Python爬虫入门教程(非常详细)适合零基础小白
一、什么是爬虫?

爬虫的全称为网络爬虫,简称爬虫,别名有网络机器人,网络蜘蛛等等。
网络爬虫是一种自动获取网页内容的程序,为搜索引擎提供了重要的数据支撑。搜索引擎通过网络爬虫技术,将互联网中丰富的网页信息保存到本地,形成镜像备份。我们熟悉的谷歌、百度本质上也可理解为一种爬虫。
如果形象地理解,爬虫就如同一只机器蜘蛛,它的基本操作就是模拟人的行为去各个网站抓取数据或返回数据。
2.爬虫的分类
网络爬虫一般分为传统爬虫和聚焦爬虫。
传统爬虫从一个或若干个初始网页的URL开始,抓取网页时不断从当前页面上抽取新的URL放入队列,直到满足系统的一定条件才停止,即通过源码解析来获得想要的内容。
聚焦爬虫需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入待抓取的URL队列,再根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到满足系统的一定条件时停止。另外,所有被爬虫抓取的网页都将会被系统存储、分析、过滤,并建立索引,以便之后的查询和检索;对于聚焦爬虫来说,这一过程所得到的分析结果还可能对以后的抓取过程给出反馈和指导。
防爬虫:KS-WAF(网站统一防护系统)将爬虫行为分为搜索引擎爬虫及扫描程序爬虫,可屏蔽特定的搜索引擎爬虫节省带宽和性能,也可屏蔽扫描程序爬虫,避免网站被恶意抓取页面。使用防爬虫机制的基本上是企业,我们平时也能见到一些对抗爬虫的经典方式,如图片验证码、滑块验证、封禁 IP等等。
3.爬虫的工作原理
下图是一个网络爬虫的基本框架:

对应互联网的所有页面可划分为五部分:

1.已下载未过期网页。
2.已下载已过期网页:抓取到的网页实际上是互联网内容的一个镜像文件,互联网是动态变化的,一部分互联网上的内容已经发生了变化,这时,这部分抓取到的网页就已经过期了。
3.待下载网页:待抓取URL队列中的页面。
4.可知网页:既没有被抓取也没有在待抓取URL队列中,但可通过对已抓取页面或者待抓取URL对应页面进行分析获取到的URL,认为是可知网页。
5.不可知网页:爬虫无法直接抓取下载的网页。
待抓取URL队列中的URL顺序排列涉及到抓取页面的先后次序问题,而决定这些URL排列顺序的方法叫做抓取策略。下面介绍六种常见的抓取策略:
1.深度优先遍历策略
深度优先遍历策略是指网络爬虫从起始页开始,由一个链接跟踪到另一个链接,这样不断跟踪链接下去直到处理完这条线路,之后再转入下一个起始页,继续跟踪链接。以下图为例:

遍历路径:A-F-G E-H-I B C D
需要注意的是,深度优先可能会找不到目标节点(即进入无限深度分支),因此,深度优先策略不一定能适用于所有情况。
2.宽度优先遍历策略
宽度优先遍历策略的基本思路是,将新下载网页中发现的链接直接插入待抓取URL队列的末尾。也就是指网络爬虫会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。还是以上图为例:

遍历路径:第一层:A-B-C-D-E-F,第二层:G-H,第三层:I
广度优先遍历策略会彻底遍历整个网络图,效率较低,但覆盖网页较广
3.反向链接数策略
反向链接数是指一个网页被其他网页链接指向的数量。反向链接数反映一个网页的内容受到其他人推荐的程度。因此,很多时候搜索引擎的抓取系统会使用这个指标来评价网页的重要程度,从而决定不同网页的抓取先后顺序。
而现实是网络环境存在各种广告链接、作弊链接的干扰,使得许多反向链接数反映的结果并不可靠。
4.Partial PageRank策略
Partial PageRank策略借鉴了PageRank算法的思想:对于已下载网页,连同待抓取URL队列中的URL,形成网页集合,计算每个页面的PageRank值,然后将待抓取URL队列中的URL按照PageRank值的大小进行排列,并按照该顺序抓取页面。
若每次抓取一个页面,就重新计算PageRank值,则效率太低。
一种折中方案是:每抓取K个页面后,重新计算一次PageRank值。而对于已下载页面中分析出的链接,即暂时没有PageRank值的未知网页那一部分,先给未知网页一个临时的PageRank值,再将这个网页所有链接进来的PageRank值进行汇总,这样就形成了该未知页面的PageRank值,从而参与排序。以下图为例:

设k值为3,即每抓取3个页面后,重新计算一次PageRank值。
已知有{1,2,3}这3个网页下载到本地,这3个网页包含的链接指向待下载网页{4,5,6}(即待抓取URL队列),此时将这6个网页形成一个网页集合,对其进行PageRank值的计算,则{4,5,6}每个网页得到对应的PageRank值,根据PageRank值从大到小排序,由图假设排序结果为5,4,6,当网页5下载后,分析其链接发现指向未知网页8,这时先给未知网页8一个临时的PageRank值,如果这个值大于网页4和6的PageRank值,则接下来优先下载网页8,由此思路不断进行迭代计算。
5.OPIC策略
此算法其实也是计算页面重要程度。在算法开始前,给所有页面一个相同的初始现金(cash)。当下载了某个页面P之后,将P的现金分摊给所有从P中分析出的链接,并且将P的现金清空。对于待抓取URL队列中的所有页面按照现金数大小进行排序。
6.大站优先策略
对于待抓取URL队列中的所有网页,根据所属的网站进行分类。待下载页面数多的网站优先下载。
二、爬虫的基本流程
首先简单了解关于Request和Response的内容:
Request:浏览器发送消息给某网址所在的服务器,这个请求信息的过程叫做HTTP Request。
Response:服务器接收浏览器发送的消息,并根据消息内容进行相应处理,然后把消息返回给浏览器。这个响应信息的过程叫做HTTP Response。浏览器收到服务器的Response信息后,会对信息进行相应处理,然后展示在页面上。
根据上述内容将网络爬虫分为四个步骤:
1.发起请求:通过HTTP库向目标站点发起请求,即发送一个Request,请求可以包含额外的headers等信息,等待服务器响应。
常见的请求方法有两种,GET和POST。get请求是把参数包含在了URL(Uniform Resource Locator,统一资源定位符)里面,而post请求大多是在表单里面进行,也就是让你输入用户名和秘密,在url里面没有体现出来,这样更加安全。post请求的大小没有限制,而get请求有限制,最多1024个字节。
2.获取响应内容:如果服务器能正常响应,会得到一个Response,Response的内容便是所要获取的页面内容,类型可能有HTML,Json字符串,二进制数据(如图片视频)等类型。
3.解析内容:得到的内容可能是HTML,可以用正则表达式、网页解析库进行解析。可能是Json,可以直接转为Json对象解析,可能是二进制数据,可以做保存或者进一步的处理。
在Python语言中,我们经常使用Beautiful Soup、pyquery、lxml等库,可以高效的从中获取网页信息,如节点的属性、文本值等。
Beautiful Soup库是解析、遍历、维护“标签树”的功能库,对应一个HTML/XML文档的全部内容。安装方法非常简单,如下:
#安装方法
pips install beautifulsoup4#验证方法
from bs4 import BeautifulSoup4.保存数据:如果数据不多,可保存在txt 文本、csv文本或者json文本等。如果爬取的数据条数较多,可以考虑将其存储到数据库中。也可以保存为特定格式的文件。
保存后的数据可以直接分析,主要使用的库如下:NumPy、Pandas、 Matplotlib。
NumPy:它是高性能科学计算和数据分析的基础包。
Pandas : 基于 NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。它可以算得上作弊工具。
Matplotlib:Python中最著名的绘图系统Python中最著名的绘图系统。它可以制作出散点图,折线图,条形图,直方图,饼状图,箱形图散点图,折线图,条形图,直方图,饼状图,箱形图等。
三、爬虫简单实例
运行平台: Windows
Python版本: Python3.7
首先查看网址的源代码,使用google浏览器,右键选择检查,查看需要爬取的网址源代码,在Network选项卡里面,点击第一个条目可看到源代码。
第一部分是General,包括了网址的基本信息,比如状态 200等,第二部分是Response Headers,包括了请求的应答信息,还有body部分,比如Set-Cookie,Server等。第三部分是,Request headers,包含了服务器使用的附加信息,比如Cookie,User-Agent等内容。
上面的网页源代码,在python语言中,我们只需要使用urllib、requests等库实现即可,具体如下
import urllib.request
import socket
from urllib import error
try:response \= urllib.request.urlopen('https://www.python.org')print(response.status)print(response.read().decode('utf-8'))
except error.HTTPError as e:print(e.reason,e.code,e.headers,sep='\\n')
except error.URLError as e:print(e.reason)
else:
print('Request Successfully')
相关文章:
Python爬虫入门教程(非常详细)适合零基础小白
一、什么是爬虫? 1.简单介绍爬虫 爬虫的全称为网络爬虫,简称爬虫,别名有网络机器人,网络蜘蛛等等。 网络爬虫是一种自动获取网页内容的程序,为搜索引擎提供了重要的数据支撑。搜索引擎通过网络爬虫技术,将…...

ArcGIS Pro基础:软件的常用设置:中文语言、自动保存、默认底图
上图所示,在【选项】(Options)里找到【语言】设置,将语言切换为中文选项,记得在安装软件时,需要提前安装好ArcGIS语言包。 上图所示,在【选项】里找到【编辑】设置,可以更改软件默认…...

依赖注入+中央事件总线:Vue 3组件通信新玩法
🌈个人主页:前端青山 🔥系列专栏:Vue篇 🔖人终将被年少不可得之物困其一生 依旧青山,本期给大家带来Vue篇专栏内容:Vue-依赖注入-中央事件总线 目录 中央事件总线使用 依赖注入使用 总结 中央事件总线 依赖注入…...
EasyCVR视频汇聚平台构建远程安防监控:5大亮点解析,助力安防无死角
随着科技的飞速发展,远程安防监控系统已经成为现代社会中不可或缺的一部分,无论是在小区、公共场所还是工业领域,安防监控都发挥着至关重要的作用。而EasyCVR作为一款功能强大的视频监控综合管理平台,其在构建远程安防监控系统方面…...

fastadmin安装插件报500的错误
项目场景: 项目新建后,想在本地项目中安装相关的插件,但是在插件管理页面点击安装的时候一直报500的错误。 问题描述 我们将项目中的调试打开,在application/config.php里修改 app_debug,将false改为true,…...

速盾:为什么需要服务器和cdn?
在互联网时代,服务器和CDN(内容分发网络)起着非常重要的作用。它们是实现高效、稳定和可靠网络服务的关键组成部分。下面我将详细阐述为什么需要服务器和CDN。 首先,服务器是互联网上存储、处理和传输数据的中心枢纽。当我们在浏…...

十四、模拟实现 list 类
Ⅰ . list 基本框架的实现 01 结点的建立 为了实现链表,我们首先要做的应该是建立结点 为了和真正的 list 进行区分,我们仍然在自己的命名空间内实现 代码实现: namespace yxt {// 建立结点template<class T>struct ListNode{T _d…...

JavaScript简介之引入方式
JavaScript 引入方式 提问:CSS的引入方式?在学习 JavaScript 语法之前,我们首先要知道在哪里写 JavaScript 才行。想要在 HTML 中引入 JavaScript,一般有 3 种方式。 外部 JavaScript 内部 JavaScript 元素事件 JavaScript&#…...

同一台电脑上安装不同版本的nodejs(搭配VSCode)
今天拉取了一个前后端分离的项目,运行前端的时候,出现node版本不匹配的情况。 本文章将从安装node.js开始到VSCode使用进行讲解 1、去官网下载node版本 以16版本为例,需要哪个版本,就在网址上把版本号替换即可 https://nodejs.o…...
python小游戏之摇骰子猜大小
最近学习Python的随机数,逻辑判断,循环的用法,就想找一些练习题,比如小游戏猜大小,程序思路如下: 附上源代码如下: 摇骰子的函数,这个函数其实并不需要传任何参数,调用后…...

C++入门——12继承
1.继承 继承(inheritance)机制是面向对象程序设计使代码可以复用的最重要的手段,它允许程序员在保持原有类特性的基础上进行扩展,增加功能,这样产生新的类,称派生类。继承呈现了面向对象程序设计的层次结构,体现了由简…...

Python做统计图之美
Python数据分析可视化 案例效果图 import pandas as pd import matplotlib.pyplot as plt import matplotlib# 数据 data {"房型": [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11],"住宅类型": ["普通宅", "普通宅", "普通宅", &q…...

激光雷达点云投影到图像平面
将激光雷达点云投影到图像平面涉及几何变换和相机模型的应用。以下是该过程的基本原理: 1. 坐标系转换 激光雷达生成的点云通常位于激光雷达的坐标系中,而图像则在相机坐标系中。为了将点云投影到图像上,首先需要将点云从激光雷达坐标系转换…...

[python]将anaconda默认创建环境python版本设置为32位的
首先看看gpt怎么回答的 装了Anaconda。如果尚未安装,可以从Anaconda官网下载适合你的操作系统的安装程序,并按照安装向导进行安装。 二、创建32位Python环境 在Anaconda中,你可以通过修改环境变量来尝试切换到32位模式(尽管这并…...
Jmeter+Influxdb+Grafana平台监控性能测试过程(三种方式)
一、Jmeter自带插件监控 下载地址:Install :: JMeter-Plugins.org 安装:下载后文件为jmeter-plugins-manager-1.3.jar,将其放入jmeter安装目录下的lib/ext目录,然后重启jmeter,即可。 启动Jmeter,测试计…...

[创业之路-135] :ERP、PDM、EDM、Git各种的用途和区别,硬件型初创公司需要哪些管理工具?
目录 前言: 一、ERP(企业资源计划) 二、PDM(产品数据管理系统) 三、EDM(文档管理系统,有时也指电子邮件营销) 四、Git 总结 五、硬件研发、生产型企业需要哪些管理工具&#…...
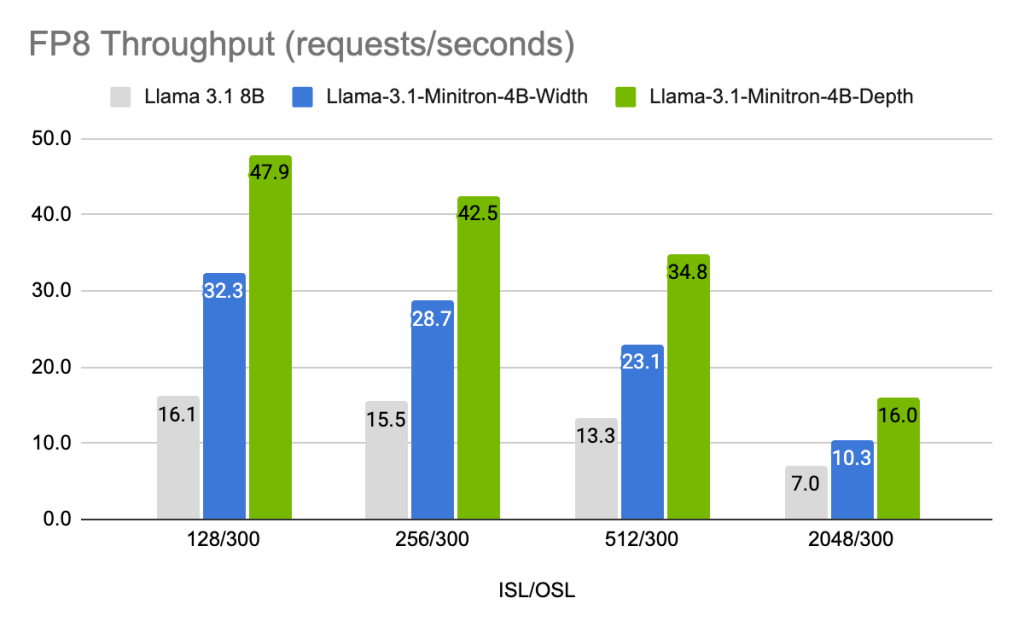
通过剪枝与知识蒸馏优化大型语言模型:NVIDIA在Llama 3.1模型上的实践与创新
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...

DOM型xss靶场实验
xss是什么? XSS是一种经常出现在web应用中的计算机安全漏洞,它允许恶意web用户将代码植入到提供给其它用户使用的页面中。比如这些代码包括HTML代码和客户端脚本。攻击者利用XSS漏洞旁路掉访问控制--例如同源策略(same origin policy)。这种类型的漏洞由…...

华为---端口隔离简介和示例配置
目录 1. 端口隔离概念 2. 端口隔离作用 3. 端口隔离优点 4. 端口隔离缺点 5. 端口隔离的方法和应用场景 6. 端口隔离配置 6.1 端口隔离相关配置命令 6.2 端口隔离配置思路 7. 示例配置 7.1 示例场景 7.2 网络拓扑图 7.3 基本配置 7.4端口隔离配置与验证 7.4.1 双…...

Android 架构模式之 MVC
目录 架构设计的目的对 MVC 的理解Android 中 MVC 的问题试吃个小李子ViewModelController 大家好! 作为 Android 程序猿,MVC 应该是我们第一个接触的架构吧,从开始接触 Android 那一刻起,我们就开始接触它,可还记得我…...

保姆级教程:解决PyTorchViz安装报错,手把手教你用AlexNet模型可视化
PyTorch模型可视化实战:从安装报错到AlexNet结构解析全指南 在深度学习模型开发过程中,可视化工具如同开发者的"第二双眼睛"。PyTorchViz作为PyTorch生态中轻量级但功能强大的可视化工具,能直观展示模型的计算图结构,帮…...

手把手教你用LwIP RAW API在STM32上实现一个能自动重连的TCP客户端
基于LwIP RAW API的STM32 TCP客户端自动重连实战指南 在物联网终端设备开发中,网络连接的稳定性直接决定了产品的可靠性。想象一下,一个部署在工厂车间的环境监测设备,如果因为Wi-Fi信号波动导致数据中断,可能让整个生产线失去关键…...

软硬一体赋能企业守护力,可穿戴手环构建员工数字健康管理新范式
在数字化转型深入推进的当下,员工健康已成为企业安全生产、高效运营的核心基石。传统健康管理模式存在数据零散、监测滞后、人工成本高、风险预警不及时等痛点,尤其铁路、港口、政企单位、生产型企业,一线员工高强度作业、慢病高发、突发健康…...

工厂考勤数据分散怎么破?实在Agent助力企业数字化转型实现非侵入式数据整合
摘要: 我是企业架构师老王。在2026年的今天,尽管智能制造已进入深水区,但“工厂考勤数据分散、打卡请假加班数据无法自动整合”依然是困扰无数中大型制造企业的“顽疾”。传统的API集成方案在面对老旧系统和复杂的异构环境时,往往…...
跑通你的量化筛选器?)
Qlib实战:如何用自定义数据(比如可转债)跑通你的量化筛选器?
Qlib实战:从可转债数据到动态筛选策略的全流程解析 在量化投资领域,标准化的股票数据往往难以满足专业投资者的特殊需求。当我们需要处理可转债、加密货币或其他另类资产时,如何将这些非标准数据整合到强大的量化框架中,成为许多开…...

从COCO到Cityscapes:实例分割指标mAP和mIOU在不同数据集上的表现差异与陷阱
从COCO到Cityscapes:实例分割指标mAP和mIOU在不同数据集上的表现差异与陷阱 当你在COCO数据集上训练的Mask R-CNN模型取得了0.85的mAP,满怀信心地将其部署到自动驾驶项目的Cityscapes数据集上时,却发现mIOU从预期的0.75骤降到0.52——这种&qu…...
)
C++中函数对象之重载 operator()
如大家所熟悉的,重载 operator() 是 C 中一种特殊机制,允许类的对象像函数一样被调用。这种对象被称为 函数对象(functor) 或 仿函数。核心要点语法形式:在类中定义名为 operator() 的成员函数。调用…...

【锂离子电池组的被动式电池均衡】电池组由两个并联的串联电池组成,每个并联串联都包含四个串联电池,目标是通过在电阻器上放电高SOC电池,直到所有电池的SOC相等附Simulink仿真
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、程序设计科研仿真。 🍎完整代码获取 定制创新 论文复现点击:Matlab科研工作室 👇 关注我领取海量matlab电子书和数学建模资料 &…...

RK3568开发板TB-96AI-3568CE深度评测:从核心接口到AI应用实战
1. 从芯片到板卡:TB-96AI-3568CE的设计哲学当一块芯片从图纸走向现实,成为一块可以握在手中的开发板时,这中间的路程远不止是简单的引脚引出和电源接通。我接触过不少基于RK3568的方案,但拿到贝启科技这块TB-96AI-3568CE时&#x…...

ESP32-S3开发板AIoT入门:从硬件解析到边缘AI实战
1. 启明云端WT32-S3-DK开发板:一款被低估的AIoT入门利器如果你正在寻找一款既能玩转物联网基础应用,又能轻松涉足边缘AI的入门级开发板,启明云端的WT32-S3-DK绝对是一个值得你花时间研究的选项。它基于乐鑫的ESP32-S3芯片,但并非简…...