Python爬虫与数据分析:中国大学排名的深度挖掘
前言
👉 小编已经为大家准备好了完整的代码和完整的Python学习资料,朋友们如果需要可以扫描下方CSDN官方认证二维码或者点击链接免费领取【保证100%免费】

一、选题背景
高考作为中国学生生涯中最为重要的事,在高考之后,选择一所好的大学则是接下的人生的一块的敲门砖,选择有着好的大学,和有着良好教育氛围的城市以及所选择的大学近年来的变化是很重要的事,在以前,想要了解这些需要翻阅查找大量的资料,而现在我们可以通过python轻易地了解这些。
二、爬虫方案设计
1.方案名称:
中国大学年排名变化数据与可视化分析
2.爬取的内容与数据特征分析:
通过网站收录的中国大学截止到2019年的排名(因为2020到2021年的疫情对排名变化)
3. 方案概述
分析网站页面结构,找到爬取数据的位置,根据不同的数据制定不同的爬取方法
三、网站页面结构分析
1.网页页面的结构与特性分析
通过浏览器“审查元素”查看源代码及“网络”反馈

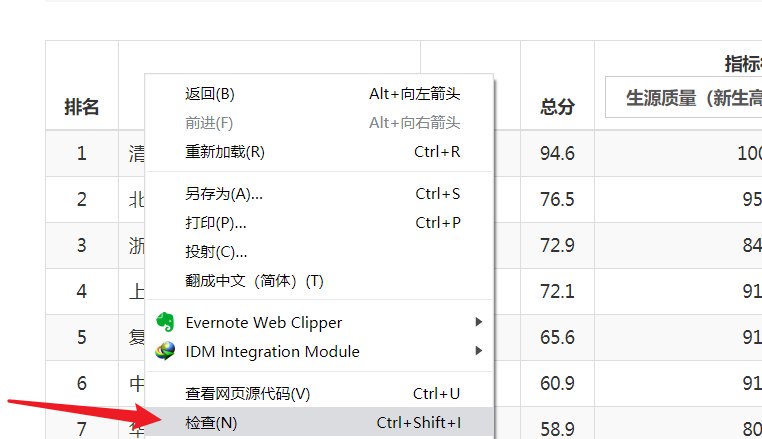
可以看到每一个 tr 里面都有一行数据,这就是所需要的数据,通过 contents 获取标签对里面的数据。

四、爬虫程序设计
1. 数据的爬取
import requests
from lxml import html
def Tree(url):req = requests.get(url)req.encoding ='utf-8-sig'allUniv = []tree = html.fromstring(req.text)trs = tree.xpath('//tbody/tr')for tr in trs:tds = tr.xpath('td')if tds == 0:continueoneUniv=[]oneUniv.append(tds[0].text)name = tds[1].xpath('div')oneUniv.append(name[0].text)for td in tds[2:]:oneUniv.append(td.text)allUniv.append(oneUniv)return allUnivurl='http://www.zuihaodaxue.cn/zuihaodaxuepaiming2019.html'
tree=Tree(url)
print("排名 学校名称 省市 总分")
for i in range(20):print(tree[i][0],tree[i][1],tree[i][2],tree[i][3],sep=' ')from bs4 import BeautifulSoup
def Req(url):req=requests.get(url)req.encoding='utf-8-sig'allUniv=[]soup=BeautifulSoup(req.text,"html.parser")trs=soup.find_all('tr')for tr in trs:tds=tr.find_all('td')if len(tds)==0:continueoneUniv=[]for td in tds:oneUniv.append(td.string)allUniv.append(oneUniv)return allUnivallUniv1=Req(url)
print("排名 学校名称 省市 总分")
for i in range(20):print(allUniv1[i][0],allUniv1[i][1],allUniv1[i][2],allUniv1[i][3],sep=' ')import matplotlib.pyplot as plt
plt.rcParams["font.sans-serif"]=["SimHei"]
name=[]
sorce=[]
for i in range(10):name.append(allUniv1[i][1])sorce.append(float(allUniv1[i][3]))
plt.barh(range(len(sorce)),sorce,tick_label=name)
plt.title("2019年排名前十位的大学及其总分")
plt.xlabel('分数')
plt.show()from collections import Counter
province=[]
for i in range(len(allUniv1)):province.append(allUniv1[i][2])
result=Counter(province)
print(result)2.数据简单分析且可视化
(1)绘制饼状图
import matplotlib as mpl
mpl.rcParams["font.sans-serif"]=["SimHei"]
mpl.rcParams["axes.unicode_minus"]=False
plt.pie(result.values(),labels=result.keys(),radius=2)
plt.title("各省份大学数量占比饼状图")
plt.show()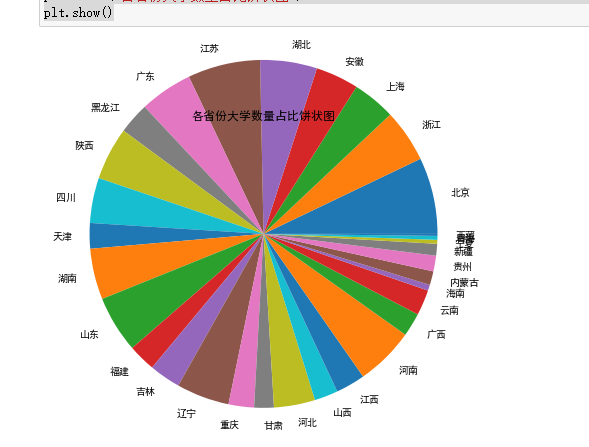
(2)绘制柱状图
def dataanly1():df_score = df.sort_values('score',ascending=False) # asc Flase降序 True升序 ; descname1 = df_score.schoolname[:10] # x轴坐标score1 = df_score.score[:10] # y轴坐标plt.bar(range(10),score1,tick_label=name1) # 绘制条形图,用range()能保持x轴顺序一致plt.ylim(10,100)plt.title("大学评分最高Top10",color=colors1)plt.xlabel("大学名称")plt.ylabel("评分")# 标记数值for x,y in enumerate(list(score1)):plt.text(x,y+0.5,'%s' %round(y,1),ha='center',color=colors1)passpl.xticks(rotation=270) # 旋转270°plt.tight_layout() # 去除空白plt.show()
def DXAnly2():area_count = df.groupby(by='area').area.count().sort_values(ascending=False)# 绘图方法1area_count.plot.bar(color='#4652B1') # 设置为蓝紫色pl.xticks(rotation=0) # x轴名称太长重叠,旋转为纵向for x, y in enumerate(list(area_count.values)):plt.text(x, y + 0.5, '%s' % round(y, 1), ha='center', color=colors1)plt.title('各地区大学数量排名')plt.xlabel('地区')plt.ylabel('数量(所)')plt.show()
def dataanly1():df_score = df.sort_values('score',ascending=False) # asc Flase降序 True升序 ; descname1 = df_score.schoolname[:10] # x轴坐标score1 = df_score.score[:10] # y轴坐标plt.bar(range(10),score1,tick_label=name1) # 绘制条形图,用range()能保持x轴顺序一致plt.ylim(10,100)plt.title("大学评分最高Top10",color=colors1)plt.xlabel("大学名称")plt.ylabel("评分")# 标记数值for x,y in enumerate(list(score1)):plt.text(x,y+0.5,'%s' %round(y,1),ha='center',color=colors1)passpl.xticks(rotation=270) # 旋转270°plt.tight_layout() # 去除空白plt.show()
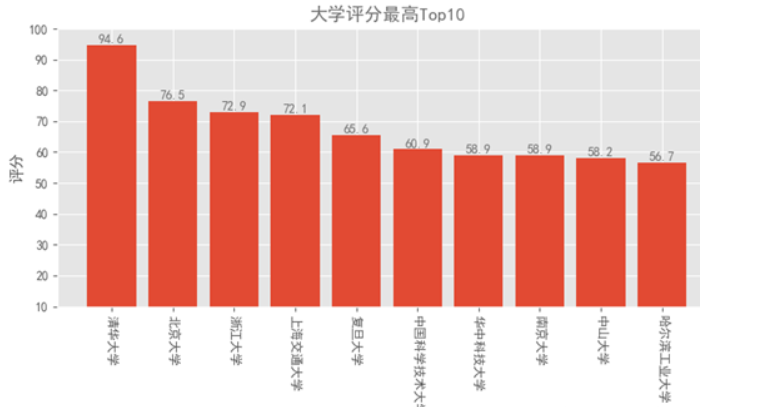

通过所绘制柱状图与饼状图,我们可以清晰地看出优秀大学在各个省份占比,在选择大学的时候,可以优先选择教育资源更加多源,高等教育水平更高的省份城市,
其中前三名的地区是北京、江苏、上海,经济水平较为发达的地区,可以简单的看见高素质教育水平可以影响地区经济的发展。
(4)绘制折线图
from pyecharts.charts import Line
from pyecharts import options as optsline = (Line().add_xaxis(top10_sum.index.tolist()).add_yaxis("总分", top10_sum["总分"].astype('int').tolist()).set_global_opts(title_opts=opts.TitleOpts(title="中国最好大学TOP10(各省份)" ,subtitle="总分"))
)
line.render_notebook()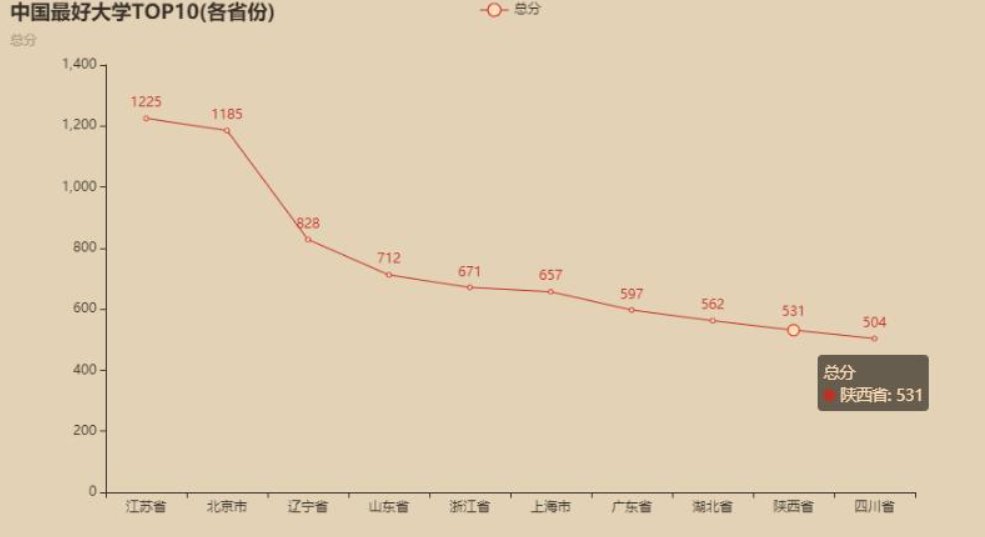
(5)绘制词云
from PIL import Image
from os import path
from wordcloud import WordCloud
wordcloud=WordCloud(background_color = '#f3f3f3',font_path = 'C:\Windows\Fonts\msyh.ttc',margin=3,max_font_size=60,random_state=50,scale=10,colormap='viridis',)
wordcloud.generate_from_frequencies(result)
plt.imshow(wordcloud,interpolation = 'bilinear')
plt.axis('off')
plt.show()
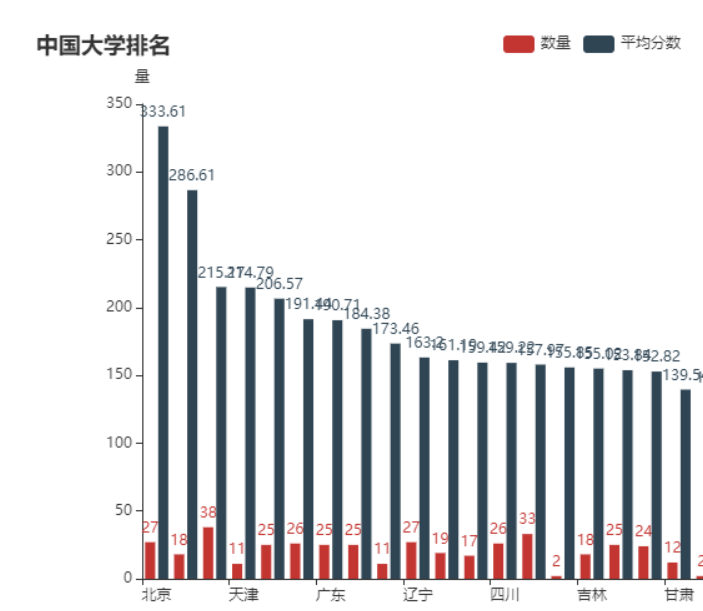
(6)各省市大学数量平均分纵向柱状图
df1.sort_values(by=['平均分'], ascending=False, inplace=True)
d1 = df1.index.tolist()
d2 = df1['数量'].values.tolist()
d3 = df1['平均分'].values.tolist()bar0 = (Bar().add_xaxis(d1).add_yaxis('数量', d2).add_yaxis('平均分数', d3).set_global_opts(title_opts=opts.TitleOpts(title='中国大学排名'),yaxis_opts=opts.AxisOpts(name='量'),xaxis_opts=opts.AxisOpts(name='省份'),)
)
(7)各省市大学数量平均分横向柱状图
df1.sort_values(by=['平均分'], inplace=True)d1 = df1.index.tolist()
d2 = df1['数量'].values.tolist()
d3 = df1['平均分'].values.tolist()bar1 = (Bar().add_xaxis(d1).add_yaxis('数量', d2).add_yaxis('平均分数', d3).reversal_axis().set_series_opts(label_opts=opts.LabelOpts(position='right')).set_global_opts(title_opts=opts.TitleOpts(title='中国大学排名'),yaxis_opts=opts.AxisOpts(name='省份'),xaxis_opts=opts.AxisOpts(name='量'),)
)
(8)绘制玫瑰图
name = df_counts.index.tolist()count = df_counts.values.tolist()c0 = (Pie().add('',[list(z) for z in zip(name, count)],radius=['20%', '60%'],center=['50%', '65%'],rosetype="radius",label_opts=opts.LabelOpts(is_show=False),).set_series_opts(label_opts=opts.LabelOpts(formatter='{b}: {c}'))
)
(9)大学地图分布
name = df0.index.tolist()count = df0.values.tolist()m = (Map().add('', [list(z) for z in zip(name, count)], 'china').set_global_opts(title_opts=opts.TitleOpts(title='中国大学排名'),visualmap_opts=opts.VisualMapOpts(max_=40, split_number=8, is_piecewise=True),))
(10)选定绘制折线图
选择一所大学,查看这所大学今年来的排名变化,这里选择北京邮电大学
sorce2=[]
for i in range(4):url='http://www.zuihaodaxue.cn/zuihaodaxuepaiming'+str(i+2016)+'.html'allUniv=Req(url)for i in range(len(allUniv)):if allUniv[i][1]=="北京邮电大学":j=ibreaksorce2.append(float(allUniv[j][3]))
print(sorce2)years=[2016,2017,2018,2019]
plt.subplot(1,1,1)
plt.plot(years,sorce2,marker='o')
plt.grid(True)
plt.title("北京邮电大学2016-2019年评分走势")
plt.xlabel('年')
plt.ylabel('分数')
plt.show()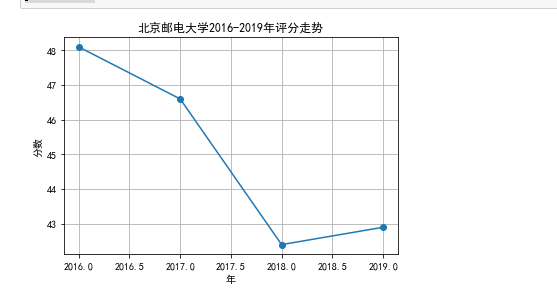
五、代码汇总
import requests
from lxml import htmldef Tree(url):req = requests.get(url)req.encoding ='utf-8-sig'allUniv = []tree = html.fromstring(req.text)trs = tree.xpath('//tbody/tr')for tr in trs:tds = tr.xpath('td')if tds == 0:continueoneUniv=[]oneUniv.append(tds[0].text)name = tds[1].xpath('div')oneUniv.append(name[0].text)for td in tds[2:]:oneUniv.append(td.text)allUniv.append(oneUniv)return allUnivurl='http://www.zuihaodaxue.cn/zuihaodaxuepaiming2019.html'tree=Tree(url)print("排名 学校名称 省市 总分")for i in range(20):print(tree[i][0],tree[i][1],tree[i][2],tree[i][3],sep=' ')from bs4 import BeautifulSoupdef Req(url):req=requests.get(url)req.encoding='utf-8-sig'allUniv=[]soup=BeautifulSoup(req.text,"html.parser")trs=soup.find_all('tr')for tr in trs:tds=tr.find_all('td')if len(tds)==0:continueoneUniv=[]for td in tds:oneUniv.append(td.string)allUniv.append(oneUniv)return allUnivallUniv1=Req(url)print("排名 学校名称 省市 总分")for i in range(20):print(allUniv1[i][0],allUniv1[i][1],allUniv1[i][2],allUniv1[i][3],sep=' ')import csvwith open('text2019.csv', 'w',newline='') as csvfile:writer = csv.writer(csvfile)writer.writerow(['排名','学校名称','省市','总分','指标得分','生源质量(新生高考成绩得分)','培养结果(毕业生就业率)','社会声誉(社会捐赠收入·千元)','科研规模(论文数量·篇)','科研质量(论文质量·FWCI)','顶尖成果(高被引论文·篇)','顶尖人才(高被引学者·人)','科技服务(企业科研经费·千元)','成果转化(技术转让收入·千元)'])for row in allUniv1:writer.writerow(row)import matplotlib.pyplot as pltplt.rcParams["font.sans-serif"]=["SimHei"]
name=[]
sorce=[]for i in range(10):name.append(allUniv1[i][1])sorce.append(float(allUniv1[i][3]))
plt.barh(range(len(sorce)),sorce,tick_label=name)
plt.title("2019年排名前十位的大学及其总分")
plt.xlabel('分数')
plt.show()from collections import Counterprovince=[]
for i in range(len(allUniv1)):province.append(allUniv1[i][2])
result=Counter(province)
print(result)import matplotlib as mplmpl.rcParams["font.sans-serif"]=["SimHei"]
mpl.rcParams["axes.unicode_minus"]=False
plt.pie(result.values(),labels=result.keys(),radius=2)
plt.title("各省份大学数量占比饼状图")from PIL import Image
from os import path
from wordcloud import WordCloudwordcloud=WordCloud(background_color = '#f3f3f3',font_path = 'C:\Windows\Fonts\msyh.ttc',margin=3,max_font_size=60,random_state=50,scale=10,colormap='viridis',)
wordcloud.generate_from_frequencies(result)
plt.imshow(wordcloud,interpolation = 'bilinear')plt.axis('off')
plt.show()
plt.show()def dataanly1():df_score = df.sort_values('score',ascending=False) # asc Flase降序 True升序 ; descname1 = df_score.schoolname[:10] # x轴坐标score1 = df_score.score[:10] # y轴坐标plt.bar(range(10),score1,tick_label=name1) # 绘制条形图,用range()能保持x轴顺序一致plt.ylim(10,100)plt.title("大学评分最高Top10",color=colors1)plt.xlabel("大学名称")plt.ylabel("评分")# 标记数值for x,y in enumerate(list(score1)):plt.text(x,y+0.5,'%s' %round(y,1),ha='center',color=colors1)passpl.xticks(rotation=270) # 旋转270°plt.tight_layout() # 去除空白plt.show()def DXAnly2():area_count = df.groupby(by='area').area.count().sort_values(ascending=False)# 绘图方法1area_count.plot.bar(color='#4652B1') # 设置为蓝紫色pl.xticks(rotation=0) # x轴名称太长重叠,旋转为纵向for x, y in enumerate(list(area_count.values)):plt.text(x, y + 0.5, '%s' % round(y, 1), ha='center',
color=colors1)plt.title('各地区大学数量排名')plt.xlabel('地区')plt.ylabel('数量(所)')plt.show()from PIL import Image
from os import path
from wordcloud import WordCloudwordcloud=WordCloud(background_color = '#f3f3f3',font_path = 'C:\Windows\Fonts\msyh.ttc',margin=3,max_font_size=60,random_state=50,scale=10,colormap='viridis',)
wordcloud.generate_from_frequencies(result)
plt.imshow(wordcloud,interpolation = 'bilinear')
plt.axis('off')
plt.show()from pyecharts.charts import Line
from pyecharts import options as optsline = (Line().add_xaxis(top10_sum.index.tolist()).add_yaxis("总分", top10_sum["总分"].astype('int').tolist()).set_global_opts(title_opts=opts.TitleOpts(title="中国最好大学TOP10(各省份)" ,subtitle="总分"))
)
line.render_notebook()df1.sort_values(by=['平均分'], ascending=False, inplace=True)
d1 = df1.index.tolist()
d2 = df1['数量'].values.tolist()
d3 = df1['平均分'].values.tolist()bar0 = (Bar().add_xaxis(d1).add_yaxis('数量', d2).add_yaxis('平均分数', d3).set_global_opts(title_opts=opts.TitleOpts(title='中国大学排名'),yaxis_opts=opts.AxisOpts(name='量'),xaxis_opts=opts.AxisOpts(name='省份'),)
)df1.sort_values(by=['平均分'], inplace=True)d1 = df1.index.tolist()
d2 = df1['数量'].values.tolist()
d3 = df1['平均分'].values.tolist()bar1 = (Bar().add_xaxis(d1).add_yaxis('数量', d2).add_yaxis('平均分数', d3).reversal_axis().set_series_opts(label_opts=opts.LabelOpts(position='right')).set_global_opts(title_opts=opts.TitleOpts(title='中国大学排名'),yaxis_opts=opts.AxisOpts(name='省份'),xaxis_opts=opts.AxisOpts(name='量'),)
)name = df_counts.index.tolist()count = df_counts.values.tolist()c0 = (Pie().add('',[list(z) for z in zip(name, count)],radius=['20%', '60%'],center=['50%', '65%'],rosetype="radius",label_opts=opts.LabelOpts(is_show=False),).set_series_opts(label_opts=opts.LabelOpts(formatter='{b}: {c}'))
)name = df0.index.tolist()count = df0.values.tolist()m = (Map().add('', [list(z) for z in zip(name, count)], 'china').set_global_opts(title_opts=opts.TitleOpts(title='中国大学排名'),visualmap_opts=opts.VisualMapOpts(max_=40, split_number=8, is_piecewise=True),))sorce2=[]
for i in range(4):url='http://www.zuihaodaxue.cn/zuihaodaxuepaiming'+str(i+2016)+'.html'allUniv=Req(url)for i in range(len(allUniv)):if allUniv[i][1]=="北京邮电大学":j=ibreaksorce2.append(float(allUniv[j][3]))
print(sorce2)years=[2016,2017,2018,2019]
plt.subplot(1,1,1)
plt.plot(years,sorce2,marker='o')
plt.grid(True)
plt.title("北京邮电大学2016-2019年评分走势")
plt.xlabel('年')
plt.ylabel('分数')
plt.show()六、总结
一所好的大学,对人生的影响是非常巨大的,在力所能及的范围内选择一所位于教育资源更加多源,高等教育水平更高的省份城市的优秀大学是非常重要的事,作为判断标准的数据,在以往单单是一所大学的相关资料就需要通过大量、繁琐的查找与翻阅才能够得到,若是多所大学的多年的变化则需要更多的时间。而现在通过python的则能够相对轻松的得到。
结语
学会了Python就业还是不用愁的,这些行业在薪资待遇上可能会有一些区别,但是整体来看还是很好的,我也不会说往哪个方向发展是最好的,各取所长选择自己最感兴趣的去学习就好。
作为一个IT的过来人,我自己整理了一些python学习资料,希望对你们有帮助。
朋友们如果需要可以点击下方链接或微信扫描下方二维码都可以免费获取【保证100%免费】。
CSDN大礼包:《2024最新Python全套学习礼包》【安全链接,放心点击】

编程资料、学习路线图、源代码、软件安装包等!
① Python所有方向的学习路线图,清楚各个方向要学什么东西
② 100多节Python课程视频,涵盖必备基础、爬虫和数据分析
③ 100多个Python实战案例,学习不再是只会理论
④ 华为出品独家Python漫画教程,手机也能学习

相关文章:
Python爬虫与数据分析:中国大学排名的深度挖掘
前言 👉 小编已经为大家准备好了完整的代码和完整的Python学习资料,朋友们如果需要可以扫描下方CSDN官方认证二维码或者点击链接免费领取【保证100%免费】 一、选题背景 高考作为中国学生生涯中最为重要的事,在高考之后,选择一所…...

微软开源库 Detours 详细介绍与使用实例分享
目录 1、Detours概述 2、Detours功能特性 3、Detours工作原理 4、Detours应用场景 5、Detours兼容性 6、Detours具体使用方法 7、Detours使用实例 - 使用Detours拦截系统库中的UnhandledExceptionFilter接口,实现对程序异常的拦截 C软件异常排查从入门到精通…...

js中的getElementById的使用方法
在JavaScript中,document.getElementById()是一种用于通过元素的id属性获取DOM元素的方法。它的作用是返回与指定id匹配的HTML元素。 使用document.getElementById()可以通过元素的id属性直接获取该元素的引用,然后可以使用该引用对元素进行各种操作。例…...

设计模式 - 桥接模式
💝💝💝首先,欢迎各位来到我的博客!本文深入理解设计模式原理、应用技巧、强调实战操作,提供代码示例和解决方案,适合有一定编程基础并希望提升设计能力的开发者,帮助读者快速掌握并灵活运用设计模式。 💝💝💝如有需要请大家订阅我的专栏【设计模式】哟!我会定…...

LeetCode530 二叉搜索树的最小绝对差
前言 题目: 530. 二叉搜索树的最小绝对差 文档: 代码随想录——二叉搜索树的最小绝对差 编程语言: C 解题状态: 成功解决! 思路 注意题目中的二叉搜索树,这个条件暗示每个节点的左子节点肯定小于该节点&am…...

【STM32 FreeRTOS】信号量与互斥锁
二值信号量 二值信号量的本质是一个队列长度为1的队列,该队列就只有空和满两种情况,这就是二值。 二值信号量通常用于互斥访问或任务同步,与互斥信号量比较类似,但是二值信号量有可能会导致优先级翻转的问题,所以二值…...
SP:eric 靶场复现【附代码】(权限提升)
靶机下载地址: https://www.vulnhub.com/entry/sp-eric,274/https://www.vulnhub.com/entry/sp-eric,274/ 1. 主机发现端口扫描目录扫描敏感信息获取 1.1. 主机发现 nmap -sn 192.168.7.0/24|grep -B 2 08:00:27:75:19:80 1.2. 端口扫描 nmap 192.168.7.104 -p…...
SpringBoot项目启动直接结束--已解决
点击启动类,项目启动了,但是却直接停止了。遇到这个问题如何解决呢? 想要项目一直启动是要部署在tomcat服务器上面了,说明现在项目没有运行在tomcat服务器上面。 解决方案: 添加springweb的starter依赖。 <dependency><…...

【笔记】从零开始做一个精灵龙女-画贴图阶段(下)
补充四点,第一,前期画体积用一号或十三号笔刷,压力60,硬度80,体积大一点 2号笔刷比较适合画过渡和软一点的东东 第二, 游戏里面角色原画海报都是发光很亮很透。但是在bp不能画那么亮,因为你进…...
React 学习——react项目中加入echarts图
实现的代码如下: import * as echarts from echarts import { useEffect, useRef } from react; const Home ()>{const chartRef useRef(null);useEffect(()>{// const chartDom document.getElementById(main);//使用id获取节点const chartDom chartRef…...

链表算法题一
旋转链表 旋转链表 首先考虑特殊情况 若给定链表为空表或者单个节点,则直接返回head,不需要旋转操作.题目给定条件范围: 0 < k < 2 ∗ 1 0 9 0 < k < 2 * 10^9 0<k<2∗109,但是受给定链表长度的限制,比如示例2中,k4与k1的效果等价. 那么可以得出kk%l…...
Unity(2022.3.38LTS) - 基础概念
目录 一. 场景 二. 游戏对象 三. 组件 四. 标签 五. 静态游戏对象 六. 保存 一. 场景 Unity 场景是游戏或应用开发中的一个重要概念。 Unity 场景的组成元素: 它通常包含了各种游戏对象,比如 3D 模型、灯光、摄像机、脚本组件、音频源等等。 作用…...

无人机之飞手必看篇
一、熟悉无人机设备 了解你的无人机:熟悉无人机的各个部分,包括遥控器、电池、螺旋桨和摄像头等。 预飞行检查:在每次飞行前进行预检查,确保所有部件正常工作,螺旋桨牢固,电池充满电。 二、选择适当的飞…...
数据结构(11)——二叉搜索树
欢迎来到博主的专栏:数据结构 博主ID:代码小豪 文章目录 二叉搜索树二叉搜索树的声明与定义二叉搜索树的查找二叉搜索树的插入二叉搜索树的中序遍历二叉搜索树的删除 二叉搜索树 二叉搜索树也称二叉排序树,是具备以下特征的二叉树 (1&#x…...

如何使用和配置 AWS CLI 环境变量?
欢迎来到雲闪世界。环境变量在配置和保护应用程序方面起着至关重要的作用,在使用 AWS CLI(命令行界面)时,它们的使用尤其重要。在这篇博客文章中,我们将深入探讨环境变量的世界,探索它们的用途、它们在 AWS…...

七、流程控制
if语句 在go语言中if语句的写法是比较简单的,也是很常见的 func main() {a : trueif a {fmt.Println("a is true")} }if else 语句 func main() {a : trueif !a {fmt.Println("a is true")} else {fmt.Println("a is false")} }el…...

【通过python启动指定的文件】
通过python启动指定的文件 在 Python 中,可以使用os模块的startfile函数(在 Windows 系统中)或者subprocess模块来启动指定的文件。 以下是使用os模块在 Windows 系统中的示例: import osfile_path "C:\\path\\to\\your\…...

区块链开源的项目有哪些?
区块链领域有许多开源项目,它们覆盖了从基础设施到应用层的不同方面。以下是一些著名的区块链开源项目: 1. Bitcoin (比特币):第一个去中心化的加密货币,源代码在 GitHub 上开源。它实现了区块链技术的基本概念。 2. Ethereum (…...
)
3152. 特殊数组 II(24.8.14)
题目 如果数组的每一对相邻元素都是两个奇偶性不同的数字,则该数组被认为是一个 特殊数组 。 你有一个整数数组 nums 和一个二维整数矩阵 queries,对于 queries[i] [fromi, toi],请你帮助你检查 子数组 nums[fromi…toi] 是不是一个 特殊数组…...

Android 全系统版本文件读写最佳适配,CV 即用(适配到 Android 14)
结合着Android的历史问题,我们需要这样写才行: 首先 manifest 部分 <manifest><!-- Devices running Android 12L (API level 32) or lower --><uses-permission android:name"android.permission.READ_EXTERNAL_STORAGE" a…...

企业级网络模拟:用eNSP搭建USG6000v双机热备+NAT的完整实验环境
企业级网络高可用实战:基于eNSP的USG6000v双机热备与NAT深度解析 当企业核心业务对网络连续性要求达到99.99%时,单台防火墙的部署就像走钢丝——任何硬件故障或链路中断都可能导致服务瘫痪。这正是我在为某电商平台设计灾备方案时遇到的痛点:…...

Windows风扇控制终极指南:FanControl让你5分钟实现专业级散热管理
Windows风扇控制终极指南:FanControl让你5分钟实现专业级散热管理 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_…...

LinkedIn内容自动化发布:基于Node.js与Playwright的实战指南
1. 项目概述:为什么我们需要一个LinkedIn帖子自动化工具?如果你在运营个人品牌、管理公司账号,或者从事市场营销、招聘工作,那么对LinkedIn这个平台一定不陌生。它早已不是单纯的求职网站,而是全球最大的职业社交与内容…...

从概念验证到生产环境:Keep开源告警管理平台的5步完整实战部署指南
从概念验证到生产环境:Keep开源告警管理平台的5步完整实战部署指南 【免费下载链接】keep The open-source AIOps and alert management platform 项目地址: https://gitcode.com/GitHub_Trending/kee/keep 在当今复杂的云原生环境中,告警管理已成…...

Fuzzz靶场学习笔记
前言正文1、端口扫描2、安卓端口反向代理3、目录遍历获取RSA密钥4、用户提权前言 本文介绍了Kali Linux的基本使用技巧和nmap常见命令,重点演示了端口扫描、安卓设备反向代理和权限提升过程。通过nmap扫描发现安卓设备5555端口开放,使用adb工具连接后&a…...
)
毕业设计救星:手把手教你用51单片机和HX711搞定高精度电子秤(附Proteus仿真+完整代码)
毕业设计实战指南:基于51单片机与HX711的高精度电子秤系统开发 在电子信息类专业的毕业设计中,基于51单片机的电子秤系统一直是热门选题。这个项目不仅涵盖了单片机开发的核心技能点,还能让学生深入理解传感器应用、模数转换原理以及人机交互…...

GitHub中文化插件终极实战指南:5分钟实现高效中文开发体验
GitHub中文化插件终极实战指南:5分钟实现高效中文开发体验 【免费下载链接】github-chinese GitHub 汉化插件,GitHub 中文化界面。 (GitHub Translation To Chinese) 项目地址: https://gitcode.com/gh_mirrors/gi/github-chinese GitHub作为全球…...
:拷贝构造函数与深浅拷贝问题)
【c++面向对象编程】第4篇:类与对象(三):拷贝构造函数与深浅拷贝问题
目录 一、一个崩溃的程序 二、拷贝构造函数是什么? 调用时机(三个场景) 三、浅拷贝 vs 深拷贝 浅拷贝(默认行为) 深拷贝(正确的做法) 四、什么时候必须自己写拷贝构造函数? 一…...

【领域驱动设计 开篇】零 来源及学习路径
DDD是什么 2003 年,Eric Evans 写了《领域驱动设计:软件核心复杂性应对之道》一书,正式提出了这种方法。领域驱动设计的英文是 Domain-Driven Design,简称 DDD。 按照作者自己的说法,“DDD 是一种开发复杂软件的方法”…...

2026廊坊硅酸铝柔性包裹,防火专业厂家这样选
最近在跑几个建筑机电工程,跟不少项目经理、施工队负责人聊了聊,发现大家不约而同遇到了同一个坎儿——管道防火验收。尤其是湿式报警阀间、排烟管道这些“硬骨头”,防火包裹的材质、阻燃等级、贴合度,直接决定了消防验收能不能一…...