通过剪枝与知识蒸馏优化大型语言模型:NVIDIA在Llama 3.1模型上的实践与创新
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/

大型语言模型现在在自然语言处理和理解领域占据了主导地位,凭借其高效性和多功能性脱颖而出。像Llama 3.1 405B和NVIDIA Nemotron-4 340B这样的大型语言模型在许多具有挑战性的任务中表现出色,包括编程、推理和数学。然而,这些模型的部署需要大量资源。因此,业界也在兴起另一种趋势,即开发小型语言模型。这些小型语言模型在许多语言任务中同样表现出色,但部署成本更低,更适合大规模应用。
最近,NVIDIA的研究人员表明,结合结构化权重剪枝和知识蒸馏是一种从大型模型逐渐获得小型模型的有效策略。NVIDIA Minitron 8B和4B就是通过剪枝和蒸馏其15B的“大型兄弟”NVIDIA Nemotron系列模型而得来的。
剪枝和蒸馏带来了多种好处:
- 与从头训练相比,MMLU评分提高了16%。
- 每个额外模型所需的训练数据token数量减少了约1000亿个,缩减比例高达40倍。
- 训练一系列模型的计算成本节省了1.8倍。
- 性能可与训练了更多token(高达15万亿)的Mistral 7B、Gemma 7B和Llama-3 8B模型相媲美。
该论文还提出了一套实用且有效的结构化压缩最佳实践,这些实践结合了深度、宽度、注意力和多层感知器剪枝,并通过基于知识蒸馏的再训练实现。
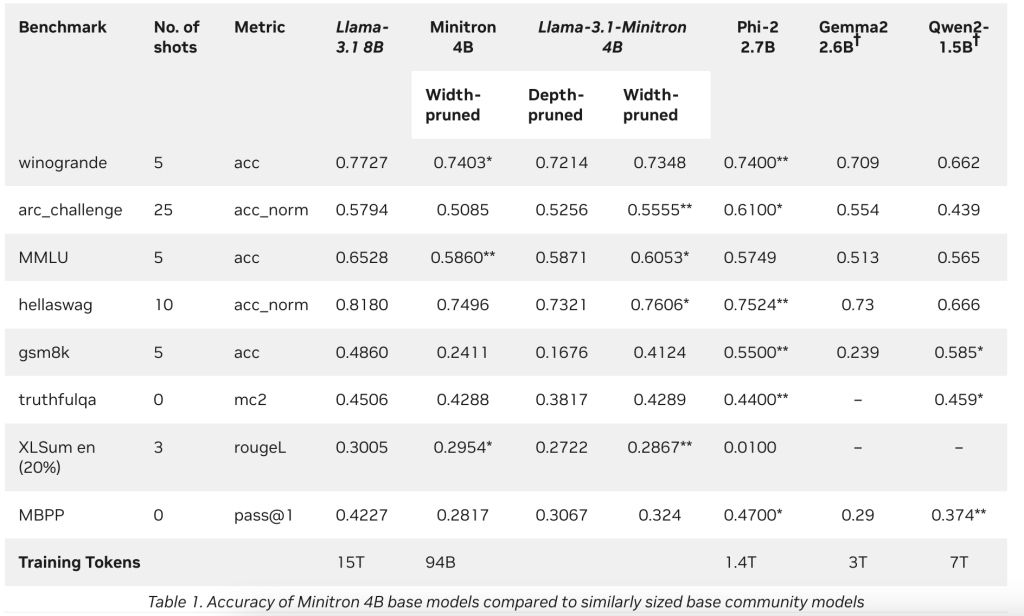
NVIDIA首先讨论这些最佳实践,然后展示它们在Llama 3.1 8B模型上的应用效果,得出Llama-3.1-Minitron 4B模型。Llama-3.1-Minitron 4B在与同类大小的开源模型(包括Minitron 4B、Phi-2 2.7B、Gemma2 2.6B和Qwen2-1.5B)的对比中表现优异。Llama-3.1-Minitron 4B即将发布到NVIDIA HuggingFace集合中,等待审批。
剪枝与蒸馏
剪枝是使模型变得更小、更精简的过程,方法包括丢弃层或丢弃神经元、注意力头和嵌入通道。剪枝通常伴随一定量的再训练以恢复准确性。
模型蒸馏是一种技术,用于将大型复杂模型中的知识转移到较小、较简单的学生模型中。其目标是在保持原始大型模型大部分预测能力的同时,创建一个运行速度更快、资源消耗更少的高效模型。
经典知识蒸馏与SDG微调
蒸馏主要有两种方式:
- SDG微调:使用从较大教师模型生成的合成数据进一步微调预训练的小型学生模型。在这种方式中,学生模型仅模仿教师模型最终预测的token。这在Llama 3.1 Azure Distillation和AWS使用Llama 3.1 405B生成合成数据并蒸馏以微调小型模型的教程中得到了体现。
- 经典知识蒸馏:学生模型模仿教师模型在训练数据集上的logits和其他中间状态,而不仅仅是学习要预测的token。这可以视为提供了更好的标签(一个分布与单个标签相比)。即使使用相同的数据,梯度也包含更丰富的反馈,从而提高了训练的准确性和效率。然而,经典蒸馏的这种方式需要训练框架支持,因为logits过大无法存储。
这两种蒸馏方式是互补的,而非互斥的。NVIDIA主要关注经典知识蒸馏方法。
剪枝与蒸馏过程
NVIDIA提出了一种结合剪枝与经典知识蒸馏的资源高效再训练技术。
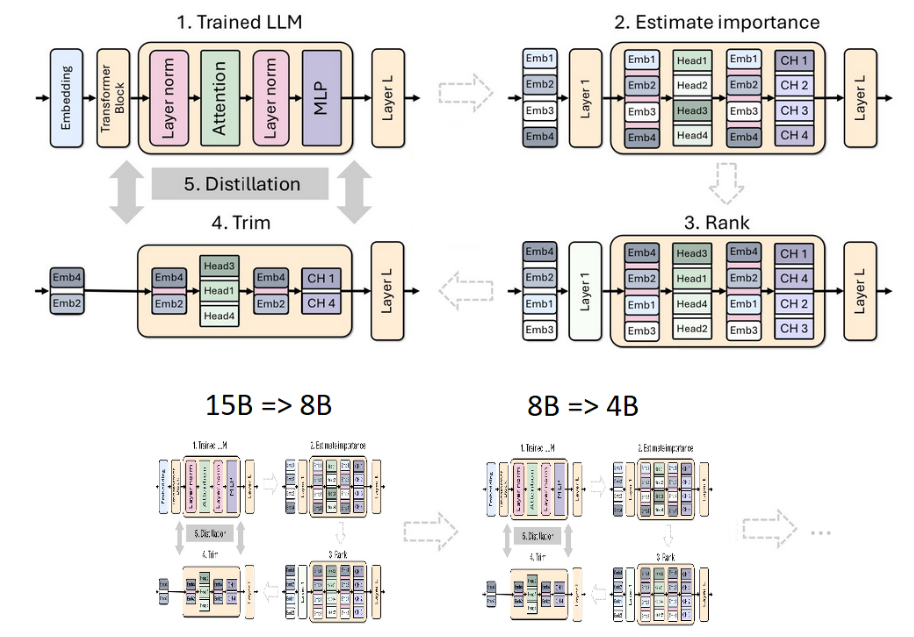
NVIDIA从一个15B的模型开始,评估每个组件的重要性(层、神经元、注意力头和嵌入通道),然后将模型修剪到目标大小:8B模型。
NVIDIA使用教师模型作为学生模型的教师,通过模型蒸馏执行轻量再训练过程。
训练完成后,小型模型(8B)作为起点进一步修剪和蒸馏到更小的4B模型。
图1显示了逐步剪枝和蒸馏模型的过程,从15B到8B,再从8B到4B。
重要性分析
要对模型进行剪枝,关键是要了解模型的哪些部分是重要的。NVIDIA建议使用一种基于激活的纯粹重要性估算策略,该策略通过使用小型校准数据集和仅前向传播计算,同时计算所有考虑轴(深度、神经元、头和嵌入通道)的敏感度信息。与依赖梯度信息且需要后向传播的策略相比,这种策略更加简单且具成本效益。
虽然可以针对给定的轴或轴的组合在剪枝和重要性估算之间反复交替进行,但NVIDIA的实验证明,使用单次重要性估算已经足够,迭代估算并没有带来任何好处。
经典知识蒸馏再训练
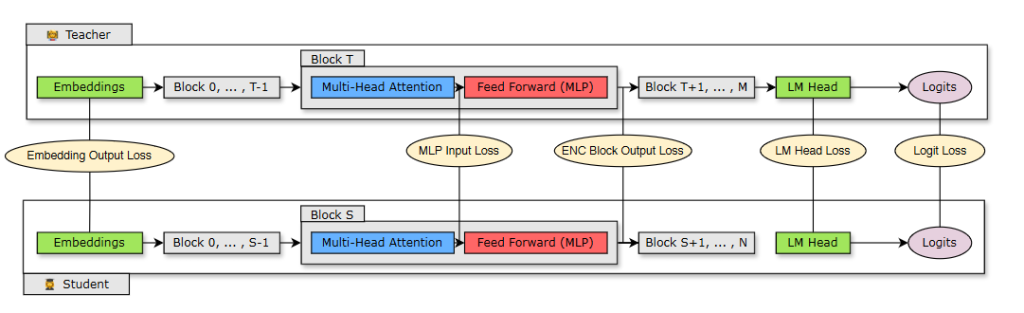
图2展示了学生模型从教师模型蒸馏的过程。学生通过最小化嵌入输出损失、logit损失和变压器编码器特定损失的组合进行学习,这些损失映射在学生模型的S块和教师模型的T块之间。
剪枝与蒸馏最佳实践
基于在《通过剪枝和知识蒸馏压缩语言模型》中进行的广泛消融研究,NVIDIA总结了几个结构化压缩的最佳实践:
尺寸:
- 要训练一系列大型语言模型,首先训练最大的模型,然后通过剪枝和蒸馏逐步获得较小的模型。
- 如果最大的模型使用多阶段训练策略,则最好剪枝并再训练最后阶段的模型。
- 剪枝时,优先选择接近目标大小的模型进行剪枝。
剪枝:
- 更倾向于进行宽度剪枝。这在考虑的模型规模(≤15B)中表现良好。
- 使用单次重要性估算。迭代重要性估算没有提供任何额外收益。
再训练:
- 专门使用蒸馏损失进行再训练,而不是传统训练。
- 当深度显著减少时,使用logit加中间状态加嵌入蒸馏。
- 当深度没有显著减少时,只使用logit蒸馏。
Llama-3.1-Minitron:实践最佳实践
Meta最近推出了功能强大的Llama 3.1模型系列,这是首批在许多基准测试中可与闭源模型相媲美的开源模型。Llama 3.1的规模从巨大的405B模型到70B和8B不等。
NVIDIA借鉴了Nemotron蒸馏的经验,开始将Llama 3.1 8B模型蒸馏为更小、更高效的4B模型:
- 教师微调
- 仅深度剪枝
- 仅宽度剪枝
- 准确性基准测试
- 性能基准测试
教师微调
为了纠正模型在原始数据集上的分布偏移,NVIDIA首先在数据集上对未剪枝的8B模型进行了微调。实验表明,如果不纠正分布偏移,教师模型在蒸馏过程中对数据集的指导效果会欠佳。
仅深度剪枝
为了将模型从8B缩减到4B,NVIDIA剪去了16层。通过移除模型中的某些层,观察语言模型损失或在下游任务中的准确性降低,来评估每一层或连续层组的重要性。
图5显示了在验证集上移除1层、2层、8层或16层后的语言模型损失值。NVIDIA发现,模型开头和结尾的层最为重要。
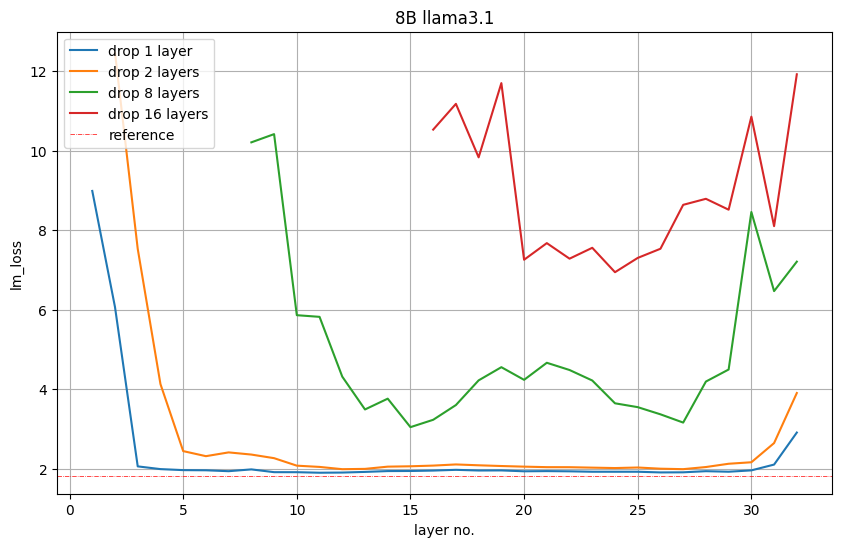
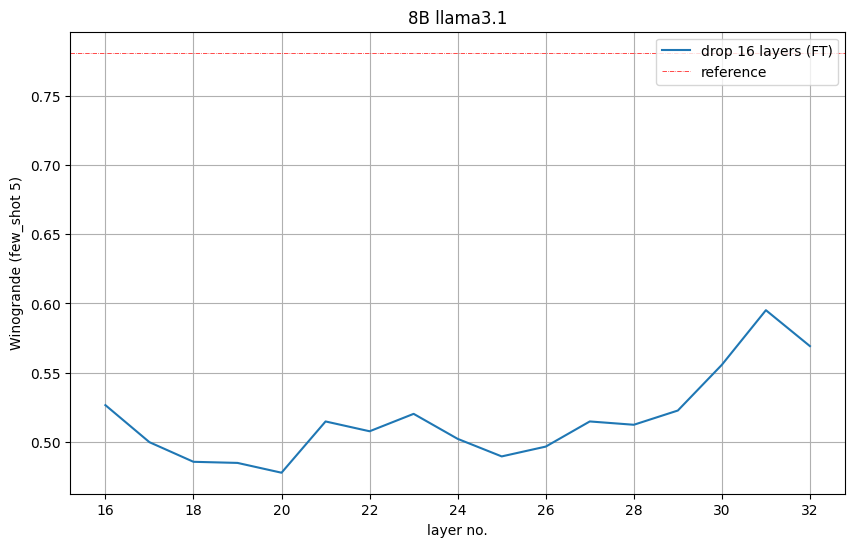
然而,NVIDIA注意到语言模型损失与下游性能之间并不直接相关。图6展示了每个剪枝模型在Winogrande任务上的准确性,表明移除16到31层(即倒数第二层)效果最佳。NVIDIA据此洞见,移除了16到31层。
仅宽度剪枝
NVIDIA通过宽度剪枝压缩了Llama 3.1 8B模型,主要剪掉了嵌入和MLP中间维度。具体而言,NVIDIA使用前面提到的基于激活的策略,计算每个注意力头、嵌入通道和MLP隐藏维度的重要性分数。随后:
- 将MLP中间维度从14336剪至9216。
- 将隐藏尺寸从409
6剪至3072。
- 重新训练了注意力头数和层数。
值得注意的是,宽度剪枝后的一次性剪枝的语言模型损失高于深度剪枝,但经过短暂的再训练后,趋势发生了逆转。
准确性基准测试
NVIDIA在以下参数下对模型进行了蒸馏:
- 最大学习率=1e-4
- 最小学习率=1e-5
- 线性热身40步
- 余弦衰减计划
- 全局批量大小=1152
表1展示了Llama-3.1-Minitron 4B模型(宽度剪枝和深度剪枝变体)与原始Llama 3.1 8B模型及其他类似大小模型在多个领域基准测试中的比较结果。整体上,NVIDIA再次确认宽度剪枝策略相比深度剪枝的有效性,这符合最佳实践。
性能基准测试
NVIDIA使用NVIDIA TensorRT-LLM(一个用于优化大型语言模型推理的开源工具包)优化了Llama 3.1 8B和Llama-3.1-Minitron 4B模型。

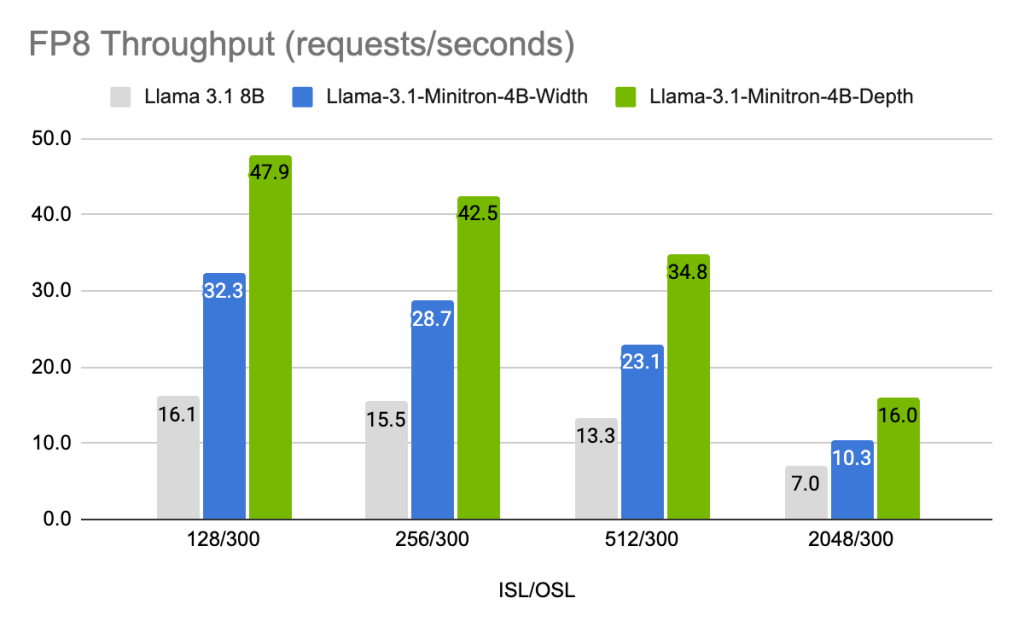
图7和图8显示了不同模型在不同精度(FP8和FP16)下的每秒请求吞吐量。在不同用例中,使用的输入序列长度/输出序列长度组合,批次大小为32(8B模型)和64(4B模型)。Llama-3.1-Minitron-4B-Depth-Base变体的平均吞吐量是Llama 3.1 8B的约2.7倍,而Llama-3.1-Minitron-4B-Width-Base变体的平均吞吐量是Llama 3.1 8B的约1.8倍。在FP8中部署所有三个模型还带来了约1.3倍的性能提升。
总结
剪枝与经典知识蒸馏是一种非常具成本效益的方法,能够逐步获得更小的大型语言模型,且在各个领域中的准确性优于从头训练。这比使用合成数据风格的微调或从头预训练更有效且数据更高效。
Llama-3.1-Minitron 4B是NVIDIA在开源Llama 3.1系列中的首次尝试。想要使用NVIDIA NeMo中Llama-3.1的SDG微调,请参见GitHub上的/sdg-law-title-generation笔记本。https://github.com/NVIDIA/NeMo/tree/main/tutorials/llm/llama-3/sdg-law-title-generation
相关文章:
通过剪枝与知识蒸馏优化大型语言模型:NVIDIA在Llama 3.1模型上的实践与创新
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...

DOM型xss靶场实验
xss是什么? XSS是一种经常出现在web应用中的计算机安全漏洞,它允许恶意web用户将代码植入到提供给其它用户使用的页面中。比如这些代码包括HTML代码和客户端脚本。攻击者利用XSS漏洞旁路掉访问控制--例如同源策略(same origin policy)。这种类型的漏洞由…...

华为---端口隔离简介和示例配置
目录 1. 端口隔离概念 2. 端口隔离作用 3. 端口隔离优点 4. 端口隔离缺点 5. 端口隔离的方法和应用场景 6. 端口隔离配置 6.1 端口隔离相关配置命令 6.2 端口隔离配置思路 7. 示例配置 7.1 示例场景 7.2 网络拓扑图 7.3 基本配置 7.4端口隔离配置与验证 7.4.1 双…...

Android 架构模式之 MVC
目录 架构设计的目的对 MVC 的理解Android 中 MVC 的问题试吃个小李子ViewModelController 大家好! 作为 Android 程序猿,MVC 应该是我们第一个接触的架构吧,从开始接触 Android 那一刻起,我们就开始接触它,可还记得我…...

节点使用简介:comfyui-photoshop
1、安装comfyui-photoshop 略过 一点要注意的是:在Photoshop上的安装增效工具,要通过Creative Cloud 桌面应用程序进行安装,才能成功在增效工具中显示,直接通过将文件解压到Plug-ins路径行不通(至少对我来说行不通&am…...
使用Go语言将PDF文件转换为Base64编码
使用 Go 语言将 Base64 编码转换为 PDF 文件-CSDN博客本文介绍了如何使用 Go 语言将 Base64 编码转换为 PDF 文件,并保存到指定路径。https://blog.csdn.net/qq_45519030/article/details/141225772 在现代编程中,数据转换和编码是常见的需求。本文将介绍…...

XSS Game
关卡网址:XSS Game - Learning XSS Made Simple! | Created by PwnFunction 1.Ma Spaghet! 见源代码分析得,somebody接收参数,输入somebody111查看所在位置 使用input标签 <input onmouseoveralert(1337)> 2.Jefff jeff接收参数,在ev…...
???牛客周赛55:虫洞操纵者
题目描述 \,\,\,\,\,\,\,\,\,\,你需要在一个可以上下左右移动的 nnn\times nnn 棋盘上解开一个迷宫:棋盘四周都是墙;每个方格要么是可以通过的空方格 ′0′\sf 0′0′ ,要么是不可通过的墙方格 ′1′\sf 1′1′ ;你可以沿着空方格…...

Unity3D开发之OnCollisionXXX触发条件
A和B碰撞触发OnCollision函数条件如下: 1.A和B都要有collider。(子物体有也可以) 2.A和B至少有一个刚体(Rigidbody)组件,且刚体的isKinematic为false。如果为true不会触发。 3.挂载脚本的物体必须有刚体…...

spfa()算法(求最短路)
spfa算法是对bellman_ford算法的优化,大部分求最短路问题都可以用spaf算法来求。 注意: (1)如若图中有负权回路,不能用spfa算法,要用bellman_ford算法;若只有负权边,则可以用 spf…...

聊聊国产数据库的生态系统建设
生态系统是指在自然界中,生物与环境构成统一的整体,之间相互影响相互制约,并在一定时期内处于相对稳定的动态平衡状态。所谓数据库的生态系统,从用户的角度看,就是充分打通产品使用过程中上下游的关联,使其…...
JDK源码解析:LinkedList
1、背景 我们咨询一下腾讯混元大模型,什么是“LinkedList”。 以下是混元大模型的回答: LinkedList 是 Java 集合框架中的一种数据结构,它实现了 List 和 Deque 接口。LinkedList 是一个双向链表,这意味着每个元素都包含对前一个和…...

drawio的问题
drawio的问题 先给出drawio的链接https://app.diagrams.net/ 我在用overleaf写论文的过程中,发现了一个问题,就是使用drawio画好图之后,只能保存以下几个选项: 但是不管是什么类型,在overleaf上面图片都不显示。如果…...

零基础学习Redis(3) -- Redis常用命令
Redis是一个 客户端-服务器 结构的程序,Redis客户端和服务器可以在同一台主机上,也可以在不同主机上,客户端和服务器之间通过网络进行通信。服务器端负责存储和管理数据。客户端则可以通过命名对服务端的数据进行操作。 Redis客户端有多种&a…...

响应式Web设计:纯HTML和CSS的实现技巧-1
响应式Web设计(Responsive Web Design, RWD)是一种旨在确保网站在不同设备和屏幕尺寸下都能良好运行的网页设计策略。通过纯HTML和CSS实现响应式设计,主要依赖于媒体查询(Media Queries)、灵活的布局、可伸缩的图片和字…...
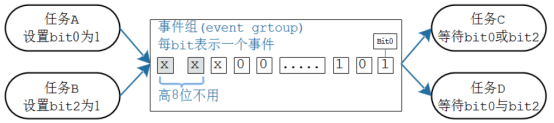
FrereRTOS事件组
文章目录 一、事件组概念与操作1、事件组的概念2、事件组的操作 二、事件组函数1、创建2、删除3、设置事件4、等待事件5、同步点 三、示例:广播四、示例:等待一个任意事件五、示例: 等待多个事件都发生 学校组织秋游,组长在等待: …...

【经典算法】BFS_最短路问题
目录 1. 最短路问题介绍2. 算法原理和代码实现(含题目链接)1926.迷宫中离入口最近的出口433.最小基因变化127.单词接龙675.为高尔夫比赛砍树 3. 算法总结 1. 最短路问题介绍 最短路径问题是图论中的一类十分重要的问题。本篇文章只介绍边权为1(或边权相同)的最简单的最短路径问…...

【题目/训练】:双指针
引言 我们已经在这篇博客【算法/学习】双指针-CSDN博客里面讲了双指针、二分等的相关知识。 现在我们来做一些训练吧 经典例题 1. 移动零 思路: 使用 0 当做这个中间点,把不等于 0(注意题目没说不能有负数)的放到中间点的左边,等于 0 的…...

LLVM - 编译器后端-指令选择
一:概述 任何后端的核心都是指令选择。LLVM 实现了几种方法;在本篇文章中,我们将通过选择有向无环图(DAG)和全局指令选择来实现指令选择。 在本篇文章中,我们将学习以下主题: • 定义调…...
ES+FileBeat+Kibana日志采集搭建体验
1.环境准备 需要linux操作系统,并安装了docker环境 此处使用虚拟机演示。(虚拟机和docker看参考我之前写的文章) VirtualBox安装Oracle Linux 7.9全流程-CSDN博客 VirtualBox上的Oracle Linux虚拟机安装Docker全流程-CSDN博客 简单演示搭建ES…...

Windows右键菜单冒出‘Microsoft WinRT Storage API‘?别慌,用Procmon揪出元凶并修复
Windows右键菜单异常选项排查指南:从Procmon分析到注册表修复 最近不少Windows用户反馈,在右键点击文件或图片时,菜单中突然出现了名为"Microsoft WinRT Storage API"的陌生选项,点击后还会弹出错误提示。这种看似系统级…...

在微服务架构中利用 Taotoken 实现多模型 API 的动态切换与调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在微服务架构中利用 Taotoken 实现多模型 API 的动态切换与调用 面向后端架构师或开发负责人,当微服务系统需要集成多种…...
)
毕设救星:手把手教你用Android Studio和OkHttp3搞定OneNET新版API数据获取(附完整Java代码)
物联网毕设实战:Android Studio对接OneNET新版API全流程解析 在物联网相关专业的毕业设计中,如何快速构建一个能实际运行的设备数据监控APP往往是让本科生头疼的难题。本文将手把手带你完成从零开始的完整开发流程,重点解决三个核心痛点&…...

软硬一体赋能企业守护力,可穿戴手环构建员工数字健康管理新范式
在数字化转型深入推进的当下,员工健康已成为企业安全生产、高效运营的核心基石。传统健康管理模式存在数据零散、监测滞后、人工成本高、风险预警不及时等痛点,尤其铁路、港口、政企单位、生产型企业,一线员工高强度作业、慢病高发、突发健康…...

三步法实战指南:用FanControl打造静音高效的Windows风扇控制系统
三步法实战指南:用FanControl打造静音高效的Windows风扇控制系统 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_T…...
)
ENSP USG6000防火墙CPU占用飙到99%?可能是你的“小云朵”网卡选错了(VMware网卡避坑指南)
ENSP USG6000防火墙CPU占用率优化实战:VMware虚拟网卡配置全解析 当你在ENSP中成功启动USG6000防火墙后,是否遭遇过整个系统突然变得异常卡顿?打开任务管理器,发现ENSP进程的CPU占用率直逼99%,仿佛你的电脑正在执行某种…...

我的第一个CANOpen主站:手把手教你用CanFestival-3源码配置心跳、SYNC和PDO映射
我的第一个CANOpen主站:手把手教你用CanFestival-3源码配置心跳、SYNC和PDO映射 当你第一次面对工业现场总线协议时,那种既兴奋又忐忑的心情我至今记忆犹新。CANOpen作为工业自动化领域的"普通话",其主站开发往往是工程师进阶路上的…...

题解:洛谷 U327333 Max Sum Plus Plus 2
本文分享的必刷题目是从蓝桥云课、洛谷、AcWing等知名刷题平台精心挑选而来,并结合各平台提供的算法标签和难度等级进行了系统分类。题目涵盖了从基础到进阶的多种算法和数据结构,旨在为不同阶段的编程学习者提供一条清晰、平稳的学习提升路径。 欢迎大…...

不只是F5隐写:一次CTF解题,带你深入理解ZIP伪加密的底层原理与手动修复
深入解析ZIP伪加密:从CTF实战到二进制手动修复 在CTF竞赛中,ZIP伪加密一直是Misc类题目的经典考点。不同于常规的加密破解,伪加密巧妙地利用了ZIP文件格式的设计特性,在不实际加密数据的情况下制造出需要密码的假象。本文将带您深…...

Multi-Agent产品创新:从单一场景到跨域协同的演进
Multi-Agent产品创新:从单一场景到跨域协同的演进 关键词:多智能体系统、产品创新、跨域协同、单一场景智能、Agent协作框架、LLM驱动Agent、分布式智能 摘要:大语言模型的爆发式发展,让智能Agent从实验室走向了大众消费级产品。本文从生活场景的真实痛点切入,逐层拆解Mul…...