基于 Appium 的 App 爬取实战
除了运行 Appium 的基本条件外,还要一个日志输出库
安装: pip install loguru
思路分析
首先我们观察一下整个 app5 的交互流程,其首页分条显示了电影数据, 每个电影条目都包括封面,标题, 类别和评分 4 个内容, 点击一个电影条目, 就可以看到这个电影的详细介绍,包括标题,类别,上映时间,评分,时长,电影简介等内容

可见详情页远比首页内容丰富, 我们需要依次点击每个电影条目,抓取看到的所有内容,把所有电影条目的信息都抓取下来后回退到首页
另外,首页一开始只显示 10 个电影条目,需要上拉才能显示更多数据,一共 100 条数据,所以为了爬取所有数据,我们需要在适当的时候模拟手机上拉的操作,已加载更多的数据
综上,这里总结出基本爬取流程
遍历现有的电影条目,依次模拟点击每个电影条目,进入详情页
爬取详情页的数据,爬取完毕后模拟点击回退按钮的操作,返回首页
当首页的所有电影条目即将爬取完毕时,模拟上拉操作,加载更多数据
在爬取过程中,将已经爬取的数据记录下来,以免重复爬取
100 条数据爬取完毕后,终止爬取
基本实现
在编写代码的过程中,我们用 Appium 观察现有的 App 的源代码,以便编写节点的提取规则。 首先启动 Appium 服务,然后启动 Session , 打开电脑端的调试窗口
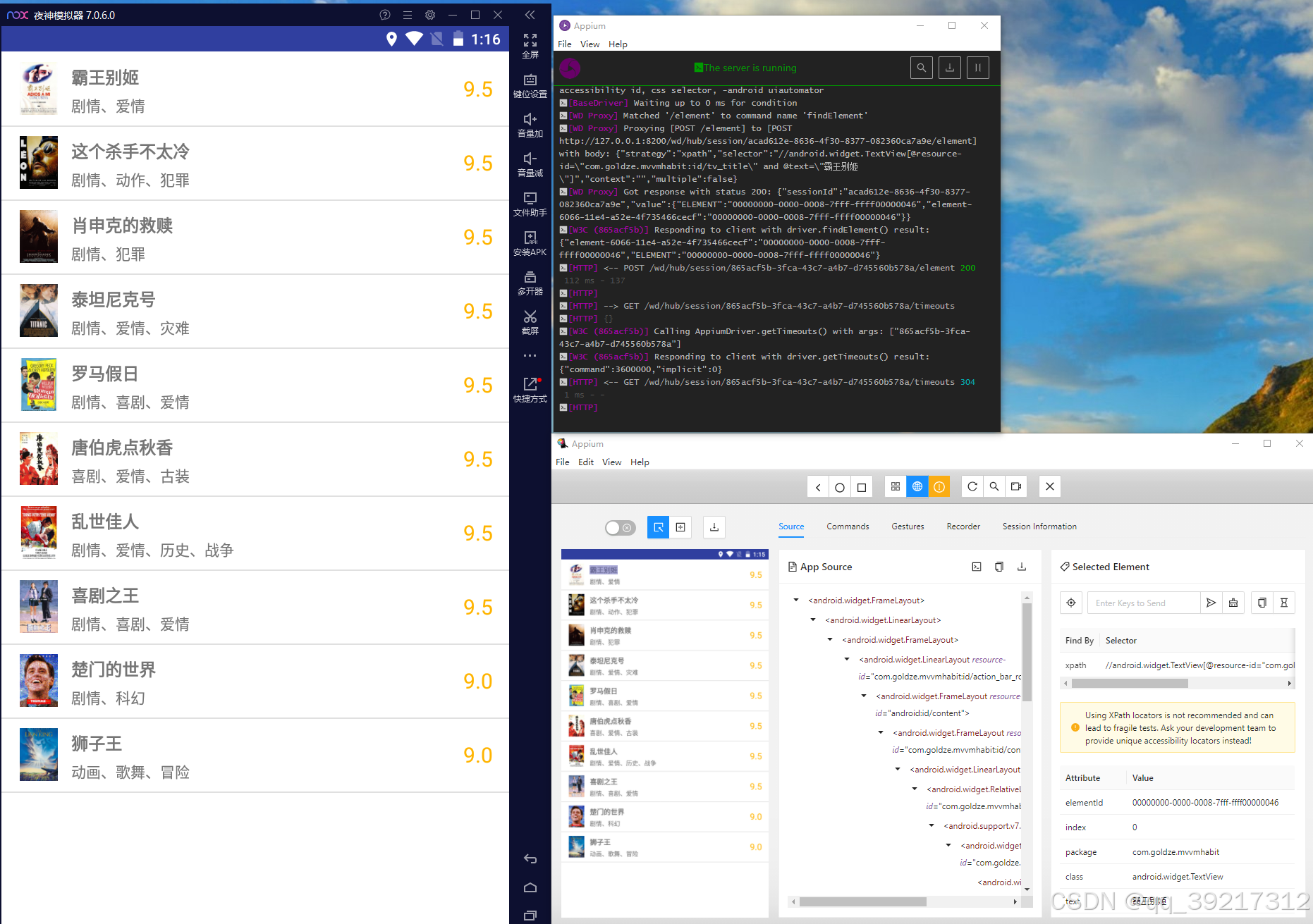
首先观察一些首页各个电影条目对应的 UI 树是怎样的。 通过观察可以发现,每个电影条目都是一个 android.widget.LinearLayout 节点, 该节点带有一个属性 resoutce-id 为 com.goldze.mvvmhabit:id/item , 条目内部的标题是一个 android.widget.TextView 节点,该节点带有一个属性 resource-id , 属性值是 com.goldze.mvvmhabit:id/tv_title, 我们可以选中所有的电影条目节点,同时记录电影标题去重
去重的目的: 因为对已经被渲染出来但是没有呈现在屏幕上的节点,我们是无法获取其信息的。在不断上拉爬取的过程中,我们同一时刻只能获取屏幕中能看到的所有电影条目的节点,被滑动出屏幕外的节点已经获取不到了。所有需要记录一下已经爬取的电影条目节点,以便下次滑动完毕后可以接着上一次爬取。由于此案例中的电影标题不存在重复,因此我们就用它来实现记录和去重
接下来做一些初始化声明
from appium import webdriver
from appium.options.android import UiAutomator2Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from selenium.common.exceptions import NoSuchElementExceptionSERVER = 'http://localhost:4723/wd/hub'
DESIRED_CAPABILITIES = {'platformName': 'Android','deviceName': 'LIO_AN00','appPackage': 'com.goldze.mvvmhabit','appActivity': '.ui.MainActivity','noReset': True
}
PACKAGE_NAME = DESIRED_CAPABILITIES['appPackage']
TOTAL_NUMBER = 100
这里我们首先声明了 SERVER 变量, 即 Appium 在本地启动的服务地址。 接着声明了 DESITED_CAPABILITIES , 这就是 Appium 启动示例 App 的配置参数,其中 deviceName 需要更改成自己手机的 model 名称, 可以使用 adb devices –l 通过 cmd 获取。另外,这里额外声明了一个变量 PACKAGE_NAME 即包名, 这是为后续编写获取节点的逻辑准备的。 最后声明 TOTAL_NUMBER 为 100 , 代表电影条目的总数为 100 , 之后以此为判断终止爬取
接下来我么声明 driver 对象, 并初始化一些必要的对象和变量
driver = webdriver.Remote(SERVER, options=UiAutomator2Options().load_capabilities(DESIRED_CAPABILITIES))
wait = WebDriverWait(driver, 30)
window_size = driver.get_window_size()
window_width, window_height = window_size.get('width'), window_size.get('height')
这里的 wait 变量就是一个 WebDriverWait 对象, 调用它的 until 方法可以实现如果查找到目标接节点就立即返回,如果等待 30 秒还查找不到目标节点就抛出异常。 我们还声明了 window_width, window_height 变量, 分别代表屏幕的宽高
初始化工作完成,下面爬取首页的所有电影条目
def scrape_index():items = wait.until(EC.presence_of_all_elements_located((By.XPATH, f'//android.widget.LinearLayout[@resource-id="{PACKAGE_NAME}:id/item"]')))return items
这里实现了一个 scrape_index 方法, 使用 XPath 选择对应的节点, 开头的 // 代表匹配根节点的所有子孙节点,即所有符合后面条件的节点都会被筛选出来, 这里对节点名称 android.widget.LinearLayout 和 属性 resource-id 进行了组合匹配。 在外层调用了 wait 变量的 until 方法,最后的结果就是如果符合条件的节点加载出来看, 就立即把这个节点赋值为 items 变量,并返回 items ,否则抛出超时异常
所以在正常情况下,使用 scrape_index 方法可以获得首页上呈现的所有电影条目数据
接下来就可以定义一个 main 方法来调用 scrape_index 方法了
from loguru import logger
def main():elements = scrape_index()for element in elements:element_data = scrape_detail(element)logger.debug(f'scraped data {element_data}')if __name__ == '__main__':main()
这里在 main 方法中首先调用 scrape_index 方法提取了当前首页的所有节点,然后遍历这些节点,并想通过一个 scrape_detail 方法提取每部电影的详情信息,最后返回并输出日志
那么问题明确了,scrape_detail 方法如何实现?大致思考一下,可以想到该方法需要做到如下三件事
模拟点击 element , 即首页的电影条目节点
进入详情页后爬取电影信息
点击回退按钮后返回首页
所以这个方法实现为
def scrape_detail(element):logger.debug(f'scraping {element}')element.click()wait.until(EC.presence_of_element_located((By.ID, f'{PACKAGE_NAME}:id/detail')))title = wait.until(EC.presence_of_element_located((By.ID, f'{PACKAGE_NAME}:id/title'))).get_attribute('text')categories = wait.until(EC.presence_of_element_located((By.ID, f'{PACKAGE_NAME}:id/categories_value'))).get_attribute('text')score = wait.until(EC.presence_of_element_located((By.ID, f'{PACKAGE_NAME}:id/score_value'))).get_attribute('text')minute = wait.until(EC.presence_of_element_located((By.ID, f'{PACKAGE_NAME}:id/minute_value'))).get_attribute('text')published_at = wait.until(EC.presence_of_element_located((By.ID, f'{PACKAGE_NAME}:id/published_at_value'))).get_attribute('text')drama = wait.until(EC.presence_of_element_located((By.ID, f'{PACKAGE_NAME}:id/drama_value'))).get_attribute('text')driver.back()return {'title': title,'categories': categories,'score': score,'minute': minute,'published_at': published_at,'drama': drama }
实现该方法需要先弄清楚详情页每个及诶蒂娜对应的节点名称, 属性都是怎样的,于是再次打开调试窗口,点击一个电影标题进入详情页, 查看器 DOM 树
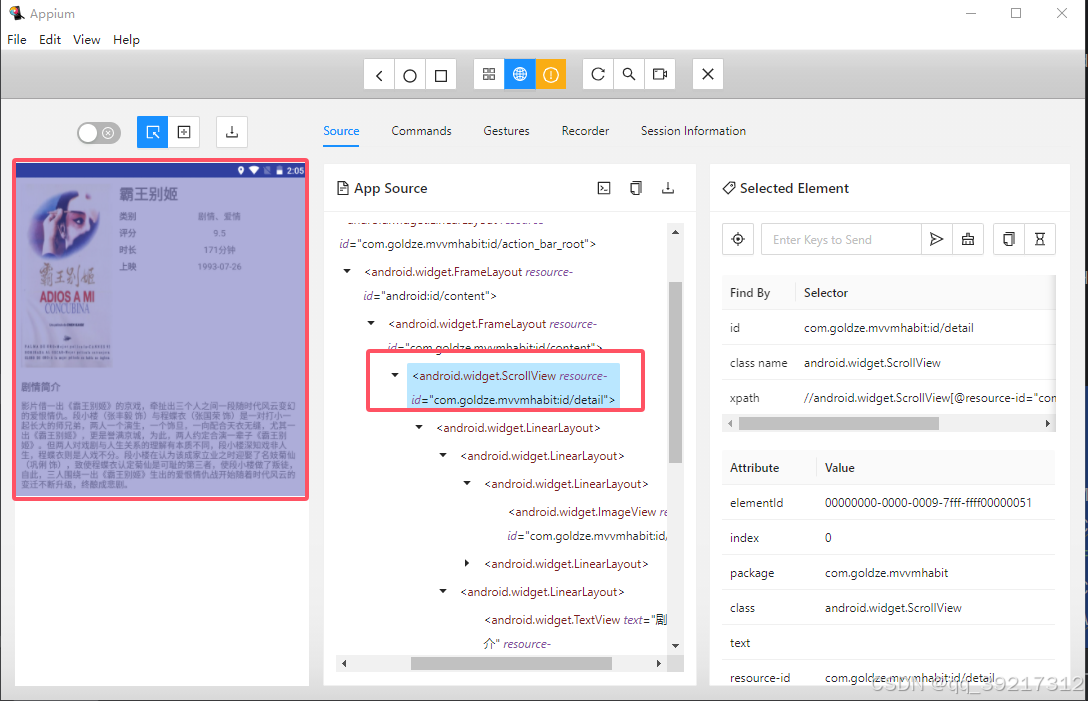
可以观察到整个详情页对应一个 android.widget.ScrollView 节点,其包含的 resource-id 属性值为 com.goldze.mnnmhabit:id/detail 。详情页上的标题,类别,评分,时长,上映时间,剧情简介页都有各自的节点名称和 resource-id , 这里就不展开描述了, 从 Appium 的 Source 面板即可查看
在 scrape_detail 方法中,首先调用了 element 的click 方法进入对应的详情页,然后等待整个详情页的信息(即 com.goldze.mnnmhabit:id/detail )加载出来,之后顺次爬取了标题,类别,评分,时长,上映时间,剧情简介,爬取完毕后抹蜜点击回退按钮,最后将所有爬取的内容构成一个字典返回
其实现在,我们已经可以成功获取首页最开始加载的几条电影信息了,执行一下代码
部分输出内容
2024-08-16 16:05:22.177 | DEBUG | __main__:scrape_detail:32 - scraping <appium.webdriver.webelement.WebElement (session="c9f0c1dc-d98a-45bc-b65f-60c5b3831219", element="00000000-0000-0015-7fff-ffff00000011")>
2024-08-16 16:05:24.149 | DEBUG | __main__:main:62 - scraped data {'title': '霸王别姬', 'categories': '剧情、爱情', 'score': '9.5', 'minute': '171分钟', 'published_at': '1993-07-26', 'drama': '影片借一出《霸王别姬》的京戏,牵扯出三个人之间一段随时代风云变幻的爱恨情仇。段小楼(张丰毅 饰)与程蝶衣(张国荣 饰)是一对打小一起长大的师兄弟,两人一个演生,一个饰旦,一向配合天衣无缝,尤其一出《霸王别姬》,更是誉满京城,为此,两人约定合演一辈子《霸王别姬》。但两人对戏剧与人生关系的理解有本质不同,段小楼深知戏非人生,程蝶衣则是人戏不分。段小楼在认为该成家立业之时迎娶了名妓菊仙(巩俐 饰),致使程蝶衣认定菊仙是可耻的第三者,使段小楼做了叛徒,自此,三人围绕一出《霸王别姬》生出的爱恨情仇战开始随着时代风云的变迁不断升级,终酿成悲剧。'}
上拉加载更多内容
现在在上面代码的基础上,加入上拉加载更多数据的逻辑,因此需要判断什么时候上拉加载数据。想想我们平时在浏览器浏览数据的时候是怎么操作的? 一般是在即将看完的时候上拉,那这里页一样,可以让程序在遍历到位于偏下方的电影条目的时候开始上拉。例如,当爬取的节点对应的电影条目差不多位于页面高度的 80% 时,就触发上拉加载,将 main 方法改写如下
def main():elements = scrape_index()for element in elements:element_location = element.locationelement_y = element_location.get('y')if element_y / window_height > 0.5:logger.debug(f'scroll up')scroll_up()element_data = scrape_detail(element)logger.debug(f'scraped data {element_data}')
这里遍历是判断了 element 的位置,获取了其 y 的坐标值,当该值小于页面高度的 80% 时,触发上拉加载,加载的方法是 scroll_up 其定义如下
def scroll_up():driver.swipe(window_width * 0.5, window_height * 0.8, window_width * 0.5, window_height * 0.5, 1000)
方法 driver.swipe(start_x, start_y, end_x, end_y, 时间)
start_x, start_y : 开始上拉的 横纵坐标
end_x, end_y:上拉到的位置的横纵坐标
时间:上拉用时多久
去重,终止和保存数据
在本节开始部分我们曾提到,需要额外添加根据标题进行去重和判断终止的逻辑,所以在遍历首页中每个电影条目的时候还需要提取一下标题,然后将其存入一个全局变量中
def get_element_title(element):try:element_title = element.find_element(by=By.ID, value=f'{PACKAGE_NAME}:id/tv_title').get_aribute('text')return element_titleexcept NoSuchElementException:return None
这里定义了一个 get_element_title 方法,该方法接收一个 element 参数, 即首页电影条目对应的节点对象,然后提取其标题文本并返回,最后将 main 方法修改如下
scraped_titles = []
def main():while len(scraped_titles) < TOTAL_NUMBER:elements = scrape_index()for element in elements:element_title = get_element_title(element)if not element_title or element_title in scraped_titles:continueelement_location = element.locationelement_y = element_location.get('y')if element_y / window_height > 0.5:logger.debug(f'scroll up')scroll_up()element_data = scrape_detail(element)scraped_titles.append(element_title)logger.debug(f'scraped data {element_data}')
这里在 main 方法里添加了 while 循环, 入股哦爬取的电影条目数量尚未达到数量 TOTAL_NUMBER, 就接着爬取, 直到爬取完毕。 其中就调用 get_element_title 方法提取了电影标题,然后将已经爬取的电仪标题存储在全局变量 scraped_titles 中, 如果经判断, 当前节点对应的电影已经爬取过了, 就跳过, 否则接着爬取,爬取完毕后将标题存到 scraped_titles 变量里,这样就实现了去重
保存数据
最后,可以再添加一个保存数据的逻辑,将爬取的数据保存到本地 movie 文件夹中, 数据以 JSON 形式保存,代码如下
import os
import jsonOUTPUT_FOLDER = 'movie'
os.path.exists(OUTPUT_FOLDER) or os.makedirs(OUTPUT_FOLDER)def save_date(element_data):with open(f'{OUTPUT_FOLDER}/{element_data.get("title")}.json', 'w', encoding='utf-8') as f:f.write(json.dumps(element_data, ensure_ascii=False, indent=2))logger.debug(f'saved as file {element_data.get("title")}.json')
最后在 main 方法中添加调用逻辑即可
完整代码
from appium import webdriver
from appium.options.android import UiAutomator2Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from selenium.common.exceptions import NoSuchElementException
from loguru import logger
import os
import jsonSERVER = 'http://localhost:4723/wd/hub'
DESIRED_CAPABILITIES = {'platformName': 'Android','deviceName': 'LIO_AN00','appPackage': 'com.goldze.mvvmhabit','appActivity': '.ui.MainActivity','noReset': True
}
OUTPUT_FOLDER = 'movie'
os.path.exists(OUTPUT_FOLDER) or os.makedirs(OUTPUT_FOLDER)
PACKAGE_NAME = DESIRED_CAPABILITIES['appPackage']
TOTAL_NUMBER = 100scraped_titles = []
driver = webdriver.Remote(SERVER, options=UiAutomator2Options().load_capabilities(DESIRED_CAPABILITIES))
wait = WebDriverWait(driver, 30)
window_size = driver.get_window_size()
window_width, window_height = window_size.get('width'), window_size.get('height')def scrape_index():items = wait.until(EC.presence_of_all_elements_located((By.XPATH, f'//android.widget.LinearLayout[@resource-id="{PACKAGE_NAME}:id/item"]')))return itemsdef scrape_detail(element):logger.debug(f'scraping {element}')element.click()wait.until(EC.presence_of_element_located((By.ID, f'{PACKAGE_NAME}:id/detail')))title = wait.until(EC.presence_of_element_located((By.ID, f'{PACKAGE_NAME}:id/title'))).get_attribute('text')categories = wait.until(EC.presence_of_element_located((By.ID, f'{PACKAGE_NAME}:id/categories_value'))).get_attribute('text')score = wait.until(EC.presence_of_element_located((By.ID, f'{PACKAGE_NAME}:id/score_value'))).get_attribute('text')minute = wait.until(EC.presence_of_element_located((By.ID, f'{PACKAGE_NAME}:id/minute_value'))).get_attribute('text')published_at = wait.until(EC.presence_of_element_located((By.ID, f'{PACKAGE_NAME}:id/published_at_value'))).get_attribute('text')drama = wait.until(EC.presence_of_element_located((By.ID, f'{PACKAGE_NAME}:id/drama_value'))).get_attribute('text')driver.back()return {'title': title,'categories': categories,'score': score,'minute': minute,'published_at': published_at,'drama': drama}def scroll_up():print(window_height)print(window_height * 0.8)print(window_height * 0.5)driver.swipe(window_width * 0.5, window_height * 0.8, window_width * 0.5, window_height * 0.5, 1000)def get_element_title(element):try:element_title = element.find_element(by=By.ID, value=f'{PACKAGE_NAME}:id/tv_title').get_attribute('text')return element_titleexcept NoSuchElementException:return Nonedef save_date(element_data):with open(f'{OUTPUT_FOLDER}/{element_data.get("title")}.json', 'w', encoding='utf-8') as f:f.write(json.dumps(element_data, ensure_ascii=False, indent=2))logger.debug(f'saved as file {element_data.get("title")}.json')def main():while len(scraped_titles) < TOTAL_NUMBER:elements = scrape_index()for element in elements:element_title = get_element_title(element)if not element_title or element_title in scraped_titles:continueelement_location = element.locationelement_y = element_location.get('y')if element_y / window_height > 0.5:logger.debug(f'scroll up')scroll_up()element_data = scrape_detail(element)scraped_titles.append(element_title)save_date((element_data))logger.debug(f'scraped data {element_data}')if __name__ == '__main__':main()
相关文章:
基于 Appium 的 App 爬取实战
除了运行 Appium 的基本条件外,还要一个日志输出库 安装: pip install loguru 思路分析 首先我们观察一下整个 app5 的交互流程,其首页分条显示了电影数据, 每个电影条目都包括封面,标题, 类别和评分 4…...

nvm与node安装
参考: 一文搞定NVM安装所有问题NVM UI解决nodejs下载慢问题 node_mirror: http://npmmirror.com/mirrors/node/ npm_mirror: http://registry.npmmirror.com/mirrors/npm/解决nvm list available报错问题 Could not retrieve https://npm.taobao.org/mirrors/node/…...

【电子通识】什么是MSL湿敏等级
潮敏失效是塑料封装表贴器件在高温焊接工艺中表现出来的特殊的失效现象。 造成此类问题的原因是器件内部的潮气膨胀后使得器件发生损坏。 MSL是“Moisture Sensitivity Level(湿气敏感性等级)”的缩写,针对需进行回流焊的产品设定了MSL基准。…...

【ARM 芯片 安全与攻击 5.4 -- Meltdown 攻击与防御介绍】
文章目录 什么是 Meltdown 攻击?Meltdown 攻击的基本原理Meltdown 攻击代码示例Meltdown 攻击在芯片中的应用应用场景Meltdown 攻击与瞬态攻击、测信道攻击的关系针对 Meltdown 攻击的防御硬件级防御Summary什么是 Meltdown 攻击? Meltdown 攻击是一种利用处理器乱序执行(o…...

Django 后端架构开发:分页器到中间件开发
🚀 Django 后端架构开发:分页器到中间件开发 🚀 🔹 应用样式:上下翻页 分页功能在处理大量数据时非常有用。通过上下翻页,我们可以让用户轻松浏览数据。以下是一个展示产品列表的分页示例: fr…...

亲测解决The client socket has failed to connect to
这个问题是因为深度学习的程序(服务)跟本地主机连接不上,解决方法是确认rank起始数为0。 报错原文 [W socket.cpp:663] [c10d] The client socket has failed to connect to [csdn-xiaohu]:12345 (errno: 22 - Invalid argument).解决方法 …...

Intel ACRN 安装WIN10 VM
上一篇帖子记录了ACRN运行rt linux,这篇帖子记录一下最近倒腾出来的WIN10。目前架构如下 ACRN可以把它理解为一个基于Linux类似软件的Type1 Hypervisor,基于Linux去做而不是baremetal是为了更方便去配置资源。 首先我们得有两台电脑,一台是开…...

贷齐乐案例
源码分析: <?php // 设置 HTTP 头部,指定内容类型为 text/html,字符集为 utf-8 header("Content-type: text/html; charsetutf-8"); // 引入数据库配置文件 require db.inc.php; // 定义函数 dhtmlspecialchars,用…...

[Qt][Qt 网络][下]详细讲解
目录 1.TCP Socket1.核心API概览2.回显服务器3.回显客户端 2.HTTP Client3.其他模块 1.TCP Socket 1.核心API概览 核⼼类是两个:QTcpServer和QTcpSocketQTcpServer用于监听端口,和获取客户端连接 listen(const QHostAddress&, quint16 port)&#…...

十三、OpenCVSharp的目标检测
文章目录 简介一、传统目标检测方法1. 基于滑动窗口的检测2. 特征提取与分类器结合(如 HOG + SVM)3. 级联分类器二、基于深度学习的目标检测1. YOLO 系列算法2. SSD 算法3. Faster R-CNN 算法三、深度学习目标检测模型的训练和部署四、目标检测的性能评估指标1. 准确率、召回…...

STM32标准库学习笔记-6.定时器-输入捕获
参考教程:【STM32入门教程-2023版 细致讲解 中文字幕】 定时器输入捕获 IC(Input Capture)输入捕获输入捕获模式下,当通道输入引脚出现指定电平跳变时,当前CNT的值将被锁存到CCR中,可用于测量PWM波形的频率…...

vue前端可以完整的显示编辑子级部门,用户管理可以为用户分配角色和部门?
用户和角色是一对多的关系用户和部门是多对多得关系<template><div class="s"><!-- 操作按钮 --><div class="shang"><el-input v-model="searchText" placeholder="请输入搜索关键词" style="width:…...

量化交易的基石:ExchangeSdk
作为长期混迹在合约市场的老韭菜来说,已不能满足与手动下单来亏钱,必须得通过脚本来加速,为了达到这个目的就产生了项目。目前封装的主要是合约的API接口,不支持现货交易。 Github: https://github.com/silently9527/exchange-sdk…...

【区块链+金融服务】基于区块链的一站式绿色金融开放平台 | FISCO BCOS应用案例
科技的进步为绿色金融发展提供了新的机遇,但银行、企业、第三方金融机构等在进行绿色金融业务操作过程中, 存在着相关系统和服务平台建设成本高、迭代难度大、数据交互弱、适配难等痛点。 基于此,中碳绿信采用国产开源联盟链底层平台 FISCO …...

使用Python实现深度学习模型:智能娱乐与虚拟现实技术
介绍 智能娱乐与虚拟现实(VR)技术正在改变我们的娱乐方式。通过深度学习模型,我们可以创建更加沉浸式和智能化的娱乐体验。本文将介绍如何使用Python和深度学习技术来实现智能娱乐与虚拟现实的应用。 环境准备 首先,我们需要安装一些必要的Python库: pip install pand…...

亚马逊云科技产 Amazon Neptune 图数据库服务体验
目录 图数据库为什么使用图数据库Amazon Neptune实践登陆创建 S3 存储桶notebook图神经网络快速构建加载数据配置端点Gremlin 查询删除环境删除 S3 存储桶 总结 图数据库 图数据库是一种专门用于存储和处理图形数据结构的数据库管理系统。图形数据结构由节点(Node&…...
【网络安全】重置密码token泄露,实现账户接管
未经许可,不得转载。 文章目录 正文 正文 对某站点测试过程中,登录账户触发忘记密码功能点,其接口、请求及响应如下: PUT /api/v1/people/forgot_password 可以看到,重置密码token和密码哈希均在响应中泄露。 删除co…...

计算机基础知识复习8.13
cookie和session区别 cookie:是服务器发送到浏览器,并保存在浏览器端的一小块数据 浏览器下次访问服务时,会自动携带该块数据,将其发送给服务器 session:是javaEE标准,用于在服务端记录客户端信息 数据存放在服务端更加安全&a…...

Unity URP无光照下Shadow 制作 <二> 合批处理
闲谈 相信大家在日常工作中发现了一个问题 , urp下虽然可以做到3个Pass 去写我们想要的效果,但是,不能合批(不能合批,那不是我们CPU要干冒烟~!) 好家伙,熊猫老师的偏方来了 &#x…...

微乐校园pf
TOC springboot451微乐校园pf 绪论 1.1 研究背景 当前社会各行业领域竞争压力非常大,随着当前时代的信息化,科学化发展,让社会各行业领域都争相使用新的信息技术,对行业内的各种相关数据进行科学化,规范化管理。这…...

ARM Cortex-M处理器仿真与Iris组件深度解析
1. ARM Cortex-M系列处理器仿真技术概述在嵌入式系统开发领域,处理器仿真技术已经成为不可或缺的工具链环节。作为ARM架构中专门面向微控制器市场的产品线,Cortex-M系列处理器凭借其优异的能效比和实时性能,广泛应用于物联网终端、工业控制和…...

高速SOIC插座技术解析:从原理到工程实践
1. 高速SOIC插座的技术演进与核心价值在射频和高速数字电路设计中,工程师们经常面临一个经典矛盾:既要保证芯片测试的便捷性,又不能牺牲信号完整性。传统DIP插座在MHz级频率下尚能应付,但当频率攀升至GHz领域时,其机械…...

基于Docker Compose的容器化数据抓取平台OpenClaw部署与实战
1. 项目概述:一个容器化的开源自动化抓取与处理平台最近在折腾一些数据采集和自动化处理的工作流,发现一个挺有意思的项目:alexleach/openclaw-compose。光看名字,openclaw直译是“开放之爪”,compose则明确指向了 Doc…...

终极ASCII流程图绘制指南:5分钟从零开始掌握专业文本图表制作
终极ASCII流程图绘制指南:5分钟从零开始掌握专业文本图表制作 【免费下载链接】asciiflow ASCIIFlow 项目地址: https://gitcode.com/gh_mirrors/as/asciiflow ASCIIFlow是一款完全免费、无需安装的在线ASCII流程图绘制工具,让任何人都能用简单的…...

终极iOS弹窗解决方案SDCAlertView:10个强大功能超越系统UIAlertController
终极iOS弹窗解决方案SDCAlertView:10个强大功能超越系统UIAlertController 【免费下载链接】SDCAlertView The little alert that could 项目地址: https://gitcode.com/gh_mirrors/sd/SDCAlertView SDCAlertView是一款强大的iOS弹窗解决方案,它为…...

面试鸭:一站式面试题库解决方案,助你轻松备战技术面试
面试鸭:一站式面试题库解决方案,助你轻松备战技术面试 【免费下载链接】mianshiya-public 持续维护的企业面试题库网站,帮你拿到满意 offer!⭐️ 2026年最新Java面试题、前端面试题、AI大模型面试题、AI Agent面试题、RAG面试题、…...

回流平台深耕闲置翡翠流通,以数字化服务激活珠宝产业新动能
据中国珠宝玉石首饰行业协会数据,我国珠宝玉石首饰产业市场规模持续扩大,翡翠玉石作为第二大珠宝消费品类,市场存量可观。与此同时,发达国家二手高端消费品交易占整个高端消费品市场的20%至30%,我国目前占比约5%&#…...

IEA-15-240-RWT:15MW海上风机开源模型的完整入门指南
IEA-15-240-RWT:15MW海上风机开源模型的完整入门指南 【免费下载链接】IEA-15-240-RWT 15MW reference wind turbine repository developed in conjunction with IEA Wind 项目地址: https://gitcode.com/gh_mirrors/ie/IEA-15-240-RWT 你是否曾经想要研究海…...

OLAP引擎全景图鉴:从架构原理到场景适配,深度解析Impala/Druid/Presto/Kylin/ClickHouse的选型之道
1. OLAP技术全景解析:从基础概念到架构分类 当你打开手机查看每日步数统计,或是浏览电商平台的年度消费报告时,背后支撑这些数据分析的正是OLAP技术。OLAP(在线分析处理)就像一位不知疲倦的数据分析师,能够…...

用74LS181和6116芯片手把手复现CPU累加器:计算机组成原理实验避坑指南
74LS181与6116芯片实战:从零构建CPU累加器的硬件艺术 实验室的灯光下,几块看似普通的集成电路板正等待着被赋予生命。对于计算机专业的学生和硬件爱好者而言,用74LS181算术逻辑单元(ALU)和6116静态RAM芯片亲手搭建一个CPU累加器,…...