. Kubernetes核心资源之名称空间和Pod实战
**什么是名称空间Namespace: ** Namespace是k8s系统中的一种非常重要资源,它的主要作用是用来实现多套环境的资源隔离或者多用户的资源隔离。默认情况下,k8s集群中的所有的Pod都是可以相互访问的。但是在实际中,可能不想让两个Pod之间进行互…...

锂电池充电板电路设计
写这篇文章的目的主要是个人经验的总结,希望能给开发者们提供一种锂电池充电电路以及电源显示的电路思路。接下来从以下几个方面讲述电路。 设计这款电路的初衷是想用一块硬币大小的锂电池作为供电电源(3.5V-4.2V),降压供给3.3V电…...

工业互联网产教融合实训基地解决方案
一、引言 随着“中国制造2025”战略的深入实施与全球工业4.0浪潮的兴起,工业互联网作为新一代信息技术与制造业深度融合的产物,正引领着制造业向智能化、网络化、服务化转型。为培养适应未来工业发展需求的高素质技术技能人才,构建工业互联网…...

Linux栈机制解析:从原理到实践应用
1. Linux中的栈机制概述在计算机系统中,栈(stack)是一种后进先出(LIFO)的数据结构,它不仅在软件层面有着广泛应用,在硬件层面也扮演着关键角色。大多数处理器架构都实现了硬件栈,有专门的栈指针寄存器和特定的硬件指令来完成入栈/…...

蒙特卡洛方法与科学计算十大经典算法解析
1. 蒙特卡洛方法:从赌场到科学计算的跨界革命 1946年,三位天才科学家在洛斯阿拉莫斯实验室的咖啡时间里,可能不会想到他们正在创造一种将彻底改变科学计算的方法。蒙特卡洛方法的名字来源于摩纳哥著名的赌城,这暗示了其核心思想—…...

ESP32/ESP8266旋转编码器驱动库:支持加速度响应与复合按键事件
1. 项目概述Ai Esp32 Rotary Encoder是一款专为 ESP32 和 ESP8266 平台深度优化的旋转编码器驱动库,其设计目标远超基础脉冲计数——它面向嵌入式人机交互(HMI)场景,提供带加速度响应的数值选择、边界约束、步进精度控制、循环遍历…...

2026届学术党必备的降AI率平台横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 降低那个AIGC率的关键要点在于削弱机器生成所呈现出的模式化特性。其一,对句式结…...

宫外孕打掉需要住院吗?术后修护核心指南
宫外孕作为妇科高发急腹症,不少女性存在认知误区,疑惑“宫外孕打掉是否需要住院”。事实上,宫外孕绝非普通流产,其处理必须住院,且术后修护直接影响女性后续生殖健康。本文结合行业洞察,围绕宫外孕住院必要…...

信通院:AI4SE行业现状调查报告 2026
这份信通院 2026 年 AI4SE 行业现状调查报告,核心是 AI 与软件工程深度融合进入规模化落地关键期,全流程提效显著,企业高度重视,但仍面临人才、成本等挑战,未来将走向自主编程、多智能体协同的新范式。一、调研概况有效…...
)
OpenCV直线检测避坑指南:HoughLinesP参数调优实战(Python版)
OpenCV直线检测避坑指南:HoughLinesP参数调优实战(Python版) 在计算机视觉项目中,直线检测往往是基础却关键的一环。无论是自动驾驶中的车道线识别,还是工业质检中的零件尺寸测量,亦或是文档扫描应用中的表…...

若依微服务版实战:5分钟搞定积木报表1.5.6集成与权限控制
若依微服务版深度整合积木报表1.5.6全流程指南 1. 环境准备与架构设计 在微服务架构中引入报表模块需要特别注意服务边界和资源隔离。积木报表1.5.6作为一款企业级Web报表工具,其与若依微服务版的整合涉及以下几个核心层面: 服务独立性:建议将…...

Vivado团队协作效率翻倍:如何用企业级Vivado_init.tcl统一团队编译环境?
Vivado团队协作效率翻倍:如何用企业级Vivado_init.tcl统一团队编译环境? 在FPGA设计领域,团队协作的效率往往被环境配置差异所拖累。想象这样一个场景:当十位工程师使用不同的线程参数编译同一项目时,不仅性能表现参差…...

BetterJoy终极指南:在Windows电脑上完美使用Switch手柄玩游戏
BetterJoy终极指南:在Windows电脑上完美使用Switch手柄玩游戏 【免费下载链接】BetterJoy Allows the Nintendo Switch Pro Controller, Joycons and SNES controller to be used with CEMU, Citra, Dolphin, Yuzu and as generic XInput 项目地址: https://gitco…...