Flink-DataWorks第四部分:数据同步(第60天)
系列文章目录
2.4.2 DataStudio侧实时同步
2.4.3 数据集成侧同步任务
文章目录
- 系列文章目录
- 前言
- 2.4.2 DataStudio侧实时同步
- 2.4.3 数据集成侧同步任务
前言
本文主要详解了DataWorks的数据同步,为第四部分:
由于篇幅过长,分章节进行发布。
后续:
数据开发
2.4.2 DataStudio侧实时同步
DataWorks为用户提供的实时数据同步功能,方便用户使用单表或整库同步方式,将源端数据库中部分或全部表的数据变化实时同步至目标数据库中,实现目标库实时保持和源库的数据对应。
使用限制:
实时同步不支持在数据开发界面运行任务,用户需要保存、提交实时同步节点后,在生产环境运维中心运行该节点。
实时同步仅支持运行在独享数据集成资源组上。
实时同步任务不支持同步视图。
目前支持的同步方式有:

步骤一:创建实时同步节点
(1)创建实时同步节点
可以通过以下两种方式创建实时同步节点。
方式一:展开业务流程,右键单击数据集成 > 新建节点 > 实时同步。
方式二:双击业务流程名称,将数据集成目录下的实时同步节点直接拖拽至右侧业务流程编辑面板。
(2)在新建节点对话框中,配置各项参数
同步方式设置为数据库变更数据同步到MaxCompute
路径设置为业务流程/test/数据集成
名称设置为stream_data_integration
步骤二:配置实时同步任务
(1)设置同步来源和规则
设置类型为MySQL,数据源设置为rdsmysql
选择同步的源表,这里勾选student_list表,然后添加到右侧

设置表(库名映射规则):设置表(表(库)名映射规则支持正则表达式转换,比如需要将名称为 “table_01”,“table_02”,“table_03” 同步到一张叫 “my_table” 的表,可以配置正则表名转换规则:源:table.* > 目标 my_table)名映射规则
因为这里是单表采集,所以无需设置
点击下一步
(2)设置目标表
目标MaxCompute数据源设置为odps_first
写入模式为实时直接写增量表
时间自动分区设置:分区表

点击编辑,修改分区间隔为天
刷新源表和MaxCompute表映射
然后点击下一步
(3)因为是新表,所以需要自动建表,点击开始建表

(4)设置表粒度同步规则
点击配置DML,可以设置插入、更新、删除的策略,是选择还是正常处理

一般选择正常处理即可,点击下一步
(5)DDL消息处理规则
对于关系型数据的实时同步,其原始实时信息会包含DDL操作,此处可以设置针对于这些DDL消息同步到目标表时的操作。
【注意】此处策略仅仅是本任务初次启动时的规则,此后用户可以在对应的实时任务运维页面中,通过停止任务,修改DDL规则,再启动的方式,应用新的DDL策略。

各个处理策略的含义:
“正常处理”,此DDL消息将会继续下发给目标数据源,由目标数据源来处理,不同目标数据源处理策略可能会不同。
“忽略”:丢弃掉此DDL消息,不再向目标数据源发送此消息。
“出错”:直接让实时同步任务以出错状态终止运行。
保持默认即可。
(6)运行资源设置
资源组选择hmcx
Tunnel资源组选择公共传输资源
点击完成配置。
步骤三:提交并发布实时同步任务
(1)单击工具栏中的保存图标,保存节点。
(2)单击工具栏中的提交图标,提交节点任务。
在提交新版本对话框中,输入变更描述。
单击确定。
(3)任务提交成功后,需要将任务发布至生产环境进行发布。单击顶部菜单栏右侧的任务发布。

选择任务节点,进行发布。
(4)点击运维中心,在实时任务运维的实时同步任务中可以看到提交上来的任务
点击启动,可以启动同步任务

(5)启动成功后,稍等片刻
在MySQL中输入
insert into test.student_list values (‘09’, ‘李博’, ‘1995-05-24’, ‘男’);
然后在dataworks
set odps.sql.allow.fullscan=true;
select * from dwhmcx.rdsmysql_test_student_list;
可以看到同步的消息。

2.4.3 数据集成侧同步任务
数据集成基于源端数据库与目标端数据库类型为用户提供丰富的数据同步任务,同步类型包括:整库离线同步(一次性全量同步、周期性全量同步、离线全增量同步、一次性增量同步、周期性增量同步)、一键实时同步(一次性全量同步,实时增量同步)。不同源端与目标端数据库支持的同步方案不同,具体支持的方案详情请参考产品界面。
步骤一:创建同步任务
打开数据集成,然后在同步任务中,创建同步任务,填写来源和去向。
这里来源选择MySQL,去向选择MaxCompute,然后点击开始创建。

步骤二:选择同步方案
填写新任务名称,full_increment_integration
选择同步类型,目前支持的类型有以下几种。这里选择整库全增量(准实时)

责任人选择xxx111
步骤三:网络与资源配置
按照下图进行配置,测试连通性没有问题后点击下一步

步骤四:设置同步来源和规则
基本配置和数据来源不用修改
选择同步的源表中,选择test库,然后添加到右侧

设置表(库)名映射规则
点击添加目标表名规则,设置目标表名规则为:full_increment_${db_table_name_src_transed}

可以使用的内置变量有:
${db_table_name_src_transed}:“源表名和目标表名转换规则”中的转换完成之后的表名。
${db_name_src_transed}:“和转换规则”中的转换完成之后的。
${ds_name_src}:源数据源名。
步骤五:设置目标表
设置“时间自动分区设置”为非分区表

然后刷新源表和MaxCompute表映射
然后点击下一步
步骤六:设置表粒度同步规则
Base表Merge设置:
每张表的实时同步数据会在其全量离线任务完成后,实时的写入MaxCompute(Log表),然后会经过拆分(Split)变为Delta表,最后再与Base表进行合并(Merge),最终结果会写入Base表中。默认情况下会根据用户在上一步中指定的MaxCompute(ODPS)时间分区来做Merge,例如用户指定的分区是“天”,则会每天进行一次merge,也就意味着Base表的数据更新需要等到第二天。但是由于每个表的大小不一样,所以全量离线同步任务完成的时间有先后,如果用户想指定某些表在完成全量离线同步之后提早进行merge动作,以便及时获得最新的Base表数据,那么用户可以在本页中进行设置。
全量任务离线任务已经完成后,将最新实时同步的结果Merge进入Base表中
按小时独立:每一小时进行一次merge动作。
按天独立:每一天进行一次merge动作。
按分区周期:按照maxcompute表的分区间隔进行merge动作,前提是上一个周期的merge已经完成。
这里修改为按天独立,点击下一步

步骤七:设置表粒度同步规则
对于关系型数据的实时同步,其原始实时信息会包含DDL操作,此处可以设置针对于这些DDL消息同步到目标表时的操作。
【注意】此处策略仅仅是本任务初次启动时的规则,此后用户可以在对应的实时任务运维页面中,通过停止任务,修改DDL规则,再启动的方式,应用新的DDL策略。
保持默认即可,点击下一步

步骤八:运行资源设置
这里可以修改资源组
连通性测试没有问题后,勾选立即执行,完成配置
此时会生成两个任务,一个离线,一个实时。离线用来同步全量任务,而实时用来同步增量任务。
任务列表中也可以查到刚刚创建的任务
在ODPS中即可查看结果:
select * from dwhmcx.full_increment_student_list;
如果任务需要停止,则需要到运维中心的实时同步任务中进行停止。

相关文章:
Flink-DataWorks第四部分:数据同步(第60天)
系列文章目录 2.4.2 DataStudio侧实时同步 2.4.3 数据集成侧同步任务 文章目录 系列文章目录前言2.4.2 DataStudio侧实时同步2.4.3 数据集成侧同步任务 前言 本文主要详解了DataWorks的数据同步,为第四部分: 由于篇幅过长,分章节进行发布。…...

go post请求,参数是raw json格式,response是固定结构。
在Go语言中,使用net/http包可以很方便地发送HTTP请求,包括POST请求。当需要发送raw JSON格式的参数时,通常会使用encoding/json包来将Go的结构体序列化为JSON字符串,然后使用http.NewRequest函数创建请求,并通过http.C…...
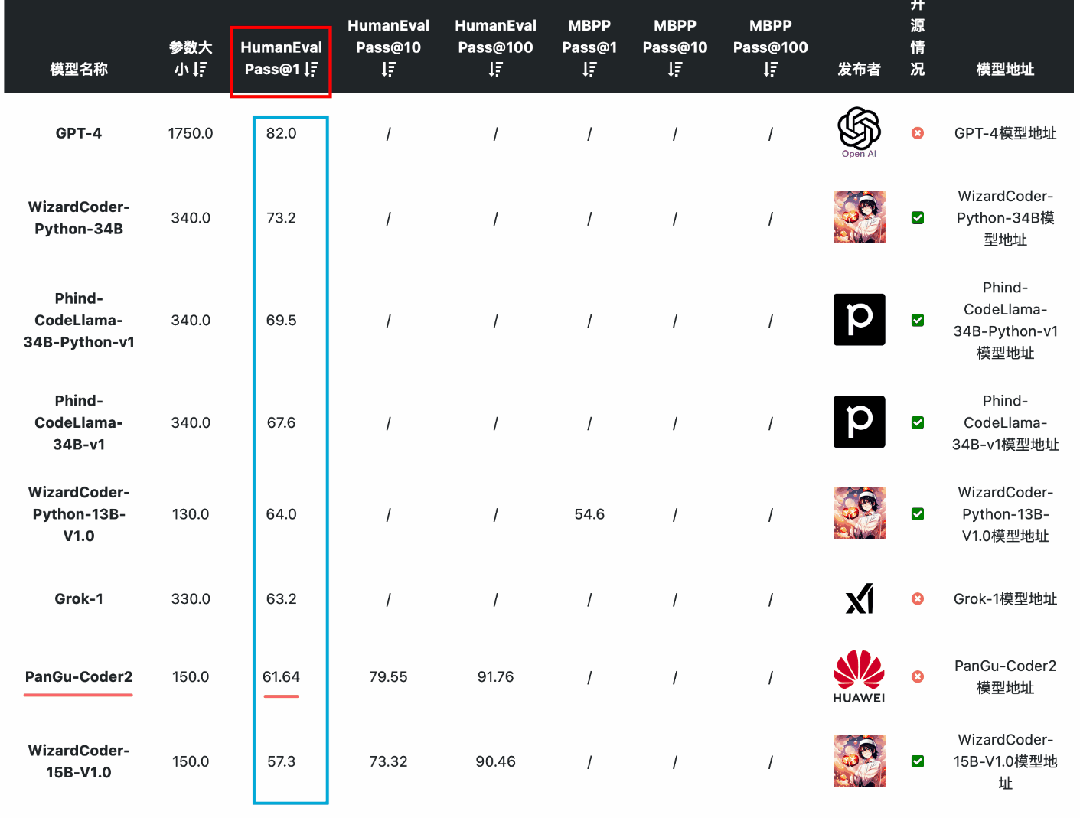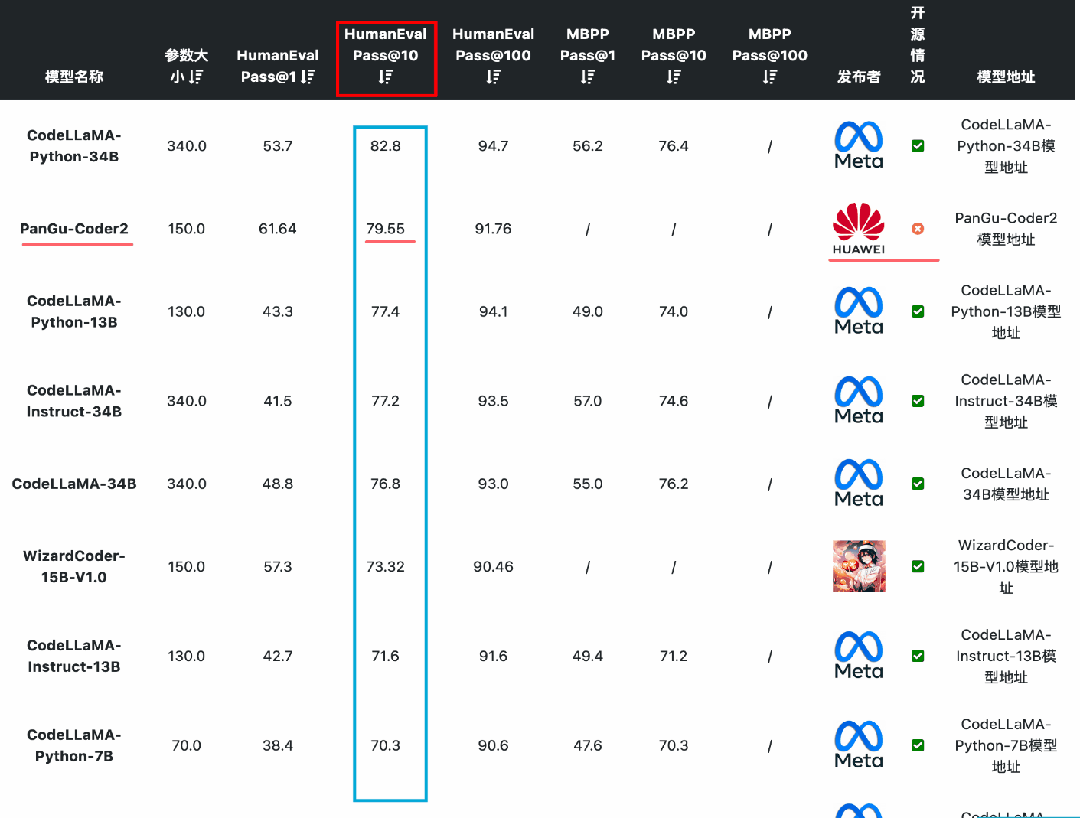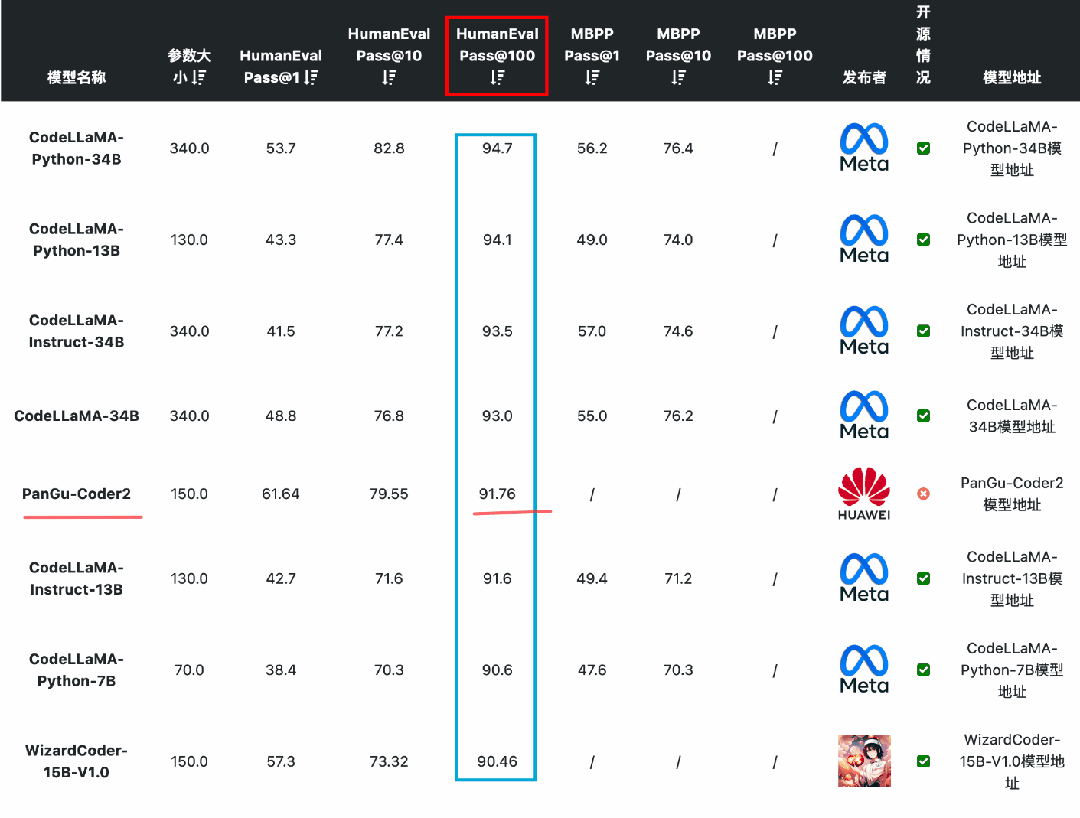
国产开源大模型都有哪些?
随着ChatGPT引领的大模型热潮,国内的公司开始相继投入研发自己的人工智能大模型,截止到2023年10月,国产公司的大模型有近百个,包括一些通用大模型,比如百度的文心一言,也有特定领域的专用大模型,…...

基于Hadoop的超市进货推荐系统设计与实现【springboot案例项目】
文章目录 有需要本项目的代码或文档以及全部资源,或者部署调试可以私信博主项目介绍系统分析系统设计数据表设计表4-1:关于我们表4-2:用户表4-3:管理员表表4-4:token表表4-5:系统简介表4-6:收藏…...

ChatGPT能从这几个方面提升学术论文质量
学境思源,一键生成论文初稿: AcademicIdeas - 学境思源AI论文写作 写作和编辑高质量的学术论文是一项具有挑战性的任务。随着人工智能技术的进步,ChatGPT作为一种强大的语言生成工具,正逐渐成为提升论文质量的得力助手。从头脑风…...

Python3的安装及基础指令
Day 20 基础语法 1、环境:python2内置,安装并使用python3,最新版3.12版可以使用源码安装 # 查看python版本号 [rootpython ~]#yum list installed|grep python [rootpython ~]#yum list installed|grep epel [rootpython ~]# yum -y …...

使用Spring与JDK动态代理实现事务管理
使用Spring与JDK动态代理实现事务管理 在现代企业级应用开发中,事务管理是一项关键的技术,它可以保证一系列操作要么全部成功,要么全部失败,从而确保数据的一致性和完整性。Spring框架提供了强大的事务管理能力,但有时…...

服务器硬件及RAID配置
服务器及 RAID 磁盘阵列介绍 RAID0 俗称 “ 条带 ” ,它将两个或多个硬盘组成一个逻辑硬盘,容量是所有硬盘之和,因 为是多个硬盘组合成一个,故可并行写操作,写入速度提高,但此方式硬盘数据没有冗余&#…...
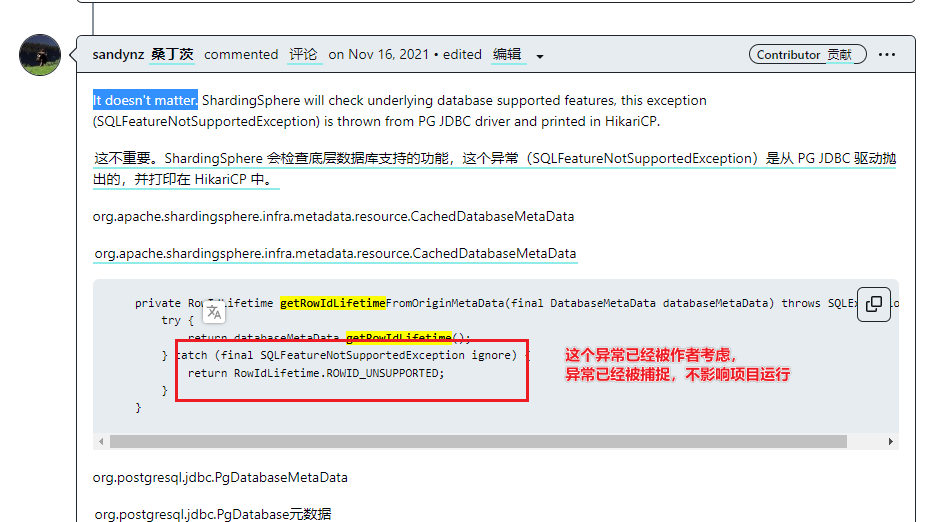
【经验总结】ShardingSphere5.2.1 + Springboot 快速开始
Sharding Sphere 官方文档地址: https://shardingsphere.apache.org/document/current/cn/overview/maven仓库:https://mvnrepository.com/artifact/org.apache.shardingsphere/shardingsphere-jdbc 官方的文档写的很详尽到位,这里会截取部分…...
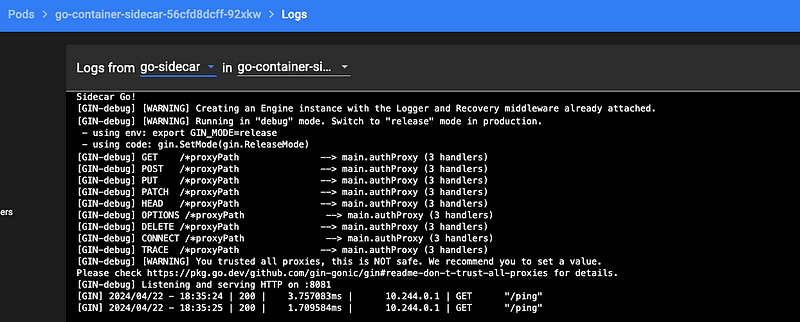
基于Golang实现Kubernetes边车模式
本文介绍了如何基于 Go 语言实现 Kubernetes Sidecar 模式,并通过实际示例演示创建 Golang 实现的微服务服务、Docker 容器化以及在 Kubernetes 上的部署和管理。原文: Sidecar Pattern with Kubernetes and Go[1] 在这篇文章中,我们会介绍 Sidecar 模式…...

TCP 通信全流程分析:从连接建立到数据传输的深度探索
目录 一、TCP报头 二、三次握手 三、数据传输 四、四次挥手 本文通过一次TCP通信过程的分析来学习TCP协议 一、TCP报头 如图是一份TCP报文的报头,标准报头是20个字节,还可带有选项报头,也就是TCP报头的最小长度是20字节。以下是对报头的各…...

4、提取H264码流中nalu
H264的NALU提取 1、nalu单元 定义nalu的存储单元,ebsp用来存储原始的包含起始码(annexb格式)的原始码流,sodb存储去除防竞争字节后的码流,prefix是3或4字节 nalu_def.h // nalu_def.h #pragma once#include <cs…...
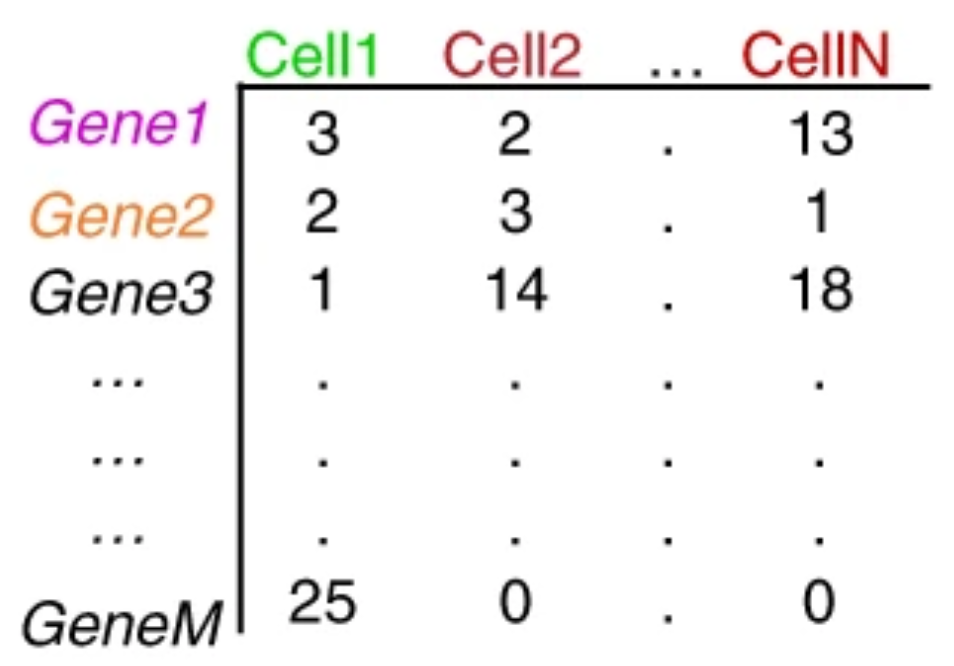
哈佛大学单细胞课程|笔记汇总 (二)
哈佛大学单细胞课程|笔记汇总 (一) (二)Single-cell RNA-seq data - raw data to count matrix 根据所用文库制备方法的不同,RNA序列(也被称为reads或tag)将从转录本((10X Genomic…...

java中抽象类和接口的区别
文章目录 接口和抽象类的区别一、定义的区别1、抽象类2、接口 二、使用场景的区别1、抽象类2、接口 三、使用案例1、抽象类2、接口 接口和抽象类的区别 一、定义的区别 1、抽象类 关键字: abstract 是模棱两可的,似是而非的,无法给出具体明…...

Spring Boot - 在Spring Boot中实现灵活的API版本控制(下)_ 封装场景启动器Starter
文章目录 Pre设计思路ApiVersion 功能特性使用示例配置示例 ProjectStarter Code自定义注解 ApiVersion配置属性类用于管理API版本自动配置基于Spring MVC的API版本控制实现WebMvcRegistrations接口,用于自定义WebMvc的注册逻辑扩展RequestMappingHandlerMapping的类…...
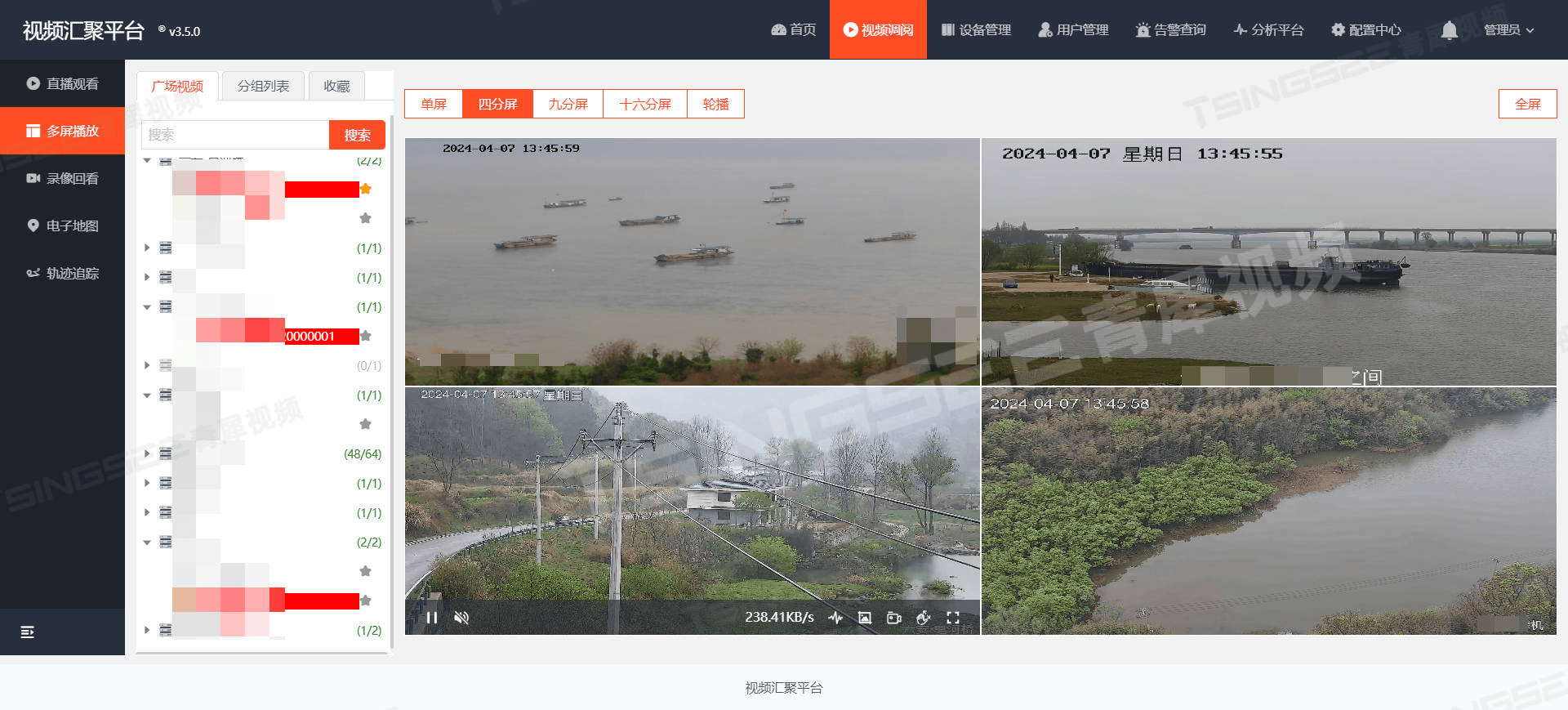
EasyCVR视频转码:T3视频平台不支持GB28181协议,应该如何实现与视频联网平台的对接与视频共享呢?
EasyCVR视频管理系统以其强大的拓展性、灵活的部署方式、高性能的视频能力和智能化的分析能力,为各行各业的视频监控需求提供了优秀的解决方案。 T3视频为公网HTTP-FLV或HLS格式的视频流,目前T3平台暂不支持国标GB28181协议,因此也无法直接接…...

Spring统一处理请求响应与异常
在web开发中,规范所有请求响应类型,不管是对前端数据处理,还是后端统一数据解析都是非常重要的。今天我们简单的方式实现如何实现这一效果 实现方式 定义响应类型 public class ResponseResult<T> {private static final String SUC…...
 WITH common_table_expression)
SqlServer公用表表达式 (CTE) WITH common_table_expression
SQL Server 中的公用表表达式(Common Table Expressions,简称 CTE)是一种临时命名的结果集,它在执行查询时存在,并且只在该查询执行期间有效。CTE 类似于一个临时的视图或者一个内嵌的查询,但它提供了更好的…...
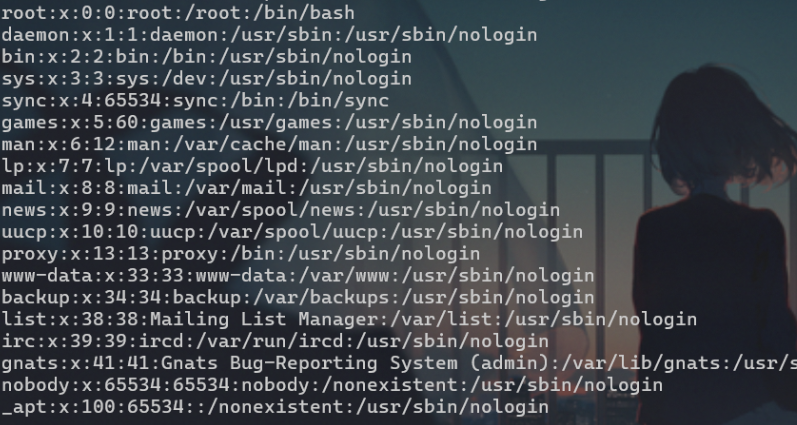
常见中间件漏洞
Tomcat CVE-2017-12615 1.打开环境,抓包 2.切换请求头为 PUT,请求体添加木马,并在请求头添加木马文件名 1.jsp,后方需要以 / 分隔 3.连接 后台弱口令部署war包 1.打开环境,进入指点位置,账户密码均为 tomcat 2.在此处上传一句话…...

elasticsearch的学习(二):Java api操作elasticsearch
简介 使用Java api操作elasticsearch 创建maven项目 pom.xml文件 <?xml version"1.0" encoding"UTF-8"?><project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi…...

Blender3mfFormat插件全攻略:从安装配置到3D打印工作流优化
Blender3mfFormat插件全攻略:从安装配置到3D打印工作流优化 【免费下载链接】Blender3mfFormat Blender add-on to import/export 3MF files 项目地址: https://gitcode.com/gh_mirrors/bl/Blender3mfFormat Blender3mfFormat插件是一款专为Blender设计的3MF…...
)
9篇8章2节:MIMIC 数据库的 CITI 注册与课程选择(2026年版)
作为包含敏感患者信息的公共数据库,MIMIC 对使用权限的申请设置了严格的伦理与合规门槛,其核心目的在于保障患者隐私、维护学术诚信。其中,通过 CITI Program 的人体研究伦理认证是不可或缺的前置条件,也是衡量研究人员是否具备合规研究素养的关键标准。本文将详细拆解 202…...

PHP脚本设置无限执行时间的四种方法
为 PHP 脚本设置无限执行时间是一个在特定场景下可能需要的操作,比如执行长时间运行的后台任务、数据迁移、大批量数据处理等。然而,值得注意的是,设置无限执行时间并不是一种推荐的做法,因为它可能导致服务器资源被长时间占用&am…...
原理与在YOLOv11中的集成)
可变形卷积(Deformable Convolution)原理与在YOLOv11中的集成
上周在产线测试YOLOv11的缺陷检测模型,遇到个头疼的问题:同一类金属件,因为冲压模具磨损导致边缘出现轻微形变,模型漏检率突然飙升。常规的卷积核是固定网格采样,对这类几何形变缺乏适应性。调了一整天数据增强&#x…...

BigDL-2.x与Spark MLlib集成:传统机器学习与深度学习的完美融合
BigDL-2.x与Spark MLlib集成:传统机器学习与深度学习的完美融合 【免费下载链接】BigDL-2.x BigDL: Distributed TensorFlow, Keras and PyTorch on Apache Spark/Flink & Ray 项目地址: https://gitcode.com/gh_mirrors/bi/BigDL-2.x BigDL-2.x是一个强…...

COMSOL 6.1版本皮秒多脉冲激光烧蚀模型:双温模型、变形几何与烧蚀模拟
COMSOL 6.1版本 皮秒多脉冲激光烧蚀模型 模型内容:涉及双温模型,变形几何,烧蚀,皮秒脉冲热源,电子、晶格温度 优势:模型注释清晰明了,各个情况都有涉及可参考性极强,可以修改&#x…...

模板号:每一家创业公司都应该有企业官网
模板号(mobanhao.com):让每一家创业公司都能轻松拥有专业官网品牌定位:专注WordPress模板建站,服务创业型企业的数字化伙伴模板号(mobanhao.com)是一家专注于WordPress模板网站搭建的专业服务机构,总部位于中国改革开放的前沿阵地…...

支持向量机避坑指南:当你的SVM分类效果差时该检查这5个参数
支持向量机避坑指南:当你的SVM分类效果差时该检查这5个参数 在机器学习实践中,支持向量机(SVM)因其出色的分类性能而广受欢迎,但许多开发者在调参过程中常常陷入困境。本文将深入剖析影响SVM性能的五大关键参数&#x…...

三星固件管理的终极跨平台解决方案:Bifrost技术深度解析与实践指南
三星固件管理的终极跨平台解决方案:Bifrost技术深度解析与实践指南 【免费下载链接】SamloaderKotlin 项目地址: https://gitcode.com/gh_mirrors/sa/SamloaderKotlin 对于三星设备用户和开发者而言,获取官方固件一直是个技术难题。传统方法要么…...
)
保姆级教程:手把手教你配置英飞凌TC38x的Overlay功能(附寄存器详解)
保姆级教程:手把手教你配置英飞凌TC38x的Overlay功能(附寄存器详解) 在汽车电子控制单元(ECU)开发中,实时标定参数是开发调试过程中不可或缺的环节。英飞凌TC38x系列微控制器提供的Overlay功能,…...