【数据结构】顺序结构实现:特殊完全二叉树(堆)+堆排序
二叉树
- 一.二叉树的顺序结构
- 二.堆的概念及结构
- 三.堆的实现
- 1.堆的结构
- 2.堆的初始化、销毁、打印、判空
- 3.堆中的值交换
- 4.堆顶元素
- 5.堆向上调整算法:实现小堆的插入
- 6.堆向下调整算法:实现小堆的删除
- 7.堆的创建
- 1.堆向上调整算法:建堆+建堆的时间复杂度:O(n * logn)
- 1.堆向下调整算法:建堆+建堆的时间复杂度:O(n)
- 四.堆的应用
- 1.TOP-K问题
- 2.堆排序+堆排序时间复杂度:O(n * logn)
一.二叉树的顺序结构
普通的二叉树是不适合用数组来存储的,因为可能会存在大量的空间浪费。而完全二叉树更适合使用顺序结构存储。现实中我们通常把堆(完全二叉树)使用顺序结构的数组来存储,需要注意的是这里的堆和操作系统虚拟进程地址空间中的堆是两回事,一个是数据结构,一个是操作系统中管理内存的一块区域分段。

二.堆的概念及结构

堆的性质:
- 堆中某个结点的值总是不大于或不小于其父结点的值;
- 堆总是一棵完全二叉树。


三.堆的实现
1.堆的结构
将堆(完全二叉树)看作顺序表,利用顺序表存储堆中的值。结构如下:
typedef int HPDataType;typedef struct Heap
{HPDataType* a;int size;int capacity;
}HP;
2.堆的初始化、销毁、打印、判空
实际就是顺序表的那一套。
void HPInit(HP* php)
{assert(php);php->a = NULL;php->size = php->capacity = 0;
}void HPDestory(HP* php)
{assert(php);free(php->a);php->a = NULL;php->size = php->capacity = 0;
}bool HPEmpty(HP* php)
{assert(php);return php->size == 0;
}void HPPrint(HP* php)
{assert(php);for (int i = 0; i < php->size; i++){printf("%d ", php->a[i]);}printf("\n");
}
3.堆中的值交换
void Swap(HPDataType* x, HPDataType* y)
{HPDataType tmp = *x;*x = *y;*y = tmp;
}
4.堆顶元素
HPDataType HPTop(HP* php)
{assert(php);assert(php->size > 0);return php->a[0];
}
5.堆向上调整算法:实现小堆的插入
堆的插入:在已知是堆的条件下进行尾插,利用堆向上调整算法使其依旧保持堆的特征。
堆向上调整算法:
- 先将元素插入堆的末尾。
- 插入之后如果堆的性质遭到破坏,将新插入的节点顺着父亲节点往上调整到合适的位置即可。
例如:先插入一个10到数组的尾上,再进行向上调整算法,直到满足堆。

void AdjustUp(HPDataType* a, int child)
{int parent = (child - 1) / 2;while (child > 0){//小堆if (a[child] < a[parent]) //大堆就是将小于号变成大于号{Swap(&a[child], &a[parent]);child = parent;parent = (child - 1) / 2;}else{break;}}
}void HPPush(HP* php, HPDataType x)
{assert(php);//容量满了——>扩容if (php->size == php->capacity){int newcapacity = php->capacity == 0 ? 4 : 2 * php->capacity;HPDataType* tmp = (HPDataType*)realloc(php->a, newcapacity * sizeof(HPDataType));if (tmp == NULL){perror("realloc fail!");return;}php->a = tmp;php->capacity = newcapacity;}//尾插php->a[php->size++] = x;//向上调整算法AdjustUp(php->a, php->size - 1);
}
6.堆向下调整算法:实现小堆的删除
堆的删除:在已知是堆的条件下删除堆顶的数据(堆的尾删无意义依旧是堆),先将堆顶与堆尾的数据进行交换,再删除堆尾的数据,最后利用堆向下调整算法,将堆顶向下调整,使其依旧保持堆的特征。
堆向下调整算法:
- 将堆顶元素与堆中最后一个元素进行交换。
- 删除堆中最后一个元素。
- 将堆顶元素向下调整到满足堆特性为止。
例如:现在我们给出一个数组,逻辑上看做一颗完全二叉树。我们通过从根结点开始的向下调整算法可以把它调整成一个小堆。向下调整算法有一个前提:左右子树必须是都是堆,才能调整。

void AdjustDown(HPDataType* a, int n, int parent)
{//假设左孩子小int child = 2 * parent + 1;while (child < n){//找出真正小的那个孩子if (child + 1 < n && a[child + 1] < a[child]) //大堆就是将小于号变成大于号{child++;}if (a[child] < a[parent]) //大堆就是将小于号变成大于号{Swap(&a[child], &a[parent]);parent = child;child = parent * 2 + 1;}else{break;}}
}void HPPop(HP* php)
{assert(php);assert(php->size > 0);Swap(&php->a[0], &php->a[php->size - 1]);php->size--;AdjustDown(php->a, php->size, 0);
}
7.堆的创建
1.堆向上调整算法:建堆+建堆的时间复杂度:O(n * logn)
//假设模拟php->a[] = {19,34,65,18,15,28};

void AdjustUpCreateHeap(HP* php)
{//根节点不需调整,从第二个节点开始调整for (int i = 1; i < php->size; i++){AdjustUp(php->a, i);}
}
int main()
{HP hp;HPInit(&hp);hp.a = (HPDataType*)malloc(sizeof(HPDataType) * 6);hp.a[0] = 19;hp.a[1] = 34;hp.a[2] = 65;hp.a[3] = 18;hp.a[4] = 15;hp.a[5] = 28;hp.size += 6;hp.capacity += 6;AdjustUpCreateHeap(&hp);HPPrint(&hp); //15 18 28 34 19 65
}
计算向上调整算法建堆时间复杂度:
因为堆是完全⼆叉树,而满⼆叉树也是完全⼆叉树,此处为了简化使用满⼆叉树来证明(时间复杂度本来看的就是近似值,多几个结点不影响最终结果)



1.堆向下调整算法:建堆+建堆的时间复杂度:O(n)
//假设模拟php->a[] = {19,34,65,18,15,28};

void AdjustDownCreateHeap(HP* php)
{//叶子节点不需调整,从倒数第一个非叶子节点开始调整for (int i = (php->size - 1 - 1) / 2; i >= 0; i--){AdjustDown(php->a, php->size, i);}
}
int main()
{HP hp;HPInit(&hp);hp.a = (HPDataType*)malloc(sizeof(HPDataType) * 6);hp.a[0] = 19;hp.a[1] = 34;hp.a[2] = 65;hp.a[3] = 18;hp.a[4] = 15;hp.a[5] = 28;hp.size += 6;hp.capacity += 6;AdjustDownCreateHeap(&hp); //15 18 28 19 34 65HPPrint(&hp);
}
计算向下调整算法建堆时间复杂度:


四.堆的应用
1.TOP-K问题
TOP-K问题:即求数据个数N中前K个最大的元素或者最小的元素,一般情况下数据量都比较大。
对于Top-K问题,能想到的最简单直接的方式就是排序,但是:如果数据量非常大,排序就不太可取了(可能数据都不能一下子全部加载到内存中)。最佳的方式就是用堆来解决,基本思路如下:
前置知识:
1 GB = 1024 MB = 1024*1024 KB = 1024*1024*1024 Byte(大约10.7亿Byte)- 40Byte转化为GB:
40 / 10.7 近似:3.72GB内存
问题一:假设只有4GB内存,要在10亿个整数中,如何找出最大的前10个数?
方法:
- 建一个10亿个整数的大堆(利用向下调整算法)。时间复杂度:
O(n) - 进行10次(Top+Pop):取最大的前10个数。时间复杂度:
O(10 * logn) = O(logn)(10忽略不计)
总时间复杂度:O(n) ; 空间复杂度:O(n)
问题二:假设只有1GB内存,在这些磁盘文件中,取最大的前10个数。
方法:
- 先存储1GB内存的数据,再取最大前10个数,依次循环4次
- 最后在40个数据中取最大的前10个数
虽然节省了一些内存,但是依旧要花费相当大的内存,而且频繁的读取数据效率低。有无不需要花费多少内存就能完成的呢?
问题三:假设只有1KB内存,在这些磁盘文件中,取最大的前10个数。
方法:
- 用数据集合中前K个元素来建堆:
- 取前K个最大的元素,则建小堆
- 取前K个最小的元素,则建大堆
时间复杂度:O(k)
- 用剩余的N-K个元素依次与堆顶元素来比较,不满足则替换堆顶元素。将剩余N-K个元素依次与堆顶元素比完之后,堆中剩余的K个元素就是所求的前K个最小或者最大的元素。
时间复杂度:O((n-k) * logk)
总时间复杂度:O(n) ;空间复杂度:O(1);(k忽略不计)
代码如下:
void CreateNDate()
{//写入n个数值int n = 10000000;srand((unsigned int)time(NULL));//以写的方式打开文件const char* file = "data.txt";FILE* pf = fopen(file, "w");if (pf == NULL){perror("fopen fail!");return;}//写数据进入文件for (int i = 0; i < n; i++){int val = (rand() + i) % 10000000;fprintf(pf, "%d\n", val);}//关闭文件fclose(pf);pf = NULL;
}void TopK()
{//以读的方式打开文件const char* file = "data.txt";FILE* pf = fopen(file, "r");if (pf == NULL){perror("fopen fail!");return;}//开K个空间:为建小堆做准备int k;printf("请输入要取的最大前k个数:");scanf("%d", &k);int* kminheap = (int*)malloc(sizeof(int) * k);if (kminheap == NULL){perror("malloc fail!");return;}//读取文件中的前K个数据for (int i = 0; i < k; i++){fscanf(pf, "%d", &kminheap[i]);}//建K个数的小堆(向下调整算法)for (int i = (k - 1 - 1) / 2; i >= 0; i--){AdjustDown(kminheap, k, i);}//取剩下的N-K个数与堆顶进行比较+向下调整int val;while (fscanf(pf, "%d", &val) != EOF){if (val > kminheap[0]){kminheap[0] = val;AdjustDown(kminheap, k, 0);}}printf("最大的前%d个数:", k);for (int i = 0; i < k; i++){printf("%d ", kminheap[i]);}printf("\n");//关闭文件fclose(pf);pf = NULL;
}int main()
{CreateNDate();TopK();return 0;
}

2.堆排序+堆排序时间复杂度:O(n * logn)
假设降序:那是建小堆还是建大堆呢?
结论:
- 升序:建大堆。
- 降序:建小堆。
利用堆删除思想来进行排序:建堆和堆删除中都用到了向下调整,因此掌握了向下调整,就可以完成堆排序。
假设6个数据建小堆:
- 已知堆顶最小,可以将堆顶与队尾进行交换。
- 向下调整保持前5个数据为小堆。
- 循环步骤1与步骤2直到排序完成。

void HeapSort(HPDataType* a, int n)
{向上调整算法建小堆:O(n*logn)//for (int i = 1; i < n; i++)//{// AdjustUp(a, i);//}//向下调整算法建小堆:O(n)for (int i = (n - 1 - 1) / 2; i >= 0; i--){AdjustDown(a, n, i);}//O(n*logn)int end = n - 1;while (end > 0){Swap(&a[0], &a[end]);AdjustDown(a, end, 0);end--;}
}
int main()
{int a[] = { 1,5,3,6,8,9,2,4,0,7 };HeapSort(a, sizeof(a) / sizeof(a[0]));for (int i = 0; i < sizeof(a) / sizeof(a[0]); i++){printf("%d ", a[i]);}printf("\n");
}

堆排序时间复杂度计算:

重点理解:向下调整算法。
相关文章:
【数据结构】顺序结构实现:特殊完全二叉树(堆)+堆排序
二叉树 一.二叉树的顺序结构二.堆的概念及结构三.堆的实现1.堆的结构2.堆的初始化、销毁、打印、判空3.堆中的值交换4.堆顶元素5.堆向上调整算法:实现小堆的插入6.堆向下调整算法:实现小堆的删除7.堆的创建1.堆向上调整算法:建堆建堆的时间复…...

【c++学习技术栈】
c学习技术栈 基础c基础组件中间件框架devops性能目标岗位 基础 计算机网络数据结构与算法操作系统linux c 基础组件 池式组件:线程池,内存池,db数据库连接池原子,无锁队列,ringbuffer,定时器。日志&…...

swift 自定义DatePacker
import Foundationenum AppDatePickerStyle {case KDatePickerDate //年月日case KDatePickerTime //年月日时分case kDatePickerMonth // 年月case KDatePickerSecond //秒}class AppDatePicker: UIView {private let jk_rootView UIApplication.shared.keyWindow!pri…...

MySQL事务,锁,MVCC总结
mysql中最重要的就是事务,其四大特性让我们维持了数据的平衡,一致。那么事务究竟是什么,与什么相关,他的使用步骤,以及使用过程中我们会遇到什么问题呢?下面我们一起学习交流! 1.MySQL的存储引擎ÿ…...

24/8/7 算法笔记 支持向量机回归问题天猫双十一
import numpy as np from sklearn.svm import SVR import matplotlib.pyplot as plt X np.linspace(0,2*np.pi,50).reshape(-1,1) y np.sin(X) plt.scatter(X,y) 建模 线性核函数 svr SVR(kernel linear) svr.fit(X,y.ravel())#变成一维y_ svr.predict(X) plt.scatter(…...

win7系统利用定时启动+脚本实现MySQL文件自动备份
前言 最近接到项目,数据量不大但对运行数据的安全性要求极高,为避免因不可抗拒因素导致的数据丢失,选择机械硬盘作为数据存储盘,并使用脚本方式对文件进行备份 一、脚本 下面为自动备份文件的 脚本,可根据自身情况进…...

基于Java多线程处理数据
基于Java多线程处理数据 背景代码实现 背景 在日常工作中,有一个同步企微客户-学员关系接口的定时任务在执行中随着数据量的不断增长,定时任务的执行结束时间也出现了当天执行不完的情况,影响到了正常业务的运行。基于这种情况,在…...

日常知识点之遇到问题结构体按位构造协议时和期望不一致,研究记录一下
遇到一个问题,在做业务的时候,涉及到协议相关,按位进行设计,用结构体来模拟协议时,发现内存存储和实际目的不一致,知道是大小端以及计算机底层存储逻辑相关,所以研究了一下。 1:简单…...

spring mvc 文件下载
在web中下载的方式大多基于servlet,在web.xml中配置下载路径,这里再介绍json(转成base64字符串)和blob的使用方式 servlet WEB-INF/web.xml <!--url映射--> <servlet-mapping><servlet-name>DowloadServlet</servlet-name>&l…...

Qt WebEngine基于WebEngineScript注入js脚本
在之前的文章中,我们介绍了Qt WebEngine注入js的用法,及runJavaScript()的用法,该方法主要是用在页面加载完成后,为了和网页做一些交互时使用。有时候需要监听网页加载完成的一些状态或信息,则需要网页加载前注入js来实…...
案例分享-国外UI设计界面赏析
国外UI设计倾向于简洁的布局和清晰的排版,减少视觉干扰,提升用户体验。通过合理的色彩搭配和图标设计,营造舒适愉悦的使用氛围。 设计师不拘泥于传统框架,勇于尝试新元素和理念,使界面独特有趣。同时,强调以…...
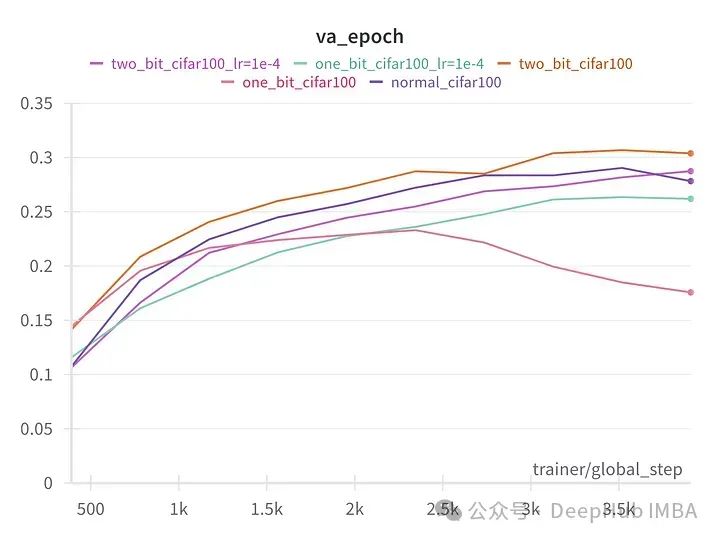
用PyTorch 从零开始构建 BitNet 1.58bit
我们手动实现BitNet的编写,并进行的一系列小实验证实,看看1.58bit 模型是否与全精度的大型语言模型相媲美! 什么是量化以及为什么需要它? 量化是用更少的比特数表示浮点数的过程。当两个数字使用不同的比特数进行量化时…...

信创安全 | 新一代内网安全方案—零信任沙盒
在当今数字化时代,访问安全和数据安全成为企业面临的重要挑战。传统的边界防御已经无法满足日益复杂的内网办公环境,层出不穷的攻击手段已经让市场单一的防御手段黔驴技穷。当企业面临越来越复杂的网络威胁和数据泄密风险时,更需要一种综合的…...
)
Redis的回收策略(淘汰策略)
volatile-lru :从已设置过期时间的数据集( server.db[i].expires )中挑选最近最少使用的数据淘汰 volatile-ttl : 从已设置过期时间的数据集( server.db[i].expires ) 中挑选将要过期的数据淘汰 volatile…...

Electron-builder 打包
项目比较简单,仅使用了 Electron 原生js 安装 electron-builder npm install electron-builder --dev配置 package.json 中的打包命令 {"script":{// ..."dev": "electron .","pack": "electron-builder"} }添…...

笔试练习day3
目录 BC149 简写单词题目解析代码 dd爱框框题目解析解析代码方法一暴力解法方法二同向双指针(滑动窗口) 除2!题目解析解法模拟贪心堆 感谢各位大佬对我的支持,如果我的文章对你有用,欢迎点击以下链接 🐒🐒🐒 个人主页 🥸…...

企业想要将大模型技术应用到企业管理中需具备什么条件?
#企业 #企业管理 #大模型 企业想要将大模型技术应用到企业管理中,需要考虑以下几个关键条件: 1.明确的需求定位:企业应首先诊断自身的业务场景、数据、算法、基础设施预算以及战略等能力,明确大模型能够为企业带来的具体赋…...

go 事件机制(观察者设计模式)
背景: 公司目前有个业务,收到数据后,要分发给所有的客户端或者是业务模块,类似消息通知这样的需求,自然而然就想到了事件,观察者比较简单就自己实现以下,确保最小功能使用支持即可,其…...

RISC-V竞赛|第二届 RISC-V 软件移植及优化锦标赛报名正式开始!
目录 赛事背景 赛道方向 适配夺旗赛 优化竞速赛 比赛赛题(总奖金池8万元!) 🔥竞速赛 - OceanBase 移植与优化 比赛赛程(暂定) 赛事说明 「赛事背景」 为了推动 RISC-V 软件生态更快地发展࿰…...

【VTK】ubuntu手动编译VTK9.3 Generating qmltypes file 失败
环境 硬件:Jetson Xavier NX 套件 系统:Ubuntu 20.04 软件 :QT5.15.6 解决 0、问题 最近在Jetson Xavier NX 套件上编译VTK库,因为想要配合QQuick使用,所以cmake配置时勾选了VTK_MODULE_ENABLE_VTK_GUISupportQtQu…...

谱聚类实战:如何让声纹模型自动分辨一段录音里有几个人说话?
谱聚类在声纹识别中的应用:如何自动判断录音中的说话人数量 想象一下,你手头有一段长达两小时的会议录音,里面有五位不同声线的参与者交替发言。作为开发者,你需要设计一个系统,不仅能识别每个人的声音特征,…...

新手避坑指南:用Boson NetSim 11模拟多子网互联,从连线到ping通的全流程复盘
新手避坑指南:用Boson NetSim 11模拟多子网互联,从连线到ping通的全流程复盘 第一次打开Boson NetSim 11时,那种兴奋和忐忑交织的感觉至今难忘。作为网络工程初学者,我们往往怀揣着教科书上的理论知识,却在第一次实操时…...

从API调用到完整应用:手把手教你用Dashscope和Streamlit搭建一个多模态聊天机器人
从API调用到完整应用:手把手教你用Dashscope和Streamlit搭建多模态聊天机器人 在AI技术快速落地的今天,将强大的API能力转化为直观可用的产品已成为开发者的核心技能。想象一下,你只需要200行Python代码,就能构建一个能"看懂…...

Rust错误处理最佳实践:从恐慌到优雅处理
Rust错误处理最佳实践:从恐慌到优雅处理 前言 大家好,我是第一程序员(名字大,人很菜),一个正在跟Rust所有权和生命周期死磕的后端转Rust萌新。最近,我开始学习Rust的错误处理,发现…...

电子工程师眼中的城市电路板:无人机航拍引发的职业思考
1. 电子工程师的强迫症与无人机视角的冲突作为一名从业十年的电子工程师,我完全理解小舒所说的那种"焊盘上的电阻、电容不能歪"的强迫症。这种职业习惯已经深深烙印在我们的工作方式中 - 从PCB布局到元件焊接,从线缆走线到机箱布线,…...

OpenClaw任务编排:Qwen3-4B-Thinking-2507-GPT-5-Codex-Distill-GGUF处理依赖型工作流
OpenClaw任务编排:Qwen3-4B-Thinking-2507-GPT-5-Codex-Distill-GGUF处理依赖型工作流 1. 为什么需要任务编排 去年夏天,我接手了一个数据分析项目,需要定期从十几个网站抓取数据,清洗后生成分析报告,再邮件发送给团…...

# 发散创新:基于Python与Stable Diffusion的AI绘画自动化流程设计与实践
发散创新:基于Python与Stable Diffusion的AI绘画自动化流程设计与实践 在人工智能技术飞速发展的今天,AI绘画已从实验室走向大众创作场景。如何将这一前沿能力融入开发者工作流?本文以 Python Stable Diffusion API(如InvokeAI或…...

雷达目标分类及宽带测角方案设计实现
本文参考,仅供学习使用基于飞腾M6678的雷达目标 分类和宽带测角研究与实现硬件计算平台介绍1. 飞腾M6678芯片核心参数与优势飞腾M6678是国防科技大学自主研发的国产多核DSP,专为数字信号处理设计,核心特性为:硬件资源:…...

国产DSP
1. 知识关联图(Mermaid)1.1 中断层级图graph LR A[Input Event<br>(SRIO/DMA/定时器等)] --> B[CIC中断分发控制器] B --> C[核内INTC中断控制器] C --> D[CorePac DSP核心] style B fill:#f0f0ff,stroke:#333 note right of B: …...
)
基于Copula函数的多风场出力相关性分析场景生成与聚类削减方法(MATLAB实现)
考虑多风场出力相关性的可再生能源场景生成/风电场景生成,并通过聚类算法场景削减成几个场景,每个场景都有确定的出现概率。 完美复现《考虑多风电场出力 Copula 相关关系的场景生成方法》 Copula 函数(连接函数)描述空间相邻风电场间的相关性࿰…...