分布式消息队列Kafka
分布式消息队列Kafka
简介: Kafka 是一个分布式消息队列系统,用于处理实时数据流。消息按照主题(Topic)进行分类存储,发送消息的实体称为 Producer,接收消息的实体称为 Consumer。Kafka 集群由多个 Kafka 实例(Server)组成,每个实例称为 Broker。
主要用途: 广泛应用于构建实时数据管道和流应用程序,适用于需要高吞吐量和低延迟的数据处理场景
依赖: Kafka 集群和消费者依赖 Zookeeper 集群来保存元数据信息(如偏移量、Broker 列表等),以确保系统的可用性和一致性。Zookeeper 是 Kafka 的协调服务,用于管理和监控 Kafka 的状态。
- 一、Kafka 数据交互与 JMS 模型的借鉴
- 二、Kafka 特性
- 三、Kafka 场景应用
- 四、Kafka的安装
- 五、Kafka命令行操作
- 六、Kafka Scala API
- 七、Kafka与大数据的集成
一、Kafka 数据交互与 JMS 模型的借鉴
1.1 数据交互
- 线程间交互:通过共享堆内存实现。
- 进程间交互:通过 Socket 实现。
使用消息中间件的原因:缓冲与解耦
- 资源管理:在生产速度远大于消费速度时,使用消息中间件可以防止内存和磁盘资源耗尽。
- 降低负担:消息中间件可以帮助生产者将数据分类并分发给不同的消费者,从而减少生产者的处理负担。
- 系统解耦:通过消息中间件,生产者与消费者无需直接连接,降低系统耦合度,提高系统的可用性和可扩展性。
1.2 Kafka 与 JMS 的借鉴与区别
- JMS (Java Message Service) 模型:
- P2P(点对点)模型:一条消息只会被消费一次,具有反馈机制。
- PS(发布/订阅)模型:消息可以被多个消费者订阅和消费。
- Kafka 的借鉴与区别:
- 借鉴但不完全遵循 JMS:虽然 Kafka 参考了 JMS 的模型,但它与传统的消息中间件(如 RabbitMQ、ActiveMQ、RocketMQ)有所不同。
- 术语对比
- 消息(Message) 在 Kafka 中称为 记录(Record)。
- JMS Provider 在 Kafka 中称为 Kafka Broker。
- 消费顺序的索引 在 Kafka 中称为 偏移量(Offset)。
二、Kafka 特性
2.1 核心特性
- 高吞吐量:Kafka 能够处理大量数据流,特别适用于实时数据管道和流应用程序,能够在大规模数据传输中保持高性能。
- 可扩展性:Kafka 可以通过增加 Broker 和分区的方式水平扩展,支持数据处理能力的动态增长。
- 容错性:Kafka 采用多副本机制和分布式架构,确保数据在副本之间的同步,从而提供高可用性和容错能力。
- 持久性和可复制性:Kafka 支持将消息持久化存储在磁盘上,并在多个副本间进行复制,以保证数据的安全性和一致性。
2.2 多副本机制
- 容错性(In-Sync Replicas, ISR)
- Kafka 通过多副本机制确保数据的高可用性。ISR 是一组与 Leader 副本保持同步的副本,当 Leader 副本丢失时,会从 ISR 中选出一个新的 Leader。
- 如果 ISR 中的副本宕机,Kafka 将从剩余的副本中选择替代者,以保持系统的可用性和数据的完整性。
- 读写分离
- 在 Kafka 中,Leader 副本负责写操作,ISR 中的任何副本都可以处理读操作。这种设计能够提高系统的读写性能,避免单点性能瓶颈。
2.3 多分区机制
- 分区(Partitions)
- Kafka 的主题(Topic)被分成多个分区,每个分区可以分布在不同的节点上。通过这种方式,Kafka 实现了数据的并行处理能力,提高了系统的吞吐量。
- 分区数量的设计通常考虑节点数与物理核数,以保证在实现高性能的同时最大化资源的利用率。
- 低延迟
- Kafka 的多分区机制有助于实现低延迟的数据处理。由于数据可以在多个分区上并行处理,Kafka 能够在处理大规模数据流时保持较低的延迟。
2.4 零拷贝技术
- Kafka 采用零拷贝(Zero-Copy)技术,通过直接将数据从磁盘传输到网络,减少了 CPU 的负载,显著提高了数据传输的效率。这种技术使得 Kafka 能够在高吞吐量的场景中保持低资源消耗。
2.5 产销解耦
- 生产者和消费者的解耦:
- Kafka 实现了生产者与消费者的解耦。生产者将数据写入 Kafka,而消费者从 Kafka 中读取数据,这种设计使得生产者和消费者可以独立扩展。
- 分区机制使得多个生产者可以通过轮询的方式将数据均匀地写入到不同的分区,从而实现负载均衡。同样,多个消费者也可以并行地从不同的分区读取数据,提高了数据处理的并发性。
- 消费模式:
- 指定位置消费:消费者可以从指定的位置开始消费数据,例如使用
--from-beginning标志从头开始消费。 - 分组消费(Group Consumption):消费者可以通过指定
--group-id参数加入消费组,Kafka 在服务端会存储分组名、主题和偏移量的映射关系,从而实现多消费者的协调消费。 - 客户端记录消费位置:消费者还可以自行记录消费位置,如使用 Redis 或 MySQL 来记录偏移量,方便在消费者重启或故障恢复时继续从上次消费的地方开始。
- 指定位置消费:消费者可以从指定的位置开始消费数据,例如使用
三、Kafka 场景应用
Kafka 广泛应用于各种需要处理大规模实时数据流的场景
3.1 日志收集与聚合
- 应用日志收集
- Kafka 常用于集中式日志管理,将来自不同应用的日志收集到统一的 Kafka 主题中,然后通过消费者将这些日志写入到持久化存储(如 HDFS、Elasticsearch)进行分析和检索。
- 这种方法可以实时监控应用程序的运行状况,快速定位问题,并支持日志数据的长期保存和历史回溯。
3.2 实时数据流处理
- 实时数据分析
- Kafka 作为数据流的中转站,将来自各种数据源的实时数据传递给流处理框架(如 Apache Storm、Apache Flink、Apache Spark Streaming)进行实时分析。
- 这种场景下,Kafka 可以处理点击流、用户行为日志、传感器数据等,并将分析结果实时反馈到业务系统中。
3.3 数据管道与ETL
- 数据管道
- Kafka 常用于构建跨系统的数据管道,将数据从一个系统可靠地传输到另一个系统。Kafka 能够确保数据传输过程中的高吞吐量和低延迟,同时支持大规模的分布式数据处理。
- 在典型的 ETL(Extract, Transform, Load)场景中,Kafka 被用作数据的传输通道,支持数据的实时采集、转换和加载。
3.4 消息队列
- 事件驱动架构
- Kafka 作为消息队列用于事件驱动架构中,将系统中的事件消息传递给多个独立的服务进行异步处理。
- 通过 Kafka,开发者可以实现应用程序内各模块之间的松耦合,使得应用程序更加灵活和可扩展。
3.5 用户行为跟踪
- 点击流分析
- 在电商网站或社交媒体平台,Kafka 可以用于捕获和处理用户的点击流数据。这些数据可以被用于实时个性化推荐、广告投放优化、用户行为分析等场景。
- Kafka 的高吞吐量特性使其非常适合处理大量的用户交互数据,支持实时响应和数据分析。
3.6 监控与报警
- 系统监控
- Kafka 可以用于系统监控数据的收集和处理。监控系统可以通过 Kafka 将各种指标数据(如 CPU 使用率、内存使用率、网络流量等)发送到集中式监控平台,如 Prometheus 或 Grafana 进行可视化和告警。
- 这种方式能够实时监控系统的健康状况,并及时处理异常情况。
3.7 物联网(IoT)
- 传感器数据收集与处理
- 在物联网场景中,Kafka 可以用于收集和处理来自各类传感器的大量实时数据。Kafka 能够高效地将这些数据传递给数据处理和分析系统,以便实时监控和自动化决策。
- 通过 Kafka,物联网系统可以在不同的地点之间高效、可靠地传输数据,并确保数据的一致性和完整性。
四、Kafka的安装
4.1 下载 Kafka
官方下载地址:Kafka 下载
# 下载 Kafka 压缩包(以Scala 2.12 Kafka 3.8.0 版本为例)
wget https://downloads.apache.org/kafka/3.8.0/kafka_2.12-3.8.0.tgz# 解压缩
tar -xzf kafka_2.12-3.8.0.tgz# 重命名文件夹
mv kafka_2.12-3.8.0 kafka
4.2 配置 Kafka
在解压后的 Kafka 目录中,有几个重要的配置文件:
- server.properties:Kafka 服务器的主要配置文件。
- zookeeper.properties:Zookeeper 的配置文件。
4.2.1 配置 Zookeeper
Zookeeper 是 Kafka 的分布式协调服务,Kafka 在启动前需要先启动 Zookeeper。
-
编辑
zookeeper.properties文件:cd kafka/config/ vim zookeeper.properties确保以下配置正确:
dataDir=/tmp/zookeeper # 指定 Zookeeper 保存其数据的目录路径。 clientPort=2181 # 指定 Zookeeper 服务监听客户端连接的端口号。 maxClientCnxns=0 # 设置单个客户端 IP 地址对 Zookeeper 服务器的最大连接数, 设置为 0,则表示不限制单个客户端的连接数量# Zookeeper 集群配置 # server.X=hostname:port1:port2 # Zookeeper 节点的主机名或 IP 地址,Zookeeper 节点间的通信的端口(通常是选举端口和仲裁端口) # 每个 server.X 的配置必须在所有 Zookeeper 节点上保持一致 server.1=zookeeper1:2888:3888 server.2=zookeeper2:2888:3888 server.3=zookeeper3:2888:3888
4.2.2 配置 Kafka 服务器
编辑 server.properties 文件来配置 Kafka 服务器。
vim server.properties
-
常用配置项:
broker.id=0 # 每个 Kafka 服务器的唯一标识符 log.dirs=/tmp/kafka-logs # 存放日志的目录 zookeeper.connect=localhost:2181 # Zookeeper 的连接地址 # Zookeeper集群 # zookeeper.connect=zookeeper1:2181,zookeeper2:2181,zookeeper3:2181
4.3 启动、停止 Zookeeper 和 Kafka
Kafka 依赖 Zookeeper,因此需要先启动 Zookeeper。
# 启动 Zookeeper
bin/zookeeper-server-start.sh config/zookeeper.properties# 启动 Kafka 服务器
bin/kafka-server-start.sh config/server.properties
# 停止 Kafka 服务器
bin/kafka-server-stop.sh# 停止 Zookeeper
bin/zookeeper-server-stop.sh
五、Kafka命令行操作
# --bootstrap-server参数就表示服务器的连接方式(必选)# 创建主题 (这里创建主题名称为test,下同)
kafka-topics.sh --bootstrap-server localhost:9092 --create --topic test# 查看所有主题
kafka-topics.sh --bootstrap-server localhost:9092 --list# 查看指定主题信息
kafka-topics.sh --bootstrap-server localhost:9092 --describe --topic test# 修改指定主题的参数
# --partitions : 修改的配置参数:分区数量
kafka-topics.sh --bootstrap-server localhost:9092 --topic test --alter --partitions 2# 删除指定名称的主题
kafka-topics.sh --bootstrap-server localhost:9092 --topic test --delete
# 消费者订阅主题
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test# 生成者推送主题
kafka-console-producer.sh --bootstrap-server localhost:9092 --topic test# 生产者批量推送文件
kafka-console-producer.sh --broker-list localhost:9092 --topic test < xxx.text
六、Kafka Scala API
6.1 依赖
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>3.6.1</version>
</dependency><!-- kafka streams -->
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-streams</artifactId><version>3.6.1</version>
</dependency>
6.2 AdminAPI
Admin API 用于管理 Kafka 集群、主题、分区等资源。
package kafkaAPIimport java.util.{Collections, Properties}
import org.apache.kafka.clients.admin.{AdminClient, AdminClientConfig, NewTopic}object AdminAPI {def main(args: Array[String]): Unit = {// 创建配置属性val props = new Properties()props.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, "master01:9092") // 设置 Kafka 集群的地址// 创建 AdminClient 实例val adminClient = AdminClient.create(props)// 创建一个新的主题,主题名称为 "my-new-topic",有 1 个分区和 1 个副本val newTopic = new NewTopic("my-new-topic", 1, 1.toShort)// 创建该主题adminClient.createTopics(Collections.singletonList(newTopic)).all().get()// 关闭 AdminClientadminClient.close()}
}
6.3 Producer API
生产者 API 用于将记录发布到一个或多个 Kafka 主题中。
package kafkaAPIimport org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, ProducerRecord}
import org.apache.kafka.common.serialization.StringSerializerimport java.util.Propertiesobject ProducerAPI {def main(args: Array[String]): Unit = {// 创建配置属性val props = new Properties()// 设置 Kafka 集群的地址props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "master01:9092")// 设置键和值的序列化器props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, classOf[StringSerializer].getName)props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, classOf[StringSerializer].getName)// 创建 KafkaProducer 实例val producer = new KafkaProducer[String, String](props)// 创建一个 ProducerRecord,指定主题、键和值val record = new ProducerRecord[String, String]("my-topic", "key2", "value2")// 发送消息producer.send(record)// 关闭 KafkaProducerproducer.close()}
}
6.4 ConsumerAPI
消费者 API 用于从 Kafka 主题中读取记录,支持自动和手动提交偏移量。
package kafkaAPIimport org.apache.kafka.clients.consumer.{ConsumerConfig, KafkaConsumer}
import org.apache.kafka.common.serialization.StringDeserializer
import java.time.Duration
import java.util.{Collections, Properties}object ConsumerAPI {def main(args: Array[String]): Unit = {// 创建配置属性val props = new Properties()// 设置 Kafka 集群的地址props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "master02:9092")// 设置消费者组 IDprops.put(ConsumerConfig.GROUP_ID_CONFIG, "my-group")// 设置键和值的反序列化器props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, classOf[StringDeserializer].getName)props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, classOf[StringDeserializer].getName)// 创建 KafkaConsumer 实例val consumer = new KafkaConsumer[String, String](props)// 订阅主题 "my-topic"consumer.subscribe(Collections.singletonList("my-topic"))// 不断地轮询 Kafka 消息while (true) {// 轮询消息,等待时间为 100 毫秒val records = consumer.poll(Duration.ofMillis(100))// 处理每条消息records.forEach(record => {println(s"offset = ${record.offset()}, key = ${record.key()}, value = ${record.value()}")})}}
}
6.5 Streams API
Streams API 用于构建具有状态和无状态的流处理应用程序。
package kafkaAPIimport java.util.Properties
import org.apache.kafka.streams.{KafkaStreams, StreamsBuilder, StreamsConfig}
import org.apache.kafka.streams.kstream.KStream
import org.apache.kafka.common.serialization.Serdesobject StreamsAPI {def main(args: Array[String]): Unit = {// 创建配置属性val props = new Properties()// 设置应用 ID,这将作为 Kafka Streams 应用程序的标识符props.put(StreamsConfig.APPLICATION_ID_CONFIG, "my-stream")// 设置 Kafka 集群的地址props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "master01:9092")// 设置默认键和值的 Serde 类props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass.getName)props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass.getName)// 创建 StreamsBuilder 实例val builder = new StreamsBuilder()// 从 Kafka 主题 "input-topic" 创建一个 KStream 实例val stream: KStream[String, String] = builder.stream("input-topic")// 处理数据,在值后拼接 "-out"val processedStream: KStream[String, String] = stream.mapValues(value => value + "-out")// 将处理后的数据发送到 Kafka 主题 "output-topic"processedStream.to("output-topic")// 创建 KafkaStreams 实例,并启动流处理应用程序val streams = new KafkaStreams(builder.build(), props)streams.start()}
}
七、Kafka与大数据的集成
Kafka 能够在大数据生态系统中充当数据流的核心传输和处理管道。
Kafka 可以与多种大数据技术集成,以实现强大的数据流处理能力。
与 Hadoop 集成,通过 Kafka Connect 将数据导入 HDFS 进行批量处理;
与 Spark 集成,使用 Spark Streaming 进行实时数据处理;
与 Flink 集成,提供低延迟流处理和复杂事件处理;
与 Elasticsearch 集成,实现实时数据索引和搜索;
与 MongoDB 集成,进行实时数据存储和查询;
以及与 Redis 集成,用于实时缓存和快速数据访问。
7.1 Kafka flume
Flume 可以将数据从各种来源传输到 Kafka 集群中,然后 Kafka 再将这些数据传输到其他系统进行处理和存储
flume采集数据到Kafka的配置
# 定义组件
a1.sources = r1
a1.channels = c1# 配置source
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = f1
# 日志(数据)文件 监控test.log文件
a1.sources.r1.filegroups.f1 = /opt/module/data/test.log
a1.sources.r1.positionFile = /opt/software/flume-1.9.0/taildir_position.json# 配置channel
# 采用Kafka Channel,省去了Sink,提高了效率
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers = single01:9092
a1.channels.c1.kafka.topic = test
a1.channels.c1.parseAsFlumeEvent = false# 组装
a1.sources.r1.channels = c1
执行flume操作采集数据到Kafka
# 进入flume
cd /opt/module/flume
# 执行
bin/flume-ng agent -n a1 -c conf/ -f job/file_to_kafka.conf
bin/flume-ng agent 启动 Flume 代理。
-n a1 指定代理名称为 a1。
-c conf/ 指定配置目录为 conf/。
-f job/file_to_kafka.conf 指定具体的 Flume 配置文件。
7.2 Kafka Spark Streaming
使用 Spark Streaming 进行实时数据处理
<spark.scala.version>2.12</spark.scala.version><!-- spark-core -->
<dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_${spark.scala.version}</artifactId><version>${spark.version}</version>
</dependency><!-- spark-streaming -->
<dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming_${spark.scala.version}</artifactId><version>${spark.version}</version>
</dependency><!-- spark-streaming-kafka-0-10 -->
<dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming-kafka-0-10_${spark.scala.version}</artifactId><version>${spark.kafka.version}</version>
</dependency>
import org.apache.kafka.clients.consumer.ConsumerConfig
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.kafka.common.serialization.StringDeserializer
import shaded.parquet.org.codehaus.jackson.map.deser.std.StdDeserializer.IntegerDeserializerobject KafkaSparkStream {def main(args: Array[String]): Unit = {val conf = new SparkConf().setAppName("spark-streaming-kafka-01").setMaster("local[*]")val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()import spark.implicits._import org.apache.spark.sql.functions._// 每3秒处理一次数据val ssc = new StreamingContext(spark.sparkContext, Seconds(5))val topic = "test"val kafkaParams = Map((ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "hostname:9092"),(ConsumerConfig.GROUP_ID_CONFIG, "group01"),(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, classOf[StringDeserializer].getName),(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, classOf[StringDeserializer].getName),)// 创建Kafka Direct StreamKafkaUtils.createDirectStream[Int, String](ssc,LocationStrategies.PreferConsistent, // 分配策略ConsumerStrategies.Subscribe[Int, String](Array(topic), kafkaParams) // 订阅主题).foreachRDD(// 对每个rdd处理)ssc.start()ssc.awaitTermination()}
}
7.3 Kafka Flink
Flink是分布式计算引擎,是一款非常强大的实时分布式计算框架,可以将Kafka作为数据源进行处理。
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>1.17.0</version>
</dependency>
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java</artifactId><version>1.17.0</version>
</dependency>
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients</artifactId><version>1.17.0</version>
</dependency>
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka</artifactId><version>1.17.0</version>
</dependency>
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer
import org.apache.flink.streaming.api.datastream.DataStream
import org.apache.kafka.clients.consumer.ConsumerConfig
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.flink.api.common.serialization.SimpleStringSchemaimport java.util.Propertiesobject KafkaFlink {def main(args: Array[String]): Unit = {// 创建 Flink 流执行环境val env = StreamExecutionEnvironment.getExecutionEnvironment// 配置 Kafka 消费者属性val properties = new Properties()properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092")properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "test")properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, classOf[StringDeserializer].getName)properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, classOf[StringDeserializer].getName)// 创建 FlinkKafkaConsumerval consumer = new FlinkKafkaConsumer[String]("my-topic", new SimpleStringSchema(), properties)val stream: DataStream[String] = env.addSource(consumer)// 打印数据流stream.print()// 执行 Flink 作业env.execute("Flink Kafka Example")}
}相关文章:

分布式消息队列Kafka
分布式消息队列Kafka 简介: Kafka 是一个分布式消息队列系统,用于处理实时数据流。消息按照主题(Topic)进行分类存储,发送消息的实体称为 Producer,接收消息的实体称为 Consumer。Kafka 集群由多个 Kafka 实…...

C# Unity 面向对象补全计划 七大原则 之 迪米特法则(Law Of Demeter )难度:☆☆☆ 总结:直取蜀汉
本文仅作学习笔记与交流,不作任何商业用途,作者能力有限,如有不足还请斧正 本系列作为七大原则和设计模式的进阶知识,看不懂没关系 请看专栏:http://t.csdnimg.cn/mIitr,查漏补缺 1.迪米特法则(…...

【C++】—— 类与对象(四)
【C】—— 类与对象(四) 6、赋值运算符重载6.1、运算符重载6.1.1、基础知识6.1.2、调用方法6.1.3、前置 与 后置 的重载6.1.4、注意事项6.1.5、<< 和 >> 运算符重载6.1.5.1、<< 和 >> 基础6.1.5.2、日期类 operator<< 的实…...

Qt无边框窗口,关闭后再show,鼠标等事件不响应问题解决办法
问题描述 使用Qt做了一个无边框界面,关闭后再打开,子控件的点击以及hover效果不可用。 setWindowFlags(windowFlags() | Qt::Dialog | Qt::FramelessWindowHint);//去掉标题栏解决方案: 在网上发现可以通过重写showEvent(QShowEvent* showE…...

StringJoiner更优雅创建含分隔符的字符序列
文章目录 1 why2 what3 how4 练习手段 1 why StringBuilder拼接包含分隔符的字符序列时,分隔符需要一个一个添加,或者需要手动删除末尾冗余的分隔符,代码不美观,不好看。 比如,单个字符串依次拼接时: Stri…...

线程池原理(一)线程池核心概述
更好的阅读体验 \huge{\color{red}{更好的阅读体验}} 更好的阅读体验 线程回顾 创建线程的方式 继承 Thread 类实现 Runnable 接口 创建后的线程有如下状态: NEW:新建的线程,无任何操作 public static void main(String[] args) {Thread…...

关于redisson的序列化配置
由于使用redisson来存储list,返回的数据格式总是不对 原因是配置的序列化格式不对 Bean(value "redissonDtClient") public RedissonClient redissonClient() {RedisConnectionProperties.RedisConfigEntity configEntity properties.getDt();log.inf…...

CentOS安装ax200驱动
如果内核低于5.1需要安装一下内核 详细移步:Centos7安装高版本内核 大致如下: rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-2.el7.elrepo.noarch.rpm yum --enablerepoelrepo-ke…...

FFMPEG Mac版本编译
Mac下FFMPEG使用 There are a few ways to get FFmpeg on OS X. One is to build it yourself. Compiling on Mac OS X is as easy as any other *nix machine, there are just a few caveats(警告). The general procedure is get the source, then ./configure <flags&g…...

Reactive Programing与“响应式”
将Reactive Programing翻译为“响应式编程”,的确不好理解。什么是Reactive?Reactive被翻译为“反应”,其英文原意是“事物对变化信号的回应、反应”。我热了,空调自动开,这就是空调对我的Reaction,我和空调…...
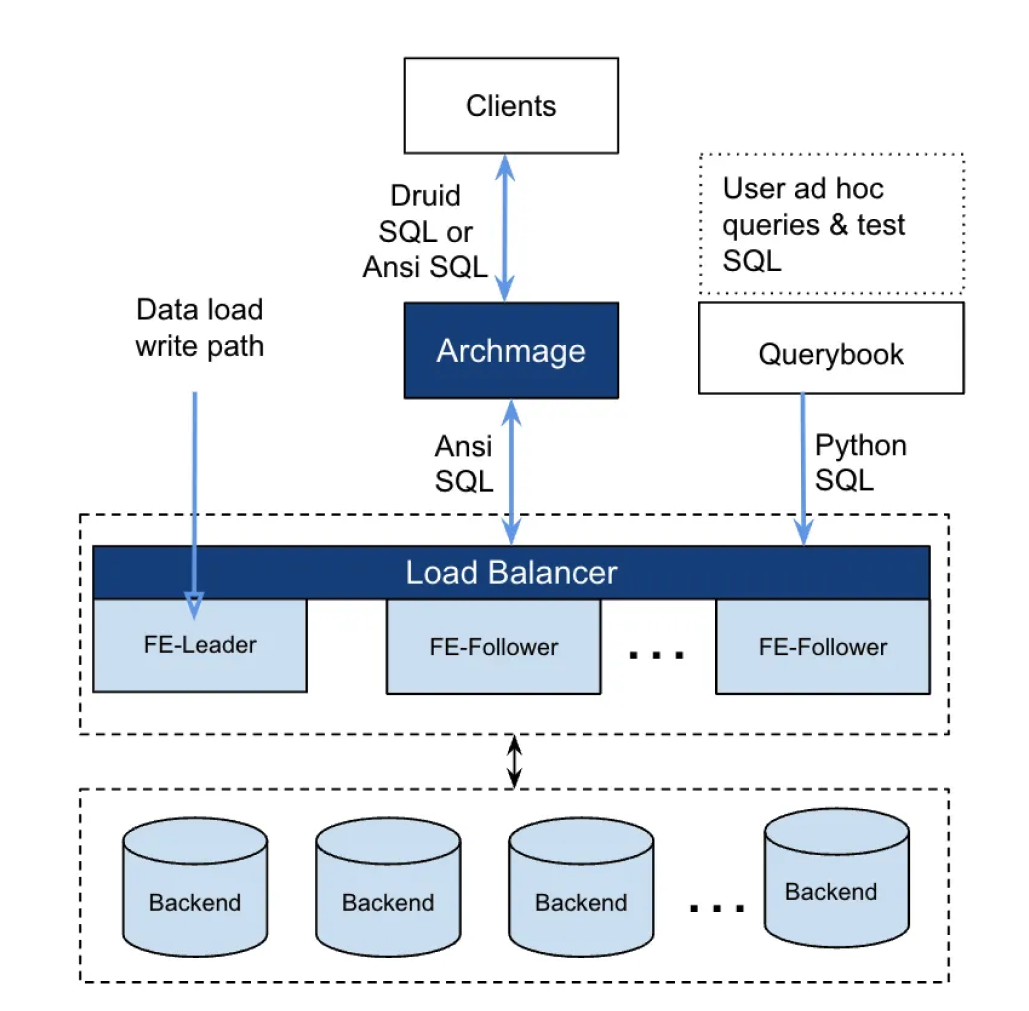
Pinterest:从 Druid 到 StarRocks,实现 6 倍成本效益比提升
导读: 开源无国界,StarRocks 自开源以来,近3年的时间里已在全球数据技术领域崭露头角。我们欣喜地发现,越来越多的海外用户正在使用并积极推广着 StarRocks。为了促进知识共享,StarRocks中文社区将精选优秀文章与大家共…...
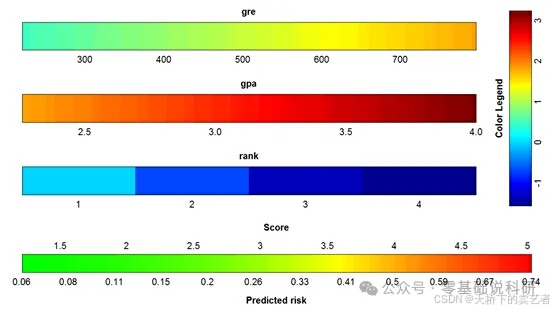
代码+视频,R语言VRPM绘制多种模型的彩色列线图
列线图,又称诺莫图(Nomogram),它是建立在回归分析的基础上,使用多个临床指标或者生物属性,然后采用带有分数高低的线段,从而达到设置的目的:基于多个变量的值预测一定的临床结局或者…...

Python 设计模式之工厂函数模式
文章目录 案例基本案例逐渐复杂的案例 问题回顾什么是工厂模式?为什么会用到工厂函数模式?工厂函数模式和抽象工厂模式有什么关系? 工厂函数模式是一种创建型设计模式,抛出问题: 什么是工厂函数模式?为什么…...
——开发:数据挖掘——概述、关注焦点)
数据赋能(171)——开发:数据挖掘——概述、关注焦点
概述 数据挖掘是从大量的数据中,提取隐藏在其中的、事先不知道的、但潜在有用的信息的过程。 数据挖掘是数据分析过程中的一个核心环节。 数据挖掘的主要目的是从大量数据中自动发现隐藏的模式、关联和趋势,以揭示数据的潜在价值。数据挖掘技术可以帮…...

L1 - OpenCompass 评测 InternLM-1.8B 实践
基础任务(完成此任务即完成闯关) 使用 OpenCompass 评测 internlm2-chat-1.8b 模型在 ceval 数据集上的性能,记录复现过程并截图。 按照教程中的顺序安装包有问题,网上找了解决方案,按一下顺序能正常执行 使用OpenCo…...
)
JS【详解】数据类型检测(含获取任意数据的数据类型的函数封装、typeof、检测是否为 null、检测是否为数组、检测是否为非数组/函数的对象)
【函数封装】获取任意数据的数据类型 /*** 获取任意数据的数据类型** param x 变量* returns 返回变量的类型名称(小写字母)*/ function getType(x) {// 获取目标数据的私有属性 [[Class]] 的值const originType Object.prototype.toString.call(x); //…...

OpenCV图像滤波(10)Laplacian函数的使用
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 功能描述 计算图像的拉普拉斯值。 该函数通过使用 Sobel 运算符计算出的 x 和 y 的二阶导数之和来计算源图像的拉普拉斯值: dst Δ src ∂…...
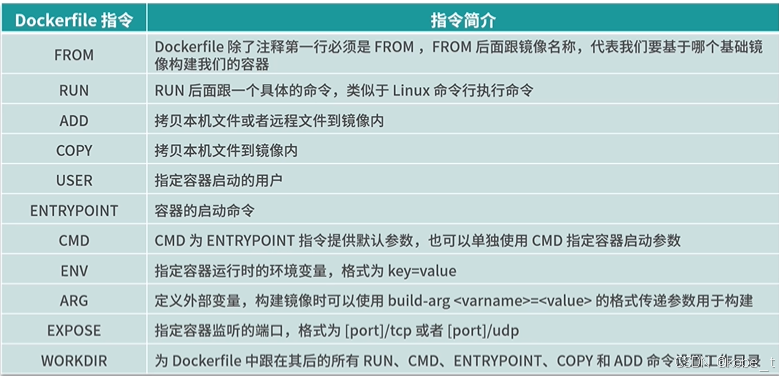
docker系列11:Dockerfile入门
传送门 docker系列1:docker安装 docker系列2:阿里云镜像加速器 docker系列3:docker镜像基本命令 docker系列4:docker容器基本命令 docker系列5:docker安装nginx docker系列6:docker安装redis docker系…...

LVS(Linux virual server)详解
目录 一、LVS(Linux virual server)是什么? 二、集群和分布式简介 2.1、集群Cluster 2.2、分布式 2.3、集群和分布式 三、LVS运行原理 3.1、LVS基本概念 3.2、LVS集群的类型 3.2.1 nat模式 3.2.2 DR模式 3.2.3、LVS工作模式总结 …...

Session共享方法
在Web开发中,会话(Session)管理是跟踪用户与服务器之间交互的一种常见方法。Session 共享通常指的是在一个应用集群或多个应用服务之间保持用户的会话状态一致。这在负载均衡、微服务架构或者分布式系统中尤为重要 一、基于SQL的session管理…...

终极艾尔登法环帧率解锁指南:轻松突破60FPS限制
终极艾尔登法环帧率解锁指南:轻松突破60FPS限制 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mirrors/el/EldenRing…...

为内部知识库问答机器人接入Taotoken多模型增强回答效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为内部知识库问答机器人接入Taotoken多模型增强回答效果 构建一个高效的企业内部知识库问答机器人,核心挑战在于如何让…...

ComfyUI-Manager完整指南:如何轻松管理你的AI工作流扩展库
ComfyUI-Manager完整指南:如何轻松管理你的AI工作流扩展库 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable various c…...

LVGL多页面开发避坑:用内部Timer替代轮询,解决页面切换时的内存踩踏问题
LVGL多页面开发中的内存安全实践:用Timer机制替代轮询的工程解决方案 在嵌入式UI开发中,LVGL因其轻量级和跨平台特性成为热门选择。但当项目复杂度提升到多页面交互时,开发者往往会遇到一个棘手问题:如何在频繁切换页面的同时保证…...

AutoWall终极指南:如何在Windows上轻松设置炫酷动态壁纸
AutoWall终极指南:如何在Windows上轻松设置炫酷动态壁纸 【免费下载链接】AutoWall 🌌 Live wallpapers on Windows 7/8/10/11 using open-source wallpaper engine 项目地址: https://gitcode.com/gh_mirrors/au/AutoWall 厌倦了千篇一律的静态桌…...

国产麒麟系统上编译GDAL 3.2.1踩坑记:从PROJ6依赖缺失到Qt环境集成
麒麟系统GDAL 3.2.1编译实战:PROJ6依赖修复与Qt工程深度集成在国产操作系统生态中部署地理数据处理工具链,往往会遇到比常规Linux发行版更复杂的依赖问题。最近在麒麟系统上为北斗定位项目编译GDAL 3.2.1时,遭遇了经典的"PROJ 6 symbols…...

开源三角洲机器人Delta-Robot One:从入门到精通的创客实践指南
1. 项目概述:一个为学习而生的开源三角洲机器人如果你对机器人感兴趣,但又觉得它高深莫测、无从下手,那么Delta-Robot One(我们亲切地称它为“One”)可能就是为你量身打造的入门项目。这不是一个遥不可及的工业设备&am…...

JavaScript对象创建:告别繁琐,四种灵活写法一学就会
在JavaScript里,创建对象的这般方法常把刚开始学习的新手弄得困惑不已,好像无论走哪条道都行得通,可又不清楚该挑哪一条才好。我编写JavaScript都有十几年功夫了,对象创建这事差不多每天都会碰到可谓基础技能。它不像变量声明那般…...
)
Sora 2原生MP4输出不兼容Premiere Pro?揭秘H.264/H.265封装层4大隐性缺陷(附MediaInfo诊断模板+自动修复脚本)
更多请点击: https://codechina.net 第一章:Sora 2原生MP4输出不兼容Premiere Pro的根源定位 Sora 2生成的原生MP4文件虽符合ISO/IEC 14496-14规范,但其底层封装结构与Adobe Premiere Pro对时间码、元数据及视频流编码参数的严格校验逻辑存在…...

四大桌面云品牌评测:从安全、体验到性价比
桌面云不再是大型企业的专属,它已成为各行各业实现数据安全、混合办公和IT降本增效的“标准配置”。经过对市场主流方案的全面评估,我们认为,深信服(Sangfor)aDesk桌面云因其在安全内生化、传输协议自研化、运维管理智…...