用Pytorch搭建一个房价预测模型
本文参加新星计划人工智能(Pytorch)赛道:https://bbs.csdn.net/topics/613989052
目录
一、项目介绍
二、准备工作
三、实验过程
3.1数据预处理
3.2拆分数据集
3.3构建PyTorch模型
3.3.1.数据转换
3.3.2定义模型架构
3.3.3定义损失准则和优化器
3.3.4创建数据加载器
3.3.5训练模型
四、原理讲解
五、补充
一、项目介绍
在此项目中,目的是预测爱荷华州Ames的房价,给定81个特征,描述了房子、面积、土地、基础设施、公共设施等。埃姆斯数据集具有分类和连续特征的良好组合,大小适中,也许最重要的是,它不像其他类似的数据集(如波士顿住房)那样存在潜在的红线或数据输入问题。在这里我将主要讨论PyTorch建模的相关方面,作为一点额外的内容,我还将演示PyTorch中开发的模型的神经元重要性。你可以在PyTorch中尝试不同的网络架构或模型类型。本项目中的重点是方法论,而不是详尽地寻找最佳解决方案。
二、准备工作
为了准备这个项目,我们首先需要下载数据,并通过以下步骤进行一些预处理。
from sklearn.datasets import fetch_openml
data = fetch_openml(data_id=42165, as_frame=True)关于该数据集的完整描述,你可以去该网址查看:https://www.openml.org/d/42165。
查看数据特征
import pandas as pd
data_ames = pd.DataFrame(data.data, columns=data.feature_names)
data_ames['SalePrice'] = data.target
data_ames.info()下面是DataFrame的信息
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1460 entries, 0 to 1459
Data columns (total 81 columns):
Id 1460 non-null float64
MSSubClass 1460 non-null float64
MSZoning 1460 non-null object
LotFrontage 1201 non-null float64
LotArea 1460 non-null float64
Street 1460 non-null object
Alley 91 non-null object
LotShape 1460 non-null object
LandContour 1460 non-null object
Utilities 1460 non-null object
LotConfig 1460 non-null object
LandSlope 1460 non-null object
Neighborhood 1460 non-null object
Condition1 1460 non-null object
Condition2 1460 non-null object
BldgType 1460 non-null object
HouseStyle 1460 non-null object
OverallQual 1460 non-null float64
OverallCond 1460 non-null float64
YearBuilt 1460 non-null float64
YearRemodAdd 1460 non-null float64
RoofStyle 1460 non-null object
RoofMatl 1460 non-null object
Exterior1st 1460 non-null object
Exterior2nd 1460 non-null object
MasVnrType 1452 non-null object
MasVnrArea 1452 non-null float64
ExterQual 1460 non-null object
ExterCond 1460 non-null object
Foundation 1460 non-null object
BsmtQual 1423 non-null object
BsmtCond 1423 non-null object
BsmtExposure 1422 non-null object
BsmtFinType1 1423 non-null object
BsmtFinSF1 1460 non-null float64
BsmtFinType2 1422 non-null object
BsmtFinSF2 1460 non-null float64
BsmtUnfSF 1460 non-null float64
TotalBsmtSF 1460 non-null float64
Heating 1460 non-null object
HeatingQC 1460 non-null object
CentralAir 1460 non-null object
Electrical 1459 non-null object
1stFlrSF 1460 non-null float64
2ndFlrSF 1460 non-null float64
LowQualFinSF 1460 non-null float64
GrLivArea 1460 non-null float64
BsmtFullBath 1460 non-null float64
BsmtHalfBath 1460 non-null float64
FullBath 1460 non-null float64
HalfBath 1460 non-null float64
BedroomAbvGr 1460 non-null float64
KitchenAbvGr 1460 non-null float64
KitchenQual 1460 non-null object
TotRmsAbvGrd 1460 non-null float64
Functional 1460 non-null object
Fireplaces 1460 non-null float64
FireplaceQu 770 non-null object
GarageType 1379 non-null object
GarageYrBlt 1379 non-null float64
GarageFinish 1379 non-null object
GarageCars 1460 non-null float64
GarageArea 1460 non-null float64
GarageQual 1379 non-null object
GarageCond 1379 non-null object
PavedDrive 1460 non-null object
WoodDeckSF 1460 non-null float64
OpenPorchSF 1460 non-null float64
EnclosedPorch 1460 non-null float64
3SsnPorch 1460 non-null float64
ScreenPorch 1460 non-null float64
PoolArea 1460 non-null float64
PoolQC 7 non-null object
Fence 281 non-null object
MiscFeature 54 non-null object
MiscVal 1460 non-null float64
MoSold 1460 non-null float64
YrSold 1460 non-null float64
SaleType 1460 non-null object
SaleCondition 1460 non-null object
SalePrice 1460 non-null float64
dtypes: float64(38), object(43)
memory usage: 924.0+ KB接下来,我们还将使用一个库,即 captum,它可以检查 PyTorch 模型的特征和神经元重要性。
pip install captum在做完这些准备工作后,我们来看看如何预测房价。
三、实验过程
3.1数据预处理
在这里,首先要进行数据缩放处理,因为所有的变量都有不同的尺度。分类变量需要转换为数值类型,以便将它们输入到我们的模型中。我们可以选择一热编码,即我们为每个分类因子创建哑变量,或者是序数编码,即我们对所有因子进行编号,并用这些数字替换字符串。我们可以像其他浮动变量一样将虚拟变量送入,而序数编码则需要使用嵌入,即线性神经网络投影,在多维空间中对类别进行重新排序。我们在这里采取嵌入的方式。
import numpy as np
from category_encoders.ordinal import OrdinalEncoder
from sklearn.preprocessing import StandardScalernum_cols = list(data_ames.select_dtypes(include='float'))
cat_cols = list(data_ames.select_dtypes(include='object'))ordinal_encoder = OrdinalEncoder().fit(data_ames[cat_cols]
)
standard_scaler = StandardScaler().fit(data_ames[num_cols]
)X = pd.DataFrame(data=np.column_stack([ordinal_encoder.transform(data_ames[cat_cols]),standard_scaler.transform(data_ames[num_cols])]),columns=cat_cols + num_cols
)
3.2拆分数据集
在构建模型之前,我们需要将数据拆分为训练集和测试集。在这里,我们添加了一个数值变量的分层。这可以确保不同的部分(其中五个)在训练集和测试集中都以同等的数量包含。
np.random.seed(12)
from sklearn.model_selection import train_test_splitbins = 5
sale_price_bins = pd.qcut(X['SalePrice'], q=bins, labels=list(range(bins))
)
X_train, X_test, y_train, y_test = train_test_split(X.drop(columns='SalePrice'),X['SalePrice'],random_state=12,stratify=sale_price_bins
)3.3构建PyTorch模型
接下来开始建立我们的PyTorch模型。我们将使用PyTorch实现一个具有批量输入的神经网络回归,具体将涉及以下步骤。
- 1. 将数据转换为Torch tensors
- 2. 定义模型结构
- 3. 定义损失标准和优化器。
- 4. 创建一个批次的数据加载器
- 5. 跑步训练
3.3.1.数据转换
首先将数据转换为torch tensors
from torch.autograd import Variable num_features = list(set(num_cols) - set(['SalePrice', 'Id'])
)
X_train_num_pt = Variable(torch.cuda.FloatTensor(X_train[num_features].values)
)
X_train_cat_pt = Variable(torch.cuda.LongTensor(X_train[cat_cols].values)
)
y_train_pt = Variable(torch.cuda.FloatTensor(y_train.values)
).view(-1, 1)
X_test_num_pt = Variable(torch.cuda.FloatTensor(X_test[num_features].values)
)
X_test_cat_pt = Variable(torch.cuda.LongTensor(X_test[cat_cols].values).long()
)
y_test_pt = Variable(torch.cuda.FloatTensor(y_test.values)
).view(-1, 1)这可以确保我们将数字和分类数据加载到单独的变量中,类似于NumPy。如果你把数据类型混合在一个变量(数组/矩阵)中,它们就会变成对象。我们希望把数值变量弄成浮点数,把分类变量弄成长(或int),索引我们的类别。我们还将训练集和测试集分开。显然,一个ID变量在模型中不应该是重要的。在最坏的情况下,如果ID与目标有任何相关性,它可能会引入目标泄漏。我们已经把它从这一步的处理中删除了。
3.3.2定义模型架构
class RegressionModel(torch.nn.Module): def __init__(self, X, num_cols, cat_cols, device=torch.device('cuda'), embed_dim=2, hidden_layer_dim=2, p=0.5): super(RegressionModel, self).__init__() self.num_cols = num_colsself.cat_cols = cat_colsself.embed_dim = embed_dimself.hidden_layer_dim = hidden_layer_dimself.embeddings = [torch.nn.Embedding(num_embeddings=len(X[col].unique()),embedding_dim=embed_dim).to(device)for col in cat_cols]hidden_dim = len(num_cols) + len(cat_cols) * embed_dim,# hidden layerself.hidden = torch.nn.Linear(torch.IntTensor(hidden_dim), hidden_layer_dim).to(device)self.dropout_layer = torch.nn.Dropout(p=p).to(device)self.hidden_act = torch.nn.ReLU().to(device)# output layerself.output = torch.nn.Linear(hidden_layer_dim, 1).to(device)def forward(self, num_inputs, cat_inputs):'''Forward method with two input variables -numeric and categorical.'''cat_x = [torch.squeeze(embed(cat_inputs[:, i] - 1))for i, embed in enumerate(self.embeddings)]x = torch.cat(cat_x + [num_inputs], dim=1)x = self.hidden(x)x = self.dropout_layer(x)x = self.hidden_act(x)y_pred = self.output(x)return y_predhouse_model = RegressionModel(data_ames, num_features, cat_cols
)我们在两个线性层(上的激活函数是整流线性单元激活(ReLU)函数。这里需要注意的是,我们不可能将相同的架构(很容易)封装成一个顺序模型,因为分类和数值类型上发生的操作不同。
3.3.3定义损失准则和优化器
接下来,定义损失准则和优化器。我们将均方误差(MSE)作为损失,随机梯度下降作为我们的优化算法。
criterion = torch.nn.MSELoss().to(device)
optimizer = torch.optim.SGD(house_model.parameters(), lr=0.001)3.3.4创建数据加载器
现在,创建一个数据加载器,每次输入一批数据。
data_batch = torch.utils.data.TensorDataset(X_train_num_pt, X_train_cat_pt, y_train_pt
)
dataloader = torch.utils.data.DataLoader(data_batch, batch_size=10, shuffle=True
)我们设置了10个批次的大小,接下来我们可以进行训练了。
3.3.5.训练模型
基本上,我们要在epoch上循环,在每个epoch内推理出性能,计算出误差,优化器根据误差进行调整。这是在没有训练的内循环的情况下,在epochs上的循环。
from tqdm.notebook import trangetrain_losses, test_losses = [], []
n_epochs = 30
for epoch in trange(n_epochs):train_loss, test_loss = 0, 0# print the errors in training and test:if epoch % 10 == 0 :print('Epoch: {}/{}\t'.format(epoch, 1000),'Training Loss: {:.3f}\t'.format(train_loss / len(dataloader)),'Test Loss: {:.3f}'.format(test_loss / len(dataloader)))训练是在这个循环里面对所有批次的训练数据进行的。
for (x_train_num_batch,x_train_cat_batch,y_train_batch) in dataloader:(x_train_num_batch,x_train_cat_batch, y_train_batch) = (x_train_num_batch.to(device),x_train_cat_batch.to(device),y_train_batch.to(device))pred_ytrain = house_model.forward(x_train_num_batch, x_train_cat_batch)loss = torch.sqrt(criterion(pred_ytrain, y_train_batch)) optimizer.zero_grad() loss.backward() optimizer.step()train_loss += loss.item()with torch.no_grad():house_model.eval()pred_ytest = house_model.forward(X_test_num_pt, X_test_cat_pt)test_loss += torch.sqrt(criterion(pred_ytest, y_test_pt))train_losses.append(train_loss / len(dataloader))test_losses.append(test_loss / len(dataloader))训练结果如下:
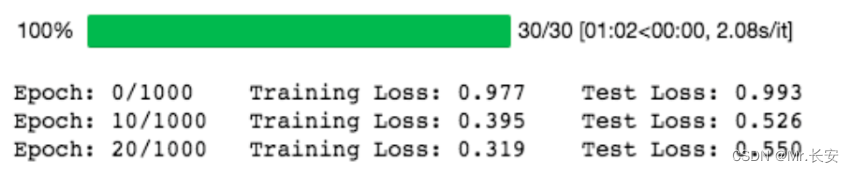
我们取 nn.MSELoss 的平方根,因为 PyTorch 中 nn.MSELoss 的定义如下:
((input-target)**2).mean()绘制一下我们的模型在训练期间对训练和验证数据集的表现。
plt.plot(np.array(train_losses).reshape((n_epochs, -1)).mean(axis=1),label='Training loss'
)
plt.plot(np.array(test_losses).reshape((n_epochs, -1)).mean(axis=1),label='Validation loss'
)
plt.legend(frameon=False)
plt.xlabel('epochs')
plt.ylabel('MSE')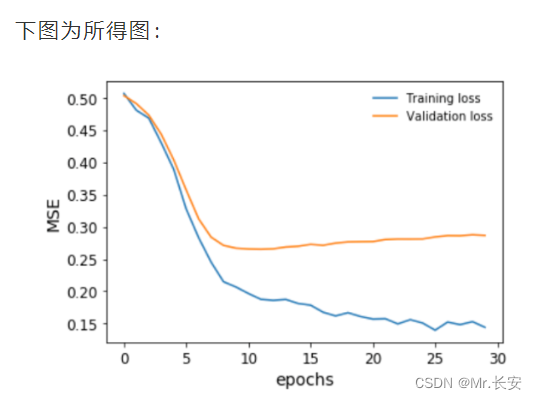
在我们的验证损失停止下降之前,我们及时停止了训练。我们还可以对目标变量进行排序和bin,并将预测结果与之对比绘制,以便了解模型在整个房价范围内的表现。这是为了避免回归中的情况,尤其是用MSE作为损失,即你只对一个中值范围的预测很好,接近平均值,但对其他任何东西都做得不好。

我们可以看到,事实上,这个模型在整个房价范围内的预测非常接近。事实上,我们得到的Spearman秩相关度约为93%,具有非常高的显著性,这证实了这个模型的表现具有很高的准确性。
四、原理讲解
深度学习神经网络框架使用不同的优化算法。其中流行的有随机梯度下降(SGD)、均方根推进(RMSProp)和自适应矩估计(ADAM)。我们定义了随机梯度下降作为我们的优化算法。另外,我们还可以定义其他优化器。
opt_SGD = torch.optim.SGD(net_SGD.parameters(), lr=LR)
opt_Momentum = torch.optim.SGD(net_Momentum.parameters(), lr=LR, momentum=0.6)
opt_RMSprop = torch.optim.RMSprop(net_RMSprop.parameters(), lr=LR, alpha=0.1)
opt_Adam = torch.optim.Adam(net_Adam.parameters(), lr=LR, betas=(0.8, 0.98))SGD的工作原理与梯度下降相同,只是它每次只在一个例子上工作。有趣的是,收敛性与梯度下降相似,并且更容易占用计算机内存。
RMSProp的工作原理是根据梯度符号来调整算法的学习率。最简单的变体是检查最后两个梯度符号,然后调整学习率,如果它们相同,则增加一个分数,如果它们不同,则减少一个分数。
ADAM是最流行的优化器之一。它是一种自适应学习算法,根据梯度的第一和第二时刻改变学习率。
Captum是一个工具,可以帮助我们了解在数据集上学习的神经网络模型的来龙去脉。它可以帮助我们学习以下内容。
-
特征重要性
-
层级重要性
-
神经元的重要性
这在学习可解释的神经网络中是非常重要的。在这里,综合梯度已经被应用于理解特征重要性。之后,还用层传导法来证明神经元的重要性。
五、补充
既然我们已经定义并训练了我们的神经网络,那么让我们使用 captum 库找到重要的特征和神经元。
from captum.attr import (IntegratedGradients,LayerConductance,NeuronConductance
)
house_model.cpu()
for embedding in house_model.embeddings:embedding.cpu()house_model.cpu()
ing_house = IntegratedGradients(forward_func=house_model.forward, )
#X_test_cat_pt.requires_grad_()
X_test_num_pt.requires_grad_()
attr, delta = ing_house.attribute(X_test_num_pt.cpu(),target=None,return_convergence_delta=True,additional_forward_args=X_test_cat_pt.cpu()
)
attr = attr.detach().numpy()现在,我们有了一个NumPy的特征重要性数组。层和神经元的重要性也可以用这个工具获得。让我们来看看我们第一层的神经元importances。我们可以传递house_model.act1,这是第一层线性层上面的ReLU激活函数。
cond_layer1 = LayerConductance(house_model, house_model.act1)
cond_vals = cond_layer1.attribute(X_test, target=None)
cond_vals = cond_vals.detach().numpy()
df_neuron = pd.DataFrame(data = np.mean(cond_vals, axis=0), columns=['Neuron Importance'])
df_neuron['Neuron'] = range(10)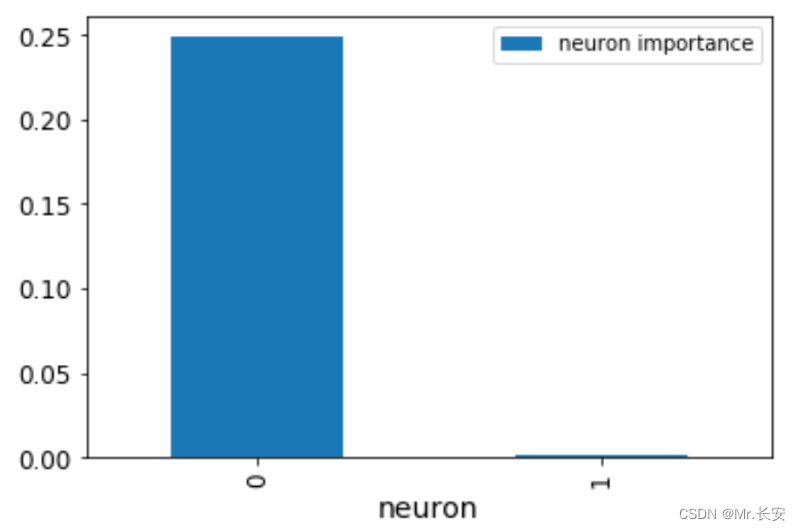
这张图显示了神经元的重要性。显然,一个神经元就是不重要的。我们还可以通过对之前得到的NumPy数组进行排序,看到最重要的变量。
df_feat = pd.DataFrame(np.mean(attr, axis=0), columns=['feature importance'] )
df_feat['features'] = num_features
df_feat.sort_values(by='feature importance', ascending=False
).head(10)这里列出了10个最重要的变量
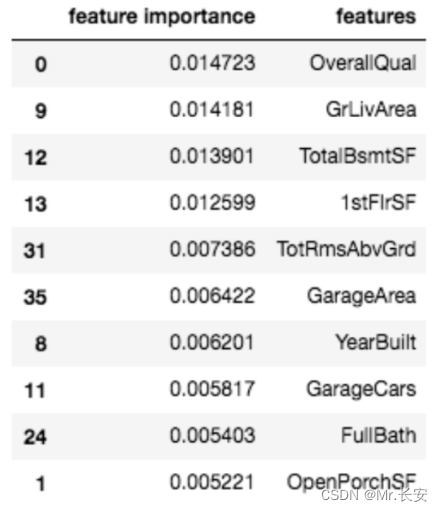
通常情况下,特征导入可以帮助我们既理解模型,又修剪我们的模型,使其变得不那么复杂(希望减少过度拟合)。
相关文章:
用Pytorch搭建一个房价预测模型
本文参加新星计划人工智能(Pytorch)赛道:https://bbs.csdn.net/topics/613989052 目录 一、项目介绍 二、准备工作 三、实验过程 3.1数据预处理 3.2拆分数据集 3.3构建PyTorch模型 3.3.1.数据转换 3.3.2定义模型架构 3.3.3定义损失准则和优化器 3.3.4创建…...

《Netty》从零开始学netty源码(十五)之ServerSocketChannel
在NioServerSocketChannel中调用newChannel方法创建java原生的channel,过程如下: ServerSocketChannel是一个抽象类,WEPollSelectorProvider调用openServerSocketChannel方法创建的是它的实现类ServerSocketChannelImpl,类结构如下…...
Java stream性能比较
环境 Ubuntu 22.04IntelliJ IDEA 2022.1.3JDK 17CPU:8核 ➜ ~ cat /proc/cpuinfo | egrep -ie physical id|cpu cores physical id : 0 cpu cores : 1 physical id : 2 cpu cores : 1 physical id : 4 cpu cores : 1 physical id : 6 cpu cores : 1 physical id …...

【数据结构与算法】设计循环队列
文章目录👑前言如何设计循环队列设计循环队列整体的代码📯写在最后👑前言 🚩前面我们 用队列实现了一个栈 ,用栈实现了一个队列 ,相信大家随随便便轻松拿捏,而本章将带大家上点难度,…...

最新版!国内IT软件外包公司汇总~
金三银四已经过去一半,再过几个月又将迎来毕业季,大家有没有找到心仪的工作机会呀?有很多同学说今年的金三银四似乎不存在了。小李:今年的金三银四变成了铜三铁四,不断地投递又不断地造拒。小王:大量已读不…...

MySQL的COUNT语句,竟然都能被面试官虐的这么惨!?
关于数据库中行数统计,无论是MySQL还是Oracle,都有一个函数可以使用,那就是COUNT 但是,就是这个常用的COUNT函数,却暗藏着很多玄机,尤其是在面试的时候,一不小心就会被虐。不信的话请尝试回答下…...
数位DP 详解及其案例实战 [模板+技巧+案例]
零. 案例引入 1.案例引入 leetcode233. 数字 1 的个数 给定一个整数 n,计算所有小于等于 n 的非负整数中数字 1 出现的个数。 输入:n 13 输出:6 2.暴力解 对于上述的案例,暴力解肯定是可行的,但时间复杂度较高,对…...
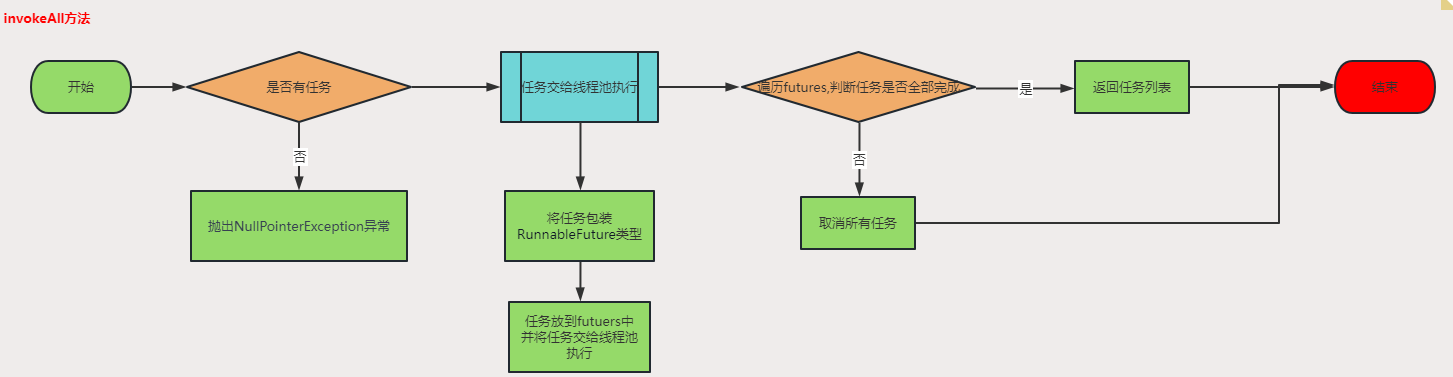
并发编程(六)—AbstractExecutorService源码分析
一、AbstractExecutorService简介AbstractExecutorService是一个抽象类,实现了ExecutorService接口,提供了线程池的基本实现。它是Java Executor框架的核心类,提供了线程池的基本操作,如提交任务、管理线程池、执行任务等。自定义…...

015行为型-职责链模式
目录定义标准模式实现:职责链变体使用链表实现使用数组实现应用场景日志输出spring过滤器spirng 拦截器mybatis动态sql定义 责链模式是一种设计模式,其目的是使多个对象能够处理同一请求,但是并不知道下一个处理请求的对象是谁。它能够解耦请…...
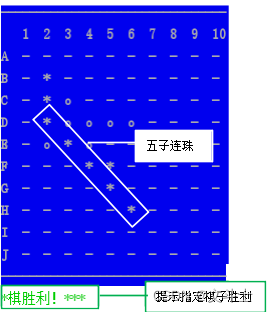
python例程:五子棋(控制台版)程序
目录《五子棋(控制台版)》程序使用说明程序示例代码可执行程序及源码下载路径《五子棋(控制台版)》程序使用说明 在PyCharm中运行《五子棋(控制台版)》即可进入如图1所示的系统主界面。 图1 游戏主界面 具…...

leveldb的Compaction线程
个人随笔 (Owed by: 春夜喜雨 http://blog.csdn.net/chunyexiyu) 1. leveldb的Compaction全局线程 在leveldb中,有一个全局的后台线程BGThread,用于数据库的MinorCompact与MajorCompact。 重点关注“全局线程”: 这个标识着无论一个进程打开…...

邪恶的想法冒出,立马启动python实现美女通通下
前言 嗨喽~大家好呀,这里是魔王呐 ❤ ~! 完整源码、python资料: 点击此处跳转文末名片获取 当我在首页刷到这些的时候~ 我的心里逐渐浮现一个邪念:我把这些小姐姐全都采集,可以嘛? 答案当然是可以的~毕竟就我这技术,…...

蓝桥杯刷题冲刺 | 倒计时18天
作者:指针不指南吗 专栏:蓝桥杯倒计时冲刺 🐾马上就要蓝桥杯了,最后的这几天尤为重要,不可懈怠哦🐾 文章目录0.知识点1.乳草的入侵今天写 搜索题 0.知识点 DFS 设计步骤 确定该题目的状态(包括边…...

经典算法面试题——Java篇-附带赠书活动,评论区随机选取一人赠书
目录 一.图书推荐 二.说一下什么是二分法?使用二分法时需要注意什么?如何用代码实现? 三.什么是插入排序?用代码如何实现? 四.什么是冒泡排序?用代码如何实现? 五.什么是斐波那契数列&#…...

支持RT-Thread最新版本的瑞萨RA2E1开发板终于要大展身手了
支持RT-Thread最新版本的瑞萨RA2E1开发板终于要大展身手了 熟悉RT-Thread和瑞萨MCU的朋友都知道,当前RT-Thread仓库的主线代码是不支持RA2E1这个BSP的。刚好,最近我在联合瑞萨推广一个叫《致敬未来的攻城狮计划》,使用的就是RA2E1开发板&…...

【C语言进阶】 12. 假期测评①
day01 1. 转义字符的判断 以下不正确的定义语句是( ) A: double x[5] {2.0, 4.0, 6.0, 8.0, 10.0}; B: char c2[] {‘\x10’, ‘\xa’, ‘\8’}; C: char c1[] {‘1’,‘2’,‘3’,‘4’,‘5’}; D: int y[53]{0, 1, 3, 5, 7, 9}; 【答案解析】 B 本…...
给程序加个进度条吧,1行Python代码,快速添加~
大家好,这里是程序员晚枫。 你在写代码的过程中,有没有遇到过以下问题? 已经写好的程序,想看看程序执行的进度? 在写代码批量处理文件的时候,如何显示现在处理到第几个文件了? 👆…...

常见的Keil5编译报错及其原因和解决方法
以下是几种常见的Keil5编译报错及其原因和解决方法: "Error: L6218E: Undefined symbol"(未定义符号错误) 这通常是由于缺少对应的库文件或者代码中有未声明的变量或函数引起的。解决方法是检查相应的库文件是否已正确添加到工程中…...
Django 实现瀑布流
需求分析 现在是 "图片为王"的时代,在浏览一些网站时,经常会看到类似于这种满屏都是图片。图片大小不一,却按空间排列,就这是瀑布流布局。 以瀑布流形式布局,从数据库中取出图片每次取出等量(7 …...
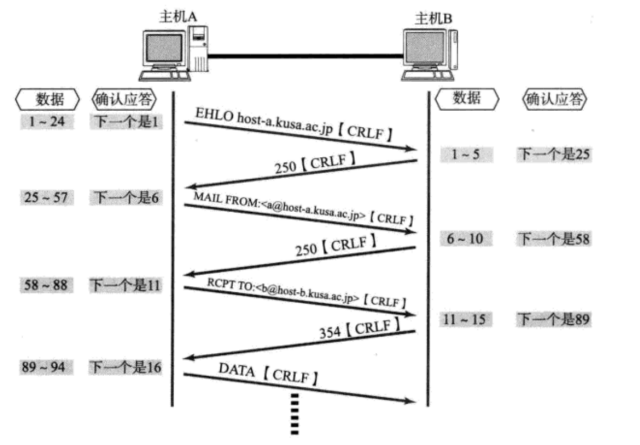
传输层协议----UDP/TCP
文章目录前言一、再谈端口号端口号的划分认识知名端口号(Well-Know Port Number)两个问题nestatpidof二、UDP协议UDP协议端格式UDP的特点面向数据报UDP的缓冲区UDP使用注意事项基于UDP的应用层协议二、TCP协议TCP协议段格式可靠性问题确认应答(ACK)机制流量控制六个标志位PSHUG…...

抖音下载终极指南:免费无水印批量保存完整方案
抖音下载终极指南:免费无水印批量保存完整方案 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support. 抖音…...

不只是打驱动:深入解读Intel Arc显卡在Linux下的RBAR技术及其对AI性能的实际影响
深入解析Intel Arc显卡RBAR技术:Linux环境下的AI性能优化实践 当一块Intel Arc显卡插入Linux工作站时,大多数用户的第一反应是寻找驱动安装指南。但真正影响AI推理性能的关键,往往隐藏在PCIe总线的一个名为RBAR(Resizable Base Ad…...
,3大未公开API接口实测报告)
别再手动复制粘贴了!ChatGPT原生PPT导出功能已上线(仅限Enterprise Tier),3大未公开API接口实测报告
更多请点击: https://intelliparadigm.com 第一章:ChatGPT原生PPT导出功能的架构演进与企业级定位 ChatGPT原生PPT导出功能并非简单集成第三方渲染库,而是OpenAI在模型服务层、内容生成中间件与文档编排引擎三者深度协同下构建的端到端能力。…...

数据缺失处理实战指南:从原理到应用,掌握KNN与MICE填补技术
1. 项目概述:数据缺失,一个绕不开的“坑”做数据分析、机器学习或者任何和数据打交道的工作,你大概率都遇到过这种情况:打开数据集,满怀期待地准备大干一场,结果发现好几列数据里都夹杂着刺眼的“NaN”、“…...
)
Pixel 6有锁机保姆级解锁教程:从‘SIM卡不受支持’到完美VoLTE通话(附ADB/Shizuku工具包)
Pixel 6有锁机完全解锁指南:从网络锁到功能优化全攻略 前言 当你从二手市场淘到一台Pixel 6,满心欢喜地插入SIM卡准备使用时,屏幕上却赫然显示"SIM卡不受支持"——这种挫败感我深有体会。作为一款硬件配置出色的设备,Pi…...

AI 超声波口罩机智能功率 MOSFET 完整选型方案
随着 AI 视觉检测与自适应控制技术深度集成,现代超声波口罩机对功率 MOSFET 提出更高要求:高频谐振效率、低损耗长寿命、高可靠精密驱动。微碧半导体(VBsemi)基于先进 SGT 及 Trench 工艺,为您提供覆盖超声波发生器、传…...

如何用250美元构建开源机器人手臂:低成本机器人学习平台技术解析
如何用250美元构建开源机器人手臂:低成本机器人学习平台技术解析 【免费下载链接】low_cost_robot 项目地址: https://gitcode.com/GitHub_Trending/lo/low_cost_robot 在机器人学习和自动化研究领域,高昂的设备成本一直是阻碍创新和普及的主要障…...

Creality Print:从新手到专家的完整3D打印切片软件指南
Creality Print:从新手到专家的完整3D打印切片软件指南 【免费下载链接】CrealityPrint 项目地址: https://gitcode.com/gh_mirrors/cr/CrealityPrint 在3D打印的世界里,切片软件是连接数字模型与物理实体的关键桥梁。无论您刚刚接触3D打印&…...
)
OpenClaw 自动处理核心逻辑(流程图+关键配置清单)
OpenClaw 自动处理核心逻辑(流程图关键配置清单) 说明:流程图可直接复制到支持Mermaid的工具(如Typora、Mermaid Live Editor)生成可视化图表;配置清单可直接用于部署、优化,适配所有自动处理场…...

单物体最优抓取轨迹生成
基于 3D 位姿规划直线平滑抓取轨迹,包含趋近 - 抓取 - 复位三段最优运动路径,适配机械臂点位运动核心规划逻辑基准位:机械臂初始安全待机点趋近段:直线匀速靠近物体上方预备抓取点抓取段:垂直下落至物体抓取中心位姿抬…...