深入探索:【人工智能】、【机器学习】与【深度学习】的全景视觉之旅
目录
第一部分:人工智能、机器学习与深度学习概述
1.1 人工智能的概念与发展
代码示例:简单的AI决策系统
1.2 机器学习的定义与分类
代码示例:简单的线性回归模型
1.3 深度学习的基础与应用
代码示例:构建简单的神经网络
第二部分:机器学习的理论基础
2.1 数据准备与特征工程
代码示例:数据清理与特征工程
2.2 模型选择与评估
代码示例:模型选择与交叉验证
2.3 模型优化与超参数调优
代码示例:超参数调优与模型优化
第三部分:深度学习的核心原理
3.1 人工神经网络的结构与工作原理
代码示例:创建和训练简单的神经网络
3.2 卷积神经网络(CNN)与图像处理
代码示例:构建简单的卷积神经网络
3.3 递归神经网络(RNN)与序列处理
代码示例:构建简单的递归神经网络
第四部分:手写数字识别案例的代码实现与讲解
4.1 项目概述与目标
代码示例:加载MNIST数据集
4.2 数据加载与预处理
代码示例:数据预处理
4.3 模型构建与编译
代码示例:构建和编译模型
4.4 模型训练与验证
代码示例:训练模型
4.5 模型评估与预测
代码示例:评估与预测
第五部分:扩展与优化
5.1 模型的扩展与改进
代码示例:增加网络深度
5.2 模型优化与调参
代码示例:调整学习率
第六部分:未来发展与挑战
6.1 人工智能的未来趋势
代码示例:简单的GAN生成器模型
6.2 持续学习与自动机器学习(AutoML)
代码示例:使用AutoKeras进行自动机器学习
6.3 人工智能的伦理与挑战
代码示例:处理算法偏见
结论


前几天偶然发现了一个超棒的人工智能学习网站,内容通俗易懂,讲解风趣幽默,简直让人欲罢不能。忍不住分享给大家,点击这里立刻跳转,开启你的AI学习之旅吧!
前言 – 人工智能教程
https://www.captainbed.cn/lzx
第一部分:人工智能、机器学习与深度学习概述
1.1 人工智能的概念与发展
人工智能(Artificial Intelligence, AI)是计算机科学的一个分支,旨在开发能够模拟或增强人类智能的系统。AI的研究范围广泛,涵盖了从基础算法到复杂系统的开发。
代码示例:简单的AI决策系统
# 简单的基于规则的AI决策系统
def ai_decision_system(weather):if weather == 'sunny':return "Go for a walk"elif weather == 'rainy':return "Stay inside and read a book"elif weather == 'snowy':return "Go skiing"else:return "Weather unknown, stay cautious"# 测试AI决策系统
print(ai_decision_system('sunny')) # 输出: Go for a walk
这个简单的代码展示了AI的最基本形式,即基于规则的决策系统。根据天气条件,AI系统作出相应的决策。这类系统可以看作是AI的早期形式,依赖于预定义的规则集。
1.2 机器学习的定义与分类
机器学习(Machine Learning, ML)是一种通过数据训练模型,使机器自动从数据中学习规律的技术。
代码示例:简单的线性回归模型
from sklearn.linear_model import LinearRegression
import numpy as np# 创建训练数据
X = np.array([[1], [2], [3], [4], [5]])
y = np.array([1, 3, 2, 3, 5])# 创建线性回归模型并训练
model = LinearRegression()
model.fit(X, y)# 预测新的数据
prediction = model.predict(np.array([[6]]))
print(f"Prediction for input 6: {prediction}") # 输出: Prediction for input 6: [5.2]
此代码示例展示了机器学习中监督学习的一个简单应用,即线性回归。我们通过训练数据创建一个线性模型,并使用该模型预测新数据点的输出。线性回归是监督学习的一种常见方法,特别适用于预测连续值。
1.3 深度学习的基础与应用
深度学习(Deep Learning, DL)是机器学习的一个分支,主要基于多层神经网络。它擅长处理非结构化数据,如图像和文本。
代码示例:构建简单的神经网络
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense# 创建一个简单的神经网络
model = Sequential([Dense(32, input_shape=(784,), activation='relu'),Dense(10, activation='softmax')
])# 编译模型
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])# 打印模型摘要
model.summary()
这个代码示例展示了如何使用Keras创建一个简单的神经网络模型。该模型包含两个全连接层,第一层有32个神经元,使用ReLU激活函数;第二层有10个神经元,使用Softmax激活函数。这种结构常用于多分类任务,如手写数字识别。

第二部分:机器学习的理论基础
2.1 数据准备与特征工程
数据准备和特征工程是机器学习项目中至关重要的步骤。它们确保数据在输入模型前已经过清理、转换和优化。
代码示例:数据清理与特征工程
import pandas as pd
from sklearn.preprocessing import StandardScaler, OneHotEncoder# 加载数据
data = pd.DataFrame({'feature1': [1.0, 2.0, np.nan, 4.0, 5.0],'feature2': ['A', 'B', 'A', 'B', 'A'],'target': [1, 0, 1, 0, 1]
})# 数据清理:填充缺失值
data['feature1'].fillna(data['feature1'].mean(), inplace=True)# 特征转换:独热编码分类特征
encoder = OneHotEncoder(sparse=False)
encoded_features = encoder.fit_transform(data[['feature2']])
encoded_df = pd.DataFrame(encoded_features, columns=encoder.get_feature_names_out(['feature2']))# 标准化数值特征
scaler = StandardScaler()
data['feature1'] = scaler.fit_transform(data[['feature1']])# 合并处理后的特征
processed_data = pd.concat([data[['feature1']], encoded_df, data[['target']]], axis=1)
print(processed_data)
这个代码示例展示了数据清理与特征工程的几个步骤:填充缺失值、对分类特征进行独热编码、标准化数值特征。通过这些处理,我们确保数据在进入模型之前处于最佳状态。
2.2 模型选择与评估
选择合适的机器学习模型以及评估模型性能是构建有效系统的关键。
代码示例:模型选择与交叉验证
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score# 准备数据
X = processed_data.drop('target', axis=1)
y = processed_data['target']# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 选择模型并训练
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)# 使用交叉验证评估模型
scores = cross_val_score(model, X_train, y_train, cv=5)
print(f"Cross-validation accuracy: {scores.mean()}")# 预测并评估在测试集上的性能
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Test set accuracy: {accuracy}")
此代码展示了如何选择一个模型(随机森林)并使用交叉验证评估其性能。通过交叉验证,我们可以了解模型在训练数据上的稳定性和泛化能力。
2.3 模型优化与超参数调优
为了提升模型的性能,我们通常需要调整超参数和进行优化。
代码示例:超参数调优与模型优化
from sklearn.model_selection import GridSearchCV# 定义超参数网格
param_grid = {'n_estimators': [50, 100, 200],'max_depth': [None, 10, 20, 30]
}# 使用GridSearchCV进行超参数调优
grid_search = GridSearchCV(RandomForestClassifier(random_state=42), param_grid, cv=5)
grid_search.fit(X_train, y_train)# 输出最佳参数
print(f"Best parameters: {grid_search.best_params_}")# 使用最佳参数训练的模型在测试集上的表现
best_model = grid_search.best_estimator_
y_pred = best_model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Test set accuracy with best parameters: {accuracy}")
这个代码展示了如何通过GridSearchCV进行超参数调优,找到最佳的超参数组合并提升模型的性能。

第三部分:深度学习的核心原理
3.1 人工神经网络的结构与工作原理
人工神经网络(ANN)是深度学习的基础,模拟了人脑神经元的工作方式。
代码示例:创建和训练简单的神经网络
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense# 创建神经网络模型
model = Sequential([Dense(32, input_shape=(784,), activation='relu'),Dense(10, activation='softmax')
])# 编译模型
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])# 假设有已经处理好的训练数据X_train, y_train
# 训练模型
model.fit(X_train, y_train, epochs=10, batch_size=32)
此代码展示了如何使用Keras创建并训练一个基本的神经网络模型,用于多分类任务。
3.2 卷积神经网络(CNN)与图像处理
卷积神经网络(CNN)特别适用于图像处理,通过卷积操作提取图像特征。
代码示例:构建简单的卷积神经网络
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten# 创建CNN模型
model = Sequential([Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),MaxPooling2D(pool_size=(2, 2)),Flatten(),Dense(128, activation='relu'),Dense(10, activation='softmax')
])# 编译模型
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])# 假设有已经处理好的训练数据X_train, y_train
# 训练模型
model.fit(X_train, y_train, epochs=10, batch_size=32)
这个代码展示了如何使用Keras构建一个简单的CNN,用于处理图像分类任务,如手写数字识别。卷积层和池化层自动提取图像的空间特征,使得模型在图像任务中具有更高的准确性。
3.3 递归神经网络(RNN)与序列处理
递归神经网络(RNN)擅长处理序列数据,通过捕捉时间依赖关系,在语音识别、时间序列预测等领域表现出色。
代码示例:构建简单的递归神经网络
from tensorflow.keras.layers import SimpleRNN# 创建RNN模型
model = Sequential([SimpleRNN(50, input_shape=(timesteps, features), activation='relu'),Dense(10, activation='softmax')
])# 编译模型
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])# 假设有已经处理好的序列数据X_train, y_train
# 训练模型
model.fit(X_train, y_train, epochs=10, batch_size=32)
这个代码展示了如何使用Keras构建一个简单的RNN,用于处理序列数据。RNN在处理具有时间依赖性的数据(如时间序列、文本数据)时非常有效。

第四部分:手写数字识别案例的代码实现与讲解
4.1 项目概述与目标
手写数字识别任务广泛用于银行票据识别、邮政编码识别等实际场景。我们将使用MNIST数据集完成该任务。
代码示例:加载MNIST数据集
from tensorflow.keras.datasets import mnist# 加载MNIST数据集
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()# 查看数据形状
print(f"Train images shape: {train_images.shape}")
print(f"Train labels shape: {train_labels.shape}")
这个代码片段展示了如何加载MNIST数据集,并查看数据集的形状。MNIST数据集包含60,000个训练样本和10,000个测试样本,每个样本是28x28像素的灰度图像。
4.2 数据加载与预处理
在模型训练前,数据需要进行归一化处理和标签的one-hot编码。
代码示例:数据预处理
from tensorflow.keras.utils import to_categorical# 归一化图像数据
train_images = train_images.astype('float32') / 255
test_images = test_images.astype('float32') / 255# 将图像数据展平
train_images = train_images.reshape((train_images.shape[0], 28 * 28))
test_images = test_images.reshape((test_images.shape[0], 28 * 28))# One-hot编码标签
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
这个代码展示了如何对图像数据进行归一化处理,以及如何将标签转换为one-hot编码形式,以便神经网络能够处理。
4.3 模型构建与编译
我们将使用Keras构建一个简单的全连接神经网络模型。
代码示例:构建和编译模型
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense# 构建全连接神经网络模型
model = Sequential([Dense(512, activation='relu', input_shape=(28 * 28,)),Dense(10, activation='softmax')
])# 编译模型
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
此代码展示了如何构建和编译一个简单的全连接神经网络,用于手写数字识别任务。该模型使用ReLU作为隐藏层的激活函数,Softmax作为输出层的激活函数。
4.4 模型训练与验证
接下来,我们将模型应用于训练数据进行训练,并使用验证集评估模型性能。
代码示例:训练模型
# 训练模型
history = model.fit(train_images, train_labels, epochs=5, batch_size=128, validation_split=0.2)
这个代码片段展示了如何使用Keras的fit方法训练模型。我们使用20%的训练数据作为验证集,模型训练5个epochs,每次更新模型使用128个样本。
4.5 模型评估与预测
在模型训练完成后,使用测试数据评估模型的性能,并展示预测结果。
代码示例:评估与预测
# 评估模型
test_loss, test_acc = model.evaluate(test_images, test_labels)
print(f"Test accuracy: {test_acc}")# 预测
predictions = model.predict(test_images)# 显示一些预测结果
import numpy as np
import matplotlib.pyplot as pltdef plot_image(i, predictions_array, true_label, img):plt.grid(False)plt.xticks([])plt.yticks([])plt.imshow(img, cmap=plt.cm.binary)predicted_label = np.argmax(predictions_array)true_label = np.argmax(true_label)if predicted_label == true_label:color = 'blue'else:color = 'red'plt.xlabel(f"{predicted_label} ({true_label})", color=color)# 显示前5个测试样本的预测结果
plt.figure(figsize=(10, 5))
for i in range(5):plt.subplot(1, 5, i+1)plot_image(i, predictions[i], test_labels[i], test_images[i].reshape(28, 28))
plt.show()
这个代码展示了如何评估模型在测试集上的表现,并通过可视化展示模型的预测结果。通过这些图像,我们可以直观地看到模型的预测效果。

第五部分:扩展与优化
5.1 模型的扩展与改进
我们可以通过增加模型的深度或使用卷积神经网络(CNN)来提升模型的性能。
代码示例:增加网络深度
from tensorflow.keras.layers import Dropout# 创建更深的神经网络模型
model = Sequential([Dense(512, activation='relu', input_shape=(28 * 28,)),Dropout(0.2),Dense(512, activation='relu'),Dropout(0.2),Dense(10, activation='softmax')
])# 编译模型
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])# 训练模型
history = model.fit(train_images, train_labels, epochs=5, batch_size=128, validation_split=0.2)
这个代码展示了如何通过增加隐藏层的数量和使用Dropout层来扩展网络,从而提高模型的表达能力和泛化能力。
5.2 模型优化与调参
为了进一步提升模型性能,可以通过调整学习率等超参数来优化模型。
代码示例:调整学习率
from tensorflow.keras.optimizers import Adam# 调整学习率
optimizer = Adam(learning_rate=0.001)# 编译模型
model.compile(optimizer=optimizer, loss='categorical_crossentropy', metrics=['accuracy'])# 训练模型
history = model.fit(train_images, train_labels, epochs=5, batch_size=128, validation_split=0.2)
这个代码展示了如何通过调整Adam优化器的学习率来优化模型训练过程。选择合适的学习率可以加快模型的收敛速度,并提升最终的性能。

第六部分:未来发展与挑战
6.1 人工智能的未来趋势
AI的发展方向可能包括自监督学习、联邦学习和生成对抗网络(GAN)等新兴技术。
代码示例:简单的GAN生成器模型
from tensorflow.keras.layers import Dense, LeakyReLU
from tensorflow.keras.models import Sequential# 创建生成器模型
generator = Sequential([Dense(128, input_dim=100),LeakyReLU(alpha=0.01),Dense(784, activation='tanh')
])# 打印生成器模型结构
generator.summary()
这个代码展示了如何构建一个简单的生成器模型,用于生成对抗网络(GAN)中的生成部分。GAN是一种新兴技术,用于生成逼真的图像、音频或文本。

6.2 持续学习与自动机器学习(AutoML)
持续学习和AutoML是AI领域中的重要发展方向,致力于降低技术门槛,简化机器学习流程。
代码示例:使用AutoKeras进行自动机器学习
import autokeras as ak# 使用AutoKeras自动化分类任务
clf = ak.ImageClassifier(overwrite=True, max_trials=3)# 假设已经有训练好的图像数据集train_images, train_labels
# 训练模型
clf.fit(train_images, train_labels, epochs=5)# 评估模型
test_loss, test_acc = clf.evaluate(test_images, test_labels)
print(f"Test accuracy: {test_acc}")
这个代码展示了如何使用AutoKeras进行自动机器学习。AutoML工具能够自动化模型选择、超参数调优等步骤,降低了构建高效机器学习模型的难度。
6.3 人工智能的伦理与挑战
随着AI技术的普及,数据隐私、算法偏见和社会影响等问题变得日益重要。
代码示例:处理算法偏见
from sklearn.metrics import classification_report# 在不同群体上评估模型
def evaluate_bias(model, X_test, y_test, group_labels):for group in np.unique(group_labels):idx = np.where(group_labels == group)y_pred = model.predict(X_test[idx])print(f"Evaluation for group {group}:")print(classification_report(y_test[idx], y_pred))# 假设我们有额外的群体标签group_labels
evaluate_bias(best_model, X_test, y_test, group_labels)
这个代码片段展示了如何在不同群体上评估模型,检测算法是否存在偏见。通过这种方法,可以识别出模型在特定群体上的表现差异,进而进行调整以减少偏见。
结论
人工智能、机器学习和深度学习是现代科技的重要组成部分,正深刻影响着各个行业的发展。从理论到实践,再到未来的发展趋势,AI技术的发展为我们提供了前所未有的工具来解决复杂的问题。然而,随着技术的进步,新的挑战也随之而来,如数据隐私、伦理问题等。为了实现AI技术的可持续发展,我们需要在技术创新与社会责任之间找到平衡。通过不断学习和实践,我们能够更好地应用AI技术,推动社会进步,并应对未来的挑战。

相关文章:
深入探索:【人工智能】、【机器学习】与【深度学习】的全景视觉之旅
目录 第一部分:人工智能、机器学习与深度学习概述 1.1 人工智能的概念与发展 代码示例:简单的AI决策系统 1.2 机器学习的定义与分类 代码示例:简单的线性回归模型 1.3 深度学习的基础与应用 代码示例:构建简单的神经网络 …...

使用js和css 实现div旋转围绕圆分布排列
记录,以防忘记 围绕圆 import React, { useEffect } from react; import ./index.scoped.scss;const Test () > {const arr Array.from({ length: 28 }, (_, index) > index 1);useEffect(() > {const dayTotal arr.length;// 动态设置每个点的旋转角…...

SQL Server中CPU使用率过高的排查
CPU使用率过高有许多可能原因,但以下原因最为常见: 1.由于以下情况,表或索引扫描导致的高逻辑读取: 过期统计信息 缺少索引 参数敏感计划 (PSP) 问题 设计不佳的查询 2.工作负荷增加 对于安装了sqlserver的服务器,可…...

AUTOSAR AP常用文档前缀
AUTOSAR AP常用文档前缀总结如下表: 缩写全称含义EXPExplanation文档类别,跟踪类别 讨论其他文件中已经显示的内容的说明材料MODModel文档类别,跟踪类别 元级别1(模型)上的建模内容(模型或从模型生成的内容)RSRequirement Specification文档…...

服务器迁移基于Tomcat部署的java应用,没有源码怎么办?
文章目录 反编译创建java工程编译新的数据库配置类DbUtilclass文件替换到Tomcat配置的应用路径 docBase背景:非国产化项目服务器审计不通过,需要迁移到外部公司。由于项目是第三方公司开发,丢失java项目源码。 部署环境:Tomcat7,JDK1.8 涉及JAVA项目的有两个服务,一个电台…...

kafka-go使用:以及kafka一些基本概念说明
关于kafka 作为开发人员kafka中最常关注的几个概念,是topic,partition和group这几个概念。topic是主题的意思,简单的说topic是数据主题,这样解释好像显得很苍白,只是做了个翻译。一图胜前言,我们还是通过图解来说明。…...

景联文科技:破解数据标注行业痛点,引领高质量AI数据服务
数据标注行业是人工智能和机器学习领域中一个非常重要的组成部分。随着AI技术的发展,对高质量标注数据的需求也在不断增长。 数据标注市场的痛点 1. 团队管理 在众包和转包模式下,管理大量的标注人员是一项挑战。 需要确保标注人员的专业性、稳定性和…...
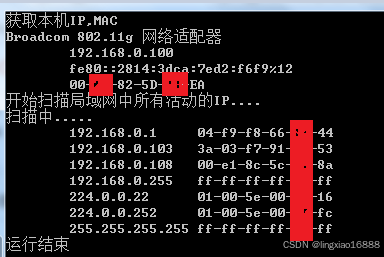
C#获取Network的相关信息
1,获取网络的通断。 //方法1:无效果,并不能反映当前网络通断 bool availableSystem.Windows.Forms.SystemInformation.Network//方法2:通过VB获取网络状态,可反映当前网络通断 Microsoft.VisualBasic.Devices.Network…...

Jenkins 部署Vue项目指引: Vue项目本地跨域代理 、解决ERR_UNSAFE_PORT
文章目录 引言I Jenkins 部署Vue项目配置插件安装系统配置NodeJS安装目录和别名设置新建任务(通用类型)构建环境Build Steps(构建步骤)II nginx部署站点(端口和站点目录的映射)查找Nginx配置文件端口和站点目录的映射III Vue项目本地跨域代理,屏蔽掉后端服务API的网关IP…...

C语言电子画板
目录 开头程序程序的流程图程序的效果结尾 开头 大家好,我叫这是我58。今天,我们来看一下我用C语言编译的电子画板和与之相关的一些东西。 程序 #define _CRT_SECURE_NO_WARNINGS 1 #include <stdio.h> #include <Windows.h> int main() …...

Android Gradle开发与应用技术原理
Android Gradle开发与应用技术原理 Android Gradle开发与应用技术原理一、概述二、Gradle构建原理1. Gradle架构2. Gradle构建过程3. 构建脚本 三、Gradle插件机制四、在Android应用中实现Text-to-Speech(TTS)功能1. 配置Gradle依赖2. 实现TTS功能示例代…...

Midjourney入门-提示词基础撰写与公式
前言 在前几篇教程里我们已经可以初步使用Midjourney进行出图了。 包括也了解了Midjourney的指令与参数。 但如果你想用Midjourney去生成各种各样高质量的图片, 并且生成的图片是你想要的画面内容,也就是更好控制生成图片的画面内容与风格…...

Apache Tomcat服务器版本号隐藏
渗透测试时发现有一台服务器的404报错页面中,有Apache Tomcat的版本号信息显示,发生了信息泄露,可能导致服务器被攻击。如下所示: 解决步骤如下: 1. 隐藏HTTP响应头中的Server信息 Tomcat默认会在HTTP响应头中包含S…...

【Qt】Qt编程注意事项
目录 Qr中的命名规范 Qt Creator中的快捷键 查询文档的方式 Qt窗口坐标体系 Qr中的命名规范 在学习编程语言阶段,给变量、函数、文件、类命名是非常有讲究的。 命名要有描述性,不要使用abc,xyz这种比较无规律的名字类描述。如果名字比较…...

在Linux系统安装Kafka
注意:我的是在云服务器上基于Docker配 在防火墙上放行端口号 2181(Zookeeper) 9092(Kafka) 一、先配置 Docker 守护进程(daemon)的镜像加速器(registry mirrors) sudo mkdir -p /etc/docker sudo tee /etc/docker/da…...

【CSharp】简单定义一个异步方法
【CSharp】定义一个异步方法 1.背景2.异步方法3.代码说明1.背景 相关博客: 【CSharp】使用异步事件处理程序和委托来进行异步调用 https://blog.csdn.net/jn10010537/article/details/140898179在 C# 中,异步方法和同步方法是两种执行代码的方式, 它们主要区别在于处理任务…...

贪心算法之货仓选址问题
#include<stdio.h> #include<stdlib.h> #include<math.h>//贪心算法之货仓选址问题/*** void* p是万能指针,可以和其它任意类型的指针进行转换,前提是确保转换是合法的*/ //写好用于qsort的比较函数,这里写的函数一般用于…...
Java网络编程——Request Response 对象
Response - 网页 上一章我们学习了 Java 中使用 Okhttp3 库请求网页或调用 API 的知识。 使用一条语句执行调用请求,并取得返回结果字符串: call.execute().body().string()execute() 方法是真正执行发送请求,前面的一系列代码是做前置准备…...

【代码随想录训练营第42期 Day24打卡 回溯Part3 - LeetCode 93.复原IP地址 78.子集 90.子集II
目录 一、做题心得 二、题目与题解 题目一:93.复原IP地址 题目链接 题解:回溯--分割问题 题目二:78.子集 题目链接 题解:回溯--子集问题 题目三:90.子集II 题目链接 题解:回溯--子集问题 三、小…...

python venv和virtualenv详解
一、venv简介 C:\Users\love1>python -m venv -h usage: venv [-h] [--system-site-packages] [--symlinks | --copies] [--clear] [--upgrade] [--without-pip][--prompt PROMPT] [--upgrade-deps]ENV_DIR [ENV_DIR ...]该命令用于在一个目录或者多个目录中创建一个虚拟的…...
ClearerVoice-Studio语音分离实用技巧:分离后各声道说话人身份标注方法
ClearerVoice-Studio语音分离实用技巧:分离后各声道说话人身份标注方法 你是不是也遇到过这种情况?用语音分离工具把一段多人对话音频分成了几个独立的声道,结果看着一堆命名为“output_1.wav”、“output_2.wav”的文件,完全搞不…...

解决图像修复与纹理合成难题的Resynthesizer:开源智能填充工具全指南
解决图像修复与纹理合成难题的Resynthesizer:开源智能填充工具全指南 【免费下载链接】resynthesizer Suite of gimp plugins for texture synthesis 项目地址: https://gitcode.com/gh_mirrors/re/resynthesizer 在数字图像处理领域,我们经常面临…...

PETRV2-BEV模型训练实战:基于星图AI算力平台的完整流程解析
PETRV2-BEV模型训练实战:基于星图AI算力平台的完整流程解析 1. 环境准备与基础配置 1.1 创建并激活conda环境 首先我们需要创建一个专用的conda环境来管理项目依赖。推荐使用Python 3.8版本: conda create -n paddle3d_env python3.8 conda activate…...

HoRain云--RESTful API设计全指南
🎬 HoRain 云小助手:个人主页 ⛺️生活的理想,就是为了理想的生活! ⛳️ 推荐 前些天发现了一个超棒的服务器购买网站,性价比超高,大内存超划算!忍不住分享一下给大家。点击跳转到网站。 目录 ⛳️ 推荐 …...

轻量工具如何承载复杂项目?揭秘GanttProject的极简主义哲学
轻量工具如何承载复杂项目?揭秘GanttProject的极简主义哲学 【免费下载链接】ganttproject Official GanttProject repository 项目地址: https://gitcode.com/gh_mirrors/ga/ganttproject 在项目管理领域,存在一个普遍的矛盾:专业工具…...

Maven Shade Plugin实战:解决Spring Boot胖JAR打包中的5个常见坑
Maven Shade Plugin实战:解决Spring Boot胖JAR打包中的5个常见坑 Spring Boot开发者们对"胖JAR"(fat JAR)应该都不陌生——这种将所有依赖打包进单个可执行文件的方式,极大简化了部署流程。但当你真正使用Maven Shade P…...

SEM优化和SEO优化的成本是多少_SEM优化和SEO优化的未来展望如何
SEM优化和SEO优化的成本是多少 在当今数字化营销的时代,SEM(搜索引擎营销)和SEO(搜索引擎优化)已经成为企业获取在线流量的两大关键手段。许多企业在投入这些优化策略时,往往会对其成本产生疑虑。本文将深…...
)
不止是IDEA!手把手教你用同一个Docker Compose文件部署全家桶(PyCharm/GoLand/DataGrip)
云端开发革命:用Docker Compose统一部署JetBrains全系Web IDE 1. 为什么需要云端IDE全家桶? 记得去年接手一个跨语言项目时,我的本地开发环境简直成了灾难现场——同时开着PyCharm处理Python数据分析、GoLand编写微服务、DataGrip管理数据库&…...

NovelAI:从文本生成到内容创作的AIGC实践
1. NovelAI:你的AI创作助手 第一次接触NovelAI时,我正被一篇商业方案折磨得焦头烂额。凌晨三点的咖啡杯旁,这个基于GPT模型的AI工具在15分钟内就帮我完成了初稿框架,那一刻我就知道,内容创作的方式正在被重新定义。Nov…...
)
千万级日志清洗仅需11秒:Polars 2.0流式分块+并行UDF实战(附可复用清洗模板库)
第一章:千万级日志清洗仅需11秒:Polars 2.0流式分块并行UDF实战(附可复用清洗模板库)传统Pandas在处理千万级Nginx或Kafka日志时,常因内存暴涨与单线程瓶颈导致清洗耗时超3分钟。Polars 2.0引入的scan_csv()流式扫描 …...