MySQL数据库10——多表连接查询
数据如果在多个表里面,需要进行连接查询。
一般在pandas里面merge合并会用到一个索引,按这个索引的规则进行合并叫做有规则的等值连接。若不按规则连接,遍历两两组合的所有可能性,叫做笛卡尔积。
笛卡尔积连接
通常人们都会设置连接规则,但无条件连接所得到的笛卡尔积有时也非常有用。例如下面的例子。
使用student表和course表的笛卡尔积,生成一个必修课成绩表(bxk_score)的内容,要求是每个学生都应该选择所有的必修课。
CREATE TABLE bxk_score AS
SELECT student.ID as 学号, student.name AS 姓名, course.ID AS 课号, course.course AS 课名
FROM student, course WHERE course.type='必修'
ORDER BY 学号, 课号;运行上面的查询语句后,会生成bxk_Score表,对其执行查询语句如下。
SELECT * FROM bxk_score;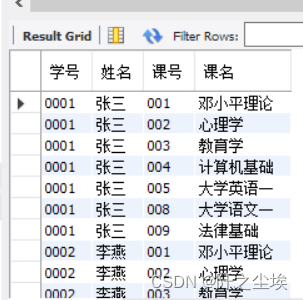
本例使用笛卡尔积,自动生成了bxk_Score表的大部分内容。当然,该表还应该有一个“成绩”字段。该字段的添加可以在后期通过修改表结构的方法解决。
(1)创建一个临时表bbb,该表只有一个数值字段“成绩”。创建表的SQL语句如下所示。
(2)向bbb表插入记录,插入语句如下所示。
(3)修改SELECT语句如下所示。
CREATE TABLE bbb(score int);
INSERT INTO bbb(score) VALUES (0);
CREATE TABLE bxk_score AS
SELECT student.ID as 学号, student.name AS 姓名, course.ID AS 课号, course.course AS 课名,bbb.score
FROM student, course ,bbb WHERE course.type='必修'
ORDER BY 学号,课号;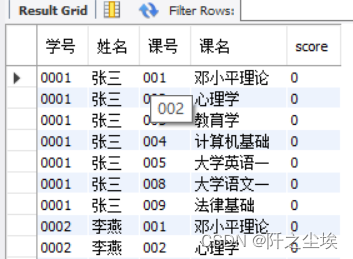
使用两表连接查询数据
数据库操作中,比起使用笛卡尔积,使用有连接规则的连接查询会更频繁一些。下面通过一个例子介绍两表连接查询的具体使用方法。
查询名叫“张三”的学生的所有课程的平时成绩和考试成绩。
分析:student表中有学生姓名,但没有成绩,而存储成绩的score表中有成绩,但没有姓名,不过这两个表都有一个共同字段——学号,所以可以将这两个表连接起来进行查询,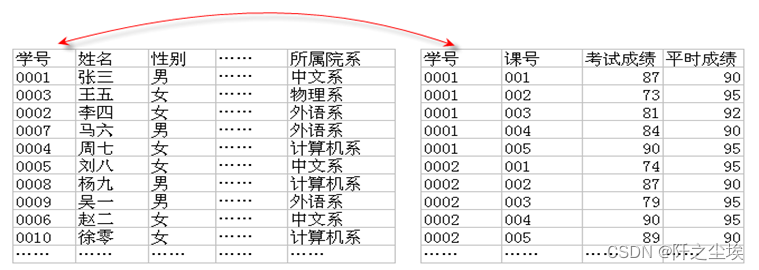
SELECT student.ID AS 学号, student.name AS 姓名, score.c_id AS 课号,score.result2 AS 平时成绩, score.result1 AS 考试成绩
FROM student, score WHERE student.name = '张三' AND student.ID=score.s_id
ORDER BY score.result1 DESC,score.result2 DESC;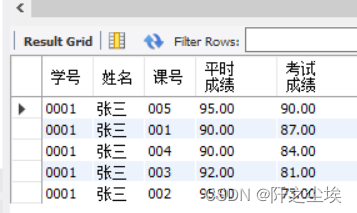
多表连接查询
继续上一节的话题,因为用户更希望看到课名,而不是课号,所以必须将存有课名的Course表也连接到Student和Score表上。
查询名叫“张三”的学生的所有课程的平时成绩和考试成绩。
分析:在上一节中,已经知道了Student和Score表可以用共同拥有的学号字段进行连接。接下来的问题是将Course表连接到上述两个表上。由于Student表和Course表没有共同字段所以不能连接,但是Score表和Course表有共同字段——课号,因此Score表和Course表可以连接,如此以来,经过Score表的搭桥,上述三个表就可以连接了,请参考下图所示。
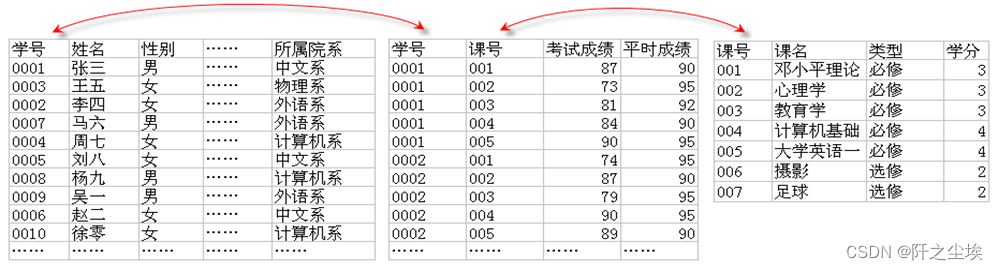
SELECT student.ID AS 学号, student.name AS 姓名, course.course AS 课名, score.result2 AS 平时成绩, score.result1 AS 考试成绩
FROM student, score, course
WHERE student.name = '张三' AND student.ID=score.s_id AND score.c_id=course.id
ORDER BY score.result1 DESC,score.result2 DESC; 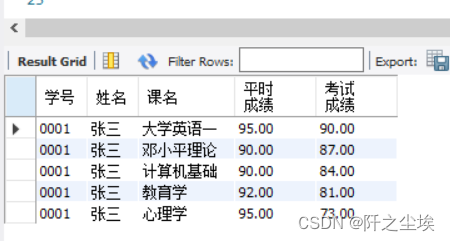
成功把课程代码换成课程名称了。
使用表别名简化语句
在前面曾经介绍过给字段起别名的方法,其实给表起别名与其非常类似。在FROM子句中,在表名的后面加上关键字“AS”和别名即可。例如,下面的查询语句使用表别名简化了上一小节例的查询语句。
SELECT a.ID AS 学号, a.name AS 姓名, c.course AS 课名, b.result2 AS 平时成绩, b.result1 AS 考试成绩
FROM student AS a,score AS b,course AS c
WHERE a.name = '张三' AND a.ID=b.s_id AND b.c_id=c.ID
ORDER BY b.result1 DESC,b.result2 DESC;
例 查询“计算机基础” 课程,考试成绩大于等于90分的学生的学号、姓名、系别和考试成绩,并按考试成绩降序排序。
分析:课程名称在course表中,成绩在score表中,而姓名、系别在student表中,因此想要得到本例要求的结果,则必须对course、score和student三个表进行连接查询。
SELECT st.ID AS 学号, st.name AS 姓名, st.institute AS 所属院系, s.result1 AS 考试成绩
FROM score AS s,course AS c,student AS st
WHERE c.course='计算机基础' AND s.result1>=90 AND s.c_id=c.ID AND st.ID= s.s_id
ORDER BY s.result1 DESC;
使用INNER JOIN连接查询
因此在ANSI SQL规范中建议使用INNER JOIN进行多表连接。如此以来,WHERE子句中就不用再放置连接规则,而只放置查询条件就可以了。使用INNER JOIN连接n个表的语法格式如下所示。
SELECT *(或字段列表) FROM 表名1
INNER JOIN 表名2
ON 接规则
INNER JOIN 表名3
ON 连接规则
……
INNER JOIN 表名n
ON 连接规则其中,关键字“ON”之后是连接表的规则。
下面通过一个具体例题介绍INNER JOIN的用法。
例 查询所有考过“心理学” 课程的学生的学号、姓名、系别、“心理学”的平时成绩和考试成绩。
SELECT st.ID AS 学号, st.name AS 姓名, st.institute AS 所属院系, s.result2 AS 平时成绩, s.result1 AS 考试成绩
FROM score AS s
INNER JOIN course AS c ON s.c_id=c.ID
INNER JOIN student AS st ON st.ID= s.s_id
WHERE c.course='心理学' ORDER BY s.result1 DESC;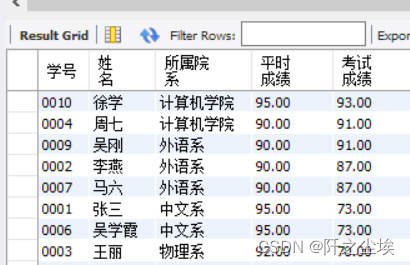
对应的WHERE语句:运行结果和上面相同。
SELECT st.ID AS 学号, st.name AS 姓名, st.institute AS 所属院系, s.result2 AS 平时成绩, s.result1 AS 考试成绩
FROM score AS s, course AS c, student AS st
WHERE c.course='心理学' AND s.c_id=c.ID AND st.ID=s.s_id
ORDER BY s.result1 DESC;
高级连接查询
自连接查询存
首先通过一个例题说明自连接查询存在的价值,其次介绍自连接查询的使用方法。
从student表中,查询“张三”所在院系的所有学生的信息。
分析:按照以前所学的知识,完成本例的查询任务需要两次查询,首先查询“张三”所在的院系是哪个院系,其次才能查询属于该院系的所有学生的信息。
(1)查询“张三”所在的院系名称。
SELECT institute AS 所属院系
FROM student
WHERE name='张三‘(2)根据上面查询,知道“张三”在中文系学习,下面查询“中文系”所有学生信息。
SELECT * FROM student
WHERE institute='中文系‘上面两条语句可以一句话自连接查询完成,因为自连接查询可以用一条SELECT语句完成本例的查询任务。具体查询语句如下所示。
SELECT st1.* FROM student AS st1, student AS st2
WHERE st1.institute= st2.institute
AND st2.name='张三';
为了强调连接规则的设置,下面再看一个例题。
例 从student表中查询与“吴刚”来源地相同的所有学生学号、姓名和所属院系。
SELECT st1.ID AS 学号, st1.name AS 姓名, st1.institute AS 所属院系
FROM student AS st1, student AS st2
WHERE st2.name='吴刚'
AND st1.origin=st2.origin;
内连接查询存
有规则的连接都属于内连接。内连接包括等值连接、自然连接、和不等值连接。
一、等值连接
前面几节的内容中,连接规则由等于号(=)组合而成,例如,st1.institute= st2.institute,并且列出两个表中所有字段的连接,即SELECT子句中使用星号(*)通配符的连接就属于等值连接。关于等值连接,由于前面的例子已经足够,因此不再具体举例说明。
二、自然连接
在等值连接的基础上稍加改动即可得到自然连接,等值连接将两个表中的所有字段全部列出,而自然连接则不将相同的字段显示两次,即在SELECT子句中列出需要显示的字段列表。
三、不等值连接
不等值连接的连接规则由等于号以外的运算符组成,例如,由>、>=、<、<=、<>或BETWEEN等。下面通过一个例题介绍不等值连接的使用方法。首先创建一个将要使用的年代对照表(nddzb),其创建语句和插入记录的语句分别如下所示。
例 从student表中,查询所有学生的出生年代。
分析:要完成此查询任务,需要将student表和nddzb连接起来,但是这两个表没有共同字段,所以没办法使用等值连接,而根据题意可以使用不等值连接。连接规则是如果student表的出生日期在nddzb的起始年份和终止年份之间就可以连接。
SELECT st.name AS 姓名,st.birthday AS 出生日期, n.年代
FROM student AS st,nddzb AS n
WHERE st.birthday BETWEEN n.起始年份 AND n.终止年份;
外连接查询存
在多表连接查询时,有时希望表的所有记录都被包含进去,即使没能匹配的记录也被查询结果集包含在内。这时,内连接查询已经满足不了需求了,所以应该采用另外一种连接查询方法——外连接查询,例如下图所示。外连接有左外连接、右外连接和全外连接三种。
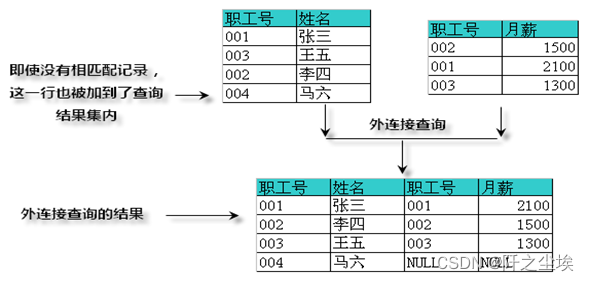
左外连接
这种连接的规则是将左外连接符号(LEFT OUTER JOIN或LEFT JOIN)左边的表的所有记录都包含到结果集中,而只将右边表中有匹配的记录包含进结果集,例如,如图10.22所示。实现图中左外连接的查询语句如下所示。

对应代码
SELECT * FROM t1
LEFT OUTER JOIN t2
ON t1.职工号=t2.职工号通过上图还可以知道,左外连接时,会将左边表的所有记录都会包含到查询结果中,这时,那些没有匹配的左边表的记录会与全部是NULL值的记录连接。
右外连接
这种连接的规则是将右外连接符号(RIGHT OUTER JOIN或RIGHT JOIN)右边的表的所有记录都包含到结果集中,而只将左边表中有匹配的记录才包含进结果集,例如,如图10.23所示。实现图中右外连接的查询语句如下所示。

SELECT * FROM t1
RIGHT OUTER JOIN t2
ON t1.职工号=t2.职工号全外连接
这种连接的规则是将两个表的所有记录都包含到结果集中,而且,这种连接只有一种FULL OUTER JOIN连接符。例如下图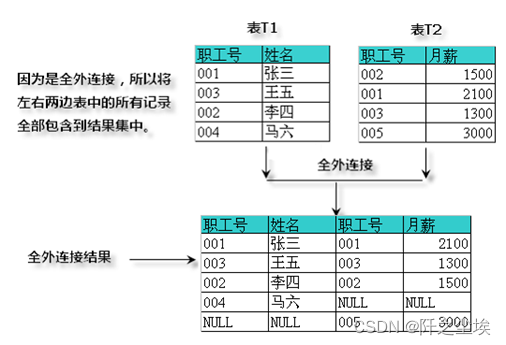
在MySQL中不支持全外连接,要实现全外连接的效果,可以采用关键字UNION来联合左、右连接,具体查询语句如下:
SELECT * FROM t1LEFT JOIN t2ON t1.职工号=t2.职工号UNION
SELECT * FROM t1RIGHT JOIN t2ON t1.职工号=t2.职工号
交叉连接查询
交叉连接类似笛卡尔积,无规则连接,例如将学生表和课程表连在一起。会生成120条数据。12(学生数量)*10(课程数量)
下面两种方法是相同的结果。
SELECT * FROM student,course;SELECT * FROM student CROSS JOIN course;
连接查询中使用聚合函数
统计没有考过任何考试的学生人数
SELECT COUNT(*) AS 没有考任何考试的人数 FROM student AS st
LEFT OUTER JOIN score AS s ON st.ID=s.s_id
WHERE s.s_id IS NULL;
组合查询
有时,需要将多个查询语句的结果放到一起,以一个查询结果集的形式将其显示出来。这时就可以使用组合查询,组合查询是使用UNION关键字将多个SELECT查询语句组合起来查询的一种查询方法,其语法格式如下例子所示。
例 从student表中,查询来源地为“北京市”或者所属院系为“计科系”或者年龄大于25岁的学生的信息。运行环境为MySQL。
SELECT * FROM student WHERE origin='北京市'
UNION SELECT * FROM student WHERE institute='计科系'
UNION SELECT * FROM student WHERE TIMESTAMPDIFF(YEAR, birthday, CURDATE())>25;
例 从student表中,查询来源地为“北京市”或 “江苏省”或“内蒙古自治区”的学生的所属院系信息。
(1)下面的语句使用UNION完成查询任务。
SELECT institute AS 所属院系 FROM student WHERE origin='北京市'
UNION SELECT institute AS 所属院系 FROM student WHERE origin='江苏省'
UNION SELECT institute AS 所属院系 FROM student WHERE origin='内蒙古自治区';
(2)下面的语句使用OR完成查询任务。
SELECT institute AS 所属院系 FROM student
WHERE origin='北京市' OR origin='江苏省' OR origin='内蒙古自治区';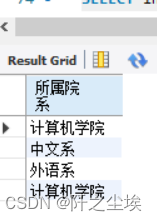
使用UNION时,如果希望不删除重复值,则可以在UNION后加上ALL关键字。
使用UNION的规则
1、每个查询语句应当有相同数量的字段。
在使用UNION组合查询语句时,一定要注意每个单独的SELECT子句内的字段个数一定要相同。如果不同则会出现错误
2、每个查询语句中相应的字段的类型必须相互兼容
在每个查询语句字段个数相等的前提下,相应的字段的类型应当互相兼容。
技巧:当独立查询语句的字段个数不同时,可以在字段个数不够的地方使用常量补位。例如,在上面的第一个SELECT子句中补上一个NULL值,就可以避免错误,具体语句如下所示。
SELECT ID, name, null
FROM student
WHERE origin='北京市'
UNION
SELECT ID, name, birthday
FROM student
WHERE institute='计科系'使用UNION解决不支持全外连接的问题。
如上面的左连接和右连接合并就是全连接了。
使用UNION得到复杂的统计汇总样式
联合UNION、GROUP BY和聚合函数三者会得到具有很棒的统计汇总样式的查询结果,这也是OR所不能替代的。例如,下面的语句会得到一个具有复杂统计汇总样式的查询结果集。
SELECT s_id AS 学号, c_id AS 课号, result1 AS 考试成绩 FROM score
UNION SELECT s_id AS 学号, '总分:', SUM(result1) FROM score GROUP BY s_id
UNION SELECT s_id, '平均分:', AVG(result1) FROM score
GROUP BY s_id ORDER BY 学号, 课号;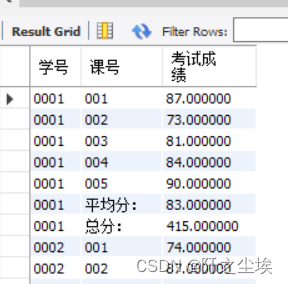
排序组合查询的结果
虽然组合查询中可以有多个单独的SELECT语句,而且每个独立的SELECT语句又都可以拥有自己的WHERE子句、GROUP BY子句和HAVING子句,但是,整个语句中却只能出现一个ORDER BY子句,而且它的位置必须在整个语句的末尾,就是说只能对组合查询最后的结果进行排序,而并不能只对某个单独的SELECT语句的结果进行排序。
SELECT st.name AS 姓名,c.ID AS 课号, c.course AS 课名, s.result1 AS 考试成绩
FROM score AS s, student AS st, course AS c
WHERE s.s_id=st.ID AND s.c_id=c.ID
UNION
SELECT st.name AS 姓名,'999', '总分:',SUM(s.result1) AS 考试成绩
FROM score AS s, student AS st
WHERE s.s_id=st.ID
GROUP BY s.s_id,st.name
UNION
SELECT st.name AS 姓名, '999', '平均分:', AVG(s.result1) AS 考试成绩
FROM score AS s, student AS st
WHERE s.s_id=st.ID
GROUP BY s.s_id,st.name
ORDER BY 姓名, 课号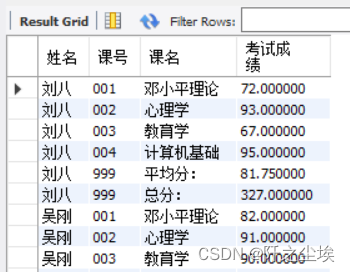
相关文章:
MySQL数据库10——多表连接查询
数据如果在多个表里面,需要进行连接查询。 一般在pandas里面merge合并会用到一个索引,按这个索引的规则进行合并叫做有规则的等值连接。若不按规则连接,遍历两两组合的所有可能性,叫做笛卡尔积。 笛卡尔积连接 通常人们都会设置…...
| 真题含思路)
华为OD机试 - 括号检查(Python)| 真题含思路
括号检查 题目 现有一字符串 仅由 (,),{,},[,] 六种括号组成,若字符串满足以下条件之一,则为无效字符串 任意类型的左右括号数量不相等 存在未按正确顺序(先左后右)闭合的括号, 输出括号的最大嵌套深度 若字符串无效则输出 0 0 <= 字符串长度 <= 100000 输入 一个只…...
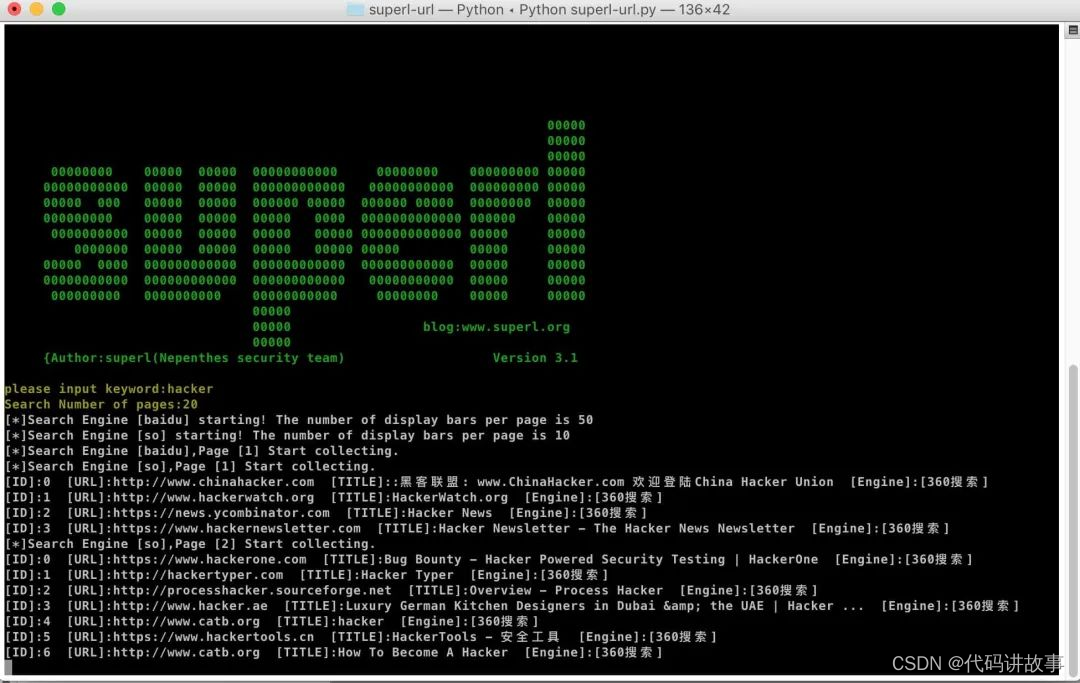
安全渗透测试中的一款免费开源的超级关键词URL采集工具
安全渗透测试中的一款免费开源的超级关键词URL采集工具。 #################### 免责声明:工具本身并无好坏,希望大家以遵守《网络安全法》相关法律为前提来使用该工具,支持研究学习,切勿用于非法犯罪活动,对于恶意使…...
解读)
数据资产管理实践白皮书(6.0版)解读
目录 第一章数据资产管理概述 ( 一 ) 数据资产管理和数据要素的关系...
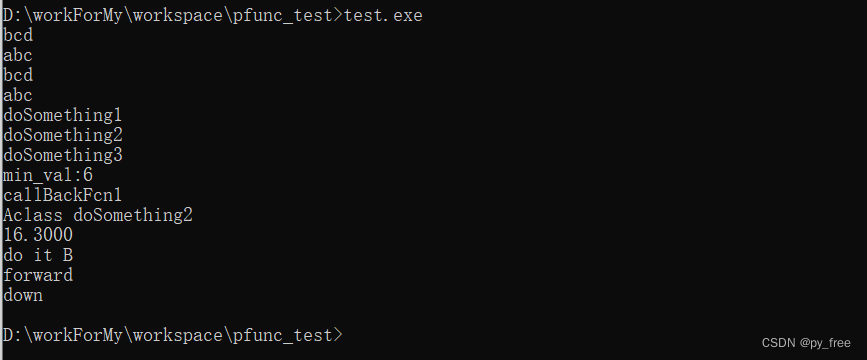
c/c++开发,无可避免的函数指针使用案例
一、函数指针简介 函数指针是指指向函数而非指向对象的指针。像其他指针一样,函数指针也指向某个特定的类型。函数类型由其返回类型以及形参表确定,而与函数名无关。例如: char* (*pf1)(char * p1,char *p2); 这是一个函数指针,其…...
-QThreadPool)
QT(12)-QThreadPool
1 简介 QThreadPool是Qt框架中的一个类,提供了一组工作线程池。该线程池自动管理一组工作线程,在线程可用时分配任务。使用线程池的主要优点是,它可以减少创建和销毁线程的开销,因为可以重复使用线程。 线程池设计用于场景中&am…...

【Java|golang】1138. 字母板上的路径
我们从一块字母板上的位置 (0, 0) 出发,该坐标对应的字符为 board[0][0]。 在本题里,字母板为board [“abcde”, “fghij”, “klmno”, “pqrst”, “uvwxy”, “z”],如下所示。 我们可以按下面的指令规则行动: 如果方格存…...

Flink 1.14从简单到源码第三讲
文章目录 1.flink多流操作Api1.1split 分流操作1.2.侧输出流1.3.connect 连接操作1.4.union 操作1.5 coGroup 协同分组1.6 join1.7 broadcast 广播2.process3.并行度和Api3.1 任务提交简单流程3.2 task与算子链4. Flink 时间相关(窗口计算)4.1时间语义(窗口计算)4.2 新版api指定…...
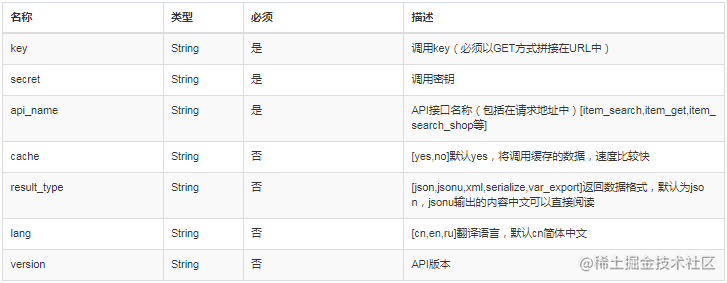
淘宝API接口系列,获取购买到的商品订单列表,卖出的商品订单列表,订单详情,订单物流,买家信息,收货地址列表,买家token
custom自定义API操作buyer_order_list获取购买到的商品订单列表buyer_order_detail获取购买到的商品订单详情buyer_order_express获取购买到的商品订单物流buyer_address_list收货地址列表buyer_address_add添加收货地址buyer_info买家信息buyer_token买家tokenseller_order_li…...

ucos-ii 的任务调度原理和实现
ucosii 任务调度和原理1、ucos-ii 任务创建与任务调度 1.1、任务的创建 当你调用 OSTaskCreate( ) 进行任务的创建的时候,会初始化任务的堆栈、保存cpu的寄存器、创建任务的控制块(OS_TCB)等的操作; if (OSTCBPrioTbl[prio] (OS_…...

Solon2 开发之容器,七、切面与函数环绕拦截
想要环绕拦截一个 Bean 的函数。需要三个前置条件: 通过注解做为“切点”,进行拦截(不能无缘无故给拦了吧?费性能)Bean 的 method 是被代理的在 Bean 被扫描之前,完成环绕拦截的注册 1、定义切点和注册环…...
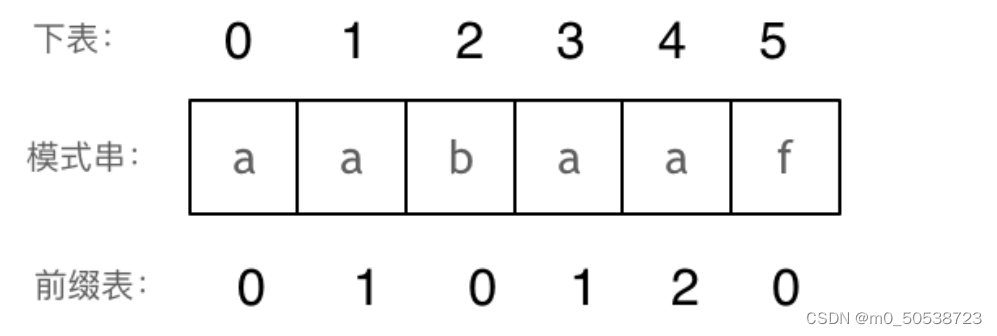
代码随想录第十天(28)
文章目录28. 找出字符串中第一个匹配项的下标看答案KMPnext数组(前缀表)最长公共前后缀如何计算前缀表前缀表与next数组时间复杂度分析28. 找出字符串中第一个匹配项的下标 莫得思路……好久没做题,都已经忘得差不多了 看答案 其实就是自己…...
循环队列来了解一下!!
笔者在之前的一篇文章,详细的介绍了:队列之单向链表与双向链表的模拟实现:https://blog.csdn.net/weixin_64308540/article/details/128742090?spm1001.2014.3001.5502 感兴趣的各位老铁,可以参考一下啦!下面进入循环…...
Idea打包springboot项目war包,测试通过
pom.xml文件 <!--包名以及版本号,这个是打包时候使用,版本可写可不写,建议写有利于维护系统--> <artifactId>tsgdemo</artifactId> <version>0.0.1-SNAPSHOT</version> <!--打包形式--> <packaging&…...

python+django高校师生健康信息管理系统pycharm
管理员功能模块 4.1登录页面 管理员登录,通过填写注册时输入的用户名、密码、角色进行登录,如图所示。 4.2系统首页 管理员登录进入师生健康信息管理系统可以查看个人中心、学生管理、教师管理、数据收集管理、问卷分类管理、疫情问卷管理、问卷调查管理…...
CUDA中的流序内存分配
文章目录CUDA中的流序内存分配1. Introduction2. Query for Support3. API Fundamentals (cudaMallocAsync and cudaFreeAsync)4. Memory Pools and the cudaMemPool_t注意:设备的内存池当前将是该设备的本地。因此,在不指定内存池的情况下进行分配将始终…...

开源、低成本的 Xilinx FPGA 下载器(高速30MHz)
目前主流的Xilinx下载器主要有两种:一种是Xilinx官方出品的Xilinx Platfom Cable USB,还有一个就是Xilinx的合作伙伴Digilent开发的JTAG-HS3 Programming Cable。 JTAG-HS系列最大支持30MHz下载速度,基于FTDI的FT2232方案。 JTAG-HS系列对比…...
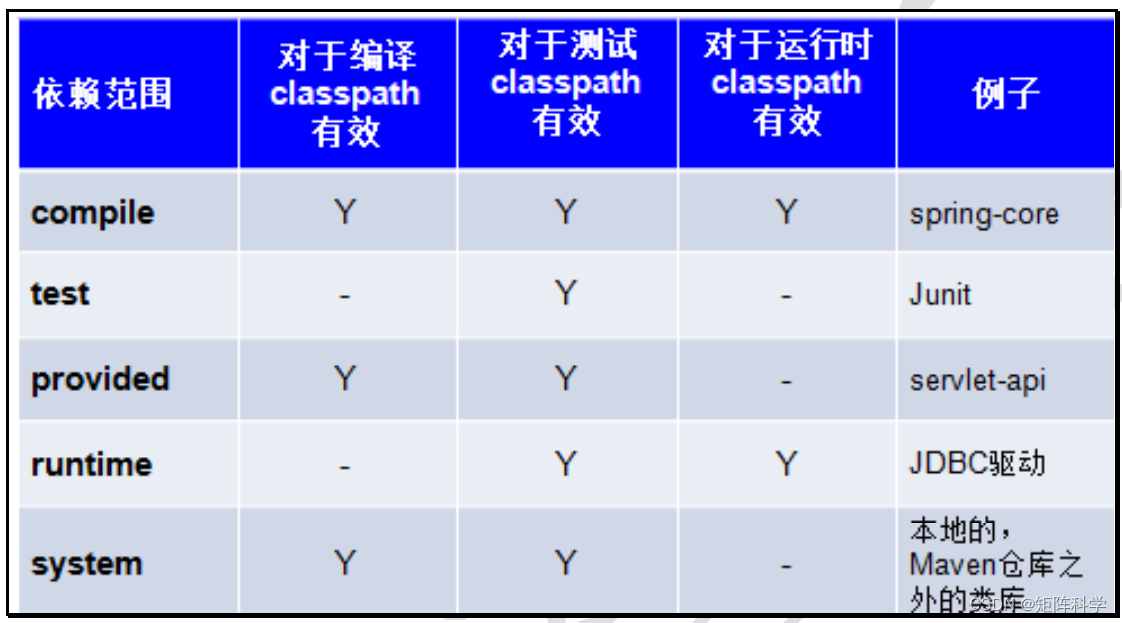
Maven专题总结
1. 什么是Maven Maven 是一个项目管理工具,它包含了一个项目对象模型 (POM: Project Object Model),一组标准集合,一个项目生命周期(Project Lifecycle),一个依赖管理系统(Dependency Management System),和…...
谷粒商城--SPU和SKU
目录 1.SPU和SKU概念 2.表的关系理解 3.导入前端代码 4.完善后端接口 5.属性分组详情 6.规格参数详情 7. 销售属性详情 8.分组与属性关联 9.发布商品 10.仓库服务 1.SPU和SKU概念 SPU:standard product unit(标准化产品单元):是商品信息聚合的…...
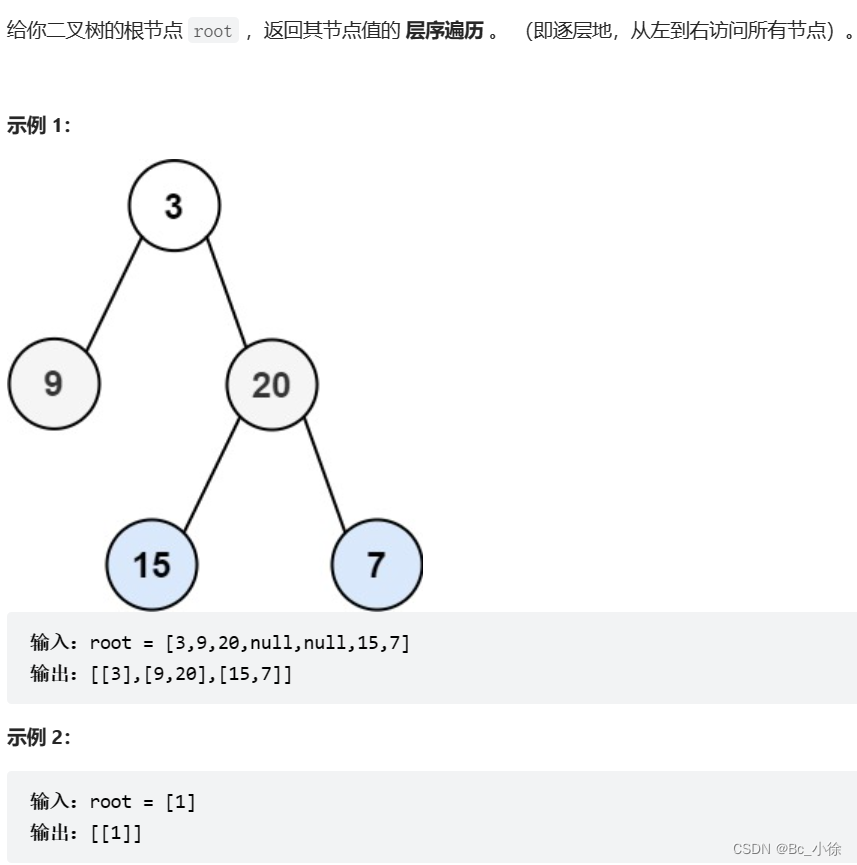
二叉树OJ题(上)
✅每日一练:100. 相同的树 - 力扣(LeetCode) 题目的意思是俩棵树的结构不仅要相同,而且每个节点的值还要相同,如果满足上面2个条件,则成立! 解题思路: 从三个方面去考虑࿱…...

终极大脑训练指南:5个简单步骤用BrainWorkshop提升你的认知能力
终极大脑训练指南:5个简单步骤用BrainWorkshop提升你的认知能力 【免费下载链接】brainworkshop Continued development of the popular brainworkshop game 项目地址: https://gitcode.com/gh_mirrors/br/brainworkshop BrainWorkshop是一款专业的免费开源大…...

为Odoo ERP构建安全的AI数据访问层:基于权限治理的语义查询实践
1. 项目概述:为Odoo ERP构建一个受治理的AI数据访问层如果你正在使用Odoo管理企业业务,同时又希望让AI助手(比如Claude、Cursor)能够安全地查询销售数据、分析库存状况,而不是让它们直接面对你的生产数据库写SQL&#…...

Tailark部署指南:从开发到生产环境的完整流程
Tailark部署指南:从开发到生产环境的完整流程 【免费下载链接】cnblocks Shadcn marketing blocks 项目地址: https://gitcode.com/gh_mirrors/cn/cnblocks Tailark是一个专为现代营销网站打造的响应式组件库,基于shadcn/ui、Tailwind CSS和Next.…...

全景视频会议核心技术解析:从200°视场角到实时图像拼接
1. 项目概述:全景视频会议如何从概念走向现实视频会议这玩意儿,我们搞通信和消费电子这行的,这些年见得多了。从最早模糊不清的像素块,到后来高清但视角固定的摄像头,大家总觉得少了点什么。没错,少的就是那…...
)
思科路由器远程管理保姆级教程:从IP配置到Telnet/SSH登录全流程(避坑line vty和密码设置)
思科路由器远程管理全流程实战指南:从基础配置到安全登录 刚接触思科设备时,最让人头疼的莫过于那一连串看似晦涩的命令行操作。记得我第一次尝试配置路由器远程访问时,明明按照教程一步步操作,却始终无法通过Telnet连接ÿ…...

LoRa模块信号弱?可能是你的“射频快递”堵车了:深入Sx1262前端电路的信号处理流水线
LoRa模块信号弱?可能是你的“射频快递”堵车了:深入Sx1262前端电路的信号处理流水线 想象一下,你精心打包的快递包裹在运输途中被随意堆放、地址模糊不清,最终导致收件人无法正常签收——这正是许多LoRa模块信号问题的真实写照。当…...

MySQL 数据库基础入门:从概念到实战
前言:在程序开发中,数据存储是核心需求之一。虽然文件也能保存数据,但面对安全性、查询效率、海量存储等场景,文件存储的短板暴露无遗。而数据库作为专门的数据分析和管理工具,完美解决了这些问题,成为程序…...

QProcess::FailedToStart “No program defined“。qtcreator用的好好的,然后就不能调试了
点击 项目-》运行-》执行档根本原因:执行档:路径为空 解决办法:添加这样执行档 就有路径了。就可以用了...

Arm CoreLink CMN-600硬件错误解析与解决方案
1. Arm CoreLink CMN-600硬件错误深度解析在复杂SoC设计中,互连架构的质量直接决定整个系统的稳定性和性能。作为Arm Neoverse平台的核心组件,CoreLink CMN-600(Coherent Mesh Network)承担着处理器集群、内存控制器和I/O设备之间…...

社区团购系统源码推荐:为什么越来越多团队开始关注 LikeShop 社区团购系统?
如果你最近在研究:社区团购系统源码社区团购平台搭建团长分销系统私域社区团购社区自提系统你会发现一个现象:越来越多人开始提到:“LikeShop社区团购系统”。尤其是在:生鲜团购社区零售社群团购县域电商社区便利店私域卖货这些场…...