注意力机制(四):多头注意力
专栏:神经网络复现目录
注意力机制
注意力机制(Attention Mechanism)是一种人工智能技术,它可以让神经网络在处理序列数据时,专注于关键信息的部分,同时忽略不重要的部分。在自然语言处理、计算机视觉、语音识别等领域,注意力机制已经得到了广泛的应用。
注意力机制的主要思想是,在对序列数据进行处理时,通过给不同位置的输入信号分配不同的权重,使得模型更加关注重要的输入。例如,在处理一句话时,注意力机制可以根据每个单词的重要性来调整模型对每个单词的注意力。这种技术可以提高模型的性能,尤其是在处理长序列数据时。
在深度学习模型中,注意力机制通常是通过添加额外的网络层实现的,这些层可以学习到如何计算权重,并将这些权重应用于输入信号。常见的注意力机制包括自注意力机制(self-attention)、多头注意力机制(multi-head attention)等。
总之,注意力机制是一种非常有用的技术,它可以帮助神经网络更好地处理序列数据,提高模型的性能。
文章目录
- 注意力机制
- 多头注意力
- 数学逻辑
- 实现
多头注意力
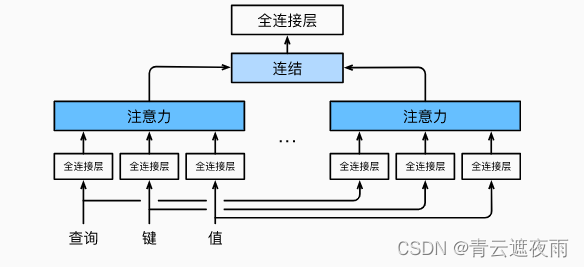
多头注意力(Multi-Head Attention)是注意力机制的一种扩展形式,可以在处理序列数据时更有效地提取信息。
在标准的注意力机制中,我们计算一个加权的上下文向量来表示输入序列的信息。而在多头注意力中,我们使用多组注意力权重,每组权重可以学习到不同的语义信息,并且每组权重都会产生一个上下文向量。最后,这些上下文向量会被拼接起来,再通过一个线性变换得到最终的输出。
多头注意力是Transformer模型中的一个重要组成部分,被广泛用于各种自然语言处理任务,如机器翻译、文本分类等。
数学逻辑
在实现多头注意力之前,让我们用数学语言将这个模型形式化地描述出来。 给定查询q∈Rdqq\in R^{d_q}q∈Rdq、 键k∈Rdkk\in R^{d_k}k∈Rdk和值v∈Rdvv\in R^{d_v}v∈Rdv, 每个注意力头的计算方法为:
hi=f(Wi(q)q,Wi(k)k,Wi(v)v)∈Rpvh_i=f(W_i^{(q)}q,W_i^{(k)}k,W_i^{(v)}v)\in R^{pv}hi=f(Wi(q)q,Wi(k)k,Wi(v)v)∈Rpv
其中,可学习的参数包括 Wi(q)W_i^{(q)}Wi(q)、 Wi(k)W_i^{(k)}Wi(k)和 Wi(v)W_i^{(v)}Wi(v), 以及代表注意力汇聚的函数fff。 fff可以是加性注意力和缩放点积注意力。 多头注意力的输出需要经过另一个线性转换, 它对应着hhh个头连结后的结果,因此其可学习参数是 WoW_oWo:

实现
在实现过程中通常选择缩放点积注意力作为每一个注意力头。 为了避免计算代价和参数代价的大幅增长, 我们设定pq=pk=pv=pp/hp_q=p_k=p_v=p_p/hpq=pk=pv=pp/h。 值得注意的是,如果将查询、键和值的线性变换的输出数量设置为pqh=pkh=pvh=ppp_qh=p_kh=p_vh=p_ppqh=pkh=pvh=pp, 则可以并行计算hhh个头。 在下面的实现中,是通过参数pop_oponum_hiddens指定的。
#@save
class MultiHeadAttention(nn.Module):"""多头注意力"""def __init__(self, key_size, query_size, value_size, num_hiddens,num_heads, dropout, bias=False, **kwargs):super(MultiHeadAttention, self).__init__(**kwargs)self.num_heads = num_headsself.attention = d2l.DotProductAttention(dropout)self.W_q = nn.Linear(query_size, num_hiddens, bias=bias)self.W_k = nn.Linear(key_size, num_hiddens, bias=bias)self.W_v = nn.Linear(value_size, num_hiddens, bias=bias)self.W_o = nn.Linear(num_hiddens, num_hiddens, bias=bias)def forward(self, queries, keys, values, valid_lens):# queries,keys,values的形状:# (batch_size,查询或者“键-值”对的个数,num_hiddens)# valid_lens 的形状:# (batch_size,)或(batch_size,查询的个数)# 经过变换后,输出的queries,keys,values 的形状:# (batch_size*num_heads,查询或者“键-值”对的个数,# num_hiddens/num_heads)queries = transpose_qkv(self.W_q(queries), self.num_heads)keys = transpose_qkv(self.W_k(keys), self.num_heads)values = transpose_qkv(self.W_v(values), self.num_heads)if valid_lens is not None:# 在轴0,将第一项(标量或者矢量)复制num_heads次,# 然后如此复制第二项,然后诸如此类。valid_lens = torch.repeat_interleave(valid_lens, repeats=self.num_heads, dim=0)# output的形状:(batch_size*num_heads,查询的个数,# num_hiddens/num_heads)output = self.attention(queries, keys, values, valid_lens)# output_concat的形状:(batch_size,查询的个数,num_hiddens)output_concat = transpose_output(output, self.num_heads)return self.W_o(output_concat)
为了能够使多个头并行计算, 上面的MultiHeadAttention类将使用下面定义的两个转置函数。 具体来说,transpose_output函数反转了transpose_qkv函数的操作。
#@save
def transpose_qkv(X, num_heads):"""为了多注意力头的并行计算而变换形状"""# 输入X的形状:(batch_size,查询或者“键-值”对的个数,num_hiddens)# 输出X的形状:(batch_size,查询或者“键-值”对的个数,num_heads,# num_hiddens/num_heads)X = X.reshape(X.shape[0], X.shape[1], num_heads, -1)# 输出X的形状:(batch_size,num_heads,查询或者“键-值”对的个数,# num_hiddens/num_heads)X = X.permute(0, 2, 1, 3)# 最终输出的形状:(batch_size*num_heads,查询或者“键-值”对的个数,# num_hiddens/num_heads)return X.reshape(-1, X.shape[2], X.shape[3])#@save
def transpose_output(X, num_heads):"""逆转transpose_qkv函数的操作"""X = X.reshape(-1, num_heads, X.shape[1], X.shape[2])X = X.permute(0, 2, 1, 3)return X.reshape(X.shape[0], X.shape[1], -1)
代码解释:
这段代码实现了多头注意力机制,其中 MultiHeadAttention 类实现了多头注意力的前向传播, transpose_qkv 函数将输入的 queries, keys, values 通过线性变换并按照 num_heads 进行分组,最终输出变换后的 queries, keys, values,在前向传播中使用这些变换后的 queries, keys, values 来计算注意力权重。在 transpose_qkv 函数的实现中,首先将 queries, keys, values 转换成形状为 (batch_size, queries/keys/values_num, num_hiddens) 的张量,然后根据 num_heads 将最后一维进行分组,变换成形状为 (batch_size, num_heads, queries/keys/values_num, num_hiddens/num_heads) 的张量,最后将第一维和第二维进行交换,输出形状为 (batch_size*num_heads, queries/keys/values_num, num_hiddens/num_heads) 的张量。transpose_output 函数实现了对 MultiHeadAttention 的输出进行逆转换的操作。
这么做的原因是因为多头注意力机制可以将输入张量进行 num_heads 个独立的注意力计算,将计算结果在最后一维拼接起来作为输出,这样可以提高模型的并行性,加快计算速度。同时,通过变换形状将 num_heads 独立处理,也可以增强模型对不同位置和特征的表征能力。
具体来说,这段代码实现的是一个MultiHeadAttention类,其中定义了一个forward方法。这个方法接收一个查询序列queries,一个键序列keys,一个值序列values和一个有效长度序列valid_lens作为输入,然后输出一个加权聚合的结果。
MultiHeadAttention类的初始化方法中,我们定义了几个线性层,以及注意力计算函数,然后用这些组件来定义一个多头注意力层。该层包括将输入queries、keys和values通过三个线性层进行变换,以便将它们的形状变为(batch_size * num_heads,查询或者“键-值”对的个数,num_hiddens/num_heads),其中num_heads表示注意力头的数量。然后,我们通过调用transpose_qkv函数对这些变换后的输入进行一次变换,以便在注意力计算函数中实现多头并行计算。最后,我们通过调用transpose_output函数将输出重构成(batch_size,查询的个数,num_hiddens),并通过一个线性层对其进行变换,输出最终结果。
transpose_qkv函数将输入的queries、keys和values通过reshape和permute操作进行变换,以便多头并行计算。具体来说,它将输入变换为(batch_size,查询或者“键-值”对的个数,num_heads,num_hiddens/num_heads)的形状,然后将第2和第3个轴进行交换。最后,它将输出变换为(batch_size * num_heads, 查询或者“键-值”对的个数, num_hiddens/num_heads)的形状。
transpose_output函数将多头并行计算得到的输出通过reshape和permute操作逆转回原来的形状,具体来说,它将输出变换为(batch_size,查询的个数,num_heads, num_hiddens/num_heads)的形状,然后将第2和第3个轴进行交换,最终将输出变换为(batch_size,查询的个数,num_hiddens)的形状。
这里似乎所有的单头都是同一些参数,这样不会导致每个单头的输出都是一样的吗?
这里的确有点难懂, 这里其实是把所有注意力头里面的参数拼起来, 变成了一个大的全连接层

相关文章:
注意力机制(四):多头注意力
专栏:神经网络复现目录 注意力机制 注意力机制(Attention Mechanism)是一种人工智能技术,它可以让神经网络在处理序列数据时,专注于关键信息的部分,同时忽略不重要的部分。在自然语言处理、计算机视觉、语…...

【2023Unity游戏开发教程】零基础带你从小白到超神19——射线检测
文章目录 射线检测从某点发射一条射线从摄像机发射一条射线射线检测 游戏中的红外线,默认肉眼是看不到的,从某个初始点开始,沿着特定的方向发射一条不可见且无限长的射线,通过此射线检测是否有任何模型添加了Collider碰撞器组件。一旦检测到碰撞,停止射线继续发射。 碰撞检…...
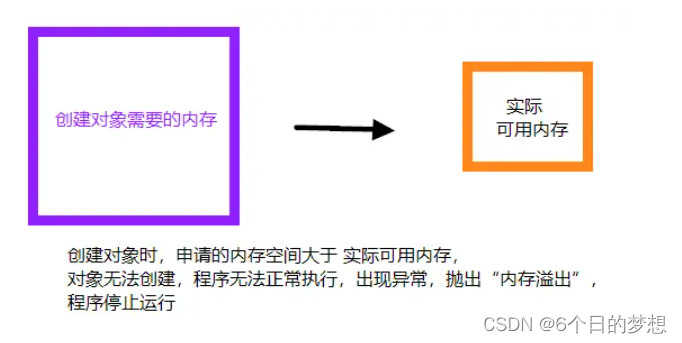
内存泄漏和内存溢出的区别
参考答案 内存溢出(out of memory):指程序在申请内存时,没有足够的内存空间供其使用,出现 out of memory。内存泄露(memory leak):指程序在申请内存后,无法释放已申请的内存空间,内存泄露堆积会导致内存被…...

文本三剑客之sed编辑器
文本三剑客:都是按行读取后处理。 grep 过滤行内容。awk 过滤字段。sed 过滤行内容;修改行内容。sed编辑器 sed是一种流编辑器,流编辑器会在编辑器处理数据之前基于预先提供的一组规则来编辑数据流。 sed编辑器可以根据命令来处理数据流中…...
深度学习:GPT1、GPT2、GPT-3
深度学习:GPT1、GPT2、GPT3的原理与模型代码解读GPT-1IntroductionFramework自监督学习微调ExperimentGPT-2IntroductionApproachConclusionGPT-3GPT-1 Introduction GPT-1(Generative Pre-training Transformer-1)是由OpenAI于2018年发布的…...

使用Docker 一键部署SpringBoot和SpringCloud项目
使用Docker 一键部署SpringBoot和SpringCloud项目 1. 准备工作2. 创建Dockerfile3. 创建Docker Compose文件4. 构建和运行Docker镜像5. 验证部署6. 总结Docker是一个非常流行的容器化技术,可以方便地将应用程序和服务打包成容器并运行在不同的环境中。在本篇博客中,我将向您展…...

【数据结构】用栈实现队列
💯💯💯 本篇总结利用栈如何实现队列的相关操作,不难观察,栈和队列是可以相互转化的,需要好好总结它们的特性,构造出一个恰当的结构来实现即可,所以本篇难点不在代码思维,…...
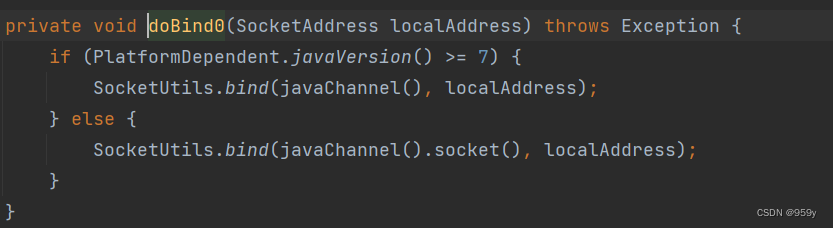
[Netty源码] 服务端启动过程 (二)
文章目录1.ServerBootstrap2.服务端启动过程3.具体步骤分析3.1 创建服务端Channel3.2 初始化服务端Channel3.3 注册selector3.4 端口绑定1.ServerBootstrap ServerBootstrap引导服务端启动流程: //主EventLoopGroup NioEventLoopGroup master new NioEventLoopGroup(); //从E…...

Week 14
代码源每日一题Div2 106. 订单编号 原题链接:订单编号 思路:这题本来没啥思路,直到获得了某位佬的提示才会做( 我们可以用set来维护一些区间,这些区间为 pair 类型,表示没有使用过的编号,每次…...

【微信小程序】-- 使用 Git 管理项目(五十)
💌 所属专栏:【微信小程序开发教程】 😀 作 者:我是夜阑的狗🐶 🚀 个人简介:一个正在努力学技术的CV工程师,专注基础和实战分享 ,欢迎咨询! &…...

leetcode每日一题:134. 加油站
系列:贪心算法 语言:java 题目来源:Leetcode134. 加油站 题目 在一条环路上有 n 个加油站,其中第 i 个加油站有汽油 gas[i] 升。 你有一辆油箱容量无限的的汽车,从第 i 个加油站开往第 i1 个加油站需要消耗汽油 cost[…...

开放式基金实时排行 API 数据接口
开放式基金实时排行 API 数据接口 多维度参数返回,实时数据,类型参数筛选。 1. 产品功能 返回实时开放式基金排行数据可定义查询基金类型参数;多个基金属性值返回多维指标,一次查询毫秒级返回;数据持续更新与维护&am…...

Android开发中synchronized的实现原理
synchronized的三种使用方式 **1.修饰实例方法,**作用于当前实例加锁,进入同步代码前要获得当前实例的锁。 没有问题的写法: public class AccountingSync implements Runnable{//共享资源(临界资源)static int i0;/*** synchronized 修饰实例方法*/p…...
)
【华为OD机试 2023最新 】 统一限载货物数最小值(C++)
题目描述 火车站附近的货物中转站负责将到站货物运往仓库,小明在中转站负责调度2K辆中转车(K辆干货中转车,K辆湿货中转车)。 货物由不同供货商从各地发来,各地的货物是依次进站,然后小明按照卸货顺序依次装货到中转车,一个供货商的货只能装到一辆车上,不能拆装,但是…...
【生活工作经验 十】ChatGPT模型对话初探
最近探索了下全球大火的ChatGPT,想对此做个初步了解 一篇博客 当今社会,自然语言处理技术得到了迅速的发展,人工智能技术也越来越受到关注。其中,基于深度学习的大型语言模型,如GPT(Generative Pre-train…...

基于Spring Boot房产销售平台的设计与实现【源码+论文】分享
开发语言:Java 框架:springboot JDK版本:JDK1.8 服务器:tomcat7 数据库:mysql 5.7 数据库工具:Navicat11 开发软件:eclipse/myeclipse/idea Maven包:Maven3.3.9 摘要 信息技术的发展…...

不同类型的电机的工作原理和控制方法汇总
电机控制是指对电机的启动、调速(加速、减速)、运转方向和停止进行的控制,不同类型的电机有着不同的工作原理和控制方法。 一、无刷电机 无刷电机是由电机主体和电机驱动板组成的一种没有电刷和换向器的机电一体化产品。在无刷电机中…...

计算机网络管理 TCP三次握手的建立过程,Wireshark抓包分析并验证TCP三次握手建立连接的报文
⬜⬜⬜ ---🟧🟨🟩🟦🟪 (*^▽^*)欢迎光临 🟧🟨🟩🟦🟪---⬜⬜⬜ ✏️write in front✏️ 📝个人主页:陈丹宇jmu 🎁欢迎各位→…...
HTTP/2.x:最新的网页加载技术,快速提高您的SEO排名
2.1 http2概念HTTP/2.0(又称HTTP2)是HTTP协议的第二个版本。它是对HTTP/1.x的更新,旨在提高网络性能和安全性。HTTP/2.0是由互联网工程任务组(IETF)标准化的,并于2015年发布。2.2 http2.x与http1.x区别HTTP…...

机器学习----线性回归
第一关:简单线性回归与多元线性回归 1、下面属于多元线性回归的是? A、 求得正方形面积与对角线之间的关系。 B、 建立股票价格与成交量、换手率等因素之间的线性关系。 C、 建立西瓜价格与西瓜大小、西瓜产地、甜度等因素之间的线性关系。 D、 建立西瓜…...

Logistic Regression实战指南:Python构建可解释二分类模型
1. 这不是数学课,是解决真实问题的工具链——从“预测用户是否会点击广告”说起你手头有一份电商后台导出的用户行为日志:20万条记录,每条包含年龄、性别、浏览时长、页面跳转次数、是否收藏过商品、最近一次下单距今天数……最后一列是标签&…...

从‘三调’到‘新国标’:深度解读用地分类演变背后的GIS数据处理逻辑与避坑指南
从‘三调’到‘新国标’:深度解读用地分类演变背后的GIS数据处理逻辑与避坑指南 当规划师第一次打开2020年11月版的《用地用海分类指南》,看到169种地类时,很多人会下意识倒吸一口冷气——这比2月版的132种足足多出37个细分项。这种"直男…...

智能交易系统:如何用AI重塑你的投资决策流程?
智能交易系统:如何用AI重塑你的投资决策流程? 【免费下载链接】TradingAgents-CN 基于多智能体LLM的中文金融交易框架 - TradingAgents中文增强版 项目地址: https://gitcode.com/GitHub_Trending/tr/TradingAgents-CN 在量化投资的世界里&#x…...
)
名胜古迹旅游网站的设计与实现(10076)
有需要的同学,源代码和配套文档领取,加文章最下方的名片哦 一、项目演示 项目演示视频 二、资料介绍 完整源代码(前后端源代码SQL脚本)配套文档(LWPPT开题报告/任务书)远程调试控屏包运行一键启动项目&…...

【专利视点】某抗病毒药物领域明星企业上市进程知产问题分析
医药领域IPO,正在随着证券市场监管新形势而发生变化,并从CXO板块向更多细分赛道延伸。知识产权问题是影响企业IPO上市的重要因素之一。从上海证券交易所官网统计得知,截至2024年10月14日,有102家医药制造业企业终止科创板IPO申请&…...

通过 API 实时监听企业微信外部群变更事件并同步本地数据库
能力介绍 在企业微信外部群的协同管理中,群聊的名称修改、群主变更、新成员加入或老成员退群等状态变更,往往无法仅靠主动拉取来感知。该能力通过配置接收事件服务器(Callback),利用标准的 HTTP POST 请求实时接收企微…...

揭秘Midjourney V6蒸汽波出图失败率高达63%的底层原因:3步绕过平台封禁,稳定生成霓虹故障美学
更多请点击: https://codechina.net 第一章:蒸汽波美学的数字幽灵:Midjourney V6封禁机制本质解构 蒸汽波(Vaporwave)以低保真采样、CRT扫描线、80年代商业图腾与数字怀旧为视觉语法,其美学内核恰恰在于对…...

CANN/asc-devkit SIMT数学函数文档
lrintf 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/can…...

ChatGPT-Web-Midjourney-Proxy终极指南:10大功能特性全解析
ChatGPT-Web-Midjourney-Proxy终极指南:10大功能特性全解析 ChatGPT-Web-Midjourney-Proxy是一个革命性的开源项目,它将ChatGPT对话、Midjourney图像生成、GPTs应用商店以及多种AI功能整合到一个统一的Web界面中。这个项目为开发者和普通用户提供了一站…...
)
Midjourney大画幅风格实战手册(从失效黑边到完美展陈:2023全球TOP 50商业项目验证的7大避坑节点)
更多请点击: https://kaifayun.com 第一章:Midjourney大画幅风格的本质解构与视觉范式跃迁 大画幅风格并非单纯指图像物理尺寸的放大,而是Midjourney通过隐式参数空间重构所催生的一种高密度视觉语义范式——它融合了胶片颗粒质感、景深压缩…...