什么是NLP分词(Tokenization)
在自然语言处理和机器学习的领域里,咱们得聊聊一个超基础的技巧——就是“分词”啦。这个技巧啊,就是把一长串的文字切分成小块,让机器能更容易地“消化”。这些小块,不管大小,单个的字符也好,整个的单词也罢,都叫“分词”。为啥这么重要呢?因为这样一弄,机器就能把那些绕口的长句子变成一小段一小段的,这样分析起来就容易多了。简单来说,分词就是帮机器把人类的语言拆成它能理解的小块块,让它们能更好地跟我们交流。

分词解释
在自然语言处理(NLP)和机器学习领域,分词是一项关键技术,它涉及将文本分解为更小的单元,这些单元被称作“分词”。分词的规模可从单个字符到整个单词不等。这一过程至关重要,因为它通过将文本拆解为机器易于分析的小单元,帮助机器更好地理解人类的语言。
可以这样想象:当你教孩子学习阅读时,你不会让他们直接阅读复杂的段落,而是先从单个字母开始,然后是音节,最终过渡到完整的单词。分词的过程与此类似,它将大量文本拆解为机器能够更轻松消化和理解的单元。
分词的核心目的在于以一种对机器有意义的方式呈现文本,同时保留其原有的上下文信息。通过将文本转换为一系列分词,算法能够更有效地识别和分析语言模式。这种模式识别对于机器理解并响应人类的输入至关重要。例如,当机器处理到单词“running”时,它不是简单地将其看作一个整体,而是将其视为一系列可以分析并赋予意义的分词单元。
分词机制
考虑这个句子:"Chatbots are helpful." 当我们采用按单词分词的方法处理时,句子被转换成一个单词列表:
["Chatbots", "are", "helpful"]
这种方法简单明了,通常以空格作为分词的界限。但如果我们采用按字符分词的方式,这个句子就会分解为:
["C", "h", "a", "t", "b", "o", "t", "s", " ", "a", "r", "e", " ", "h", "e", "l", "p", "f", "u", "l"]
这种基于字符的分词方式更为细致入微,对于某些语言或者特定的自然语言处理任务来说,这种方法尤其有其价值。
分词类型
分词技术依据文本的分解程度以及具体任务的需求而有所差异。这些技术可能包括从将文本拆分为单独的单词到将其拆分为字符,甚至是更小的单元。以下是对不同分词方法的进一步阐释:
-
单词分词:这种方法将文本拆分为独立的单词。这是最为普遍的做法,尤其适用于英语这类单词边界清晰的语言。
-
字符分词:在这种方法中,文本被划分为单独的字符。这对于没有明显单词边界的语言或是需要进行细致分析的任务(例如拼写检查)非常有帮助。
-
子词分词:这种方法介于单词分词和字符分词之间,将文本拆分为大于单个字符但小于完整单词的单元。例如,单词“Chatbots”可以被拆分为“Chat”和“bots”。这种技术对于需要组合较小单元以形成意义的语言,或是在处理自然语言处理任务中遇到的生僻单词时特别有用。
分词用例
分词是数字化领域中众多应用的基石,它赋予了机器处理和理解海量文本数据的能力。通过将文本拆分为易于管理的单元,分词技术提升了数据分析的效率和准确性。以下是一些分词技术发挥关键作用的主要场景:
-
搜索引擎:当你在如Google这样的搜索引擎中输入查询时,分词技术被用来解析你的查询。这种文本分解使得搜索引擎能够在数十亿份文档中快速筛选,为你提供最相关的搜索结果。
-
机器翻译:像Google Translate这样的翻译工具使用分词技术来切分源语言中的句子。分词后的句子片段可以被翻译,并在目标语言中重新组合,确保翻译结果能够保持原文的上下文和意义。
-
语音识别:Siri或Alexa等语音激活助手在很大程度上依赖于分词技术。当你提出问题或发出指令时,你的语音首先被转换成文本。随后,该文本经过分词处理,使得系统能够理解并响应你的请求。
通过这些应用,我们可以看到分词技术在提升机器对人类语言的理解方面起着至关重要的作用。
分词挑战
处理人类语言的复杂性、细微差别和模糊性,为分词带来了一系列独特的挑战。以下是对这些难题的深入探讨:
-
歧义性:语言本身具有模糊性。以句子“Flying planes can be dangerous.”为例,根据分词和解释的不同,这句话可以被理解为驾驶飞机这一行为本身是危险的,或者可以理解为飞行中的飞机可能构成威胁。这种歧义性可能导致截然不同的解释。
-
无明显边界的语言:有些语言,例如中文或日语,其单词之间没有明显的空格分隔,这使得分词任务变得更加复杂。在这些语言中,确定单词的起始和结束位置可能面临较大挑战。
-
特殊字符的处理:文本内容不仅限于单词,还可能包括电子邮件地址、URL或特殊符号,这些元素对分词来说可能难以处理。例如,对于"john.doe@email.com"这样的电子邮件地址,是否应该作为一个整体分词处理,还是应该在句点或"@"符号处进行分割?
为了应对这些挑战,已经开发出了高级的分词方法,如BERT分词器,它能够处理语言中的歧义问题。对于没有清晰单词边界的语言,字符分词或子词分词提供了更为有效的解决方案。此外,预定义的规则和正则表达式也可以帮助处理包含特殊字符的复杂字符串。这些高级技术使得分词过程更加精确,有助于提升自然语言处理系统的性能和准确性。
实现分词
自然语言处理(NLP)领域提供了多种工具,这些工具针对不同的需求和复杂性而设计。以下是一些最突出的分词工具和方法的介绍:
-
NLTK(自然语言工具包):NLTK是NLP社区的基石,是一个全面的Python库,能够满足广泛的语言处理需求。它提供了单词和句子分词的功能,适合从初学者到资深从业者的各类用户。
-
Spacy:作为NLTK的现代且高效的替代品,Spacy是另一个基于Python的NLP库。它以其快速处理能力而闻名,并支持多种语言,成为大规模应用的首选。
-
BERT分词器:这种分词器基于BERT预训练模型,擅长进行上下文感知的分词。它能够很好地处理语言的细微差别和歧义,是高级NLP项目的优选工具(有关使用BERT进行NLP的教程,请参阅相关资料)。
-
高级技术:
-
字节对编码(BPE):这是一种自适应分词方法,根据文本中最常见的字节对进行分词。它特别适合于那些通过组合较小单元来构成意义的语言。
-
SentencePiece:这是一种无监督的文本分词器和反分词器,主要用于基于神经网络的文本生成任务。它能够用单一模型处理多种语言,并且可以将文本分词为子词,适用于各种NLP任务。
-
选择工具时应考虑项目的具体需求。对于NLP新手来说,NLTK或Spacy可能提供更平缓的学习曲线。而对于需要深入理解上下文和细节的项目,BERT分词器则是一个强大的选择。
举例
比如在评分分类器项目中,我们如何使用分词呢?
因为分词在评分分类器项目中的应用是一个将文本数据转换为可操作信息的过程,比较有代表性。我们可以按下面的步骤进行:
-
数据准备:启动项目时,首先需要搜集包含用户评论及其对应评分的数据集,这是构建模型的基础。
-
文本清洗:对收集到的文本数据进行预处理,包括去除标点符号、停用词,以及清理可能的格式错误或特殊字符,以净化数据。
-
分词工具选择:基于项目需求,选择一个合适的分词工具。NLTK、Spacy和BERT分词器都是流行的选择,各有其特点和优势。
-
执行分词:应用选定的分词工具,将清洗后的文本分解为更小的单元,如单词或字符,为后续处理打下基础。
-
数值化转换:将分词结果转换为数值型序列,这是模型训练的必经步骤。可以通过词袋模型、TF-IDF或预训练的词嵌入来实现。
-
序列处理:根据模型输入的要求,对数值序列进行填充或截断,以保证序列长度一致性。
-
模型构建:设计并构建一个评分分类模型,选择合适的算法框架,如逻辑回归、SVM或神经网络。
-
模型训练:使用处理好的数据训练模型,通过调整模型参数,让模型学习如何根据文本内容预测评分。
-
性能评估:在测试集上评估模型性能,关注准确率、召回率和F1分数等评价指标。
-
模型优化:根据评估结果,对模型进行细致的调整,包括超参数调优和结构改进,以提高预测准确性。
-
模型部署:当模型表现达到预期,将其部署到生产环境中,实现对实时数据的自动评分分类。
-
持续监控与更新:在模型部署后,持续监控其性能,并根据反馈进行迭代更新,确保模型的长期有效性和适应性。
以下是一个使用Python和Keras进行分词和模型构建的示例,可以实现词的嵌入和基本的模型评估:
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.models import Sequential
from keras.layers import Embedding, LSTM, Dense
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report# 假设我们有以下评论和对应的评分数据
comments = ["I loved the product", "Worst experience ever", "Not bad, could be better"]
ratings = [5, 1, 3] # 评分转换为二进制标签:正面或负面# 初始化Tokenizer并适应文本数据
tokenizer = Tokenizer(num_words=10000)
tokenizer.fit_on_texts(comments)# 将文本转换为数值序列,并进行填充
sequences = tokenizer.texts_to_sequences(comments)
padded_sequences = pad_sequences(sequences, maxlen=100)# 假设我们加载了预训练的词嵌入矩阵
# embeddings_index = load_pretrained_embeddings()# 构建模型
model = Sequential()
model.add(Embedding(input_dim=10000, output_dim=128, input_length=100))
model.add(LSTM(64))
model.add(Dense(1, activation='sigmoid'))# 编译模型
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(padded_sequences, ratings, test_size=0.2)# 训练模型
model.fit(X_train, y_train, epochs=10, validation_data=(X_test, y_test))# 评估模型
y_pred = (model.predict(X_test) > 0.5).astype(int)
print(classification_report(y_test, y_pred))
在这个示例中,我们展示了如何使用Keras的Tokenizer进行分词,如何构建一个简单的LSTM模型,并进行了基本的模型评估。在实际应用中,可能还需要进行更深入的数据探索、特征工程和模型调优。

相关文章:
什么是NLP分词(Tokenization)
在自然语言处理和机器学习的领域里,咱们得聊聊一个超基础的技巧——就是“分词”啦。这个技巧啊,就是把一长串的文字切分成小块,让机器能更容易地“消化”。这些小块,不管大小,单个的字符也好,整个的单词也…...

基于深度学习的图像伪造检测
基于深度学习的图像伪造检测主要利用深度学习技术来识别和检测伪造的图像内容,尤其是在生成对抗网络(GAN)等技术发展的背景下,伪造图像的逼真程度大大提升。图像伪造检测在信息安全、隐私保护、司法鉴定等领域具有重要意义。以下是…...

Windows11 WSL2 Ubuntu编译安装perf工具
在Windows 11上通过WSL2安装并编译perf工具(Linux性能分析工具)可以按以下步骤进行。perf工具通常与Linux内核一起发布,因此你需要确保你的内核版本和perf版本匹配。以下是安装和编译perf的步骤: 1. 更新并升级系统 首先&#x…...

探索算法系列 - 前缀和算法
目录 一维前缀和(原题链接) 二维前缀和(原题链接) 寻找数组的中心下标(原题链接) 除自身以外数组的乘积(原题链接) 和为 K 的子数组(原题链接) 和可被 …...

Stable Diffusion绘画 | 提示词基础原理
提示词之间使用英文逗号“,”分割 例如:1girl,black long hair, sitting in office 提示词之间允许换行 但换行时,记得在结尾添加英文逗号“,”来进行区分 权重默认为1,越靠前权重越高 每个提示词自身的权重默认值为1,但越靠…...

利用python写一个可视化的界面
要利用Python编写一个可视化界面,你可以使用一些图形库来实现,例如Tkinter、PyQt、wxPython等。以下是一个使用Tkinter的示例代码: import tkinter as tk# 创建一个窗口对象 window tk.Tk()# 定义一个按钮点击事件的处理函数 def buttonCli…...

第13节课:Web Workers与通信——构建高效且实时的Web应用
目录 Web Workers简介Web Workers的基本概念创建和使用Web WorkersWeb Workers的应用场景 WebSocket通信WebSocket的基本概念创建和使用WebSocketWebSocket的应用场景 实践:使用Web Workers和WebSocket示例:使用Web Workers进行大数据集处理示例…...

pam_pwquality.so模块制定密码策略
目录 设置密码策略的方法pam_pwquality.so配置详解pam_pwquality.so默认密码规则pam_pwquality.so指定密码规则问题补充设置密码策略的方法 这篇文章重点讲通过pam_pwquality.so模块配置密码策略 指定pam_pwquality.so模块参数Centos7开始使用pam_pwquality模块进行密码复杂度…...
spark3.3.4 上使用 pyspark 跑 python 任务版本不一致问题解决
问题描述 在 spark 上跑 python 任务最常见的异常就是下面的版本不一致问题了: RuntimeError: Python in worker has different version 3.7 than that in driver 3.6, PySpark cannot run with different minor versions. Please check environment variables PY…...

处理Pandas中的JSON数据:从字符串到结构化分析
在数据科学领域,JSON作为一种灵活的数据交换格式,被广泛应用于存储和传输数据。然而,JSON数据的非结构化特性在进行数据分析时可能会带来一些挑战。本文将指导读者如何使用Pandas库将DataFrame中的JSON字符串列转换为结构化的表格数据&#x…...

国内的 Ai 大模型,有没有可以上传excel,完成数据分析的?
小说推文AI视频生成:小说文案智能分镜智能识别角色和场景批量Ai绘图自动配音添加音乐一键合成视频百万播放量https://aitools.jurilu.com/ 有啊!智谱清言、KiMI、豆包都可以做数分,在计算领域尤其推荐智谱清言,免费、快速还好使&a…...

Spring: jetcache
一、介绍 JetCache是一个基于Java的缓存系统封装,提供统一的API和注解来简化缓存的使用。 JetCache提供了比SpringCache更加强大的注解,可以原生的支持TTL(Time To Live,即缓存生存时间)、两级缓存、分布式自动…...
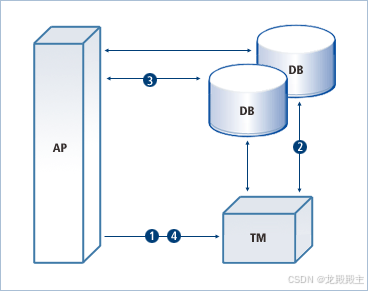
什么是分布式事务?
分布式事务跨越多个系统,确保所有操作一起成功或失败,这对于在现代计算环境中跨不同地理位置分离的资源维护数据完整性和一致性至关重要。 1. 为什么需要分布式事务? 分布式事务的需求源于确保分布式计算环境中多个独立系统或资源之间的数据…...

深入Java内存区域:堆栈、方法区与程序计数器的奥秘
引言 在Java开发过程中,合理地管理和利用内存资源对于提高程序的运行效率至关重要。特别是在大型项目或高并发场景下,一个小小的内存泄漏就可能导致整个系统崩溃。因此,掌握Java内存区域的相关知识,不仅能帮助我们更好地理解程序…...

【ML】异常检测、二分类问题
【ML】异常检测、二分类问题 1. 异常检测、二分类问题1.1 异常检测(Anomaly Detection)1.2 二分类问题(Binary Classification)1.3 异常检测与二分类问题的对比1.4 总结 2. 模型额训练与评估3. 为什么会出现比较高的误识别&#x…...

8.8-配置python3环境+python语法的使用
1.环境 python2 ,python3 [rootpython ~]# yum list installed|grep python [rootpython ~]# yum list installed|grep epel epel-release.noarch 7-11 extras #安装python3 [rootpython ~]# yum -y install python3…...

高质量WordPress下载站模板5play主题源码
5play下载站是由国外站长开发的一款WordPress主题,主题简约大方,为v1.8版本, 该主题模板中包含了上千个应用,登录后台以后只需要简单的三个步骤就可以轻松发布apk文章, 我们只需要在WordPress后台中导入该主题就可以…...

【C++】类的概念与基本使用介绍
C类是面向对象编程(OOP)的基础,它允许我们将数据(属性)和行为(方法)封装在一起,形成一个自定义的数据类型。以下是C类的基本概念、特点、特性以及使用注意事项,最后会提供…...

基于Python和OpenCV的图像处理的轮廓查找算法及显示
文章目录 概要轮廓查找算法示例代码代码解释小结 概要 在图像处理中,轮廓查找是一个重要的步骤,它可以帮助我们识别图像中的形状和边界。Python结合OpenCV库可以非常方便地实现这一功能。本文将详细介绍如何使用Python和OpenCV来查找图像中的轮廓&#…...

使用ant design的modal时,发现自定义组件的样式(组件高度)被改变了!
一 问题描述 在项目中,自定义了一个组件,分别在界面和 antd的modal中都有使用到。但是突然发现,界面中的组件样式跟modal中的组件样式高度不一样。modal中的组件整体要比页面中的组件要高一点。 项目中的自定义组件比较复杂,因此&…...

csp预习day2
set#include<bits/stdc.h> using namespace std;int main(){// ios::sync_with_stdio(0);// cin.tie(0);// cout.tie(0);int n,m; //值域、询问个数scanf("%d%d",&n,&m);int set[n1]; //大小为n的随机序列for (int i 1; i < n; i){scanf(&qu…...
迁移到 RKE2(容器化)后,JSON 日志未能正确解析)
118. 从 RKE1(Docker)迁移到 RKE2(容器化)后,JSON 日志未能正确解析
Situation 地理位置After migrating the cluster from RKE1 to RKE2, JSON logs sent to Elasticsearch are not being split into fields correctly. 在将集群从 RKE1 迁移到 RKE2 后,发送到 Elasticsearch 的 JSON 日志没有被正确划分为字段。 Resolution 结局T…...

浅析 Python 中数据离散化的实现方式
一、什么是数据离散化?在数据分析和机器学习的预处理阶段,数据离散化是一个非常核心且常用的操作。简单来说,数据离散化就是将连续的数值型数据,按照一定的规则划分成若干个离散的区间 / 类别。连续数据:身高ÿ…...

DMA内存访问与Cheat Engine插件开发全指南:零基础配置到高效内存分析
DMA内存访问与Cheat Engine插件开发全指南:零基础配置到高效内存分析 【免费下载链接】CheatEngine-DMA Cheat Engine Plugin for DMA users 项目地址: https://gitcode.com/gh_mirrors/ch/CheatEngine-DMA CheatEngine-DMA是一款专为技术爱好者和开发者设计…...

HarmonyOS 6学习:语音识别准确率提升与错误纠正方案
引言 在HarmonyOS 6应用开发中,语音识别能力已成为构建智能交互体验的核心技术。随着AI技术的快速发展,语音识别已广泛应用于教育、办公、智能家居等多个场景。然而,在实际开发过程中,开发者常面临一个普遍问题:语音识…...

实战分享:WAN2.2文生视频结合SDXL风格,用Python打造自动化视频生产线
实战分享:WAN2.2文生视频结合SDXL风格,用Python打造自动化视频生产线 1. 为什么选择WAN2.2SDXL组合进行视频创作 在数字内容爆炸式增长的今天,视频创作已经成为各行各业的基本需求。但传统视频制作流程复杂、成本高昂,让许多创作…...

开源抢票工具成功率提升指南:从配置到实战的全方位优化
开源抢票工具成功率提升指南:从配置到实战的全方位优化 【免费下载链接】damaihelper 支持大麦网,淘票票、缤玩岛等多个平台,演唱会演出抢票脚本 项目地址: https://gitcode.com/gh_mirrors/dam/damaihelper 你是否曾在开票瞬间眼睁睁…...

终极指南:3步快速备份QQ空间完整历史记录,永久保存青春回忆
终极指南:3步快速备份QQ空间完整历史记录,永久保存青春回忆 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 还在为QQ空间里那些珍贵的青春记忆可能随时消失而担忧…...

我用 Codex 一段时间后,才发现提示词真正该怎么写
(LetAiCode - AI 编程助手) 大家好呀,我是 Lazy熊。 最近这段时间,我越来越明显地感受到一件事。 很多人在聊 AI 编程的时候,关注点其实都差不多。看模型、看价格、看速度、看功能,或者看哪个工具最近更火。 这些当…...

Web全栈开发学习路径规划:Phi-3-mini-gguf你的个性化导师
Web全栈开发学习路径规划:Phi-3-mini-gguf你的个性化导师 1. 为什么需要个性化学习路径 学习Web全栈开发就像建造一栋房子,不同的人需要不同的施工图纸。传统学习路径往往千篇一律,忽略了学习者的基础差异和目标差异。Phi-3-mini模型通过分…...