HBase高手之路4-Shell操作
文章目录
- HBase高手之路3—HBase的shell操作
- 一、hbase的shell命令汇总
- 二、需求
- 三、表的操作
- 1.进入shell命令行
- 2.创建表
- 3.查看表的定义
- 4.列出所有的表
- 5.删除表
- 1)禁用表
- 2)启用表
- 3)删除表
- 四、数据的操作
- 1.添加数据
- 2.获取(查看)数据
- 1)获取一行数据
- 2)获取单个数据
- 3.更新(修改)数据
- 4.删除数据
- 1)删除指定列的数据
- 2)删除整行数据
- 3)清空表
- 五、导入数据
- 1.数据文件的准备
- 2.把数据文件上次到服务器
- 3.创建表,根据数据文件的定义
- 4.执行命令导入命令数据文件
- 5.查看数据
- 六、计数操作
- 1.计数命令
- 2.MR程序计数
- 七、扫描操作
- 1.全表扫描
- 2.限定记录数
- 3.限定列
- 4.限定rowkey
- 八、HBase的过滤器
- 1.简介
- 2.过滤器
- 3.过滤器的用法
- 1)比较运算符
- 2)比较器
- 3)比较器表达式
- 4.案例一:查询指定订单id的数据
- 1)需求
- 2)分析
- 3)实现
- 5.案例二:查询状态为已付款的订单
- 1)需求
- 2)分析
- 6.案例三:组合多条件过滤1
- 1)需求
- 2)分析
- 7. 案例四:组合多条件过滤2
- 1)需求
- 2)分析
- 8.作业
- 九、INCR
- 1. 需求
- 2. incr操作
- 3.基本使用
- 4.导入准备好的数据
- 5.获取计数器值的命令
- 6.使用incr进行累加操作,修改计数器的值
- 十、Shell管理操作
- 1.status
- 2.whoami
- 3.list
- 4.count
- 5.describe
- 6.exists
- 7.is_enabled、is_disabled
- 8.alter
- 参考文章

HBase高手之路3—HBase的shell操作
一、hbase的shell命令汇总
| 命令 | 功能 |
|---|---|
| create | 创建表 |
| put | 插入或者更新数据 |
| get | 获取限定行或者列的数据 |
| scan | 全表扫描或扫描表并返回表的数据 |
| describe | 查看表的结构 |
| count | 统计行数 |
| delete | 删除指定的行或列的数据 |
| deleteall | 删除整个行或者列的数据 |
| truncate | 删除表的数据,结构还在 |
| drop | 删除整个表(包括数据) |
二、需求
有以下的订单数据,需要将其保存在HBase中
| 订单id | 订单状态 | 支付金额 | 支付方式 | 用户id | 操作时间 | 商品分类 |
|---|---|---|---|---|---|---|
| 001 | 已付款 | 189.5 | 1 | 100001 | 2023-3-6 9:10:24 | 手机 |
三、表的操作
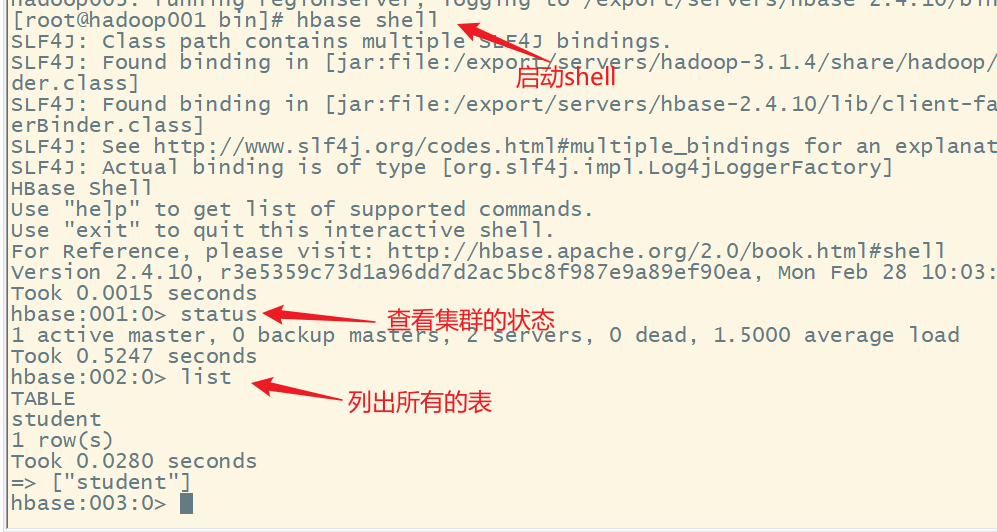
1.进入shell命令行
注意:需要提前启动 ZooKeeper、hdfs、hbase集群
2.创建表
命令格式:
create '表名','列簇名1'[,'列簇名2',...]
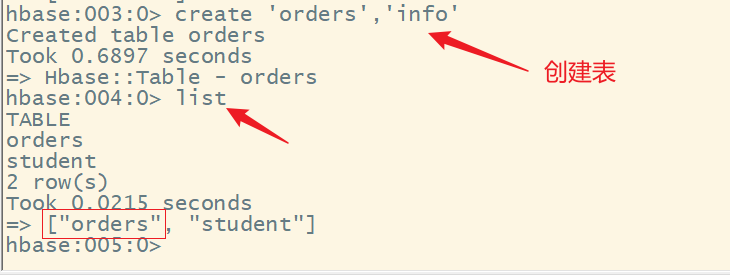
注意:create要小写,一个表可以有多个列簇
3.查看表的定义
命令格式:
describe '表名'

4.列出所有的表
命令格式:
list
5.删除表
1)禁用表
命令格式:
disable '表名'

2)启用表
命令格式:
enable '表名'

3)删除表
命令格式:
drop '表名'
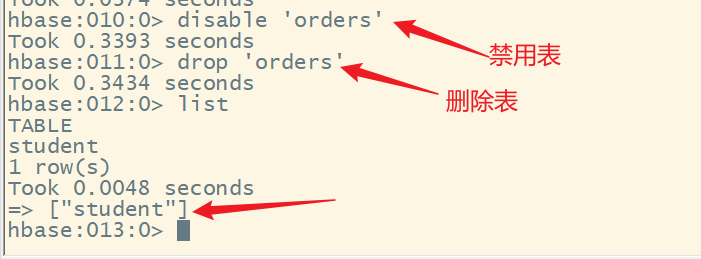
注意:表处于启用状态时是无法删除的,若要删除表需要先禁用表,在进行删除。
四、数据的操作
1.添加数据
命令格式:
put '表名','rowkey行键','列簇名:列名',值

依次添加其他的数据

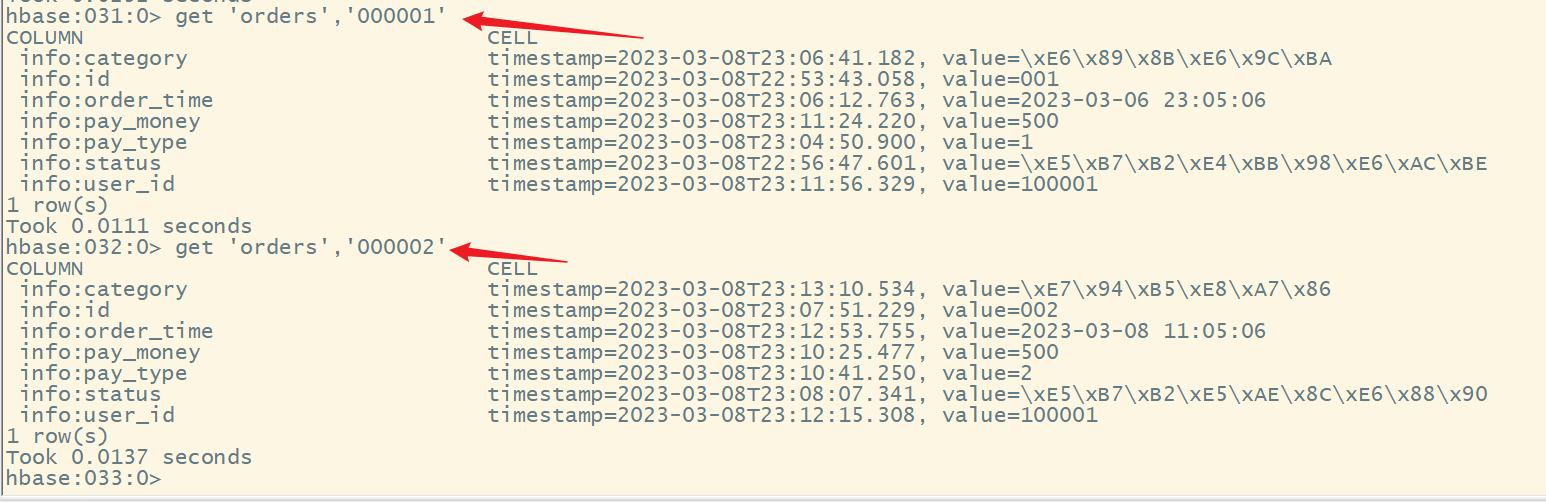
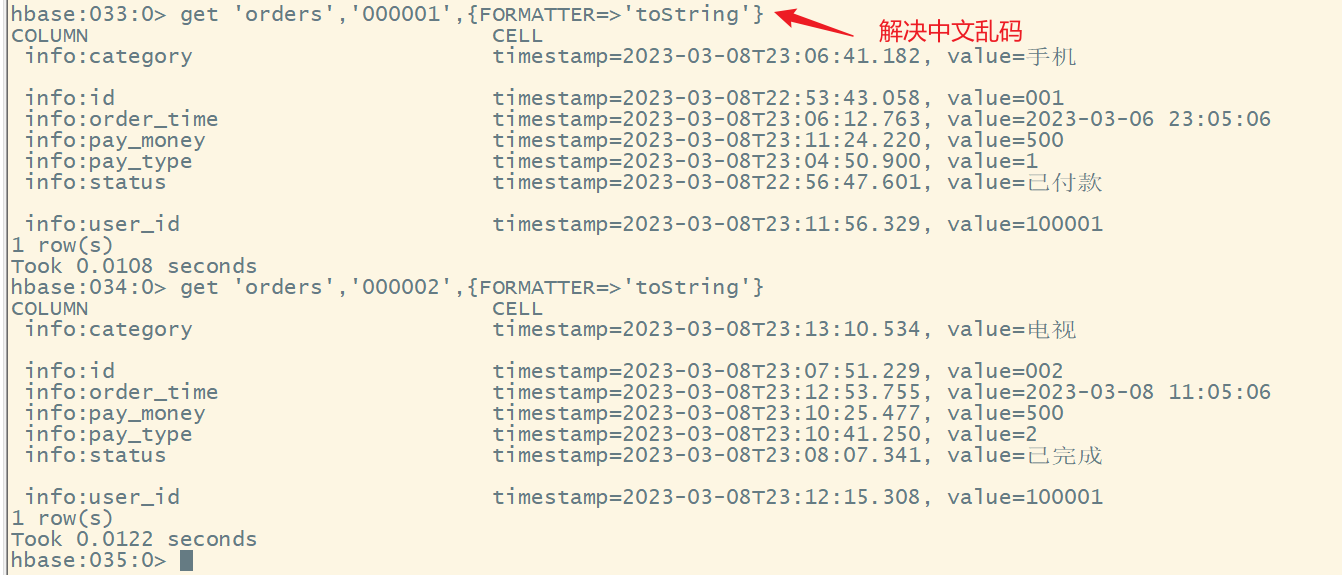
注意:如果显示中文乱码,是因为hbase的shell中显示的是中文的十六进制编码,要解决中文乱码,需要添加选项,jrubby语法格式:
{属性名=>属性值}如果有多个属性,中间用逗号格式


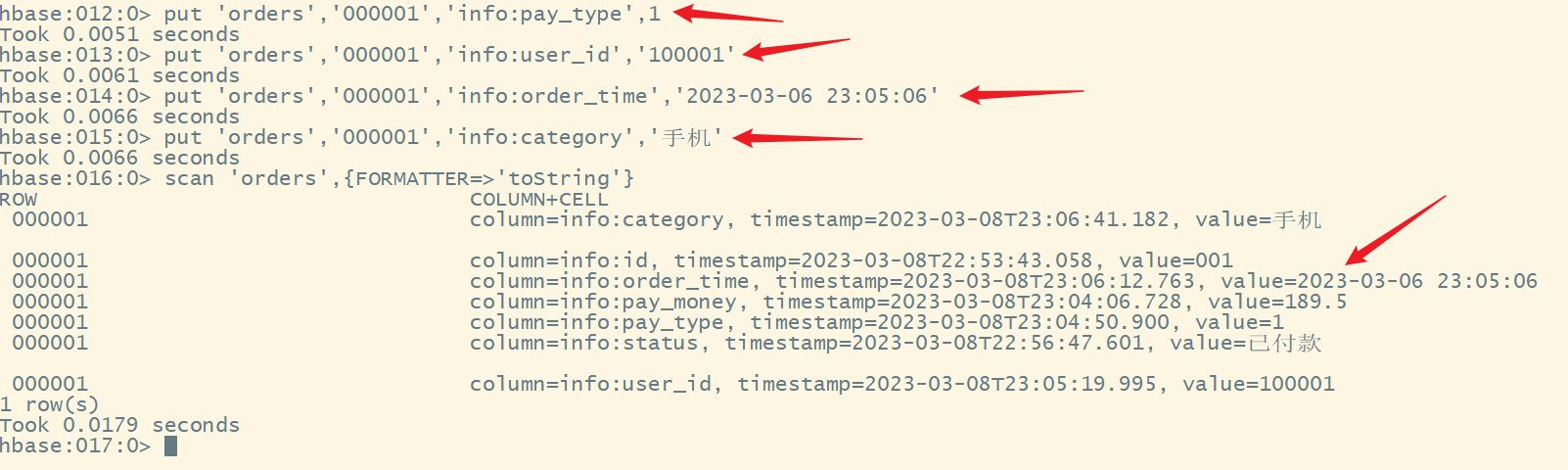
再次添加另一个rowkey的数据

2.获取(查看)数据
1)获取一行数据
命令格式:
get '表名','rowkey'
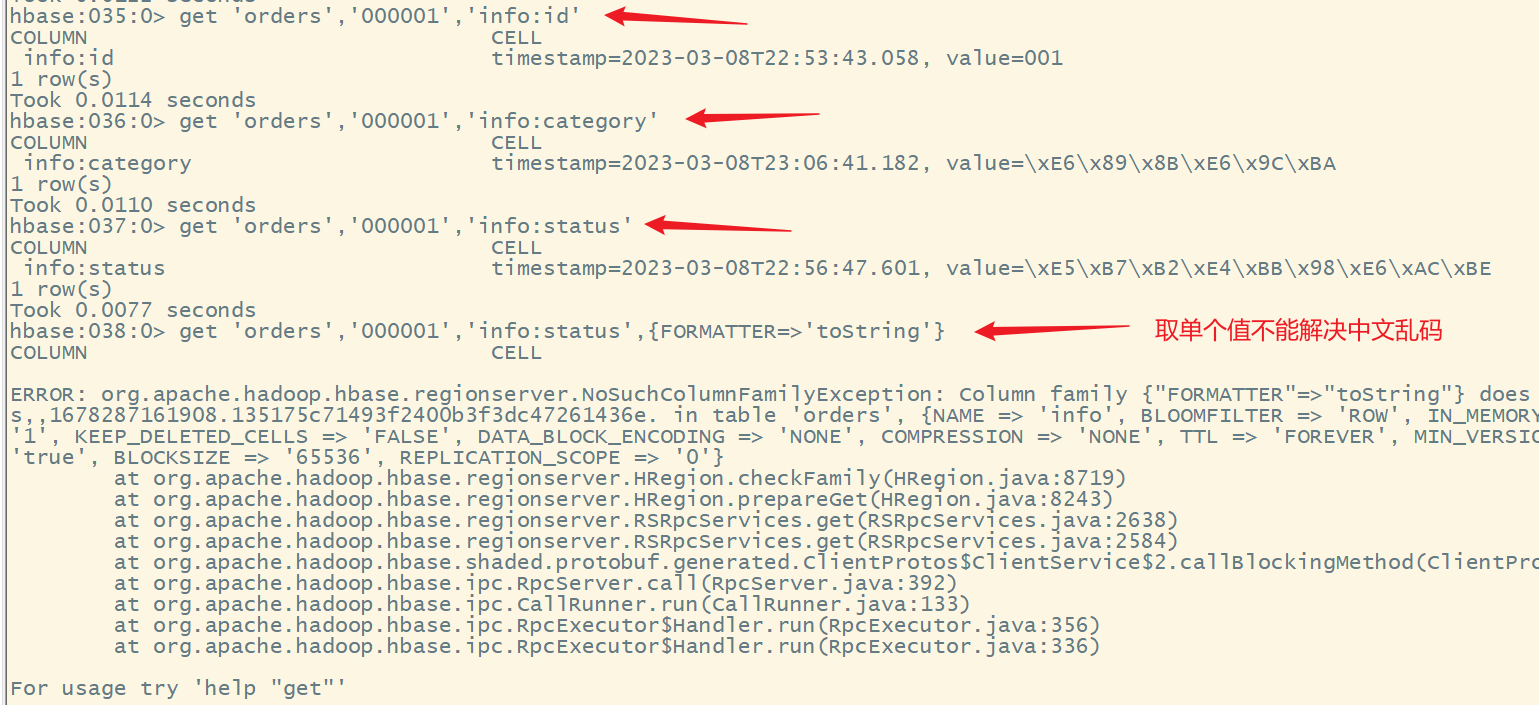
2)获取单个数据
命令格式:
get '表名','rowkey','列簇名:列名'
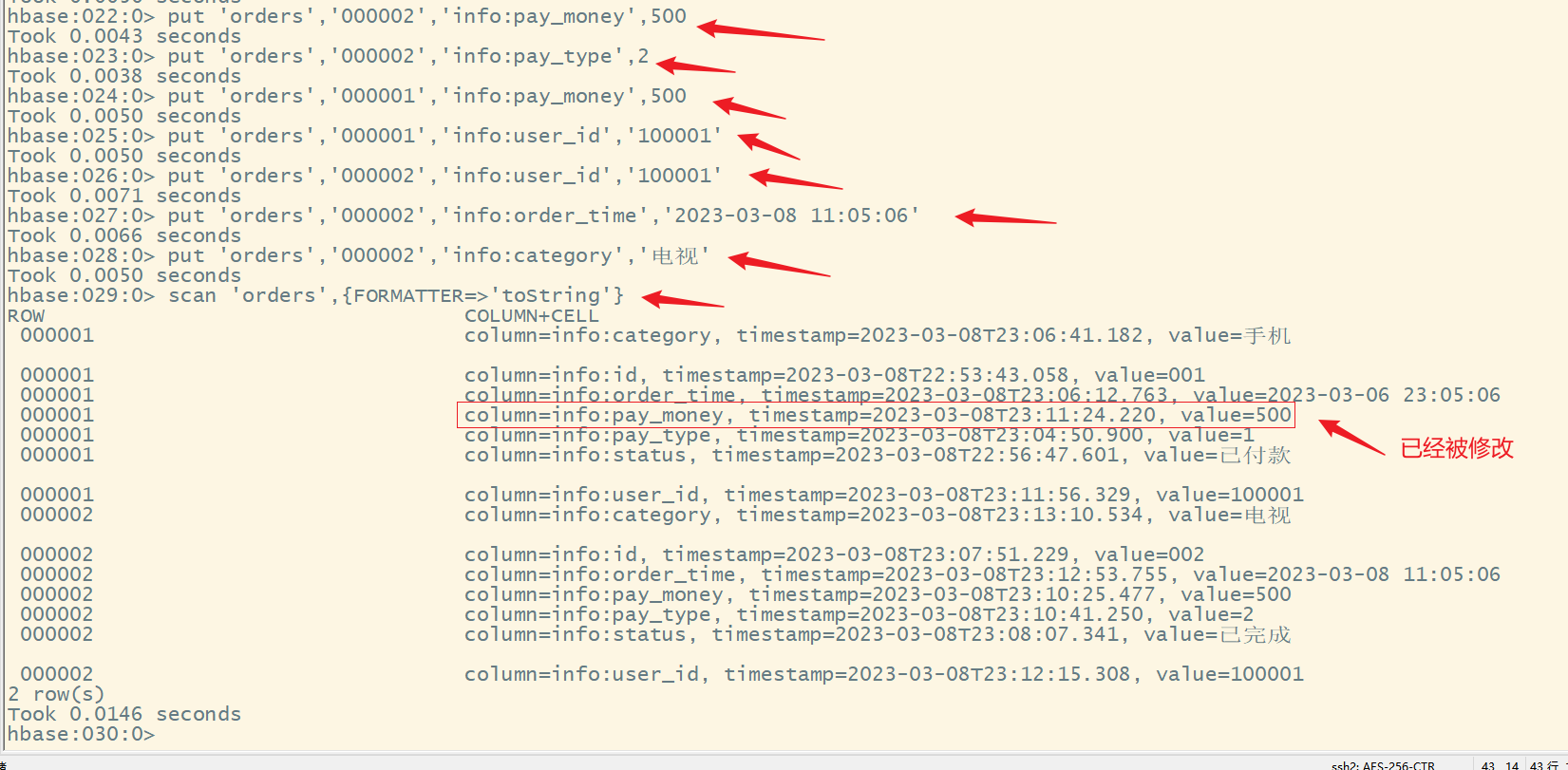
3.更新(修改)数据
命令格式:
put '表名','rowkey行键','列簇名:列名',新值

说明:
- put命令如果键值存在则修改,如果不存在则添加
- 在HBase中会自动维护表中数据的版本,即时间戳
- 每执行一次put操作,都会生产一个新的时间戳
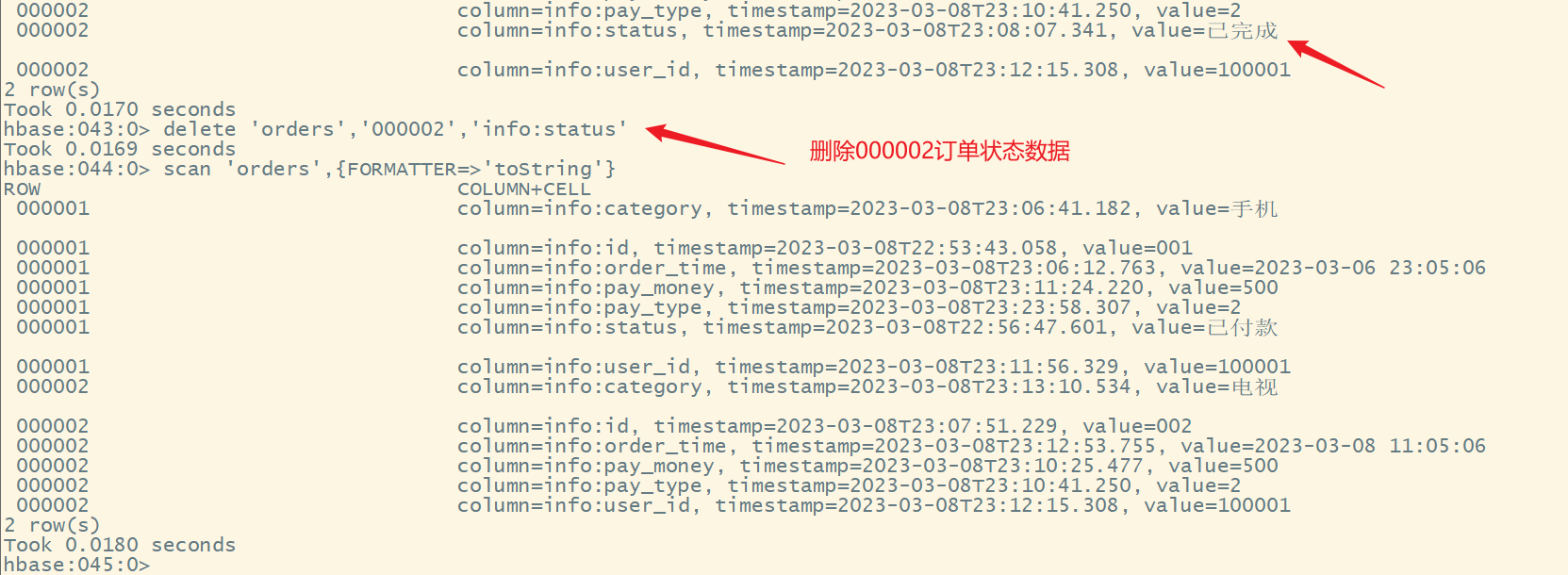
4.删除数据
1)删除指定列的数据
命令格式:
delete '表名','行键','列簇名:列名'
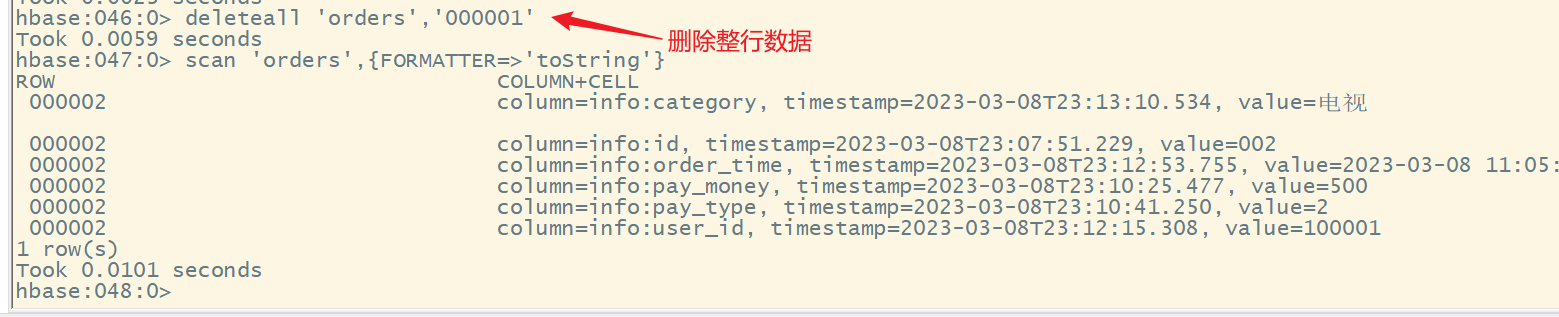
2)删除整行数据

命令格式:
deleteall '表名','行键'
3)清空表
命令格式:
truncate '表名'

五、导入数据
1.数据文件的准备
2.把数据文件上次到服务器
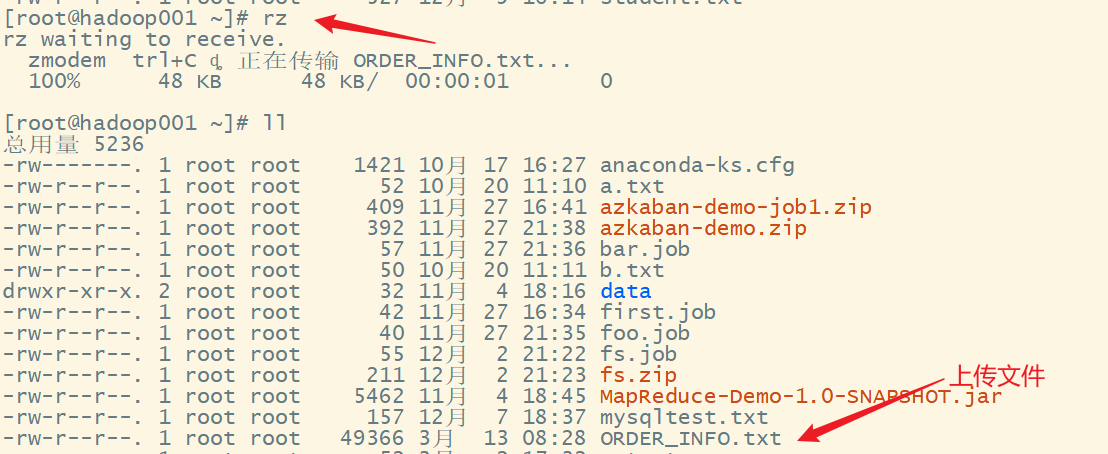
3.创建表,根据数据文件的定义
注意:集群启动
- 启动ZooKeeper
- 启动hdfs
- 启动HBASE
- 进入shell命令行
create 'ORDER_INFO' ,'C1'
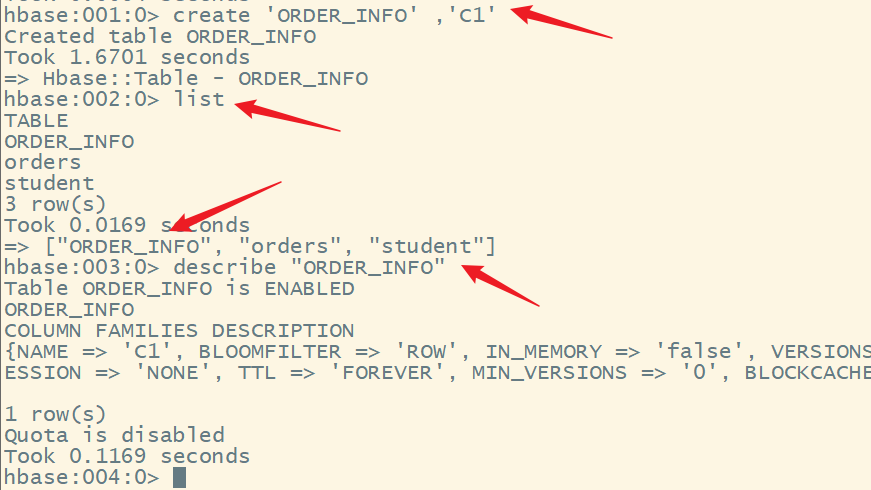
4.执行命令导入命令数据文件

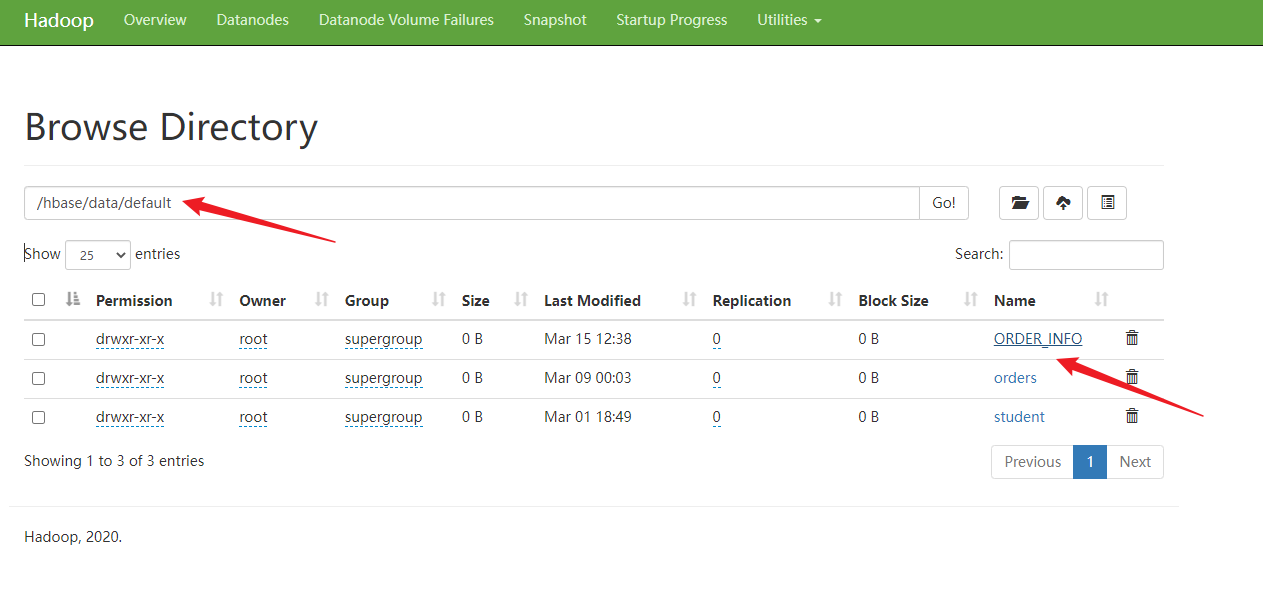
5.查看数据

此时,HBase的数据在HDFS上是的存储查看
六、计数操作
统计表中有多少条数据
1.计数命令
语法:
count '表名'
功能:统计rowkey不同的行数
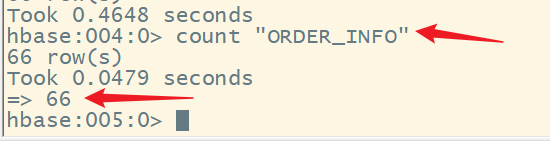
注意:当数据量很大的时候,这个操作是比较耗时的
2.MR程序计数
当数据量很大很大的时候,可以通过HBase提供的MR程序进行计数,这个mr程序是
org.apache.hadoop.hbase.mapreduce.RowCounter,语法格式:
hbase org.apache.hadoop.hbase.mapreduce.RowCounter '表名'
此时需启动yarn
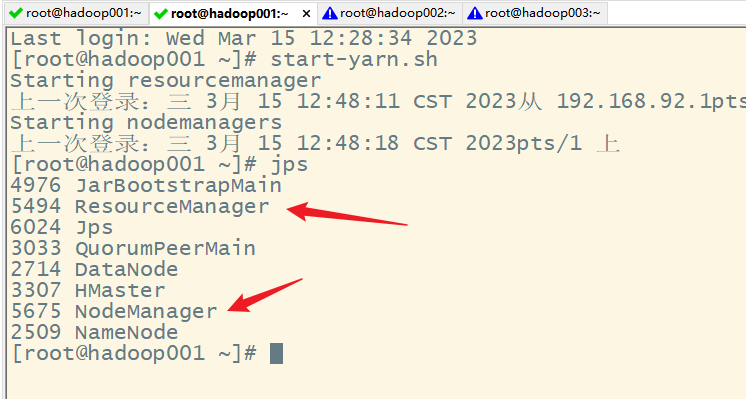
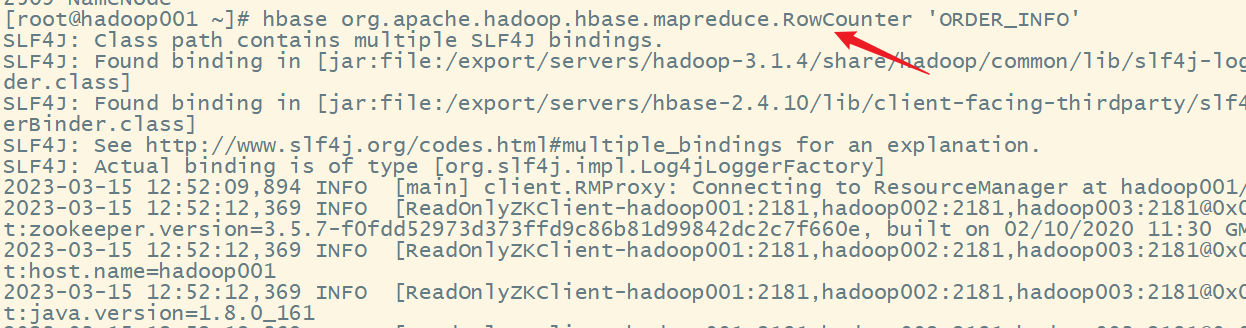
启动计数命令
hbase org.apache.hadoop.hbase.mapreduce.RowCounter 'ORDER_INFO'
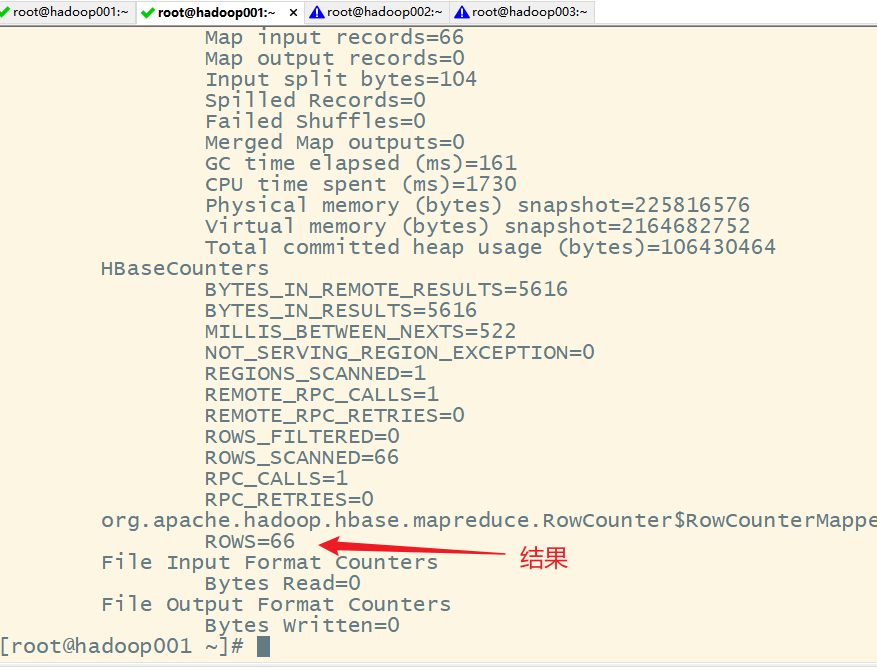
七、扫描操作
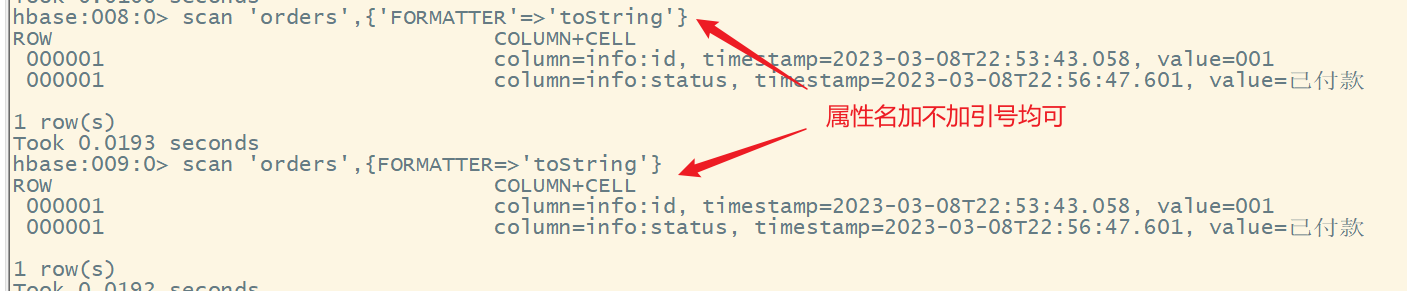
1.全表扫描
语法:
scan ‘表名’,{FORMATTER=>‘toString’}

注意:尽量避免全表扫描一张很大很大的表
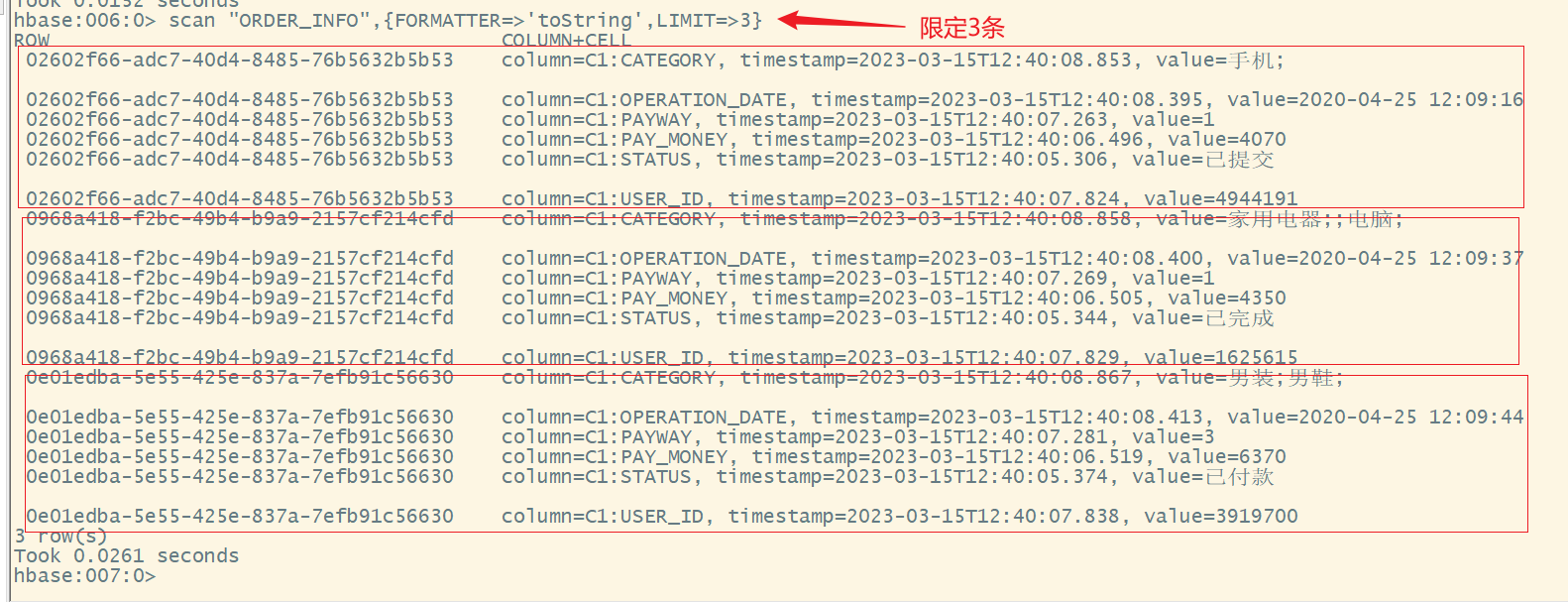
2.限定记录数
语法:
scan ‘表名’,{FORMATTER=>'toString',LIMIT=>数字}
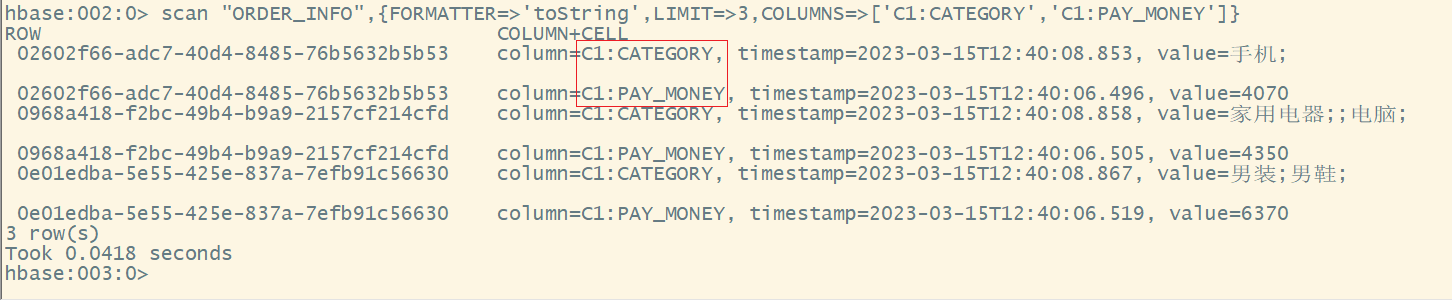
3.限定列
Rubby语法:
scan ‘表名’,{FORMATTER=>'toString',COLUMNS=>[‘列簇名1:列名1’,’列簇名1:列名2’,...]}
scan "ORDER_INFO",{FORMATTER=>'toString',LIMIT=>3,COLUMNS=>['C1:CATEGORY','C1:PAY_MONEY']}
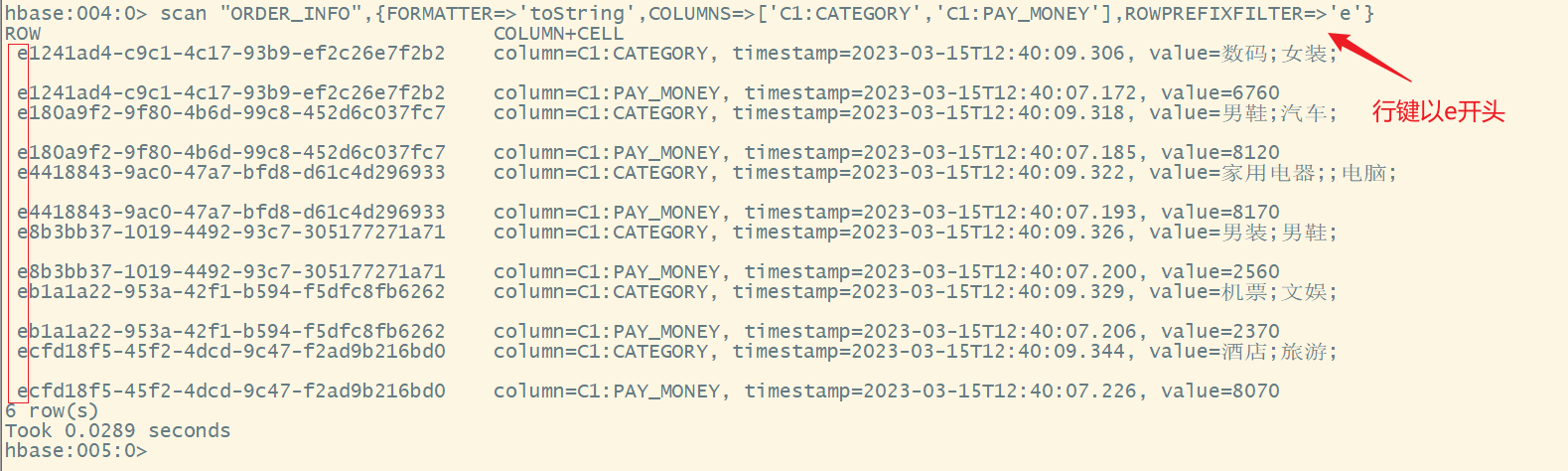
4.限定rowkey
语法:
scan ‘表名’,{FORMATTER=>'toString',ROWPREFIXFILTER=>’rowkey一部分’}
scan "ORDER_INFO",{FORMATTER=>'toString',COLUMNS=>['C1:CATEGORY','C1:PAY_MONEY'],ROWPREFIXFILTER=>'e'}
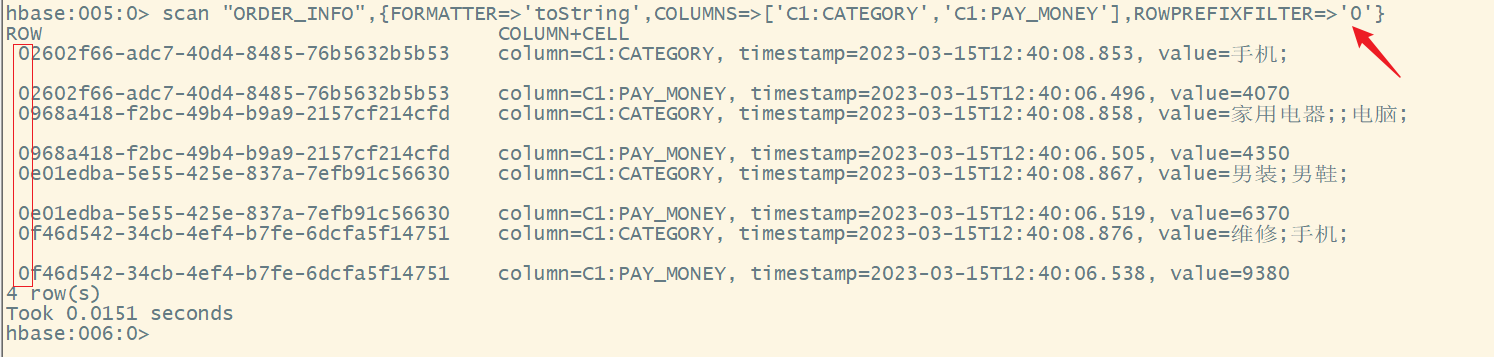
八、HBase的过滤器
1.简介
在HBase中,如果要对海量的数据进行扫描查询,尤其是全表扫描效率很低,可以使用过滤器Filter来提高查询的效率。过滤器Filter可以根据主键、列簇、列、版本号(时间戳)等条件对数据进行查询过滤。
在HBase中,使用过滤器有两种方式,一种就是使用命令行基于jRubby语法的选项实现交互式查询,另一种是基于HBase的JAVA API的方式进行编程开发。
官网文档:https://hbase.apache.org/devapidocs/index.html
2.过滤器
可以通过show_filters命令,查看hbase内置的过滤器
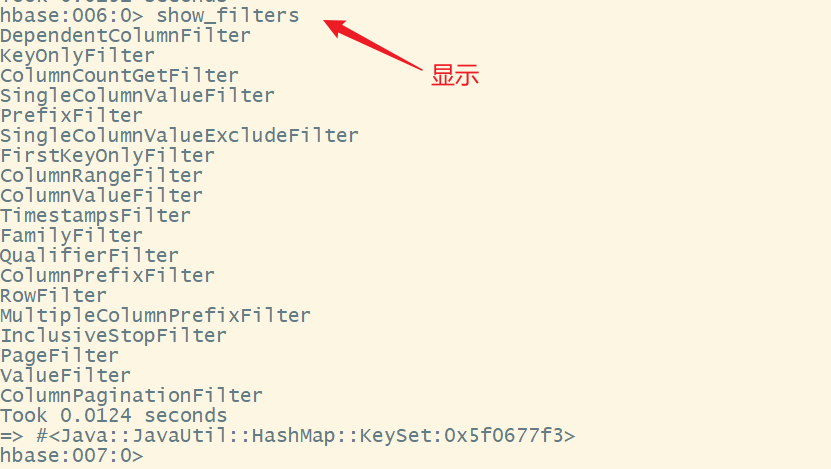
我们来解释一下这些过滤器的用法:
| 类型 | 过滤器 | 功能 |
|---|---|---|
| rowkey过滤器 | RowFilter | 实现行键字符串的比较和过滤 |
| PrefixFilter | rowkey的前缀过滤器 | |
| KeyOnlyFilter | 只对单元格的键过滤不显示值 | |
| FirstKeyOnlyFilter | 只扫描显示相同键的第一个单元格,其对应的键值会显示出来 | |
| 列过滤器 | FamilyFilter | 列簇过滤器 |
| QualifierFilter | 列限定符过滤器,只显示对应列簇列名的数据 | |
| ColumnPrefixFilter | 对列名的前缀进行限定 | |
| MultipleColumnPrefixFilter | 对多个列名的前缀进行限定 | |
| ColumnRangeFilter | 列名称范围的过滤器 | |
| 值过滤器 | ValueFilter | 值过滤器,查询符合条件的键值对 |
| SingleColumnValueFilter | 对单个值进行过滤 | |
| ColumnValueFilter | 列值的过滤器 | |
| SingleColumnValueExcludeFilter | 排除匹配成功的值 | |
| 其他过滤器 | ColumnPaginationFilter | 列分页过滤器,返回offset、limit的列 |
| PageFilter | 分页过滤器,分页显示 | |
| TimestampsFilter | 时间戳过滤器 | |
| ColumnCountGetFilter | 限制每个逻辑行返回值对的个数 | |
| DependentColumnFilter | 依赖列过滤器 | |
3.过滤器的用法
过滤器一般结合scan来使用
scan "ORDER_INFO",{FORMATTER=>'toString',FILTER=>"RowFilter(=,'binary:02602f66-adc7-40d4-8485-76b5632b5b53')"}

一般语法:
scan ‘表名’,{FILTER=>”过滤器的名称(参数列表(如比较运算符,比较器))”}
1)比较运算符
比较运算符是我们比较常见的。
| 运算符 | 功能 |
|---|---|
| = | 等于 |
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
| != | 不等于 |
2)比较器
| 比较器 | 功能 |
|---|---|
| BinaryComparator | 匹配完整的字节数组 |
| BinaryPrefixComparator | 匹配字节数组的前缀 |
| BitComparator | 匹配比特位 |
| NullComparator | 匹配空值 |
| RegexStringComparator | 匹配正则表达式 |
| SubstringComparator | 匹配子字符串 |
3)比较器表达式
| 比较器 | 表达式缩写 |
|---|---|
| BinaryComparator | binary:值 |
| BinaryPrefixComparator | binaryprefix:值 |
| BitComparator | bit:值 |
| NullComparator | null |
| RegexStringComparator | regexstring:正则表达式 |
| SubstringComparator | substring:值 |
4.案例一:查询指定订单id的数据
1)需求
查询指定订单的数据,订单号为“e8b3bb37-1019-4492-93c7-305177271a71”,订单状态及支付方式
2)分析
- 因为订单id就说表的rowkey,所以应该使用rowkey过滤器RowFilter
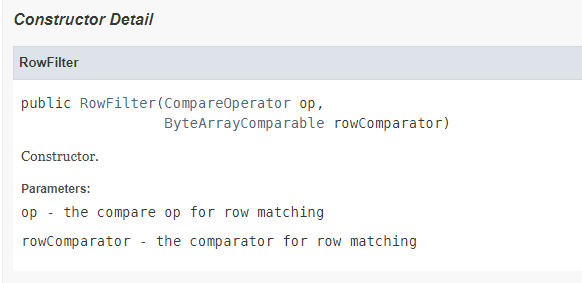
只需要两个参数
- 比较运算符:=
- 比较器表达式:binary:订单号
3)实现
scan 'ORDER_INFO',{FORMATTER=>'toString',COLUMNS=>['C1:STATUS','C1:PAYWAY'],FILTER=>"RowFilter(=,'binary:e8b3bb37-1019-4492-93c7-305177271a71')"}

5.案例二:查询状态为已付款的订单
1)需求
查询状态为已付款的订单
2)分析
- 因为查询状态为已付款要查询指定值,所以应该使用值过滤器SingleColumnValueFilter
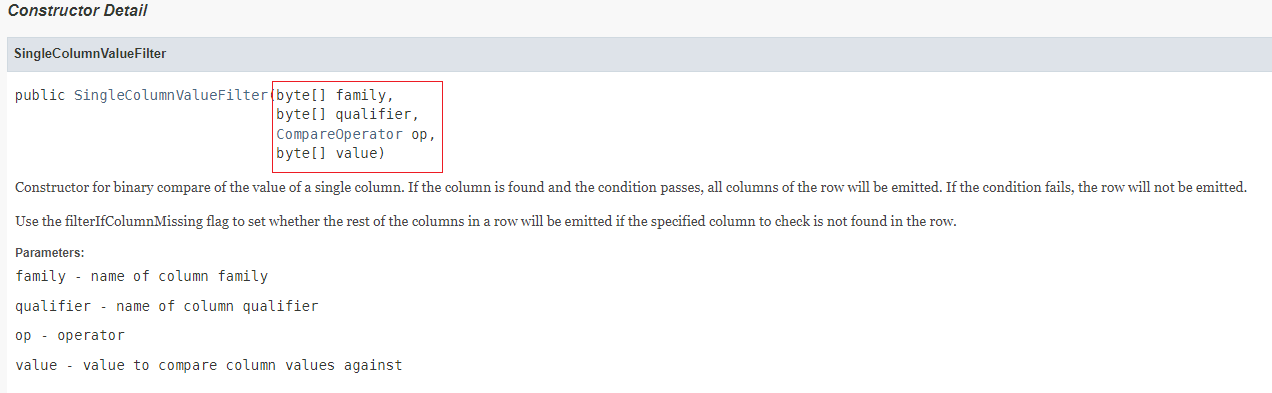
需要传入四个参数
- 列簇
- 列名
- 比较运算符
- 比较器表达式
scan 'ORDER_INFO',{FORMATTER=>'toString',FILTER=>"SingleColumnValueFilter('c1','STATUS',=,'binary:已付款')"}
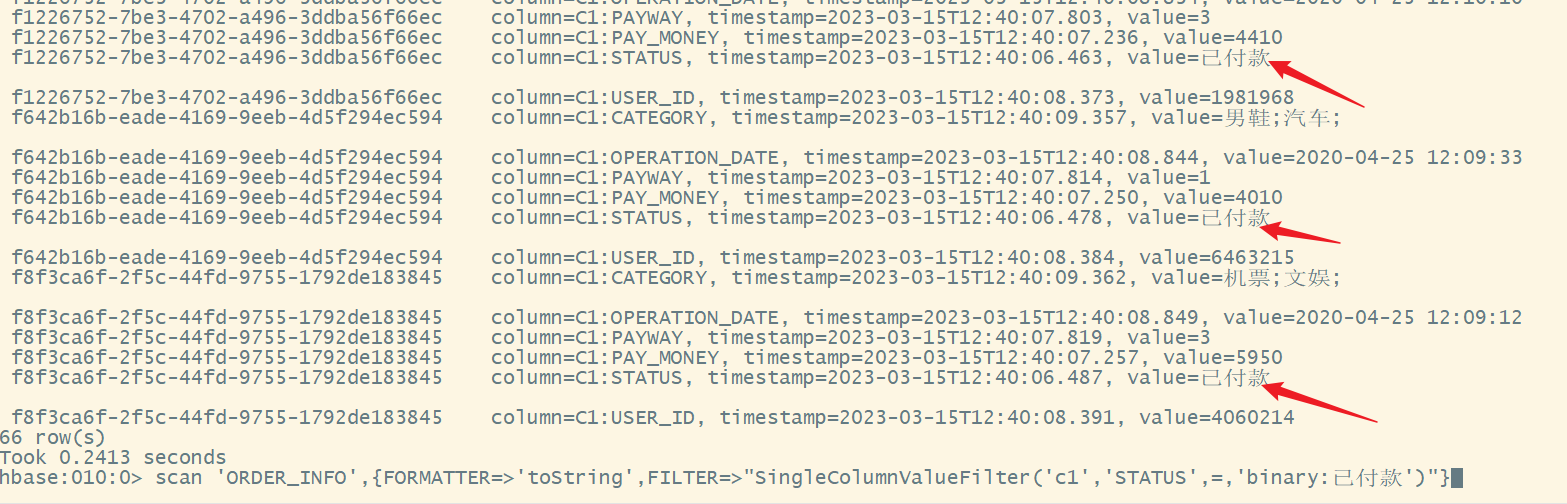
注意:
- 列簇名和列名大小写一定要写对
- 如果列簇名和列名大小写写错并不能过滤数据,但是HBase不会报错,而是显示全部的数据,因为HBase是无模式的
6.案例三:组合多条件过滤1
1)需求
查询支付方式为1,且支付金额大于8000的订单
2)分析
- 此处需要使用多个过滤器共同来实现查询,多个过滤器,可以使用AND(并且)或者OR(或者)来组合多个过滤器完成查询
- 使用SingleColumnValueFilter实现对应列的查询
- 支付方式为1的过滤器
SingleColumnValueFilter('C1', 'PAYWAY', = , 'binary:1')
- 支付金额大于8000的过滤器
SingleColumnValueFilter('C1', 'PAY_MONEY', > , 'binary:8000')
- 完整的命令
scan 'ORDER_INFO', {FORMATTER => 'toString',FILTER => "SingleColumnValueFilter('C1', 'PAYWAY', = , 'binary:1') AND SingleColumnValueFilter('C1', 'PAY_MONEY', > , 'binary:8000')"}

注意:
- HBase shell中比较默认都是字符串比较,所以如果是比较数值类型的,会出现不准确的情况
- 例如:在字符串比较中4000是比100000大的
- 外层必须使用双引号,内层使用单引号
我们还可以加上限定列:
scan 'ORDER_INFO', {FORMATTER => 'toString',FILTER => "SingleColumnValueFilter('C1', 'PAYWAY', = , 'binary:1') AND SingleColumnValueFilter('C1', 'PAY_MONEY', > , 'binary:8000')",COLUMNS=>['C1:PAYWAY','C1:PAY_MONEY']}

7. 案例四:组合多条件过滤2
1)需求
查询类别为“维修;手机;”或者“数码;女装;”,并且状态为“已付款”的订单,只显示类别和状态
2)分析
- 此处需要使用多个过滤器组合使用,多个过滤器可以使用AND(并且)、OR(或者)来进行组合
- 使用值过滤器中的SingleColumnValueFilter实现对应列值的查询
完整的命令
scan 'ORDER_INFO', {FORMATTER => 'toString',FILTER => "(SingleColumnValueFilter('C1', 'CATEGORY', = , 'binary:维修;手机;') OR SingleColumnValueFilter('C1', 'CATEGORY', = , 'binary:数码;女装;')) AND SingleColumnValueFilter('C1', 'STATUS', =, 'binary:已付款')",COLUMNS=>['C1:CATEGORY','C1:STATUS']}
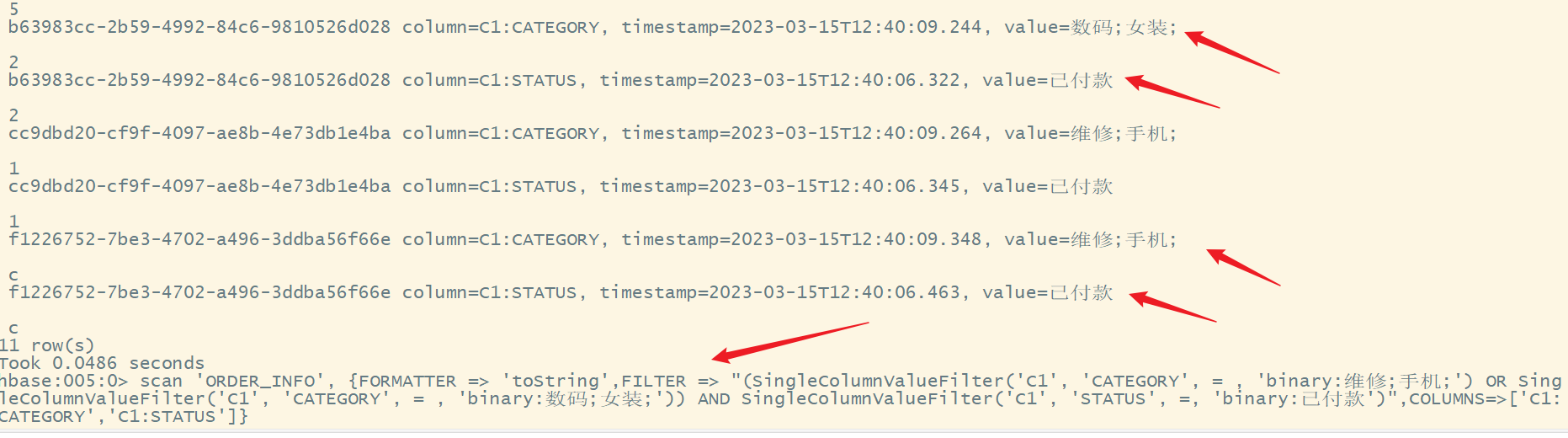
8.作业
选择操作时间在2020-04-25,12点8分到9分之间的已完成的订单,只显示操作时间和状态
scan 'ORDER_INFO', {FORMATTER => 'toString',FILTER => "SingleColumnValueFilter('C1', 'OPERATION_DATE', > , 'binary:2020-04-25 12:08:00') AND SingleColumnValueFilter('C1', 'OPERATION_DATE', = , 'binary:2020-04-25 12:09:00')",COLUMNS=>['C1:OPERATION_DATE','C1:STATUS']}

九、INCR
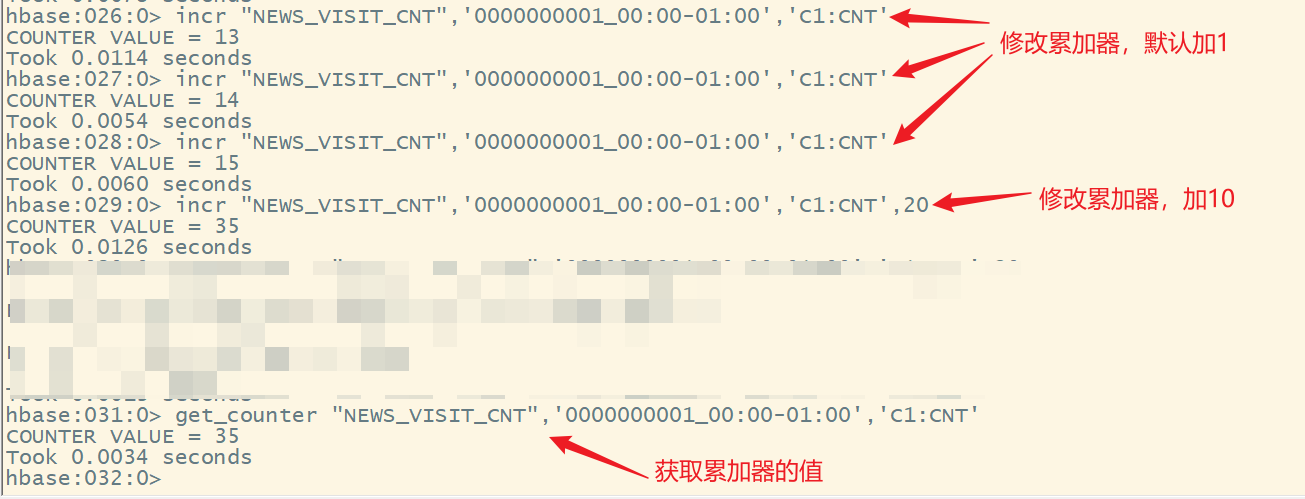
incr(increament)命令可以实现某个单元格的值进行原子性计数累加,默认累加1
1. 需求
某新闻app应用为了统计每个新闻的每隔一段时间的访问次数,将新闻数据保存在HBase中,该表格的数据如下所示,要求原子性的增加新闻的访问次数
| 新闻ID | 访问次数 | 时间段 | rowkey |
|---|---|---|---|
| 0000000001 | 12 | 00:00-01:00 | 0000000001_00:00-01:00 |
| 0000000002 | 20 | 01:00-02:00 | 0000000002_01:00-02:00 |
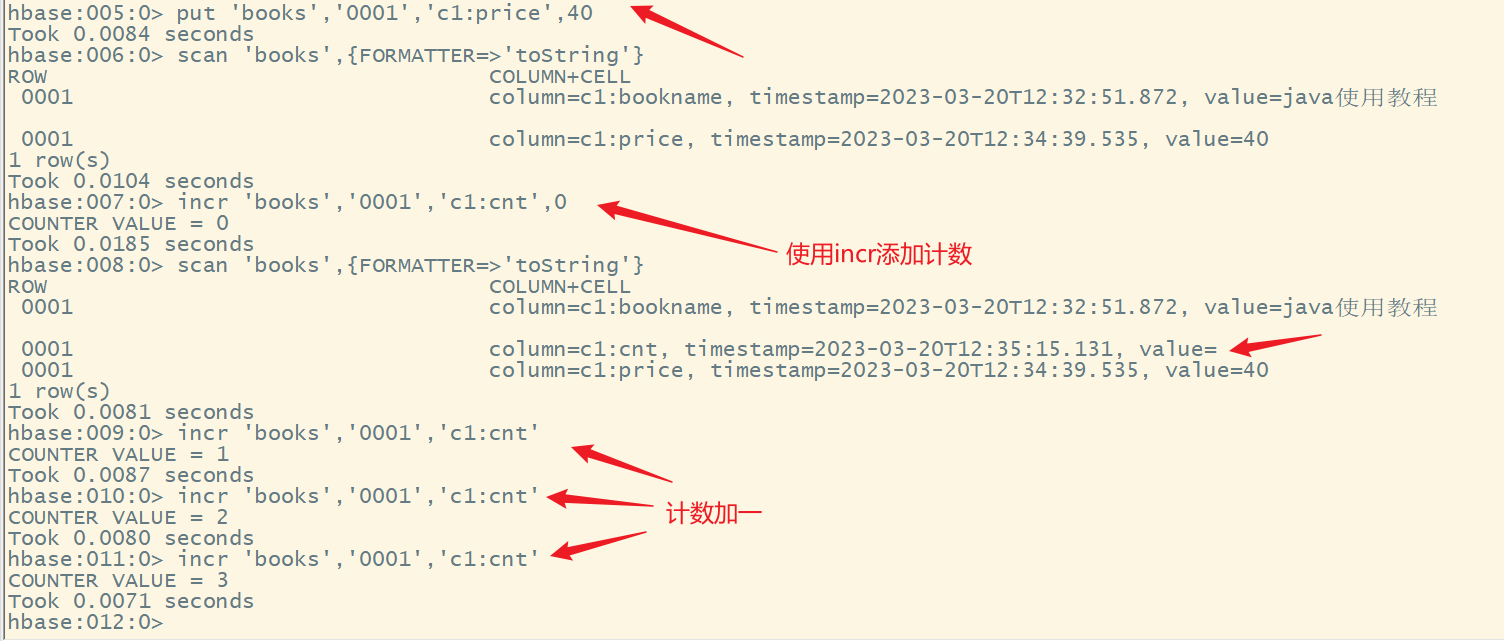
2. incr操作
语法:
incr ‘表名’,‘rowkey’,‘列簇名:列名’,[累加值]
说明:
- 如果某一列要实现计数功能,必须要使用incr来创建对应的列
- 使用put创建的额列是不能实现累加的
- 默认累加1
3.基本使用


4.导入准备好的数据
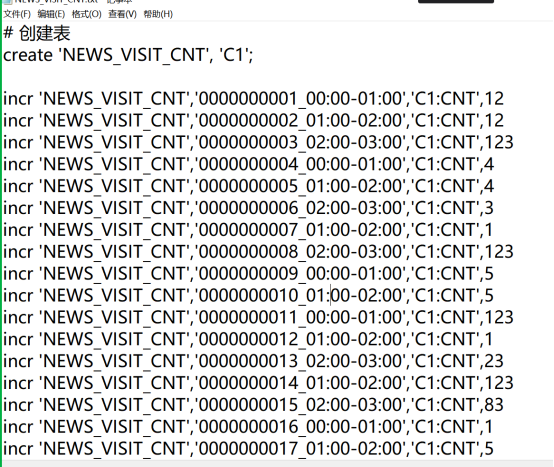
上传服务器
导入HBase
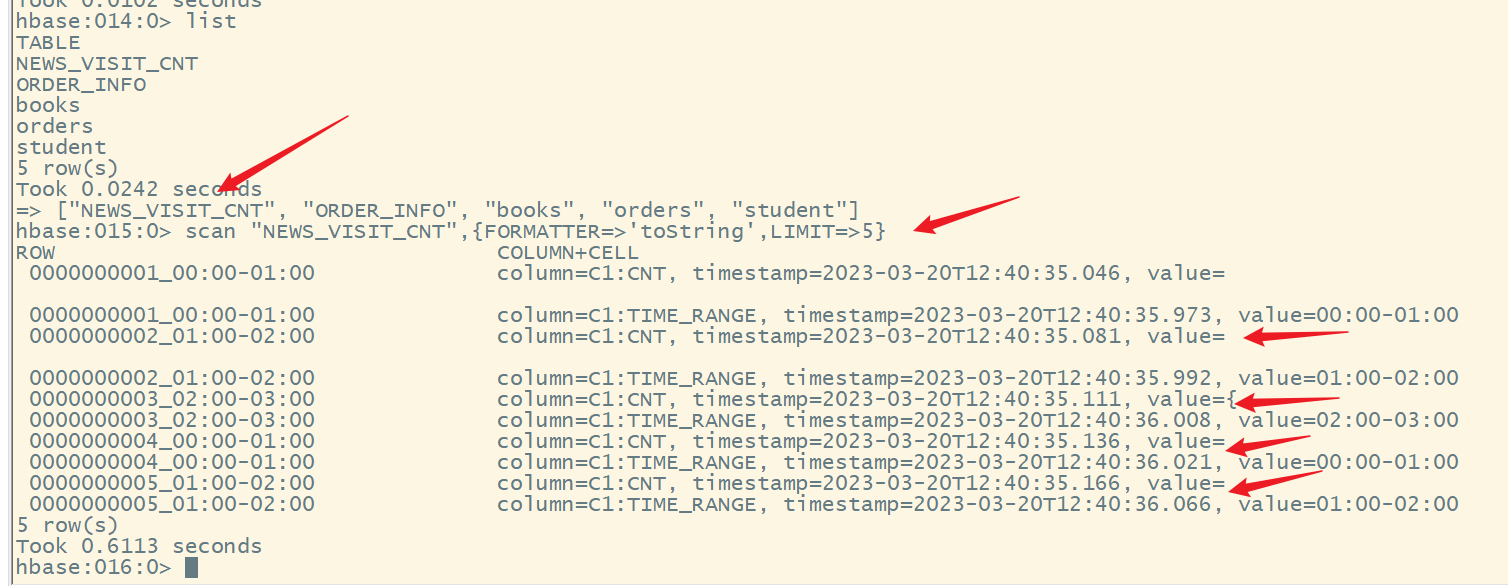
显示前5条数据
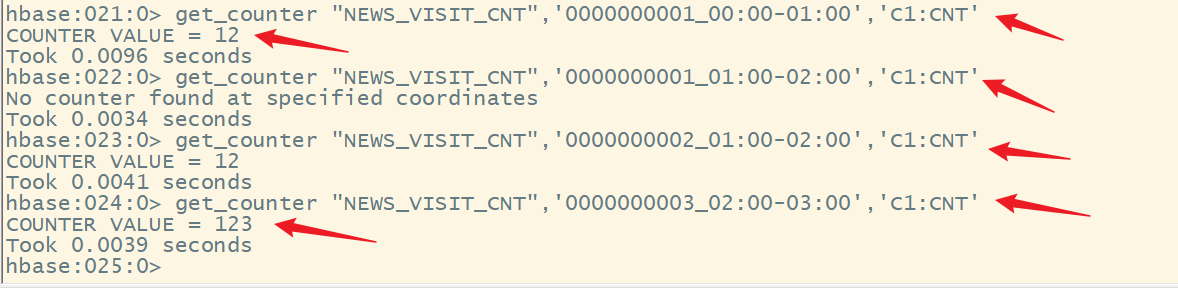
5.获取计数器值的命令
不能使用get来获取计数器的值
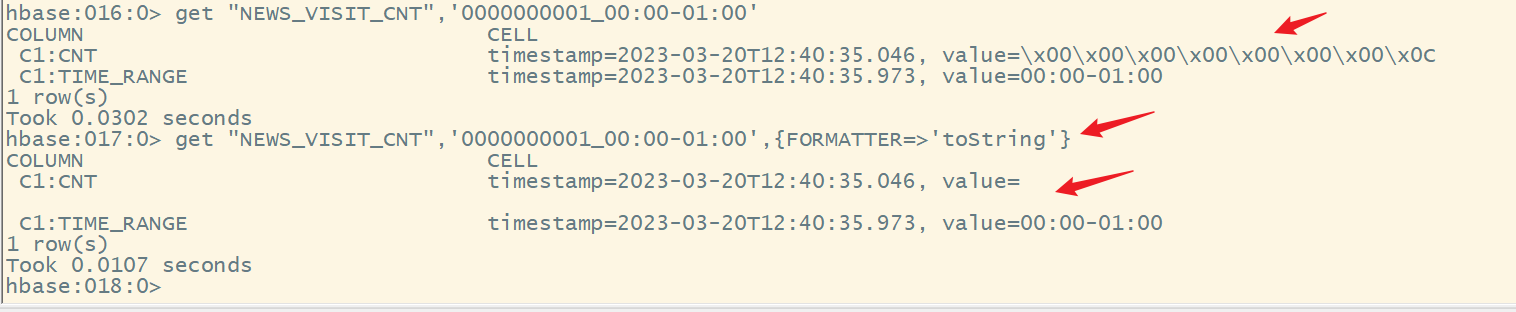
语法:
get_counter ‘表名’,‘rowkey’,‘列簇名:列名’

6.使用incr进行累加操作,修改计数器的值

十、Shell管理操作
1.status
查看服务器的状态

2.whoami
显示当前用户
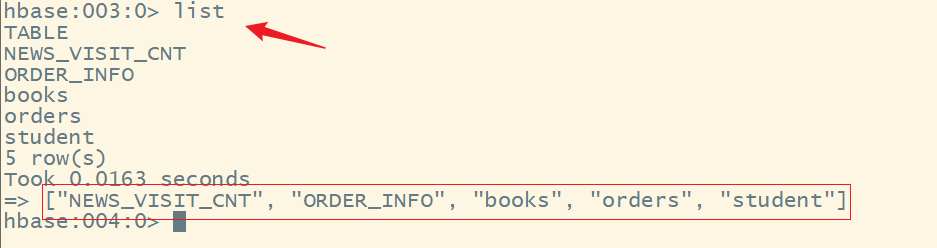
3.list
显示当前的所有的表
4.count
统计表的记录数

5.describe
显示表的结构信息

6.exists
判断某个表是否存在
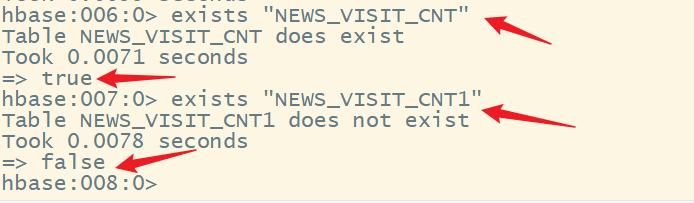
7.is_enabled、is_disabled
判断某个表是否被启用或者禁用
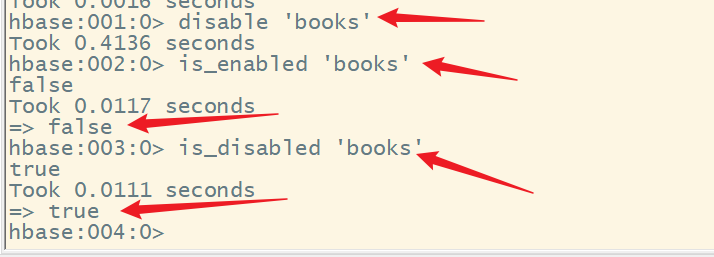
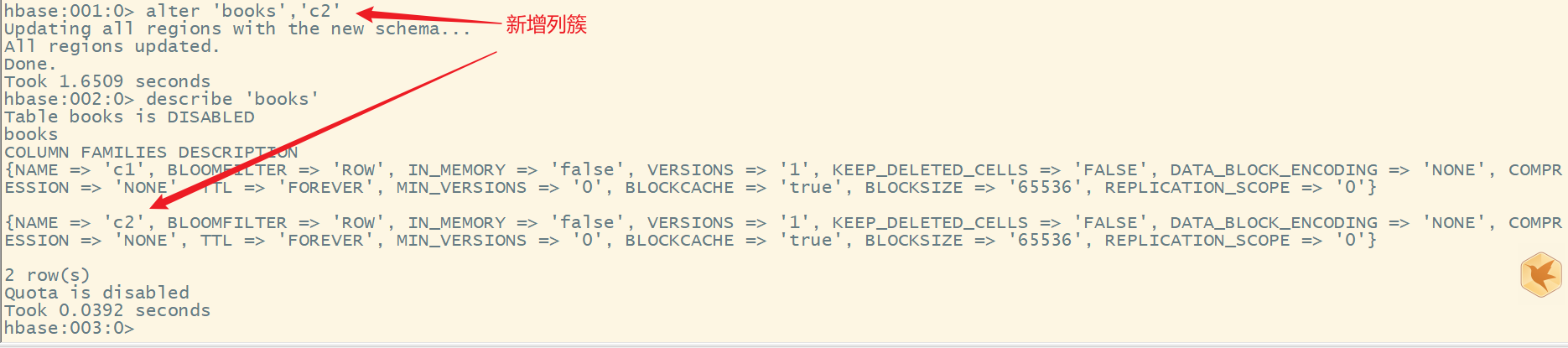
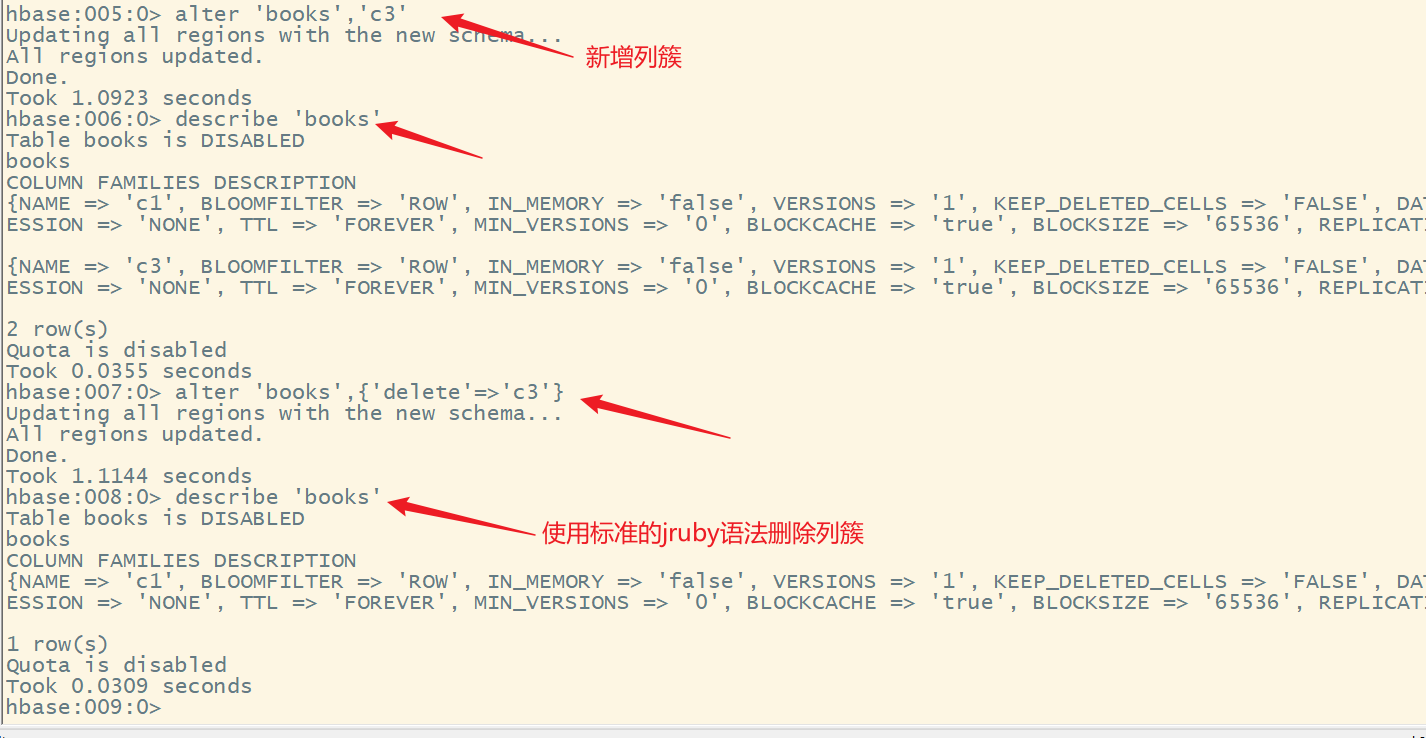
8.alter
改变表和列簇的模式
- 新增列簇
- 删除列簇

参考文章
HBASE官网文档
相关文章:
HBase高手之路4-Shell操作
文章目录HBase高手之路3—HBase的shell操作一、hbase的shell命令汇总二、需求三、表的操作1.进入shell命令行2.创建表3.查看表的定义4.列出所有的表5.删除表1)禁用表2)启用表3)删除表四、数据的操作1.添加数…...

聊聊SQL审计功能
什么是sql审计SQL审计是指对SQL语句的执行情况进行记录和追踪,包括SQL语句的执行时间、执行次数、执行结果等信息。通过SQL审计,可以对数据库的使用情况进行监控和管理,包括对SQL注入、非法访问、数据泄露等安全问题的检测和防范,…...
)
Markdown常用语法(字体颜色)
一些不错的帖子 写CSDN博客时,调节字体大小、颜色及其他样式的常用操作方法 设置字体颜色 使用<font>标记: 这是红色字体:<font colorred>我是红色的字体</font>显示效果如下: 这是红色字体:我是…...
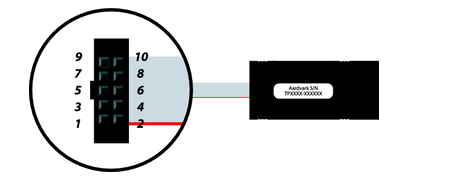
I2C模块理解
I2C模块理解 文章目录I2C模块理解1.配置I2C2.信号3.数据传输3.1主机发送3.2主机接收3.3从机发送3.4从机接收4.中断传输5.Aardvark1.配置I2C I2C的特征 只需要两条公共总线(线)即可控制I2C网络上的任何设备无需像UART通信那样事先约定数据传输速率。因此…...

手把手教你使用--常用模块--HC05蓝牙模块,无线蓝牙串口透传模块,(实例:手机蓝牙控制STM32单片机点亮LED灯)
最近在学STM32,基本的学完了,想学几个模块来巩固一下知识,就想到了蓝牙模块。玩啥好难过有很多博客教怎么连的,但自己看起来还是有点糊涂。模块的原理和知识点我就不讲解了,这里我主要手把手记录一下我是如何对蓝牙模块…...

MyBatis高频面试题
目录 1、Mybatis中#和$的区别 2、Mybatis的编程步骤是什么样的 3...
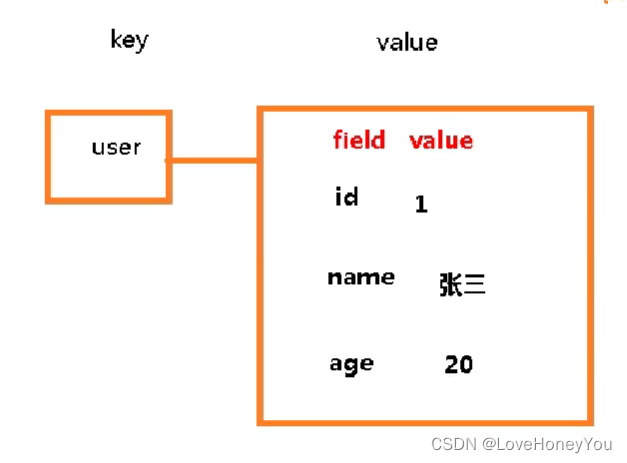
Redis基础篇
redis的三大特点: 支持多数据类型,支持持久化,单线程 多路IO复用 对键操作的命令: keys * 查看当前库所有key exists key 判断key是否存在 del key 删除 unlink key 非阻塞删除,异步删除 expire key …...

unity的C#学习——静态常量和动态常量的定义与使用
定义常量 在C#中,常量是一种不可改变的量,一旦被定义,其值就不能被修改。C#中有两种类型的常量,静态常量和动态常量。 1、静态常量的定义 静态常量是在编译时就已经确定其值的常量,使用const关键字定义。由于在编译…...
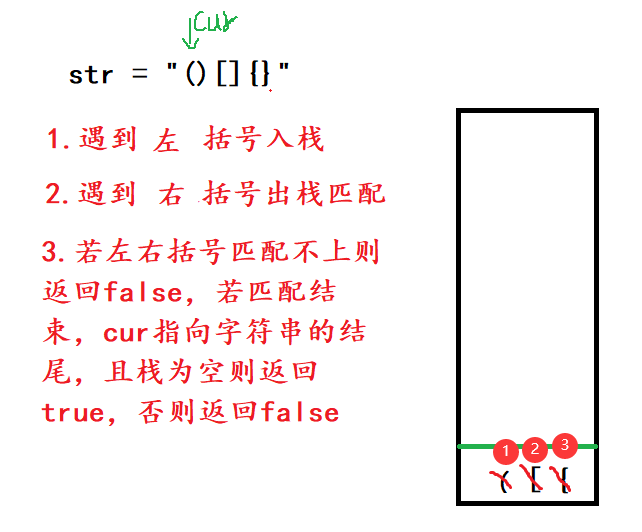
栈----数据结构
栈🔆栈的概念🔆栈的结构🔆栈的实现🔆括号匹配问题🔆结语🔆栈的概念 栈:一种特殊的线性表,其只允许在固定的一端进行插入和删除元素操作。**进行数据插入和删除操作的一端称为栈顶&am…...
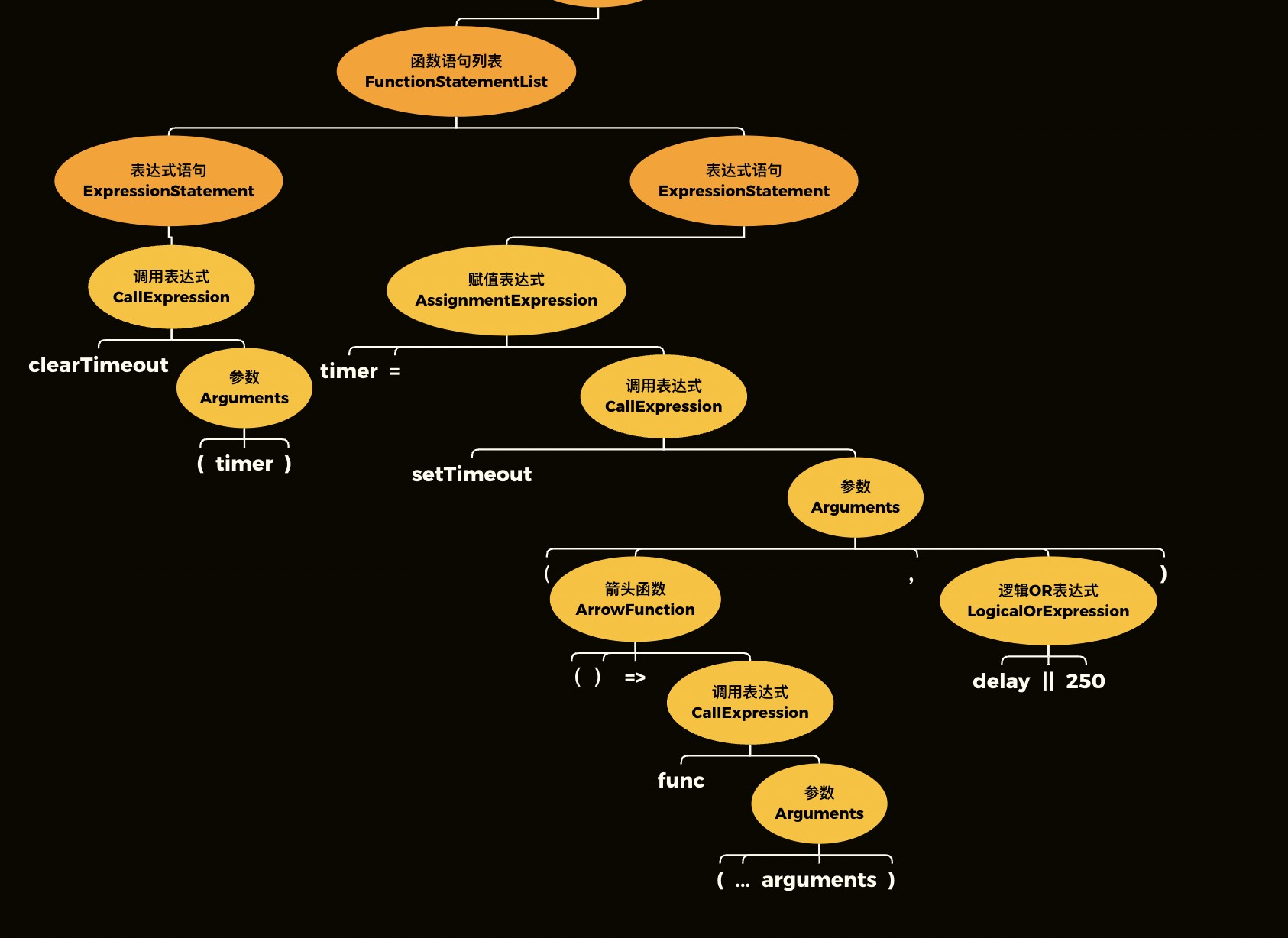
【人人都能读标准】11. 原理篇总结:一个程序的完整执行过程
本文为《人人都能读标准》—— ECMAScript篇的第11篇。我在这个仓库中系统地介绍了标准的阅读规则以及使用方式,并深入剖析了标准对JavaScript核心原理的描述。 我们一路走了很远很远,终于到了本书原理篇的最后一站。 在原理篇中,我们先讲了…...
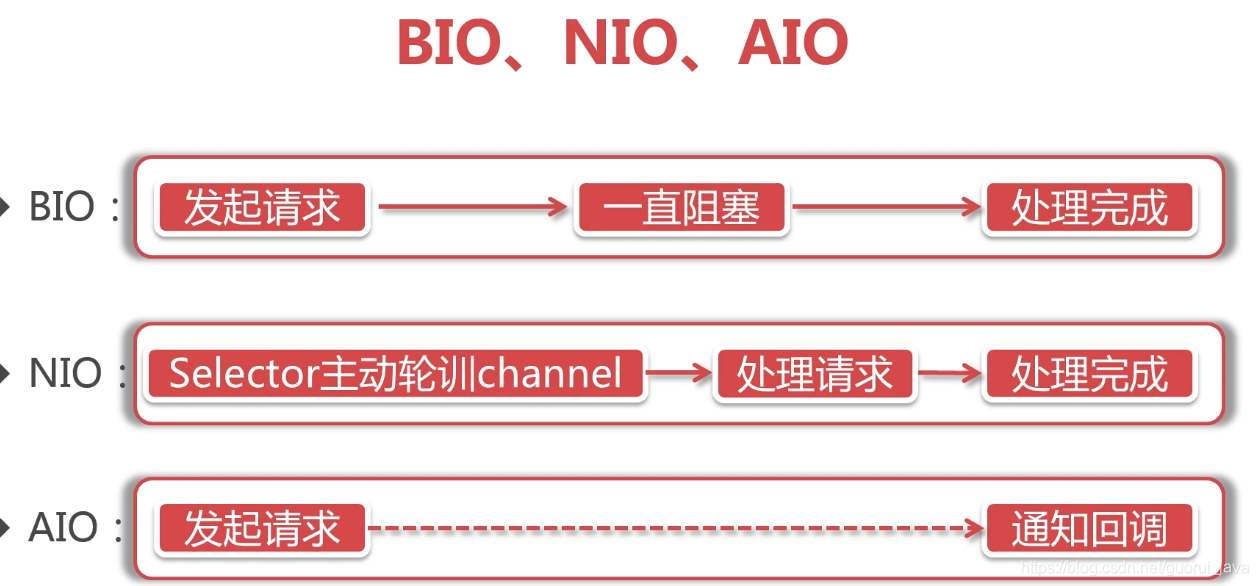
sheng的学习笔记-IO多路复用,NIO,BIO,AIO
基础概念IO分为几种:同步阻塞的BIO,同步非阻塞的NIO,异步非阻塞AIO,IO多路复用,信号驱动IO(不常用)对于一个network IO,它会涉及到两个系统对象,一个是调用这个IO的proce…...
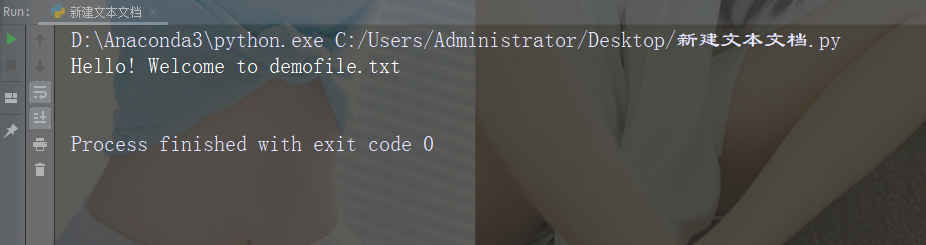
【Python入门第三十五天】Python丨文件打开
在服务器上打开文件 假设我们有以下文件,位于与 Python 相同的文件夹中。 demofile.txt Hello! Welcome to demofile.txt This file is for testing purposes. Good Luck!如需打开文件,请使用内建的 open() 函数。 open() 函数返回文件对象ÿ…...
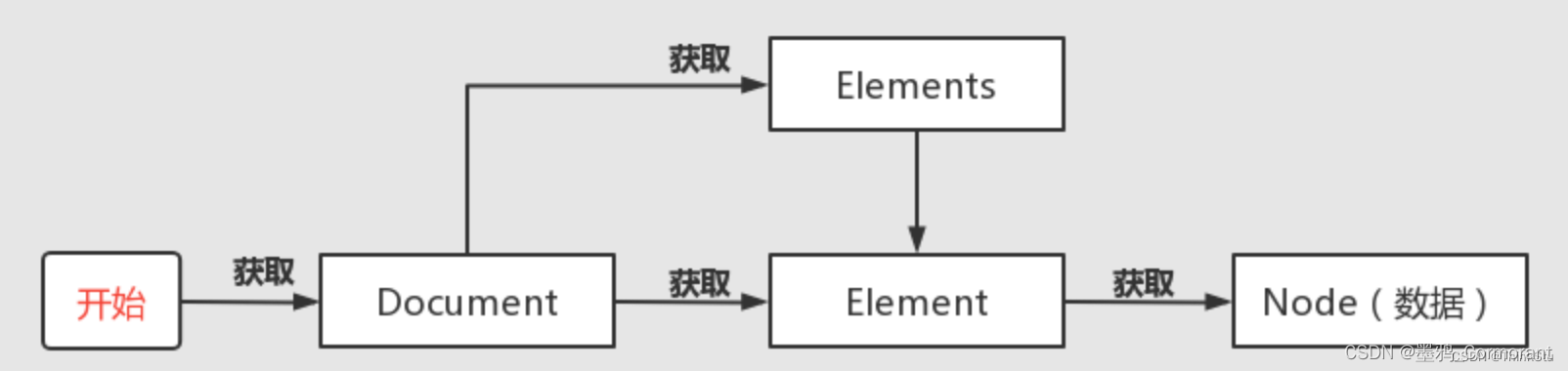
jsoup 框架的使用指南
概述 参考: 官方文档jsoup的使用JSoup教程jsoup 在 GitHub 的开源代码 概念简介 jsoup 是一款基于 Java 的 HTML 解析器,它提供了一套非常省力的 API,不但能直接解析某个 URL 地址、HTML 文本内容,而且还能通过类似于 DOM、CS…...

web前端开发和后端开发哪个难度大?
前言 因为涉及到的具体的应用的领域不同,所以说不能简单地说哪一个难,对于前端而言你会感觉到入门会非常的简单,这也是会给许多人一种错觉,前端很简单,但是只能说是在入门理解上是有利于新手的,前端在主要…...

认证与认可之间有什么区别和联系?
认证与认可之间有什么区别和联系? 当今社会,认证与认可已经深入企业的生活,那么认证与认可之间到底有什么区别和联系呢? 认证,是指由认证机构证明产品、服务、管理体系符合相关技术规范、相关技术规范的强制性要求或者…...

【Java|golang】1626. 无矛盾的最佳球队---最长子序列,不连续,二维数组排序
假设你是球队的经理。对于即将到来的锦标赛,你想组合一支总体得分最高的球队。球队的得分是球队中所有球员的分数 总和 。 然而,球队中的矛盾会限制球员的发挥,所以必须选出一支 没有矛盾 的球队。如果一名年龄较小球员的分数 严格大于 一名…...
)
C++ 八股文(简单面试题)
1.左值 可寻址变量,持久性; 2.右值 没有变量名,不可寻址,短暂性; 3.指针 指向的内存地址,指针变量存储的就是指向的对象的首地址 4.引用 为一个变量起别名,定义引用的时候一定要初始化&a…...

RK3588平台开发系列讲解(显示篇)DP显示调试方法
平台内核版本安卓版本RK3588Linux 5.10Android 12文章目录 一、查看 connector 状态二、强制使能/禁⽤ DP三、DPCP 读写四、Type-C 接口 Debug五、查看 DP 寄存器六、查看 VOP 状态七、查看当前显示时钟八、调整 DRM log 等级沉淀、分享、成长,让自己和他人都能有所收获!😄…...

模拟请求发生跨域问题
参考:传送门 问题产生: Access to XMLHttpRequest at ‘http://test-cms.jinhuahuolong.com/api/pages/list’ from origin ‘null’ has been blocked by CORS policy: No ‘Access-Control-Allow-Origin’ header is present on the requested resourc…...
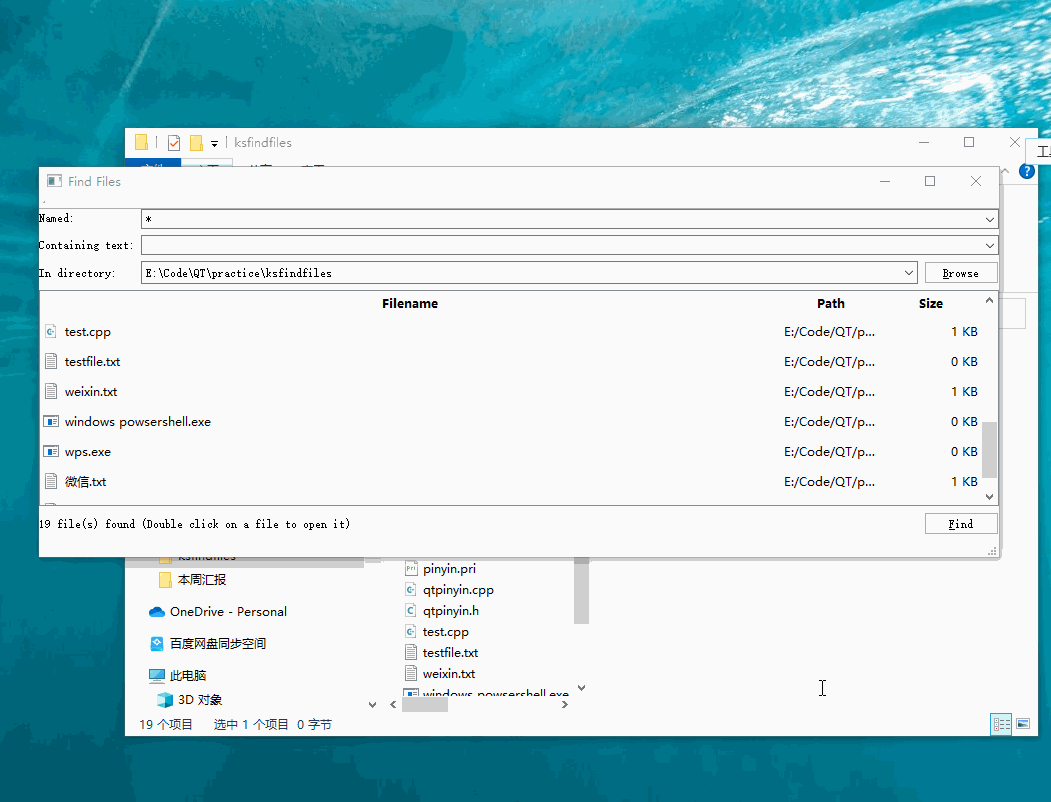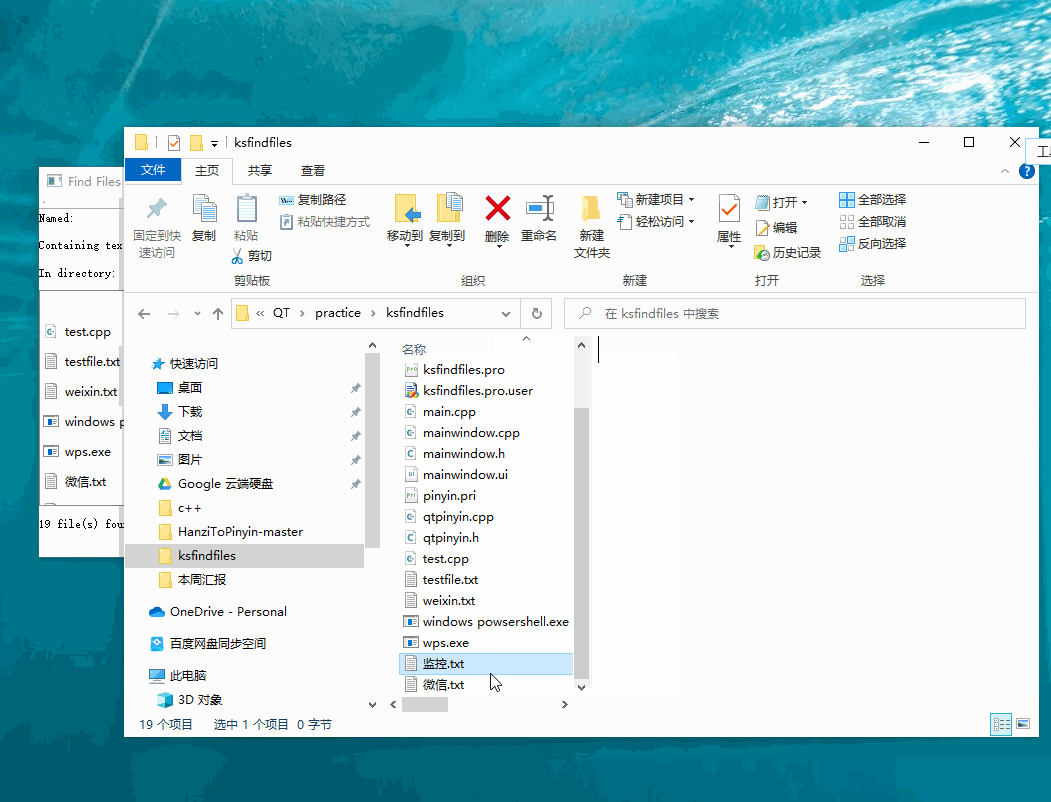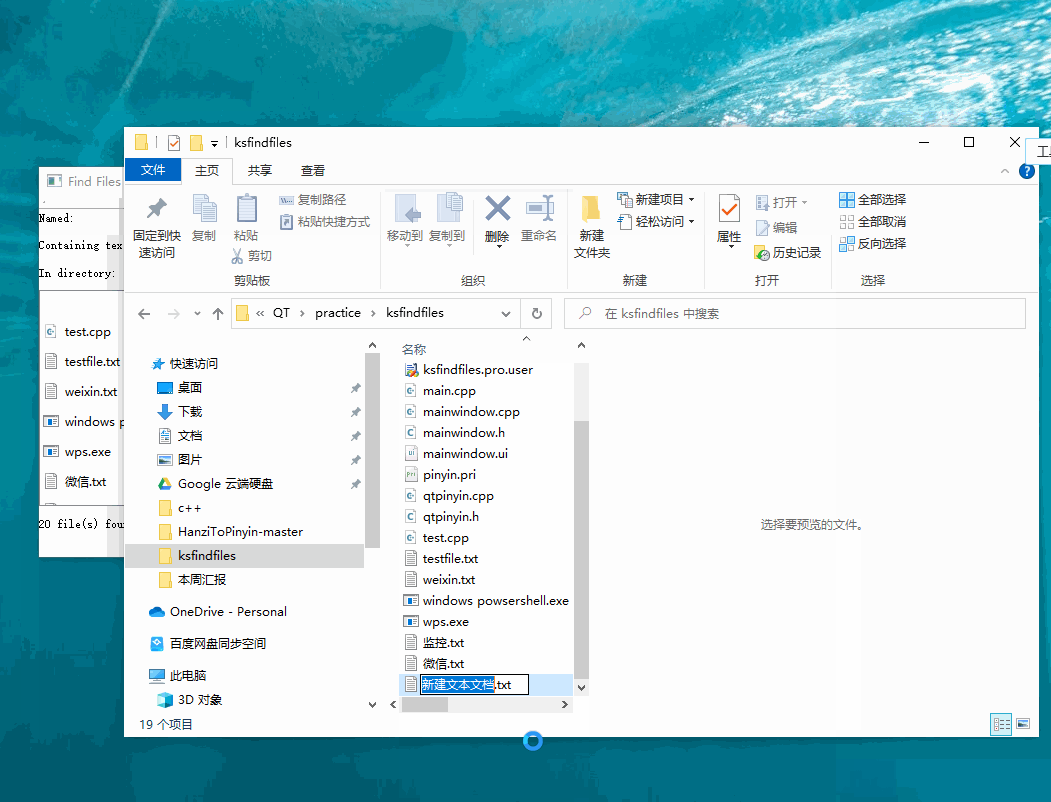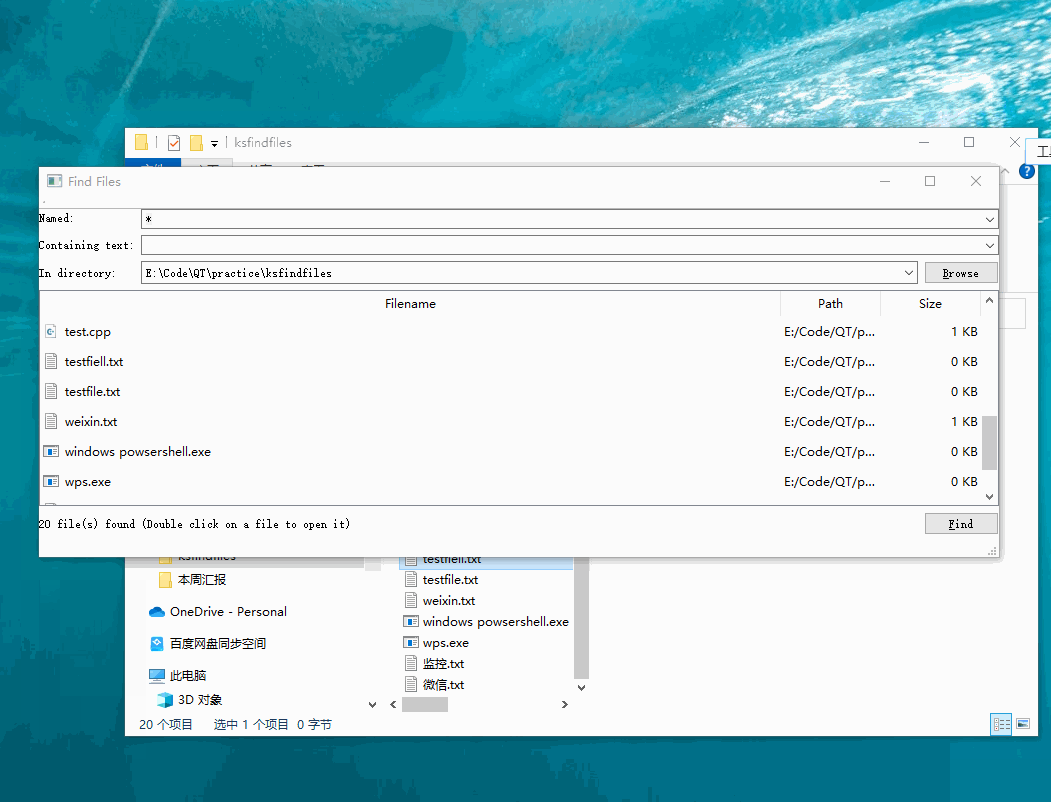
Qt实践项目:仿Everything软件实现一个QtEverything
⭐️我叫忆_恒心,一名喜欢书写博客的在读研究生👨🎓。 如果觉得本文能帮到您,麻烦点个赞👍呗! 近期会不断在专栏里进行更新讲解博客~~~ 有什么问题的小伙伴 欢迎留言提问欧,喜欢的小伙伴给个三…...

Buildah容器调试终极指南:10个实用技巧快速解决构建问题
Buildah容器调试终极指南:10个实用技巧快速解决构建问题 【免费下载链接】buildah A tool that facilitates building OCI images. 项目地址: https://gitcode.com/gh_mirrors/bu/buildah Buildah是一个强大的开源工具,专门用于构建符合OCI标准的…...

淘宝淘金币自动化脚本:每天节省20分钟的终极解决方案
淘宝淘金币自动化脚本:每天节省20分钟的终极解决方案 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/ta/taojinbi 淘宝淘…...

RVC与VITS技术对比:检索式vs端到端语音转换的适用场景分析
RVC与VITS技术对比:检索式vs端到端语音转换的适用场景分析 1. 引言 你有没有想过,为什么有些AI翻唱听起来特别像原唱,而有些则感觉“味儿”不太对?或者,为什么有些语音转换工具训练起来飞快,但效果时好时…...

BGE-Reranker-v2-m3批量处理优化:提升高并发排序效率
BGE-Reranker-v2-m3批量处理优化:提升高并发排序效率 你是不是也遇到过这样的问题?在搭建RAG系统时,向量检索返回了一大堆文档,但真正相关的却没几个。大模型拿着这些“噪音”文档生成答案,结果要么答非所问ÿ…...

Simple Comic:Mac平台的开源漫画阅读解决方案
Simple Comic:Mac平台的开源漫画阅读解决方案 【免费下载链接】Simple-Comic OS X comic viewer 项目地址: https://gitcode.com/gh_mirrors/si/Simple-Comic 你是否曾遇到这样的困扰:在Mac上尝试打开漫画文件时,不是格式不兼容就是阅…...

政务短信钓鱼攻击机理与防控研究 —— 以美国宾州 PennDOT 诈骗事件为例
摘要 2026 年 3 月 27 日,宾夕法尼亚州官方发布安全预警,提示公众警惕冒充 PennDOT(宾州交通局)的短信钓鱼诈骗。此类攻击以车辆管理、罚单缴费、证件状态异常为诱饵,通过仿冒政务身份诱导用户点击恶意链接,…...

Realistic Vision V5.1显存占用对比:启用offload前后VRAM峰值下降62%实测
Realistic Vision V5.1显存占用对比:启用offload前后VRAM峰值下降62%实测 1. 项目背景与技术特点 Realistic Vision V5.1是目前Stable Diffusion 1.5生态中最顶级的写实风格模型之一,能够生成媲美专业单反相机拍摄的人像作品。然而在实际使用中&#x…...

用Isaac Sim的Action Graph给ROS2机器人发布激光雷达数据:一个完整的传感器仿真流程
用Isaac Sim的Action Graph实现ROS2激光雷达数据仿真:从传感器配置到RViz可视化的全流程指南 在机器人开发和自动驾驶系统测试中,高保真的传感器仿真能够显著降低硬件成本和迭代周期。NVIDIA Isaac Sim作为一款强大的机器人仿真平台,与ROS2生…...
)
Vue3实战:5分钟搞定全局WebSocket封装(含心跳检测与断线重连)
Vue3全局WebSocket封装实战:心跳检测与断线重连的最佳实践 WebSocket在现代Web应用中扮演着越来越重要的角色,特别是在需要实时数据更新的场景中。Vue3作为当前最流行的前端框架之一,与WebSocket的结合能够为开发者提供强大的实时交互能力。本…...

RexUniNLU新手入门指南:3步搞定智能家居、金融、医疗场景意图识别
RexUniNLU新手入门指南:3步搞定智能家居、金融、医疗场景意图识别 1. 认识RexUniNLU:零样本意图识别利器 RexUniNLU是一款基于Siamese-UIE架构的轻量级自然语言理解框架,它能让你无需准备标注数据,仅通过简单的标签定义就能完成…...