redis内存淘汰策略-------Reservoir Sampling(水库采样)
文章目录
- 过期删除策略和内存淘汰策略
- 内存淘汰策略
- evictionPoolEntry
- evictionPoolPopulate
- Reservoir Sampling
- dictGetRandomKey
- dictGetSomeKeys
- Reservoir Sampling
- chatgpt对Reservoir Sampling的介绍
过期删除策略和内存淘汰策略
详细介绍请参考博客“redis过期删除策略和内存淘汰策略”
内存淘汰策略
为了节省内存,redis并没有采用传统的方法实现LRU和LFU而是基于随机采样的方式,近似实现LRU和LFU,并引入淘汰池进行优化。接下来详细看看是如何淘汰池进行优化的。具体实现在"evict.c"文件中的函数"evictionPoolPopulate"。
/* This is a helper function for performEvictions(), it is used in order* to populate the evictionPool with a few entries every time we want to* expire a key. Keys with idle time bigger than one of the current* keys are added. Keys are always added if there are free entries.** We insert keys on place in ascending order, so keys with the smaller* idle time are on the left, and keys with the higher idle time on the* right. */这个函数是"performEvictions()"的辅助函数。每当想要过期一些key时该函数被用来向淘汰池填充一些数据。当淘汰池未满时,keys总是被添加;反之的话,添加具有更大idle time的keys。淘汰池按照idle time升序排序,即较小idle time的key存储在淘汰池的左边,较大idle time的key存储在淘汰池的右边。
/* When an LFU policy is used instead, a reverse frequency indication is used* instead of the idle time, so that we still evict by larger value (larger* inverse frequency means to evict keys with the least frequent accesses).*/当使用LFU策略时,用反向频率reverse frequency代替idle time。按照reverse frequency升序排序,较大的inverse frequency意味着keys具有较小的lfu值即least frequent accesses。
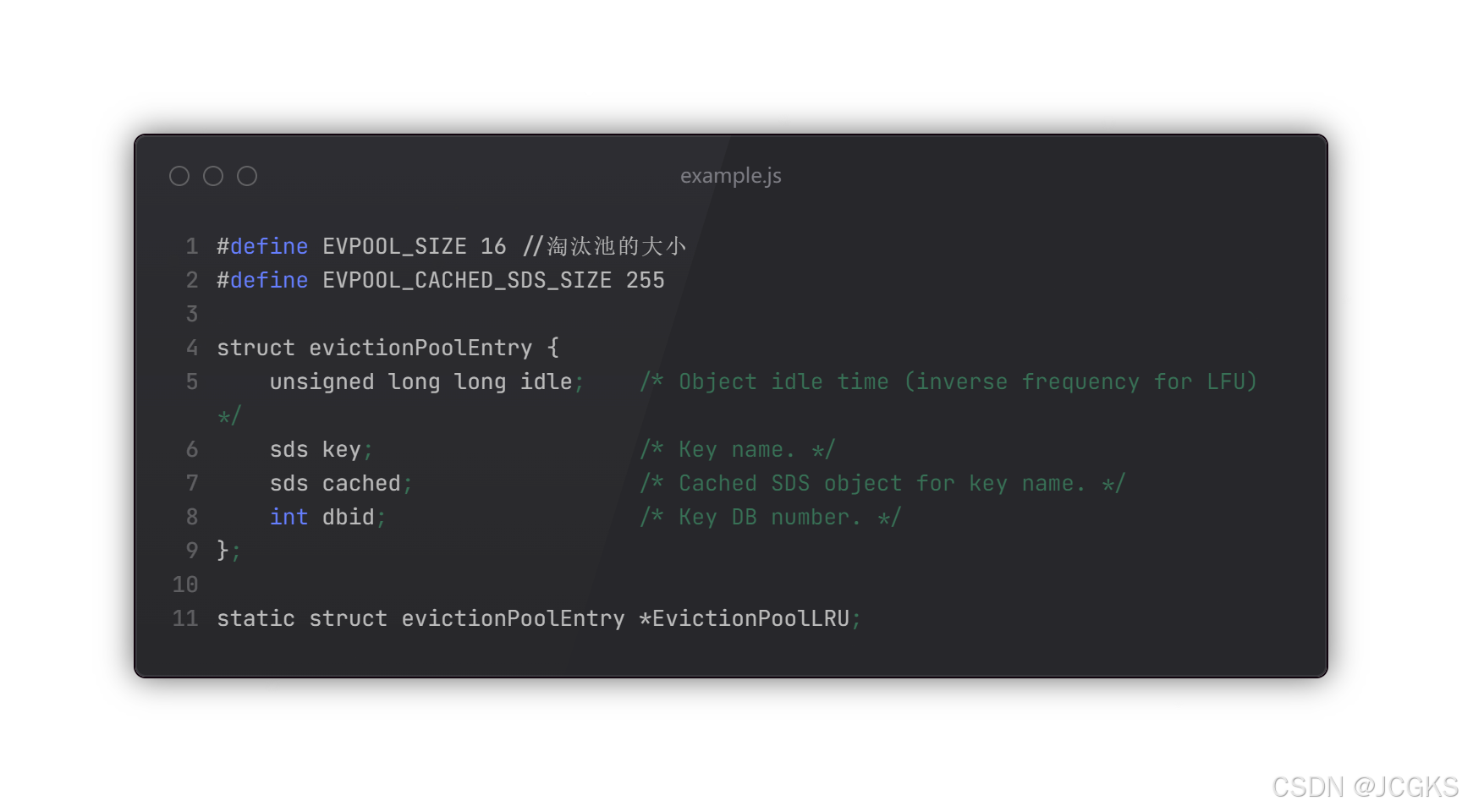
evictionPoolEntry
evictionPoolPopulate
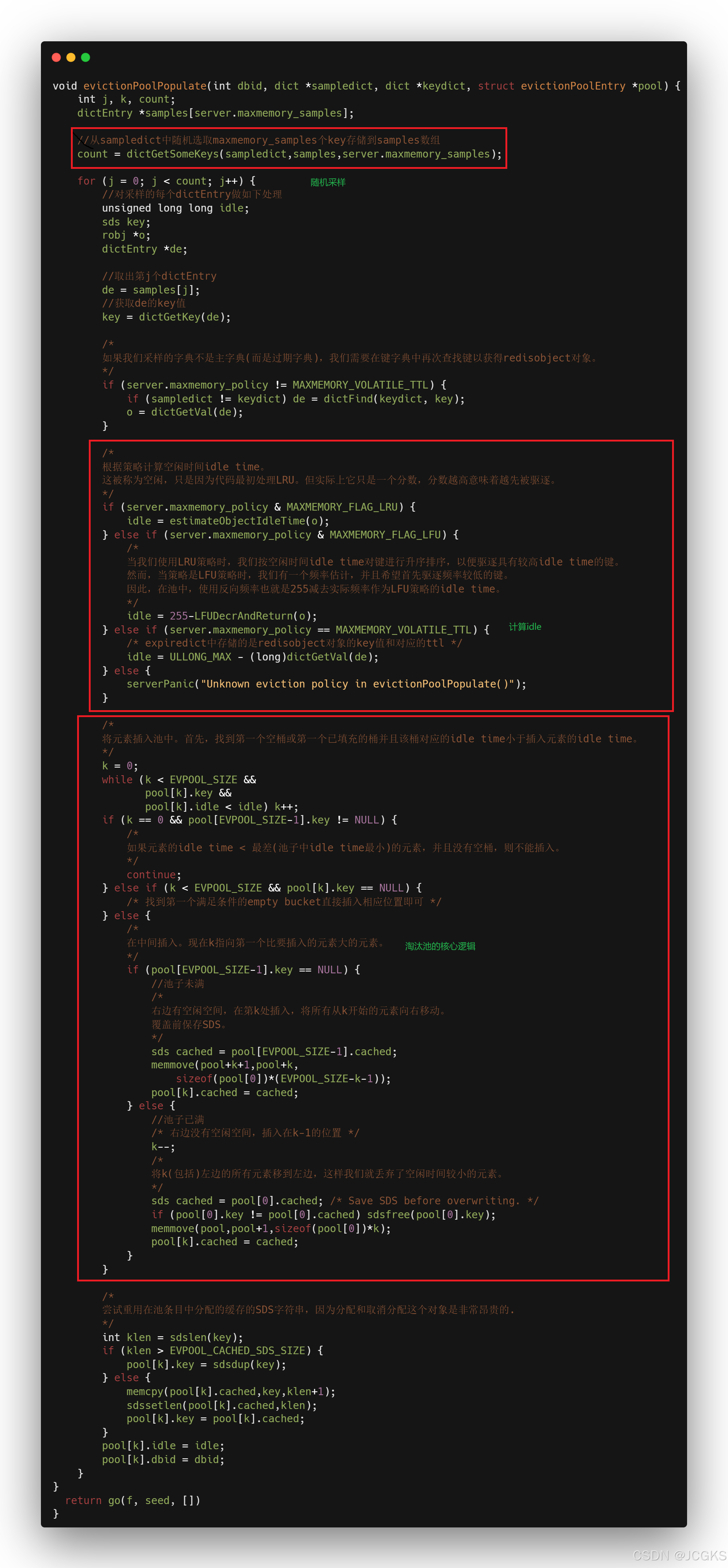
Reservoir Sampling
count = dictGetSomeKeys(sampledict,samples,server.maxmemory_samples);
接下来看一下随机采样的逻辑。
dictGetRandomKey
首先看一下随即采取一个dictEntry的逻辑
/* Return a random entry from the hash table. Useful to* implement randomized algorithms */
从hash table中返回一个随机entry。用来实现随机算法。
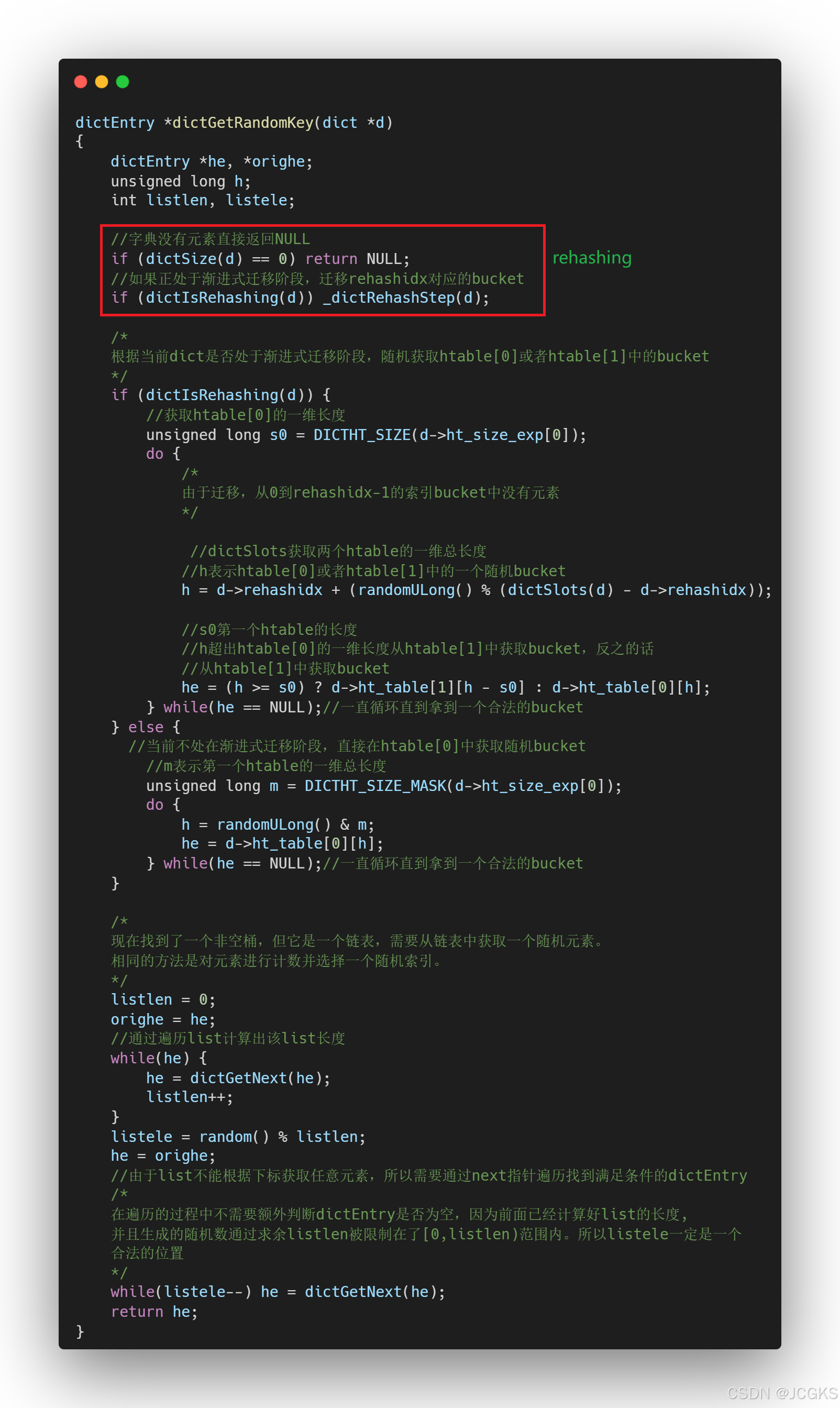
从代码中可以看出,在进行随机采样一个dictEntry时,会判断dict当前是否处于rehashing阶段,如果是的话就进行迁移操作
在"redis7.2.2|Dict"这篇文章中已经介绍过,dict何时会发生rehashing
dictGetSomeKeys
接下来看一下随机采取多个dictEntry的逻辑。
/* This function samples the dictionary to return a few keys from random* locations.** It does not guarantee to return all the keys specified in 'count', nor* it does guarantee to return non-duplicated elements, however it will make* some effort to do both things.** Returned pointers to hash table entries are stored into 'des' that* points to an array of dictEntry pointers. The array must have room for* at least 'count' elements, that is the argument we pass to the function* to tell how many random elements we need.** The function returns the number of items stored into 'des', that may* be less than 'count' if the hash table has less than 'count' elements* inside, or if not enough elements were found in a reasonable amount of* steps.** Note that this function is not suitable when you need a good distribution* of the returned items, but only when you need to "sample" a given number* of continuous elements to run some kind of algorithm or to produce* statistics. However the function is much faster than dictGetRandomKey()* at producing N elements. */
这个函数对字典进行采样,从随机位置返回几个键。
它不保证返回'count'中指定的所有键,也不保证返回不重复的元素,但是它会努力做到这两件事。
返回的指向哈希表项的指针存储在指向dictEntry指针数组的'des'中。
数组必须至少有容纳'count'元素的空间,这是我们传递给函数的参数,用于告诉我们需要多少个随机元素。
该函数返回存储在'des'中的项数,如果哈希表中包含的元素少于'count',或者在合理的步骤中没有找到足够的元素,则可能小于'count'。
请注意,当您需要返回项的良好分布时,此函数不适用,而只适用于需要“抽样”给定数量的连续元素以运行某种算法或生成统计数据时。
然而,在生成N个元素时,该函数比dictGetRandomKey()快得多。
在生成N个元素时,该函数比dictGetRandomKey()快得多。
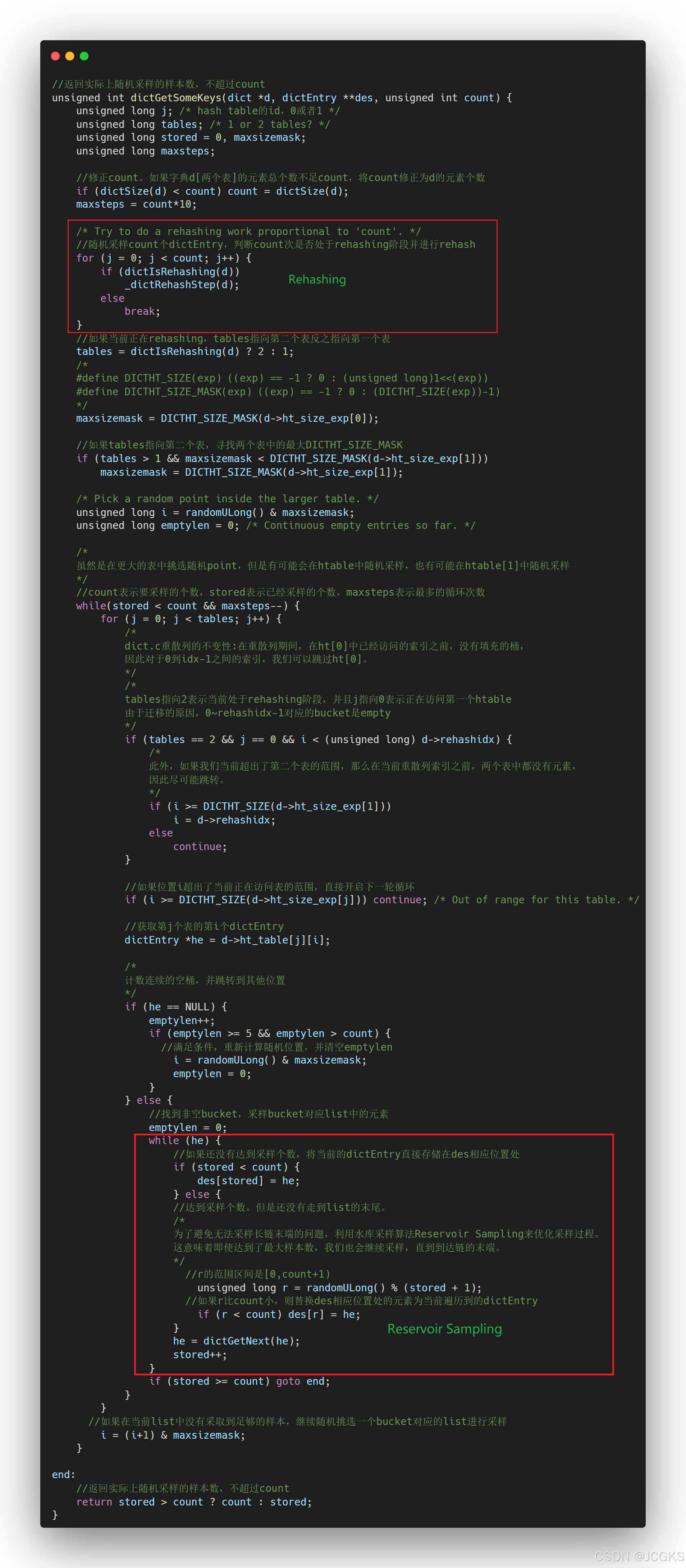
从代码中可以看出,在进行随机采样一个dictEntry时,会判断dict当前是否处于rehashing阶段,如果是的话就进行迁移操作
在"redis7.2.2|Dict"这篇文章中已经介绍过,dict何时会发生rehashing
- 通过研究代码发现:在生成N个元素时,函数"dictGetSomeKeys"确实要比函数"dictGetRandomKey"快得多。
- 因为对于"dictGetSomeKeys"函数来说,只需要确定一个bucket然后沿着list取样即可。但是对于"dictGetRandomKey"函数每生成一个元素都需要随机找到一个bucket并且还需要计算list的长度并且找到其中一个随机位置。
Reservoir Sampling
/* Collect all the elements of the buckets found non empty while iterating
* To avoid the issue of being unable to sample the end of a long chain,
* we utilize the Reservoir Sampling algorithm to optimize the sampling process.
* This means that even when the maximum number of samples has been reached,
* we continue sampling until we reach the end of the chain.
* See https://en.wikipedia.org/wiki/Reservoir_sampling. */
为了避免在长链末端无法采样的问题,我们采用了Reservoir Sampling算法来优化采样过程。
这意味着即使达到了最大样本数,我们也会继续采样,直到到达链的末端。
有关“Reservior Sampling”的详细介绍见https://en.wikipedia.org/wiki/Reservoir_sampling。
chatgpt对Reservoir Sampling的介绍
水库采样法(Reservoir Sampling)是一种在处理大规模数据流或未知大小的数据集合时,用于从中随机抽取固定数量样本的算法。它特别适用于数据流场景,因为在数据流开始之前并不知道其总量。
核心思想
水库采样的核心思想是在处理一个可能无限大的数据流时,从中抽取固定数量的样本,使得每个数据元素被选中的概率是相同的。
操作步骤
假设我们要从数据流中随机抽取k个元素,具体步骤如下:
- 初始化:创建一个大小为k的“水库”数组,并将前k个元素直接存入水库。
- 替换阶段:
- 对于每一个新的元素(假设这是第n个元素),生成一个随机数r,该随机数的范围是[0, n-1]。
- 如果r的值小于k,则用这个新元素替换水库中的第r个元素。
- 如果r的值大于等于k,则忽略这个元素。
举例说明
假设你有一个数据流,其中包含1000个元素,你想从中随机抽取10个样本。你会按以下步骤进行:
- 将前10个元素直接放入水库。
- 对第11个元素,生成一个随机数r,范围是[0, 10]。如果r的值在0到9之间,则用第11个元素替换水库中对应位置的元素。如果r等于10,则忽略这个元素。
- 重复上述步骤,直到处理完所有的1000个元素。
优势
- 空间效率高:只需要存储k个元素的水库,不论数据流的大小如何,这使得水库采样在内存限制的环境中特别有用。
- 公平性:保证了在最终的k个样本中,数据流中的每个元素被选中的概率是相同的。
应用场景
- 在线广告系统:随机抽取用户的行为数据,用于后续分析。
- 流媒体处理:在数据流不断到来的情况下,实时生成随机样本。
水库采样是一种简单而有效的算法,特别适用于在处理大规模数据时,确保样本具有代表性。
相关文章:
redis内存淘汰策略-------Reservoir Sampling(水库采样)
文章目录 过期删除策略和内存淘汰策略内存淘汰策略evictionPoolEntryevictionPoolPopulate Reservoir SamplingdictGetRandomKeydictGetSomeKeysReservoir Samplingchatgpt对Reservoir Sampling的介绍 过期删除策略和内存淘汰策略 详细介绍请参考博客“redis过期删除策略和内存…...

C++《类和对象》(上)
在之前的C入门基础知识中我们了解了C的发展过程已经重要性,还初步了解了C中一些相比C语言特有的知识点,例如命名空间、缺少参数、函数重载、引用等,接下来在本篇中我们将开始C整个体系中非常重要的一个知识章节——类和对象,类和对…...

LLM大语言模型算法特训
百度 LLM(Large Language Model)大语言模型算法特训是一个深度学习领域的高级培训项目,专门设计用于训练和优化大规模语言模型的开发者和研究人员。本文将详细探讨LLM算法的基本原理、训练技术、应用领域以及参与者可以预期的学习收获和挑战。…...

Docker相关笔记
Docker笔记 1. Dockerfile编译构建docker Dockerfile 是一个文本文件,包含了构建 Docker 镜像的所有指令。 Dockerfile 常用的有如下关键字: FROM:指定基础镜像,后续定制操作都是基于这个基础镜像,比如: …...

前端技术day01-HTML入门
一、前端介绍 技术描述HTML用于构建网站的基础结构的CSS用于美化页面的,作用和化妆或者整容作用一样JS实现网页和用户的交互Vue主要用于将数据填充到html页面上的Element主要提供了一些非常美观的组件 二、工具软件 VsCode 在前端领域,有一个公认好用…...

Multisim 用LM358 运放模拟线性稳压器 - 运放输出饱和 - 前馈电容
就是拿运放搭一个可调的LDO 稳压器,类似下面这个功能框图里的感觉。本来应该非常简单,没什么好说的,没想到遇到了两个问题。 原理 - 理想运放 我用PNP 三极管Q2 作为输出,运放输出电压升高时,流过PNP 三极管BE 的电流变…...

宁德大屏第二版总结
碰到难点 1.wss 心跳机制 实现前端和后端双向绑定 只要后端发送了消息 前端通过全局总线去触发你想要的函数。 全局总线 vue3可以全局总线下一个mitt 新建一个eventBus.js import mitt from "mitt"; const eventBus mitt();export default eventBus; 然后wss…...
)
冥想第一千二百四十七天(1247)
1.今天上午带桐桐去游泳了,买了卡吉诺,吃过最好吃的甜点。推荐。还有鸡排。 2.回来后带着媳妇,先加油。去给丈母娘看腿,等丈母娘等了好久,还帮她推车。 3.回来后,在丈母娘家跑步。很舒服。家长麦田的香味。…...

基于光学动捕定位下的Unity-VR手柄交互
Unity VR 场景手柄交互实现方案 需求 在已创建好的 Unity VR 场景中,接入游戏手柄,通过结合动捕系统与 VRPN,建立刚体,实时系统获取到手柄的定位数据与按键数据,通过编写代码实现手柄的交互逻辑,实现手柄…...

php json_decode 带反斜杠字符串json解析
PHP json_decode 带反斜杠字符串json解析 今天再次遇到了json字符串中包含反斜杠的问题,记录下解决方法 在JSON字符串中,反斜杠\用作转义字符。当JSON_UNESCAPED_SLASHES选项被用于json_encode()函数时,不会在slashes前面添加反斜杠。 但是…...
【NLP】文本张量表示方法【word2vec、词嵌入】
文章目录 1、文本张量表示2、one-hot词向量表示2.1、one-hot编码代码实现:2.2、onehot编码器的使用2.3、one-hot编码的优劣势 3、word2vec模型3.1、模型介绍3.2、CBOW模式3.3、skipgram模式3.4、word2vec的训练和使用3.4.1、获取训练数据3.4.2、训练词向量3.4.3、查…...

疯狂Java讲义_08_泛型
文章目录 泛型的传参若函数里的参数使用基类接受所有的派生类,怎么做? 类型通配符的上限类型通配符的下限 泛型的传参 注意 若类 Base 是类 Derived 的基类(父类),那么数组类型 Base[] 是 Derived[] 的基类࿰…...

HCIA、OSPF笔记
一、OSI参考模型 1、OSI的结构 应用层:把人类语言转化成编码,为各种应用程序提供网络服务。 表示层:定义一些数据的格式,(对数据进行加密、解密、编码、解码、压缩、解压缩,每一层都可以实现,…...

Python删除lru_cache缓存
在 Python 中,lru_cache 是一个装饰器,用于添加缓存功能以提高函数的性能。如果你想清除或者删除 lru_cache 中的缓存,有几种方法可以做到: 手动清除缓存: lru_cache 对象有一个方法叫做 cache_clear(),可以手动清除所有缓存。示例:@lru_cache(maxsize=128) def some_fun…...

Android面试必问题:大白文讲透Android View工作原理
目录 第一章 引言 第二章 Android View 基础概念 2.1 视图(View) 2.2 布局(Layout) 2.3 绘制(Drawing) 第三章 Android View 工作原理详解 3.1 测量过程剖析 3.2 布局流程探究 第四章 Android View 性能优化建议 4.1 视图层级优化 4.2 避免过度的视觉效果 4.…...

WinDbg配置远程调试
WinDbg配置远程调试 1、为什么需要远程调试 某些特殊的场合需要远程调试,如: ①调试特殊的程序,比如在调试全屏程序,内核。 ②需要别人帮助调试或者帮助别人调试。比如由于商业性质不能直接给你pdb和源代码。 ③还有一类就是…...

spl注入实战thinkphp
目录 一、环境的部署 二、本地创建数据库 三、填写数据库连接文件 四、编写控制器 五、访问分析 debug报错会显示物理路径 原因是config.php文件相关配置 六、注入分析 七、进入断点调试 八、通过mysql执行语句查看结果 九、总结: 一、环境的部署 二、本地…...
)
整理深度学习时最常用的Linux命令(自用)
清华大学镜像源: https://pypi.tuna.tsinghua.edu.cn/simple/tar文件解压 tar -xzvf xxx.tar.gztar xvf xxx.tarzip文件解压 unzip xxx.zip -d path/to/your/fold清理GPU异常内存占用 杀掉 1 号显卡的所有进程 fuser -v /dev/nvidia1 | xargs -t -n 1 kill -9杀掉…...

LVS——>linux 虚拟服务器知识汇总
一、概念: LVS(Linux Virtual Server),是Linux Virtual Server的简写,也就是Linux 虚拟服务器,是一个虚拟的服务器集群系统负载均衡解决方案,它将一个真实服务器集群虚拟成一台服务器来对外提供…...
AI赋能周界安防:智能视频分析技术构建无懈可击的安全防线
周界安全防范是保护机场、电站、油库、监狱、工业园区等关键设施免受非法入侵和破坏的重要措施。传统的周界安防手段主要依靠人员巡查和物理屏障,但这种方式不仅人力成本高,而且效率较低,难以满足日益复杂多变的安全需求。随着AI技术的引入&a…...
)
保姆级教程:在ROS2 Humble/Foxy的Gazebo中配置RGB-D相机(附解决点云颜色/坐标问题)
ROS2 Humble/Foxy中Gazebo深度相机仿真全攻略:从配置到点云问题解决在机器人仿真开发中,深度相机(RGB-D)是不可或缺的传感器之一。它能够同时提供彩色图像和深度信息,为SLAM、物体识别、避障等任务提供关键数据支持。本…...

SSH工具对比:新手用户和熟练运维,选型逻辑有什么不同
结论 新手用户和熟练运维在选择 SSH 工具时,关注点往往完全不同。 新手更在意的是:能不能顺利连接、界面是否直观、文件和配置是否容易找到、网站出问题时能不能快速定位。 而熟练运维更在意的是:连接效率、命令自由度、多服务器管理能力、原…...

对比 Token Plan 与按量计费在 Taotoken 平台上的成本体感差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比 Token Plan 与按量计费在 Taotoken 平台上的成本体感差异 对于个人开发者或项目管理者而言,在接入大模型服务时&a…...

3步解锁专业级MMD创作:Blender插件如何重塑二次元动画工作流
3步解锁专业级MMD创作:Blender插件如何重塑二次元动画工作流 【免费下载链接】blender_mmd_tools MMD Tools is a blender addon for importing/exporting Models and Motions of MikuMikuDance. 项目地址: https://gitcode.com/gh_mirrors/bl/blender_mmd_tools …...
)
ROS Noetic实战:从bag包里‘抠’出雷达点云和IMU数据的保姆级教程(Ubuntu 20.04)
ROS Noetic实战:从bag包里提取雷达点云和IMU数据的完整指南(Ubuntu 20.04)在机器人开发中,ROS bag文件就像是一个装满珍贵数据的宝箱,而雷达点云和IMU数据则是其中最闪亮的宝石。作为一名长期与ROS打交道的开发者&…...

荣耀出征官方网站下载正版手游 翅膀养成细节玩法全方位讲解
玩荣耀出征的玩家都清楚,翅膀不仅是角色的颜值象征,更是提升整体战力的核心途径。很多新手玩家只顾着升级、刷装备,完全忽略翅膀养成,导致等级很高但战力始终上不去。还有不少玩家胡乱合成、盲目进阶,浪费了大量稀有翅…...

从RD、CS到WK:一文讲透SAR主流成像算法的演进与选型实战
从RD、CS到WK:SAR成像算法选型实战指南 当无人机掠过灾区上空,或卫星扫描地球表面时,合成孔径雷达(SAR)正通过电磁波穿透云层和黑暗,将地面信息转化为高分辨率图像。而决定图像质量的关键,在于工…...

1688运营培训/询盘成本从500元降到63.9!1688运营培训还原1688真实玩法
1688运营培训/询盘成本从500元降到63.9!1688运营培训还原1688真实玩法500块钱一个询盘,你敢信?做1688运营培训这么多年,这个数字我都觉得离谱。前阵子遇到一个老板,一上来就开始吐槽1688,说1688就是个垃圾平…...

League Akari:如何通过LCU API实现英雄联盟游戏流程的智能化管理?
League Akari:如何通过LCU API实现英雄联盟游戏流程的智能化管理? 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit Leag…...

接口测试用例设计:超详细防御体系与分层校验实践
1. 为什么“超详细”三个字在接口测试用例里不是修饰词,而是生死线我带过三支不同行业的测试团队——金融支付、SaaS中台、IoT设备管理平台。每次新人入职第一周,我都会收走他们写的前5条接口测试用例,逐行标红批注。不是因为格式不对&#x…...