【Impala】学习笔记
Impala学习笔记
- 【一】Impala介绍
- 【1】简介
- (1)简介
- (2)优点
- (3)缺点
- 【2】架构
- (1)Impalad(守护进程)
- (2)Statestore(存储状态)
- (3)metadata(元数据)/metastore(元存储)
- 【三】Impala安装
- 【四】Impala接口
- 【五】Impala查询处理
- 【1】database
- 【2】table
- 【3】条件
【一】Impala介绍
【1】简介
(1)简介
Impala是Cloudera公司主导开发的新型查询系统,提供SQL语义,能查询存储在Hadoop的HDFS和Hbase中的PB级大数据。已有的Hive系统虽然也提供了sql语义,但是由于Hive底层之心使用的是MapReduce引擎,仍然是一个批处理过程,难以满足查询的交互性。相比之下,Impala的最大特点也是最大卖点就是它的快速。
Impala是建立砸Hadoop生态圈的交互式sql解析、执行引擎,Impala的sql语法和Hive高度兼容,并且提供标准的ODBC和JDBC接口。
Impala本身不提供数据的存储服务,其底层数据可来自HDFS、Kudu、Hbase
Impala是一个MPP(大规模并行处理)SQL查询引擎:
1-是一个用C ++和Java编写的开源软件;
2-用于处理存储在Hadoop集群中大量的数据;
3-性能最高的SQL引擎(提供类似RDBMS的体验),提供了访问存储在Hadoop分布式文件系统中的数据的最快方法。
(2)优点
(1)基于内存运算,不需要把中间结果写入磁盘,省掉了大量的I/O开销。
(2)无需转换为Mapreduce,直接访问存储在HDFS,HBase中的数据进行作业调度,速度快。
(3)使用了支持Data locality的I/O调度机制,尽可能地将数据和计算分配在同一台机器上进行,减少了网络开销。
(4)支持各种文件格式,如TEXTFILE 、SEQUENCEFILE 、RCFile、Parquet。
(5)可以访问hive的metastore,对hive数据直接做数据分析。
(3)缺点
1-不提供任何对序列化和反序列化的支持;
2-只能读取文本文件,而不能读取自定义二进制文件;
3-每当新的记录/文件被添加到HDFS中的数据目录时,该表需要被刷新。
【2】架构

impala主要由以下三个组件组成:
(1)Impala daemon(守护进程);
(2)Impala Statestore(存储状态);
(3)Impala元数据或metastore(元数据即元存储)。
(1)Impalad(守护进程)
daemon安装在Impala的每个节点上运行,它接受来自各种接口的查询,然后将工作分发到Impala集群中的其它Impala节点来并行化查询,结果返回到中央协调节。
可以将查询提交到专用Impalad或以负载平衡方式提交到集群中的另一Impalad
(2)Statestore(存储状态)
Statestore负责检查每个Impalad的运行状况,然后经常将每个Impala Daemon运行状况中继给其他守护程序,如果由于任何原因导致节点故障的情况下,Statestore将更新所有其他节点关于此故障,并且一旦此类通知可用于其他Impalad,则其他Impala守护程序不会向受影响的节点分配任何进一步的查询。
(3)metadata(元数据)/metastore(元存储)
Impala使用传统的MySQL或PostgreSQL数据库来存储表定义和列信息这些元数据。
当表定义或表数据更新时,其它Impala后台进程必须通过检索最新元数据来更新其元数据缓存,然后对相关表发出新查询。
【三】Impala安装
【四】Impala接口
Impala提供了三种方式去做查询处理:
(1)Impala-shell :命令窗口中键入impala-shell命令来启动Impala shell;
(2)Hue界面 :您可以使用Hue浏览器处理Impala查询;
(3)ODBC / JDBC驱动程序 :与其他数据库一样,Impala提供ODBC / JDBC驱动程序。
了解impala的数据类型:

【五】Impala查询处理
【1】database
(1)创建数据库
-- 示例:
CREATE DATABASE IF NOT EXISTS database_name;(2)删除数据库
-- 语法:
DROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT |
CASCADE] [LOCATION hdfs_path];-- 示例:
DROP DATABASE IF EXISTS samp`在这里插入代码片`le_database;
(3)选择数据库
-- 语法:
USE db_name;
【2】table
(1)创建表
-- 语法:
create table IF NOT EXISTS database_name.table_name (column1 data_type,column2 data_type,column3 data_type,………columnN data_type
);-- 示例:
CREATE TABLE IF NOT EXISTS my_db.student(name STRING, age INT, contact INT );(2)插入表
-- 语法:
insert into table_name (column1, column2, column3,...columnN) values (value1, value2, value3,...valueN);
insert overwrite table_name values (value1, value2, value2);-- 示例:
insert into employee (ID,NAME,AGE,ADDRESS,SALARY)VALUES (1, 'Ramesh', 32, 'Ahmedabad', 20000 );
insert overwrite employee values (1, 'Ram', 26, 'Vishakhapatnam', 37000 );(3)查询表
-- 语法:
SELECT column1, column2, columnN from table_name;--示例:
select name, age from customers; (4)表描述
-- 语法:
describe table_name;-- 示例:
describe customer;(5)修改表(重命名表案例,其它自行查阅):
-- 语法:
ALTER TABLE [old_db_name.]old_table_name RENAME TO [new_db_name.]new_table_name-- 示例:
ALTER TABLE my_db.customers RENAME TO my_db.users;(6)删除表
-- 语法:
DROP table database_name.table_name;--示例:
drop table if exists my_db.student;(7)截断表
-- 语法:
truncate table_name;-- 示例:
truncate customers;
(8)显示表
show tables (9)创建视图
-- 语法:
Create View IF NOT EXISTS view_name as Select statement
-- 示例:
CREATE VIEW IF NOT EXISTS customers_view AS select name, age from customers;(10)修改视图
-- 语法
ALTER VIEW database_name.view_name为Select语句
-- 示例
Alter view customers_view as select id, name, salary from customers;(11)删除视图
-- 语法:
DROP VIEW database_name.view_name;
-- 示例:
Drop view customers_view;【3】条件
(1)order by 子句
--语法
select * from table_name ORDER BY col_name [ASC|DESC] [NULLS FIRST|NULLS LAST]
--示例
Select * from customers ORDER BY id asc;(2)group by 字句
-- 语法
select data from table_name Group BY col_name;
-- 示例
Select name, sum(salary) from customers Group BY name;(3)having子句
--语法
select * from table_name ORDER BY col_name [ASC|DESC] [NULLS FIRST|NULLS LAST]
-- 示例
select max(salary) from customers group by age having max(salary) > 20000;(4)limit限制
-- 语法:
select * from table_name order by id limit numerical_expression;(5)offset偏移
-- 示例:
select * from customers order by id limit 4 offset 0;(6)union聚合
-- 语法:
query1 union query2;
-- 示例:
select * from customers order by id limit 3
union select * from employee order by id limit 3;(7)with子句
-- 语法:
with x as (select 1), y as (select 2) (select * from x union y);
-- 示例:
with t1 as (select * from customers where age>25), t2 as (select * from employee where age>25) (select * from t1 union select * from t2);(8)distinct去重
-- 语法:
select distinct columns… from table_name;
-- 示例:
select distinct id, name, age, salary from customers; 相关文章:
【Impala】学习笔记
Impala学习笔记 【一】Impala介绍【1】简介(1)简介(2)优点(3)缺点 【2】架构(1)Impalad(守护进程)(2)Statestore(存储状态…...
视频汇聚平台EasyCVR接入移动执法记录仪,视频无法播放且报错500是什么原因?
GB28181国标视频汇聚平台EasyCVR视频管理系统以其强大的拓展性、灵活的部署方式、高性能的视频能力和智能化的分析能力,为各行各业的视频监控需求提供了优秀的解决方案。视频智能分析平台EasyCVR支持多协议接入,兼容多类型的设备,包括IPC、NV…...

【Linux基础】Linux基本指令(二)
目录 🚀前言一,mv指令二,more & less指令2.1 more 指令2.1 less指令 三,重定向技术(重要)3.1 echo指令3.2 输出重定向 >3.3 追加重定向 >>3.4 输入重定向 < 四,head & tail指令4.1 head 指令4.2 t…...
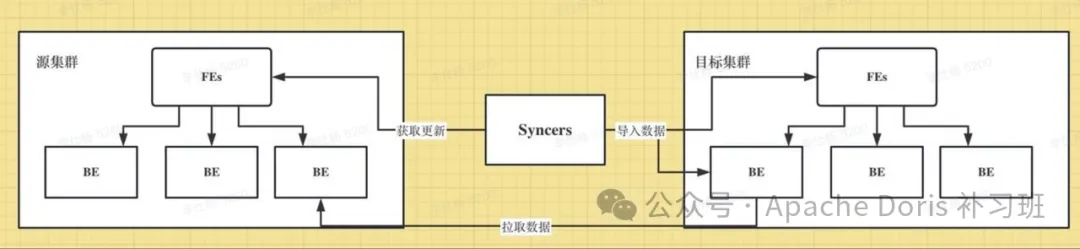
全面介绍 Apache Doris 数据灾备恢复机制及使用示例
引言 Apache Doris 作为一款 OLAP 实时数据仓库,在越来越多的中大型企业中逐步占据着主数仓这样的重要位置,主数仓不同于 OLAP 查询引擎的场景定位,对于数据的灾备恢复机制有比较高的要求,本篇就让我们全面的介绍和示范如何利用这…...

Python pandas常见函数
Pandas库 基本概念读取数据数据处理数据输出其他常用功能 pip install pandas基本概念 数据结构 Series: 一维数据结构 import pandas as pd data pd.Series([10, 20, 30, 40], index[a, b, c, d]) print(data)DataFrame: 二维数据结构 data {Name: [Alice, Bob, Charlie],Ag…...

行业落地分享:阿里云搜索RAG应用实践
最近这一两周看到不少互联网公司都已经开始秋招提前批了。 不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。 最近,我们又陆续整理了很多大厂的面试题,帮助一些球友…...

【SQL】温度比较
目录 题目 分析 代码 题目 表: Weather ------------------------ | Column Name | Type | ------------------------ | id | int | | recordDate | date | | temperature | int | ------------------------ id 是该表具有唯…...

Istio 项目会往用户的 Pod 里注入 Envoy 容器,用来代理 Pod 的进出流量,这是什么设计模式?
Istio 项目会往用户的 Pod 里注入 Envoy 容器,用来代理 Pod 的进出流量,这是什么设计模式? A. 装饰器 B. sidecar C. 工厂模式 D. 单例 选择B Sidecar模式是一种设计模式,它将应用程序的一部分功能作为单独的进程实现ÿ…...
(24.1) FPV和仿真的机载OSD(三))
(24)(24.1) FPV和仿真的机载OSD(三)
文章目录 前言 5 呼号面板 6 用户可编程警告 7 使用SITL测试OSD 8 OSD面板列表 前言 此面板允许在机载 OSD 屏幕上显示业余无线电呼号(或任何其他单个字符串)。它将从 SD 卡根目录下名为“callsign.txt”的文件中读取字符串。 5 呼号面板 此面板允…...

测试开发岗面试总结
某基金管理公司线下测试开发面试题总结。 测开题目如下 可以尝试自己先写,写完之后再去看参考解法哦 ~ 1、编写一段代码,把 list 的数平方(语言不限) ListA [1, 3, 5, 7, 9, 11] 2、使用 Python 语言编写一个日志装饰器 3、进程、线程、协程有什么…...

编程-设计模式 7:桥接模式
设计模式 7:桥接模式 定义与目的 定义:桥接模式将抽象部分与它的实现部分分离,使得它们都可以独立地变化。目的:该模式的主要目的是解耦一个类的抽象部分与其实现部分,使得这两部分可以独立地发展和变化。 实现示例…...

C语言----结构体
结构体 结构体的含义 自定义的数据类型 它是由很多的数据组合成的一个整体,结构型数据 其中的每一个数据,都是结构体的成员 书写的位置: 函数的里面:局部位置,只能再本函数中使用 函数的外面:全局位置,在所有的函数中都可以…...
基于HKELM混合核极限学习机多输出回归预测 (多输入多输出) Matlab代码
基于HKELM混合核极限学习机多输出回归预测(多输入多输出)Matlab代码 每个输出都有以下线性拟合图等四张图!!!具体看图,独家图像!!! 程序已经调试好,替换数据集根据输出个数修改out…...

经纬恒润荣获小米汽车优秀质量奖!
小米SU7上市已超百天,在品质经过客户严选的同时,产量与交付量屡创新高,6-7月连续两个月交付量均超过10000台。为奖励对小米汽车质量和交付做出卓越贡献的合作伙伴团队及个人,小米向质量表现突出的供应商授予了优秀质量奖。经纬恒润…...

Linux 软件编程学习第十一天
1.管道: 进程间通信最简单的形式 2.信号: 内核层和用户层通信的一种方式 1.信号类型: 1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP 6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 1…...

hive udtf 函数:输入一个字符串,将这个字符串按照特殊的逻辑处理之后,输出4个字段
这里要继承GenericUDTF 这个抽象类,直接上代码: package com.xxx.hive.udf; import org.apache.commons.lang.StringUtils; import org.apache.hadoop.hive.ql.exec.Description; import org.apache.hadoop.hive.ql.exec.UDFArgumentException; import …...

【实现100个unity特效之16】unity2022之前或者之后版本实现全屏shader graph的不同方式 —— 适用于人物受伤红屏或者一些其他状态效果
最终效果 文章目录 最终效果前言unity2022版本 Fullscreen shader graph首先,请注意你的Inity版本,是不是2022.2以上,并且项目是URP项且基本配置 修改shader graph边缘效果动起来优化科幻风制作一些变量最终效果最终节点图代码控制 2022之前版…...

比特币使用ord蚀刻符文---简单笔记
说明 毕竟符文热度过了,今年四月份做的笔记分享出来 蚀刻符文需要先同步完区块数据,和index文件,不然蚀刻会失败,在testnet和signet网络也一样。 创建钱包(会输出助记词): ord --bitcoin-da…...

大数据-74 Kafka 高级特性 稳定性 - 控制器、可靠性 副本复制、失效副本、副本滞后 多图一篇详解
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完)HDFS(已更完)MapReduce(已更完&am…...

c# 什么是扩展方法
官方解释 扩展方法使你能够向现有类型“添加”方法,而无需创建新的派生类型、重新编译或以其他方式修改原始类型。 扩展方法是一种静态方法,但可以像扩展类型上的实例方法一样进行调用。 对于用 C#、F# 和 Visual Basic 编写的客户端代码&#x…...

Kerberos身份认证原理与企业级排错实战指南
1. 这不是“另一个登录框”,而是一套精密运转的身份验证齿轮系统很多人第一次听说 Kerberos,是在公司内网登录邮箱或访问内部系统时,看到那个带小盾牌图标的弹窗——“正在使用 Kerberos 协议进行身份验证”。于是下意识觉得:“哦…...

AI大模型应用开发全攻略:从入门到精通,掌握LLM、RAG、Agent核心技能!“
本文全面介绍了AI大模型应用开发的核心技术和实践。从大模型API交互基础,到关键参数Messages和Tools的作用,深入解析了RAG、ReAct、Agent等应用范式。文章还探讨了Fine-tuning微调和Prompt提示词工程的重要性,强调工程实践与业务需求相结合。…...

51单片机驱动ST7735S彩屏避坑指南:从5秒刷屏到流畅贪吃蛇的优化实战
51单片机驱动ST7735S彩屏性能优化实战:从卡顿到流畅游戏的蜕变之路当一块128x160分辨率的ST7735S彩屏遇上传统的51单片机,这种组合看似矛盾却又充满挑战。许多开发者初次尝试时会发现,原本在STM32等平台上运行流畅的显示驱动,移植…...

对称与负电源测试:动态直流电子负载的设计、原理与应用
1. 项目概述:对称与负电源的静态与动态直流负载在电子实验室里,测试一个电源的性能,尤其是它的动态响应能力,是件既基础又关键的事。我们常说的“直流电子负载”就是这个领域的核心工具。我之前设计并分享过一个用于正电源测试的静…...
)
别再用SonarQube凑数了!DeepSeek原生圈复杂度引擎的6大颠覆性能力(含GitHub私有部署密钥)
更多请点击: https://kaifayun.com 第一章:DeepSeek圈复杂度分析的底层原理与范式革命 DeepSeek圈复杂度分析并非传统McCabe度量的简单复刻,而是基于控制流图(CFG)动态重构与语义感知路径裁剪的双重机制构建的新范式。…...

关联规则挖掘在Calabi-Yau流形Hodge数分析中的应用与复现
1. 项目概述:当数据挖掘遇见高维几何在理论物理和代数几何的交叉领域,Calabi-Yau流形一直扮演着核心角色。这些具有特殊拓扑结构的空间,不仅是弦理论中额外维度紧化的关键候选者,其本身丰富的数学性质也吸引着无数研究者。然而&am…...
)
Unity3D深度纹理实战:手把手教你实现可交互的激光雷达扫描特效(附完整C#/Shader代码)
Unity3D深度纹理实战:手把手教你实现可交互的激光雷达扫描特效(附完整C#/Shader代码)在科幻题材的游戏开发中,激光雷达扫描特效是营造科技感的经典元素。从《赛博朋克2077》的战术目镜到《看门狗》的环境扫描,这种动态…...
)
别再只用鼠标了!用Leap Motion手势控制Unity游戏,保姆级配置避坑指南(2024版)
2024年Unity手势交互开发实战:Leap Motion从配置到游戏逻辑全解析在游戏开发领域,交互方式的创新往往能带来全新的体验。想象一下,玩家不再需要键盘鼠标,仅凭自然的手部动作就能操控游戏角色——这正是Leap Motion手势识别技术为U…...

HiveWE终极指南:快速掌握魔兽争霸III现代化地图编辑器
HiveWE终极指南:快速掌握魔兽争霸III现代化地图编辑器 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 还在为传统魔兽争霸III地图编辑器缓慢的加载速度和复杂的操作界面而烦恼吗?Hiv…...

基于Arduino与433MHz射频的智能灯光定时系统设计与实现
1. 项目概述:告别机械定时器,打造智能灯光管家家里前后院的照明,还有出门度假时屋内的几盏灯,过去一直靠四个老旧的机械定时器来管理。说实话,这玩意儿用起来真是费劲。它的核心问题在于“死板”——你设定好晚上7点开…...