C++从入门到起飞之——string类的模拟实现 全方位剖析!

🌈个人主页:秋风起,再归来~
🔥系列专栏:C++从入门到起飞
🔖克心守己,律己则安
目录
1、多文件之间的关系
2、模拟实现常用的构造函数
2.1 无参构造函数
2.2 有参的构造函数
2.3 析构函数(顺便实现)
3、size()、capacity()、[]运算符重载
4、模拟实现简单的正向迭代器
5、reserve、push_back、append
6、operator+=、insert、erase
7、find、substr
8、非成员函数operator比较系列
9、非成员函数operator<<、operator>>
10. 完结散花
1、多文件之间的关系
>string.h
在string.h中我们用来包含各种头文件以及定义我们的string类和非成员函数的声明!
注意:在string.h中string类的定义和非成员函数的声明放到我们自己定义的命名空间my_string中(原因就是为了和库里面的std:string类进行区分!)

>string.cpp
在string.cpp中我们来完成string类中一些(类里面短小频繁调用的函数声明和定义不用分离)成员函数和非成员函数的定义!
注意:在string.cpp中我们要包含“string.h”并且要在命名空间域中完成成员函数和非成员函数的定义!

>test.cpp
这个文件用来测试我们的接口是否有bug!

2、模拟实现常用的构造函数
这里我们实现的是简单的string类,没有搞vs下用buff数组来存放字符串那一套,所以我们就只有三个成员变量:
private:char* _str;//指向字符串的指针size_t _size;//有效字符个数(不包含'\0')size_t _capacity;//空间大小(不包含'\0')注意:这里的有效字符个数_size和空间大小_capacity都不包含'\0'!但我们实际开空间时都会多开一个来存放’\0‘
2.1 无参构造函数
声明:以下实现的函数都是直接在类里面定义(短小频繁调用,在类里面直接默认为inline)
>有误的无参构造函数
string():_str(nullptr)//有问题,标准库里面的是可以输出空字符串的, _size (0),_capacity (0)
{}在写构造函数时,一般我们都是建议显示写初始化列表的,于是我们上来可能就会写出如上的代码!不过上面的代码并不符合C++标准规定,当我们空参构造时,库里面输出的是一个空字符串,而上面写的构造函数却是不能直接访问的空指针!
在测试代码前,因为我们还没有重载流提取和流插入函数,那我们就先实现一个简单的c_str()函数来帮助我们实现打印输出!
>返回C字符串(c_str())
//返回C字符串
const char* c_str() const
{return _str;
}>指定命名空间使用库里面的string
std::string s1;//指定命名空间用的是库里面的string
cout << s1.c_str() << endl;
通过调试我们发现,库里面的string空参构造一个string对象s1时, s1里面存放的是一个’\0‘,并输出一个空字符串!
>未指定命名空间,在命名空间my_string内,优先使用自己实现的string
//未指定命名空间,在命名空间my_string内,优先使用自己实现的string
string s1;
cout << s1.c_str() << endl;
通过调试我们发现,我们模拟实现的string空参构造一个string对象s1时, s1里面存放的是一个nullptr,所以我们在输出时,程序就直接崩溃了!

>正确的无参构造函数
那我们就按照标准库的规定来写,在走初始化列表时开一个空间来存放’\0‘即可!
string():_str(new char[1]{'\0'})//实际的空间大小要比capacity大1来存放'\0', _size (0),_capacity (0)
{}2.2 有参的构造函数
走初始化列表通过计算str的长度来开辟空间并确定_size和_capacity的大小,然后在函数体内将str的值拷贝到_str中,我们就完成了带参数的构造函数!
string(const char* str):_str(new char[strlen(str) + 1]), _size(strlen(str)),_capacity(strlen(str))
{strcpy(_str, str);
}不过这里并不建议走初始化列表,因为每次都要调用strlen(),有性能和效率的消耗。
建议写下面这一种版本!
string(const char* str)//加上缺省值合二为一
{_size = strlen(str);_capacity = _size;_str = new char[_capacity + 1];//记住开空间时多开一个strcpy(_str, str);//会把str的'\0'拷贝进来
}当然,我们还可以将无参构造函数和带参构造函数合二为一!
string(const char* str="")//加上缺省值合二为一
{_size = strlen(str);_capacity = _size;_str = new char[_capacity + 1];//记住开空间时多开一个strcpy(_str, str);//会把str的'\0'拷贝进来
}注意:合二为一之后我们就要将之前写的无参构造函数屏蔽掉,不然编译器不知道调用谁就会报错!(一个类中只能有一个默认构造函数(即可以无参调用的构造函数)!)

2.3 析构函数(顺便实现)
因为有资源的申请,所以我们要显示实现我们的析构函数!
~string()
{delete[] _str;_str = nullptr;_capacity = _size = 0;
}3、size()、capacity()、[]运算符重载
声明:以下实现的函数都是直接在类里面定义(短小频繁调用,在类里面直接默认为inline)
这些接口都比较简单我就不赘述了
//返回size和capacity
size_t size() const
{return _size;
}
size_t capacity() const
{return _capacity;
}
//[]运算符重载
char& operator[](size_t pos)
{assert(pos < _size);return _str[pos];
}
//const版本
const char& operator[](size_t pos) const
{assert(pos < _size);return _str[pos];
}好啦!到这里,我们配合一下前面实现的一些接口,测试一下有没有什么问题!
string s1("hello world");
for (size_t i = 0; i < s1.size(); i++)
{cout << s1[i];
}
cout << endl;
for (size_t i = 0; i < s1.size(); i++)
{s1[i] += 2;cout << s1[i];
}
好,这里看到结果也是没有任何问题的呢!
4、模拟实现简单的正向迭代器
声明:以下实现的函数都是直接在类里面定义(短小频繁调用,在类里面直接默认为inline)
上面用下标访问遍历了我们的string对象,范围for这么方便,那我们也来尝试用它来遍历一下吧!
string s1("hello world");
for (auto ch :s1 )
{cout << ch;
}
完蛋了!一写出来就给我们报了一大堆的错误!
不过,我在上一篇博客里写到了范围for的底层就是迭代器,我们冷静下来思考并结合报错就会发现原来我们自己实现的string类中目前还没有迭代器,所以我们不能用范围for来遍历s1
那我们怎么来实现string类的迭代器呢?
这里我就直接告诉大家,所有的迭代器iterator都是typedef出来的!在这里迭代器其实就是典型的封装的一种体现,所有的容器(链表,队列,树等)都有迭代器,并且使用他们的迭代器的方式都是一样的(即迭代器给我们提供了统一的接口,但其底层的实现并不相同,不过我们在使用时并不关心它底层的细节,我们只要掌握了迭代器的使用方式,就会对所有容器进行操作。这种封装的方式大大方便了我们对容器的使用!)
好啦!到这里我们就来实现一下string类里面简单的一个迭代器吧!
我们上篇文章就说过在string中,正向迭代器的使用就可以把它当做指针来看(不一定是指针),那我们在实现时不就可以参考使用原始指针的方式来实现我们的简单迭代器呢?
1. 我们将char*重新命名为iterator(即iterator就是char* 的类型)
2. 然后我们再实现begin()和end()俩个接口来返回_str的开头和结尾
typedef char* iterator;
//正向迭代器
iterator begin()const
{return _str;
}
iterator end() const
{return _str+_size;
}好啦!到这里我们就实现好了一个简单的正向迭代器!我们来测试一下:
string s1("hello world");for (auto ch :s1 ){cout << ch;}cout<< endl;
我们再简单的实现一下正向常量迭代器!
//正向常量迭代器
typedef const char* const_iterator;
const_iterator cbegin() const
{return _str;
}
const_iterator cend() const
{return _str + _size;
}这里,我们就不实现反向迭代器了(用原始指针已经解决不了了),因为它要用到一个叫适配器的东西(目前我也不知道那是啥玩意),还挺复杂的~
5、reserve、push_back、append
>reserve
标准库里面的reserve只有在预留空间大于容量时才会扩容并且决不改变有效字符个数,strcpy会拷贝到\0!
void string::reserve(size_t n){//标准库里面的reserve只有在预留空间大于容量时才会扩容//并且决不改变有效字符if (n > _capacity){char* tmp = new char[n + 1];//开新空间,记得加一strcpy(tmp, _str);//拷贝数据到新空间delete[] _str;//释放旧空间_str = tmp;//_str指向新空间_capacity = n;}return;}
好啦!写到这里,我们来测试一下上面的接口是否有问题!
string s1("hello world");
cout << "capacity:" << s1.capacity() << endl;
//reserve
s1.reserve(20);
cout << "capacity:" <<s1.capacity() << endl << endl;
string s1("hello world");
cout << "capacity:" << s1.capacity() << endl;
//reserve
s1.reserve(10);
cout << "capacity:" <<s1.capacity() << endl << endl;
好啦, 也是没有任何问题的!
>push_back
先判断是否需要扩容,空间为0,则开4个空间,否则二倍扩,记得要手动放一个'\0'!
void string::push_back(char c)
{//先判断是否需要扩容if (_size == _capacity){ //空间为0,则开4个空间,否则二倍扩!reserve(_capacity == 0 ? 4 : _capacity * 2);}_str[_size++] = c;//有效字符已经更新_str[_size] = '\0';//记得要手动放一个'\0'
}
好啦!写到这里,我们来测试一下上面的接口是否有问题!
string s1("hello world");
cout << s1.c_str() << endl;
s1.push_back('x');
cout << s1.c_str() << endl<<endl;
OK啊!也是没有任何问题的!
>append
先判断是否需要扩容,原字符串与追加的字符串总长度大于2 * _capacity,就开len + _size,否则二倍扩,不要忘了更新_size,strcpy会拷贝到\0!
string& string::append(const char* s){size_t len = strlen(s);if (len + _size > _capacity){//原字符串与追加的字符串总长度大于2 * _capacity,就开len + _size,否则二倍扩reserve(len + _size > 2 * _capacity ? len + _size : 2 * _capacity);}strcpy(_str + _size, s);_size += len;//不要忘了更新_sizereturn *this;}好啦!写到这里,我们来测试一下上面的接口是否有问题!
string s1("hello world");
cout << s1.c_str() << endl;
s1.append("test append ");
cout << s1.c_str() << endl << endl;
6、operator+=、insert、erase
>operator+=
直接复用push_back即可!
string& string::operator+=(char c){push_back(c);return *this;}因为是复用的代码,就不测试了!
>insert(任意位置前插入一个字符)
//任意位置前插入一个字符
string& string::insert(size_t pos, char c)
{assert(pos <=_size);//先判断是否需要扩容if (_size == _capacity){ //空间为0,则开4个空间,否则二倍扩!reserve(_capacity == 0 ? 4 : _capacity * 2);}for (size_t i = _size; i >=pos; i--){//把pos位置开始 的字符全部后移一个位置_str[i + 1] = _str[i];}_str[pos] = c;_size++;return *this;
}
好啦!写到这里,我们来测试一下上面的接口是否有问题!
我们先尾插一个字符!
string s1("hello world");
cout << s1.insert(s1.size(), '*').c_str() << endl << endl;![]()
没有什么问题!
我们再头插一个字符!
string s1("hello world");
cout << s1.insert(0, '&').c_str() << endl << endl;我的发!坏了,程序直接崩溃了。我们程序员最害怕的就是自己写的程序测试出bug来,不过我们不要慌,我们调试一下来解决问题!

按照我们的挪动逻辑,循环结束前后i的位置应该如下!


我们来调试检查检查一下哪里出了问题!

通过调试我们发现头插前 i 的值雀氏为11

所有的数据都按我们的想法挪 动到后面去了,不过!i的值却不是-1,而是一个非常大的数值!
好了,这里我们就大概明白哪里出问题了,这里其实就是C语言遗留下来的一个坑,i的类型是size_t是无符号的整型,当i的值为-1时,其在内存中的补码是全一的序列,而它又是无符号的整型(正数),因此这全一的序列会被认为是该值的原码 (即这是整型的最大值!)
解决这个问题的方法有很多,比如可以用int来解决,不过我这里就直接改变一下挪动的逻辑啦!
for (size_t i = _size+1; i >pos; i--)
{//把pos位置开始 的字符全部后移一个位置_str[i] = _str[i-1];
}这样挪i就不会到-1
>insert(任意位置前插入一个字符串)
注释很详细啦,友友们认真看哦~
//任意位置前插入一个字符串
string& string::insert(size_t pos, const char* s)
{assert(pos <=_size);size_t len = strlen(s);if (len + _size > _capacity){//原字符串与追加的字符串总长度大于2 * _capacity,就开len + _size,否则二倍扩reserve(len + _size > 2 * _capacity ? len + _size : 2 * _capacity);}//把pos位置开始 的字符全部后移len个位置//1、用库函数memmove一个一个字节的拷贝挪动(注意一定要多挪动一个字节,把'\0'也挪动到后面去)memmove(_str + pos + len, _str + pos, (len+1) * sizeof(char));//2、手动挪/*for (size_t i = _size + len; i > pos+len-1; i--){_str[i] = _str[i - len];}*///一个一个字符拷贝for (size_t i = 0; i < len ; i++){_str[pos+i] =s[i];}_size += len;return *this;
}>erase
string& erase(size_t pos, size_t len=npos);上面的代码是类里面的成员函数声明有缺省值npos(这是在类里面声明的一个静态的常量成员)
static const size_t npos;注意:
//static const size_t npos=-1;
//特殊的可以在声明(类内部)处定义的static成员变量
//而且只有整形可以
//static const double d = 1.1;报错:const double类型不能包含类内初始值设定项
不过,我们这里还是建议让静态成员变量定义到类外中,不过,我们要注意定义一定不要在头文件中,不然我们在test.cpp和string.cpp中包含了俩次npos的定义,这时在链接时编译器就找不到重复定义的成员从而发生链接错误!

所以我们在string.cpp中定义npos!

声明处给了缺省值,定义处就不能显示写缺省值了!先判断pos的有效性,再判断从pos位置开始的字符够不够删,如果不够,直接在pos位置放\0,并更新有效字符的个数为pos。如果够删,就走挪动的逻辑!
从任意位置开始删除len个字符string& string::erase(size_t pos, size_t len){assert(pos < _size);if (len >= _size - pos){_str[pos] = '\0';_size = pos;}else{//把pos+len位置开始的字符全部前移len个位置//1、用库函数memmove一个一个字节的挪动(注意一定要多挪动一个字节,把'\0'也挪动到后前 //面去)//memmove(_str + pos, _str +pos+ len, (_size -pos+1) * sizeof(char));//2、手动挪for (size_t i = pos + len; i <=_size; i++){_str[i-len] = _str[i];}_size -= len;}return *this;}7、find、substr
>find(从pos位置开始找字符c)
循环遍历查找即可,没什么好说的,但要注意如果没有找到返回npos
//从pos位置开始找字符c
size_t string::find(char c, size_t pos )
{assert(pos < _size);for (size_t i = pos; i < _size; i++){if (_str[i] == c){return i;}}return npos;
}>find从(pos位置开始找字符串s)
找子串问题,可以用kmp算法,但该算法在实际应用中用的并不多(C语言中strstr用的就不是该算法),而BM算法就用的较多,不过BM算法较为复杂,有兴趣的小伙伴可以自己去查阅一下资料哦!我们下面就直接使用库里面的函数来匹配子串了!
//从pos位置开始找字符串s
size_t string::find(const char* s, size_t pos )
{assert(pos < _size);char* ret=strstr(_str + pos, s);if (ret == nullptr){return npos;}return ret - _str;
}>substr(从pos位置开始取子串)
//从pos位置开始取子串
string string::substr(size_t pos, size_t len)
{if (len > _size-pos){len = _size - pos;}string sub;sub.reserve(len);for (size_t i = pos; i < _size; i++){sub += _str[i];}return sub;
}测试代码:
string s1("hello world");
string s2 = s1.substr(6);
cout << s2.c_str() << endl;这里我就直接说结论,我们上面的代码还是有问题的,我们在vs2022debug版本上测试倒不会出现什么问题,但vs2019或更早一点的版本就会有运行时错误。因为我还没有安装更早的版本,这里就没办法演示了。
那到底是哪里出了问题呢?我们在函数里面创建了一个局部变量sub来暂时存放取到的子串,并传值返回,在传值返回时,函数还会先调用拷贝构造来拷贝一个临时的string对象,然后再用临时的string对象来拷贝构造我们在函数外面用来接收返回值的string对象s2

不过,编译器默认的拷贝构造是浅拷贝,即将对象一个一个字节的拷贝构造另一个对象

通过调试我们发现s2的_str和sub的_str指向的是同一块空间!当sub出函数的局部作用域时,sub对象就会调用析构函数而销毁,而其所指向的空间也同时被释放!

所以,当一个类里面有成员向内存申请资源时,我们就不能使用编译器默认生成的拷贝构造了,必须自己显示生成拷贝构造进行深拷贝!
//拷贝构造(深拷贝)
string(const string& s)
{_str = new char[s._capacity + 1];strcpy(_str, s._str);_size = s._size;_capacity = s._capacity;
}那为什么在vs2022debug版本上测试倒不会出现什么问题呢?这里简单的说一下,在进行传值拷贝构造时,编译器可能不会进行sub对象的创建,直接用临时对象拷贝构造s2,而在这里,编译器的优化更为激进直接和三为一,sub和临时对象都不创建了,直接拷贝构造s2!所以也就不存在同一块空间被多次析构的问题了!
8、非成员函数operator比较系列
这个系列比较简单,大家看看代码就明白了!
bool operator<(const string& s1, const string& s2)
{return strcmp(s1.c_str(), s2.c_str()) < 0;
}
bool operator<=(const string& s1, const string& s2)
{return s1 < s2 || s1 == s2;
}
bool operator>(const string& s1, const string& s2)
{return !(s1 <= s2);
}
bool operator>=(const string& s1, const string& s2)
{return !(s1 < s2);
}
bool operator==(const string& s1, const string& s2)
{return strcmp(s1.c_str(), s2.c_str()) == 0;
}
bool operator!=(const string& s1, const string& s2)
{return !(s1 == s2);
}9、非成员函数operator<<、operator>>
> operator<<
ostream& operator<<(ostream& out, const string& s)
{for (auto ch : s){out << ch;}return out;
}
> operator>>
istream& operator>>(istream& in, string& s)
{s.clear();//先清理有效字符char ch;in >> ch;//将流里面的字符插入到ch中while (ch != ' ' && ch != '\n'){s += ch;in >> ch;}s += '\0';//末尾记得加上'\0'return in;
}上面的代码看似没问题,其实这样写in读取不到缓冲区里面的换行和空格,与scanf一样,cin在读取字符时,默认将空格和换行视为字符分割符不进行读取(记住就行)!所以我们就可以用in.get()来读取每一个字符,作用和getc一样!
istream& operator>>(istream& in, string& s)
{s.clear();//先清理有效字符char ch;ch = in.get();//将流里面的字符插入到ch中while (ch != ' ' && ch != '\n'){s += ch;ch = in.get();}s += '\0';//末尾记得加上'\0'return in;
}如果字符串很长,会有频繁的扩容消耗,可以优化一下
istream& operator>>(istream& in, string& s)
{s.clear();//先清理有效字符const size_t N = 256;int i = 0;char buff[N];//用一个buff数组做我们的缓冲char ch= in.get();while (ch != ' ' && ch != '\n'){buff[i++] = ch;if (i == N - 1)//数组满了再把字符加进s中,避免频繁扩容{buff[i] = '\0';i = 0;s += buff;}ch = in.get();}if (i > 0)//把最后一组没有满的也加上{buff[i] = '\0';s += buff;}return in;
}10、完整代码
>string.h
#pragma once#include<iostream>
#include<assert.h>
using namespace std;namespace my_string
{class string{public://类里面短小频繁调用的函数声明和定义不用分离//1、无参构造函数//string()// :_str(new char[1]{'\0'})//实际的空间大小要比capacity大1来存放'\0'// , _size (0)// ,_capacity (0)//{}// string()// :_str(nullptr)//有问题,标准库里面的是可以输出空字符串的// , _size (0)// ,_capacity (0)//{}//2、有参的构造函数string(const char* str="")//加上缺省值合二为一{_size = strlen(str);_capacity = _size;_str = new char[_capacity + 1];//记住开空间时多开一个strcpy(_str, str);//会把str的'\0'拷贝进来}/** 不建议走初始化列表,每次都要调用strlen()!string(const char* str):_str(new char[strlen(str) + 1]), _size(strlen(str)),_capacity(strlen(str)){strcpy(_str, str);}*///3、析构函数~string(){delete[] _str;_str = nullptr;_capacity = _size = 0;}//4、返回C字符串const char* c_str() const{return _str;}//5、返回size和capacitysize_t size() const{return _size;}size_t capacity() const{return _capacity;}//6、[]运算符重载char& operator[](size_t pos){assert(pos < _size);return _str[pos];}//const版本const char& operator[](size_t pos) const{assert(pos < _size);return _str[pos];}//7、实现两个简单的迭代器typedef char* iterator;//正向迭代器iterator begin()const {return _str;}iterator end() const{return _str+_size;}//正向常量迭代器typedef const char* const_iterator;const_iterator cbegin() const{return _str;}const_iterator cend() const{return _str + _size;}//拷贝构造(深拷贝)string(const string& s){_str = new char[s._capacity + 1];strcpy(_str, s._str);_size = s._size;_capacity = s._capacity;}//显示赋值运算符重载string& operator=(const string& s){if (this != &s){delete[] _str;_str = new char[s._capacity + 1];strcpy(_str, s._str);_size = s._size;_capacity = s._capacity;}return *this;}void clear(){_str[0] = '\0';_size = 0;}//下面的成员函数声明和定义分离//0、预留空间void reserve(size_t n);//1、尾插一个字符void push_back(char c);//2、追加一个字符串string& append(const char* s);//3、+=一个字符string& operator+=(char s);//4、+=一个字符串string& operator+=(const char* s);//5、任意位置插入一个字符string& insert(size_t pos, char c);//6、任意位置插入一个字符串string& insert(size_t pos,const char* s);//7、从任意位置删除len个字符string& erase(size_t pos, size_t len=npos);//8、从pos位置开始找字符csize_t find(char c, size_t pos = 0);//9、从pos位置开始找字符串ssize_t find(const char* s, size_t pos = 0);//10、从pos位置开始取子串string substr(size_t pos = 0, size_t len = npos);private:char* _str;//指向字符串的指针size_t _size;//有效字符个数(不包含'\0')size_t _capacity;//空间大小(不包含'\0')static const size_t npos;//static const size_t npos=-1;//特殊的可以在声明(类内部)处定义的static成员变量//而且只有整形可以//static const double d = 1.1;报错:const double类型不能包含类内初始值设定项friend ostream& operator<<(ostream& out, const string& s);};//const size_t string::npos = -1;//非成员函数!bool operator<(const string& s1, const string& s2);bool operator<=(const string& s1, const string& s2);bool operator>(const string& s1, const string& s2);bool operator>=(const string& s1, const string& s2);bool operator==(const string& s1, const string& s2);bool operator!=(const string& s1, const string& s2);ostream& operator<<(ostream& out, const string& s);istream& operator>>(istream& in, string& s);
}>string.cpp
#define _CRT_SECURE_NO_WARNINGS#include"string.h"namespace my_string
{const size_t string::npos = -1;void string::reserve(size_t n){//标准库里面的reserve只有在预留空间大于容量时才会扩容//并且决不改变有效字符if (n > _capacity){char* tmp = new char[n + 1];//开新空间,记得加一strcpy(tmp, _str);//拷贝数据到新空间delete[] _str;//释放旧空间_str = tmp;//_str指向新空间_capacity = n;}return;}void string::push_back(char c){//先判断是否需要扩容if (_size == _capacity){ //空间为0,则开4个空间,否则二倍扩!reserve(_capacity == 0 ? 4 : _capacity * 2);}_str[_size++] = c;_str[_size] = '\0';//记得要手动放一个'\0'}string& string::append(const char* s){size_t len = strlen(s);if (len + _size > _capacity){//原字符串与追加的字符串总长度大于2 * _capacity,就开len + _size,否则二倍扩reserve(len + _size > 2 * _capacity ? len + _size : 2 * _capacity);}strcpy(_str + _size, s);_size += len;//不要忘了更新_sizereturn *this;}string& string::operator+=(char c){push_back(c);return *this;}string& string::operator+=(const char* s){append(s);return *this;}//5、任意位置前插入一个字符string& string::insert(size_t pos, char c){assert(pos <=_size);//先判断是否需要扩容if (_size == _capacity){ //空间为0,则开4个空间,否则二倍扩!reserve(_capacity == 0 ? 4 : _capacity * 2);}//for (size_t i = _size; i >=pos; i--)//{// //把pos位置开始 的字符全部后移一个位置// _str[i + 1] = _str[i];// //这种写法有bug//}for (size_t i = _size+1; i >pos; i--){//把pos位置开始 的字符全部后移一个位置_str[i] = _str[i-1];}_str[pos] = c;_size++;return *this;}//6、任意位置前插入一个字符串string& string::insert(size_t pos, const char* s){assert(pos <=_size);size_t len = strlen(s);if (len + _size > _capacity){//原字符串与追加的字符串总长度大于2 * _capacity,就开len + _size,否则二倍扩reserve(len + _size > 2 * _capacity ? len + _size : 2 * _capacity);}//把pos位置开始 的字符全部后移len个位置//1、用库函数memmove一个一个字节的拷贝挪动(注意一定要多挪动一个字节,把'\0'也挪动到后面去)memmove(_str + pos + len, _str + pos, (len+1) * sizeof(char));//2、手动挪/*for (size_t i = _size + len; i > pos+len-1; i--){_str[i] = _str[i - len];}*/for (size_t i = 0; i < len ; i++){_str[pos+i] =s[i];}_size += len;return *this;}//7、从任意位置开始删除len个字符string& string::erase(size_t pos, size_t len){assert(pos < _size);if (len >= _size - pos){_str[pos] = '\0';_size = pos;}else{//把pos+len位置开始的字符全部前移len个位置//1、用库函数memmove一个一个字节的挪动(注意一定要多挪动一个字节,把'\0'也挪动到后前面去)//memmove(_str + pos, _str +pos+ len, (_size -pos+1) * sizeof(char));//2、手动挪for (size_t i = pos + len; i <=_size; i++){_str[i-len] = _str[i];}_size -= len;}return *this;}//8、从pos位置开始找字符csize_t string::find(char c, size_t pos ){assert(pos < _size);for (size_t i = pos; i < _size; i++){if (_str[i] == c){return i;}}return npos;}//9、从pos位置开始找字符串ssize_t string::find(const char* s, size_t pos ){assert(pos < _size);char* ret=strstr(_str + pos, s);if (ret == nullptr){return npos;}return ret - _str;}//10、从pos位置开始取子串string string::substr(size_t pos, size_t len){if (len > _size-pos){len = _size - pos;}string sub;sub.reserve(len);for (size_t i = pos; i < _size; i++){sub += _str[i];}//注意一定要自己实现拷贝构造,sub是局部的return sub;}bool operator<(const string& s1, const string& s2){return strcmp(s1.c_str(), s2.c_str()) < 0;}bool operator<=(const string& s1, const string& s2){return s1 < s2 || s1 == s2;}bool operator>(const string& s1, const string& s2){return !(s1 <= s2);}bool operator>=(const string& s1, const string& s2){return !(s1 < s2);}bool operator==(const string& s1, const string& s2){return strcmp(s1.c_str(), s2.c_str()) == 0;}bool operator!=(const string& s1, const string& s2){return !(s1 == s2);}ostream& operator<<(ostream& out, const string& s){for (auto ch : s){out << ch;}return out;}//>1、这样写有问题!读取不到换行和'\0'//istream& operator>>(istream& in, string& s)//{// s.clear();//先清理有效字符// char ch;// in >> ch;//将流里面的字符插入到ch中// while (ch != ' ' && ch != '\n')// {// s += ch;// in >> ch;// }// s += '\0';//末尾记得加上'\0'// return in;//}//>2、如果字符串很长,会有频繁的扩容消耗,可以优化一下//istream& operator>>(istream& in, string& s)//{// s.clear();//先清理有效字符// char ch;// ch = in.get();//将流里面的字符插入到ch中// while (ch != ' ' && ch != '\n')// {// s += ch;// ch = in.get();// }// s += '\0';//末尾记得加上'\0'// return in;//}istream& operator>>(istream& in, string& s){s.clear();//先清理有效字符const size_t N = 256;int i = 0;char buff[N];//用一个buff数组做我们的缓冲char ch= in.get();while (ch != ' ' && ch != '\n'){buff[i++] = ch;if (i == N - 1)//数组满了再把字符加进s中,避免频繁扩容{buff[i] = '\0';i = 0;s += buff;}ch = in.get();}if (i > 0)//把最后一组没有满的也加上{buff[i] = '\0';s += buff;}return in;}
}>test.cpp
#include"string.h"
using namespace my_string;
namespace my_string
{void test_my_string1(){string s1;cout << s1.c_str() << endl;/*string s2("hello world");cout << s2.c_str() << endl;*/}void test_my_string2(){/* string s1("hello world");for (size_t i = 0; i < s1.size(); i++){cout << s1[i];}cout << endl;for (size_t i = 0; i < s1.size(); i++){s1[i] += 2;cout << s1[i];}cout << endl;*///string::const_iterator it = s1.cbegin();//while (it != s1.cend())//{// //*it += 2;报错:表达式必须是可修改的左值// cout << *it;// it++;//}//cout << endl;string s1("hello world");for (auto ch :s1 ){cout << ch;}cout<< endl;}void test_my_string3(){//string s1("hello world");//cout << "capacity:" << s1.capacity() << endl;reserve//s1.reserve(10);//cout << "capacity:" <<s1.capacity() << endl << endl;//push_back/*string s1("hello world");cout << s1.c_str() << endl;s1.push_back('x');cout << s1.c_str() << endl<<endl;*/+=//cout << s1.c_str() << endl;//s1 += '&';//cout << s1.c_str() << endl << endl;//append/*string s1("hello world");cout << s1.c_str() << endl;s1.append("test append ");cout << s1.c_str() << endl << endl;*///append//cout << s1.c_str() << endl;//s1+="test+= ";//cout << s1.c_str() << endl << endl;}void test_my_string4() {//Test insert/*string s1("hello world");cout << s1.insert(s1.size(), '*').c_str() << endl << endl;*/string s1("hello world");cout << s1.insert(0, '&').c_str() << endl << endl;//cout << s1.insert(s1.size(), "test insert s").c_str() << endl << endl;/*string s2("hello world");s2.erase(6,2);cout << s2.c_str()<<endl;s2.erase(0,8);cout << s2.c_str() << endl;*/}void test_my_string5(){//Test findstring s1("hello world");/*size_t ret = s1.find("llo");cout << ret << endl;*/string s2 = s1.substr(6);cout << s2.c_str() << endl;}void test_my_string6(){//Test << >>string s1="hello world";cout << s1 << endl;cin >> s1;cout << s1;}
}int main()
{test_my_string5();
}11. 完结散花
好了,这期的分享到这里就结束了~
如果这篇博客对你有帮助的话,可以用你们的小手指点一个免费的赞并收藏起来哟~
如果期待博主下期内容的话,可以点点关注,避免找不到我了呢~
我们下期不见不散~~


相关文章:
C++从入门到起飞之——string类的模拟实现 全方位剖析!
🌈个人主页:秋风起,再归来~🔥系列专栏:C从入门到起飞 🔖克心守己,律己则安 目录 1、多文件之间的关系 2、模拟实现常用的构造函数 2.1 无参构造函数 2.2 有参的构造函数 2.3 析构函…...

数据库国产化大趋势下,还需要学习Oracle吗?
由于众所周知的原因,近两年各行各业都开始了数据库国产化替代的进程,从国外商业数据库替换到国产或者开源数据库,相信很多的数据库从业人员会把部分精力转移到其他数据库产品的学习中,也有一些人在大肆的宣扬Oracle已经过时了&…...

WebLogic
二、WebLogic 2.1 后台弱口令GetShell 漏洞描述 通过弱口令进入后台界面,上传部署war包,getshell 影响范围 全版本(前提后台存在弱口令) 漏洞复现 默认账号密码:weblogic/Oracle123weblogic常用弱口令: Default Passwords | CIRT.net这里注意&am…...

Aspose.Words.dll 插入模板表格,使用的是邮件合并MailMerge功能,数据源是DataTable或list对象,实例
本实例中的实例功能有: 1、 Aspose.Words.dll 插入模板指定域替换为文字或html标签,见1 2、Aspose.Words.dll 插入模板表格,使用的是邮件合并MailMerge功能,数据源是DataTable或List对象(将list转换成DataTable),见1和2 3、word转换Pdf文件,见1 4、将多个word输出文…...

同时打开多个微信
注: 以下方法用到的 D:\微信\WeChat\WeChat.exe是我的电脑微信路径,可右击桌面微信快捷方式 > 属性 > 目标查看 以下方法都需要先关掉已登录的微信后操作 <一> 找到微信路径 新建一个txt文件输入以下内容 start D:\微信\WeChat\WeChat.exe …...

MPU6050的STM32数据读取
目录 1. 概述2. STM32G030对MPU6050的读取3. STM32F1xx对MPU6050的读取 1. 概述 项目中,往往需要根据不同的环境使用不同的芯片处理某些数据,当使用不同的芯片对六轴陀螺仪芯片MPU6050进行数据处理中,硬件的连接、I/O口的设置往往需要根据相…...

【微信小程序开发】——奶茶点餐小程序的制作(二)
👨💻个人主页:开发者-曼亿点 👨💻 hallo 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 👨💻 本文由 曼亿点 原创 👨💻 收录于专栏:…...

Java 文件上传七牛云
Java系列文章目录 文章目录 Java系列文章目录一、前言二、学习内容:三、问题描述四、解决方案:4.1 新建空间4.2 查找密钥4.3 进入开发者中心查找JavaSDK文档4.4 查找文件上传方法4.5 运行测试 五、总结:5.1 学习总结: 一、前言 学…...
可以执行的指令序列)
大语言模型生成无人系统(如机械臂、无人机等)可以执行的指令序列
大语言模型生成无人系统(如机械臂、无人机等)可以执行的指令序列涉及将自然语言指令转化为具体的、可执行的指令集合。以下是一个详细的流程,展示了如何从自然语言指令生成无人系统的执行指令序列。 1. 输入自然语言指令 用户输入自然语言指…...

尚硅谷谷粒商城项目笔记——十、调试前端项目renren-fast-vue【电脑CPU:AMD】
十、调试前端项目renren-fast-vue 如果遇到其他问题发在评论区,我看到后解决 1 先下载安装git git官网下载地址 2 登录gitee搜索人人开源找到renren-fast-vue复制下载链接。【网课视频中也有详细步骤】 3 下载完成后桌面会出现renren-fast-vue的文件夹 4 开始调…...

Python 的元组和列表的区别是什么?
以下是 Python 中元组(tuple)和列表(list)的主要区别: 1. 语法表示:元组使用小括号 () 来定义,例如 (1, 2, 3) ;列表使用方括号 [] 来定义,例如 [1, 2, 3] 。 2. 可变性…...

【Impala】学习笔记
Impala学习笔记 【一】Impala介绍【1】简介(1)简介(2)优点(3)缺点 【2】架构(1)Impalad(守护进程)(2)Statestore(存储状态…...
视频汇聚平台EasyCVR接入移动执法记录仪,视频无法播放且报错500是什么原因?
GB28181国标视频汇聚平台EasyCVR视频管理系统以其强大的拓展性、灵活的部署方式、高性能的视频能力和智能化的分析能力,为各行各业的视频监控需求提供了优秀的解决方案。视频智能分析平台EasyCVR支持多协议接入,兼容多类型的设备,包括IPC、NV…...

【Linux基础】Linux基本指令(二)
目录 🚀前言一,mv指令二,more & less指令2.1 more 指令2.1 less指令 三,重定向技术(重要)3.1 echo指令3.2 输出重定向 >3.3 追加重定向 >>3.4 输入重定向 < 四,head & tail指令4.1 head 指令4.2 t…...
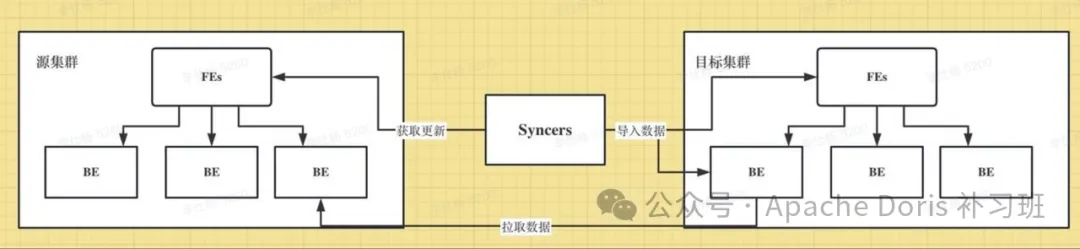
全面介绍 Apache Doris 数据灾备恢复机制及使用示例
引言 Apache Doris 作为一款 OLAP 实时数据仓库,在越来越多的中大型企业中逐步占据着主数仓这样的重要位置,主数仓不同于 OLAP 查询引擎的场景定位,对于数据的灾备恢复机制有比较高的要求,本篇就让我们全面的介绍和示范如何利用这…...

Python pandas常见函数
Pandas库 基本概念读取数据数据处理数据输出其他常用功能 pip install pandas基本概念 数据结构 Series: 一维数据结构 import pandas as pd data pd.Series([10, 20, 30, 40], index[a, b, c, d]) print(data)DataFrame: 二维数据结构 data {Name: [Alice, Bob, Charlie],Ag…...

行业落地分享:阿里云搜索RAG应用实践
最近这一两周看到不少互联网公司都已经开始秋招提前批了。 不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。 最近,我们又陆续整理了很多大厂的面试题,帮助一些球友…...

【SQL】温度比较
目录 题目 分析 代码 题目 表: Weather ------------------------ | Column Name | Type | ------------------------ | id | int | | recordDate | date | | temperature | int | ------------------------ id 是该表具有唯…...

Istio 项目会往用户的 Pod 里注入 Envoy 容器,用来代理 Pod 的进出流量,这是什么设计模式?
Istio 项目会往用户的 Pod 里注入 Envoy 容器,用来代理 Pod 的进出流量,这是什么设计模式? A. 装饰器 B. sidecar C. 工厂模式 D. 单例 选择B Sidecar模式是一种设计模式,它将应用程序的一部分功能作为单独的进程实现ÿ…...
(24.1) FPV和仿真的机载OSD(三))
(24)(24.1) FPV和仿真的机载OSD(三)
文章目录 前言 5 呼号面板 6 用户可编程警告 7 使用SITL测试OSD 8 OSD面板列表 前言 此面板允许在机载 OSD 屏幕上显示业余无线电呼号(或任何其他单个字符串)。它将从 SD 卡根目录下名为“callsign.txt”的文件中读取字符串。 5 呼号面板 此面板允…...

CVPR 2023反无人机数据集实战:用ModelScope上的开源模型快速上手目标检测
CVPR 2023反无人机数据集实战:用ModelScope上的开源模型快速上手目标检测无人机技术的普及带来了新的安全挑战,从隐私侵犯到关键设施威胁,反无人机技术正成为计算机视觉领域的热点。CVPR 2023反无人机竞赛提供的开源数据集和基线模型…...

机器学习与深度学习在地球物理勘探中的应用:基于电阻率数据预测极化率模型
1. 项目概述与核心价值在花岗岩这类地质条件复杂的地区搞勘探,最头疼的就是地下情况“看不清”。传统的电阻率(ERT)和激发极化(IP)联合反演,就像用一把刻度模糊的尺子去量一块表面坑洼不平的石头——面对高…...

MBTI性格测试
简介 MBTI(Myers‑Briggs Type Indicator,迈尔斯‑布里格斯类型指标)是基于荣格心理类型理论发展出的性格类型工具,由凯瑟琳库克布里格斯及其女儿伊莎贝尔布里格斯迈尔斯创建。它通过四对偏好维度将个体的认知与行为倾向归纳为 16…...

贵阳婚礼西服定制攻略:面料、工艺、版型避坑指南
婚礼西装是男士婚礼造型的核心,区别于日常商务正装,婚礼西服更看重版型精致度、面料质感、上身挺拔感以及镜头适配度。在贵阳备婚的新人,大多会放弃成品西装,选择专属定制服务。但本地婚礼西服定制市场参差不齐,很多新…...
)
Postgresql基础实践教程(九)
⭐️⭐️⭐️⭐️⭐️ 完整数据详见 练习数据免费 ⭐️⭐️⭐️⭐️⭐️ 七十二、WITH查询(公用表表达式CTE) 1. SELECT 中的 WITH 2. 递归查询 3. 公用表表达式的物化 4. WITH中的数据修改语句 WITH提供了一种在主查询中写辅助语句的方法。这些语…...

Burp抓包失败的五大隐形墙与HTTPS解密断裂点排查指南
1. 这不是Burp用得不对,是环境链路断在了你没看见的地方“Burp抓不到包”——这句话我过去三年里听开发、测试、刚转安全的新人说了不下两百遍。但真正打开Burp一看,Proxy标签页里空空如也,连个localhost:8080的请求都没有,十有八…...

反向海淘站点常见配置故障复盘与数据一致性优化方案
摘要反向海淘独立站运行过程中,容易出现价格换算异常、页面语种错乱、商品同步失败、订单状态停滞、运费计算偏差等问题。多数故障并非系统底层缺陷,而是配置逻辑理解偏差、数据规范不统一引发。本文结合实际运维场景,汇总高频故障成因&#…...

Python Android打包终极指南:5个实战技巧解决移动开发痛点
Python Android打包终极指南:5个实战技巧解决移动开发痛点 【免费下载链接】python-for-android Turn your Python application into an Android APK 项目地址: https://gitcode.com/gh_mirrors/py/python-for-android Python-for-Android(简称p4…...

如何用Nucleus Co-Op让单机游戏变身本地多人分屏神器
如何用Nucleus Co-Op让单机游戏变身本地多人分屏神器 【免费下载链接】nucleuscoop Starts multiple instances of a game for split-screen multiplayer gaming! 项目地址: https://gitcode.com/gh_mirrors/nu/nucleuscoop 还在为想和朋友一起玩游戏却只有一台电脑而烦…...

从无人机到自动驾驶:一文读懂ROS中ENU、NED、相机坐标系到底怎么用
从无人机到自动驾驶:ROS中ENU、NED与相机坐标系实战指南 当你在无人机上安装Realsense相机时,是否遇到过相机数据与飞控数据"对不上"的情况?或者在自动驾驶项目中,GPS的北东地坐标如何与激光雷达的东北天坐标对齐&#…...