Leaf分布式ID
文章目录
- 系统对Id号的要求
- UUID
- snowflake
- Leaf
- Leaf-snowflake
- Leaf-segment
- MySQL自增主键
- segment
- 双buffer
系统对Id号的要求
1、业务
1)全局唯一性:不能出现重复的ID号,既然是唯一标识,这是最基本的要求
2)趋势递增:在MySQL InnoDB引擎中使用的是聚集索引,由于多数RDBMS使用B-tree的数据结构来存储索引数据,在主键的选择上面我们应该尽量使用有序的主键保证写入性能
3)单调递增:保证下一个ID一定大于上一个ID,例如事务版本号、IM增量消息、排序等特殊需求
- 数据自增id
4)信息安全:如果ID是连续的, 竞对在两天中午12点分别下单,通过订单id号相减就能大致计算出公司一天的订单量 。所以在一些应用场景下,会需要ID无规则
- UUID或雪花算法
2、可靠性
- 平均延迟和TP999延迟都要尽可能低
- 可用性5个9
- 高QPS
UUID
1、定义
36个字符,示例:550e8400-e29b-41d4-a716-446655440000
public class IdUtil {/** 返回使用ThreadLocalRandom的UUID,比默认的UUID性能更优*/public static UUID fastUUID() {ThreadLocalRandom random = ThreadLocalRandom.current();return new UUID(random.nextLong(), random.nextLong());}
}
2、缺点
- 太长,不易于存储
- 无序性,如果作为数据库主键,可能会引起数据页位置频繁变动,严重影响性能
- 信息不安全,基于MAC地址生成UUID的算法可能会造成MAC地址泄露
snowflake
1、结构
Long型64位的整数,如图1所示

-
41-bit的时间戳
可以表示(1L<<41)/(1000L360024*365)=69年的时间
-
10-bit 数据中心ID和机器
5bit数据中心id,5bit机器id,一般使用ZK分配
-
12个自增序列号
在同一毫秒内生成2^12个唯一的ID
理论上snowflake方案的QPS约为409.6w/s,可以保证在任何一个IDC、任何一台机器、在任意毫秒内、生成的ID都是不同的
2、问题
41-bit时间戳部分,强依赖机器时钟,如果机器上时钟回拨,会导致发号重复
Leaf
Leaf-snowflake
1、适合场景:生成的ID需要无规则
2、解决机器时钟回拨问题
1)要求当前时间戳,必须 > 机器创建时间
2)同时
- 对比其余Leaf节点的系统时间,来判断自身系统时间是否准确
- RPC请求得到所有节点的系统时间,计算sum(time)/nodeSize < 阈值,则认为正确
阈值 = 5ms
因为理论上5ms内无法,完全使用完成后12个自增序列号,所以不会重复
否则直接报错自动摘除本身节点并报警
Leaf-segment
1、适合场景:生成的ID单调递增
2、实现:基于MySQL的自增主键
MySQL自增主键
1、获取ID方式
使用下列SQL读写MySQL得到ID号
begin;
REPLACE INTO Tickets64 (stub) VALUES ('a');
SELECT LAST_INSERT_ID();
commit;
- Tickets64:表
- stub:列
实现方式类似:
useGeneratedKeys=“true“ keyProperty=“id“
- int insert(XxxDO xxxDo)时,先将DO内容写入db
- insert成功后,再将JDBC自增主键值AUTO_INCREMENT,回写到DO的id属性字段
- 后续可能会从DO中获取此id值进行查询数据、编辑数据
2、存在问题
因为每次都是都需要写,读MySQL才能获取ID值,单台MySQL的读写性能是瓶颈
3、解决-集群
-
在分布式系统中多部署几台机器
-
每台机器设置不同的初始值,且步长和机器数相等
比如有两台机器。设置步长step为2,TicketServer1的初始值为1(1,3,5,7,9,11…)
TicketServer2的初始值为2(2,4,6,8,10…)
-
假设部署N台机器,步长需设置为N,每台的初始值依次为0,1,2…N-1 ,则整个Leaf架构如图2

4、存在问题
- 数据库压力还是很大,每次获取ID都得读写一次数据库,只能靠堆机器来提高性能
- 系统水平扩展比较困难,定义好了步长和机器台数之后,如果要添加机器不好做
5、解决- 批量分段(segment)获取
segment
1、实现,如图3所示
1)db表设计
+-------------+--------------+------+-----+-------------------+-------------------------
| Field | Type | Null | Key | Default | Extra
+-------------+--------------+------+-----+-------------------+--------------------------
| biz_tag | varchar(128) | NO | PRI | |
| max_id | bigint(20) | NO | | 1 |
| step | int(11) | NO | | NULL |
| desc | varchar(256) | YES | | NULL |
| update_time | timestamp | NO | | CURRENT_TIMESTAMP | on update
- biz_tag用来区分业务(外卖、支付)
- max_id表示该biz_tag目前所被分配的ID号段的最大值
UPDATE table SET max_id=max_id+step WHERE biz_tag=xxx
- step表示每次分配的号段长度
2)系统架构

3) ID值趋势递增
eg:test_tag业务
- Leaf Server 1:从DB加载号段[1,1000]。
- Leaf Server 2:从DB加载号段[1001,2000]。
- Leaf Server 3:从DB加载号段[2001,3000]。
用户通过Round-robin的方式调用Leaf Server的各个服务,通过CAS获取ID,所以某一个Client获取到的ID序列
可能是:1,1001,2001,2,1002,2002……
也可能是:1,2,1001,2001,2002,2003,3,4…
当某个Leaf Server号段用完之后,下一次请求就会从DB中加载新的号段,这样保证了每次加载的号段是递增
2、解决-读写性能
-
原来获取一个ID值,都需要读写一次数据库
-
现在只需要把step设置得足够大,比如1000。那么只有当1000个号被消耗完了之后才会去重新读写一次
读写数据库的频率从1减小到了1/step
-
test_tag业务,在第一台Leaf机器上是1~1000的号段,当这个号段用完时
-
会去加载另一个长度为step=1000的号段
-
假设另外两台号段都没有更新,这个时候第一台机器新加载的号段就应该是3001~4000
-
同时数据库对应的biz_tag = test_tag 这条数据的max_id会从3000被更新成4000
3、 解决-扩容操作
只需要对biz_tag分库分表
4、问题
-
在号段消耗完的时候进行取号段时,还是会夯在更新数据库的I/O上
-
假如取DB的时候网络发生抖动,或者DB发生慢查询就会导致整个系统的响应时间变慢
5、解决-双buffer
双buffer
1、解决-双buffer
- 当其中一个Buffer中的号段消费到某个点(90%)时,就启异步线程的把下一个号段加载到内存中的另一个Buffer
2、 容灾
分库分表
3、异常兜底
使用redis原子自增等手段参考:生成单据号异常兜底
相关文章:
Leaf分布式ID
文章目录 系统对Id号的要求UUIDsnowflakeLeafLeaf-snowflakeLeaf-segmentMySQL自增主键segment双buffer 系统对Id号的要求 1、业务 1)全局唯一性:不能出现重复的ID号,既然是唯一标识,这是最基本的要求 2)趋势递增&a…...

Starrocks解析json数组
json数据 [{"spec": "70g/支","unit": "支","skuId": "1707823848651276346","amount": 6,"weight": 70,"spuName": "伊利 甄稀 苦咖啡味雪糕 流心冰淇淋 70g/支",&quo…...
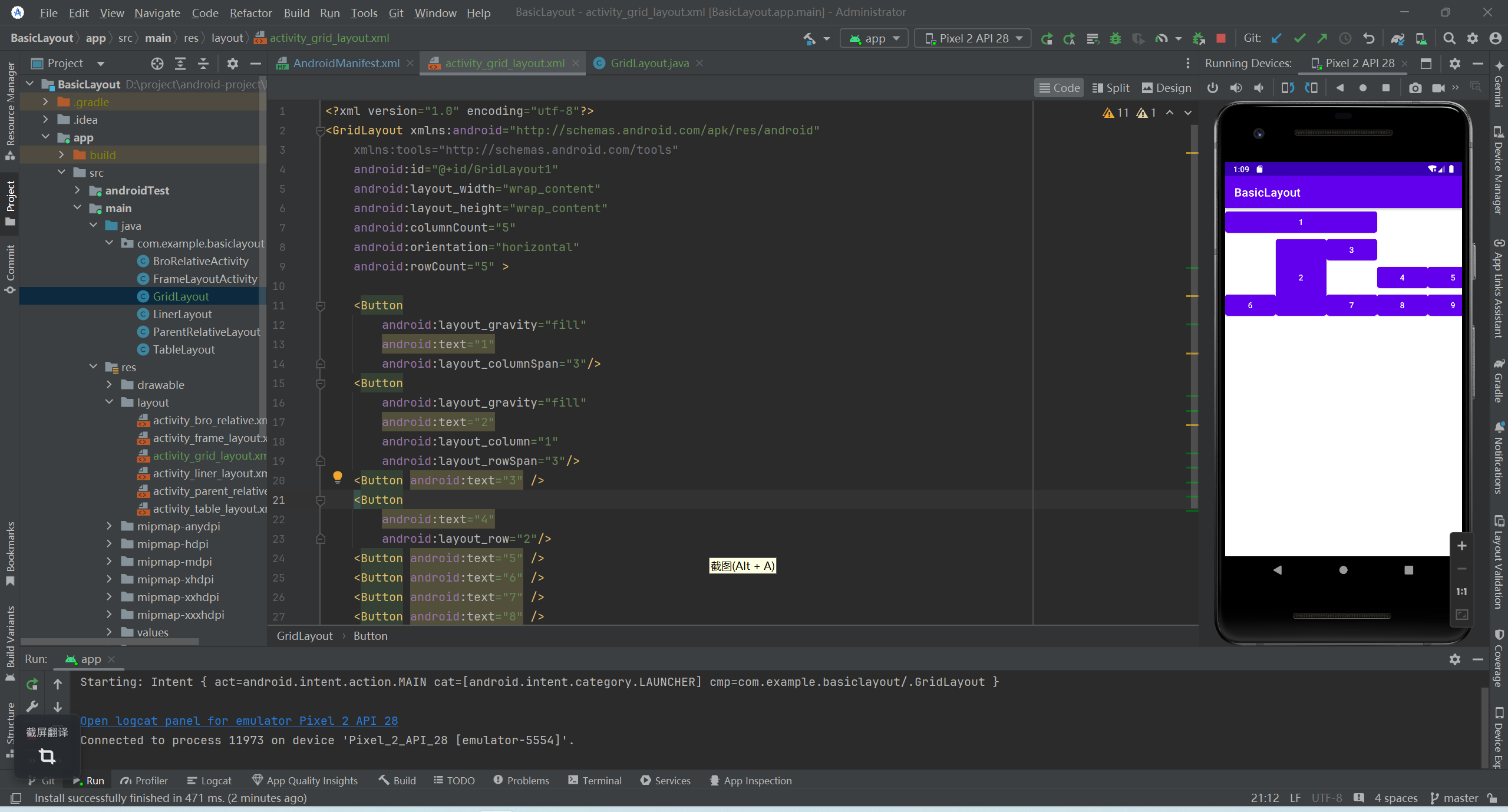
安卓基本布局(下)
TableLayout 常用属性描述collapseColumns设置需要被隐藏的列的列号。shrinkColumns设置允许被伸缩的列的列号。stretchColumns设置允许被拉伸的列的列号。 <TableLayout xmlns:android"http://schemas.android.com/apk/res/android"android:id"id/TableL…...

Python中使用正则表达式
摘要: 正则表达式,又称为规则表达式,它不是某种编程语言所特有的,而是计算机科学的一个概念,通常被用来检索和替换某些规则的文本。 一.正则表达式的语法 ①行定位符 行定位符就是用来描述字符串的边界。"^&qu…...

三大口诀不一样的代码,小小的制表符和换行符玩的溜呀
# 小案例,打印输出加法口诀 for i in range(1,10):for j in range(1,10):if j>i:breakprint(f"{j}{i}{ji}".strip(),end\t)print() print(\n) for i in range(1,10):for j in range(1,10):if j>i:breakprint(f"{j}x{i}{j*i}",end\t)print…...

[qt] 线程等待与唤醒
对于生产者与消费者的数据处理的另一种好的解决方法是使用QWaitCondition类,允许线程在一定的条件下唤醒其他多个线程来共同处理。 一 定义公共变量 DataSize: 生产者生产数据的大小BufferSize: 也就是这个缓冲区的大小,每个单元是一个int,也有可能是一个链表,结构…...

Springboot 实现 Modbus Rtu 协议接入物联网设备
Modbus RTU 技术教程 引言 Modbus是一种开放标准的通信协议,它最初由Modicon(现施耐德电气)在1979年发布,旨在让可编程逻辑控制器(PLC)之间能够进行通信。随着时间的发展,Modbus已经成为工业自动化领域中最常用的通信协议之一,尤其适用于连接工业电子设备。本文将详细…...

鸿蒙笔记--装饰器
这一节主要了解一下鸿蒙里的装饰器,装饰器是一种特殊的语法结构,用于装饰类、结构体、方法以及变量; 1 Component在鸿蒙(HarmonyOS)开发中扮演着重要角色,主要用于定义可重用的UI组件,主要作用:1)组件化:Component装饰…...
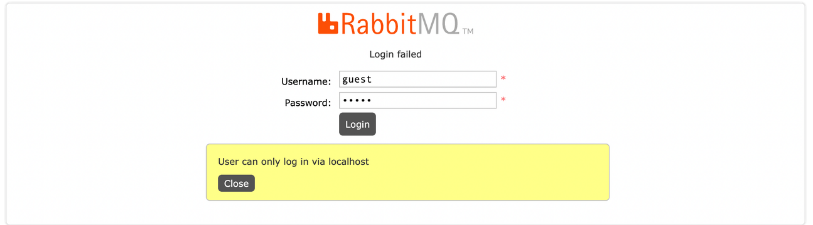
不同环境下RabbitMQ的安装-3 操作RabbitMQ
前面两篇从不同环境下RabbitMQ的安装-1 为什么要使用消息服务 到同环境下RabbitMQ的安装-2 ARM架构、X86架构、Window系统环境下安装RabbitMQ介绍了关于如何在ARM架构、X86架构和Window系统下如何安装,各位小伙伴可以根据自己的实际开发场景参考安装。 到本篇是一些…...

postgregSQL配置vector插件
1.下载vector 下载vector:https://pgxn.org/dist/vector/0.5.1/ 放在:C:\Program Files\PostgreSQL\vector-0.5.1 2.安装Visual Studio 2022 下载:https://visualstudio.microsoft.com/zh-hans/downloads/ 安装Visual Studio是为了C编译环…...
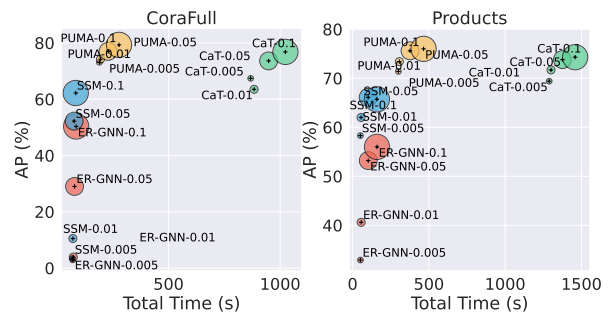
PUMA论文阅读
PUMA: Efficient Continual Graph Learning with Graph Condensation PUMA:通过图压缩进行高效的连续图学习 ABSTRACT 在处理流图时,现有的图表示学习模型会遇到灾难性的遗忘问题,当使用新传入的图进行学习时,先前学习的这些模…...
)
算法学习day31(动态规划)
一、比特位计数 给你一个整数 n ,对于 0 < i < n 中的每个 i ,计算其二进制表示中 1 的个数 ,返回一个长度为 n 1 的数组 ans 作为答案。 输入:n 2 输出:[0,1,1] 解释:0 --> 0 1 --> 1 2 -…...

嵌入式学Day25---Linux软件编程---线程间通信
目录 编辑 一、线程的分离属性 1.1.什么是分离属性 1.2.分离属性相关函数接口 1.初始化线程属性-pthread_attr_init() 2.销毁线程属性-pthread_attr_destory() 3.设置线程属性-pthread_setdetachstate() 1.3.注意 二、互斥锁 2.1.资源 2.2.互斥锁 1.什么是互斥锁 2.互…...

【实现100个unity特效之17】在unity中使用shader和ShaderGraph分别实现模糊特定层,高斯模糊效果
最终效果 Unity通过Shader来模糊场景画面 参考:【游戏开发小技】Unity通过UI全屏图来模糊场景画面(Shader | 模糊 | 滤镜 | Blur) ShaderGraph实现图片的高斯模糊 参考:【游戏开发实战】Unity ShaderGraph实现图片的高斯模糊效…...

Unity补完计划 之 SpriteEditer Multiple
本文仅作笔记学习和分享,不用做任何商业用途 本文包括但不限于unity官方手册,unity唐老狮等教程知识,如有不足还请斧正 1. SpriteEditer Multiple Automatic slicing - Unity 手册 这是用于裁剪图集的模式 应用之后精灵编辑器会看到Slice亮…...

C++ IOStream
IOStream 类流特性 不可赋值和复制缓冲重载了<< >> 状态位 示例 状态位操作函数coutcin getget(s,n)/get(s,n,d):getline otherif(!fs)/while(cin) operator void*()与 operator!()代码示例 File Stream open 函数 文件打开方式 文件读写 读写接口 一次读一个字符…...

2024/8/8训练
A - 无线网络整点栅格统计 题目链接 算法:模拟 题目大意 给你一个n*m的网格,然后输出每一个点作为顶点能构成的正方形数量(可以为斜正方形). 算法思路 本身题目数据是很小的,可以通过n^2的时间复杂度枚举每一个顶点,然后再通过n平方的时间复杂度枚举出另一个对角顶点,判断…...

项目的小结
项目场景: 作业的发布,打回 。 学生端做作业 由作业的state来确定作业是否上交,批改,打回作业。 实体类的建立,还有各种成员变量的设计要满足需求 问题描述 问题: 在进行上传作业后,老师端…...

【目标检测实验系列】YOLOv5高效涨点:基于NAMAttention规范化注意力模块,调整权重因子关注有效特征(文内附源码)
1. 文章主要内容 本篇博客主要涉及规范化注意力机制,融合到YOLOv5(v6.1版本,去掉了Focus模块)模型中,通过惩罚机制,调整特征权重因子,使模型更加关注有效特征,助力模型涨点。 2. 简要概括 论文地址&#x…...

LSPatch制作内置模块应用软件无需root 教你制作内置应用
前言 LSPatch功能非常强大,它是一款基于LSPosed核心的免Root Xposed框架软件。这意味着用户无需进行手机root操作,即可轻松植入内置Xposed模块,享受更多定制化的功能和体验,比如微某内置模块版等,这为那些不想root手机…...

Windows高DPI缩放导致Qt界面崩了?手把手教你用‘高DIP缩放替代’快速修复
Windows高DPI缩放导致Qt界面崩溃?三步搞定“高DPI缩放替代”修复方案 最近几年4K显示器价格越来越亲民,很多用户都升级到了高分辨率屏幕。但随之而来的一个常见问题就是:一些老旧的Qt程序在高分屏上运行时,界面元素变得错乱不堪—…...

Zynq XADC测量电压从配置到换算:DRP接口实战与AXI4-Lite选择指南
Zynq XADC电压测量全解析:DRP与AXI4-Lite接口深度对比与实战指南 在嵌入式系统设计中,精确的模拟信号监测往往是实现智能控制的关键环节。Xilinx Zynq系列芯片内置的XADC(Xilinx Analog-to-Digital Converter)模块,为工…...

PVE中使用SPICE功能遇到的10个高频率问题和解答方法
SPICE(Simple Protocol for Independent Computing Environments)是PVE(Proxmox VE)虚拟机中一款高效的远程桌面协议,相比默认的VNC,它具备更高的画面流畅度、更低的延迟,还支持文件夹共享、音频传输、USB设备重定向等增强功能,是…...

已登CVPR&Nature子刊,小波变换+深度学习杀疯了 !!
融合小波变换的深度学习模型是当前的研究热点之一,这个交叉领域热度高、前景好、创新空间大,只要选对结合点和方法,冲顶会顶刊问题不大。比如Transformer、GNN、KAN、CNN、mamba等,就是目前比较前沿而且热度很高的结合方式&#x…...

IceC:面向嵌入式平台的轻量级ICE兼容中间件
1. IceC:面向资源受限嵌入式平台的轻量级ZeroC ICE兼容中间件 1.1 设计定位与工程必要性 IceC并非ZeroC ICE的全功能移植,而是在AVR(如ATmega328P)和ESP8266等典型资源受限平台约束下,对ICE通信模型进行深度裁剪与重构…...

Qt Modbus 报文构建实战:QModbusRequest构造与sendRawRequest发送详解
1. Qt Modbus开发环境搭建与基础概念 在工业自动化领域,Modbus协议就像设备之间的"普通话",而Qt Modbus库则是我们与设备对话的翻译器。我刚开始接触这个领域时,花了一整天时间才搞明白如何正确发送一个简单的控制指令。下面分享我…...

PolyServo:基于中断的软件PWM多路伺服控制库
1. PolyServo 库深度解析:基于中断的多路 RC 伺服电机精确控制方案1.1 项目定位与工程价值PolyServo 是一个面向嵌入式实时控制场景设计的轻量级伺服驱动库,其核心创新在于完全摒弃对硬件 PWM 外设引脚的依赖,转而采用高精度软件定时器中断机…...

Visio是什么?附安装使用全流程
Visio是什么? 它是微软出品的专业图表绘制工具,是Office家族里最低调、但也是职场进阶最硬核的成员之一。如果说Excel是处理数字的神,那Visio就是处理逻辑和流程的王者。 安装教程和安装包获取 为什么建议你试试Visio? 1. 拖拽…...
+Oracle实现的(界面)教务管理系统)
基于QT(C++)+Oracle实现的(界面)教务管理系统
一、选题背景 教务管理系统是基本每个高校都有的一个系统,教务系统管理系统充分利用互联网络B/S管理系统模式,以网络为平台,为各个学校教务系统的管理提供一个平台,帮助学校管理教务,用一个账号解决学校教务教学管理&…...

MCGS 基于PLC的风力发电控制系统 带解释的梯形图程序,接线图原理图图纸,io分配
MCGS 基于PLC的风力发电控制系统 带解释的梯形图程序,接线图原理图图纸,io分配,组态画面最近在搞风力发电控制系统,发现MCGS和PLC的组合真是工业自动化领域的黄金搭档。今天就拿个真实项目里的风机控制程序开刀,带大家…...