Flink-DataWorks第二部分:数据集成(第58天)
系列文章目录
- 数据集成
2.1 概述
2.1.1 离线(批量)同步简介
2.1.2 实时同步简介
2.1.3 全增量同步任务简介
2.2 支持的数据源及同步方案
2.3 创建和管理数据源
文章目录
- 系列文章目录
- 前言
- 2. 数据集成
- 2.1 概述
- 2.1.1 离线(批量)同步简介
- 2.1.2 实时同步简介
- 2.1.3 全增量同步任务简介
- 2.2 支持的数据源及同步方案
- 2.3 创建和管理数据源
前言
本文主要详解了DataWorks的数据集成,为第二部分:
由于篇幅过长,分章节进行发布。
后续:
数据集成的使用
数据开发流程及操作
运维中心的使用
2. 数据集成
2.1 概述
2.1.1 离线(批量)同步简介
数据集成主要用于离线(批量)数据同步。离线(批量)的数据通道通过定义数据来源和去向的数据源和数据集,提供一套抽象化的数据抽取插件(Reader)、数据写入插件(Writer),并基于此框架设计一套简化版的中间数据传输格式,从而实现任意结构化、半结构化数据源之间数据传输。

2.1.2 实时同步简介
数据集成的实时同步包括实时读取、转换和写入三种基础插件,各插件之间通过内部定义的中间数据格式进行交互。
一个实时同步任务支持多个转换插件进行数据清洗,并支持多个写入插件实现多路输出功能。同时针对某些场景,支持整库实时同步全增量同步任务,用户可以一次性实时同步多个表。
2.1.3 全增量同步任务简介
实际业务场景下,数据同步通常不能通过一个或多个简单离线同步或者实时同步任务完成,而是由多个离线同步、实时同步和数据处理等任务组合完成,这就会导致数据同步场景下的配置复杂度非常高。
为了解决上述问题,DataWorks提出了面向业务场景的同步任务配置化方案,支持不同数据源的一键同步功能,例如,“一键实时同步至Elasticsearch”、“一键实时同步至Hologres”和“一键实时同步至MaxCompute”功能等,通过此类功能,用户只需要进行简单的配置,就可以完成一个复杂业务场景。
全增量同步任务具有如下优势:
全量数据初始化。
增量数据实时写入。
增量数据和全量数据定时自动合并写入新的全量表分区。
2.2 支持的数据源及同步方案
数据集成包括离线同步、实时同步和全增量同步任务三个功能模块,可以根据各模块对数据源的支持情况,选择对应的功能模块进行同步任务的配置。
支持的数据源及同步方案详见下表:
https://help.aliyun.com/zh/dataworks/user-guide/supported-data-source-types-and-read-and-write-operations?spm=a2c4g.11186623.0.0.6d9e7bca0fYAUx

2.3 创建和管理数据源
按照配置文档进行配置即可。下面以MySQL为例进行学习。
(1)数据同步前准备:MySQL环境准备
1)确认MySQL版本
登录数据库管理系统https://dms.aliyun.com/,打开SQL Console,运行以下命令:
select version();

2)配置账号权限
建议提前规划并创建一个专用于DataWorks访问数据源的MySQL账号,操作如下。
CREATE USER 'dw'@'%' IDENTIFIED BY 'xxxxx666!';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'dw'@'%';
3)(仅实时同步需要)开启MySQL Binlog
数据集成通过实时订阅MySQL Binlog实现增量数据实时同步,需要在DataWorks配置同步前,先开启MySQL Binlog服务。操作如下。
注意:
如果Binlog在消费中,则无法被数据库删除。如果实时同步任务运行延迟将可能导致源端Binlog长时间被消费,请合理配置任务的延迟告警,并及时关注数据库的磁盘空间。
Binlog至少保留72小时以上,避免任务失败后因Binlog已经消失,再启动无法重置位点到故障发生前而导致的数据丢失(此时只能使用全量离线同步来补齐数据)。
① 检查Binlog是否开启。
使用如下语句检查Binlog是否开启。
show variables like "log_bin";
返回结果为ON时,表明已开启Binlog。
如果返回的结果与上述结果不符:
o 开源MySQL请参考MySQL官方文档开启Binlog。
o 阿里云RDS MySQL请参考日志备份开启Binlog。
② 查询Binlog的使用格式。
使用如下语句查询Binlog的使用格式。
show variables like "binlog_format";

返回结果说明:
返回ROW,表明开启的Binlog格式为ROW。
返回STATEMENT,表明开启的Binlog格式为STATEMENT。
返回MIXED,表明开启的Binlog格式为MIXED。
注意:DataWorks实时同步仅支持同步MySQL服务器Binlog配置格式为ROW。如果返回非ROW请修改Binlog Format。
(2)新增数据源
1)打开DataWorks控制台,点击工作空间列表,打开dwhmcx,点击管理中心

2)点击数据源,点击新增数据源,选择MySQL

3)首次创建数据源源需要在对话框中点击前往RAM进行角色授权

点击同意授权。
4)填写配置信息
数据源名称:rdsmysql
适用环境:开发、生产
注意:在实际工作中开发和生产对应不同的数据库,一个是测试数据库一个是生产数据库。
地区:北京
实例所属账号:当前云账号
RDS实例ID: rm-cn-x0r3fp1lj000qa
注意:RDS实例ID需要打开RDS控制台,在实例列表中,复制实例ID
默认数据库名:test
用户名:dw
密码:xxxxx666!
点击测试连通性
点击完成
(3)管理数据源
可以在数据源管理页面,根据数据源类型、数据源名称等条件筛选需要查看的数据源。同时,支持用户对目标数据源进行编辑、删除、克隆、权限管理等操作。

编辑:可以单击编辑按钮,在弹出的数据源配置窗口,修改数据源的配置信息。
删除:
删除开发环境和生产环境的数据源:需确认是否存在生产环境关联的同步任务,操作不可逆,删除后,在开发环境配置同步任务时此数据源不可见。
如果生产环境在使用此数据源配置的同步任务,删除后,生产环境任务不可正常运行。请删除同步任务后再删除此数据源。
删除开发环境的数据源:需确认是否存在生产环境关联的同步任务,操作不可逆,删除后,在开发环境配置同步任务时此数据源不可见。
如果生产环境在使用此数据源配置的同步任务,删除后,任务编辑时将不能获取到元数据信息,但生产环境任务可以正常运行。
删除生产环境的数据源:需确认是否存在生产环境关联的同步任务,删除后,在开发环境使用此数据源配置的同步任务将不能提交生产发布。
如果生产环境在使用此数据源配置的同步任务,删除后,生产环境任务不可正常运行。
克隆:可以单击克隆,在弹出的克隆数据源窗口,输入新数据源名称,单击克隆,即可生成一个相同数据源类型且连接信息相同的新数据源。
权限管理:可以分享数据源权限给相应的工作空间,并进入被分享的工作空间查看该数据源。详情请参见:管理数据源权限。
篇幅原因:后续会接着发
相关文章:
Flink-DataWorks第二部分:数据集成(第58天)
系列文章目录 数据集成 2.1 概述 2.1.1 离线(批量)同步简介 2.1.2 实时同步简介 2.1.3 全增量同步任务简介 2.2 支持的数据源及同步方案 2.3 创建和管理数据源 文章目录 系列文章目录前言2. 数据集成2.1 概述2.1.1 离线(批量)同步…...
4个从阿里毕业的P7打工人,当起了包子铺的老板
吉祥知识星球http://mp.weixin.qq.com/s?__bizMzkwNjY1Mzc0Nw&mid2247483727&idx1&sndb05d8c1115a4539716eddd9fde4e5c9&chksmc0e47813f793f105017fb8551c9b996dc7782987e19efb166ab665f44ca6d900210e6c4c0281&scene21#wechat_redirect 《网安面试指南》h…...

javaweb_07:分层解耦
一、三层架构 (一)基础 在请求响应中,将代码都写在controller中,看起来内容很复杂,但是复杂的代码总体可以分为:数据访问、逻辑处理、接受请求和响应数据三个部分。在程序中我们尽量让一个类或者一个方法…...

调用 Python 开源库,获取油管英文视频的手动或自动英文srt字幕,以及自动中文简体翻译srt字幕
前提条件 非常抱歉,这个程序就是个雏形,非常不完善,输入需要手动编辑,凑活着可以用,请自己完善吧。 开源声明:此文代码引用了一个开源MIT License的Python库,其他代码是本人自写自用。你可以随…...
)
UDP协议实现通信与数据传输(创建客户端和服务器)
目录 一、UDP (传输层,用户数据报协议) 二、服务器Server的创建 三、客户端Client的创建 四、效果实现(描述) 一、UDP (传输层,用户数据报协议) UDP(User Datagram Pr…...

【红黑树】
红黑树 小杨 红黑树的概念 红黑树,是一种二叉搜索树,但在每个结点上增加一个存储位表示结点的颜色,可以是Red或Black。 通过对任何一条从根到叶子的路径上各个结点着色方式的限制,红黑树确保没有一条路径会比其他路径长出俩倍&am…...

排序算法——简单选择排序
一、算法原理 简单选择排序是一种基本的排序算法,其原理是每次从未排序的元素中选择最小(或最大)的元素,然后与未排序部分的第一个元素交换位置,直到所有元素都被排序。 二、算法实现流程 简单选择排序法(Simple Se…...
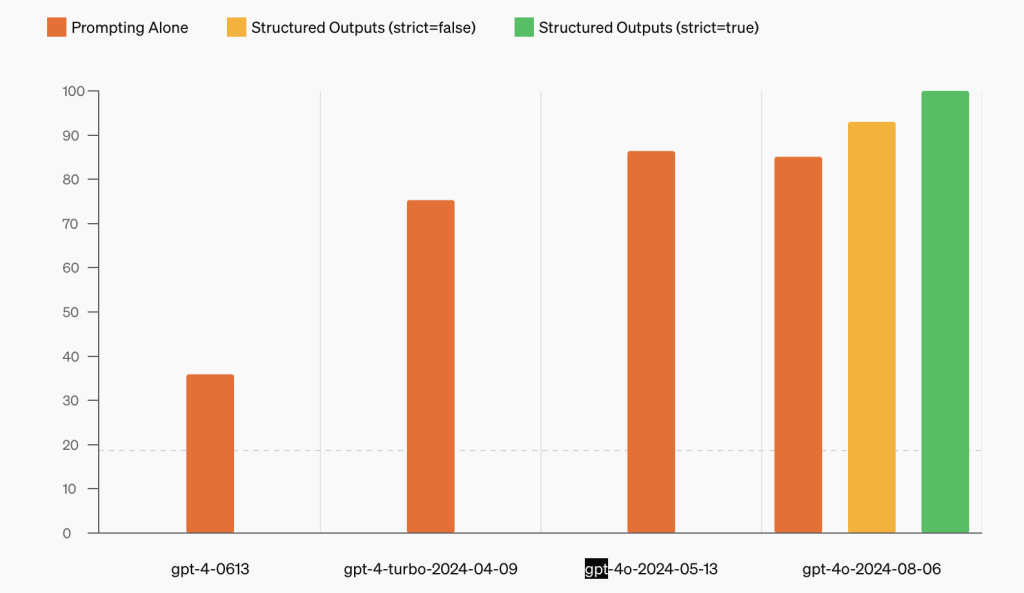
OpenAI API推出结构化输出功能
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...
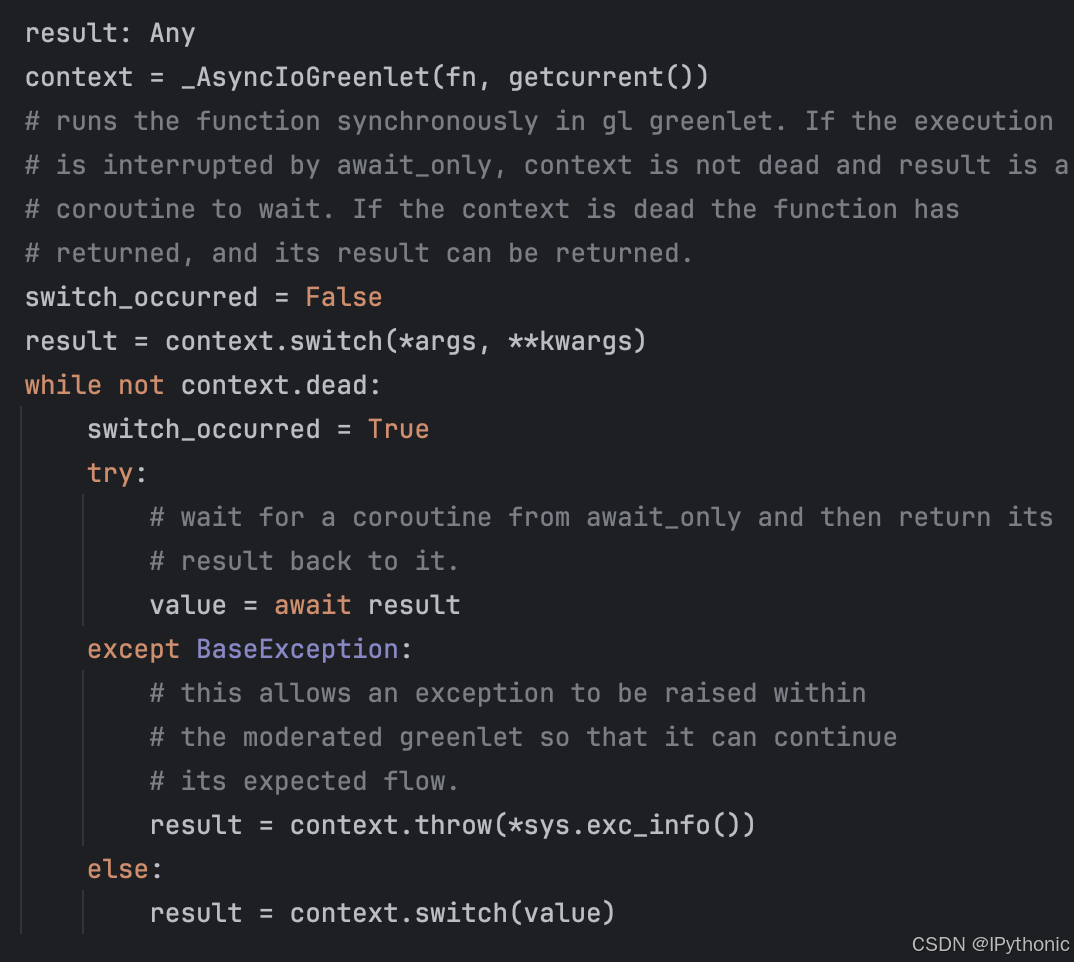
Python 异步编程:Sqlalchemy 异步实现方式
SQLAlchemy 是 Python 中最流行的数据库工具之一,在新版本中引入了对异步操作的支持。这为使用异步框架(如 FastAPI)开发应用程序带来了极大的便利。在这篇文章中,简单介绍下 SQLAlchemy 是如何利用 Greenlet 实现异步操作的。 什…...

父类引用指向子类对象
在 Java 中,父类引用可以指向子类对象,这是多态的一种表现。这种特性允许你使用父类的引用来操作子类对象,从而实现更灵活和可扩展的代码设计。 基本概念 多态:父类引用可以指向子类对象。这使得你可以用统一的接口处理不同的对象…...
分享一个基于Spring Boot的面向社区的智能化健康管理系统的设计与实现(源码、调试、LW、开题、PPT)
💕💕作者:计算机源码社 💕💕个人简介:本人 八年开发经验,擅长Java、Python、PHP、.NET、Node.js、Android、微信小程序、爬虫、大数据、机器学习等,大家有这一块的问题可以一起交流&…...

【扒代码】reduction参数是什么
model DensityMapRegressor(in_channels256, reduction8)reduction 参数在 DensityMapRegressor 类中用于决定模型在上采样过程中的层级配置。具体来说,它决定了上采样过程中使用多少个 UpsamplingLayer,从而影响输出的分辨率。 reduction 参数的作用 …...
Python,Spire.Doc模块,处理word、docx文件,极致丝滑
Python处理word文件,一般都是推荐的Python-docx,但是只写出一个,一句话的文件,也没有什么样式,就是36K。 再打开word在另存一下,就可以到7-8k,我想一定是python-docx的问题,但一直没…...

redis的安装与命令
一、redis与memcache总体对比 1.性能 Redis:只使用单核,平均每一个核上Redis在存储小数据时比Memcached性能更高。 Memcached:可以使用多核,而在100k以上的数据中,Memcached性能要高于Redis。 2.内存使用效率 Mem…...

【C++】特殊类设计类型转换
目录 💡前言一,特殊类设计1. 请设计一个类,不能被拷贝2. 请设计一个类,只能在堆上创建对象3. 请设计一个类,只能在栈上创建对象4. 请设计一个类,不能被继承5. 请设计一个类,只能创建一个对象(单…...

为git 命令行 设置代理环境变量
http://t.csdnimg.cn/cAxkg 国内需要修改pinoko根目录下gitconfig文件,添加 [http]proxy http://127.0.0.1:1080 [https]proxy https://127.0.0.1:1080或者通过命令行配置: git config --global http.proxy http://127.0.0.1:1080 git config --glo…...

自定义linux某些常见配置
1.当前路径 echo "PS1\u\h:\w\$ " >> /etc/profile source /etc/profile 2.ssh使能 1.开启openssh 2.权限赋予chown root.root /var/empty/ 3.开发板作为server echo "PermitRootLogin yes" >> /etc/ssh/sshd_config 3开机自启动脚本 1.init…...
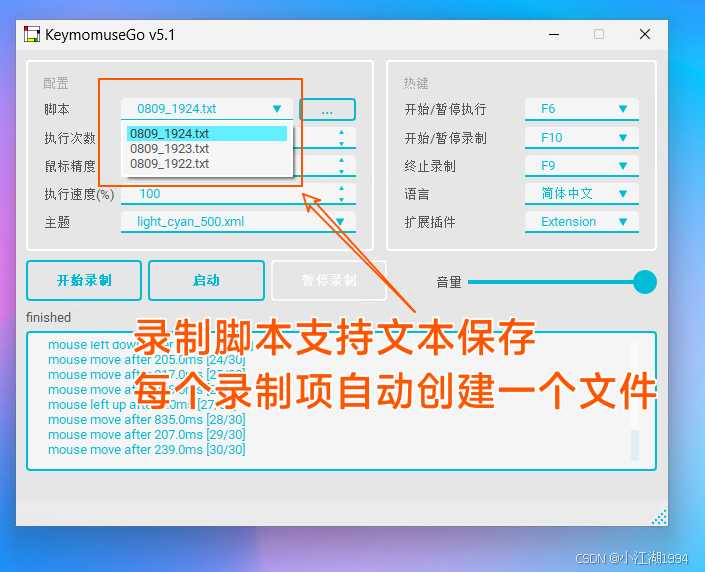
告别手动操作!KeyMouseGo实现自动化工作流
前言 在这个快节奏的时代,我们每天都在与电脑打交道,重复着那些繁琐而单调的操作;你是否曾想过,能让电脑自己完成这些任务,而你则悠闲地喝着咖啡,享受着生活?今天,就让我们一起揭开一…...

大型语言模型微调 新进展-4篇 论文
1. Brevity is the soul of wit: Pruning long files for code generation 发布时间:2024-06-29链接:https://arxiv.org/abs/2407.00434机构:伦敦大学学院 (UCL) 本研究针对大型语言模型的代码生成任务中的数据清理问题进行了探索。研究发现…...
专业课140+杭电杭州电子科技大学843信号与系统考研经验电子信息与通信工程真题,大纲,参考书。
顺利上岸杭电,由于专业课考的不错140,群里不少同学希望分享一点经验,回头看看这一年考研复习,确实有得有失,总结一下自己的专业课复习经验,希望对大家有帮助,基础课考的没有专业好,而…...

无机布防火卷帘门价格怎么算?按尺寸定制,按需报价
无机布防火卷帘门作为建筑防火分区的核心设备,价格一直是工程采购的关注重点。很多用户在询价时,会发现不同厂家的报价差异较大,这是因为无机布防火卷帘门的价格并非按统一单价计算,而是完全根据项目的实际需求定制化核算。 &…...

新手村任务:成为一个架构师需要哪些装备?
新手村任务:成为一个架构师需要哪些装备? 一、前言 如果你刚入行不久,想成为一名架构师,那这篇文章就是为你写的。 我们把成为架构师比作一个RPG游戏,你是主角,需要收集各种装备、刷经验、升级技能。 新手村的第一个任务就是:了解你需要哪些装备。 二、架构师技能树…...

Veo 2胶片质感生成器失效?——深度解析Color Science v2.3内核中被屏蔽的Cinematic Grain Injection层
更多请点击: https://kaifayun.com 第一章:Veo 2胶片质感生成器失效现象全景透视 近期大量用户反馈,Veo 2 胶片质感生成器在调用 generate_film_effect() 接口后返回空纹理、纯灰帧或 HTTP 503 Service Unavailable 错误,且该问题…...

为内部知识库问答机器人接入Taotoken多模型增强回答效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为内部知识库问答机器人接入Taotoken多模型增强回答效果 构建一个高效的企业内部知识库问答机器人,核心挑战在于如何让…...

开启Python GUI开发新纪元:Tkinter Designer可视化界面自动化生成终极指南
开启Python GUI开发新纪元:Tkinter Designer可视化界面自动化生成终极指南 【免费下载链接】Tkinter-Designer An easy and fast way to create a Python GUI 🐍 项目地址: https://gitcode.com/gh_mirrors/tk/Tkinter-Designer 在Python GUI开发…...

风控系统如何全维度识别爬虫:IP、账号与行为的协同决策机制
1. 这不是“反爬失败”,而是风控系统在对你做全维度画像你写完一段 requests BeautifulSoup 的代码,本地跑通了,开开心心部署到服务器,结果第二天早上发现:所有请求返回 403,日志里全是空响应;…...

工业云脑:06 现在就能干:树莓派边缘盒子+PLC,10分钟缺陷检测小案例
06 现在就能干:树莓派边缘盒子+PLC,10分钟缺陷检测小案例 今天第九篇06小节——现在就能干:树莓派边缘盒子+PLC,10分钟缺陷检测小案例。新手照着做10分钟就能跑起来,老手一看就知道这玩意儿省了多少钱。以前想上AI检测,得花几万块买专业边缘盒子;现在?树莓派5(RPi 5)…...

微信红包助手终极指南:无需ROOT的智能抢红包解决方案
微信红包助手终极指南:无需ROOT的智能抢红包解决方案 【免费下载链接】WeChatLuckyMoney :money_with_wings: WeChats lucky money helper (微信抢红包插件) by Zhongyi Tong. An Android app that helps you snatch red packets in WeChat groups. 项目地址: ht…...
)
Sora 2 GIF导出速度提升300%?20年多媒体架构师亲授GPU加速转码链路(CUDA 12.4 + cuVID硬编实测)
更多请点击: https://kaifayun.com 第一章:Sora 2 GIF导出方法概览 Sora 2 并非 OpenAI 官方发布的模型,当前(截至2024年)并无名为“Sora 2”的公开产品。因此,所谓“Sora 2 GIF导出”实为社区对视频生成工…...

Linux平台终极Jellyfin客户端:如何用Tsukimi打造专业级媒体中心体验?
Linux平台终极Jellyfin客户端:如何用Tsukimi打造专业级媒体中心体验? 【免费下载链接】tsukimi A simple third-party Jellyfin client for Linux 项目地址: https://gitcode.com/gh_mirrors/ts/tsukimi 你是否厌倦了网页版Jellyfin的笨重体验&am…...