统计软件与数据分析—Lesson2
jupyter Note环境配置,安装及使用以及python数据的读取操作
- 统计软件与数据分析—Lesson2
- 1.Jupyter Note环境配置,安装及使用
- 1.1 Jupyter Note 基本操作
- 1.2 Notebook中的Magic开关
- 1.2.1 Magic开关总览
- 1.2.2 Line Magic 全局
- 1.2.3 Cell Magic 当前cell
- 1.3 Notebook 扩展
- 1.3.1 Jupyter Lab
- 1.3.2 Jupyter notebook功能扩展Nbextensions
- 1.3.3 添加对R语言的支持
- 1.3.4 添加对stata语言的支持
- 2. Python简介,解释执行,运行方式
- 2.1 Python解释与运行
- 2.2 延伸阅读:Python解释器
- 2.3 Python的两种运行方式
- 2.3.1 解释式运行:如PyCharme,或命令行下python pyname.py
- 2.3.2 交互式运行
- 2.4 Python内置及三方库的管理及使用
- 2.4.1 模块Module与包Package
- 2.4.2 模块的导入
- 2.4.3 包的安装
- 2.4.4 包的导入
- 2.4.5 包的其它操作:
- 2.5 如何更好得获得帮助
- 3. python数据的存取
- 3.1 数据的保存
- 3.1.1 保存list
- 3.1.2 保存Dict
- 3.1.3 保存Set
- 3.1.4 保存Dataframe
- 3.1.5 保存Matrix
- 3.2 数据的读取
- 3.2.1 读取txt文件中的数据
- 3.2.2 读取excel文件中的数据
- 3.2.3 读取csv文件中的数据
- 3.2.4 读取stata文件中的数据
- 3.2.5 读取R文件中的数据
- 3.2.6 读取SPSS文件中的数据
- 3.2.7 读取Eviews文件中的数据
- 3.2.8 读取JSON文件中的数据
- 3.2.9 读取MYSQL文件中的数据
- 3.2.10 读取SQLite文件中的数据
统计软件与数据分析—Lesson2
主要包含jupyter Note环境配置,安装及使用以及python数据的读取操作等
1.Jupyter Note环境配置,安装及使用
1.1 Jupyter Note 基本操作
1.启动
win+R键—>输入‘cmd’—>点击‘确定’—>jupyter notebook
shift+右键
2.上传、下载
upload
复制粘贴
File–>Download as—> …
后缀ipynb(ipython+notebook)
3.创建、命名
new—>python3
4.cell 基本操作
插入:Insert Esc+A Esc+B
删除:D+D
快捷键:Esc+h
cell类型:code、markdown
1.2 Notebook中的Magic开关
https://blog.csdn.net/s1164548515/article/details/89458668
- 为实现一些快捷操作,提升效率。Notebook中提供了Magic开关,能极大得优化我们使用Notebook的体验。
- Magic 开关分为两大类:%line magic & %%cell magic
1.2.1 Magic开关总览
%lsmagic
%quickref
1.2.2 Line Magic 全局
%config InteractiveShell.ast_node_interactivity = ‘all’
%whos
%matplotlib inline
1.2.3 Cell Magic 当前cell
%%system
%%time
%%timeit
dir
1.3 Notebook 扩展
1.3.1 Jupyter Lab
cmd 输入jupyter lab
1.3.2 Jupyter notebook功能扩展Nbextensions
cmd中一次运行以下三行命令:
pip install jupyter_contrib_nbextensions -i https://pypi.tuna.tsinghua.edu.cn/simple
jupyter contrib nbextension install --user
pip install yapf -i https://pypi.tuna.tsinghua.edu.cn/simple
1.3.3 添加对R语言的支持
https://blog.csdn.net/s1164548515/article/details/100747987
1.3.4 添加对stata语言的支持
https://blog.csdn.net/s1164548515/article/details/10834249
2. Python简介,解释执行,运行方式
2.1 Python解释与运行
Python解释器interpreter
运行在系统线程上的C语言函数+超大循环。每个字节码指令均对应一个完全由C实现的逻辑。
Python解释器在执行过程
先对文件中的Python源代码进行编译,编译的主要结果是产生的一组Python的字节码(byte code),pyc文件是字节码在磁盘上的表现形式,是进行import module时对py文件进行编译的文件结果(如果之前编译过,且源文件又没有变化,则直接运行该pyc文件),而编译结果就是Python中的PyCodeObject对象,然后PyCodeObject对象交给Python虚拟机(Virtual Machine),由虚拟机按照顺序一条一条地执行字节码,从而完成对Python程序的执行动作。
python: .py -->(编译器)–>.pyc–>解释器(虚拟机)–>返回结果
在编译好的Python环境中,编译器和解释器都被封装进了pythonxx.dll中,由python.exe调用
2.2 延伸阅读:Python解释器
默认用到的都是用C语言实现的对Python的解释器CPython。也有用Python实现的python解释器PyPy,.Net实现的IronPython
- CPython解释器中的两个栈:
- 执行栈Evaluation Stack:存储指令操作数
- 块栈Block Stack:存储循环,异常等信息
字码基于栈式虚拟机,没有寄存器概念,转译简单,没有另类优化。不能被CPU执行,每条字节码对应C实现的机器指令。
Python 实现了栈式虚拟机 (Stack-Based VM) 架构,通过与机器⽆关的字节码来实现跨平台执⾏能⼒。
这种字节码指令集没有寄存器,完全以栈 (抽象层⾯) 进⾏指令运算。
2.3 Python的两种运行方式
2.3.1 解释式运行:如PyCharme,或命令行下python pyname.py
- 下方新建py文件
%%writefile lesson2_1.py
import sys
print('the file run name ',sys.argv[0],'The time that file should run:',sys.argv[1])
for i in range(int(sys.argv[1])):print(i,'times run')
!python lesson2_1.py 2
2.3.2 交互式运行
- 命令行Python,bpython,ipython, notebook
2.4 Python内置及三方库的管理及使用
2.4.1 模块Module与包Package
- 模块:一个模块就是一个Python源码文件(也可能是对c语言文件编译生成的pyd文件)
- 包:组织一堆相关功能的模块,并包含
__init__.py文件的目录。
2.4.2 模块的导入
一个模块本质上是一个py文件
%%writefile lesson2.py
a=123
_b='str'#
def lesson2_fun():return globals()
import lesson2
lesson2.__name__
__name__
#修改源码后不生效?试下reload
import lesson2
from imp import reloadreload(lesson2)
lesson2.a
2.4.3 包的安装
Python包是一组功能相关的模块,通常由多个.py文件组成,它们可以被其他程序导入和使用。Python提供了一个标准的包管理系统pip,可以方便地安装和管理第三方包。
1.单个包安装
- 使用pip安装包:
!pip install package_name
但通常建议在cmd窗口安装更稳定:win+R键–>输入cmd–>点击‘确定’—>pip install package_name
pip install tushare #注意jupyter notebook中运行前面需要加!
- 下载源代码并安装:
```python
!git clone https://github.com/package_name.git
!cd package_name && python setup.py install
- 批量安装Package
创建requirements.txt文件,将所需安装的包的名字都分行放在里,再运行:
pip install -r ./requirements.txt
2.4.4 包的导入
1.导入包
- 直接导入整个包:import package_name
示例:
import numpy
- 导入包中的指定模块:from package_name import module_name
示例:
from numpy import array
- 导入包中的所有模块:from package_name import *
from numpy import *
- 给包起别名:import package_name as alias_name
import numpy as np
总之,Python包是非常重要的,它们扩展了Python的功能,提供了丰富的库和工具来帮助我们编写更好的程序。
2.4.5 包的其它操作:
- 使用浏览器查看内置包:
cmd命令行下运行,python -m pydoc -p 1234
- 三方包的管理:
!pip list #列出所有的package
2.5 如何更好得获得帮助
-
1.官网文档 https://docs.python.org/3/
-
2.dir与tab的使用
-
3.help, ?,shift-tab的使用
str1='http://tsxy.zuel.edu.cn/'
# str1.rjust?
# help(exec)str1.find('t')#查找字符串中的指定字符所在的位置
3. python数据的存取
3.1 数据的保存
在Python中,可以使用不同的包来将不同类型的数据保存到不同类型的文件中。下面是一些示例:
3.1.1 保存list
- 保存List到txt文件
data_list = ['apple', 'banana', 'orange']
with open('data_list.txt', 'w') as f:for item in data_list:f.write("%s\n" % item)
- 保存List到csv文件
import csvdata_list = [['apple', 1], ['banana', 2], ['orange', 3]]
with open('data_list.csv', mode='w', newline='') as f:writer = csv.writer(f)writer.writerows(data_list)
- 保存List到Excel文件
import pandas as pddata = ['apple', 'banana', 'orange']
df = pd.DataFrame(data_list, columns=['fruits'])
df.to_excel('data_list.xlsx', index=False)
3.1.2 保存Dict
- 保存Dict到txt文件
data_dict = {'a': 1, 'b': 2, 'c': 3}with open('data_dict.txt', 'w') as f:for key, value in data_dict.items():f.write(f'{key}:{value}\n')
- 保存Dict到csv文件
import csvdata_dict = {'apple': 1, 'banana': 2, 'orange': 3}
with open('data_dict.csv', mode='w', newline='') as file:writer = csv.writer(file)for key, value in data_dict.items():writer.writerow([key, value])
- 保存Dict到Excel文件
import pandas as pddata_dict = {'name': ['apple', 'banana', 'orange'], 'price': [1, 2, 3]}
df = pd.DataFrame(data)
df.to_excel('data_dict.xlsx', index=False)
3.1.3 保存Set
- 保存Set到txt文件
data_set = {'apple', 'banana', 'orange'}
with open('data_set.txt', 'w') as f:for item in data_set :f.write("%s\n" % item)
- 保存Set到csv文件
data_set = {1, 2, 3, 4, 5}import csvwith open('data_set.csv', 'w', newline='') as f:writer = csv.writer(f)writer.writerow(['value'])for value in data_set :writer.writerow([value])
- 保存Set到excel文件
import pandas as pddata_set = {1, 2, 3, 4, 5}df = pd.DataFrame(list(data_set), columns=['value'])
df.to_excel('data_set.xlsx', index=False)3.1.4 保存Dataframe
- 保存Dataframe到txt文件
import pandas as pddata = {'name': ['Alice', 'Bob', 'Charlie'], 'age': [25, 30, 35]}data_df = pd.DataFrame(data)
data_df.to_csv('data_df.txt', index=False, sep='\t')
- 保存Dataframe到csv文件
import pandas as pddata = {'name': ['apple', 'banana', 'orange'], 'price': [1, 2, 3]}
data_df = pd.DataFrame(data)
data_df.to_csv('data_df.csv', index=False)
- 保存Dataframe到Excel文件
import pandas as pddata = {'name': ['apple', 'banana', 'orange'], 'price': [1, 2, 3]}
data_df = pd.DataFrame(data)
writer = pd.ExcelWriter('data_df.xlsx')
data_df.to_excel(writer, index=False, sheet_name='Sheet1')
writer.save()
3.1.5 保存Matrix
- 保存Matrix到txt文件
import numpy as npdata_matrix = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
np.savetxt('data_matrix.txt', data_matrix)
- 保存Matrix到csv文件
import numpy as npdata_matrix = np.random.rand(3, 3)
np.savetxt('data_matrix.csv', data_matrix, delimiter=',')
- 保存Matrix到Excel文件
import pandas as pd
import numpy as npdata_matrix = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
df = pd.DataFrame(data_matrix)
df.to_excel('data_matrix.xlsx', index=False)
总之,Python提供了很多包和方法来处理不同类型的数据,并将它们保存到不同类型的文件中,这些示例只是其中一部分,读者可以根据自己的需要选择适合自己的方法。
3.2 数据的读取
3.2.1 读取txt文件中的数据
with open('data_list.txt', 'r') as f:data = f.read()
print(data)
3.2.2 读取excel文件中的数据
import pandas as pd
data = pd.read_excel('data_dict.xlsx')
print(data)
3.2.3 读取csv文件中的数据
import pandas as pddata = pd.read_csv('data_df.csv')
print(data)
3.2.4 读取stata文件中的数据
import pandas as pddata = pd.read_stata('example.dta')
print(data)
3.2.5 读取R文件中的数据
import pandas as pddata = pd.read_r('example.Rdata')
print(data)
3.2.6 读取SPSS文件中的数据
import pandas as pddata = pd.read_spss('example.sav')
print(data)
3.2.7 读取Eviews文件中的数据
import pandas as pddata = pd.read_table('example.prg', delim_whitespace=True)
print(data)
3.2.8 读取JSON文件中的数据
import jsonwith open('example.json', 'r') as f:data = json.load(f)
print(data)
3.2.9 读取MYSQL文件中的数据
import mysql.connectorconn = mysql.connector.connect(user='username', password='password', host='host_address', database='database_name')
c = conn.cursor()
c.execute('SELECT * FROM table_name')
data = c.fetchall()
print(data)
3.2.10 读取SQLite文件中的数据
import sqlite3conn = sqlite3.connect('example.db')
c = conn.cursor()
c.execute('SELECT * FROM table_name')
data = c.fetchall()
print(data)
相关文章:

统计软件与数据分析—Lesson2
jupyter Note环境配置,安装及使用以及python数据的读取操作统计软件与数据分析—Lesson21.Jupyter Note环境配置,安装及使用1.1 Jupyter Note 基本操作1.2 Notebook中的Magic开关1.2.1 Magic开关总览1.2.2 Line Magic 全局1.2.3 Cell Magic 当前cell1.3 …...

ISO体系认证全方位解析让!
ISO体系认证全方位解析让! 常常有人问小编, 某某体系是什么意思? 某某证书的有效期是多久? 新版标准的转换要求有哪些? 小编尽量一一解答, 但难免会错过部分朋友的问题。 为了更全面地解决大家关于认证的疑…...

真要被00后职场整顿了?老员工纷纷表示真的干不过.......
最近聊到软件测试的行业内卷,越来越多的转行和大学生进入测试行业。想要获得更好的待遇和机会,不断提升自己的技能栈成了测试老人迫在眉睫的问题。 不论是面试哪个级别的测试工程师,面试官都会问一句“会编程吗?有没有自动化测试…...

NDK FFmpeg音视频播放器二
NDK前期基础知识终于学完了,现在开始进入项目实战学习,通过FFmpeg实现一个简单的音视频播放器。本文主要内容如下:阻塞式队列SafeQueue。音视频BaseChannel基础通道。音视频压缩包加入队列。视频解码与播放。ANativeWindow渲染用到的ffmpeg、…...
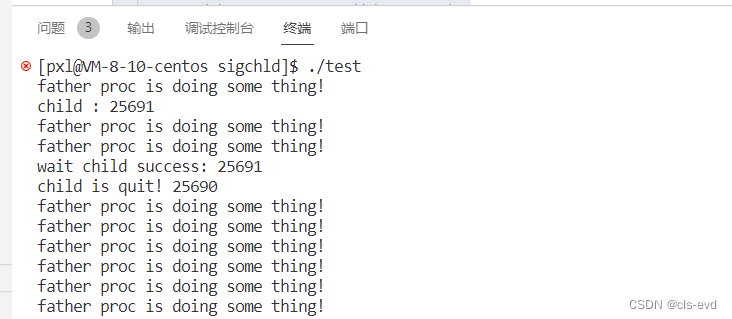
Linux之进程信号
目录 一、生活中的信号 背景知识 生活中有没有信号的场景呢? 是不是只有这些场景真正的放在我面前的时候,我才知道怎么做呢? 进程在没有收到信号的时候,进程知道不知道应该如何识别哪一个是信号?以及如何处理它&a…...
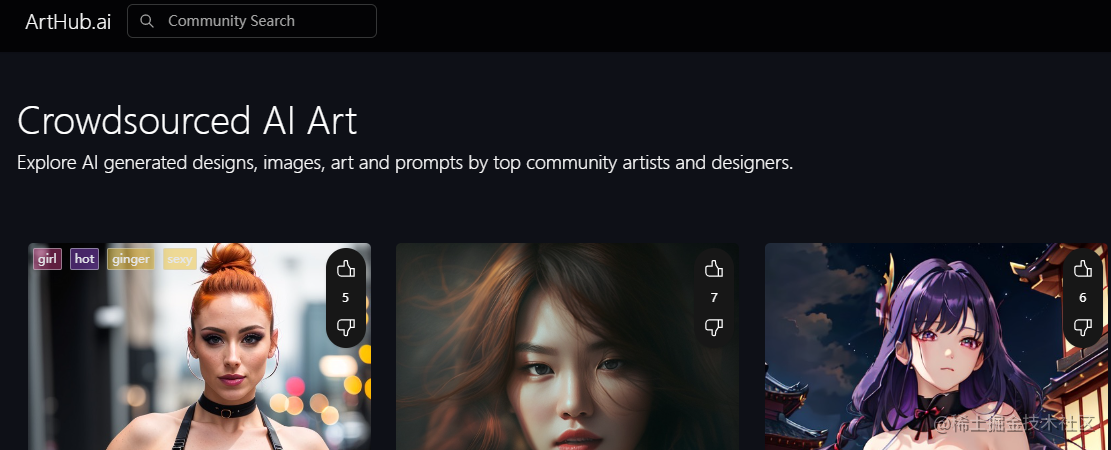
AI绘画关键词网站推荐 :轻松获取百万个提示词!完全免费
一、lexica.art 该网站拥有数百万Stable Diffusion案例的文字描述和图片,可以为大家提供足够的创作灵感。 使用上也很简单,只要在搜索框输入简单的关键词或上传图片,就能为你提供大量风格不同的照片。点击照片就能看到完整的AI关键词&#…...

Java-Collections and Lambda
Java SE API know how 集合API 根据算法访选择合适集合 linkedlist不适合搜索 随机访问数据用hashmap 数据保持有序使用treemap 通过索引访问使用数组集合 同步和非同步 访问性能统计 与简单的非同步访问相比,使用任何数据保护技术都会有较小的损失 设置集合…...

KDGX-A光缆故障断点检测仪
一、产品概述 KDGX-A光纤寻障仪是武汉凯迪正大为光纤网络领域施工、测试、维护所设计的一款测试仪表。可实现对光纤链路状态和故障的快速分析,适用于室外维护作业,是现场光纤网络测试与维护中替代OTDR的经济型解决方案。 二、主要特点 1)一键式光纤链路…...
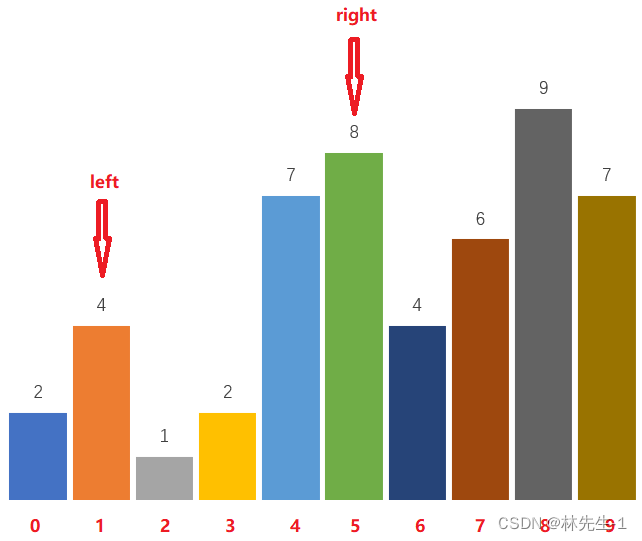
【刷题之路Ⅱ】牛客 NC107 寻找峰值
【刷题之路Ⅱ】牛客 NC107 寻找峰值一、题目描述二、解题1、方法1——直接遍历1.1、思路分析1.2、代码实现2、方法2——投机取巧的求最大值2.1、思路分析2.2、代码实现3、方法3——二分法3.1、思路分析3.2、代码实现一、题目描述 原题连接: NC107 寻找峰值 题目描…...
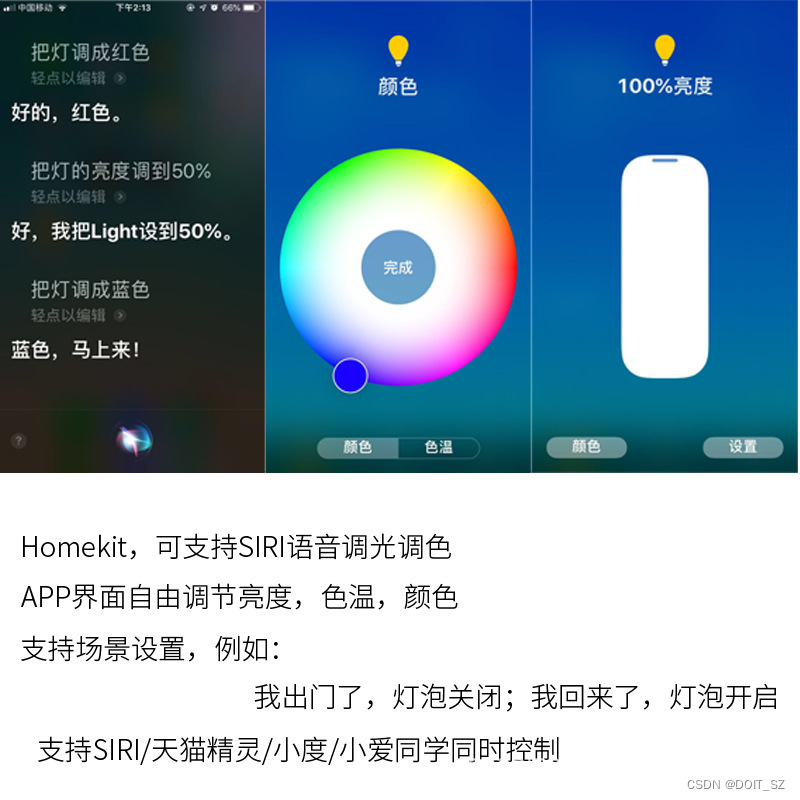
智能灯泡一Homekit智能家居系列
传统的灯泡是通过手动打开和关闭开关来工作。有时,它们可以通过声控、触控、红外等方式进行控制,或者带有调光开关,让用户调暗或调亮灯光。 智能灯泡内置有芯片和通信模块,可与手机、家庭智能助手、或其他智能硬件进行通信&#…...

外包离职,历时学习416天,成功上岸百度,分享成长过程~
前言: 没有绝对的天才,只有持续不断的付出。对于我们每一个平凡人来说,改变命运只能依靠努力幸运,但如果你不够幸运,那就只能拉高努力的占比。 2020年7月,我有幸成为了百度的一名Java后端开发,…...
利用客户支持建立忠诚度和竞争优势
客户支持可以极大地改变您的业务;最细微、最微妙的差异都会使拥有一次性客户和拥有终身客户之间产生差异。在这篇博文中,我们将揭示客户对企业的忠诚度的三种核心类型,以及如何利用强大的客户支持工具和原则来提高理想的忠诚度并获得决定性的竞争优势。一…...

看他人代码小总结
针对几个功能类似的函数: 1.需要经常调试则定义一个参数比如is_debug来选择是否在调试,定义一些参数专门用于调试用,不用每次都修改这些参数,只需要修改is_debug这个参数; 2.把其中的变量(常量)单独拎出来放到一个文件…...
cudaMemGetInfo()函数cudaDeviceGetAttribute()函数来检查设备上的可用内存
使用CUDA Runtime API中的cudaMemGetInfo()函数来检查设备上的可用内存。该函数将返回当前可用于分配的总设备内存大小和当前可用于分配的最大单个内存块大小。 示例代码,演示了如何在分配内存之前和之后调用cudaMemGetInfo()函数来检查可用内存 size_t free_byte…...

【基础阶段】01中华人民共和国网络安全法
文章目录1 网络安全行业介绍2 什么是黑客和白帽子3 网络安全课程整体介绍4 网络安全的分类5 常见的网站攻击方式6 安全常见术语介绍7 《网络安全法》制定背景和核心内容8 《全国人大常委会关于维护互联网安全的决定》9《中华人民共和国计算机信息系统安全保护条例》10 《中华人…...

隐私计算领域大咖推荐,这些国内外导师值得关注
开放隐私计算 经过近一个月的信息收集,研习社已经整理了多位国内外研究隐私计算的导师资料。邻近考研复试,研习社希望小伙伴们能够通过本文整理的信息,选择自己心仪的老师,在研究生的路途上一帆风顺!1. 国内隐私计算导…...

009 uni-app之vue、vuex
vue.js 视频教程 vue3.js 中文官网 vue.js 视频教程 vue语法:https://uniapp.dcloud.net.cn/tutorial/vue-vuex.html vue2迁移到 vue3:https://uniapp.dcloud.net.cn/tutorial/migration-to-vue3.html Vuex Vuex 是一个专为 Vue.js 应用程序开发的…...
Linux防火墙——SNAT、DNAT
目录 NAT 一、SNAT策略及作用 1、概述 SNAT应用环境 SNAT原理 SNAT转换前提条件 1、临时打开 2、永久打开 3、SNAT转换1:固定的公网IP地址 4、SNAT转换2:非固定的公网IP地址(共享动态IP地址) 二、SNAT实验 配置web服务…...
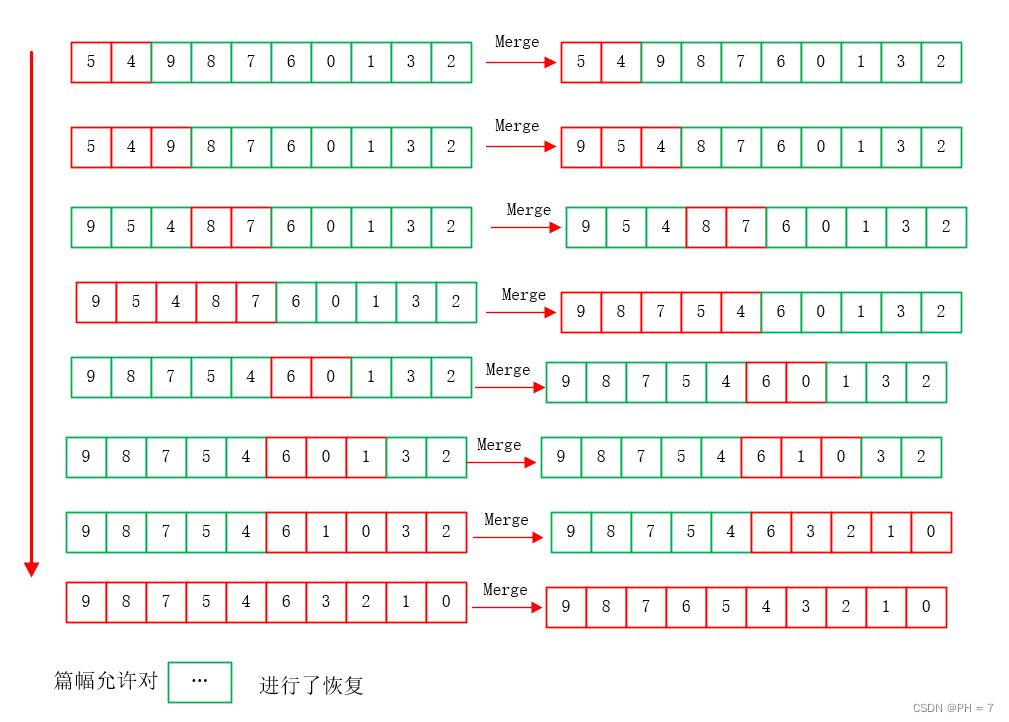
递归理解三:深度、广度优先搜索,n叉树遍历,n并列递归理解与转非递归
参考资料: DFS 参考文章BFS 参考文章DFS 参考视频二叉树遍历规律递归原理源码N叉树规律总结: 由前面二叉树的遍历规律和递归的基本原理,我们可以看到,二叉树遍历口诀和二叉树递推公式有着紧密的联系 前序遍历:F(x…...
MATLAB 2023a安装包下载及安装教程
[软件名称]:MATLAB 2023a [软件大小]: 12.2 GB [安装环境]: Win11/Win 10/Win 7 [软件安装包下载]:https://pan.quark.cn/s/8e24d77ab005 MATLAB和Mathematica、Maple并称为三大数学软件。它在数学类科技应用软件中在数值计算方面首屈一指。行矩阵运算、绘制函数和数据、实现算…...

从仿真到实物:音频功率放大器PCB设计前的Proteus验证全流程
从仿真到实物:音频功率放大器PCB设计前的Proteus验证全流程 在硬件开发领域,音频功率放大器的设计往往需要经历多次迭代才能达到理想性能。传统开发流程中,工程师们常常需要反复制作PCB原型并进行实测,这不仅耗时耗力,…...

罗技鼠标宏:专业级压枪系统构建指南
罗技鼠标宏:专业级压枪系统构建指南 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 在竞技射击游戏中,精准控制武器后坐力…...

SEO 每天需要做内容优化吗
<h2>SEO 每天需要做内容优化吗?</h2> <p>在当今数字化时代,搜索引擎优化(SEO)已经成为每一个网站和品牌在争夺在线流量和曝光度时不可或缺的工具。面对SEO的复杂性,许多人常常会疑惑:SEO…...

OpenClaw 2026年阿里云8分钟本地云端集成零基础部署及使用教程
OpenClaw 2026年阿里云8分钟本地云端集成零基础部署及使用教程。本文面向零基础用户,完整说明在轻量服务器与本地Windows11、macOS、Linux系统中部署OpenClaw(Clawdbot)的流程,包含环境配置、服务启动、Skills集成、阿里云百炼API…...

CLIP-GmP-ViT-L-14真实案例:医学影像报告关键词→对应CT/MRI图精准检索
CLIP-GmP-ViT-L-14真实案例:医学影像报告关键词→对应CT/MRI图精准检索 1. 项目背景与价值 在医疗影像诊断领域,医生经常需要根据影像报告中的关键词快速定位到对应的CT或MRI图像片段。传统方法依赖人工标注和检索,效率低下且容易出错。CLI…...

Cogito-V1-Preview-Llama-3B开发:微信小程序智能客服对接实战
Cogito-V1-Preview-Llama-3B开发:微信小程序智能客服对接实战 最近有不少朋友在问,把大模型部署到服务器上之后,怎么才能让微信小程序用起来?今天我就以星图GPU平台上部署的Cogito-V1-Preview-Llama-3B模型为例,跟大家…...

蓝桥杯备赛避坑指南:从校赛落选到国三逆袭的实战经验分享
蓝桥杯备赛避坑指南:从校赛落选到国三逆袭的实战经验分享 第一次参加蓝桥杯校赛时,我连最简单的编程题都没能完整写出。看着屏幕上仅完成的两道签到题和一堆未通过的测试用例,那种挫败感到现在都记忆犹新。但正是这次失败,让我后来…...

从零构建:基于FreeRTOS与LVGL的低功耗智能手表实战指南
1. 项目背景与核心目标 第一次接触智能手表开发是在三年前,当时市面上开源的方案要么功能简陋,要么功耗高得离谱。作为一个嵌入式老鸟,我决定自己动手搞一套真正可用的低功耗方案。经过多次迭代,最终选择了FreeRTOSLVGL这个黄金组…...

Qwen3-4B-Instruct-2507从入门到精通:Chainlit界面定制化教程
Qwen3-4B-Instruct-2507从入门到精通:Chainlit界面定制化教程 1. 引言:为什么选择Qwen3-4B-Instruct-2507? 如果你正在寻找一个既强大又轻量、既能快速部署又能灵活定制界面的AI模型,那么Qwen3-4B-Instruct-2507绝对值得你深入了…...
推理实测)
vLLM-v0.17.1效果展示:vLLM支持MoE模型(如Mixtral)推理实测
vLLM-v0.17.1效果展示:vLLM支持MoE模型(如Mixtral)推理实测 1. vLLM框架核心能力 vLLM是一个专注于大语言模型推理的高性能服务库,最新发布的v0.17.1版本带来了对MoE(混合专家)架构模型的全面支持。这个最…...