性能调优 18. Tomcat整体架构及其设计精髓分析
1. Tomcat介绍
1.1. 介绍
这边使用的是Tomcat9来做说明,本章节先对Tomcat架构和设计有个整体认识。后续章节会对Tomcat性能调优做说明。
官方文档介绍
https://tomcat.apache.org/tomcat-9.0-doc/index.html1.2. Tomcat概念
Tomcat是Apache Software Foundation(Apache软件基金会)开发的一款开源的Java Servlet容器。它是一种Web服务器,用于在服务器端运行Java Servlet和JavaServer Pages (JSP)技术。它可以为Java Web应用程序提供运行环境,并通过HTTP协议处理客户端请求。Tomcat也支持多种Web应用程序开发技术,例如JavaServer Faces (JSF)、Java Persistence API (JPA)等。总的来说,Tomcat是一款高效、稳定和易于使用的Web服务器。
Tomcat核心: Http服务器+Servlet容器。

1.3. Tomcat目录结构
Tomcat的解压之后的目录可以看到如下的目录结构。

binbin目录主要是用来存放tomcat的脚本,如startup.sh , shutdown.shconfcatalina.policy: Tomcat安全策略文件,控制JVM相关权限,具体可以参考java. security.Permissioncatalina.properties : Tomcat Catalina行为控制配置文件,比如Common ClassLoaderlogging.properties : Tomcat日志配置文件, JDK Logging server.xml : Tomcat Server配置文件GlobalNamingResources :全局JNDI资源context.xml :全局Context配置文件tomcat-users.xml : Tomcat角色配置文件web.xml : Servlet标准的web.xml部署文件, Tomcat默认实现部分配置入内:org.apache.catalina.servlets.DefaultServletorg.apache.jasper.servlet.JspServletlib公共类库logstomcat在运行过程中产生的日志文件webapps用来存放应用程序,当tomcat启动时会去加载webapps目录下的应用程序work用来存放tomcat在运行时的编译后文件,例如JSP编译后的文件
1.4. web应用部署的三种方式
Tomcat的web应用支持war包部署,文件夹部署,描述符部署。
1.4.1. war包部署和文件夹部署
默认情况下,项目war包和文件夹拷贝到webapps目录下就行。war包会自动解压成war包名称的文件夹。
该目录跟Host标签的appBase有关。
//指定appBase
<Host name="localhost" appBase="webapps" unpackWARs="true" autoDeploy="true"> autoDeploy:表示支持热部署。
1.4.2. 描述符部署
在server.xml 的Context标签下配置Context。比如下面这样,比较常用的描述符部署。
<Context docBase="D:\mvc" path="/mvc" reloadable="true" /> path:指定访问该Web应用的URL入口(context-path)。
docBase:指定Web应用的文件路径,可以给定绝对路径,也可以给定相对于<Host>的appBase属性的相对路径。
reloadable:如果这个属性设为true,支持热加载,tomcat服务器在运行状态下会监视在WEB-INF/classes和WEB-INF/lib目录下class文件的改动,如果监测到有class文件被更新的,服务器会自动重新加载Web应用。
1.4.3. 比较特殊的部署
在$CATALINA_BASE/conf/[enginename]/[hostname]/ 目录下(默认conf/Catalina/localhost)创建xml文件,文件名就是contextPath。比如创建mvc.xml,path就是/mvc。
这种方式不需要重启应用,就可以部署应用。
<Context docBase="D:\mvc" reloadable="true" /> 注意
想要根路径访问,文件名就设置为ROOT.xml。
2. Tomcat整体架构分析
Tomcat 要实现 2 个核心功能:
处理 Socket 连接,负责网络字节流与 Request 和 Response 对象的转化。
加载和管理 Servlet,以及具体处理 Request 请求。
因此 Tomcat 设计了两个核心组件连接器(Connector)和容器(Container)来分别做这两件事情。连接器负责对外交流,容器负责内部处理。
2.1. Tomcat架构图
Tomcat的架构分为以下几个部分:
1. Connector:Tomcat的连接器,用于接收请求并将其发送给容器。
2. Container:Tomcat的容器,负责管理Servlet、JSP和静态资源的生命周期。
3. Engine:Tomcat的引擎,管理容器的生命周期和分配请求。
4. Host:Tomcat的主机,可以管理多个Web应用程序。
5. Context:Tomcat的上下文,用于管理单个Web应用程序的配置信息。
6. Servlet:Tomcat的Servlet,负责处理请求并生成响应。
7. JSP:Tomcat的JSP,用于动态生成Web内容。
总的来说,Tomcat的架构是一个分层的架构,每一层都有其自己的功能和职责。该架构可以提高Tomcat的性能和可维护性,并使得Tomcat可以支持大量的Java Web应用程序。
其中四大容器分别是Engine,Host,Context,Wrapper。其标准实现分别有StandardEngine,StandardHost,StandardContext,StandardWrapper,都实现了org.apache.catalina.Container接口。

2.2. Tomcat核心组件详解
2.2.1. Server 组件
指的就是整个 Tomcat 服务器,包含多组服务(Service),负责管理和启动各个Service,同时监听8005端口发过来的 shutdown 命令,用于关闭整个容器 。
2.2.2. Service组件
每个 Service 组件都包含了若干用于接收客户端消息的 Connector 组件和处理请求的 Engine 组件。 Service 组件还包含了若干 Executor 组件,每个 Executor 都是一个线程池,它可以为 Service内所有组件提供线程池执行任务。 Tomcat 内可能有多个 Service,这样的设计也是出于灵活性的考虑。通过在Tomcat 中配置多个 Service,可以实现通过不同的端口号来访问同一台机器上部署的不同应用。

2.2.3. 连接器Connector组件
Tomcat 与外部世界的连接器,监听固定端口接收外部请求,传递给 Container,并将Container处理的结果返回给外部。连接器对 Servlet 容器屏蔽了不同的应用层协议及 I/O 模型,无论是 HTTP还是 AJP,在容器中获取到的都是一个标准的 ServletRequest 对象。
2.2.4. 容器Container组件
容器,顾名思义就是用来装载东西的器具,在 Tomcat 里,容器就是用来装载 Servlet 的。
Tomcat 通过一种分层的架构,使得 Servlet 容器具有很好的灵活性。Tomcat 设计了 4 种容器,分别是 Engine、Host、Context 和 Wrapper。这 4 种容器不是平行关系,而是父子关系。
Engine:引擎,Servlet 的顶层容器,用来管理多个虚拟站点,一个 Service 最多只能有一个 Engine。
Host:虚拟主机,负责 web 应用的部署和 Context 的创建。可以给 Tomcat配置多个虚拟主机地址,而一个虚拟主机下可以部署多个 Web 应用程序。
Context:Web 应用上下文,包含多个 Wrapper,负责 web 配置的解析、管理所有的 Web 资源。一个Context对应一个 Web 应用程序。
Wrapper:表示一个 Servlet,最底层的容器,是对 Servlet 的封装,负责 Servlet 实例的创建、执行和销毁。

2.3. 结合Server.xml理解Tomcat架构
以通过 Tomcat 的 server.xml 配置文件来加深对 Tomcat 架构的理解。Tomcat 采用了组件化的设计,它的构成组件都是可配置的,其中最外层的是 Server,其他组件按照一定的格式要求配置在这个顶层容器中。
<Server> //顶层组件,可以包括多个Service<Service> //顶层组件,可包含一个Engine,多个连接器<Connector/>//连接器组件,代表通信接口<Engine>//容器组件,一个Engine组件处理Service中的所有请求,包含多个Host<Host> //容器组件,处理特定的Host下客户请求,可包含多个Context<Context/> //容器组件,为特定的Web应用处理所有的客户请求</Host></Engine></Service> </Server>
Tomcat启动期间会通过解析 server.xml,利用反射创建相应的组件,所以xml中的标签和源码一一对应。
2.4. 请求定位 Servlet 的过程
Tomcat 是用 Mapper 组件来完成这个任务的。Mapper 组件的功能就是将用户请求的 URL 定位到一个 Servlet,它的工作原理是:Mapper 组件里保存了 Web 应用的配置信息,其实就是容器组件与访问路径的映射关系,比如 Host 容器里配置的域名、Context 容器里的 Web 应用路径,以及Wrapper 容器里 Servlet 映射的路径,你可以想象这些配置信息就是一个多层次的 Map。当一个请求到来时,Mapper 组件通过解析请求 URL 里的域名和路径,再到自己保存的 Map 里去查找,就能定位到一个 Servlet。一个请求 URL 最后只会定位到一个 Wrapper 容器,也就是一个 Servlet。

3. Tomcat架构设计精髓分析
3.1. Connector高内聚低耦合设计
优秀的模块化设计应该考虑高内聚、低耦合:
高内聚是指相关度比较高的功能要尽可能集中,不要分散。
低耦合是指两个相关的模块要尽可能减少依赖的部分和降低依赖的程度,不要让两个模块产生强依赖。
Tomcat连接器需要实现的功能
监听网络端口(三次握手)。
接受网络连接请求。
读取请求网络字节流。
根据具体应用层协议(HTTP/AJP)解析字节流,生成统一的 Tomcat Request 对象。
将 Tomcat Request 对象转成标准的 ServletRequest。
调用 Servlet 容器,得到 ServletResponse。
将 ServletResponse 转成 Tomcat Response 对象。
将 Tomcat Response 转成网络字节流。
将响应字节流写回给浏览器。
分析连接器详细功能列表,我们会发现连接器需要完成 3 个高内聚的功能
网络通信。
应用层协议解析。
Tomcat Request/Response 与 ServletRequest/ServletResponse 的转化。
因此 Tomcat 的设计者设计了 3 个组件来实现这 3 个功能,分别是 EndPoint、Processor 和
Adapter。
EndPoint 负责提供字节流给 Processor。
Processor 负责提供 Tomcat Request 对象给 Adapter。
Adapter 负责提供 ServletRequest 对象给容器。
注意
组件之间通过抽象接口交互。这样做的好处是封装变化。这是面向对象设计的精髓,将系统中经常变化的部分和稳定的部分隔离,有助于增加复用性,并降低系统耦合度。
由于 I/O 模型和应用层协议可以自由组合,比如 NIO + HTTP 或者 NIO2 + AJP。Tomcat的设计者将网络通信和应用层协议解析放在一起考虑,设计了一个叫 ProtocolHandler 的接口来封装这两种变化点。各种协议和通信模型的组合有相应的具体实现类。比如:Http11NioProtocol 和AjpNioProtocol。
除了这些变化点,系统也存在一些相对稳定的部分,因此 Tomcat 设计了一系列抽象基类来封装这些稳定的部分,抽象基类 AbstractProtocol 实现了 ProtocolHandler 接口。每一种应用层协议有自己的抽象基类,比如 AbstractAjpProtocol 和 AbstractHttp11Protocol,具体协议的实现类扩展了协议层抽象基类。
NIO2就是AIO。
APR是早期没有NIO通过调用操作系统动态链接库,实现该效果。
AJP早期时候,Apache可以反向代理到Tomcat,Apache跟Tomcat通信就用AJP协议。

3.1.2. ProtocolHandler
连接器用 ProtocolHandler 来处理网络连接和应用层协议,包含了 2 个重要部件:EndPoint 和Processor。

连接器用 ProtocolHandler 接口来封装通信协议和 I/O 模型的差异,ProtocolHandler 内部又分为 EndPoint 和 Processor 模块,EndPoint 负责底层 Socket 通信,Proccesor 负责应用层协议解析。连接器通过适配器 Adapter 调用容器。
3.1.2.1. EndPoint
EndPoint 是通信端点,即通信监听的接口,是具体的 Socket 接收和发送处理器,是对传输层的抽象,因此 EndPoint 是用来实现 TCP/IP 协议的。
EndPoint 是一个接口,对应的抽象实现类是 AbstractEndpoint,而 AbstractEndpoint 的具体子类,比如在 NioEndpoint 和 Nio2Endpoint 中,有两个重要的子组件:Acceptor 和SocketProcessor。其中 Acceptor 用于监听 Socket 连接请求。SocketProcessor 用于处理接收到的Socket 请求,它实现 Runnable 接口,在 Run 方法里调用协议处理组件 Processor 进行处理。为了提高处理能力,SocketProcessor 被提交到线程池来执行,而这个线程池叫作执行器(Executor)。
NIO的对应的类还会创建Ploller线程,里头有多路复用选择器处理连接上来的socket的读写。
3.1.1.2. Processor
Processor 用来实现 HTTP/AJP 协议,Processor 接收来自 EndPoint 的 Socket,读取字节流解析成 Tomcat Request 和 Response 对象,并通过 Adapter 将其提交到容器处理,Processor 是对应用层协议的抽象。
Processor 是一个接口,定义了请求的处理等方法。它的抽象实现类 AbstractProcessor 对一些协议共有的属性进行封装,没有对方法进行实现。具体的实现有 AJPProcessor、HTTP11Processor等,这些具体实现类实现了特定协议的解析方法和请求处理方式。

EndPoint 接收到 Socket 连接后,生成一个 SocketProcessor 任务提交到线程池去处理,SocketProcessor 的 Run 方法会调用 Processor 组件去解析应用层协议,Processor 通过解析生成Request 对象后,会调用 Adapter 的 Service 方法。
3.1.2. Adapter(适配器)
由于协议不同,客户端发过来的请求信息也不尽相同,Tomcat 定义了自己的 Request 类来“存放”这些请求信息。ProtocolHandler 接口负责解析请求并生成 Tomcat Request 类。但是这个 Request 对象不是标准的 ServletRequest,也就意味着,不能用 Tomcat Request 作为参数来调用容器。Tomcat 设计者的解决方案是引入 CoyoteAdapter,这是适配器模式的经典运用,连接器调用 CoyoteAdapter 的 Sevice 方法,传入的是 Tomcat Request 对象,CoyoteAdapter 负责将 Tomcat Request 转成 ServletRequest,再调用容器的 Service 方法。
设计复杂系统的基本思路
首先要分析需求,根据高内聚低耦合的原则确定子模块,然后找出子模块中的变化点和不变点,用接口和抽象基类去封装不变点,在抽象基类中定义模板方法,让子类自行实现抽象方法,也就是具体子类去实现变化点。
3.2. 父子容器组合模式设计
思考:Tomcat 设计了 4 大容器,分别是 Engine、Host、Context 和 Wrapper,Tomcat 是怎么管理这些容器的?
Tomcat 采用组合模式来管理这些容器。具体实现方法是,所有容器组件都实现了 Container 接口,因此组合模式可以使得用户对单容器对象和组合容器对象的使用具有一致性。
Container 接口定义如下
public interface Container extends Lifecycle {public void setName(String name);public Container getParent();public void setParent(Container container);public void addChild(Container child);public void removeChild(Container child);public Container findChild(String name);
}3.3. Pipeline-Valve 责任链模式设计
连接器中的 Adapter 会调用容器的 Service 方法来执行 Servlet,最先拿到请求的是 Engine 容器,Engine 容器对请求做一些处理后,会把请求传给自己子容器 Host 继续处理,依次类推,最后这个请求会传给 Wrapper 容器,Wrapper 会调用最终的 Servlet 来处理。那么这个调用过程具体是怎么实现的呢?答案是使用 Pipeline-Valve 管道。
Pipeline-Valve 是责任链模式,责任链模式是指在一个请求处理的过程中有很多处理者依次对请求进行处理,每个处理者负责做自己相应的处理,处理完之后将再调用下一个处理者继续处理。
为什么要使用管道机制?
在一个比较复杂的大型系统中,如果一个对象或数据流需要进行繁杂的逻辑处理,我们可以选择在一个大的组件中直接处理这些繁杂的业务逻辑, 这个方式虽然达到目的,但扩展性和可重用性较差, 因为可能牵一发而动全身。更好的解决方案是采用管道机制,用一条管道把多个对象(阀门部件)连接起来,整体看起来就像若干个阀门嵌套在管道中一样,而处理逻辑放在阀门上。
场景
1. 比如要对符合的IP进行黑白名单过滤,可以在host层加个阀门过滤。
2. 请求日志处理。
3.3.1. Vavle接口设计
理解它的设计,第一步就是阀门设计。Valve 表示一个处理点,比如权限认证和记录日志。
public interface Valve {public Valve getNext();public void setNext(Valve valve);public void invoke(Request request, Response response) throws IOException, ServletException;
} 阀门的创建
阀门可以在Tomcat项目根目录->config->server.xml->对应容器标签下->自定义标签,也就是当前容器的一个阀门,对应到一个阀门类。请求进来后它会执行这个类实例的invoke方法。
例如
给Host容器加阀门。
1. 添加阀门标签。
<Host name="localhost" appBase="webapps"unpackWARs="true" autoDeploy="true"><Valve className="com.liu.TestValue"/></Host> 2. 创建阀门类:在Tomcat源码根目录->java目录->自定义包名,创建阀门类需要继承org.apache.catalina.valves.RequestFilterValve。
package com.liu;import org.apache.catalina.connector.Request;
import org.apache.catalina.connector.Response;
import org.apache.catalina.valves.RequestFilterValve;
import org.apache.juli.logging.Log;import javax.servlet.ServletException;
import java.io.IOException;/*** @author liuYangHong* @version 1.0* @description:* @date 2023/1/8 17:42*/
public class TestValue extends RequestFilterValve {@Overridepublic void invoke(Request request, Response response) throws IOException, ServletException {System.out.println("自己处理些东西");getNext().invoke(request,response);}@Overrideprotected Log getLog() {return null;}
}3.3.2. Pipline接口设计
由于Pipline是为容器设计的,所以它在设计时加入了一个Contained接口, 就是为了制定当前Pipline所属的容器。
public interface Pipeline extends Contained {// 基础的处理阀public Valve getBasic();public void setBasic(Valve valve);// 对节点(阀门)增删查public void addValve(Valve valve);public Valve[] getValves();public void removeValve(Valve valve);// 获取第一个节点,遍历的起点,所以需要有这方法public Valve getFirst();// 是否所有节点(阀门)都支持处理Servlet3异步处理public boolean isAsyncSupported();// 找到所有不支持Servlet3异步处理的阀门public void findNonAsyncValves(Set<String> result);
} Pipeline 中维护了 Valve 链表,Valve 可以插入到 Pipeline 中,对请求做某些处理。整个调用链的触发是 Valve 来完成的,Valve 完成自己的处理后,调用 getNext.invoke() 来触发下一个 Valve 调用。每一个容器都有一个 Pipeline 对象,只要触发这个 Pipeline 的第一个 Valve,这个容器里 Pipeline 中的 Valve 就都会被调用到。Basic Valve 处于 Valve 链表的末端,它是 Pipeline 中必不可少的一个 Valve,负责调用下层容器的 Pipeline 里的第一个 Valve。

整个调用过程由连接器中的 Adapter 触发的,它会调用 Engine 的第一个 Valve:
//org.apache.catalina.connector.CoyoteAdapter#service
// Calling the container
connector.getService().getContainer().getPipeline().getFirst().invoke(request, response); Wrapper 容器的最后一个 Valve 会创建一个 Filter 链,并调用 doFilter() 方法,最终会调到 Servlet 的 service 方法。
//org.apache.catalina.core.StandardWrapperValve#invoke
filterChain.doFilter(request.getRequest(), response.getResponse());3.3.2.1. Valve 和 Filter 的区别:
Valve 是 Tomcat 的私有机制,与 Tomcat 的基础架构 /API 是紧耦合的。Servlet API 是公有的标准,所有的 Web 容器包括 Jetty 都支持 Filter 机制。
Valve 工作在 Web 容器级别,拦截所有应用的请求;而 Servlet Filter 工作在应用级别,只能拦截某个 Web 应用的所有请求。
对比两种责任链模式

Filter递归方法方式取数组的Filter调用(没取完就继续取方式,一个个调用数组后面元素)。
3.4. Tomcat生命周期设计
通过对Tomcat架构的分析,我们知道了Tomcat 都有哪些组件,组件之间是什么样的关系,以及 Tomcat 是怎么处理一个 HTTP 请求的。如果想让Tomcat能够对外提供服务,我们需要创建、组装并启动Tomcat组件;在服务停止的时候,我们还需要释放资源,销毁Tomcat组件,这是一个动态的过程。Tomcat 需要动态地管理这些组件的生命周期。
在我们实际的工作中,如果你需要设计一个比较大的系统或者框架时,你同样也需要考虑这几个问题:如何统一管理组件的创建、初始化、启动、停止和销毁?如何做到代码逻辑清晰?如何方便地添加或者删除组件?如何做到组件启动和停止不遗漏、不重复?
3.4.1. 一键式启停:LifeCycle 接口
系统设计就是要找到系统的变化点和不变点。这里的不变点就是每个组件都要经历创建、初始化、启动这几个过程,这些状态以及状态的转化是不变的。而变化点是每个具体组件的初始化方法,也就是启动方法是不一样的。因此,我们把不变点抽象出来成为一个接口,这个接口跟生命周期有关,叫作 LifeCycle。LifeCycle 接口里应该定义这么几个方法:init()、start()、stop() 和 destroy(),每个具体的组件去实现这些方法。
public interface Lifecycle {/** 第1类:针对监听器,在对应流程状态下触发对应事件 **/// 添加监听器public void addLifecycleListener(LifecycleListener listener);// 获取所有监听器public LifecycleListener[] findLifecycleListeners();// 移除某个监听器public void removeLifecycleListener(LifecycleListener listener);/** 第2类:针对控制流程 **/// 初始化方法public void init() throws LifecycleException;// 启动方法public void start() throws LifecycleException;// 停止方法,和start对应public void stop() throws LifecycleException;// 销毁方法,和init对应public void destroy() throws LifecycleException;/** 第3类:针对状态,比如在启动前,启动后做一些事,这边记录状态**/// 获取生命周期状态public LifecycleState getState();// 获取字符串类型的生命周期状态public String getStateName();
} 在父组件的 init() 方法里需要创建子组件并调用子组件的 init() 方法。同样,在父组件的 start() 方法里也需要调用子组件的 start() 方法,因此调用者可以无差别的调用各组件的 init() 方法和 start() 方法,这就是组合模式的使用,并且只要调用最顶层组件,也就是 Server 组件的 init() 和 start() 方法,整个 Tomcat 就被启动起来了。
3.4.2. 可扩展性:LifeCycle 事件
因为各个组件 init() 和 start() 方法的具体实现是复杂多变的,比如在 Host 容器的启动方法里需要扫描 webapps 目录下的 Web 应用,创建相应的 Context 容器,如果将来需要增加新的逻辑,直接修改 start() 方法?这样会违反开闭原则,那如何解决这个问题呢?开闭原则说的是为了扩展系统的功能,你不能直接修改系统中已有的类,但是你可以定义新的类。
组件的 init() 和 start() 调用是由它的父组件的状态变化触发的,上层组件的初始化会触发子组件的初始化,上层组件的启动会触发子组件的启动,因此我们把组件的生命周期定义成一个个状态,把状态的转变看作是一个事件。而事件是有监听器的,在监听器里可以实现一些逻辑,并且监听器也可以方便的添加和删除,这就是典型的观察者模式(当一个对象的状态发生改变时,其所有依赖者都会收到通知并自动更新。)。
具体来说就是在 LifeCycle 接口里加入两个方法:添加监听器和删除监听器。



3.4.3. 重用性:LifeCycleBase 抽象基类(解决代码共同逻辑地方)
有了接口,我们就要用类去实现接口。一般来说实现类不止一个,不同的类在实现接口时往往会有一些相同的逻辑,如果让各个子类都去实现一遍,就会有重复代码。那子类如何重用这部分逻辑呢?其实就是定义一个基类来实现共同的逻辑,然后让各个子类去继承它,就达到了重用的目的。而基类中往往会定义一些抽象方法,所谓的抽象方法就是说基类不会去实现这些方法,而是调用这些方法来实现骨架逻辑。抽象方法是留给各个子类去实现的,并且子类必须实现,否则无法实例化。
Tomcat 定义一个基类 LifeCycleBase 来实现 LifeCycle 接口,把一些公共的逻辑放到基类中去,比如生命状态的转变与维护、生命周期事件的触发以及监听器的添加和删除等,而子类就负责实现自己的初始化、启动和停止等方法。为了避免跟基类中的方法同名,我们把具体子类的实现方法改个名字,在后面加上 Internal,叫 initInternal()、startInternal() 等。

LifeCycleBase 实现了 LifeCycle 接口中所有的方法,还定义了相应的抽象方法交给具体子类去实现,这是典型的模板设计模式(骨架抽象类和模板方法)。
LifeCycleBase 的 init() 方法实现:

思考:是什么时候、谁把监听器注册进来的呢?
Tomcat 自定义了一些监听器,这些监听器是父组件在创建子组件的过程中注册到子组件的。比如 MemoryLeakTrackingListener监听器,用来检测 Context 容器中的内存泄漏,这个监听器是 Host 容器在创建 Context 容器时注册到 Context 中的。
监听器的添加,可以在 server.xml 的Server标签下,定义自己的监听器,监听器可以监听对应状态执行逻辑。Tomcat 在启动时会解析 server.xml,创建监听器并注册到容器组件。

3.4.4. 生命周期总体类图

StandardServer、StandardService 是 Server 和 Service 组件的具体实现类,它们都继承了 LifeCycleBase。
StandardEngine、StandardHost、StandardContext 和 StandardWrapper 是相应容器组件的具体实现类,因为它们都是容器,所以继承了 ContainerBase 抽象基类,而 ContainerBase 实现了 Container 接口,也继承了 LifeCycleBase 类,它们的生命周期管理接口和功能接口是分开的,这也符合设计中接口分离的原则。
Tomcat 为了实现一键式启停以及优雅的生命周期管理,并考虑到了可扩展性和可重用性,将面向对象思想和设计模式发挥到了极致,分别运用了组合模式、观察者模式、骨架抽象类和模板方法。
如果你需要维护一堆具有父子关系的实体,可以考虑使用组合模式。
观察者模式听起来“高大上”,其实就是当一个事件发生后,需要执行一连串更新操作。传统的实现方式是在事件响应代码里直接加更新逻辑,当更新逻辑加多了之后,代码会变得臃肿,并且这种方式是紧耦合的、侵入式的。观察者模式实现了低耦合、非侵入式的通知与更新机制。
模板方法在抽象基类中经常用到,用来实现通用逻辑。
5. 思路总结
Tomcat是Http服务器+Servlet容器,是Web服务器,用于服务端运行Servlet和JSP的技术,也支持很多web应用程序开发技术如JPA,JSF等。
应用部署方式主要分为,war部署,文件夹部署,描述符部署(在server.xml中配置部署)。
描述符部署下可以通过配置host 和Context部署应用,涉及docbase,appbase,path的设置。
还有一种特别就是在$CATALINA_BASE/conf/[enginename]/[hostname]/ 目录创建xml部署。
Tomcat启动流程,通过脚本调用Bootstrap的main方法,解析Server.xml的个节点,使用Digester解析节点组件,容器,监听器等转成对象。初始化组件和容器,启动组件和容器。
Tomcat处理请求流程,请求进来处理 Socket 连接,借助Socket读取字节流,根据协议将字节流与转换成Request对象,最终转成ServletRequest的对象。加载和管理Servlet对象,将ServletRequest的对象做为参数,调用其service的方法。Servlet对象的service方法进行请求逻辑处理。请求逻辑处理完,将Servlet响应数据最终适配转成Tomcat的Response对象,转成响应字节流,将响应字节流写回给浏览器。
Tomcat涉及,两个核心组件连接器(Connector)和容器(Container)来分别做这两件事情。连接器负责对外交流,读取通信内容将网络字节流到ServletRequest/ServletResponse对象之间的转换,容器负责ServletRequest/ServletResponse和Servlet的之间的交互的内部处理。
连接器(Connector)主要处理功能分为,网络通信,应用层协议解析,Tomcat Request/Response 与 ServletRequest/ServletResponse 的转化。
Tomcat 的设计者设计了 3 个组件来实现这 3 个功能,分别是 EndPoint、Processor 和Adapter。
EndPoint负责Socket的网络通信处理Socket连接。
Processor负责处理网络协议,读取网络字节流,流解析成 Tomcat Request 和 Response 对象,并通过 Adapter 将其提交到容器处理。
Adapter适配器负责将Tomcat Request 对象转成ServletRequest对象交给Servlert。
Tomcat连接器ProtocolHandler,包含了EndPoint 和Processor。就是高内聚低耦合的原则,将相关功能整合在一个子模块下,通过接口或者抽象基类的方式分离出不变点,子模块按照模板方法动态实现自己功能,可变点。
Adapter使用了责任链模式,每个容器都有自己的管道,管道当中有自己阀门Value,可以自定义阀门Value在Servlet的容器节点下配置。阀门本质就是类似单向链表,有头尾节点。容器按照父子级的关系,先走一遍管道的阀门,在转交给下级容器管道的第一个阀门。第一个容器Engine阀门由Adapter调用,Wrapper容器走完阀门会调用过滤链,在调用Servlet的service()。
Container容器,顾名思义就是用来装载东西的器具,在 Tomcat 里,容器就是用来装载 Servlet 的。Tomcat的四大容器是Engine Host Context Wrapper 它们是父子容器关系,Wrapper是对 Servlet 的封装,负责 Servlet 实例的创建、执行和销毁。
Tomcat使用了组合模式设计这些容器,就是一个接口定义了模板方法,容器实现这些方法、能操作父子容器。
Tomcat的生命周期,设计使用接口分离原则,一个接口定义生命周期流程,添加监听器的方法和获取流程状态,用个枚举定义生命周期流程里头很多状态,容器实现对应生命周期流程的方法,里头会判断流程状态调用该状态下对应的监听事件。
相关文章:
性能调优 18. Tomcat整体架构及其设计精髓分析
1. Tomcat介绍 1.1. 介绍 这边使用的是Tomcat9来做说明,本章节先对Tomcat架构和设计有个整体认识。后续章节会对Tomcat性能调优做说明。 官方文档介绍 https://tomcat.apache.org/tomcat-9.0-doc/index.html1.2. Tomcat概念 …...

【C++高阶】:特殊类设计和四种类型转换
✨ 人生如梦,朝露夕花,宛若泡影 🌏 📃个人主页:island1314 🔥个人专栏:C学习 ⛺️ 欢迎关注:👍点赞 👂&am…...

kafka基础概念二
1.Kafka中主题和分区的概念 1.主题Topic 主题-topic在kafka中是一个逻辑的概念,kafka通过topic将消息进行分类。不同的topic会被订阅该topic的消费者消费 但是有一个问题,如果说这个topic中的消息非常非常多,多到需要几T来存,因…...

牛客-热身小游戏
题目链接:热身小游戏 第一种写法:线段树 介绍第二种写法:并查集 对于一些已经查询过的点,我们可以往后跳,进行路径压缩,他们的父亲为下一个点。 a数组记录[ l , r ] 之间的乘积,初始值为1。…...

Python 深度学习调试问题
Python–深度学习解决的常见问题 1.在自己写测试样例的时候,有时候可能将要传入的是input_size,不小心传入为input_dim,这个时候会导致出现问题,自定义的卷积模块或者池化等模块会提示类型问题。 解决的策略是: 1.进行assert i…...

linux恶意请求
nginx访问日志: 162.243.135.29 - - [05/Jan/2024:00:12:07 0800] "GET /autodiscover/autodiscover.json?zdi/Powershell HTTP/1.1" 404 153 "-" "Mozilla/5.0 zgrab/0.x"107.151.182.54 - - [04/Mar/2024:11:30:06 0800] "G…...

Java 反射笔记总结(油管)
Java系列文章目录 IDEA使用指南 Java泛型总结(快速上手详解) Java Lambda表达式总结(快速上手详解) Java Optional容器总结(快速上手图解) Java 自定义注解笔记总结(油管) Jav…...

HTML表格、表单、标签、CSS、选择器
目录 一、HTML表格 二、表单 三、布局标签 四、CSS 五、选择器 一、HTML表格 table:表格 tr:行 td:单元格;rowspan:纵向合并相邻单元格;clospan:横向合并相邻单元格 th:单元格加粗居中 border&…...

【javaWeb技术】·外卖点餐小程序(脚手架学习1·数据库)
🌈 个人主页:十二月的猫-CSDN博客 🔥 系列专栏: 🏀系统学javaWeb开发_十二月的猫的博客-CSDN博客 💪🏻 十二月的寒冬阻挡不了春天的脚步,十二点的黑夜遮蔽不住黎明的曙光 【免费】项…...

LVS 实现四层负载均衡项目实战--DR模式
一、环境准备 主机名IP地址router eth0:172.25.254.100 eth1:192.168.0.100 clienteth0:172.25.254.200lvseth1:192.168.0.50web1web2 1、client配置 [rootclient ~]# cat /etc/NetworkManager/system-connections/eth0.nmconne…...

Python与Qt的对应版本
Python与Qt的对应版本并没有严格的一一对应关系,但通常在使用Python与Qt进行开发时,会选择一个兼容性较好的版本组合。Qt的Python绑定库主要是PyQt和PySide,以下是几个常见的搭配: 1. **PyQt5**: - Python 3.5及以上版…...
WPF篇(12)-Image图像控件+GroupBox标题容器控件
Image图像控件 Image也算是独门独户的控件,因为它是直接继承于FrameworkElement基类。 Image控件就是图像显示控件。Image类能够加载显示的图片格式有.bmp、.gif、.ico、.jpg、.png、.wdp 和 .tiff。要注意的是,加载.gif动画图片时,仅显示第…...

LeetCode 热题 HOT 100 (024/100)【宇宙最简单版】
【哈希表】No. 0128 最长连续序列【中等】👉力扣对应题目指路 希望对你有帮助呀!!💜💜 如有更好理解的思路,欢迎大家留言补充 ~ 一起加油叭 💦 欢迎关注、订阅专栏 【力扣详解】谢谢你的支持&am…...

如何在AWS上进行 环境迁移
在 AWS 上进行环境迁移通常包括以下几个步骤和最佳实践: 1. 评估和规划 评估当前环境:审查现有的应用程序、数据库、网络架构和依赖关系。确定迁移目标:明确迁移的目标(如成本节约、性能提升、可扩展性等)。选择迁移策略:根据应用程序的类型和复杂性,选择合适的迁移策略…...

云服务器和物理服务器的优缺点对比
云服务器优点在于灵活性强、成本效益高、易于扩展且支持全球化部署;缺点则包括安全性与可控性相对较弱,性能可能受限,以及存在服务中断风险。物理服务器则以其高性能、高稳定性、强安全性和完全可控性著称,但成本较高、扩展性受限…...

postgreSQL16添加审计功能
下载审计插件 https://github.com/pgaudit/pgaudit/releases他的分支版本支持不同的PGSQL按需下载 编译安装审计插件 tar -xvf pgaudit-16.0.tar.gzmake install USE_PGXS1 PG_CONFIG/app/postgresql/bin/pg_config启用postgreSQL审计功能 修改配置文件# 启用 pgAudit shar…...
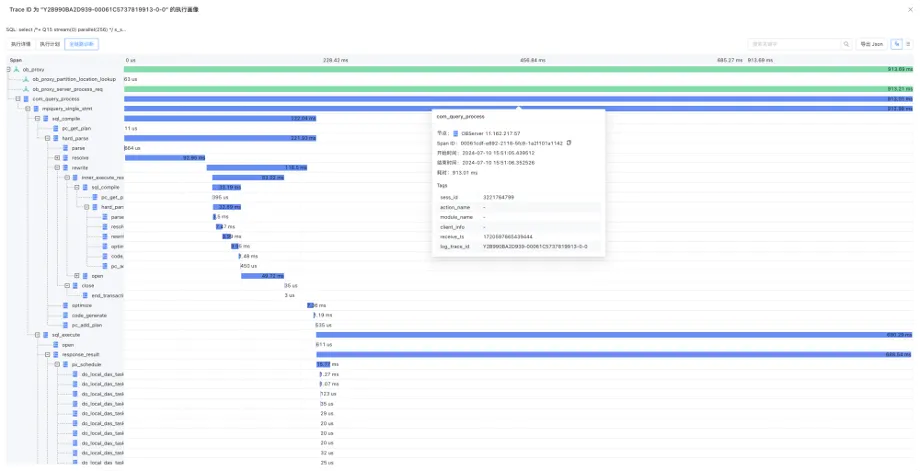
如何应用OceanBase 的实时SQL诊断,解决AP场景下的痛点
随着数据量的快速增长与用户需求的变化,数据库的管理与优化工作日益凸显其重要性。作为DBA及开发者,您是否曾面临以下挑战: ○ 分析场景下,在处理大规模数据的且耗时较长的查询是,常涉及海量数据的处理及复杂的计算&…...

【数据结构】—— 栈
一、栈的基本概念1、栈的定义2、栈的常见基本操作 二、栈的顺序存储1、栈的顺序存储结构2、顺序栈存储实现(1)初始化(2)判空(3)进栈(4)出栈(5)取栈顶元素&…...

Kafka服务端日志详解
文章目录 服务端日志Topic消息存储方式主体介绍log文件追加记录消息index和timeindex索引文件 日志文件清理Kafka的文件高效读写机制Kafka的文件结构顺序写磁盘零拷贝 合理配置刷盘频率客户端消费进度管理 服务端日志 Kafka的日志信息是通过conf/server.properties文件中的log…...

C++ 数据语义学——进程内存空间布局
进程内存空间布局 1. 栈(堆栈/栈区)2. 堆(堆区)3. BSS段4. 数据段5. 代码段进程内存空间布局示意图可执行文件的内存布局示例代码 当把一个可执行文件加载到内存后,就变成了一个进程。这个虚拟空间(内存&am…...

AI赋能5G核心网故障诊断:从PCAP解析到智能根因分析的工程实践
1. 项目概述:当AI遇见5G核心网故障诊断在5G核心网的运维与测试一线干了这么多年,最头疼的莫过于面对海量的PCAP抓包文件。一个复杂的信令流程下来,动辄几千甚至上万个数据包,工程师需要像侦探一样,逐帧审视协议交互&am…...
)
告别外部中断!用EnableInterrupt库轻松搞定Arduino Nano多通道PWM读取(附完整代码)
Arduino Nano多通道PWM读取实战:用EnableInterrupt突破硬件限制当你用Arduino Nano开发四轴飞行器或机器人项目时,是否遇到过这样的尴尬:遥控器的四个通道PWM信号需要同时读取,但Nano只有两个外部中断引脚?这个问题困扰…...

亚马逊 Rufus 关停,Alexa 正式上线:卖家必须读懂的6条新规则
2026年5月13日,亚马逊官方正式宣布,下线Rufus,推出全新AI购物助手:Alexa for Shopping。但是,这不是粗暴地直接下线 Rufus,而是一次购物AI底层架构的重组 —— 将 Rufus 的商品专长 与 Alexa的用户理解力&a…...

终极艾尔登法环帧率解锁指南:轻松突破60FPS限制
终极艾尔登法环帧率解锁指南:轻松突破60FPS限制 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mirrors/el/EldenRing…...

光效崩坏?噪点泛滥?色温漂移?——Midjourney专业级光效渲染全流程校准协议,含ACEScg色彩空间适配模板
更多请点击: https://kaifayun.com 第一章:光效崩坏、噪点泛滥与色温漂移的系统性归因诊断 图像采集链路中出现的光效崩坏、噪点泛滥与色温漂移并非孤立现象,而是光学设计、传感器响应、ISP管线调度及环境耦合失配共同作用的结果。三者常呈现…...

WPF虚拟桌宠组件:可嵌入、高性能、工程化UI生命体
1. 这不是“桌面宠物”,而是一个可嵌入的WPF UI组件化生命体你可能在Windows XP时代见过那只晃着尾巴、偶尔打哈欠的3D小猫,也可能在Win10系统托盘里点开过一个会眨眼的像素狐狸——但那些是独立进程、是系统级小工具、是“看一眼就关掉”的轻量娱乐。而…...

告别浪费!SolidWorks企业级共享方案,实现降本增效全攻略
还在为 SolidWorks 高昂的硬件投入和混乱的图纸管理头疼?告别“一人一机”的浪费模式,企业级共享方案才是降本增效的正解。这套攻略基于“1 台高性能服务器 云飞云共享云桌面”架构,帮你把硬件成本砍掉 60%,把软件利用率翻倍。一…...
)
Unity事件系统实战:用事件驱动重构你的金币拾取逻辑(告别硬编码)
Unity事件系统实战:用事件驱动重构你的金币拾取逻辑(告别硬编码)在游戏开发中,我们经常会遇到这样的场景:玩家拾取金币后,需要更新UI、播放音效、解锁成就、保存数据……如果把这些逻辑全部写在金币拾取的代…...

从安装到排错:手把手解决Linux服务器上Nacos启动失败的十大常见问题
从安装到排错:手把手解决Linux服务器上Nacos启动失败的十大常见问题当你在Linux服务器上部署Nacos时,是否遇到过启动失败却无从下手的困境?作为阿里巴巴开源的服务发现和配置管理平台,Nacos在微服务架构中扮演着重要角色。然而&am…...
 讲清楚,并结合 金融场景(含自进化智能体) 给出可直接用的案例)
招行+工行:ReAct(Reasoning + Acting) 讲清楚,并结合 金融场景(含自进化智能体) 给出可直接用的案例
下面我把 ReAct(Reasoning Acting) 讲清楚,并结合 ** 金融场景(含自进化智能体)** 给出可直接用的案例与话术,适合分享 / 汇报。一、ReAct 是什么(一句话)ReAct 推理(T…...