经典算法题总结:十大排序算法,外部排序和Google排序简介
十大排序算法
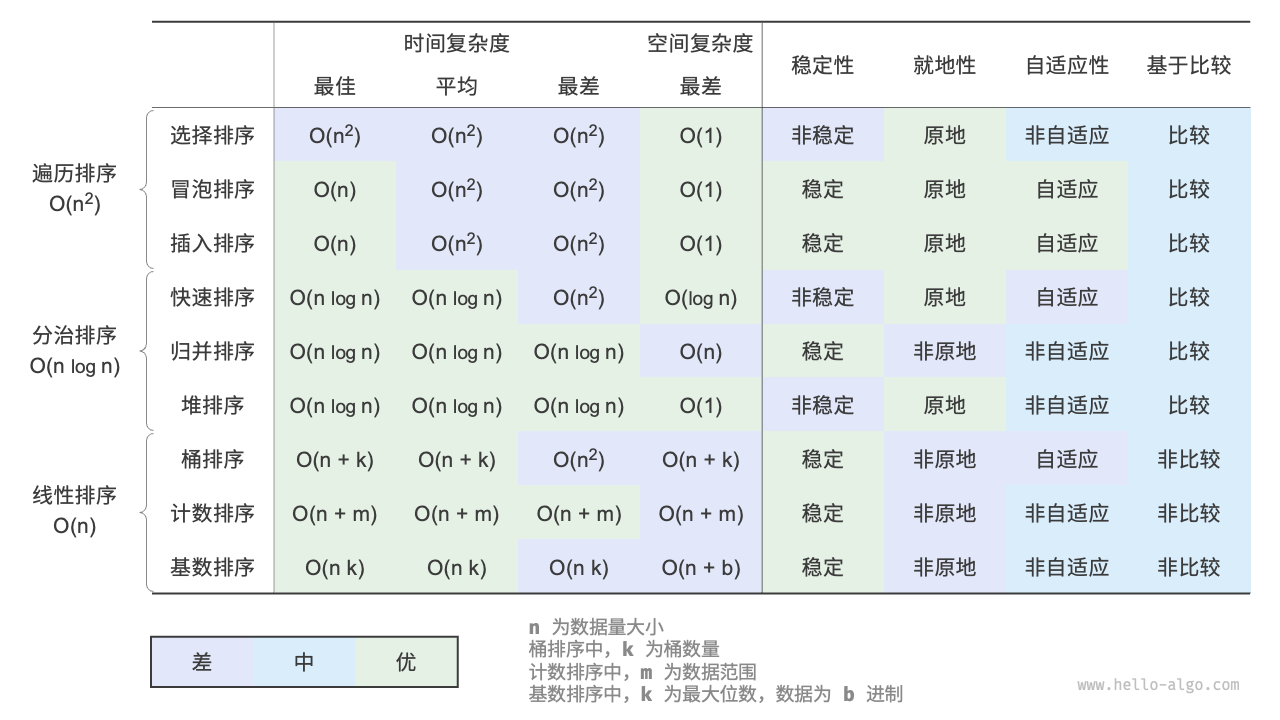
就地性:顾名思义,原地排序通过在原数组上直接操作实现排序,无须借助额外的辅助数组,从而节省内存。通常情况下,原地排序的数据搬运操作较少,运行速度也更快。
稳定性:稳定排序在完成排序后,相等元素在数组中的相对顺序不发生改变。
自适应性:自适应排序的时间复杂度会受输入数据的影响,即最佳时间复杂度、最差时间复杂度、平均时间复杂度并不完全相等。
基于比较的排序算法
常用排序
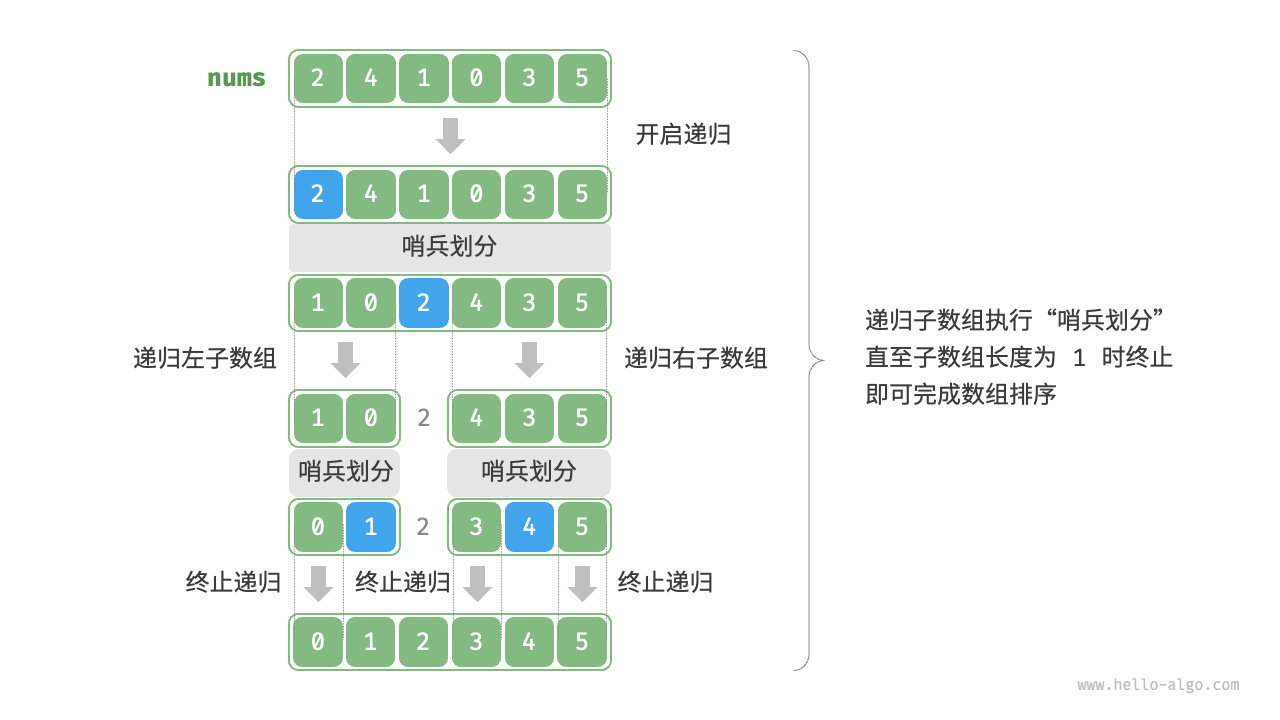
快速排序
快速排序(Quick Sort)是一种常用的高效的排序算法,它是一种基于比较的排序算法,利用了分治(自顶向下)的思想。快速排序的主要思想是选择一个基准元素,将数组分成两个子数组,一个子数组的所有元素都小于基准元素,另一个子数组的所有元素都大于基准元素,然后递归地对这两个子数组进行排序,最后将它们合并起来。
快速排序的基本步骤如下:
- 选择基准元素:从数组中选择一个元素作为基准(pivot)元素。选择合适的基准元素可以影响算法的性能。
- 划分:将数组中的其他元素与基准元素进行比较,将小于基准元素的元素放在左边,大于基准元素的元素放在右边。最终基准元素将位于其正确的位置,左边是小于它的元素,右边是大于它的元素。
- 递归:递归地对左右两个子数组进行快速排序。
快速排序的平均时间复杂度为O(N * logN),其中N是待排序数组的长度。然而,在最坏情况下,如果选择的基准元素始终是数组中的最小或最大元素,快速排序的时间复杂度可能达到O(N^2),但这种情况相对较少出现。快速排序的实际性能通常比其他基于比较的排序算法好,尤其在大规模数据集上。
优化方案:选择基准元素(随机化(常用),三数取中法),双指针(三向划分)快速排序,小规模子数据使用插入排序。
在快速排序中,如果每次选择基准元素都是数组中的最小或最大元素,那么每次分割都会将数组分成一个元素和 N - 1 个元素的子数组,导致算法的时间复杂度退化为 O(N^2)。随机选择基准元素可以降低这种最坏情况发生的概率,从而避免退化。
import java.util.Random;/*** 随机化基准元素优化快速排序*/
public class QuickSort {private Random random = new Random();public int[] sortArray(int[] nums) {if (nums == null || nums.length < 2) {return nums;}quickSort(nums, 0, nums.length - 1);return nums;}private void quickSort(int[] nums, int low, int high) {// 边界情况if (low >= high) {return;}// 自上而下递归根据基准元素进行划分子数组int pivot = partition(nums, low, high);quickSort(nums, low, pivot - 1);quickSort(nums, pivot + 1, high);}private int partition(int[] nums, int low, int high) {// 随机化基准元素,避免基本有序情况下的不平衡划分,将基准元素移到当前子数组的起始位置int randomIndex = low + random.nextInt( high - low + 1);int pivot = nums[randomIndex];nums[randomIndex] = nums[low];nums[low] = pivot;// 双指针遍历后,数组基准元素位置左边小于基准元素,右边大于基准元素while (low < high) {while (low < high && nums[high] > pivot) {high--;}nums[low] = nums[high];while (low < high && nums[low] < pivot) {low++;}nums[high] = nums[low];}nums[low] = pivot;return low;}}通常快速排序的效率更高,主要有以下原因:
- 出现最差情况的概率很低:虽然快速排序的最差时间复杂度为 O(N^2),没有归并排序稳定,但在绝大多数情况下,快速排序能在 O(N * logN) 的时间复杂度下运行。
- 缓存使用效率高:在执行哨兵划分操作时,系统可将整个子数组加载到缓存,因此访问元素的效率较高。而像“堆排序”这类算法需要跳跃式访问元素,从而缺乏这一特性。
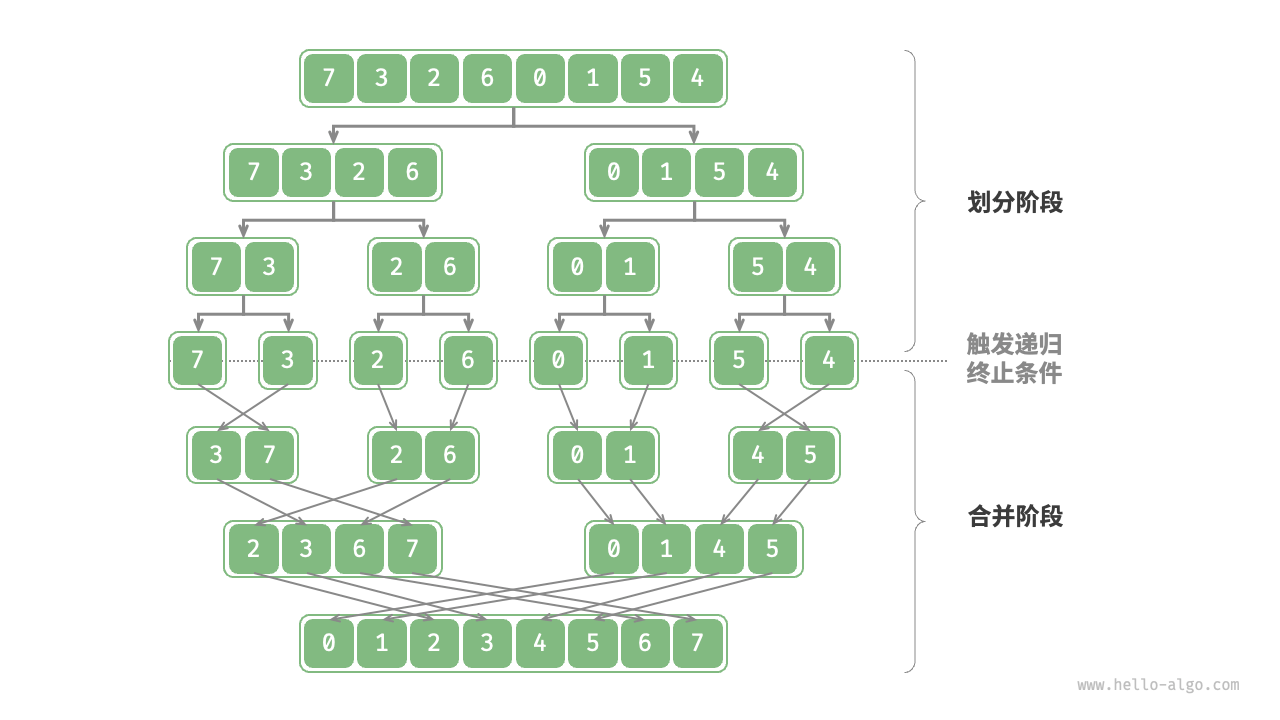
归并排序
归并排序(Merge Sort)是一种基于分治(自底向上)的排序算法,它的主要思想是将一个未排序的数组划分为两个子数组,分别对这两个子数组进行排序,然后再将排好序的子数组合并成一个有序数组。归并排序的关键步骤在于"合并"操作,这是通过将两个已排序的子数组按照顺序合并而实现的。
归并排序的过程可以分为以下几个步骤:
- 分解:将待排序的数组分成两个子数组,通常是将数组分成相等大小的两部分,直到每个子数组的大小为1或0为止,因为一个元素的数组是有序的。
- 排序:对每个子数组进行递归地排序。这个步骤通过将问题逐步分解为更小的子问题,直到达到基本情况(即单个元素的数组),然后逐步合并子问题的解来实现排序。
- 合并:将已排序的子数组合并为一个有序数组。这是归并排序的核心步骤,它通过比较两个子数组中的元素,并按照顺序将它们合并到一个新的数组中,直到所有元素都被合并。
归并排序具有稳定性,即相等元素的顺序在排序后仍然保持不变。其时间复杂度为O(N * logN),其中N是数组的大小,这使得归并排序在大规模数据集上表现出色。然而,它需要额外的空间来存储临时数组,所以空间复杂度为O(N)。
/*** 归并排序*/
public class MergeSort {public int[] sortArray(int[] nums) {if (nums == null || nums.length < 2) {return nums;}mergeSort(nums, 0, nums.length - 1);return nums;}private void mergeSort(int[] nums, int left, int right) {// 边界情况if (left >= right) {return;}int mid = left + (right - left) / 2;// 自上而下分治mergeSort(nums, left, mid);mergeSort(nums, mid + 1, right);// 自下而上合并mergeArray(nums, left, mid, right);}private void mergeArray(int[] nums, int left, int mid, int right) {int[] helperArray = new int[right - left + 1];int leftPointer = left;int rightPointer = mid + 1;int i = 0; // 辅助数组索引while (leftPointer <= mid && rightPointer <= right) {helperArray[i++] = nums[leftPointer] < nums[rightPointer] ?nums[leftPointer++] : nums[rightPointer++];}while (leftPointer <= mid) {helperArray[i++] = nums[leftPointer++];}while (rightPointer <= right) {helperArray[i++] = nums[rightPointer++];}for (i = 0; i < helperArray.length; i++) {nums[left + i] = helperArray[i];}}}堆排序
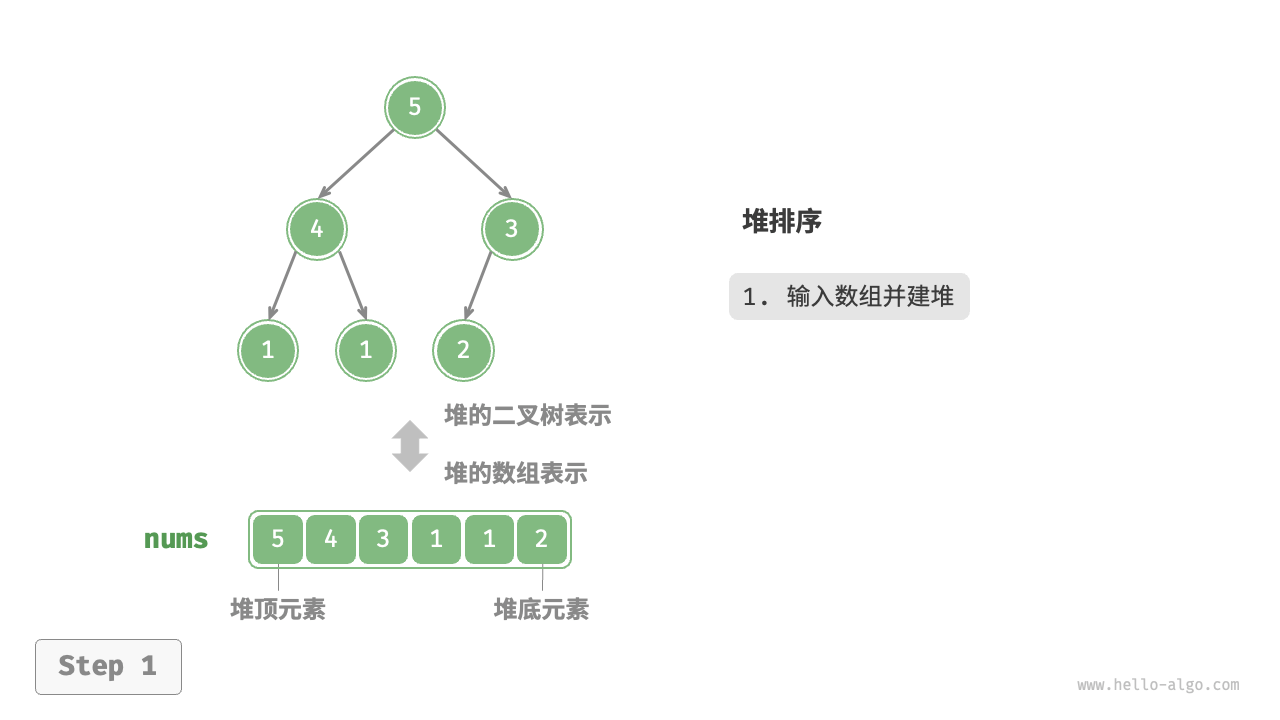
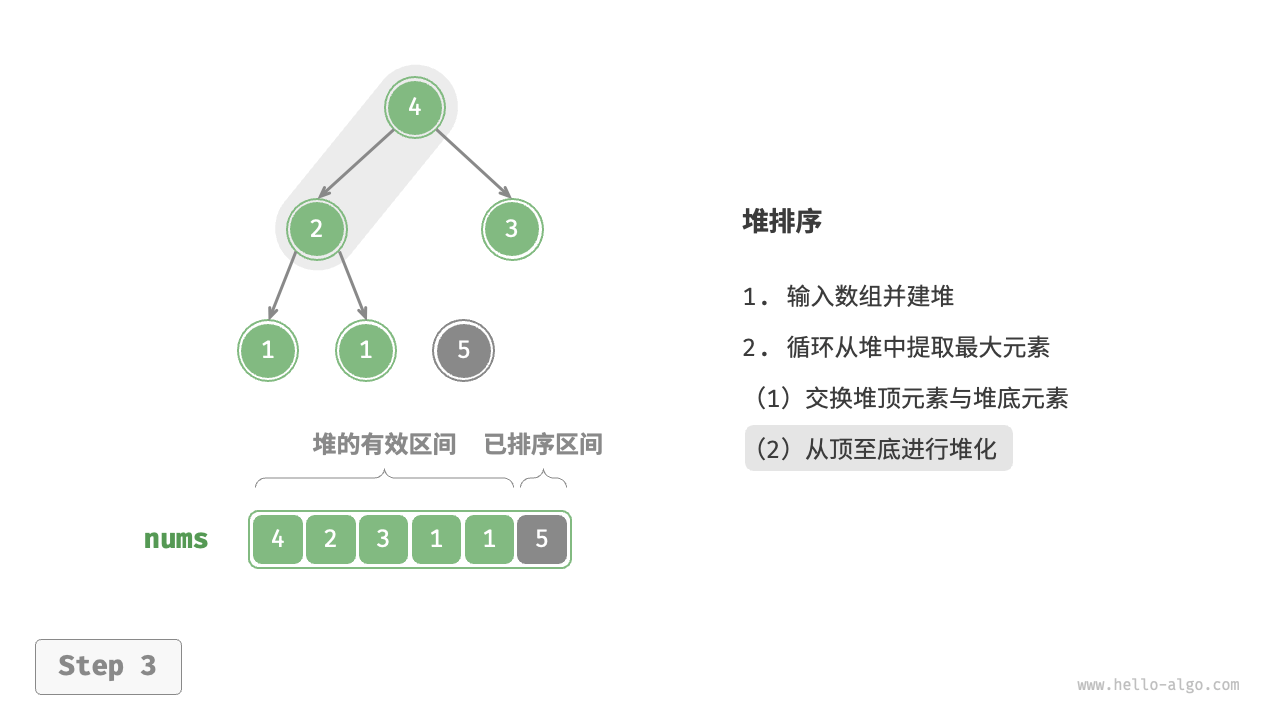
堆排序(Heap Sort)是一种基于二叉堆数据结构的排序算法,它是一种选择排序的一种改进,具有较好的时间和空间复杂度。堆是一种特殊的完全二叉树,分为最大堆和最小堆两种类型,其中最大堆要求父节点的值大于或等于子节点的值,最小堆要求父节点的值小于或等于子节点的值。
堆排序的基本思想:首先将待排序的数组构建成一个二叉堆(通常使用最大堆),出元素的时候将堆顶元素(即最大元素)与堆的最后一个元素交换,并从堆中移除,然后对剩余的元素重新调整为一个合法的堆,重复这个过程直到堆为空,得到一个有序的数组。
以下是堆排序的关键步骤:
- 构建最大堆:从最后一个非叶子节点开始,自底向上地将数组调整为一个最大堆(构建最大堆的时间复杂度是 O(N))。
- 交换堆顶元素和末尾元素:将堆顶元素与堆的最后一个元素交换,然后将堆的大小减一。
- 调整堆:从堆顶开始,通过逐级下沉(或上浮)操作将堆重新调整为最大堆。(调整堆的时间复杂度是O(logN))
- 重复步骤 2 和 3,直到堆为空。
Poor use of cache memory:平均时间上,堆排序的时间常数比快排要大一些,因此通常会慢一些,但是堆排序最差时间也是O(N * logN),这点比快排好。快排在递归进行部分的排序的时候,只会访问局部的数据,因此缓存能够更大概率的命中;而堆排序的建堆过程是整个数组各个位置都访问到的,后面则是所有未排序数据各个位置都可能访问到的,所以不利于缓存发挥作用。简单的说就是快排的存取模型的局部性更强,堆排序差一些。
/*** 堆排序* 非叶子节点:在完全二叉树中,所有非叶子节点的索引都在 0 到 n / 2 - 1 之间,其中 n 是数组的长度。* 叶子节点:叶子节点是树的最底层节点,没有子节点。在完全二叉树中,从 n / 2 到 n - 1 的节点都是叶子节点。*/
public class HeapSort {public int[] sortArray(int[] nums) {if (nums == null || nums.length < 2) {return nums;}int n = nums.length;// 从最后一个非叶子节点自下而上进行调整for (int i = n / 2 - 1; i >= 0; i--) {heapify(nums, n, i);}for (int i = n - 1; i >= 0; i--) {swap(nums, 0, i);heapify(nums, i, 0);}return nums;}/*** 堆化方法,维护堆的性质* @param nums 数组表示的堆* @param n 堆的大小* @param i 当前需要堆化的节点的索引*/private void heapify(int[] nums, int n, int i) {int largest = i;int left = 2 * i + 1; // 左子节点的索引int right = 2 * i + 2; // 右子节点的索引if (left < n && nums[left] > nums[largest]) {largest = left;}if (right < n && nums[right] > nums[largest]) {largest = right;}if (largest != i) {swap(nums, largest, i);heapify(nums, n, largest);}}private void swap(int[] nums, int i, int j) {int temp = nums[i];nums[i] = nums[j];nums[j] = temp;}}排序算法:堆排序【图解+代码】
低级排序
冒泡排序
public class BubbleSort {// 冒泡排序public void bubbleSort(int[] arr) {if (arr == null || arr.length < 2) {return;}for (int i = arr.length - 1; i > 0; i--) {for (int j = 0; j < i; j++) {if (arr[j] > arr[j + 1]) {swap(arr, j, j + 1);}}}}}我们发现,如果某轮“冒泡”中没有执行任何交换操作,说明数组已经完成排序,可直接返回结果。因此,可以增加一个标志位 flag 来监测这种情况,一旦出现就立即返回。
public class BubbleSort {public int[] sortArray(int[] nums) {if (nums == null || nums.length < 2) {return nums;}boolean flag; // 标志该轮循环数组是否已经有序for (int i = nums.length - 1; i > 0; i--) {flag = true;for (int j = 0; j < i; j++) {if (nums[j] > nums[j + 1]) {swap(nums, i, j);flag = false;}}if (flag) {break;}}return nums;}private void swap(int[] nums, int i, int j) {int temp = nums[i];nums[i] = nums[j];nums[j] = temp;}}选择排序
public class SelectionSort {public void selectionSort(int[] arr) {if (arr == null || arr.length < 2) {return;}for (int i = 0; i < arr.length - 1; i++) {int minIndex = i;// 在未排序部分找到最小值的索引for (int j = i + 1; j < arr.length; j++) {minIndex = arr[j] < arr[minIndex] ? j : minIndex;}// 将最小值交换到已排序部分的末尾swap(arr, i, minIndex);}}}直接插入排序
public class InsertionSort {// 插入排序,比较有效地排序方法public void insertionSort(int[] arr) {if (arr == null || arr.length < 2) {return;}for (int i = 1; i < arr.length; i++) {// [0, i) 范围内有序,这里的 i 是要比较的元素位置for (int j = i - 1; j >= 0 && arr[j] > arr[j + 1]; j--) {swap(arr, j, j + 1);}}}}尽管插入排序的时间复杂度更高,但在数据量较小的情况下,插入排序通常更快(递归的栈空间的消耗)。
插入排序在时间复杂度的常数因素上比冒泡排序和选择排序更小:
- 较少的交换操作:插入排序在排序过程中,通常需要较少的交换操作。每次插入一个元素时,只需将其与前面已排序部分进行比较,然后移动这些元素,而不是每次都交换元素的位置。相对于冒泡排序来说,冒泡排序每次比较后都可能进行交换操作,交换操作的次数较多,效率较低。
- 较少的比较操作:插入排序在每次插入时,会逐步将元素插入到正确位置,而不像冒泡,选择排序那样需要反复遍历数组来找到未排序部分的最小元素。
希尔排序
希尔排序(Shell Sort)是一种插入排序的一种改进,它通过将数组分成若干个子序列来进行排序,逐步减小子序列的长度,最终完成排序。希尔排序的核心思想是将间隔较大的元素先排好序,然后逐步减小间隔,直到间隔为1,最后进行一次插入排序。
希尔排序的步骤:
- 选择一个增量序列(也称为间隔序列),常用的增量序列有希尔增量、Hibbard增量和Sedgewick增量等。
- 根据增量序列将数组分成若干个子序列,对每个子序列进行插入排序。
- 逐步减小增量,重复步骤 2,直到增量为1,此时进行一次完整的插入排序,完成排序。
希尔增量序列:最希尔增量是最简单的增量序列,其取值为 N / 2,每次递减一半,直到增量为1。其中,N 是数组的长度。最坏时间复杂度 O(N^2),平均时间复杂度 O(N^1.3)~O(N^1.5)。
Hibbard增量序列:Hibbard增量序列采用 2^k - 1(k 为非负整数)作为增量。Hibbard增量的性能较好,但在实际应用中可能并不总是最优。最坏时间复杂度O(N^3/2),平均时间复杂度O(N^5/4)。
Sedgewick增量序列:Sedgewick增量序列通过 4^k + 3 * 2^(k-1) 和 2^(k+2) * (2^(k+2) - 3) + 1 两种增量交替使用,最坏时间复杂度O(N^(4/3)),平均时间复杂度 O(N^(7/6))。
基于比较的排序算法时间复杂度下限证明
经过k次比较最多能区分的序列个数是2^k,如果有M种序列,需要logM次比较才能区分出大小。那有N个元素的数组有 N! 种排序可能,需要logN!次比较才能区分出大小,使用斯特林公式可知最低复杂度是N * logN。

排序算法会出现不稳定的状态原因
比较操作不考虑相等情况:许多排序算法是基于比较操作的,它们只考虑元素的大小关系,而不考虑相等情况。当两个元素的大小相等时,排序算法可能会交换它们的位置,从而破坏了它们在原始序列中的相对顺序,导致排序结果不稳定。
基于非比较的排序算法
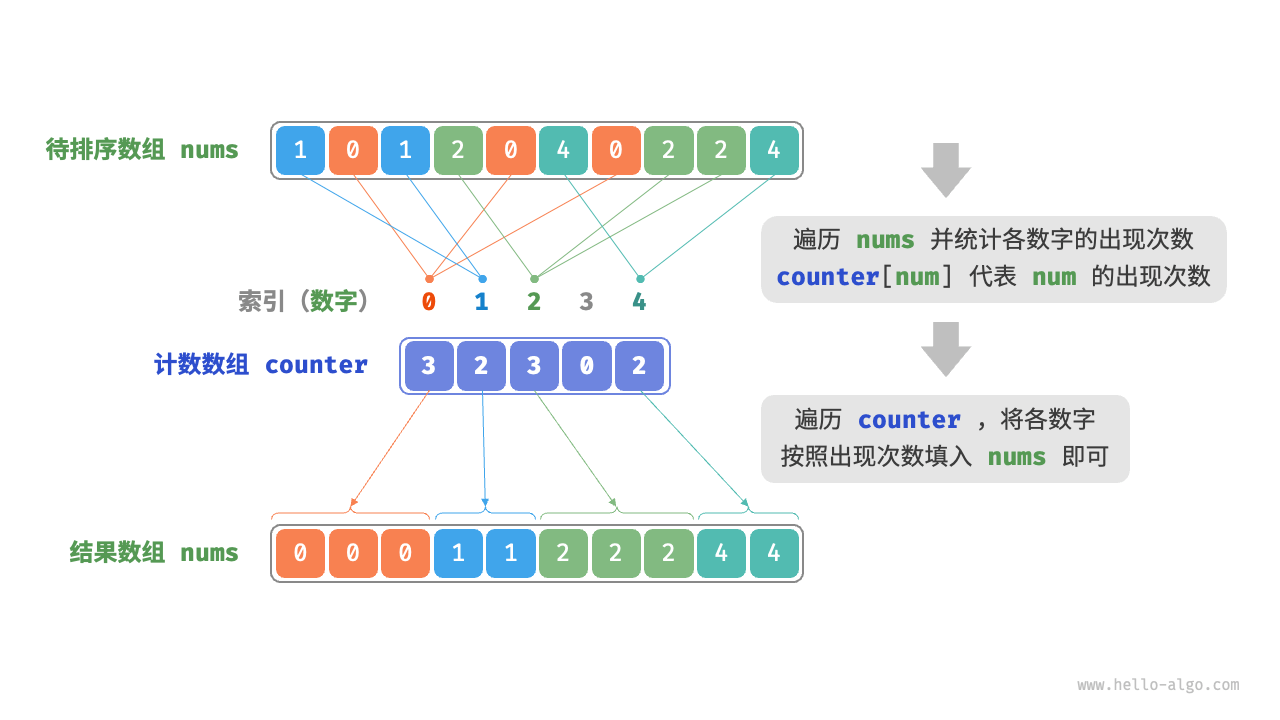
计数排序
计数排序适用于待排序元素的范围比较小且非负整数的情况。它的基本思想是,统计每个元素出现的次数,然后根据统计信息构建有序的结果序列。
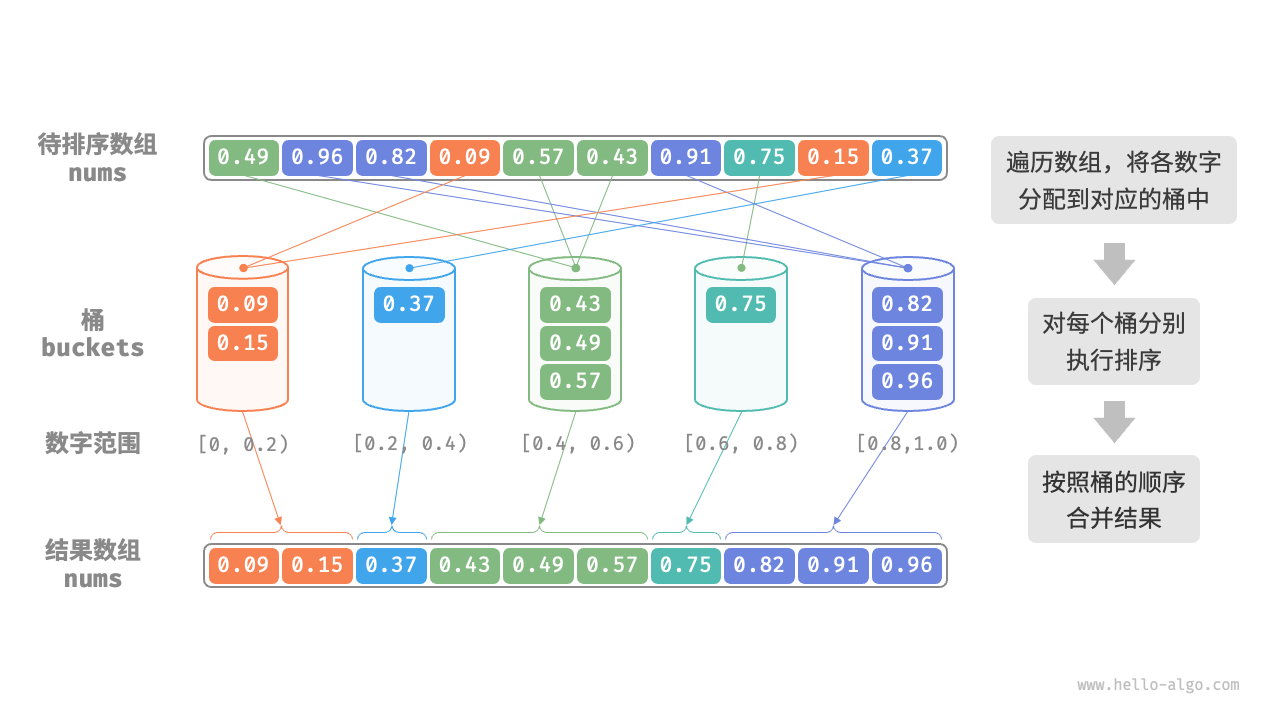
桶排序
桶排序适用于待排序元素服从均匀分布的情况,它将待排序元素划分为一定数量的桶,然后对每个桶内的元素进行排序,最后将排序后的桶依次合并成有序的结果。
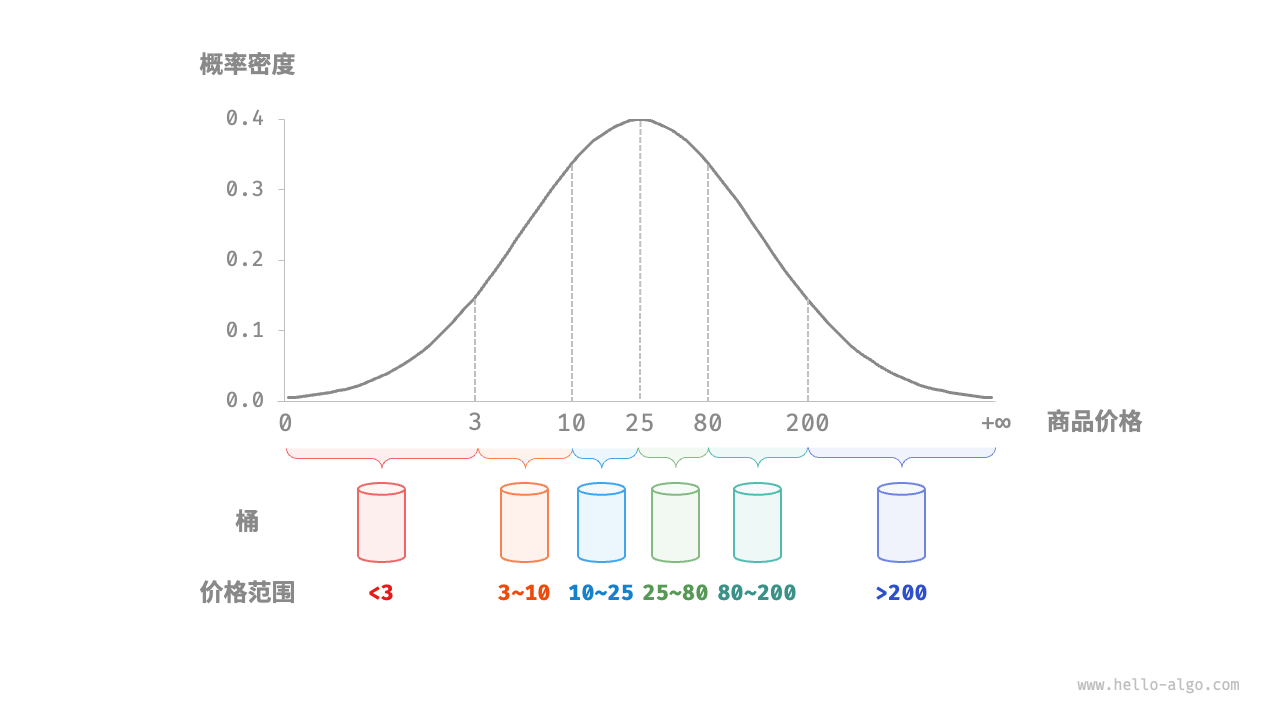
桶排序的时间复杂度理论上可以达到 O(N),关键在于将元素均匀分配到各个桶中,因为实际数据往往不是均匀分布的。为实现平均分配,我们可以先设定一条大致的分界线,将数据粗略地分到 3 个桶中。分配完毕后,再将商品较多的桶继续划分为 3 个桶,直至所有桶中的元素数量大致相等。
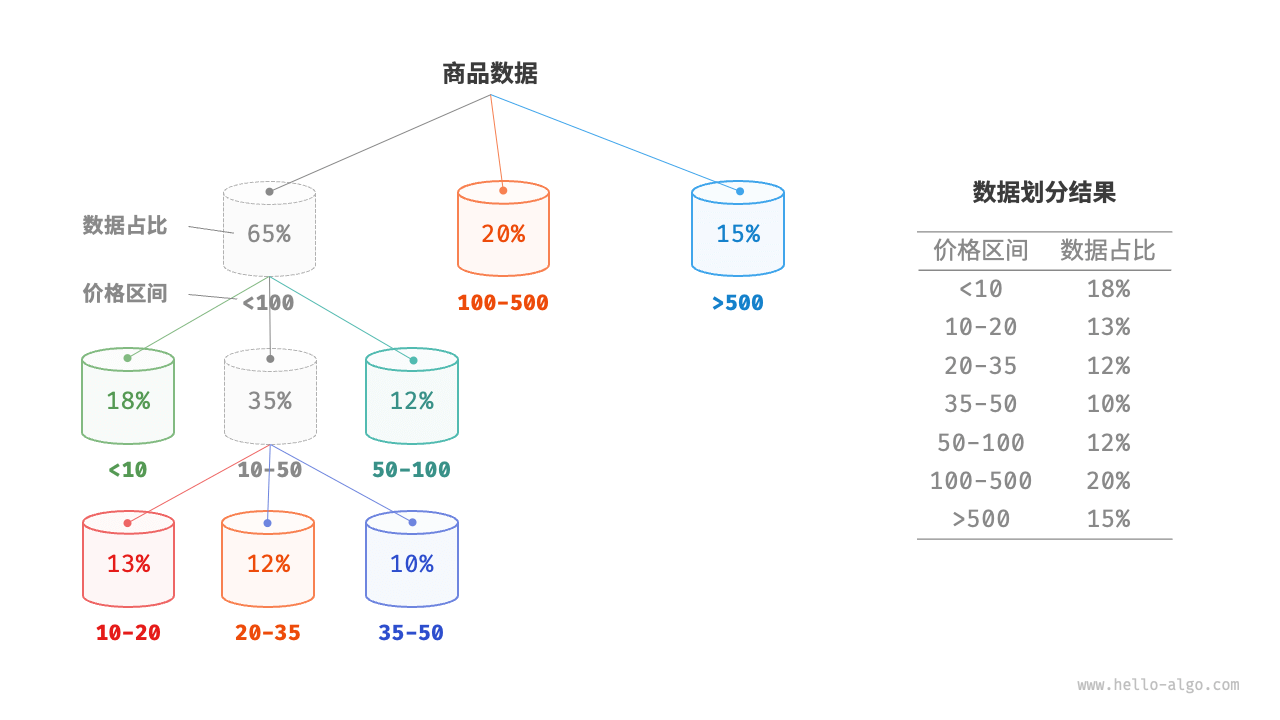
如果我们提前知道商品价格的概率分布,则可以根据数据概率分布设置每个桶的价格分界线。值得注意的是,数据分布并不一定需要特意统计,也可以根据数据特点采用某种概率模型进行近似。
基数排序
基数排序是一种非比较的排序算法,它适用于整数或字符串等具有固定位数的元素。基数排序的基本思想是将待排序的元素从低位到高位依次进行排序,以实现整体的排序。具体来说,基数排序将元素按照各个位上的值进行桶排序,从最低位到最高位依次进行,最终得到有序的结果。
思考:如何实现在 O(1) 时间复杂度的排序算法?
可以对有限的数字范围内的元素建立一个大哈希表,直接进行映射。
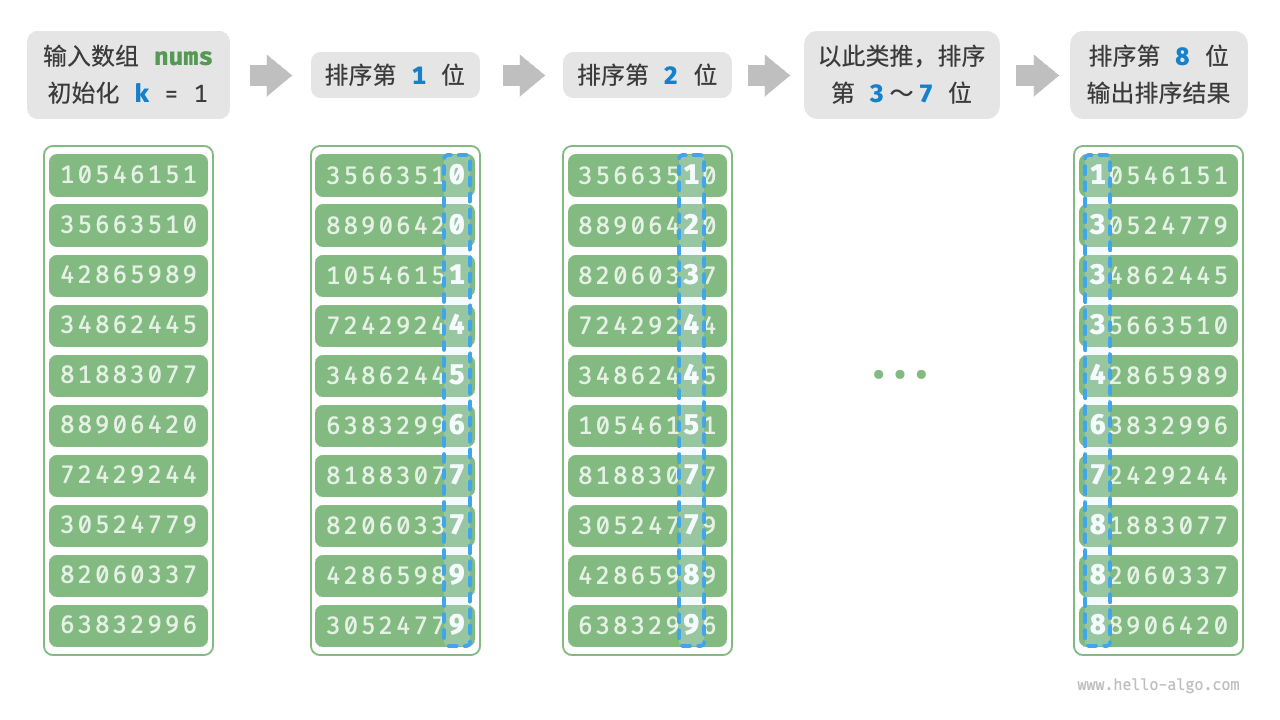
延伸:JDK 中的排序:Arrays.sort 的源码实现
| 数组长度 | 所使用的排序算法 |
| length < 47 | 插入排序 |
| 47 <= length < 286 | 快速排序 |
| length >= 286 且数组基本有序 | 归并排序 |
| length >= 286 且数组基本无序 | 快速排序 |
基本有序的判断方法:逆序对计数法。
延伸:Google 是如何做到如此快的速度对关键词网页进行高质量排序
Google 之所以能够实现如此快速的搜索结果排序,是因为其搜索引擎背后运用了一系列高效的技术和算法。以下是一些关键因素:
- 索引技术: Google 使用了高度优化的索引技术,例如倒排索引(Inverted Indexing)。这使得系统能够快速定位包含特定关键词的网页,而不需要遍历整个数据集;
- PageRank 算法: Google 的搜索排序算法中,PageRank 算法是一个关键的组成部分。PageRank 基于网页之间的链接关系来评估网页的重要性。这使得搜索结果更加倾向于显示具有高质量内容和受欢迎的网页;
- 分布式计算: Google 的搜索系统是基于大规模的分布式计算架构构建的。这意味着搜索索引和计算是分布在多台服务器上完成的,可以并行处理大量的数据。采用分布式计算可以显著提高搜索速度;
- 机器学习: Google 使用机器学习技术来不断改进搜索排序。通过分析用户的搜索行为、点击模式以及网页的内容,机器学习模型可以自动调整搜索结果的排序,以提供更符合用户需求的结果。
需要注意的是,Google 搜索引擎的高速度是整个系统综合运作的结果,包括硬件、分布式架构、算法优化等多个方面。这种高效性是通过多年来不断的研究和工程实践来实现的。
延伸:外部排序算法
外部排序算法用于处理不能完全装入内存的大型数据集。由于数据量超出了内存容量,需要借助外存(如磁盘)进行排序。外部排序算法的主要思想是将数据分成适当大小的块,逐块排序后再进行合并。以下是外部排序的基本步骤:
分块:假设有一个非常大的数据集,需要对其进行排序,但内存有限。首先,将数据集分成若干个块,每个块的大小应能在内存中完全处理。
- 从数据集中读取一个块的数据到内存中。
- 对该块进行内部排序。
- 将排序后的块写回外存。
- 重复上述步骤,直到所有数据块都已排序并写回外存。
多路归并排序:假设已经有n个排序后的数据块,现在需要将它们合并成一个整体的有序数据集。这一步使用多路归并排序来完成。
- 从每个已排序的块中选取第一个元素,构建一个最小堆。
- 将堆顶元素(最小的元素)输出到最终的有序输出文件中,并从相应的块中读取下一个元素,替换堆顶元素,并调整堆以维持最小堆性质。
- 重复步骤2,直到所有块中的所有元素都已处理完毕。
相关文章:
经典算法题总结:十大排序算法,外部排序和Google排序简介
十大排序算法 就地性:顾名思义,原地排序通过在原数组上直接操作实现排序,无须借助额外的辅助数组,从而节省内存。通常情况下,原地排序的数据搬运操作较少,运行速度也更快。 稳定性:稳定排序在完…...

服务器是什么?怎么选择适合自己的服务器?
在这个数字化的世界中,我们每天都在与各种网站打交道,浏览新闻、购物、看视频等。你是否曾经好奇过,这些网站是如何运行的?它们又是如何实现随时随地可访问的呢? 在这背后,有一个神秘的角色在默默地支撑着…...

区块链技术的应用场景
区块链技术是一种分布式数据库或公共分类账的形式,它保证了数据的完整性和透明性。它最初是为了支持比特币这种加密货币而被发明的,但现在已经被广泛应用于多种领域,包括供应链管理、投票系统、数字身份验证等。 基本概念 区块 (Block) 区块…...

凤凰端子音频矩阵应用领域
凤凰端子音频矩阵,作为一种集成了凤凰端子接口的音频矩阵设备,具有广泛的应用领域。以下是其主要应用领域: 一、专业音响系统 会议系统:在会议室中,凤凰端子音频矩阵能够处理多个话筒和音频源的信号,实现…...

LeetCode-字母异位词分组
题目描述 给你一个字符串数组,请你将 字母异位词 组合在一起。可以按任意顺序返回结果列表。 字母异位词 是由重新排列源单词的所有字母得到的一个新单词。 示例 1: 输入: strs ["eat", "tea", "tan", "ate", "na…...

《Linux运维总结:基于x86_64架构CPU使用docker-compose一键离线部署etcd 3.5.15容器版分布式集群》
总结:整理不易,如果对你有帮助,可否点赞关注一下? 更多详细内容请参考:《Linux运维篇:Linux系统运维指南》 一、部署背景 由于业务系统的特殊性,我们需要面对不同的客户部署业务系统࿰…...

WPF动画
补间动画:动画本质就是在一个时间段内对象尺寸、位移、旋转角度、缩放、颜色、透明度等属性值的连续变化。也包括图形变形的属性。时间、变化的对象、变化的值 工业应用场景:蚂蚁线、旋转、高度变化、指针偏移、小车 WPF动画与分类 特定对象处理动画过…...

大数据系列之:统计hive表的详细信息,生成csv统计表
大数据系列之:统计hive表的详细信息,生成csv统计表 一、获取源数据库、源数据库类型、hive数据库名称二、获取hive数据库名、hive表名、数仓层级、空间、维护者信息三、统计hive表信息四、统计源库信息五、合并hive表信息六、生成csv统计表七、完整代码一、获取源数据库、源数…...

flutter 画转盘
import package:flutter/material.dart; import dart:math;const double spacingAngle 45.0; // 每两个文字之间的角度 // 自定义绘制器,ArcTextPainter 用于在圆弧上绘制文字 class ArcTextPainter extends CustomPainter {final double rotationAngle; // 动画旋…...

图像识别,图片线条检测
import cv2 import numpy as np # 读取图片 img cv2.imread(1.png)# 灰度化 gray cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)# 边缘检测 edges cv2.Canny(gray, 100, 200) 当某个像素点的梯度强度低于 threshold1 时,该像素点被认为是非边缘;当梯度强度…...

python crawler web page
npm install or pip install 插件 import json import time from openpyxl import load_workbook from pip._vendor import requests from bs4 import BeautifulSoup import pandas as pd import re import xlsxwriter 設置request header header {user-agent: Mozilla/5.0…...

基于QT实现的TCP连接的网络通信(客户端)
上篇介绍了QT实现网络通信的服务器端,还没看服务器的朋友们先去上篇了解,这篇我来实现一下客户端的实现。 首先还是新建一个项目 选择mainwindow类 在通信前将.pro文件的第一行代码中追加network 窗口搭建 在mainwindow.ui中完成一下窗口的搭建 首先在…...

Vue2中watch与Vue3中watch对比
上一节说到了 computed计算属性对比 ,虽然计算属性在大多数情况下更合适,但有时也需要一个自定义的侦听器。这就是为什么 Vue 通过 watch 选项提供了一个更通用的方法,来响应数据的变化。当需要在数据变化时执行异步或开销较大的操作时&#…...

Web 3 一些常见术语
目录 Provider 提供者Signer 签名者Transaction 交易Contract 合约Receipt 收据 首先,从高层次上对可用对象的类型及其负责的内容有一个基本的了解是很有用的。 Provider 提供者 一个 Provider 是与区块链的只读连接,允许查询区块链状态,例…...

揭开数据分析中的规范性分析:从入门到精通
目录 引言1. 规范性分析的基本概念2. 规范性分析的方法论2.1 线性规划:资源利用最大化2.2 决策树分析:直观的选择路径2.3 贝叶斯网络:应对不确定性的利器2.4 多目标优化:平衡多重目标的艺术 3. 规范性分析的实际应用3.1 商业决策中…...

Linux文件IO
目录 前言 一.文件操作 系统调用接口 1.打开文件 2.关闭文件 3.读取文件 4.写入文件 二.文件描述符 重定向 三.动静态库 前言 在Linux操作系统中,文件I/O是一个核心概念,涉及如何读写文件、与设备通信以及如何管理数据流。Linux下一切皆文件, …...
)
ccfcsp-202309(1、2、3)
202309-1 坐标变换(其一) #include <bits/stdc.h> using namespace std; int main() {ios::sync_with_stdio(false);cin.tie(0);cout.tie(0);int n, m;cin >> n >> m;int x, y;int opx 0, opy 0;for(int i 0; i < n; i){cin &g…...

数据结构--数据结构概述
一、数据结构三要素 1. 数据的逻辑结构 数据的逻辑结构是指数据元素之间的关系和组织方式,通常分为线性结构和非线性结构。 线性结构:例如线性表,其中数据元素按照顺序排列,彼此之间存在一对一的关系。 非线性结构:…...

Spring中的BeanFactoryAware
BeanFactoryAware 是 Spring 框架中的一个接口,用于在 Spring 容器中获取 BeanFactory 实例。实现这个接口的类可以在其属性被设置后获取到 BeanFactory,从而可以访问 Spring 容器中的其他 bean。 BeanFactoryAware 接口概述 BeanFactoryAware 接口位于…...

Neo4j service is not installed
问题: Starting Neo4j. Neo4j service is not installed Unable to start. See user log for details. Run with --verbose for a more detailed error message.解决: neo4j windows-service install neo4j start ok了...

半导体设备投资热潮:千亿美元流向、产业逻辑与工程师应对策略
1. 从百亿投资狂潮看半导体制造的底层逻辑最近和几个在晶圆厂和Fab设备商工作的老朋友聊天,话题总绕不开一个词:投资。无论是台积电、三星的先进制程军备竞赛,还是中芯国际、联电的成熟制程扩产,背后都是一台台价值数千万甚至上亿…...

移动通信浪潮如何重塑半导体产业格局:从高通与英特尔市值对比说起
1. 从市场估值看产业浪潮:移动通信如何重塑半导体格局2013年春天,一则消息在半导体和投资圈内引发了不小的震动:无线通信芯片巨头高通(Qualcomm)的市值,悄然与行业传统霸主英特尔(Intel…...

上网行为怎么监控?教你五个简单实用的上网行为监控方法,建议收藏
在数字化办公时代,企业管理面临着新的挑战:一方面需要网络提供资讯和工具,另一方面,无节制的非工作上网行为正在侵蚀企业的生产力。如何科学、合理地监控上网行为?以下为您介绍五个监控方法,涵盖了从硬件到…...
)
用微信小程序点灯!STC89C51+ESP8266物联网入门实战(附完整源码)
用微信小程序点灯!STC89C51ESP8266物联网入门实战(附完整源码) 当你第一次看到手机上的按钮能控制真实世界的灯泡时,那种"魔法成真"的震撼感,正是物联网的魅力所在。本文将带你用不到百元的硬件成本…...

2026最权威的十大AI辅助论文工具实测分析
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 要降低AIGC也就是人工智能生成内容的检测率,关键之处在于减少机器生成的痕迹,还要增加文本的…...

用AI写论文怎么不被判AI?写作prompt+降AI工具双层防御攻略!
用AI写论文怎么不被判AI?写作prompt降AI工具双层防御攻略! 用 AI 写论文最稳的姿势是「双层防御」——写作端用降 AI 提示词预防(0 成本但有能力上限) 写完用降 AI 工具兜底(4.8 元/千字双降到位)。 这两…...

NemoClaw资源导航:从Awesome列表构建到高效使用指南
1. 项目概述:一个为“NemoClaw”而生的资源宝库 如果你正在寻找一个关于“NemoClaw”的、经过筛选和整理的高质量资源集合,那么你很可能已经听说过或者正在寻找 VoltAgent/awesome-nemoclaw 这个项目。在开源世界里,以 awesome- 为前缀的…...

【信息科学与工程学】【通信工程】第四十三篇 骨干网方案设计-02跨境网络
一、方案 1.1 整体方案设计概要 设计的云网融合方案,综合考虑其全球互联需求、安全合规性、性能优化及跨国运营挑战: 1.1.1、需求分析 网络互联需求: 国内互通: 安全、稳定、低延迟连接中国大陆(严格合规要求)。 国际互通: 高性能连接美国(东西海…...

AMBA 3 AXI协议架构解析与工程实践
1. AMBA 3 AXI协议架构解析AMBA 3 AXI协议作为ARM推出的第三代高级可扩展接口,其架构设计充分考虑了现代SoC对高带宽和低延迟的核心需求。与传统的AMBA 2 AHB协议相比,AXI通过五项关键技术革新实现了性能的质的飞跃:1.1 五通道分离式架构AXI协…...

用LDAP Browser连接OpenLDAP时,这3个配置细节坑了我一整天
用LDAP Browser连接OpenLDAP时,这3个配置细节坑了我一整天 第一次用LDAP Browser连接OpenLDAP服务器时,我本以为照着教程五分钟就能搞定,结果硬是折腾了一整天。明明服务端已经正常启动,客户端工具也装好了,但就是连不…...