kafka基础概念二
1.Kafka中主题和分区的概念
1.主题Topic
主题-topic在kafka中是一个逻辑的概念,kafka通过topic将消息进行分类。不同的topic会被订阅该topic的消费者消费
但是有一个问题,如果说这个topic中的消息非常非常多,多到需要几T来存,因为消息是会被保存到10g日志文件中的。为了解决这个文件过大的问题,kafka提出了Partition分区的概念
2.分区Partition
1)分区的概念
通过partition将一个topic中的消息分区来存储。这样的好处有多个:
- 分区存储,可以解决统一存储文件过大的问题
- 提供了读写的吞吐量:读和写可以同时在多个分区中进行

2)创建多分区的主题
[root@k8s-master bin]# kafka-topics.sh --create --bootstrap-server 10.0.8.2:9092 --replication-factor 1 --partitions 2 --topic test1
分区的作用:
- 可以分布式存储
- 可以并行写
实际上是存在data/kafka-logs/test-0 和 test-1中的0000000.log文件中,且消费者定期将自己消费分区的ofset提交给kafka内部 topic
小细节:
- 00000.og:这个文件中保存的就是消息
- __consumer_offsets-49:
kafka内部自己创建了_consumer_offsets主题包含了50个分区。这个主题用来存放消费者消费某个主题的偏移量。因为每个消费者都会自己维护着消费的主题的偏移量,也就是说每个消费者会把消费的主题的偏移量自主上报给kafka中的默认主题:__consumer_offsets。因此kafka为了提升这个主题的并发性,默认设置了50个分区。
提交到哪个分区:通过hash函数:hash(consumerGroupld)%consumer offsets主题的分区数。提交到该主题中的内容是:key是consumerGroupld+topic+分区号,value就是当前offset的值 - 文件中保存的消息,默认保存7天。七天到后消息会被删除。
2.kafka集群操作
kafka集群搭建之前博客有介绍,且部署文档百度搜索很多,不过多赘述;
1.搭建kafka集群(三个broker)
创建三个server.properties文件.
#0 1 2
broker.id=2
// 9092 9093 9094
listenerS=PLAINTEXT://192.168.65.60:9094//kafka-logs kafka-logs-l kafka-logs-2log.dir=/usr/local/data/kafka-logs-2
通过命令来启动三台broker.
kafka-server-start.sh-daemon ../config/server.properties
kafka-server-start.sh-daemon ../config/serverl.properties
kafka-server-start.sh-daemon ../config/server2.properties校验是否启动成功
进入到zk中查看/brokers/ids中过是否有三个znode(0,1,2)
2. 副本的概念
在创建主题时,除了指明了主题的分区数以外,还指明了副本数,那么副本是一个什么概念呢?
副本是为了为主题中的分区创建多个备份,多个副本在kafka集群的多个broker中,会有一个副本作为leader,其他是follower。


- leader:
kafka的写和读的操作,都发生在leader上。leader负责把数据同步给folower。当leader挂了,经过主从选举,从多个follower中选举产生一个新的leader - follower
接收leader的同步的数据 - isr:
可以同步和已同步的节点会被存入到isr集合中。这里有一个细节:如果isr中的节点性能较差,会被提出isr集合
此时,broker、主题、分区、副本 这些概念就全部展现了;
集群中有多个broker,创建主题时可以指明主题有多个分区(把消息拆分到不同的分区中存储),可以为分区创建多个副本,不同的副本存放在不同的broker里。
3.关于集群消费
- 向集群发送消息:
kafka-console-consumer.sh--bootstrap-server 172.16.253.38:9092,172.16.253.38:9093,172.16.253.38:9094 --from-beginning --consumer-property group.id=testGroupl --topic my-replicated-topic
- 从集群中消费消息
kafka-console-producer.sh--broker-list 172.16.253.38:9092,172.16.253.38:9093,172.16.253.38:9094 --topicmy-replicated-topic
- 指定消费组来消费消息
kafka-console-consumer.sh --bootstrap-server 172.16.253.38:9092,172.16.253.38:9093,172.16.253.38:9094 --from-beginning --consumer-property group.id=testGroup1 --topicmy-replicated-topic
分区分消费组的集群消费中的细节

- 一个partition只能被一个消费组中的一个消费者消费,目的是为了保证消费的顺序性,但是多个partion的多个消费者消费的总的顺序性是得不到保证的,那怎么做到消费的总顺序性呢?
- partition的数量决定了消费组中消费者的数量,建议同一个消费组中消费者的数量不要超过partition的数量,否则多的消费者消费不到消息
- 如果消费者挂了,那么会触发rebalance机制(后面介绍),会让其他消费者来消费该分区
3.kafka的java客户端-生产者的实现
1.生产者的基本实现
- 引入依赖
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactIdA<version>2.4.1</version>
</dependency>
具体实现
package com.qf.kafka;
import org.apache.kafka.clients.producer**
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.ExecutionExceptioon;public class MySimpleProducer {private final static String TOPIC_NAME = "my-reeplicated-topic";public static void main(String[] args) throws ExecutiionException, InterruptedException//1.设置参数Properties props=new Properties();props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG"172.16.253.38:9092,172.16.253.38:9093,1722.16.253.38:9094");//把发送的key从字符串序列化为字节数组props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName())//把发送消息value从字符串序列化为字节数组props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());//2.创建生产消息的客户端,传入参数Producer<String, String> producer = new KafkaProducer<String, String>(props)//3.创建消息//key:作用是决定了往哪个分区上发,value:具体要发送的消息内容ProducerRecord<String, String> producerRecord =new ProducerRecord<>(TOPIC_NAME,"mykeyvalue","hellokafka");//4.发送消息,得到消息发送的元数据并输出 --同步发送RecordMetadata metadata = producer.send(producerRecord).get()System.out.println("同步方式发送消息结果:"+" topiic-" + metadata.topic()+ "| partition-" + metadata.partition() + "| offset-" + metadata.offset())})
2.生产者同步发消息

如果生产者发送消息没有收到ack,生产者会阻塞,阻塞到3s的时间,如果还没有收到消息,会进行重试。重试的次数3次。
RecordMetadata metadata = producer.send(producerRecord).get()
System.out.println("同步方式发送消息结果: "+" topiic-" + metadata.topic()+ " |partition-" + metadata.partition() + "|offset-" + metadata.offset())
3.生产者的异步发送消息
异步发送,生产者发送完消息后就可以执行之后的业务,broker在收到消息后异步调用生产者提供的callback回调方法。

//5.异步发送消息
producer.send(producerRecord, new Callback() {public void onCompletion(RecordMetadata metadata,Exception exception)if (exception != null) {System.err.println("发送消息失败:"+exception.getsStackTrace());}if (metadata != null) {System.out.println("异步方式发送消息结果: " + "topic-" + metadata.topic() + " | partition-"metadata.partition() + "| offset-" + metadata.offset());}}
});
4.生产者中的ack的配置
在同步发送的前提下,生产者在获得集群返回的ack之前会一直阻塞。那么集群什么时候返回ack呢?此时ack有3个配置:
- ack=0kafka-cluster不需要任何的broker收到消息,就立即返回ack给生产者,最容易丢消息的,效率是最高的
- ack=1(默认):多副本之间的leader已经收到消息,并把消息写/入到本地的log中,才会返回ack给生产者,性能和安全性是最均衡的
- ack=-1/all。里面有默认的配置min.insync.replicas=2(默认为1,推荐配置大于等于2),此时就需要leader和一个follower同步完后, 才会返回ack给生产者(此时集群中有2个broker已完成数据的接收),这种方式最安全,但性能最差。

下面是关于ack和重试(如果没有收到ack,就开启重试)的配置
props.put(ProducerConfig.ACKS_CONFIG, "1");/* 发送失败会重试,默认重试间隔100ms,重试能保证消息发送的可靠性,但是也可能造成消息重复发送,比如网络抖动,所以需要在
接收者那边做好消息接收的幂等性处理 */props.put(ProducerConfig.RETRIES_CONFIG, 3);//重试间隔设置props.put(ProducerConfig.RETRY_BACKOFF_MS_CONFIG, 300);
5.关于消息发送的缓冲区

kafka默认会创建一个消息缓冲区,用来存放要发送的消息,缓冲区是32m
props.put(ProducerConfig.BUFFER_MEMORY_CONFIG,33554432);
kafka本地线程会去缓冲区中一次拉16k的数据,发送到broker
props.put(ProducerConfig.BATCH_SIZE_CONFIG, 161384)
如果线程拉不到16k的数据,间隔10ms也会将已拉到的数据发到到broker
props.put(ProducerConfig.LINGER_MS_CONFIG,10);
3.Java客户端消费者的实现细节
1.消费者的基本实现
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
public class MySimpleConsumer {
private final static String TOPIC_NAME = "my-replicated-topic";
private final static String CONSUMER_GROUP_NAME = "testGroup";public static void main(String[] args){Properties props=new Properties();props.put (ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "172.16.253.38:9092,172.16.253.38:9093,172.16.253.388:9094");//消费分组名props.put(ConsumerConfig.GROUP_ID_CONFIG, CONSUMER_GROUP_NAME);props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());props.put (ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONPIG, SStringDeserializer.class.getName())//创建一个消费者的客户端KafkaConsumer<String, String> consumer = new Kafkaconsumer<String,String>(props)//消费者订阅主题列表consumer.subscribe (Arrays.asList(TOPIC_NAME)) ;while (true) {/**poll()API是拉取消息的长轮询*/ConsumerRecords<String, String> records = coonsumer.poll(Duration.ofMillis(1000))for (ConsumerRecord<String,String>record:records){System.out.printf("收到消息:partition= %d, offset = %d, key = is, value = %s%n", record.partition(),record.offset(),record.key(), record.value())}}
}

2.关于消费者自动提交和手动提交offset
1) 提交的内容
消费者无论是自动提交还是手动提交,都需要把所属的消费组消费的某个主题+消费的某个分区及消费的偏移量,这样的信息是交到集群的_consumer_offsets主题里面。
2) 自动提交
消费者poll消息下来以后就会自动提交offset
// 是否自动提交offset,默认就是true
props.put (ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");//自动提交offset的间隔时间
props.put (ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
3) 手动提交
需要把自动提交的配置改成false
props.put (ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false")
手动提交又分成了两种:

- 手动同步提交
在消费完消息后调用同步提交的方法,当集群返回ack前一直阻塞,返回ack后表示提交成功,执行之后的逻辑
while(true) {/**poll()API是拉取消息的长轮询*/ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000))for (ConsumerRecord<String, String> record : records) {System.out.printf("收到消息:partition=1d,offset=td,key = ts,value = ts@n",record.partition(),record.offset(),record.key(),record.value());}//所有的消息已消费完if(records.count()>0){//有消息//手动同步提交offset,当前线程会阻塞直到offset提交房成功//一般使用同步提交,因为提交之后一般也没有什么逻辑代码了consumer.commitSync();//==========提交成功}}
}
- 异步提交
while (true) {/**poll()API是拉取消息的长轮询*/ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000))for (ConsumerRecord<String, String> record : records) {System.out.printf("收到消息:partition = %d,offset = %d,key = %s,value = %s%n",record.partition(),record.offset(),record.key(),record.value());}//所有的消息已消费完if(records.count()>0){//手动异步提交offset,当前线程提交offset不会阻塞,可以继续处理后面的程序逻辑consumer.commitAsync(new OffsetCommitCallback(){@Overridepublic void onComplete(Map<TopicPartition,OffsetAndMetadata> offsets, Exception exception){if(exception!=null){System.err.println("Commit failed for " + offsets);System.err.println("Commit failed exception: " + exception.getStackTrace())}}
}
3.长轮询poll消息
默认情况下,消费者一次会poll500条消息。
//一次pol1最大拉取消息的条数,可以根据消费速度的快慢来设置
props.put (ConsumerConfig.MAX_POLL_RECORDS_COMNFIG, 500);
代码中设置了长轮询的时间是1000毫秒
while(true){* poll()API是拉取消息的长轮询ConsumerRecords<String, String> records = conisumer.poll(Duration.ofMillis(1000))for (ConsumerRecord<String, String> record : records)System.out.printf("收到消息:partition= %d,offset= %d, key = %s, value = %s%n", record.partition(),record.offset(),record.key(), record.vaalue())}
意味着:
-
- 如果一次poll到500条,就直接执行for循环
- 如果这一次没有poll到500条。且时间在1秒内,那么长轮询继续poll,要么到500条,要么到1s
- 如果多次poll都没达到500条,且1秒时间到了,那么直接执行for循环
- 如果两次poll的间隔超过30s,集群会认为该消费者的消费能力过弱,该消费者被踢出消费组,触发rebalance机制,rebalance机制
会造成性能开销。可以通过设置这个参数,让一次poll的消息条数少一点
//一次pol1最大拉取消息的条数,可以根据消费速度的快慢来设置
props.put(ConsumerConfig.MAX_POLL_RECORDS_CODNFIG,500)
//如果两次pol1的时间如果超出了30s的时间间隔,kafka会认为其消费能力过弱,将其踢出消费组。将分区分配给其他消费者。-rebalance
props.put(ConsumerConfig.MAX_POLL_INTERVAL_MIS_CONFIG, 30 * 1000);
相关文章:
kafka基础概念二
1.Kafka中主题和分区的概念 1.主题Topic 主题-topic在kafka中是一个逻辑的概念,kafka通过topic将消息进行分类。不同的topic会被订阅该topic的消费者消费 但是有一个问题,如果说这个topic中的消息非常非常多,多到需要几T来存,因…...

牛客-热身小游戏
题目链接:热身小游戏 第一种写法:线段树 介绍第二种写法:并查集 对于一些已经查询过的点,我们可以往后跳,进行路径压缩,他们的父亲为下一个点。 a数组记录[ l , r ] 之间的乘积,初始值为1。…...

Python 深度学习调试问题
Python–深度学习解决的常见问题 1.在自己写测试样例的时候,有时候可能将要传入的是input_size,不小心传入为input_dim,这个时候会导致出现问题,自定义的卷积模块或者池化等模块会提示类型问题。 解决的策略是: 1.进行assert i…...

linux恶意请求
nginx访问日志: 162.243.135.29 - - [05/Jan/2024:00:12:07 0800] "GET /autodiscover/autodiscover.json?zdi/Powershell HTTP/1.1" 404 153 "-" "Mozilla/5.0 zgrab/0.x"107.151.182.54 - - [04/Mar/2024:11:30:06 0800] "G…...

Java 反射笔记总结(油管)
Java系列文章目录 IDEA使用指南 Java泛型总结(快速上手详解) Java Lambda表达式总结(快速上手详解) Java Optional容器总结(快速上手图解) Java 自定义注解笔记总结(油管) Jav…...

HTML表格、表单、标签、CSS、选择器
目录 一、HTML表格 二、表单 三、布局标签 四、CSS 五、选择器 一、HTML表格 table:表格 tr:行 td:单元格;rowspan:纵向合并相邻单元格;clospan:横向合并相邻单元格 th:单元格加粗居中 border&…...

【javaWeb技术】·外卖点餐小程序(脚手架学习1·数据库)
🌈 个人主页:十二月的猫-CSDN博客 🔥 系列专栏: 🏀系统学javaWeb开发_十二月的猫的博客-CSDN博客 💪🏻 十二月的寒冬阻挡不了春天的脚步,十二点的黑夜遮蔽不住黎明的曙光 【免费】项…...

LVS 实现四层负载均衡项目实战--DR模式
一、环境准备 主机名IP地址router eth0:172.25.254.100 eth1:192.168.0.100 clienteth0:172.25.254.200lvseth1:192.168.0.50web1web2 1、client配置 [rootclient ~]# cat /etc/NetworkManager/system-connections/eth0.nmconne…...

Python与Qt的对应版本
Python与Qt的对应版本并没有严格的一一对应关系,但通常在使用Python与Qt进行开发时,会选择一个兼容性较好的版本组合。Qt的Python绑定库主要是PyQt和PySide,以下是几个常见的搭配: 1. **PyQt5**: - Python 3.5及以上版…...
WPF篇(12)-Image图像控件+GroupBox标题容器控件
Image图像控件 Image也算是独门独户的控件,因为它是直接继承于FrameworkElement基类。 Image控件就是图像显示控件。Image类能够加载显示的图片格式有.bmp、.gif、.ico、.jpg、.png、.wdp 和 .tiff。要注意的是,加载.gif动画图片时,仅显示第…...

LeetCode 热题 HOT 100 (024/100)【宇宙最简单版】
【哈希表】No. 0128 最长连续序列【中等】👉力扣对应题目指路 希望对你有帮助呀!!💜💜 如有更好理解的思路,欢迎大家留言补充 ~ 一起加油叭 💦 欢迎关注、订阅专栏 【力扣详解】谢谢你的支持&am…...

如何在AWS上进行 环境迁移
在 AWS 上进行环境迁移通常包括以下几个步骤和最佳实践: 1. 评估和规划 评估当前环境:审查现有的应用程序、数据库、网络架构和依赖关系。确定迁移目标:明确迁移的目标(如成本节约、性能提升、可扩展性等)。选择迁移策略:根据应用程序的类型和复杂性,选择合适的迁移策略…...

云服务器和物理服务器的优缺点对比
云服务器优点在于灵活性强、成本效益高、易于扩展且支持全球化部署;缺点则包括安全性与可控性相对较弱,性能可能受限,以及存在服务中断风险。物理服务器则以其高性能、高稳定性、强安全性和完全可控性著称,但成本较高、扩展性受限…...

postgreSQL16添加审计功能
下载审计插件 https://github.com/pgaudit/pgaudit/releases他的分支版本支持不同的PGSQL按需下载 编译安装审计插件 tar -xvf pgaudit-16.0.tar.gzmake install USE_PGXS1 PG_CONFIG/app/postgresql/bin/pg_config启用postgreSQL审计功能 修改配置文件# 启用 pgAudit shar…...
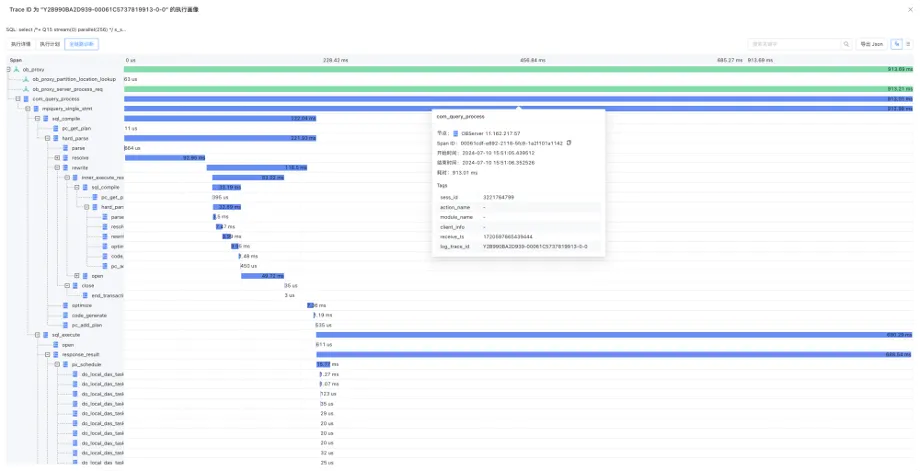
如何应用OceanBase 的实时SQL诊断,解决AP场景下的痛点
随着数据量的快速增长与用户需求的变化,数据库的管理与优化工作日益凸显其重要性。作为DBA及开发者,您是否曾面临以下挑战: ○ 分析场景下,在处理大规模数据的且耗时较长的查询是,常涉及海量数据的处理及复杂的计算&…...

【数据结构】—— 栈
一、栈的基本概念1、栈的定义2、栈的常见基本操作 二、栈的顺序存储1、栈的顺序存储结构2、顺序栈存储实现(1)初始化(2)判空(3)进栈(4)出栈(5)取栈顶元素&…...

Kafka服务端日志详解
文章目录 服务端日志Topic消息存储方式主体介绍log文件追加记录消息index和timeindex索引文件 日志文件清理Kafka的文件高效读写机制Kafka的文件结构顺序写磁盘零拷贝 合理配置刷盘频率客户端消费进度管理 服务端日志 Kafka的日志信息是通过conf/server.properties文件中的log…...

C++ 数据语义学——进程内存空间布局
进程内存空间布局 1. 栈(堆栈/栈区)2. 堆(堆区)3. BSS段4. 数据段5. 代码段进程内存空间布局示意图可执行文件的内存布局示例代码 当把一个可执行文件加载到内存后,就变成了一个进程。这个虚拟空间(内存&am…...
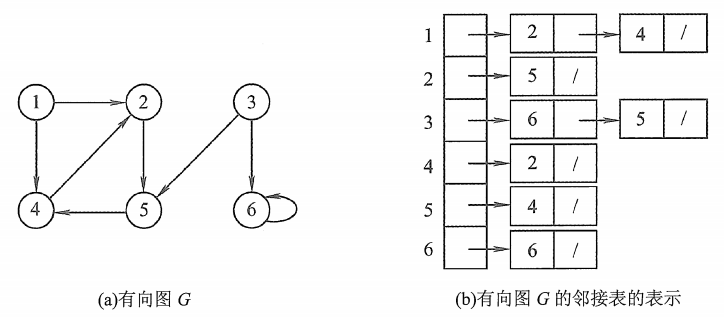
【数据结构】六、图:2.邻接矩阵、邻接表(有向图、无向图、带权图)
二、存储结构 文章目录 二、存储结构❗1.邻接矩阵1.1无向图❗邻接矩阵-无向图代码-C 1.2有向图❗邻接矩阵-有向图代码-C 1.3带权图1.4性能分析1.5相乘 ❗2.邻接表2.1无向图2.2有向图❗邻接表-C 邻接矩阵VS邻接表邻接矩阵邻接表 ❗1.邻接矩阵 图的邻接矩阵(Adjacency Matrix) 存…...

财务会计与管理会计(三)
文章目录 销售回款提成表MATCH函数的模糊查询在提成类业务中的应用 营业收入分类数据分析OFFSET函数在制作图表数据中的应用 自动生成销售记录对账单VLOOKUP函数的应用 销售回款提成表 MATCH函数的模糊查询在提成类业务中的应用 G3INDEX(I$1:M$1,MATCH(E3,H3:M3,1)) G3INDEX(…...

告别虚频困扰:用VASP+DynaPhoPy搞定高温材料声子谱的保姆级教程
高温材料声子谱计算实战:从虚频困境到非谐解决方案 引言:虚频问题的根源与突破路径 在计算材料学领域,声子谱分析是理解材料动力学稳定性和热力学性质的核心手段。然而许多研究者都遭遇过这样的困境:对实验合成的材料进行简谐近似…...

PDF 可视化签名盖章页技术解析
本文是我在设备检测系统项目开发中,无设备检测的技术实现备忘录,记载实现过程。 本文以 PC 端页面 sign-pdf.vue 为主线,说明「无设备报检」在报告审批环节如何通过前后端协作,完成报告/记录 PDF 上的签名、印章、报告编号拖放定位,并在审批通过后由后端合并生成带签章的正…...
)
毕业设计 yolov11骨折检测医疗辅助系统(源码+论文)
文章目录 0 前言1 项目运行效果2 课题背景2.1 研究背景2.2 国内外研究现状2.3 研究意义 3 设计框架(骨折检测系统设计框架说明)3.1. 系统架构图3.2. 技术选型3.2.1 核心组件3.2.2 辅助工具 3.3. 核心模块设计3.3.1 YOLO模型训练模块训练流程图关键伪代码…...

解密高校教师必会的Gemini 3.1 Pro五大科研隐藏技能:从论文评估到创新点锁定
各位同仁好,我是七哥。一个在高校里从事人工智能相关领域研究,钻研用大模型AI实操的学术人。可以和七哥交流学术写作或Gemini、GPT、Claude等大模型学术实操相关问题,多多交流,相互成就,共同进步。 科研路上,有人发完顶刊顺利晋升,有人还在为创新点抓耳挠腮。 大多数教…...

OpenRASP原理与实战:Java应用层实时防护技术详解
1. 为什么我宁愿花三天部署OpenRASP,也不愿再写第五个自定义WAF过滤器去年冬天,我在给一家做在线教育SaaS平台做安全加固时,连续踩了三个坑:第一次用NginxLua写了套SQL注入规则,结果学生提交的“SELECT * FROM courses…...

Python strip 与 rstrip 函数区别
Python strip 与 rstrip 函数区别 文章目录Python strip 与 rstrip 函数区别一、核心作用二、基础语法三、基础使用示例四、指定删除特定字符五、常用业务场景一、核心作用 函数作用范围strip()移除字符串首尾空白字符rstrip()仅移除字符串右侧末尾字符,左侧保持不…...

绝了!原来毕业论文还能这样写?2026降AIGC工具推荐合集
还在为查重率爆红、AI痕迹太明显、格式乱成一团而发愁?2026 年的 AI 论文工具早已不只是写文章那么简单,从选题构思到降AIGC率、去AI痕迹、查重优化,全流程智能辅助,帮你把论文写作变得简单高效,告别熬夜改稿的焦虑&am…...

深入解析NxDumpTool:Switch游戏文件系统提取的终极指南 [特殊字符]
深入解析NxDumpTool:Switch游戏文件系统提取的终极指南 🎮 【免费下载链接】nxdumptool Generates XCI/NSP/HFS0/ExeFS/RomFS/Certificate/Ticket dumps from Nintendo Switch gamecards and installed SD/eMMC titles. 项目地址: https://gitcode.com…...

终极Obsidian笔记模板指南:如何用kepano-obsidian构建你的第二大脑
终极Obsidian笔记模板指南:如何用kepano-obsidian构建你的第二大脑 【免费下载链接】kepano-obsidian My personal Obsidian vault template. A bottom-up approach to note-taking and organizing things I am interested in. 项目地址: https://gitcode.com/gh_…...

3个核心问题:如何突破Cursor AI的使用限制并持续获得Pro功能体验?
3个核心问题:如何突破Cursor AI的使用限制并持续获得Pro功能体验? 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: …...