【NLP】文本张量表示方法【word2vec、词嵌入】
文章目录
- 1、文本张量表示
- 2、one-hot词向量表示
- 2.1、one-hot编码代码实现:
- 2.2、onehot编码器的使用
- 2.3、one-hot编码的优劣势
- 3、word2vec模型
- 3.1、模型介绍
- 3.2、CBOW模式
- 3.3、skipgram模式
- 3.4、word2vec的训练和使用
- 3.4.1、获取训练数据
- 3.4.2、训练词向量
- 3.4.3、查看单词对应的词向量
- 3.4.4、模型超参数设定
- 3.4.5、模型效果检验
- 3.4.6、模型的保存与重加载
- 4、词嵌入word embedding介绍
- 5、数学公式
- 5.1、CBOW 模式
- 输入和目标
- 步骤解释
- 5.2、Skip-gram 模式
- 输入和目标
- 步骤解释
- 5.3、小节
- 6、本章总结
🍃作者介绍:双非本科大三网络工程专业在读,阿里云专家博主,专注于Java领域学习,擅长web应用开发、数据结构和算法,初步涉猎人工智能和前端开发。
🦅个人主页:@逐梦苍穹
📕所属专栏:人工智能
🌻gitee地址:xzl的人工智能代码仓库
✈ 您的一键三连,是我创作的最大动力🌹
1、文本张量表示
本章目标:
- 了解什么是文本张量表示及其作用
- 掌握文本张量表示的几种方法及其实现
将一段文本使用张量进行表示,其中一般将词汇为表示成向量,称作词向量,再由各个词向量按顺序组成矩阵形成文本表示。
举个例子:
["人生", "该", "如何", "起头"]
==>
# 每个词对应矩阵中的一个向量
[[1.32, 4,32, 0,32, 5.2],[3.1, 5.43, 0.34, 3.2],[3.21, 5.32, 2, 4.32],[2.54, 7.32, 5.12, 9.54]]
文本张量表示的作用:
将文本表示成张量(矩阵)形式,能够使语言文本可以作为计算机处理程序的输入,进行接下来一系列的解析工作。
文本张量表示的方法:
one-hot编码
Word2vec
Word Embedding
2、one-hot词向量表示
又称独热编码,将每个词表示成具有n个元素的向量,这个词向量中只有一个元素是1,其他元素都是0;
不同词汇元素为0的位置不同,其中n的大小是整个语料中不同词汇的总数
举个例子:
["改变", "要", "如何", "起手"]`
==>
[[1, 0, 0, 0],[0, 1, 0, 0],[0, 0, 1, 0],[0, 0, 0, 1]]
2.1、one-hot编码代码实现:
# -*- coding: utf-8 -*-
# @Author: CSDN@逐梦苍穹
# @Time: 2024/8/10 0:41
# 导入用于对象保存与加载的joblib库
import joblib
# 从keras的文本预处理模块中导入Tokenizer类,主要用于将文本转化为词汇索引或进行one-hot编码等处理
from keras.preprocessing.text import Tokenizer# TODO 假定vocab为语料集中所有不同的词汇集合
vocab = {"周杰伦", "陈奕迅", "王力宏", "李荣浩", "林俊杰", "薛之谦"}# 实例化一个Tokenizer对象,用于将文本数据转化为词汇索引
# num_words=None表示不限制词汇数量,char_level=False表示按词而不是按字符进行处理
tokenizer = Tokenizer(num_words=None, char_level=False)# 使用Tokenizer对象根据vocab集合拟合文本数据,这一步将为每个词汇生成一个唯一的索引
tokenizer.fit_on_texts(vocab)# 遍历vocab中的每一个词汇
for token in vocab:# 创建一个长度为vocab中词汇数量的全0列表,作为one-hot编码的基础zero_list = [0] * len(vocab)# 使用Tokenizer对象将当前词汇转化为索引# texts_to_sequences将返回一个嵌套列表,例如[[2]],我们需要通过[0][0]来取出索引值# 因为索引从1开始,而列表索引从0开始,所以我们减去1token_index = tokenizer.texts_to_sequences([token])[0][0] - 1# 将对应索引位置的值设为1,以表示该词汇在one-hot编码中的位置zero_list[token_index] = 1# 打印当前词汇及其one-hot编码print(token, "的one-hot编码为:", zero_list)# 使用joblib工具将Tokenizer对象保存到指定路径,以便以后加载和使用
tokenizer_path = "./Tokenizer"
joblib.dump(tokenizer, tokenizer_path)
输出效果:
E:\anaconda3\python.exe D:\Python\AI\自然语言处理\2-onehot编码\1-onehot编码.py
2024-08-10 00:44:16.369535: I tensorflow/core/util/port.cc:153] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable `TF_ENABLE_ONEDNN_OPTS=0`.
2024-08-10 00:44:17.451160: I tensorflow/core/util/port.cc:153] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable `TF_ENABLE_ONEDNN_OPTS=0`.
周杰伦 的one-hot编码为: [1, 0, 0, 0, 0, 0]
王力宏 的one-hot编码为: [0, 1, 0, 0, 0, 0]
林俊杰 的one-hot编码为: [0, 0, 1, 0, 0, 0]
李荣浩 的one-hot编码为: [0, 0, 0, 1, 0, 0]
薛之谦 的one-hot编码为: [0, 0, 0, 0, 1, 0]
陈奕迅 的one-hot编码为: [0, 0, 0, 0, 0, 1]Process finished with exit code 0
2.2、onehot编码器的使用
# -*- coding: utf-8 -*-
# @Author: CSDN@逐梦苍穹
# @Time: 2024/8/10 0:46
# 导入用于对象保存与加载的joblib库
# 如果使用scikit-learn的旧版本,可以使用from sklearn.externals import joblib
# 但在较新版本中,直接使用import joblib
import joblibtokenizer_path = r"Tokenizer"
# 加载之前保存的Tokenizer对象,将其实例化为t对象
# tokenizer_path为保存的Tokenizer文件路径,使用joblib.load从文件中恢复这个对象
t = joblib.load(tokenizer_path)vocab = {"周杰伦", "陈奕迅", "王力宏", "李荣浩", "林俊杰", "薛之谦"}# 定义要进行编码的token(词汇)为"薛之谦"
token = "薛之谦"# 使用加载的Tokenizer对象t将token转化为索引
# texts_to_sequences方法将token转换为一个嵌套列表,例如[[3]],我们需要使用[0][0]来提取索引
# 因为Tokenizer中的索引从1开始,而Python列表索引从0开始,所以减去1以调整为从0开始的索引
token_index = t.texts_to_sequences([token])[0][0] - 1# 初始化一个长度为vocab词汇数量的全0列表,作为one-hot编码的基础
zero_list = [0] * len(vocab)# 将zero_list列表中对应于token索引的位置设为1,表示该词汇的one-hot编码
zero_list[token_index] = 1# 打印出token及其对应的one-hot编码
print(token, "的one-hot编码为:", zero_list)
输出效果:
E:\anaconda3\python.exe D:\Python\AI\自然语言处理\2-onehot编码\2-onehot编码器的使用.py
2024-08-10 00:51:06.065640: I tensorflow/core/util/port.cc:153] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable `TF_ENABLE_ONEDNN_OPTS=0`.
2024-08-10 00:51:07.173912: I tensorflow/core/util/port.cc:153] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable `TF_ENABLE_ONEDNN_OPTS=0`.
薛之谦 的one-hot编码为: [0, 0, 0, 0, 1, 0]Process finished with exit code 0
2.3、one-hot编码的优劣势
- 优势:操作简单,容易理解.
- 劣势:完全割裂了词与词之间的联系,而且在大语料集下,每个向量的长度过大,占据大量内存.
正因为one-hot编码明显的劣势,这种编码方式被应用的地方越来越少,取而代之的是下面的稠密向量的表示方法word2vec和word embedding.
3、word2vec模型
3.1、模型介绍
word2vec是一种流行的将词汇表示成向量的无监督训练方法,该过程将构建神经网络模型,将网络参数作为词汇的向量表示,它包含CBOW和skipgram两种训练模式.
3.2、CBOW模式
CBOW:Continuous bag of words
给定一段用于训练的文本语料,再选定某段长度(窗口)作为研究对象,使用上下文词汇预测目标词汇

图中窗口大小为9,使用前后4个词汇对目标词汇进行预测
CBOW模式下的word2vec过程说明:
- 假设我们给定的训练语料只有一句话:Hope can set you free (愿你自由成长),窗口大小为3,
- 因此模型的第一个训练样本来自Hope can set
- 因为是CBOW模式,所以将使用Hope和set作为输入,can作为输出,
- 在模型训练时, Hope,can,set等词汇都使用它们的one-hot编码
如图所示:每个one-hot编码的单词与各自的变换矩阵(即参数矩阵3x5,这里的3是指最后得到的词向量维度)相乘之后再相加, 得到上下文表示矩阵(3x1)
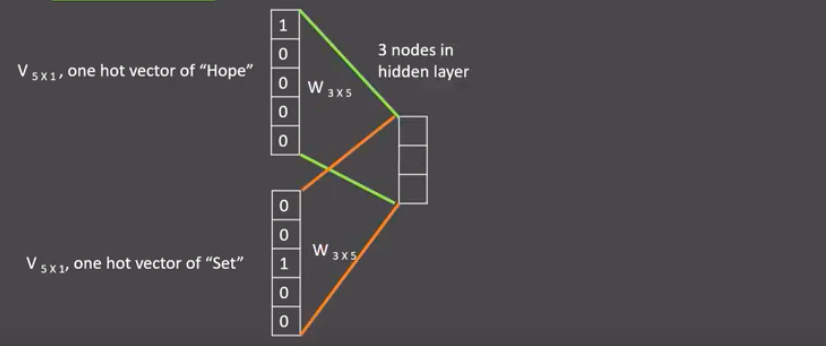
- 接着, 将上下文表示矩阵与变换矩阵(参数矩阵5x3, 所有的变换矩阵共享参数)相乘, 得到5x1的结果矩阵, 它将与我们真正的目标矩阵即can的one-hot编码矩阵(5x1)进行损失的计算, 然后更新网络参数完成一次模型迭代

- 最后窗口按序向后移动,重新更新参数,直到所有语料被遍历完成,得到最终的变换矩阵(3x5),这个变换矩阵与每个词汇的one-hot编码(5x1)相乘,得到的3x1的矩阵就是该词汇的word2vec张量表示.
3.3、skipgram模式
给定一段用于训练的文本语料,再选定某段长度(窗口)作为研究对象,使用目标词汇预测上下文词汇

图中窗口大小为9,使用目标词汇对前后四个词汇进行预测
skipgram模式下的word2vec过程说明:
- 假设我们给定的训练语料只有一句话:Hope can set you free (愿你自由成长),窗口大小为3,因此模型的第一个训练样本来自Hope can set
- 因为是skipgram模式,所以将使用can作为输入 ,Hope和set作为输出,
- 在模型训练时, Hope、can、set等词汇都使用它们的one-hot编码
- 如图所示:将can的one-hot编码与变换矩阵(即参数矩阵3x5, 这里的3是指最后得到的词向量维度)相乘, 得到目标词汇表示矩阵(3x1);接着, 将目标词汇表示矩阵与多个变换矩阵(参数矩阵5x3)相乘, 得到多个5x1的结果矩阵, 它将与我们Hope和set对应的one-hot编码矩阵(5x1)进行损失的计算, 然后更新网络参数完成一次模 型迭代
- 最后窗口按序向后移动,重新更新参数,直到所有语料被遍历完成,得到最终的变换矩阵即参数矩阵(3x5),这个变换矩阵与每个词汇的one-hot编码(5x1)相乘,得到的3x1的矩阵就是该词汇的word2vec张量表示

3.4、word2vec的训练和使用
步骤如下:
第一步:获取训练数据
第二步:训练词向量
第三步:模型超参数设定
第四步:模型效果检验
第五步:模型的保存与重加载
3.4.1、获取训练数据
数据来源:http://mattmahoney.net/dc/enwik9.zip
在这里, 我们将研究英语维基百科的部分网页信息,它的大小在300M左右/
这些语料已经被准备好, 我们可以通过Matt Mahoney的网站下载。

原始数据将输出很多包含XML/HTML格式的内容,这些内容并不是我们需要的

使用head -31 enwik9查看:

原始数据处理——使用wikifil.pl文件处理脚本来清除XML/HTML格式的内容:
perl wikifil.pl enwik9 > enwik9_dispose

wikifil.pl的内容如下:

wikifil.pl文件:
#!/usr/bin/perl# Program to filter Wikipedia XML dumps to "clean" text consisting only of lowercase
# letters (a-z, converted from A-Z), and spaces (never consecutive).
# All other characters are converted to spaces. Only text which normally appears
# in the web browser is displayed. Tables are removed. Image captions are
# preserved. Links are converted to normal text. Digits are spelled out.# Written by Matt Mahoney, June 10, 2006. This program is released to the public domain.$/=">"; # input record separator
while (<>) {if (/<text /) {$text=1;} # remove all but between <text> ... </text>if (/#redirect/i) {$text=0;} # remove #REDIRECTif ($text) {# Remove any text not normally visibleif (/<\/text>/) {$text=0;}s/<.*>//; # remove xml tagss/&/&/g; # decode URL encoded charss/</</g;s/>/>/g;s/<ref[^<]*<\/ref>//g; # remove references <ref...> ... </ref>s/<[^>]*>//g; # remove xhtml tagss/\[http:[^] ]*/[/g; # remove normal url, preserve visible texts/\|thumb//ig; # remove images links, preserve captions/\|left//ig;s/\|right//ig;s/\|\d+px//ig;s/\[\[image:[^\[\]]*\|//ig;s/\[\[category:([^|\]]*)[^]]*\]\]/[[$1]]/ig; # show categories without markups/\[\[[a-z\-]*:[^\]]*\]\]//g; # remove links to other languagess/\[\[[^\|\]]*\|/[[/g; # remove wiki url, preserve visible texts/\{\{[^\}]*\}\}//g; # remove {{icons}} and {tables}s/\{[^\}]*\}//g;s/\[//g; # remove [ and ]s/\]//g;s/&[^;]*;/ /g; # remove URL encoded chars# convert to lowercase letters and spaces, spell digits$_=" $_ ";tr/A-Z/a-z/;s/0/ zero /g;s/1/ one /g;s/2/ two /g;s/3/ three /g;s/4/ four /g;s/5/ five /g;s/6/ six /g;s/7/ seven /g;s/8/ eight /g;s/9/ nine /g;tr/a-z/ /cs;chop;print $_;}
}
查看预处理后的数据:
查看前80个字符:head -c 80 enwik9_dispose

输出结果为由空格分割的单词
3.4.2、训练词向量

代码:
# -*- coding: utf-8 -*-
# @Author: CSDN@逐梦苍穹
# @Time: 2024/8/10 19:00
import fasttext# 使用fasttext的train_unsupervised(无监督训练方法)进行词向量的训练
def train(data_path, model_path):model = fasttext.train_unsupervised(data_path)model.save_model(model_path)# 有效训练词汇量为124M, 共218316个单词# Read 124M words# Number of words: 218316# Number of labels: 0# Progress: 100.0% words/sec/thread: 53996 lr: 0.000000 loss: 0.734999 ETA: 0h 0mif __name__ == '__main__':data_path = r"data/enwik9_dispose"model_path = r"data/enwik9_dispose.bin"train(data_path, model_path)
输出:
3.4.3、查看单词对应的词向量

输出:
E:\anaconda3\python.exe D:\Python\AI\自然语言处理\3-word2vec模型\1-训练词向量.py
[ 0.3236698 0.15532747 0.07212797 0.14861616 0.08830975 -0.09903079-0.21126537 -0.13538036 -0.05028402 -0.39098987 0.24709384 0.00532825-0.08847354 -0.10930646 0.1367174 -0.04121845 -0.00373753 0.24774668-0.08185875 -0.27455944 0.101092 -0.39713272 0.20641634 -0.3742763-0.29339704 0.10094105 0.22513224 -0.11774707 -0.24269272 0.467444570.29645196 -0.13918303 -0.1818411 -0.33125505 -0.35807863 0.47185534-0.16940233 0.39648807 -0.12481215 0.1663422 0.10196311 0.116137750.23823759 -0.13661717 0.2745812 -0.3213522 0.53022105 -0.1537360.02329425 0.17255007 -0.07889199 -0.14739406 0.16769122 -0.35456875-0.0400268 -0.06117349 -0.15143405 -0.22094537 -0.00261665 -0.147020440.2708343 0.11334934 -0.05286217 0.29824734 -0.0585679 0.247214480.12718058 -0.11213452 0.04822333 0.13984725 -0.07734621 0.198328060.02776946 -0.24167208 -0.06241349 -0.06172606 -0.12841716 -0.15416296-0.07451887 -0.24592046 -0.23765343 0.14552937 0.20293383 0.08167906-0.03572037 0.03773127 0.16349053 -0.08558396 -0.03878127 -0.05893503-0.23126844 0.537188 -0.10704986 -0.00842452 -0.13096736 -0.40923432-0.03984451 -0.22873439 0.19669639 -0.34490398]Process finished with exit code 0
3.4.4、模型超参数设定
在训练词向量过程中,我们可以设定很多常用超参数来调节我们的模型效果
如:
- 无监督训练模式:
skipgram或者cbow,默认为skipgram,在实践中,skipgram模式在利用子词方面比cbow更好 - 词嵌入维度dim:默认为100,但随着语料库的增大,词嵌入的维度往往也要更大
- 数据循环次数epoch:默认为5,但当你的数据集足够大,可能不需要那么多次
- 学习率lr:默认为0.05,根据经验,建议选择 [0.01,1] 范围内
- 使用的线程数thread:默认为12个线程,一般建议和你的cpu核数相同
代码:
# 模型超参数设定
def train2(data_path, model_path_hyperparameter):model = fasttext.train_unsupervised(data_path, "cbow", dim=300, epoch=1, lr=0.01, thread=8)model.save_model(model_path_hyperparameter)
结果:

3.4.5、模型效果检验
检查单词向量质量的一种简单方法就是查看其邻近单词,通过我们主观来判断这些邻近单词是否与目标单词相关来粗略评定模型效果好坏
# -*- coding: utf-8 -*-
# @Author: CSDN@逐梦苍穹
# @Time: 2024/8/11 0:27
import fasttextdef load(model_path):# 可以使用以下代码加载已经训练好的模型print("start the model effect test")print("*" * 120)model = fasttext.load_model(model_path)sports = model.get_nearest_neighbors('sports')music = model.get_nearest_neighbors('music')dog = model.get_nearest_neighbors('dog')affection = model.get_nearest_neighbors('affection')print("sports series: ", sports)print("-" * 120)print("music series: ", music)print("-" * 120)print("dog series: ", dog)print("-" * 120)print("affection series: ", affection)if __name__ == '__main__':model_path = r"data/enwik9_dispose.bin"model_path_hyperparameter = r"data/enwik9_dispose_hyperparameter.bin"load(model_path)
输出:
E:\anaconda3\python.exe D:\Python\AI\自然语言处理\3-word2vec模型\2-模型效果检验.py
start the model effect test
************************************************************************************************************************
sports series: [(0.8618593811988831, 'sport'), (0.8410608768463135, 'sportsground'), (0.836230456829071, 'sportsnet'), (0.8285531997680664, 'sportscars'), (0.8258230090141296, 'sporting'), (0.817905068397522, 'sportscar'), (0.7884496450424194, 'sportswomen'), (0.7868256568908691, 'sportsplex'), (0.7829296588897705, 'athletics'), (0.7825238108634949, 'sportsman')]
------------------------------------------------------------------------------------------------------------------------
music series: [(0.8817312717437744, 'musics'), (0.8547526597976685, 'musical'), (0.8259414434432983, 'musices'), (0.8251302242279053, 'musicman'), (0.8039880990982056, 'musico'), (0.777938723564148, 'folksongs'), (0.7773587703704834, 'folk'), (0.7762141823768616, 'orchestral'), (0.7751703858375549, 'emusic'), (0.7751681804656982, 'musicam')]
------------------------------------------------------------------------------------------------------------------------
dog series: [(0.8613849878311157, 'dogs'), (0.8245790600776672, 'sheepdogs'), (0.8098610639572144, 'sheepdog'), (0.7857441306114197, 'coonhounds'), (0.7672119736671448, 'coonhound'), (0.7589083313941956, 'hound'), (0.7564846873283386, 'breed'), (0.7492610216140747, 'puppy'), (0.7469111084938049, 'hounds'), (0.745738685131073, 'elkhound')]
------------------------------------------------------------------------------------------------------------------------
affection series: [(0.9352437257766724, 'affections'), (0.8597129583358765, 'affectional'), (0.838163435459137, 'affectionate'), (0.8194665312767029, 'youthfulness'), (0.8134668469429016, 'feeling'), (0.8038593530654907, 'aloofness'), (0.802234411239624, 'mildness'), (0.8008064031600952, 'affectation'), (0.8002446293830872, 'affectionally'), (0.7990461587905884, 'bashfulness')]Process finished with exit code 0
可以看到预测的结果表现还不错:

使用刚刚优化过的超参数设定,效果更佳:

3.4.6、模型的保存与重加载
使用save_model保存模型:model.save_model(path)
使用fasttext.load_model加载模型:model = fasttext.load_model(path)
4、词嵌入word embedding介绍
这部分的代码在Linux系统运行
- 通过一定的方式将词汇映射到指定维度(一般是更高维度)的空间
- 广义的word embedding包括所有密集词汇向量的表示方法,如之前学习的word2vec,即可认为是word embedding的一种
- 狭义的word embedding是指在神经网络中加入的embedding层,对整个网络进行训练的同时产生的embedding矩阵(embedding层的参数),这个embedding矩阵就是训练过程中所有输入词汇的向量表示组成的矩阵
- word embedding的可视化分析
- 通过使用tensorboard可视化嵌入的词向量
import tensorflow as tf
import torch
import fileinput
from torch.utils.tensorboard import SummaryWriter# 使用 TensorFlow 的 gfile
gfile = tf.io.gfile
# 导入torch和tensorboard的摘要写入方法
# 实例化一个摘要写入对象
writer = SummaryWriter()
# 随机初始化一个100x50的矩阵, 认为它是我们已经得到的词嵌入矩阵
# 代表100个词汇, 每个词汇被表示成50维的向量
embedded = torch.randn(100, 50)
# 导入事先准备好的100个中文词汇文件, 形成meta列表原始词汇
meta = list(map(lambda x: x.strip(), fileinput.FileInput("./vocab100.csv")))
writer.add_embedding(embedded, metadata=meta)
writer.close()在Linux终端启动tensorboard服务:tensorboard --logdir=runs --host 0.0.0.0
通过终端返回的http地址访问浏览器可视化页面
浏览器展示并可以使用右侧近邻词汇功能检验效果:
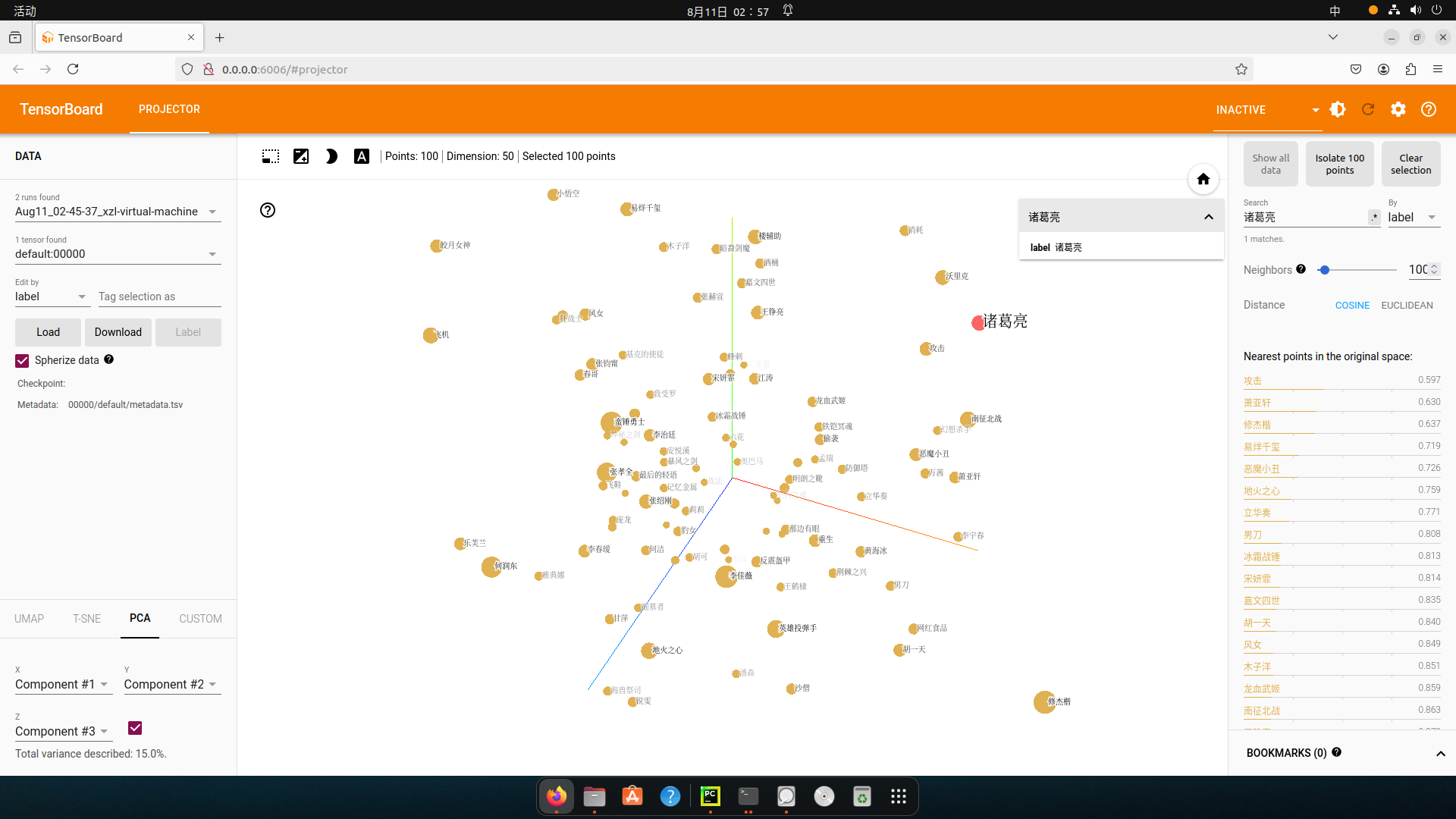
Windows运行代码会报错:

Linux则不会报错:
5、数学公式
5.1、CBOW 模式
CBOW模式的目标是通过给定上下文词预测中心词。它的数学原理如下:
输入和目标
- 输入:上下文词的 one-hot 编码向量。
- 目标:预测的中心词的 one-hot 编码向量。
步骤解释
- 输入层:
- 对于每个上下文词,使用 one-hot 编码表示。假设词汇表大小为 V V V,每个词的 one-hot 向量是 V × 1 V \times 1 V×1 的列向量。
- 隐藏层:
- 每个上下文词的 one-hot 向量与共享的权重矩阵 W W W(尺寸为 N × V N \times V N×V)相乘,将 one-hot 向量转换为隐藏层向量表示。这里 N N N 是词向量的维度。
- 对于每个输入上下文词,隐藏层的输出是: h i = W ⋅ v i h_i = W \cdot v_i hi=W⋅vi
其中 v i v_i vi 是第 i i i 个上下文词的 one-hot 向量, W W W 是共享的权重矩阵。
- 平均隐藏层向量:
- 计算所有上下文词隐藏层向量的平均值 h = 1 C ∑ i = 1 C h i h = \frac{1}{C} \sum_{i=1}^{C} h_i h=C1∑i=1Chi
其中 C C C 是上下文词的数量。
- 计算所有上下文词隐藏层向量的平均值 h = 1 C ∑ i = 1 C h i h = \frac{1}{C} \sum_{i=1}^{C} h_i h=C1∑i=1Chi
- 输出层:
- 隐藏层的平均向量 h h h 通过另一个权重矩阵 W ′ W' W′(尺寸为 V × N V \times N V×N)映射到输出层,即词汇表大小的向量: u = W ′ ⋅ h u = W' \cdot h u=W′⋅h
- 使用 softmax 函数对输出层向量 u u u 进行归一化,得到预测的中心词的概率分布:
p ( w o ∣ w 1 , w 2 , . . . , w C ) = exp ( u o ) ∑ w ∈ V exp ( u w ) p(w_o | w_1, w_2, ..., w_C) = \frac{\exp(u_o)}{\sum_{w \in V} \exp(u_w)} p(wo∣w1,w2,...,wC)=∑w∈Vexp(uw)exp(uo)
其中 u o u_o uo 是目标词的分数。
- 损失函数:
- 采用交叉熵损失函数计算预测的中心词与实际中心词之间的差异;
- 并反向传播调整权重: L = − log p ( w o ∣ w 1 , w 2 , . . . , w C ) L = - \log p(w_o | w_1, w_2, ..., w_C) L=−logp(wo∣w1,w2,...,wC)
- 权重更新:使用梯度下降算法,根据损失函数的梯度更新权重矩阵 W W W 和 W ′ W' W′。
最终,权重矩阵 W W W(或 W ′ W' W′)的列向量即为每个词的词向量。
5.2、Skip-gram 模式
Skip-gram 模式与 CBOW 模式相反,其目标是通过给定中心词预测上下文词。其数学原理如下:
输入和目标
- 输入:中心词的 one-hot 编码向量。
- 目标:预测的上下文词的 one-hot 编码向量。
步骤解释
- 输入层:
- 中心词的 one-hot 向量 v c v_c vc(尺寸为 V × 1 V \times 1 V×1)。
- 隐藏层:
- 中心词的 one-hot 向量与权重矩阵 W W W(尺寸为 N × V N \times V N×V)相乘,
- 将其转换为隐藏层向量表示 h = W ⋅ v c h = W \cdot v_c h=W⋅vc
- 输出层:
- 隐藏层向量 h h h 通过权重矩阵 W ′ W' W′(尺寸为 V × N V \times N V×N)映射到输出层,
- 得到预测的上下文词的概率分布: u w = W w ′ ⋅ h u_w = W'_w \cdot h uw=Ww′⋅h
- 使用 softmax 函数对每个输出层向量 u w u_w uw 进行归一化,得到每个上下文词的概率分布:
p ( w c o n t e x t ∣ w c ) = exp ( u w ) ∑ w ∈ V exp ( u w ) p(w_{context} | w_c) = \frac{\exp(u_w)}{\sum_{w \in V} \exp(u_w)} p(wcontext∣wc)=∑w∈Vexp(uw)exp(uw)
- 损失函数:
- 对于每个上下文词,使用交叉熵损失计算预测概率和实际 one-hot 编码之间的差异:
L = − ∑ w ∈ c o n t e x t log p ( w c o n t e x t ∣ w c ) L = - \sum_{w \in context} \log p(w_{context} | w_c) L=−∑w∈contextlogp(wcontext∣wc)
- 对于每个上下文词,使用交叉熵损失计算预测概率和实际 one-hot 编码之间的差异:
- 权重更新:使用梯度下降算法,根据损失函数的梯度更新权重矩阵 W W W 和 W ′ W' W′。
最终,Skip-gram 模式的权重矩阵 W W W 也能得到每个词的词向量。
5.3、小节
- CBOW 模式通过上下文词预测中心词,适合处理小型语料库,因其需要计算的上下文词较少,训练速度相对较快。
- Skip-gram 模式通过中心词预测上下文词,适合处理大型语料库,因为它更关注单个词对上下文词的影响,因此能更好地捕捉低频词的语义信息。
这两种模式都使用神经网络,通过调整权重矩阵来学习每个词汇的向量表示,即 word2vec
最终,这些向量能够捕捉词汇之间的语义相似性,被广泛应用于各种自然语言处理任务中
6、本章总结
- 学习了什么是文本张量表示:
- 将一段文本使用张量进行表示,其中一般将词汇为表示成向量,称作词向量,再由各个词向量按顺序组成矩阵形成文本表示.
- 学习了文本张量表示的作用:
- 将文本表示成张量(矩阵)形式,能够使语言文本可以作为计算机处理程序的输入,进行接下来一系列的解析工作.
- 学习了文本张量表示的方法:
- one-hot编码
- Word2vec
- Word Embedding
- 什么是one-hot词向量表示:
- 又称独热编码,将每个词表示成具有n个元素的向量,这个词向量中只有一个元素是1,其他元素都是0,不同词汇元素为0的位置不同,其中n的大小是整个语料中不同词汇的总数.
- 学习了onehot编码实现
- 学习了one-hot编码的优劣势:
- 优势:操作简单,容易理解.
- 劣势:完全割裂了词与词之间的联系,而且在大语料集下,每个向量的长度过大,占据大量内存.
- 学习了什么是word2vec:
- 是一种流行的将词汇表示成向量的
无监督训练方法, 该过程将构建神经网络模型, 将网络参数作为词汇的向量表示,它包含CBOW和skipgram两种训练模式.
- 是一种流行的将词汇表示成向量的
- 学习了CBOW(Continuous bag of words)模式:
- 给定一段用于训练的文本语料, 再选定某段长度(窗口)作为研究对象, 使用上下文词汇预测目标词汇.
- 学习了CBOW模式下的word2vec过程说明:
- 假设我们给定的训练语料只有一句话: Hope can set you free (愿你自由成长),窗口大小为3,因此模型的第一个训练样本来自Hope you set,因为是CBOW模式,所以将使用Hope和set作为输入,you作为输出,在模型训练时, Hope,set,you等词汇都使用它们的one-hot编码. 如图所示: 每个one-hot编码的单词与各自的变换矩阵(即参数矩阵3x5, 这里的3是指最后得到的词向量维度)相乘之后再相加, 得到上下文表示矩阵(3x1).
- 接着, 将上下文表示矩阵与变换矩阵(参数矩阵5x3, 所有的变换矩阵共享参数)相乘, 得到5x1的结果矩阵, 它将与我们真正的目标矩阵即you的one-hot编码矩阵(5x1)进行损失的计算, 然后更新网络参数完成一次模型迭代.
- 最后窗口按序向后移动,重新更新参数,直到所有语料被遍历完成,得到最终的变换矩阵(3x5),这个变换矩阵与每个词汇的one-hot编码(5x1)相乘,得到的3x1的矩阵就是该词汇的word2vec张量表示.
- 学习了skipgram模式:
- 给定一段用于训练的文本语料, 再选定某段长度(窗口)作为研究对象, 使用目标词汇预测上下文词汇.
- 学习了skipgram模式下的word2vec过程说明:
- 假设我们给定的训练语料只有一句话: Hope can set you free (愿你自由成长),窗口大小为3,因此模型的第一个训练样本来自Hope you set,因为是skipgram模式,所以将使用you作为输入 ,hope和set作为输出,在模型训练时, Hope,set,you等词汇都使用它们的one-hot编码. 如图所示: 将you的one-hot编码与变换矩阵(即参数矩阵3x5, 这里的3是指最后得到的词向量维度)相乘, 得到目标词汇表示矩阵(3x1).
- 接着, 将目标词汇表示矩阵与多个变换矩阵(参数矩阵5x3)相乘, 得到多个5x1的结果矩阵, 它将与我们hope和set对应的one-hot编码矩阵(5x1)进行损失的计算, 然后更新网络参数完成一次模 型迭代.
- 最后窗口按序向后移动,重新更新参数,直到所有语料被遍历完成,得到最终的变换矩阵即参数矩阵(3x5),这个变换矩阵与每个词汇的one-hot编码(5x1)相乘,得到的3x1的矩阵就是该词汇的word2vec张量表示.
- 学习了使用fasttext工具实现word2vec的训练和使用:
- 第一步:获取训练数据
- 第二步:训练词向量
- 第三步:模型超参数设定
- 第四步:模型效果检验
- 第五步:模型的保存与重加载
- 学习了什么是word embedding(词嵌入):
- 通过一定的方式将词汇映射到指定维度(一般是更高维度)的空间.
- 广义的word embedding包括所有密集词汇向量的表示方法,如之前学习的word2vec, 即可认为是word embedding的一种.
- 狭义的word embedding是指在神经网络中加入的embedding层, 对整个网络进行训练的同时产生的embedding矩阵(embedding层的参数), 这个embedding矩阵就是训练过程中所有输入词汇的向量表示组成的矩阵.
- 学习了word embedding的可视化分析:
- 通过使用tensorboard可视化嵌入的词向量.
- 在终端启动tensorboard服务.
- 浏览器展示并可以使用右侧近邻词汇功能检验效果.
相关文章:
【NLP】文本张量表示方法【word2vec、词嵌入】
文章目录 1、文本张量表示2、one-hot词向量表示2.1、one-hot编码代码实现:2.2、onehot编码器的使用2.3、one-hot编码的优劣势 3、word2vec模型3.1、模型介绍3.2、CBOW模式3.3、skipgram模式3.4、word2vec的训练和使用3.4.1、获取训练数据3.4.2、训练词向量3.4.3、查…...

疯狂Java讲义_08_泛型
文章目录 泛型的传参若函数里的参数使用基类接受所有的派生类,怎么做? 类型通配符的上限类型通配符的下限 泛型的传参 注意 若类 Base 是类 Derived 的基类(父类),那么数组类型 Base[] 是 Derived[] 的基类࿰…...

HCIA、OSPF笔记
一、OSI参考模型 1、OSI的结构 应用层:把人类语言转化成编码,为各种应用程序提供网络服务。 表示层:定义一些数据的格式,(对数据进行加密、解密、编码、解码、压缩、解压缩,每一层都可以实现,…...

Python删除lru_cache缓存
在 Python 中,lru_cache 是一个装饰器,用于添加缓存功能以提高函数的性能。如果你想清除或者删除 lru_cache 中的缓存,有几种方法可以做到: 手动清除缓存: lru_cache 对象有一个方法叫做 cache_clear(),可以手动清除所有缓存。示例:@lru_cache(maxsize=128) def some_fun…...

Android面试必问题:大白文讲透Android View工作原理
目录 第一章 引言 第二章 Android View 基础概念 2.1 视图(View) 2.2 布局(Layout) 2.3 绘制(Drawing) 第三章 Android View 工作原理详解 3.1 测量过程剖析 3.2 布局流程探究 第四章 Android View 性能优化建议 4.1 视图层级优化 4.2 避免过度的视觉效果 4.…...

WinDbg配置远程调试
WinDbg配置远程调试 1、为什么需要远程调试 某些特殊的场合需要远程调试,如: ①调试特殊的程序,比如在调试全屏程序,内核。 ②需要别人帮助调试或者帮助别人调试。比如由于商业性质不能直接给你pdb和源代码。 ③还有一类就是…...

spl注入实战thinkphp
目录 一、环境的部署 二、本地创建数据库 三、填写数据库连接文件 四、编写控制器 五、访问分析 debug报错会显示物理路径 原因是config.php文件相关配置 六、注入分析 七、进入断点调试 八、通过mysql执行语句查看结果 九、总结: 一、环境的部署 二、本地…...
)
整理深度学习时最常用的Linux命令(自用)
清华大学镜像源: https://pypi.tuna.tsinghua.edu.cn/simple/tar文件解压 tar -xzvf xxx.tar.gztar xvf xxx.tarzip文件解压 unzip xxx.zip -d path/to/your/fold清理GPU异常内存占用 杀掉 1 号显卡的所有进程 fuser -v /dev/nvidia1 | xargs -t -n 1 kill -9杀掉…...

LVS——>linux 虚拟服务器知识汇总
一、概念: LVS(Linux Virtual Server),是Linux Virtual Server的简写,也就是Linux 虚拟服务器,是一个虚拟的服务器集群系统负载均衡解决方案,它将一个真实服务器集群虚拟成一台服务器来对外提供…...
AI赋能周界安防:智能视频分析技术构建无懈可击的安全防线
周界安全防范是保护机场、电站、油库、监狱、工业园区等关键设施免受非法入侵和破坏的重要措施。传统的周界安防手段主要依靠人员巡查和物理屏障,但这种方式不仅人力成本高,而且效率较低,难以满足日益复杂多变的安全需求。随着AI技术的引入&a…...

FastAPI+Vue3工程项目管理系统项目实战私教课 上课笔记20240808 课程和学习计划制定
学习目标 将Word和Excel做的东西放到数据库里面去工程类公司,甲方,劳务存到数据库存储的信息主要是人员的信息 基本信息: 人员信息,资料库,甲方的人出现在哪些项目上,考勤材料信息,进货记录&…...

Robot Operating System——发布相对湿度数据
大纲 应用场景定义字段解释 案例 sensor_msgs::msg::RelativeHumidity 是 ROS (Robot Operating System) 中的一个消息类型,用于表示相对湿度数据。 应用场景 环境监测 气象站:在气象站中,相对湿度传感器可以用于监测环境湿度,帮…...

一文搞懂后端面试之不停机数据迁移【中间件 | 数据库 | MySQL | 数据一致性】
数据迁移方面的工作: 重构老系统:使用新的表结构来存储数据单库拆分分库分表、分库分表扩容大表修改表结构定义 数据备份工具 MySQL上常用的两款数据备份工具:mysqldump和XtraBackup mysqldump:一个用于备份和恢复数据库的命令…...

【ESP01开发实例】- ISD1820录音控制
ISD1820录音控制 文章目录 ISD1820录音控制1、ISD1820模块介绍2、硬件准备及接线3、代码以实现录音技术已经取得了长足的进步,它已成为从语音助手到安全系统的各种应用不可或缺的一部分。如果您有兴趣构建自己的录音系统,将 ISD1820 模块与 ESP01 微控制器相结合可能是一个不…...

Linux驱动面试高频考点后面继续改整理
Linux驱动开发是将硬件设备与操作系统内核连接起来的重要环节,它涉及到设备模型、中断处理、文件操作等方面,是一项挑战性且充满乐趣的工作。今天给大家分享45道Linux驱动面试高频考点,直接上干货。 1、驱动程序分为几类? 内核驱动…...

【Python】nn.ConvTranspose1、2、3d()函数详解和示例
前言 在深度学习中,特别是在处理图像、音频和三维数据时,转置卷积(Transposed Convolution)或称为反卷积(Deconvolution)是一种非常重要的操作。PyTorch提供了nn.ConvTranspose1d、nn.ConvTranspose2d和nn…...

vtkConnectivityFilter提取连通区域中的问题
直接使用vtkConnectivityFilter提取连通区域,渲染上没问题,但是打印出polydata中的点数,发现跟原始数据是一致的。 for (int i 0; i < numRegions; i){vtkSmartPointer<vtkConnectivityFilter> connectivityFilter vtkSmartPointe…...
购物系统小程序的设计
管理员账户功能包括:系统首页,个人中心,商品分类管理,商品信息管理,特价商品管理,用户管理,留言板管理,订单管理,系统管理 微信端账号功能包括:系统首页&…...

做报表用什么工具?不想再用Excel了!!!
一、什么是中国式报表? 不知道大家现在还是使用Excel来制作报表,然后跟领导汇报工作吗?虽然Excel功能很强大,但是用Excel做过中国式报表的小伙伴一定知道它的制作过程有多复杂。 中国式报表可以用一句话简单概括:格式…...

c++实现学生管理系统(附源码)
目录 一、基本功能: 二、包含的模块: 三、系统介绍 1. 学生管理系统的功能: 2. 具体的需求: 3. 支持的标准: 四、系统结构功能图: 五、系统设计 1. 退出系统: 2. 增加学生:…...

别再让模型在Unity里‘抽风’了!Blender导出FBX到Unity的7步避坑自查清单
别再让模型在Unity里‘抽风’了!Blender导出FBX到Unity的7步避坑自查清单当你花了三天三夜精心雕琢的Blender模型,导入Unity后却变成了一团旋转错乱、贴图闪烁的"抽象艺术",那种崩溃感每个3D开发者都懂。本文将用实战经验帮你建立一…...

MCP Server生产级配置:Playwright与LLM集成的避坑指南
1. 这不是又一个“Playwright入门教程”,而是一份能直接塞进CI流水线的MCP Server生产级配置实录你有没有遇到过这样的场景:团队刚决定用AI驱动自动化测试,技术选型会上大家一致看好Playwright MCP(Model Context Protocol&#…...

Obsidian PDF++:如何在Obsidian中实现PDF与笔记的无缝双向链接?
Obsidian PDF:如何在Obsidian中实现PDF与笔记的无缝双向链接? 【免费下载链接】obsidian-pdf-plus PDF: the most Obsidian-native PDF annotation & viewing tool ever. Comes with optional Vim keybindings. 项目地址: https://gitcode.com/gh_…...

51单片机驱动ST7735S彩屏避坑指南:从5秒刷屏到流畅贪吃蛇的优化实战
51单片机驱动ST7735S彩屏性能优化实战:从卡顿到流畅游戏的蜕变之路当一块128x160分辨率的ST7735S彩屏遇上传统的51单片机,这种组合看似矛盾却又充满挑战。许多开发者初次尝试时会发现,原本在STM32等平台上运行流畅的显示驱动,移植…...

HFSS仿真结果怎么看?一文读懂S参数与电场图,让你的T型波导分析不再迷茫
HFSS仿真结果深度解析:从S参数到电场图的工程实践指南面对HFSS仿真生成的复杂数据图表,许多工程师常陷入"看得见数据却读不懂含义"的困境。本文将带您穿透数据表象,掌握T型波导性能分析的核心方法论。1. S参数:波导性能…...

服务器日志分析实战:用Python追踪HTTP 404错误并可视化异常频率
作为一名爬虫开发者或网站运维人员,服务器日志就像飞机的“黑匣子”——它记录了每个请求的来龙去脉。而404错误(页面未找到)尤其值得关注:它可能是用户输错了网址,可能是你爬虫的URL构造逻辑有漏洞,也可能是网站改版后旧的链接失效了。更严重的是,大量突然涌出的404请求…...

别再死记硬背Payload了!我用XSS-Game靶场,带你拆解18种过滤规则背后的绕过逻辑
从XSS-Game靶场实战中掌握18种过滤规则的逆向思维在网络安全领域,跨站脚本攻击(XSS)始终是Web应用面临的主要威胁之一。许多开发者虽然了解XSS的基本概念,但当面对各种复杂的过滤规则时,往往不知如何系统分析并构造有效…...

企业内统一API网关与Taotoken聚合平台对接方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业内统一API网关与Taotoken聚合平台对接方案 在推进AI应用落地的过程中,许多中大型企业面临一个共同挑战:…...

Java项目中如何提升整体系统性能?
性能优化可以说是我们程序员的必修课,如果你想要跳出CRUD的苦海,成为一个更“高级”的程序员的话,性能优化这一关你是无论无何都要去面对的。为了提升系统性能,开发人员可以从系统的各个角度和层次对系统进行优化。除了最常见的代…...

模拟电路实现自主循线机器人:无MCU的硬件逻辑设计
1. 项目概述:用最纯粹的模拟电路,造一台会“思考”的机器人每次看到那些在赛道上灵巧穿梭的循线小车,你是不是也手痒,想自己动手做一个?但一听到“单片机”、“编程”、“Arduino”这些词,又觉得门槛太高&a…...