Pytorch常用训练套路框架(CPU)
文章目录
- 1. 数据准备
- 示例:加载 CIFAR-10 数据集
- 2. 模型定义
- 示例:定义一个简单的卷积神经网络
- 3. 损失函数和优化器
- 示例:定义损失函数和优化器
- 4. 训练循环
- 示例:训练循环
- 5. 评估和测试
- 示例:评估模型
- 6. 保存和加载模型
- 示例:保存和加载模型
- 7. 完整案例:训练 CIFAR-10 分类模型
- 解释
在 PyTorch 中,模型训练通常遵循一个标准的流程,包括数据准备、模型定义、损失函数和优化器的选择、训练循环以及评估和测试。以下是一个详细的步骤介绍:
1. 数据准备
首先,需要准备好训练和测试数据。通常使用 torchvision.datasets 加载内置数据集,或者使用自定义数据集。数据加载后,使用 torch.utils.data.DataLoader 进行批量加载。
示例:加载 CIFAR-10 数据集
from torchvision import datasets, transforms
from torch.utils.data import DataLoader# 定义图像转换
transform = transforms.Compose([transforms.Resize((256, 256)),transforms.RandomCrop(224),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])# 加载数据集
train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)# 使用 DataLoader 加载数据
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)
2. 模型定义
定义一个神经网络模型,通常继承自 torch.nn.Module,并在 __init__ 方法中定义网络层,在 forward 方法中定义前向传播过程。
示例:定义一个简单的卷积神经网络
import torch.nn as nn
import torch.nn.functional as Fclass SimpleCNN(nn.Module):def __init__(self):super(SimpleCNN, self).__init__()self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1)self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1)self.fc1 = nn.Linear(64 * 56 * 56, 128)self.fc2 = nn.Linear(128, 10)def forward(self, x):x = F.relu(self.conv1(x))x = F.max_pool2d(x, 2)x = F.relu(self.conv2(x))x = F.max_pool2d(x, 2)x = x.view(x.size(0), -1)x = F.relu(self.fc1(x))x = self.fc2(x)return xmodel = SimpleCNN()
3. 损失函数和优化器
选择合适的损失函数和优化器。常见的损失函数包括 nn.CrossEntropyLoss 用于分类任务,nn.MSELoss 用于回归任务。优化器通常使用 torch.optim 模块中的优化器,如 optim.SGD 或 optim.Adam。
示例:定义损失函数和优化器
import torch.optim as optim# 定义损失函数
criterion = nn.CrossEntropyLoss()# 定义优化器
optimizer = optim.Adam(model.parameters(), lr=0.001)
4. 训练循环
编写训练循环,包括前向传播、计算损失、反向传播和参数更新。通常还会包括模型保存和日志记录。
示例:训练循环
def train(model, train_loader, criterion, optimizer, num_epochs):model.train()for epoch in range(num_epochs):for images, labels in train_loader:# 前向传播outputs = model(images)loss = criterion(outputs, labels)# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')# 训练模型
train(model, train_loader, criterion, optimizer, num_epochs=10)
5. 评估和测试
在训练完成后,使用测试数据集评估模型的性能。通常包括计算准确率、损失等指标。
示例:评估模型
def evaluate(model, test_loader, criterion):model.eval()total_loss = 0.0correct = 0total = 0with torch.no_grad():for images, labels in test_loader:outputs = model(images)loss = criterion(outputs, labels)total_loss += loss.item()_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()print(f'Test Loss: {total_loss/len(test_loader):.4f}, Accuracy: {100 * correct / total:.2f}%')# 评估模型
evaluate(model, test_loader, criterion)
6. 保存和加载模型
训练完成后,可以保存模型参数以便后续使用。
示例:保存和加载模型
# 保存模型
torch.save(model.state_dict(), 'model.pth')# 加载模型
model = SimpleCNN()
model.load_state_dict(torch.load('model.pth'))
7. 完整案例:训练 CIFAR-10 分类模型
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torchvision import datasets, transforms
from torch.utils.data import DataLoader# 1. 数据准备
transform = transforms.Compose([transforms.Resize((256, 256)),transforms.RandomCrop(224),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)# 2. 模型定义
class SimpleCNN(nn.Module):def __init__(self):super(SimpleCNN, self).__init__()self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1)self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1)self.fc1 = nn.Linear(64 * 56 * 56, 128)self.fc2 = nn.Linear(128, 10)def forward(self, x):x = F.relu(self.conv1(x))x = F.max_pool2d(x, 2)x = F.relu(self.conv2(x))x = F.max_pool2d(x, 2)x = x.view(x.size(0), -1)x = F.relu(self.fc1(x))x = self.fc2(x)return xmodel = SimpleCNN()# 3. 损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)# 4. 训练循环
def train(model, train_loader, criterion, optimizer, num_epochs):model.train()for epoch in range(num_epochs):for images, labels in train_loader:outputs = model(images)loss = criterion(outputs, labels)optimizer.zero_grad()loss.backward()optimizer.step()print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')train(model, train_loader, criterion, optimizer, num_epochs=10)# 5. 评估和测试
def evaluate(model, test_loader, criterion):model.eval()total_loss = 0.0correct = 0total = 0with torch.no_grad():for images, labels in test_loader:outputs = model(images)loss = criterion(outputs, labels)total_loss += loss.item()_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()print(f'Test Loss: {total_loss/len(test_loader):.4f}, Accuracy: {100 * correct / total:.2f}%')evaluate(model, test_loader, criterion)# 6. 保存和加载模型
torch.save(model.state_dict(), 'model.pth')model = SimpleCNN()
model.load_state_dict(torch.load('model.pth'))
解释
- 数据准备:加载 CIFAR-10 数据集,并应用一系列图像转换操作。
- 模型定义:定义一个简单的卷积神经网络
SimpleCNN。 - 损失函数和优化器:选择交叉熵损失函数和 Adam 优化器。
- 训练循环:编写训练循环,包括前向传播、计算损失、反向传播和参数更新。
- 评估和测试:使用测试数据集评估模型的性能,并计算准确率和损失。
- 保存和加载模型:训练完成后,保存模型参数以便后续使用。
相关文章:
)
Pytorch常用训练套路框架(CPU)
文章目录 1. 数据准备示例:加载 CIFAR-10 数据集 2. 模型定义示例:定义一个简单的卷积神经网络 3. 损失函数和优化器示例:定义损失函数和优化器 4. 训练循环示例:训练循环 5. 评估和测试示例:评估模型 6. 保存和加载模…...

C++ | Leetcode C++题解之第338题比特位计数
题目: 题解: class Solution { public:vector<int> countBits(int n) {vector<int> bits(n 1);for (int i 1; i < n; i) {bits[i] bits[i & (i - 1)] 1;}return bits;} };...
智慧校园云平台电子班牌系统源码,智慧教育一体化云解决方案
智慧校园云平台电子班牌系统,利用先进的云计算技术,将教育信息化资源和教学管理系统进行有效整合,实现生态基础数据共享、应用生态统一管理,为智慧教育建设的统一性,稳定性,可扩展性,互通性提供…...

数据库系统 第17节 数据仓库 案例赏析
下面我将通过几个具体的案例来说明数据仓库如何在不同的行业中发挥作用,并解决实际业务问题。 案例 1: 零售业 背景: 一家大型零售商希望改进其库存管理和市场营销策略,以提高销售额和顾客满意度。 解决方案: 数据仓库: 构建一个数据仓库࿰…...
硬件面试经典 100 题(71~90 题)
71、请问下图电路的作用是什么? 该电路实现 IIC 信号的电平转换(3.3V 和 5V 电平转换),并且是双向通信的。 上下两路是一样的,只分析 SDA 一路: 1) 从左到右通信(SDA2 为输入状态&…...

【git】代理相关
问题: 开启了翻墙代理工具,拉取代码时报错:fatal: 无法访问 xxxx : Failed to connect to github.com port 443: 连接超时 解决: 0,取消代理仍然无法拉取 1,查看控制面板-网络与Internet-代理ÿ…...
方式和闭包函数方式定义gin中间件)
golang gin框架中创建自定义中间件的2种方式总结 - func(*gin.Context)方式和闭包函数方式定义gin中间件
在gin框架中,我们可以通过2种方式创建自定义中间件: 1. 直接定义一个类型为 func(*gin.Context)的函数或者方法 这种方式是我们常用的方式,也就是定义一个参数为*gin.Context的函数或者方法。定义的方法就是创建一个 参数类型为 gin.Handler…...

Linux高级编程 8.13 文件IO
一、文件IO 操作系统为了方便用户使用系统功能而对外提供的一组系统函数。称之为 系统调用(unistd.h) 其中有个 文件IO,一般都是对设备文件操作,当然也可以对普通文件进行操作。 这是一个基于Linux内核的没有缓存的IO机制 文件IO特性&…...

【k8s】ubuntu18.04 containerd 手动从1.7.15 换为1.7.20
ubutnu18.04之前手动安装了1.7.15现在下载1.7.20containerd-1.7.20-linux-amd64.tar.gz root@k8s-worker-i58265u:/home/zhangbin# root@k8s-worker-i58265u:/home/zhangbin# https://github.com/containerd/containerd/releases/download/v1.7.20/containerd-1.7.20-linux-am…...

常用浮动方式
目录 一、标准流 二、float浮动 三、 flex浮动 3.1flex组成 3.2 主轴对齐方式 3.3侧轴对齐方式 3.4修改主轴方向 3.5弹性盒子换行 3.6行对齐方式 一、标准流 标签在网页中的默认排布规则 例如: 块元素独占一行、行内元素可以一行显示多个 二、float浮动 让块…...

设计模式反模式:UML常见误用案例分析
文章目录 设计模式反模式:UML常见误用案例分析1. 反模式概述2. 反模式的 UML 图示误用2.1 God Object 反模式2.2 Spaghetti Code 反模式2.3 Golden Hammer 反模式2.4 Poltergeist 反模式 3. 总结 设计模式反模式:UML常见误用案例分析 在软件工程领域&am…...

Python编码系列—Python SQL与NoSQL数据库交互:深入探索与实战应用
🌟🌟 欢迎来到我的技术小筑,一个专为技术探索者打造的交流空间。在这里,我们不仅分享代码的智慧,还探讨技术的深度与广度。无论您是资深开发者还是技术新手,这里都有一片属于您的天空。让我们在知识的海洋中…...

贪心算法---跳跃游戏
题目: 给你一个非负整数数组 nums ,你最初位于数组的 第一个下标 。数组中的每个元素代表你在该位置可以跳跃的最大长度。 判断你是否能够到达最后一个下标,如果可以,返回 true ;否则,返回 false 。 思路…...
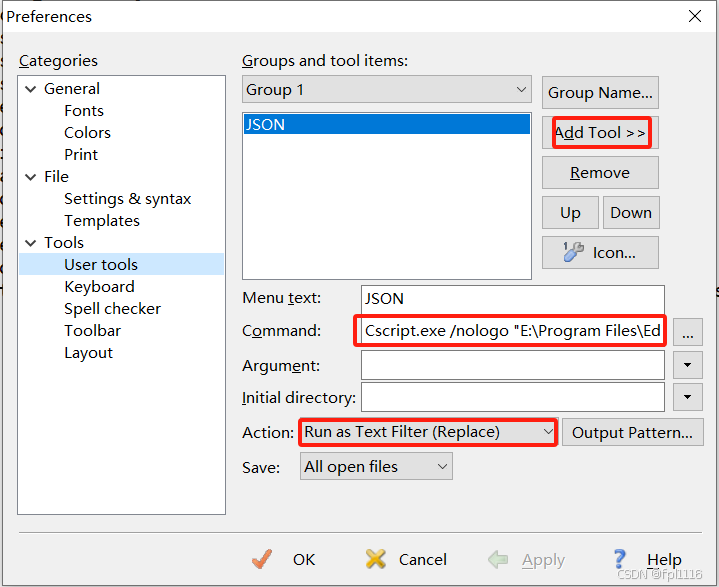
利用EditPlus进行Json数据格式化
利用EditPlus进行Json数据格式化 git下载地址:https://github.com/michael-deve/CommonData-EditPlusTools.git (安装过editplus的直接将里面的json.js文件复制走就行) 命令:Cscript.exe /nologo “D:\Program Files (x86)\EditPlus 3\json.js” D:\P…...
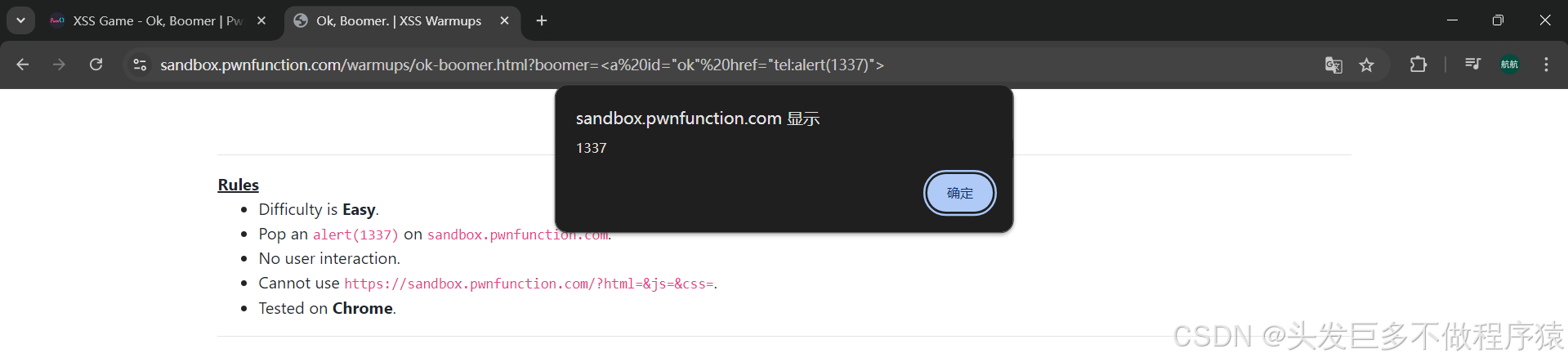
xss.function靶场(easy)
文章目录 第一关Ma Spaghet!第二关Jefff第三关Ugandan Knuckles第四关Ricardo Milos第五关Ah Thats Hawt第六关Ligma第七关Mafia第八关Ok, Boomer 网址:https://xss.pwnfunction.com/ 第一关Ma Spaghet! 源码 <!-- Challenge --> <h2 id"spaghet&qu…...
【LLM入门】Let‘s reproduce GPT-2 (124M)【完结,重新回顾一下,伟大!】
文章目录 03:43:05 SECTION 4: results in the morning! GPT-2, GPT-3 repro03:56:21 shoutout to llm.c, equivalent but faster code in raw C/CUDA【太牛了ba】03:59:39 summary, phew, build-nanogpt github repo 03:43:05 SECTION 4: results in the morning! GPT-2, GPT-…...

c语言----取反用什么符号
目录 前言 一、逻辑取反 二、按位取反 三、应用场景 前言 在C编程语言中,取反使用符号!表示逻辑取反,而使用~表示按位取反。 其中,逻辑取反!是将表达式的真值(非0值)转换为假(0),…...

【html+css 绚丽Loading】 - 000003 乾坤阴阳轮
前言:哈喽,大家好,今天给大家分享htmlcss 绚丽Loading!并提供具体代码帮助大家深入理解,彻底掌握!创作不易,如果能帮助到大家或者给大家一些灵感和启发,欢迎收藏关注哦 💕…...
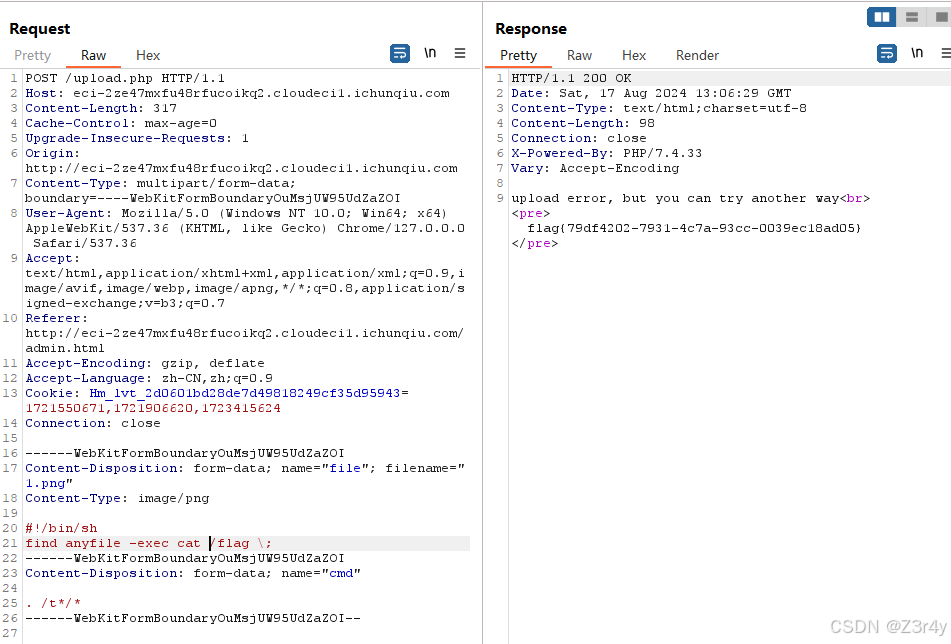
【Web】巅峰极客2024 部分题解
目录 EncirclingGame GoldenHornKing php_online admin_Test EncirclingGame 玩赢游戏就行 GoldenHornKing 利用点在传入的app 可以打python内存马 /calc?calc_reqconfig.__init__.__globals__[__builtins__][exec](app.add_api_route("/flag",lambda:__i…...

在AMD GPU上进行Grok-1模型的推理
Inferencing with Grok-1 on AMD GPUs — ROCm Blogs 我们展示了如何通过利用ROCm软件平台,能在AMD MI300X GPU加速器上无缝运行xAI公司的Grok-1模型。 介绍 xAI公司在2023年11月发布了Grok-1模型,允许任何人使用、实验和基于它构建。Grok-1的不同之处…...

pyecharts-assets终极指南:告别网络依赖,打造本地可视化环境
pyecharts-assets终极指南:告别网络依赖,打造本地可视化环境 【免费下载链接】pyecharts-assets 🗂 All assets in pyecharts 项目地址: https://gitcode.com/gh_mirrors/py/pyecharts-assets 还在为pyecharts图表加载慢而烦恼吗&…...
)
PyTorch实战:手把手教你处理Mini-ImageNet数据集(附100类标签映射文件)
PyTorch实战:从零构建Mini-ImageNet数据管道与标签映射系统 当你第一次打开Mini-ImageNet的压缩包时,可能会被三个看似友好的CSV文件迷惑——train.csv、val.csv和test.csv。但当你真正尝试用PyTorch加载这些数据时,才会发现它们就像IKEA的组…...

3大核心优势:为什么GanttProject能让你秒懂项目管理
3大核心优势:为什么GanttProject能让你秒懂项目管理 【免费下载链接】ganttproject Official GanttProject repository. 项目地址: https://gitcode.com/gh_mirrors/ga/ganttproject 你是否曾经面对复杂的项目计划感到无从下手?GanttProject这款免…...

深入AD9361:除了QPSK和FM,这颗射频芯片在Zynq平台上还能玩出什么花样?
深入AD9361:解锁Zynq平台上的射频创新潜能 当工程师们首次接触AD9361这颗射频芯片时,往往会被其标准应用场景如QPSK调制或FM收音所吸引。然而,这颗高度集成的RF收发器IC的真正价值,在于它为Zynq PSPL架构带来的无限可能性。本文将…...

Niagara Editor界面详解:从零上手视觉特效创作
1. 认识Niagara Editor:视觉特效的创作工坊 第一次打开Niagara Editor时,满屏的面板和按钮可能会让你感到不知所措。别担心,这就像走进一个设备齐全的厨房——虽然工具很多,但每样都有其特定用途。作为Unreal Engine的粒子特效系…...

小红书内容采集全攻略:XHS-Downloader开源工具完整指南
小红书内容采集全攻略:XHS-Downloader开源工具完整指南 【免费下载链接】XHS-Downloader 小红书(XiaoHongShu、RedNote)链接提取/作品采集工具:提取账号发布、收藏、点赞、专辑作品链接;提取搜索结果作品、用户链接&am…...

【AI面试临阵磨枪-56】大模型服务部署:Docker、K8s、GPU 调度、推理加速
一、 面试题目在生产环境中部署大模型服务时,你是如何结合 Docker 和 K8s 实现高效治理的?特别是在 GPU 调度(如共享、切分) 和 推理加速(如 vLLM, TensorRT-LLM) 方面有哪些实战经验?二、 知识…...

李辉《曾国藩日记》笔记:人到晚年,最重保全!
李辉《曾国藩日记》笔记:人到晚年,最重保全!原文:同治三年五月二十日早饭后清理文件。见客,坐见者二次,立见者一次。程希辕来,围棋二局,又观程与鲁秋航一局。习字一纸。巳刻见客二次…...

Zotero插件市场:一站式管理插件的终极解决方案
Zotero插件市场:一站式管理插件的终极解决方案 【免费下载链接】zotero-addons Zotero Add-on Market | Zotero插件市场 | Browsing, installing, and reviewing plugins within Zotero 项目地址: https://gitcode.com/gh_mirrors/zo/zotero-addons 还在为Zo…...

MCP服务器开源集市:AI智能体开发者的插件生态与实战指南
1. 项目概述:MCP服务器的开源集市最近在折腾AI智能体开发,特别是想让它们能更“主动”地去获取和处理外部信息,而不是仅仅依赖训练好的模型参数。在这个过程中,一个绕不开的概念就是模型上下文协议。简单来说,它就像给…...