scheduler 的使用实验对比和总结(PyTorch)
这篇文章是在完成 HW02 的过程中所产生的,是关于各 scheduler (ReduceLROnPlateau(),CosineAnnealingLR(),CosineAnnealingWarmRestarts())使用的对比实验。
起因是为了在 Kaggle 上跑出更高的成绩,但结果确出乎我的意料,为了工作不白费,我决定将它们的结果重新可视化分享给你们。我一开始没有过多的修改初始配置,这篇文章的目的仅仅是为了给你展现不同 scheduler 下的学习率变化以及对实验结果的影响(片面的)。
时间原因我仅在这个数据集上跑了对比实验。
文章目录
- 开始实验
- **ReduceLROnPlateau()**
- 学习率变化曲线
- 实验数据
- **Kaggle 分数: 0.74427**
- **CosineAnnealingLR()**
- 学习率变化曲线
- 实验数据
- **Kaggle 分数: 0.74391(没有提升)**
- **CosineAnnealingWarmRestarts()**
- 学习率变化曲线
- 实验结果
- **Kaggle 分数: 0.74328(没有提升)**
- T_0 *= 2
- 学习率变化曲线
- 实验结果
- **Kaggle 分数: 0.74403(没有提升)**
- **no scheduler**
- 学习率变化曲线
- 实验结果
- **Kaggle 分数: 0.74408**
- **实验结果对比**
- 修改 lr=2.5e-4,重新实验
- **实验结果对比**
- 总结
开始实验
为了对比,每个 scheduler 都跑了 300 个epoch,可能不多,但也能看出些端倪。
这里贴一下我的其他参数,如果不需要做这个 HW,可以跳过这段往下看,并不影响。
跑 300 个 epoch 是因为在这个参数的设置(请勿模仿)下,大概到 300 就没有什么波动了。
"""dropout(p=0.25)"""concat_nframes = 15 # the number of frames to concat with, n must be odd (total 2k+1 = n frames) train_ratio = 0.95 # the ratio of data used for training, the rest will be used for validation# training parameters seed = 1213 # random seed batch_size = 512 # batch size num_epoch = 300 # the number of training epoch learning_rate = 5e-4 # learning ratehidden_layers = 6 # the number of hidden layers hidden_dim = 512 # the hidden dim
最初,我增加了一个自动调整 learning_rate 的 scheduler,选择的是 torch.optim.lr_scheduler 中的 ReduceLROnPlateau()。
ReduceLROnPlateau()
先介绍一下参数方便理解:
torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode=‘min’, factor=0.1, patience=10, threshold=0.0001, threshold_mode=‘rel’, cooldown=0, min_lr=0, eps=1e-08, verbose=False)
optimizer (Optimizer):指定需要对哪个优化器对象进行学习率调整。mode (str):指标的模式。可以是“min”或“max”。如果是“min”,那么当指标停止降低时将调整学习率;如果是“max”,那么当指标停止升高时将调整学习率。factor (float):学习率缩小的因子。新学习率=旧学习率 * factor。注意,factor 不能大于1。patience (int):如果指标没有改善,则等待多少个epoch来调整学习率。threshold (float):指标的变化量阈值,如果小于此值,则将其视为没有改进。threshold_mode (str):判断阈值的模式。可以是“rel”或“abs”。如果是“rel”,动态阈值等于最优值乘以(1+threshold)(在’max’模式下)或最优值乘以(1-threshold)(在’min’模式下)。在’abs’模式下,动态阈值等于最优值加上threshold(在’max’模式下)或最优值减去threshold(在’min’模式下)。cooldown (int):表示在减小学习率之后等待几个epoch才能再次减小学习率。min_lr (float or list):学习率的下限。eps (float):表示应用于学习率的最小衰减量。如果新旧学习率之间的差异小于eps,则更新会被忽略。verbose (bool):如果为True,则在调整学习率时打印更新的消息。
optimizer = torch.optim.Adam(model.parameters(), lr=5e-4) # 假设初始学习率为 5e-4
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='max', factor=0.8, patience=10, threshold=0.001) # 如果 10 个 epoch 后都没有提升,lr *= factorfor epoch in range(num_epoch):train(...) # 训练模型validate(...) # 验证模型scheduler.step(metric) # 根据 metric 更新学习率
学习率变化曲线

实验数据
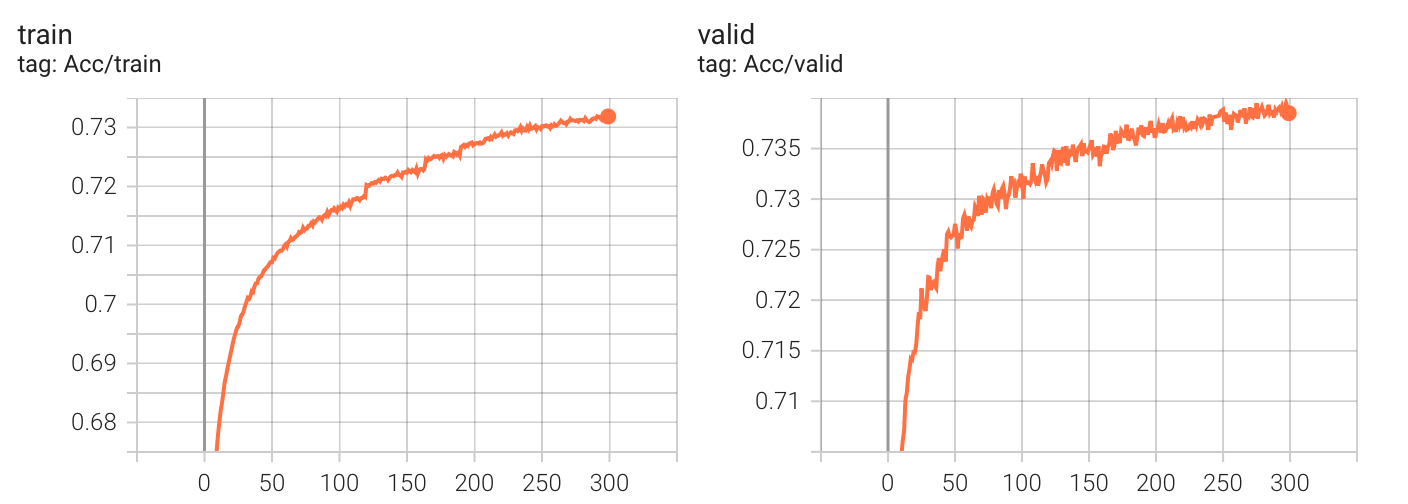
Kaggle 分数: 0.74427
最初选择 ReduceLROnPlateau() 的原因是基于一个设想的较乐观的情况:只要慢慢减少学习率一定会收敛到优秀的解。
当时发现了好几种scheduler,但看到根据 epoch 变化 learing rate 的 scheduler(比如 StepLR,ExponentialLR),觉得完全不如根据实验结果动态变化的 ReduceLROnPlateau 便没有进行选择。
看到这里你应该仅仅对 ReduceLROnPlateau() 有了简单的认识,不妨继续往下看,看看实验对比。
在 acc 卡住后,我试图去寻找其他的 scheduler,看能不能让 learning rate 在中途变大跳出一些区域后再变小,然后发现还有周期性变化的 scheduler(比如 CosineAnnealingLR,CyclicLR),于是,我尝试修改成 CosineAnnealingLR()。
CosineAnnealingLR()
torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min=0, last_epoch=- 1, verbose=False)
optimizer (Optimizer):指定需要对哪个优化器对象进行学习率调整。T_max (int): 表示半个周期的长度。例如,如果T_max=10,则学习率在第0个epoch时为最大值,在第0到第10个epoch之间以余弦函数形式逐渐减小,在第10个epoch时达到最小值,在第11到第20个epoch之间以余弦函数形式逐渐增大,在第20个epoch时回到最大值。eta_min (float): 表示学习率的最小值,在学习率下降到这个值之后,就不再下降了。默认为0。last_epoch (int): 表示上一次更新学习率的epoch索引。默认为-1,表示还没有开始训练。这个参数用于恢复训练时使用,可以将其设置为已经训练的epoch数减 1。verbose (bool):如果为True,则在调整学习率时打印更新的消息。
optimizer = torch.optim.Adam(model.parameters(), lr=5e-4) # 假设初始学习率为 5e-4
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=10, eta_min=1e-7)for epoch in range(num_epoch):train(...) # 训练模型validate(...) # 验证模型scheduler.step() # 更新学习率
学习率变化曲线

实验数据
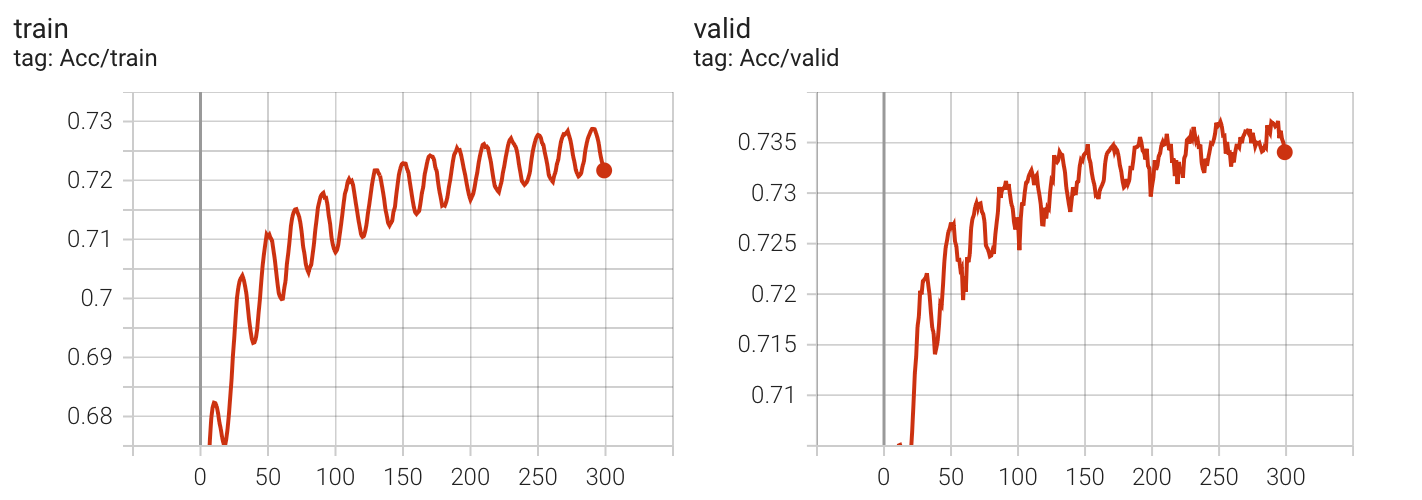
Kaggle 分数: 0.74391(没有提升)
这个 scheduler 中的 learning rate 变化曲线与余弦函数一致,但观察发现,CosineAnnealLR 的周期性变化似乎让收敛的过程变得曲折(多次实验效果都类似)。
观察 acc 和 lr 的变化:每一次 lr 逐步上升都会让 acc 下降。于是我想着有没有一种 scheduler,让 lr 跳过逐步上升的过程,于是找到了 CosineAnnealingWarmRestarts,这个 scheduler 会让 learning rate 在周期的最后瞬间上升 ,这个概念在李宏毅老师过去的视频中也有说到,即:warm restart。
CosineAnnealingWarmRestarts()
torch.optim.lr_scheduler.``CosineAnnealingWarmRestarts(optimizer, T_0, T_mult=1, eta_min=0, last_epoch=- 1, verbose=False)
optimizer (Optimizer):指定需要对哪个优化器对象进行学习率调整。T_0 (int): 表示第一次restart的epoch,即在T_0个epoch后,学习率将回到最高点,重新开始下降。默认值为10。T_mult (float): 表示每次restart之后T_0的值将乘以T_mult。默认值为1。eta_min (float): 表示学习率的最小值,在学习率下降到这个值之后,就不再下降了。默认为0。last_epoch (int): 表示上一次更新学习率的epoch索引。默认为-1,表示还没有开始训练。这个参数用于恢复训练时使用,可以将其设置为已经训练的epoch数减 1。verbose (bool):如果为True,则在调整学习率时打印更新的消息
optimizer = torch.optim.Adam(model.parameters(), lr=5e-4) # 假设初始学习率为 5e-4
scheduler = torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer, T_0=10, T_mult=1, eta_min=1e-7)for epoch in range(num_epoch):train(...) # 训练模型validate(...) # 验证模型scheduler.step() # 更新学习率
学习率变化曲线

实验结果
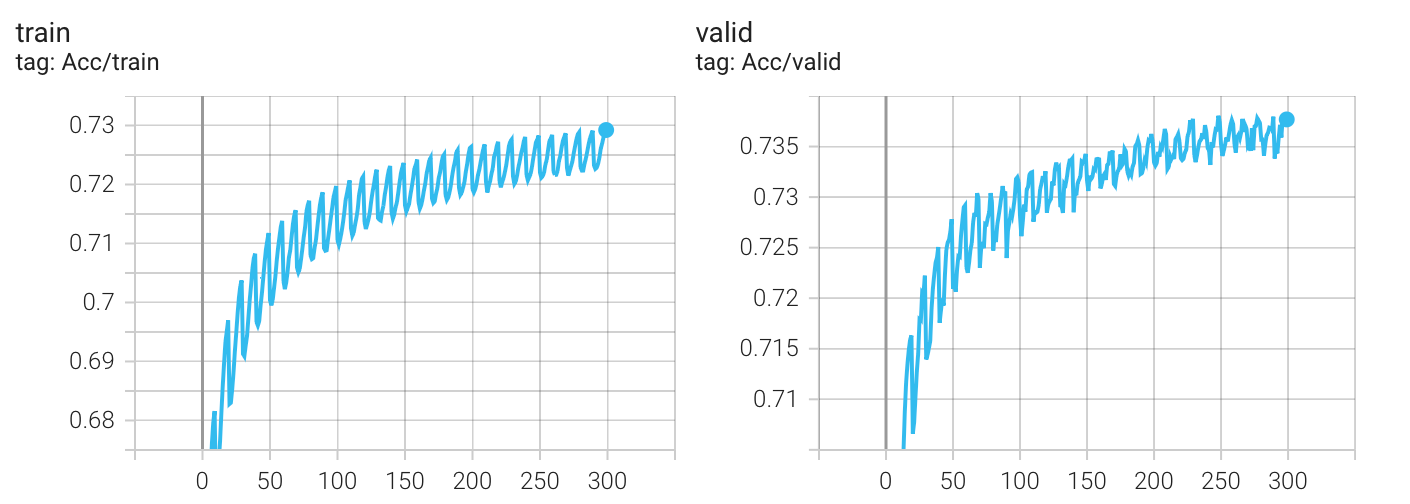
Kaggle 分数: 0.74328(没有提升)
我以为实验结果会变得更好,发现并没有,无论哪种 scheduler,最终的结果都差不多(epoch = 300),这可能是我初始lr设置的太大(5e-4)的原因?
虽然我产生了修改学习率的想法,但我还想尝试一下另一种修改方式,因为我发现 CosineAnnealLR 参数中 T_max 指代的是半个周期的长度,而 CosineAnnealingWarmRestarts 参数中的 T_0 指代的是一个周期长度,我将二者都设置成了 10,这使得 CosineAnnealingWarmRestarts 在300个epoch中有30个周期,是 CosineAnnealLR 的两倍,我或许应该将 T_0 设置为 2*T_max 来进行最终的对比实验。

T_0 *= 2
学习率变化曲线

实验结果
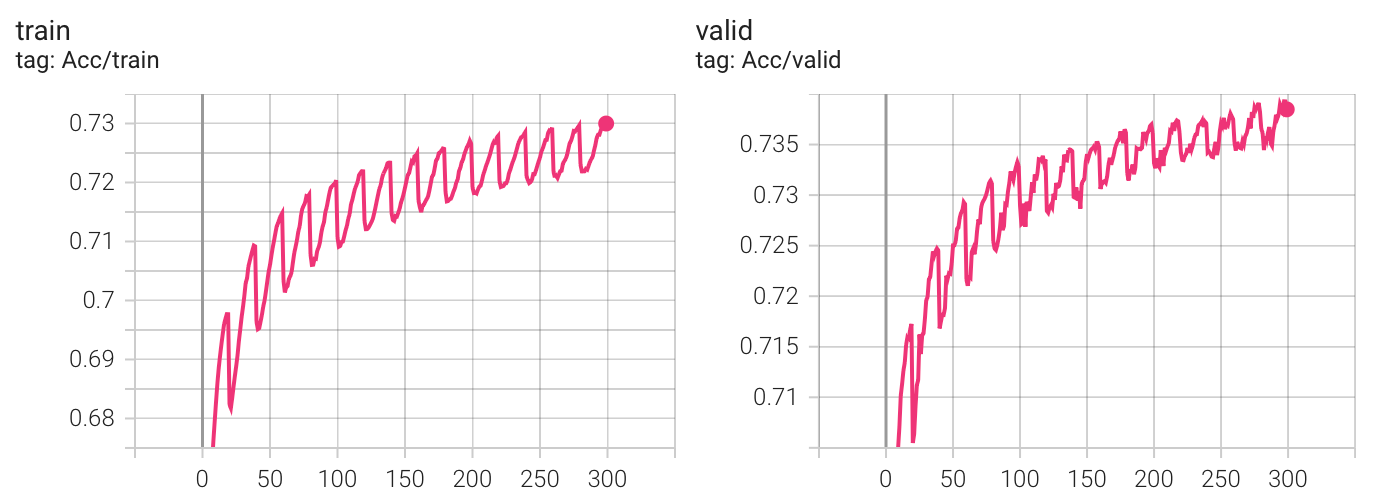
Kaggle 分数: 0.74403(没有提升)
看起来,各个 scheduler 最终的表现似乎没有区别?我决定跑一个没有scheduler的版本(是的,我一开始默认的觉得加上scheduler一定会让实验变得更好,但发现似乎并不是这样,最起码在当前的配置下不是(有可能是batchnorm的原因?))。
no scheduler
学习率变化曲线

实验结果
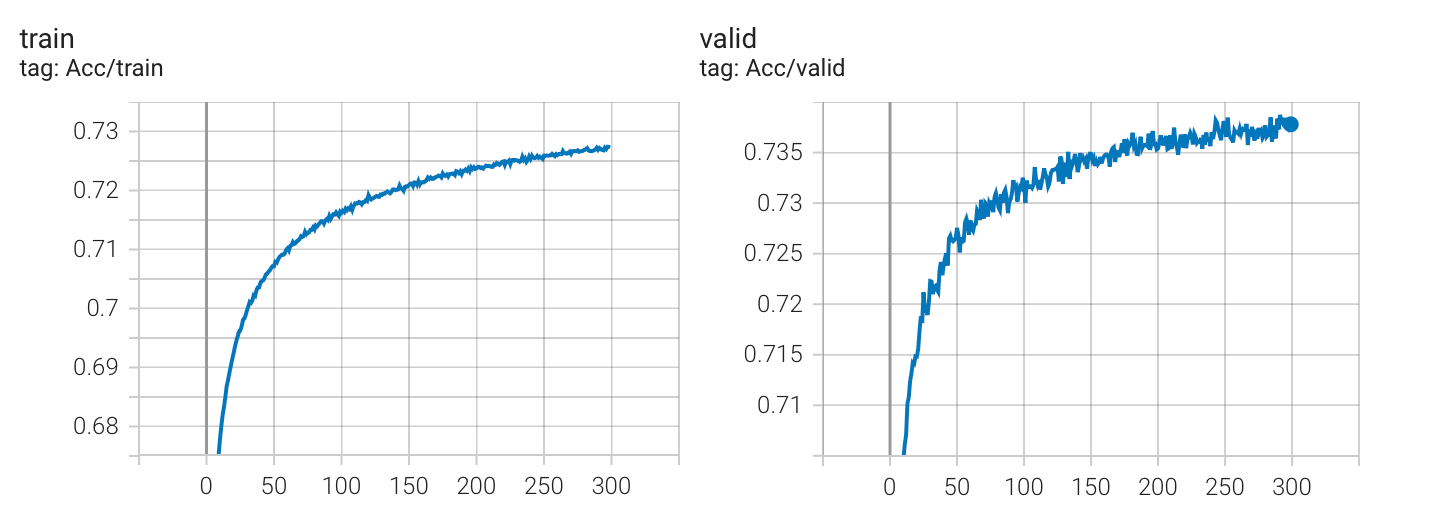
Kaggle 分数: 0.74408
实验结果对比
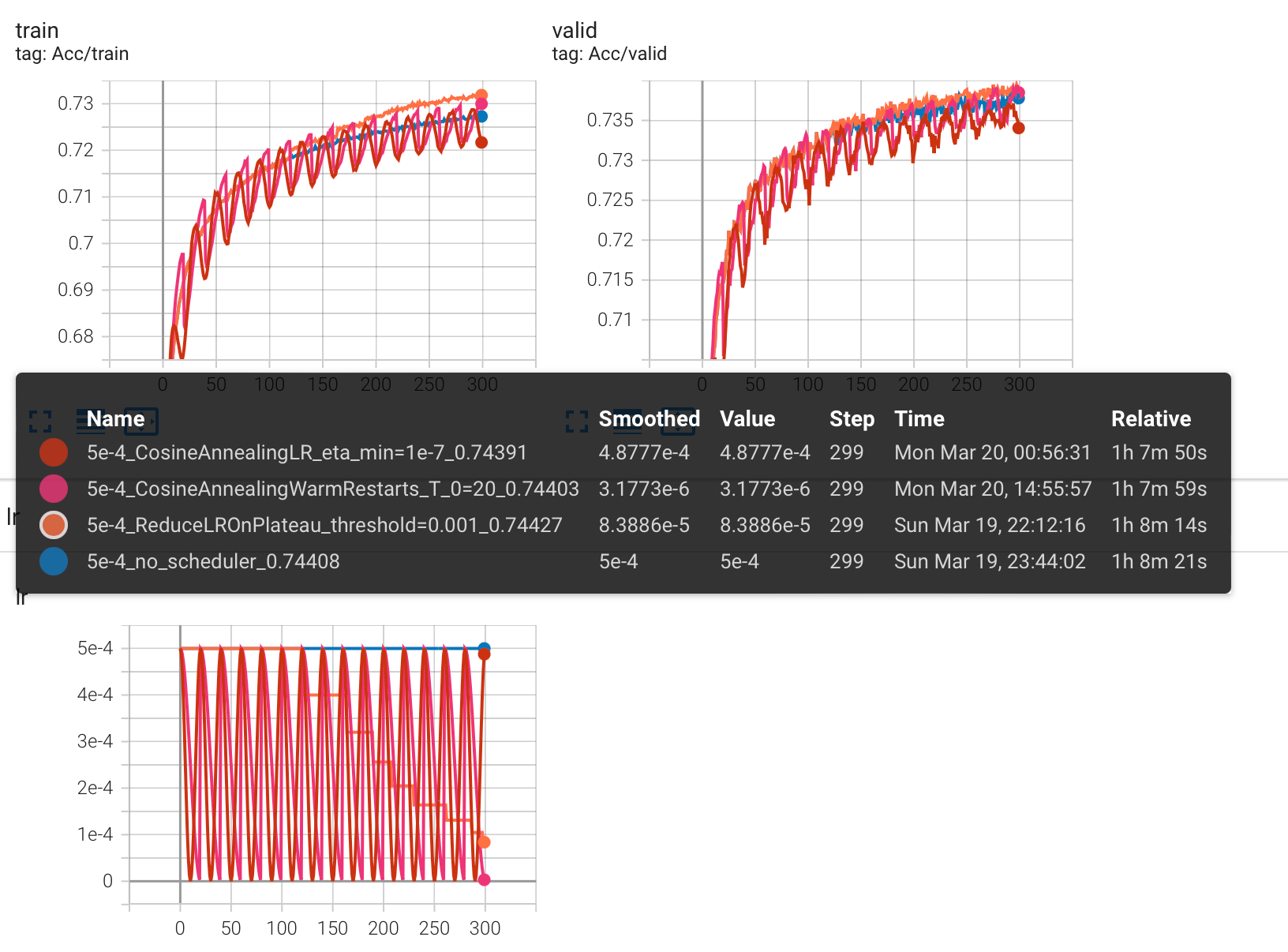
评价是:花里胡哨,没有区别(HW02 下)。真要用的话, ReduceLROnPlateau() 就够了,有时可以减少训练时间。
现在,我决定根据一个现象去改变 lr 的初始值:从输出中,观察到在所有周期中,每次 lr=2.5e-4 和 1.72e-4 的时候上升幅度最大,于是我将 lr 设置成 2.5e-4 重新跑了所有的实验。
修改 lr=2.5e-4,重新实验
实验结果对比
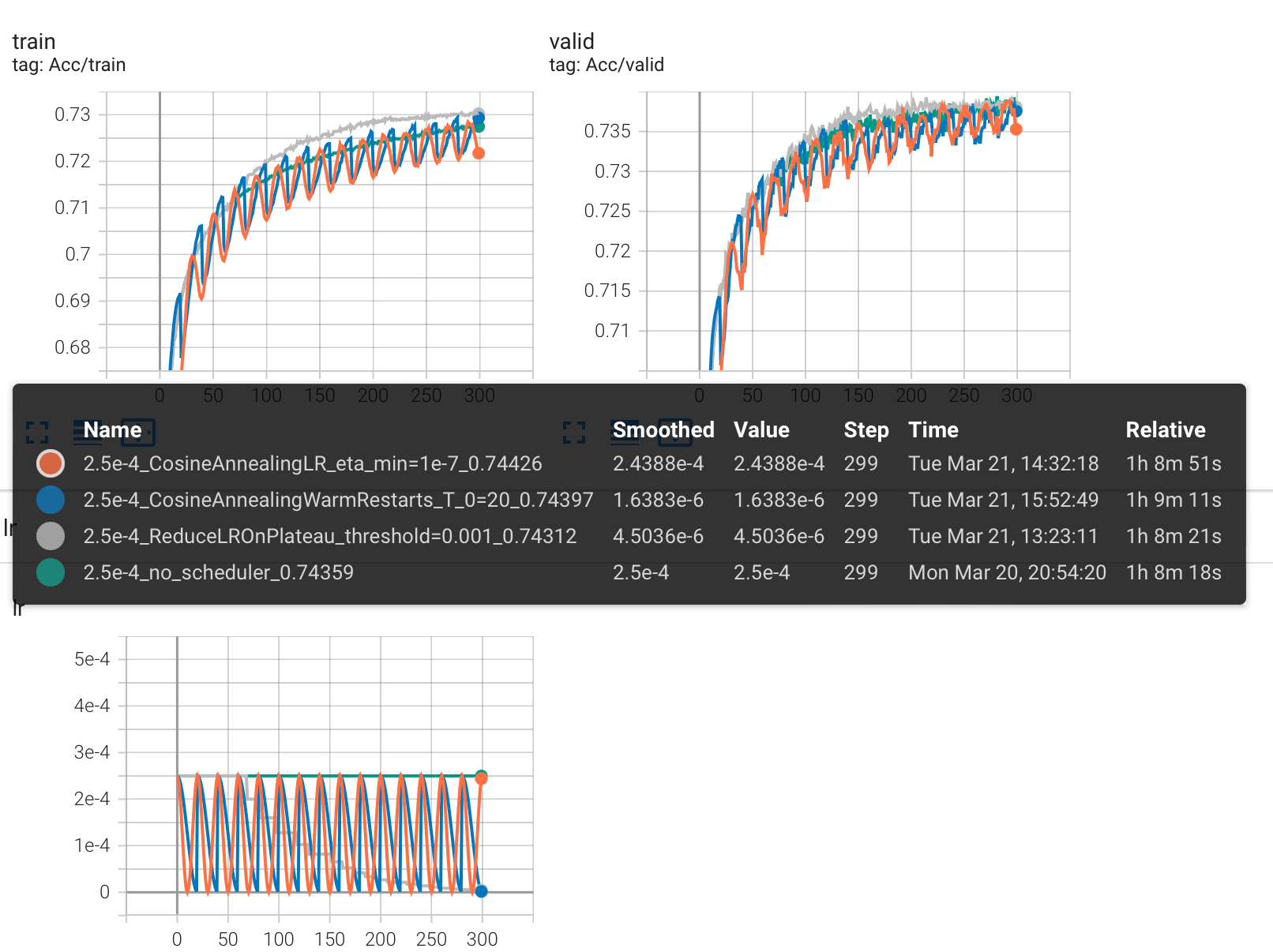
可以看到,Kaggle 分数没有提升。
下图是 lr = 5e-4 和 lr=2.5e-4 的 CosineAnnealingWarmRestarts 对比结果:
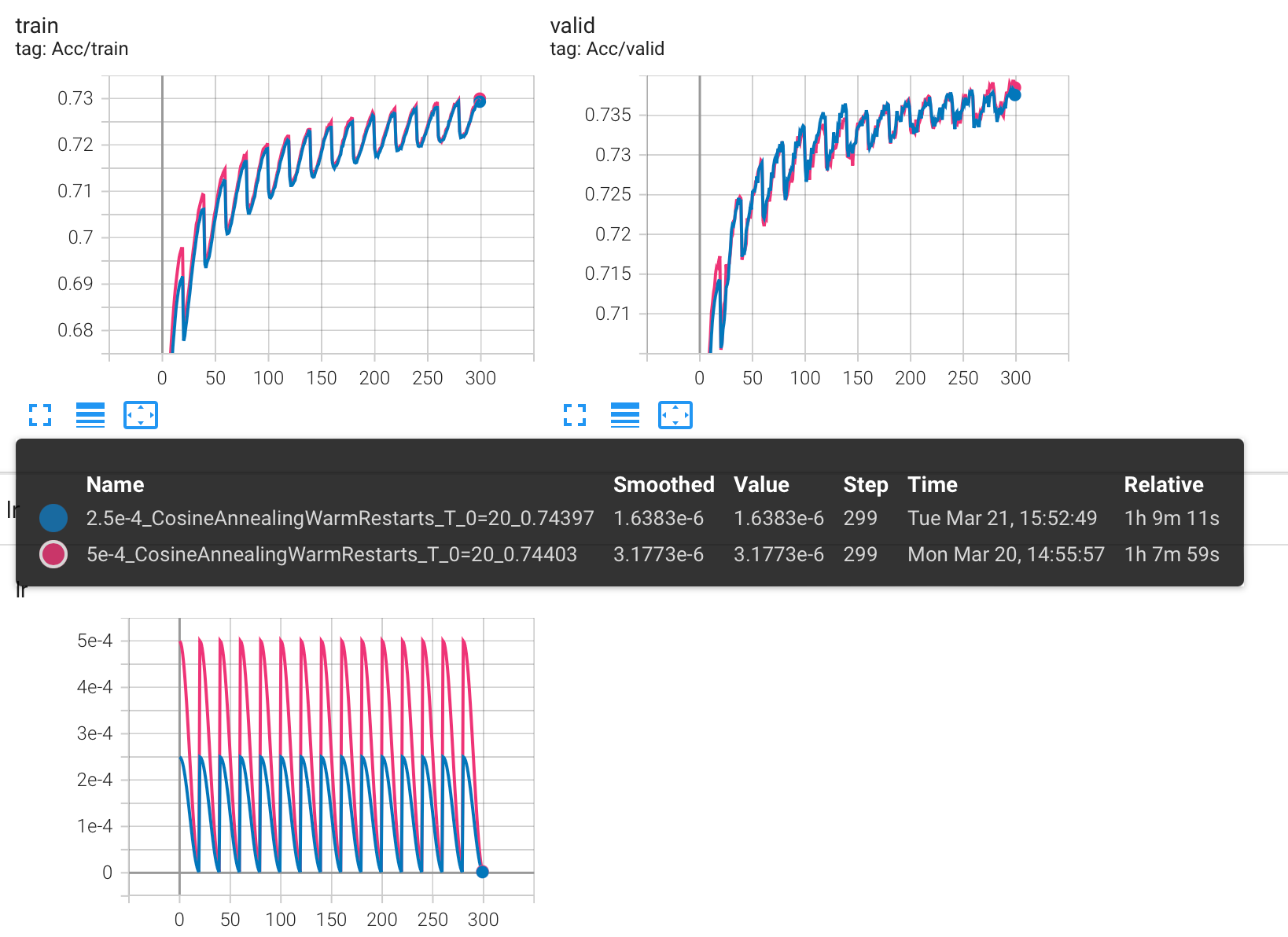
原以为会有很大的变化,比如在 lr 的最高点处 acc 不会降低这么多,发现并没有,甚至可以说是一模一样,这其中一定有什么我还不了解的东西在发挥作用。
总结
scheduler 真的没有作用吗?不尽然,这很大程度上取决于你现在的损失函数面和参数配置,使用 scheduler 往往可以更快的收敛。下图是对比:
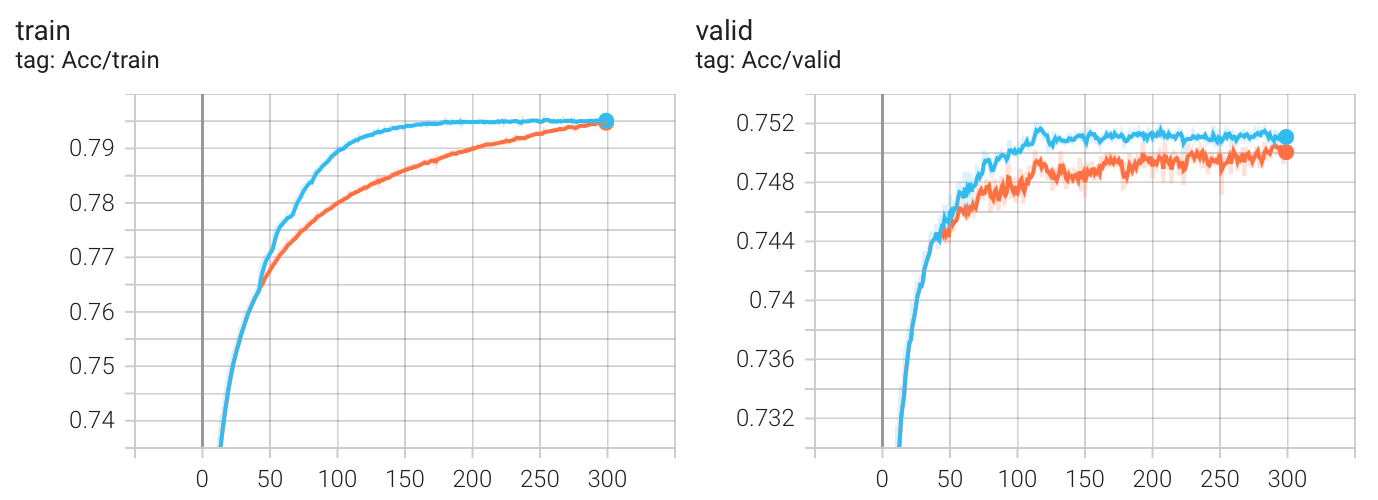
但相对于盲目的使用一些可能提高 metric 的函数,你更应该在预处理数据上下功夫:
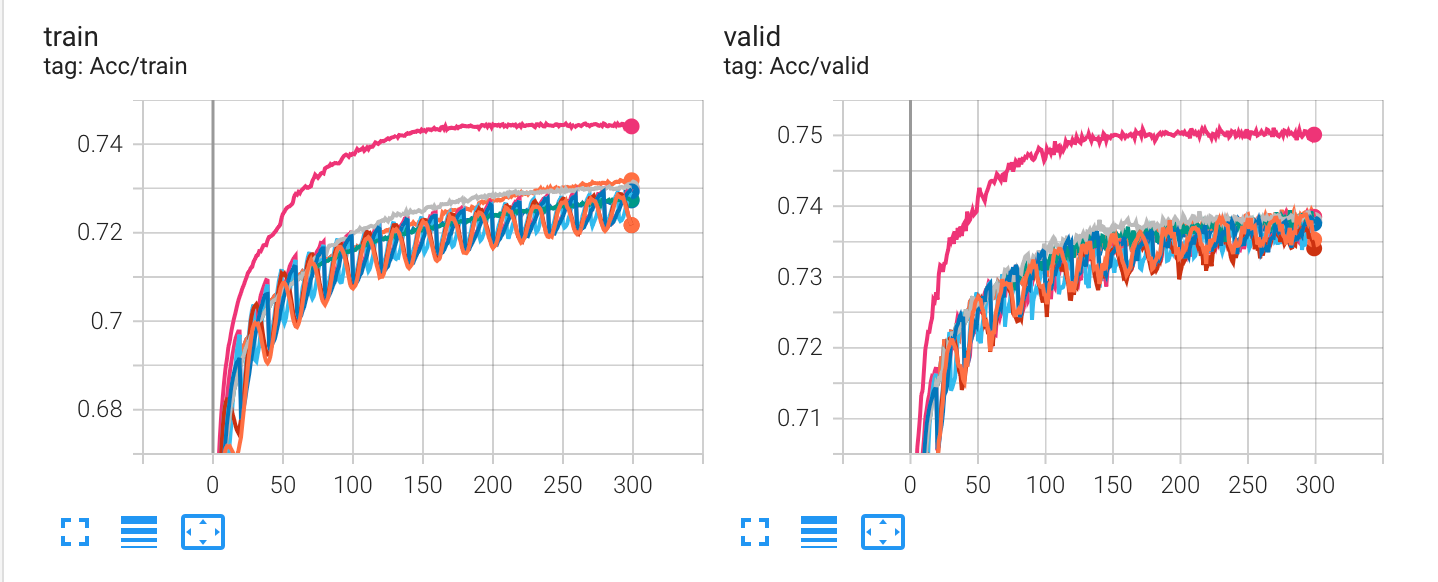
- 跑完这个对比实验后,我增加了输入的维度,让数据在一开始拥有更多的信息(对应到 HW02 就是:将 concat_nframes 从 15 增加到了 21,使得在网络可以更多的考虑到相邻的音素),仅仅改变这一条,Kaggle 的分数便超过了 strong baseline,达到了 0.75623。
- 进一步的,dropout 其实不应设置成 25,通过观察可以发现:没有 dropout 的时候,训练集很容易便能达到 90+ 的准确率,当然,这是过拟合了。但 p=25 时,acc 一直上不去又何尝不是欠拟合呢?基于这个想法,我在 p=25/15 下做了对比,下图是大致的实验结果(使用了 ReduceLROnPlateau()):
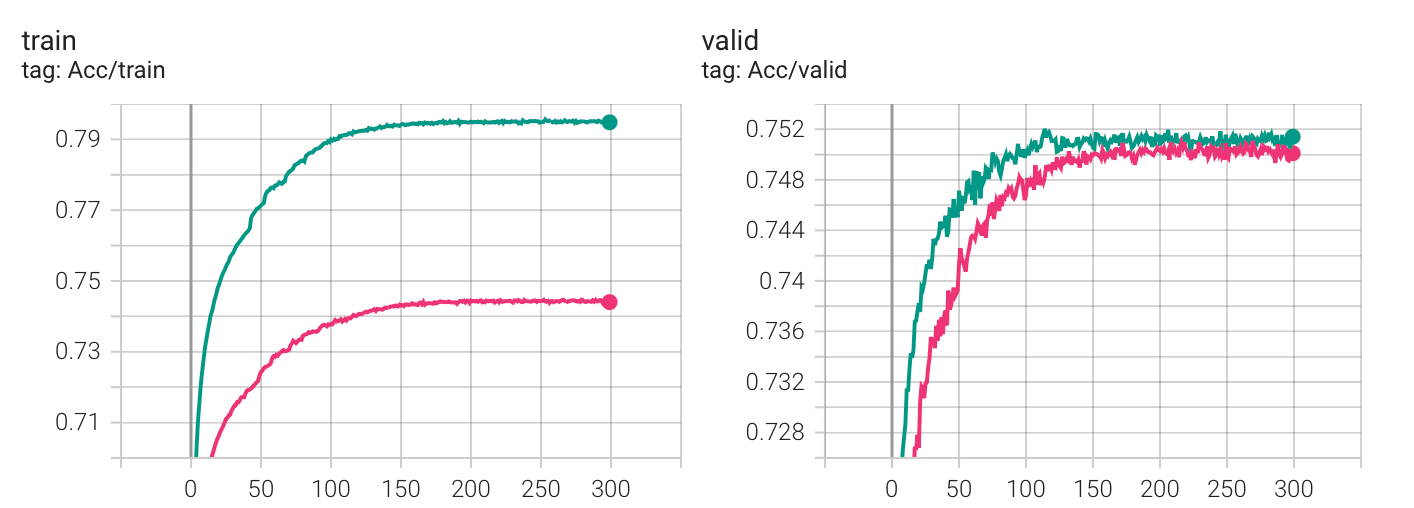
发现这使得 acc 比之前更快的抵达了 strong baseline,至于刚刚所想的欠拟合,好像没有体现出来 : )
P.S. epoch 设置成 300 完全是为了跑对比实验,做 HW 的时候不要设这么大,浪费时间。
实验局限在一个可能不好的参数配置,也局限在单独的 optimizer 之下,仅向大家展示片面的的结果 : )
以上是关于部分 scheduler 使用的实验对比和总结,希望对你有所帮助~
相关文章:
scheduler 的使用实验对比和总结(PyTorch)
这篇文章是在完成 HW02 的过程中所产生的,是关于各 scheduler (ReduceLROnPlateau(),CosineAnnealingLR(),CosineAnnealingWarmRestarts())使用的对比实验。 起因是为了在 Kaggle 上跑出更高的成绩,但结果确…...

vue2 虚拟列表(优化版)
作用: 虚拟列表是优化长列表的一种手段,防止列表存在过多的dom元素导致页面卡顿(包扣移动端下拉到底加载下一页这种列表加载的dom元素多了一样会卡)。 原理: 如上图简单地说就是以 <div classlist-view">作…...

从应用层到MCU,看Windows处理键盘输入 [1.在应用层调试Notepad.exe (按键消费者)]
文本编辑器/文本编辑框是应用层常见的键盘处理程序。微软泄露的WinXP源码下有文本编辑器Notepad的实现:Microsoft_leaked_source_code\nt5src\Source\XPSP1\NT\shell\osshell\accesory\notepad文本编辑器的实现并不复杂,微软又(被迫)提供了Sample&#x…...

什么是大数据?大数据能做什么
大数据发现现在如火如荼,也吸引了很多有志人士想要加入这个行业,但是在正式入行之前了解大数据是什么以及能做什么是非常重要的~ 下面我们一起来看一下~ 比较官方的定义是指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合ÿ…...
)
Git 和 GitHub 超入门指南(四)
Git基本命令 以下是一些基本的Git命令: git add:将文件添加到Git索引中git commit:将索引中的文件提交到Git仓库中git status:查看工作目录和索引的状态git log:查看提交历史记录 Git高级命令 以下是一些高级的Git…...

Java 响应式编程 Reactor 框架
文章目录 Java 响应式编程 Reactor 框架FluxMono其它的关键对象Java 响应式编程 Reactor 框架 Reactor框架的核心理念是基于响应式编程的异步流处理。这意味着应用程序可以通过异步事件流来处理请求,而不是通过传统的同步请求-响应模型。在响应式编程中, 应用程序可以处理多个…...
Hazel引擎学习(十一)
我自己维护引擎的github地址在这里,里面加了不少注释,有需要的可以看看 参考视频链接在这里 很高兴的是,引擎的开发终于慢慢开始往深了走了,前几章的引擎UI搭建着实是有点折磨人,根据课程,接下来的引擎开发…...
:如何判断训练过程中深度学习模型损失值不再下降)
深度学习(22):如何判断训练过程中深度学习模型损失值不再下降
2023年3月22日,与 chatGPT 的沟通如何判断训练过程中深度学习模型损失值不再下降在深度学习中,判断模型是否收敛是非常重要的,这可以通过监控模型损失值来实现。一般来说,当训练模型的损失值不再下降,我们就可以认为模…...
一个比较全面的C#公共帮助类
上次跟大家推荐过2个C#开发工具箱:《推荐一个不到2MB的C#开发工具箱,集成了上千个常用操作类》、《推荐一个.Net常用代码集合,助你高效完成业务》。 今天再给大家推荐一个,这几个部分代码功能有重合的部分,大家可以根…...

人脸识别经典网络-MTCNN(含Python源码实现)
人脸检测-mtcnn 本文参加新星计划人工智能赛道:https://bbs.csdn.net/topics/613989052 文章目录人脸检测-mtcnn1. 人脸检测1.1 人脸检测概述1.2 人脸检测的难点1.3 人脸检测的应用场景2. mtcnn2.1 mtcnn概述2.2 mtcnn的网络结构2.3 图像金字塔2.4 P-Net2.5 R-Net2…...

OpenCV入门(十八)快速学会OpenCV 17 直线检测
OpenCV入门(十八)快速学会OpenCV 17 直线检测1.霍夫直线变换概述2.霍夫变换原理3.操作实例3.1 HoughLines函数3.2 HoughLinesP函数作者:Xiou 1.霍夫直线变换概述 霍夫变换是一种在图像中寻找直线、圆形以及其他简单形状的方法。霍夫变换采用…...
nginx快速入门.跟学B站nginx一小时精讲课程笔记
nginx快速入门.跟学B站nginx一小时精讲课程笔记nginx简介及环境准备nginx简介环境准备一、nginx 安装1.使用yum安装2.常用命令3.使用systemctl启动、停止、重新加载4.配置文件5.配置文件结构二、配置静态web1.静态网页配置2.listen监听3.server_name4.location三、HTTP反向代理…...
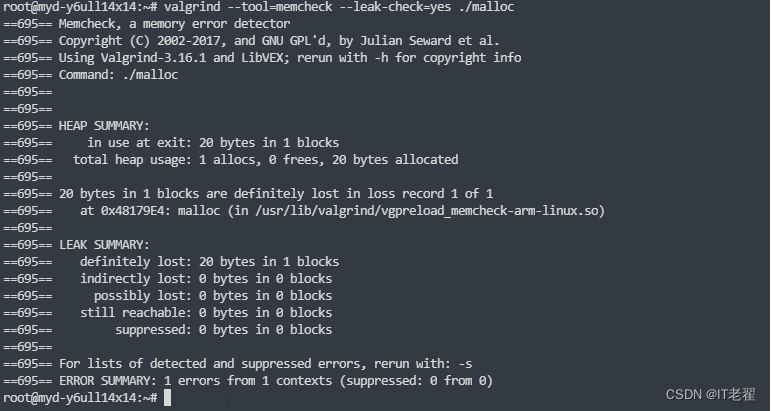
内存泄漏定位工具之 valgrind
内存泄漏检测工具 文章目录内存泄漏检测工具一、valgrind介绍1. memcheck2. cachegrind3. helgrind二、源码下载三、命令操作1.memcheck 工具四、虚拟机下使用1. x86编译2. 正常程序测试3. 申请内存不释放测试4. 内存越界的测试5. 读写已经释放的内存五、ARM平台使用1.交叉编译…...
Django(一)安装
好久没更新了 学习的内容太多了有点杂 一时不知道从何说起 !!! 对于Django我也不是很了解 在网上搜了个词条就是以下显示 我目前的了解也仅限于此 希望在接下来的学习过程中 有更多的学习体会可以和大家分享 一涉及到在对应python环境 下载东西时思维就会很混乱 这里再把之前…...
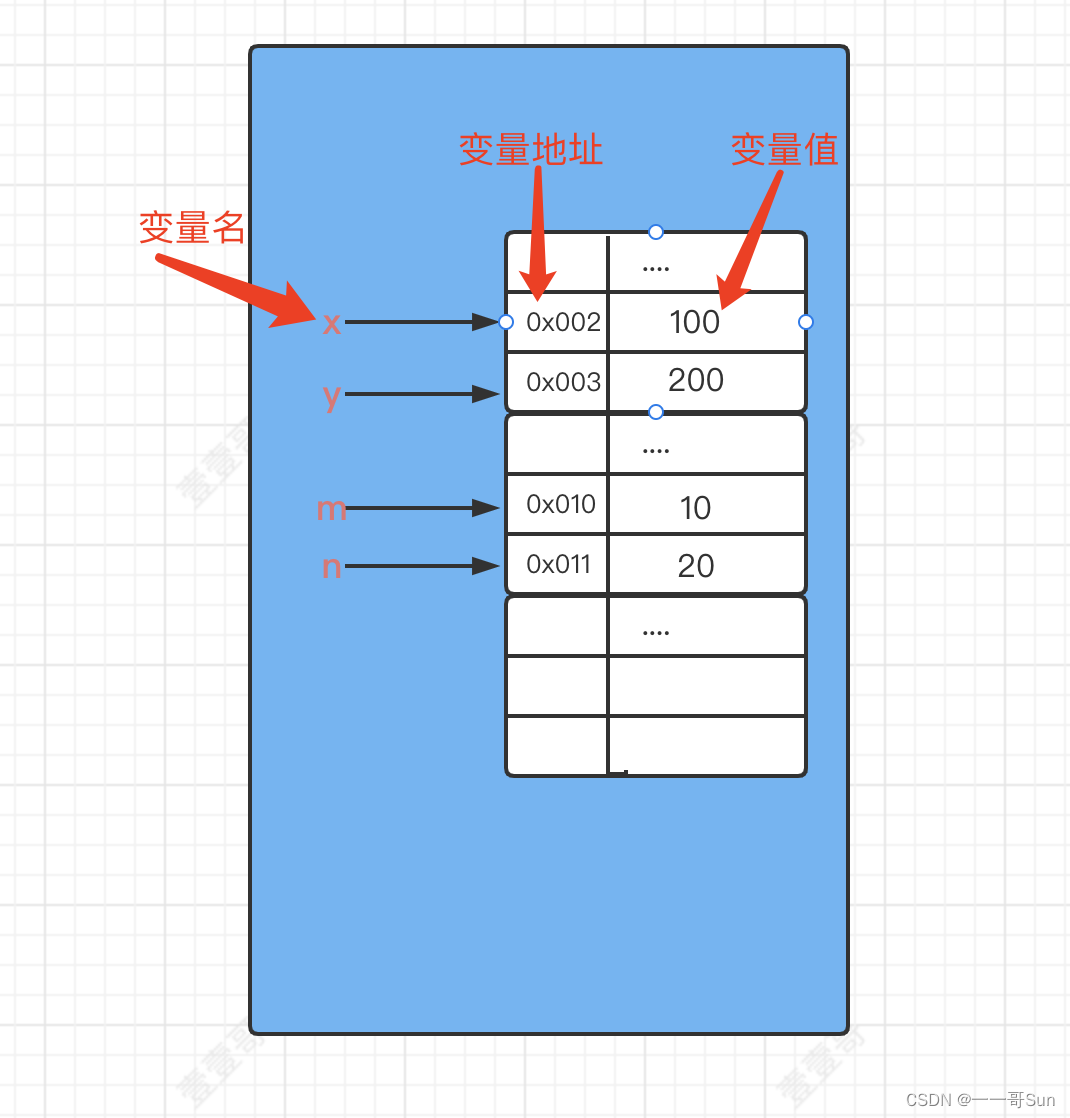
11从零开始学Java之如何正确地定义变量?
作者:孙玉昌,昵称【一一哥】,另外【壹壹哥】也是我哦CSDN博客专家、万粉博主、阿里云专家博主、掘金优质作者前言在之前的文章中,壹哥给大家讲解了Java的第一个案例HelloWorld,并详细给大家介绍了Java的标识符…...
51单片机之喝水提醒器
定时器定时器介绍晶振晶体震荡器,又称数字电路的“心脏”,是各种电子产品里面必不可少的频率元器件。数字电路的所有工作都离不开时钟,晶振的好坏、晶振电路设计的好坏,会影响到整个系统的稳定性。时钟周期时钟周期也称为振荡周期…...
扒一扒抖音是如何做线程优化的
背景 最近在对一些大厂App进行研究学习,在对某音App进行研究时,发现其在线程方面做了一些优化工作,并且其解决的问题也是之前我在做线上卡顿优化时遇到的,因此对其具体实现方案做了深入分析。本文是对其相关源码的研究加上个人理…...

149.网络安全渗透测试—[Cobalt Strike系列]—[重定器/代理服务器/流量走向分析]
我认为,无论是学习安全还是从事安全的人多多少少都会有些许的情怀和使命感!!! 文章目录一、Cobalt Strike 重定器1、Cobalt Strike 重定器简介2、重定器用到的端口转发工具二、cobalt strike重定器实验1、实验背景2、实验过程3、流…...

Qt调用Chrome浏览器
一、前言 最近有个小项目需要跳转网页,之前有了解过,但是没有在项目中使用过Qt网页嵌入; 结合自己之前的博客,有如下两种技术可以实现我的需求: 1、Qt–网页嵌入 2、Qt使用QAxWidget调用Windows组件 但是在实际开…...
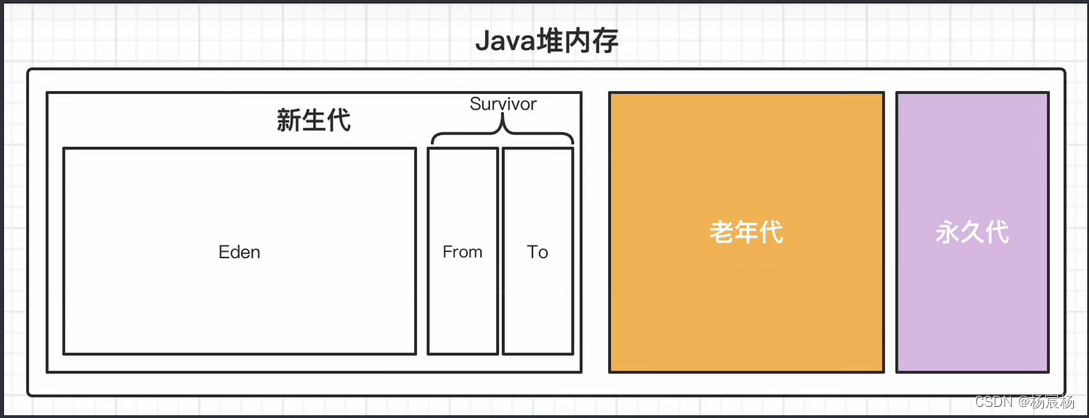
JVM虚拟机垃圾回收机制
JVM虚拟机垃圾回收机制垃圾回收机制判断是否存活算法引用计数法可达性分析法最终判定垃圾回收算法分代收集机制空间分配担保垃圾回收机制 判断是否存活算法 java语言和我们之前学的c/c不同,c/c可以手动进行内存释放,那样随时随地就可以释放不必要的内存…...

从报文周期到安全状态:ISO26262通信故障诊断的5个关键时间参数详解
从报文周期到安全状态:ISO26262通信故障诊断的5个关键时间参数详解 在智能驾驶系统快速发展的今天,确保车辆电子系统的功能安全已成为行业共识。ISO26262作为汽车功能安全的黄金标准,其核心在于建立一套完整的故障诊断与处理机制。本文将深入…...

Flux Sea Studio 与Node.js全栈项目集成:打造在线海景艺术画廊
Flux Sea Studio 与Node.js全栈项目集成:打造在线海景艺术画廊 最近在做一个挺有意思的业余项目,想给喜欢海洋艺术的朋友们弄个在线画廊。这个画廊的特别之处在于,它不只是展示静态图片,而是能让用户自己动手,用文字描…...

浏览器插件开发:OpenClaw+GLM-4.7-Flash增强网页交互
浏览器插件开发:OpenClawGLM-4.7-Flash增强网页交互 1. 为什么需要智能化的浏览器插件? 在日常网页浏览中,我们经常会遇到这样的场景:看到一篇长文想快速提取核心观点,或者需要将网页内容与本地文件进行联动处理。传…...
)
PX4串口通讯避坑指南:从波特率设置到数据收发全流程解析(以Serial4/5为例)
PX4串口通讯实战指南:从硬件配置到数据交互的深度解析 在无人机和机器人开发领域,PX4作为一款开源的飞控系统,其串口通讯功能是实现传感器数据采集、地面站通信以及外设控制的核心技术。然而,许多开发者在实际项目中常会遇到数据丢…...
)
ArcGIS10.2许可服务启动失败?别急着重装,试试这个命令行修复大法(附端口冲突排查)
ArcGIS 10.2许可服务启动失败的终极排查指南:从命令行到端口冲突解决 当你面对灰色的启动按钮和毫无反应的ArcGIS License Administrator界面时,那种挫败感我深有体会。作为地理信息行业的从业者,我们常常依赖ArcGIS完成关键工作,…...

异构数据库迁移利器:dbswitch实现多源数据高效同步
1. 异构数据库迁移的痛点与常见方案 第一次接触异构数据库迁移时,我被各种工具搞得晕头转向。当时公司需要把Oracle的业务数据同步到Greenplum做分析,试了好几种方案都不太理想。比如用kettle配置gpload,光是理解那些参数就花了两天时间&…...

别再手动改配置了!用Docker Compose一键部署带Web管理界面的Pulsar独立集群
告别手动配置:Docker Compose全自动部署Pulsar集群与Web管理平台 每次搭建开发环境都要重复输入十几条Docker命令?配置文件散落在各个角落难以维护?今天我要分享的这套方案,将彻底改变你部署消息队列的方式。只需一个YAML文件&…...

Jellyfin MetaTube插件:5分钟打造专业级媒体库的终极指南
Jellyfin MetaTube插件:5分钟打造专业级媒体库的终极指南 【免费下载链接】jellyfin-plugin-metatube MetaTube Plugin for Jellyfin/Emby 项目地址: https://gitcode.com/gh_mirrors/je/jellyfin-plugin-metatube MetaTube是一款专为Jellyfin和Emby设计的免…...
的全面排查指南)
2003 - MySQL连接localhost失败(10061错误)的全面排查指南
1. 为什么会出现MySQL连接localhost失败(10061错误)? 当你兴致勃勃地打开数据库客户端准备大干一场时,突然蹦出个"2003 - Cant connect to MySQL server on localhost(10061)"的错误提示,是不是瞬间就懵了&a…...

Youtu-VL-4B-Instruct基础教程:system message规范写法避免API响应异常
Youtu-VL-4B-Instruct基础教程:system message规范写法避免API响应异常 你是不是在用Youtu-VL-4B-Instruct的API时,偶尔会遇到一些奇怪的响应?比如模型突然不按套路出牌,或者干脆给你返回一些看不懂的内容? 别担心&a…...