【数据结构】汇总八、排序算法
排序Sort
【注意】本章是 排序 的知识点汇总,全文1万多字,含有大量代码和图片,建议点赞收藏(doge.png)!!
【注意】在这一章,记录就是数据的意思。
排序可视化网站:
Data Structure Visualization (usfca.edu)
文章目录
- 排序Sort
- 1.排序概述
- 2.分类
- 排序算法
- 1.直接插入排序Insertion Sort
- 1.1算法
- 1.2性能分析
- 2.折半插入排序
- 2.1算法
- 2.2性能分析
- 3.希尔排序Shell Sort
- 3.1算法思想
- 3.2算法
- 3.3性能分析
- 4.冒泡排序Bubble Sort
- 4.1算法思想
- 4.2算法
- 4.3性能分析
- ❗5.快速排序Quick Sort
- 5.1算法思想
- 5.2算法
- 5.3性能分析
- 5.简单选择排序Selection Sort
- 5.1算法
- 5.2性能分析
- 6.堆排序Heap Sort
- 6.1堆的定义
- 6.2创建堆
- 6.3堆排序
- 6.4算法
- 6.5性能分析
- 6.6在堆中插入删除元素
- 6.6.1插入
- 6.6.2删除
- 7.归并排序Merge Sort
- 7.1算法
- 7.2性能分析
- 8.基数排序Counting Sort
- 8.1性能分析
- 8.2应用
- 9.外部排序
- 9.1外存与内存之间的数据交换
- 9.2外部排序的原理
- 9.3影响外部排序效率的因素
- 9.4优化思路
- 10.败者树
- 败者树在多路平衡归并中的应用
- 11.置换-选择排序
- 12.最佳归并树
- 各种排序算法的比较
- 参考
1.排序概述
就是重新排列表中的元素,使表中的元素满足按关键字有序的过程。为了查找方便,通常希望计算机中的表是按关键字有序的。
-
排序的稳定性。假设 k i = k j ( 1 ≤ i ≤ n , 1 ≤ j ≤ n , i ! = j ) k_i=k_j(1≤i≤n,1≤j≤n,i!=j) ki=kj(1≤i≤n,1≤j≤n,i!=j),且在排序前的序列中 Ri 领先于 Rj(即 i < j)。
如果排序后 Ri 仍领先于 Rj,则称所用的排序方法是稳定的;反之,若可能使得排序后的序列中 Rj 领先于Ri,则称所用的排序方法是不稳定的。

【注意】算法是否具有稳定性并不能衡量一个算法的优劣,它主要是对算法的性质进行描述。如果待排序表中的关键字不允许重复,则排序结果是唯一的,那么选择排序算法时的稳定与否就无关紧要。
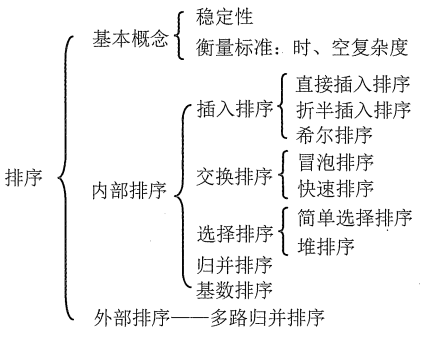
2.分类
-
内排序
内排序是在排序整个过程中,待排序的所有数据全部被放置在内存中。
-
外排序
外排序是由于排序的数据个数太多,不能同时放置在内存,整个排序过程需要在内外存之间多次交换数据才能进行。

通常可以将排序算法分为插入排序、交换排序、选择排序、归并排序和基数排序 5 大类。每种排序算法都有各自的优缺点,适合在不同的环境下使用,就其全面性能而言,很难提出一种被认为是最好的算法。内部排序算法的性能取决于算法的时间复杂度和空间复杂度,而时间复杂度一般是由比较和移动的次数决定的。
插入排序:
- 直接插入排序
- 折半插入排序
- 希尔排序
交换排序:
基于“交换”的排序:根据序列中两个元素关键字的比较结果来对换这两个记录在序列中的位置。
- 冒泡排序
- 快速排序
选择排序:
选择排序:每一趟在待排序元素中选取关键字最小(或最大)的元素加入有序字序列。
- 简单选择排序
- 堆排序
归并排序
基数排序
排序算法
1.直接插入排序Insertion Sort
**直接插入排序(Straight Insertion Sort)**的基本操作是将一个数据插入到已经排好序的有序表中,从而得到一个新的、数据数增1的有序表。
就是用一个for正向遍历所有的数据,每当遍历到一个数据的时候,就把它和前面所有已经遍历过的排好序的数据用for反向遍历进行对比,然后放到正确的位置。
1.1算法
// 直接插入排序,n是数组的长度
void InsertSort(int A[], int n){int i,j,temp;// i=1开始遍历for(i=1; i<n; i++){//若当前关键码A[i]小于其前驱A[i-1],将A[i]插入有序表if(A[i] < A[i-1]){temp = A[i]; //temp暂存A[i]//从后往前查找前面已经排好序的待插入位置(后移)for(j=i-1; j>=0 && temp<A[j]; --j){A[j+1] = A[j]; //向后挪位}A[j+1] = temp; //A[i]复制到插入位置}}
}
1.2性能分析
- 空间复杂度:O(1)
仅使用了常数个辅助单元。
- 时间复杂度:O(n2)
主要来自对比关键字、移动元素若有n个元素,则需要n-1趟处理,每趟操作都分为比较关键字和移动元素,而比较次数和移动次数取决于待排序表的初始状态。
最好:O(n)
最坏:O(n2)
- 稳定性:稳定
由于每次插入元素时总是从后向前先比较再移动,所以不会出现相同元素相对位置发生变化的情况,即直接插入排序是一个稳定的排序方法。
- 适用性:线性表(顺序存储和链式存储)
直接插入排序算法适用于顺序存储和链式存储的线性表。为链式存储时,可以从前往后查找指定元素的位置。
2.折半插入排序
因为使用上面直接插入排序之后,前面的序列已经是有序的了,那么此时就可以使用折半查找的方式去把数据移动到对应的位置。
下图使用了**带哨兵A[0]**的直接插入排序,此处的哨兵作用等价于temp:

2.1算法
//折半插入排序
void InsertSort(int A[] ,int n){int i, j, low, high, mid;//依次将A[2]~A[n]插入前面的已排序序列for(i=2; i<=n; i++){A[0]=A[i];//将A[i]暂存到A[0]low=1; high=i-1;//设置折半查找的范围while(low<=high){//折半查找(默认递增有序)mid=(low+high)/2; //取中间点if(A[mid]>A[0]) high=mid-1; //查找左半子表else low=mid+1; //查找右半子表}//元素后移for(j=i-1; j>=high+1; --j)A[j+1]=A[j]; //统一后移元素,空出插入位置//插入A[high+1]=A[0];}
}
2.2性能分析
- 空间复杂度:O(1)
仅使用了常数个辅助单元。
- 时间复杂度:O(n2)
比起“直接插入排序”,比较关键字的次数减少,但是移动元素的次数没变,整体来看时间复杂度依然是O(n2)。
最好:O(n)
最坏:O(n2)
- 稳定性:稳定
由于每次插入元素时总是从后向前先比较再移动,所以不会出现相同元素相对位置发生变化的情况,即直接插入排序是一个稳定的排序方法。
- 适用性:线性表(顺序存储和链式存储)
直接插入排序算法适用于顺序存储和链式存储的线性表。为链式存储时,可以从前往后查找指定元素的位置。
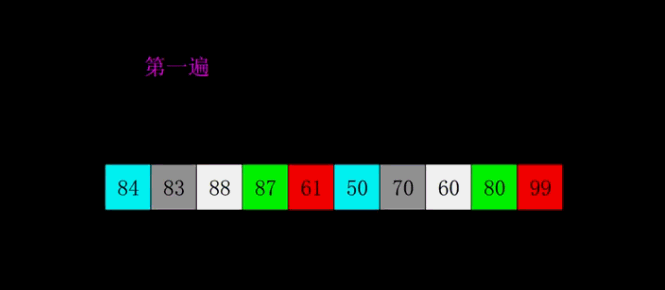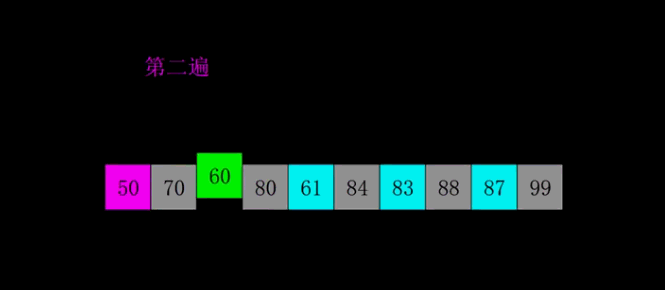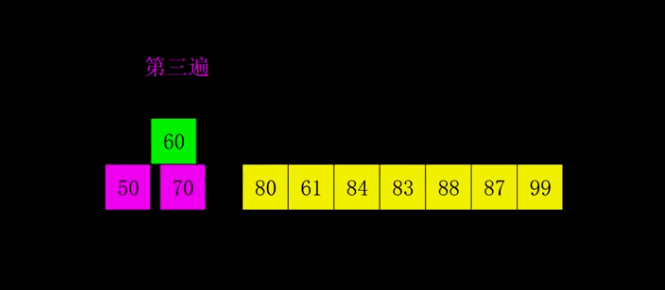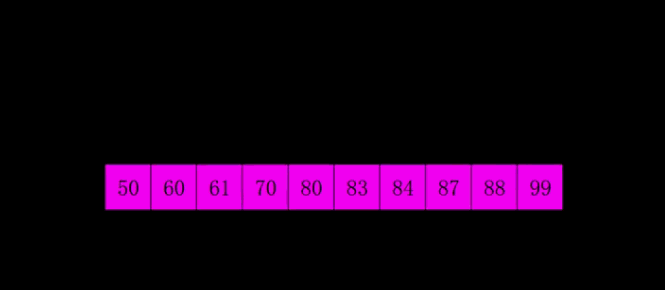
3.希尔排序Shell Sort
希尔排序(shell sort)是对直接插入排序进行改进而得来的,又称缩小增量排序。
1959年Shell发明,第一个突破O(n2)的排序算法,是简单插入排序的改进版。它与插入排序的不同之处在于,它会优先比较距离较远的元素。
3.1算法思想
算法思想(严谨):先将待排序表分割成若干形如 L [ i, i + d, i + 2d, . . . , i + kd ] 的“特殊”子表(即把相隔某个“增量d”的记录组成一个子表),对各个子表分别进行直接插入排序,当整个表中的元素已呈“基本有序”时,再对全体记录进行一次直接插入排序。
算法思想(个人):先追求表中元素部分有序,再逐渐逼近全局有序。
例如有8个元素,那么我们先用元素个数的一半 8/2=4 作为增量d1=4。
那么第一个元素的相距d1的元素就是1+d1=5。


第二趟的d2 = d1 / 2 = 4/2=2。
也就是1,(1+2),(1+4)
1,3,5,7构成一个子表。

第三趟d3 = 2/2 = 1那么就是最后一次处理。
完成所有排序。
动图:
或者:

3.2算法
//希尔排序
void ShellSort(int A[] ,int n){int d, i,j; //d是增量//A[0]只是暂存单元,不是哨兵,当j<=8时,插入位置已到// 一开始是元素个数的一半for(d=n/2; d>=1; d=d/2){ //步长变化//一开始从第一个子表的第二个元素d+1开始for(i=d+1; i<=n; ++i){if(A[i] < A[i-d]){ //需将A[i]插入有序增量子表A[0]=A[i]; //暂存在A[0]for(j= i-d; j>0 && A[0]<A[j]; j-=d)A[j+d] = A[j]; //记录后移,查找插入的位置A[j+d] = A[0]; //插入}//if}}
}
3.3性能分析
- 空间复杂度:O(1)
仅使用了常数个辅助单元。
- 时间复杂度:O(n3/2)
由于希尔排序的时间复杂度依赖于增量序列的函数,这涉及数学上尚未解决的难题,所以其时间复杂度分析比较困难。当n在某个特定范围时,希尔排序的时间复杂度约为O(n{3/2})。要好于直接排序的O(n2)。
- 稳定性:不稳定
当相同关键字的记录被划分到不同的子表时,可能会改变它们之间的相对次序,因此希尔排序是一种不稳定的排序方法。
- 适用性:顺序存储
希尔排序算法仅适用于线性表为顺序存储的情况。
4.冒泡排序Bubble Sort
一种交换排序
基于“交换”的排序:根据序列中两个元素关键字的比较结果来对换这两个记录在序列中的位置。
4.1算法思想
算法思想(严谨):从后往前(或从前往后)两两比较相邻元素的值,若为逆序,则交换它们,直到序列比较完。第一趟冒泡,结果是将最小的元素交换到待排序列的第一个位置(或将最大的元素交换到待排序列的最后一个位置),关键字最小的元素如气泡一般逐渐往上“漂浮”直至“水面”(或关键字最大的元素如石头一般下沉至水底)。下一趟冒泡时,前一趟确定的最小元素不再参与比较,每趟冒泡的结果是把序列中的最小元素(或最大元素)放到了序列的最终位置…这样最多做 n − 1 趟冒泡就能把所有元素排好序。
算法思想(个人):两两比较两个数大小,正向先找大的,逆向先找小的。共进行n趟排序。
4.2算法
//冒泡排序
void BubbleSort(int A[], int n){ for(int i=0; i<n-1; i++){bool flag=false; //表示本趟冒泡是否发生交换的标志for(int j=n-1; j>i; j--){ //一趟冒泡过程if(A[j-1] > A[j]){ //若为逆序swap(A[j-1],A[j]); //交换flag=true;}}if(flag==false) return; //本趟遍历后没有发生交换,说明表已经有序}
}
//交换
void swap(int &a, int &b){int temp = a;a = b;b = temp;
}
【注意】每次交换都需要移动3次元素。
4.3性能分析
- 空间复杂度:O(1)
仅使用了常数个辅助单元。
- 时间复杂度:O(n2)
最好:O(n)。原本就有序,只需要比较n-1次,交换次数为0。
最坏:O(n2)
-
稳定性:稳定
-
适用性:顺序存储和链表
❗5.快速排序Quick Sort
8.3_2_快速排序_哔哩哔哩_bilibili
基于“交换”的排序:根据序列中两个元素关键字的比较结果来对换这两个记录在序列中的位置
快速排序算法,被列为20世纪十大算法之一。快速排序是所有内部排序算法中平均性能最优的排序算法。
前面介绍及几种算法中,希尔排序相当于直接插入排序的升级,它们同属于插入排序类,堆排序相当于简单选择排序的升级,它们同属于选择排序类。
而快速排序是冒泡排序的升级,它们都属于交换排序类。即它也是通过不断比较和移动交换来实现排序的,只不过它的实现,增大了记录的比较和移动的距离,将关键字较大的记录从前面直接移动到后面,关键字较小的记录从后面直接移动到前面,从而减少了总的比较次数和移动交换次数。
5.1算法思想
算法思想(严谨):在待排序表L[1…n]中任取一个元素pivot作为枢轴(或基准,通常取首元素),通过一趟排序将待排序表划分为独立的两部分L[1k-1]和L[k+1n],使得L[1k-1]中的所有元素小于pivot,L[k+1n]中的所有元素大于等于pivot,则pivot放在了其最终位置L(k)上,这个过程称为一次“划分”。然后分别递归地对两个子表重复上述过程,直至每部分内只有一个元素或空为止,即所有元素放在了其最终位置上。
算法思想(个人):通过一趟排序将待排记录分割成独立的两部分,其中一部分记录的关键字均比另一部分记录的关键字小, 则可分别对这两部分记录继续进行排序,以达到整个序列有序的目的。
5.2算法
//用第一个元素将待排序序列划分成左右两个部分
int Partition(int A[],int low,int high){ int pivot=A[low]; //第一个元素作为枢轴while(low < high){ //用low、high搜索枢轴的最终位置 while(low < high && A[high] >= pivot)--high;A[low] = A[high]; //比枢轴大的元素移动到右端while(low<high&&A[low]<=pivot)++low;A[high] = A[low]; //比枢轴小的元素移动到左端}A[low] = pivot; //枢轴元素存放到最终位置return low; //返回存放枢轴的最终位置
}//快速排序
void QuickSort(int A[], int low,int high){if(low < high){ //递归跳出的条件int pivotpos = Partition(A,low,high); //划分QuickSort(A,low,pivotpos-1); //划分左子表QuickSort(A,pivotpos+1,high); //划分右子表}
}
5.3性能分析
- 空间复杂度: O ( l o g 2 n ) O(log_2n) O(log2n)
由于快速排序是递归的,需要借助一个递归工作栈来保存每层递归调用的必要信息,其容量应与递归调用的最大深度一致。所以空间复杂度:O(递归层数)。
最好情况下为 O ( l o g 2 n ) O(log_2n) O(log2n);
最坏情况下,因为要进行 n-1 次递归调用,所以栈的深度为 O(n);
平均情况下,栈的深度为 O ( l o g 2 n ) O(log_2n) O(log2n)。
- 时间复杂度: O ( n l o g 2 n ) O(nlog_2n) O(nlog2n)
快速排序的运行时间与划分是否对称有关,
最坏情况发生在两个区域分别包含 n-1 个元素和0个元素时,这种最大程度的不对称性若发生在每层递归上,即对应于初始排序表基本有序或基本逆序时,就得到最坏情况下的时间复杂度为 O(n2)。
【优化】提高算法的效率:
一种方法是尽量选取一个可以将数据中分的枢轴元素,如从序列的头尾及中间选取三个元素,再取这三个元素的中间值作为最终的枢轴元素;或者随机地从当前表中选取枢轴元素,这样做可使得最坏情况在实际排序中几乎不会发生。
在最理想的状态下,即Partition()可能做到最平衡的划分,得到的两个子问题的大小都不可能大于 n/2,在这种情况下,快速排序的运行速度将大大提升,此时,时间复杂度为 O ( n l o g 2 n ) O(nlog_2n) O(nlog2n)。
好在快速排序平均情况下的运行时间与其最佳情况下的运行时间很接近,而不是接近其最坏情况下的运行时间。
快速排序是所有内部排序算法中平均性能最优的排序算法。
- 稳定性:不稳定
在划分算法中,若右端区间有两个关键字相同,且均小于基准值的记录,则在交换到左端区间后,它们的相对位置会发生变化,即快速排序是一种不稳定的排序方法。
- 适用性:顺序存储和链表
5.简单选择排序Selection Sort
选择排序:每一趟在待排序元素中选取关键字最小(或最大)的元素加入有序字序列。
简单选择排序法(Simple Selection Sort):就是通过 n-i 次关键字间的比较,从 n-i+1 个记录中选出关键字最小的记录,并和第 i (1<i<n)个记录交换。
5.1算法
//简单选择排序
void SelectSort(int A[],int n){for(int(i=0; i<n-1; i++){ //一共进行n-1趟int min=i; //记录最小元素位置for(int j=i+1; j<n; j++){ //在A[i...n-1]中选择最小的元素if(A[j] < A[min]) min=j;//更新最小元素位置 }if(min!=i) swap(A[i],A[min]);//封装的swap()函数共移动元素3次}
}//交换
void swap(int &a,int &b){int temp = a;a = b;b = temp;
}
5.2性能分析
- 空间复杂度:O(1)
仅使用了常数个辅助单元。
- 时间复杂度:O(n2)
从上述代码中不难看出,在简单选择排序过程中,元素移动的操作次数很少,不会超过 3(n-1)次,最好的情况是移动 0 次,此时对应的表已经有序。
但元素间比较的次数与序列的初始状态无关,无论有序、逆序、还是乱序,一定需要 n-1 趟处理,所以需要对比的关键字始终是 (n-1)+(n-2)+…+1= n(n -1)/2 次,因此时间复杂度始终是O(n2)。
- 稳定性:不稳定
在第 i 趟找到最小元素后,和第 i 个元素交换,可能会导致第 i 个元素与其含有相同关键字元素的相对位置发生改变。例如,表L={2,2,1},经过一趟排序后L={1,2,2},最终排序序列也是L={1,2,2},显然,2与2的相对次序已发生变化。因此,简单选择排序是一种不稳定的排序方法。
- 适用性:顺序存储和链表
6.堆排序Heap Sort
8.4_2_堆排序_哔哩哔哩_bilibili
堆排序(Heap sort)是指利用堆这种数据结构所设计的一种排序算法,是对简单选择排序进行的一种改进。
6.1堆的定义
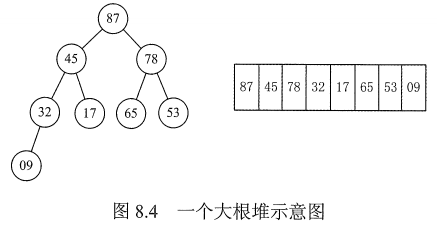
堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。
大根堆:每个结点的值都大于或等于其左右孩子结点的值。
或者理解为在完全二叉树中,根的值大于或等于左右子树的所有结点的值。
小根堆:每个结点的值都小于或等于其左右孩子结点的值。
大根堆:
6.2创建堆
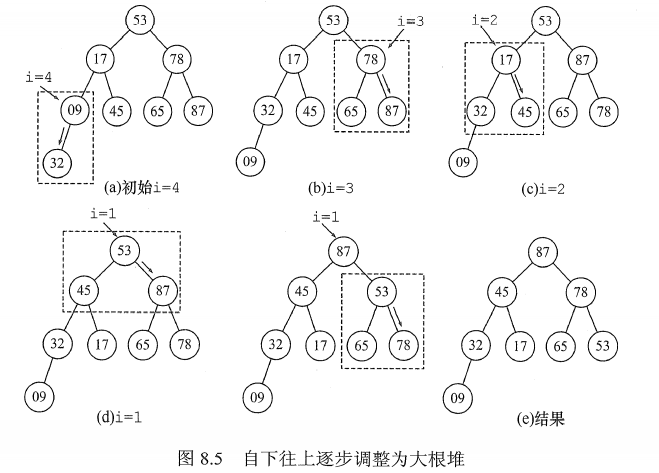
算法思想(严谨):堆排序的关键是构造初始堆。n个结点的完全二叉树,最后一个结点是第 ⌊n/2⌋ 个结点的孩子。对第 ⌊n/2⌋ 个结点为根的子树筛选(对于大根堆,若根结点的关键字小于左右孩子中关键字较大者,则交换),使该子树成为堆。之后向前依次对各结点(⌊n/2⌋-1~1)为根的子树进行筛选,看该结点值是否大于其左右子结点的值,若不大于,则将左右子结点中的较大值与之交换,交换后可能会破坏下一级的堆,于是继续采用上述方法构造下一级的堆,直到以该结点为根的子树构成堆为止。反复利用上述调整堆的方法建堆,直到根结点
算法思想(个人):从最后面一个非叶子节点开始,判断是否满足堆(大根堆or小根堆)的要求,不满足则进行调整,满足后再往前寻找不满足的结点进行调整,直到根节点完全调整完毕。
这时候,如果根节点的小元素“下坠”之后,破坏了原先子树的根堆,那么再对进行交换的子树进行调整。
6.3堆排序
创建大根堆之后,根节点就是所有元素的最大值,这时候,把这个最大值加入有序序列,剩下的再进行大根堆创建(小元素下坠),得到新的大根堆,再拿走最大元素根节点。
多次重复上面的过程,直到所有元素都放入有序序列。
【注意】大根堆 = 增序,树顶上最大,那么有序序列中最后一个元素最大。

6.4算法
//建立大根堆
void BuildMaxHeap(int A[], int len){for(int i=len/2; i>0; i--) //从后往前调整所有非终端(叶子)结点HeadAdjust(A,i,len);
}//将以 k 为根的子树调整为大根堆(len是长度)
void HeadAdjust(int A[], int k, int len){A[0] = A[k]; //A[0]暂存子树的根结点for(int i=2*k; i<=len; i*=2){ //沿key较大的子结点向下筛选(2*k就是左孩子)if(i<len && A[i]<A[i+1]) //判断左右孩子谁key更大i++; //取key较大的子结点的下标if(A[0]>=A[i]) break; //左右孩子都不如根节点key大,筛选结束,不需要交换else{A[k]=A[i]; //将A[i]调整到双亲结点上k=i; //修改k值,以便继续向下筛选}}A[k]=A[0] ; //被筛选结点的值放入最终位置
}//堆排序的完整逻辑
void HeapSort(int A[], int len){BuildMaxHeap(A,len) ; //初始建堆for(int i=len; i>1, i--){ //n-1趟的交换和建堆过程swap(A[i], A[1]); //堆顶元素和堆底元素交换HeadAdjust(A,1,i-1); //把剩余的待排序元素整理成堆}
}
6.5性能分析
- 空间复杂度:O(1)
仅使用了常数个辅助单元。
- 时间复杂度: O ( n l o g 2 n ) O(nlog_2n) O(nlog2n)
一个结点,每“下坠”一层,最多只需对比关键字2次。
若树高为h,某结点在第i层,则将这个结点向下调整最多只需要“下坠”h-i层,关键字对比次数不超过2(h-i)。
n个结点的完全二叉树树高 h = ⌊log2n⌋+1。
第i层最多有2i-1个结点,而只有第1~(h-1)层的结点才有可能需要“下坠”调整。
建堆时间为O(n),之后有 n-1 次向下调整操作,每次调整的时间复杂度为O(h)=O(log2n)。故在最好、最坏和平均情况下,堆排序的时间复杂度为 O ( n l o g 2 n ) O(nlog_2n) O(nlog2n)。
- 稳定性:不稳定
进行筛选时,有可能把后面相同关键字的元素调整到前面,所以堆排序算法是一种不稳定的排序方法。
- 适用性:顺序存储和链表
6.6在堆中插入删除元素
6.6.1插入
- 将新元素放入表尾,也就是树的最后一个叶子节点。
- 对于小根堆,与父节点对比,若新元素比父节点更小,则将二者互换。
- 新元素就这样一路“上升”,直到无法继续上升为止。
【注意】每次上升,只需要进行1次关键字的对比。
6.6.2删除
被删除的元素用堆底元素替代,然后让该元素不断“下坠”,直到无法下坠为止。
【注意】每次下坠,如果有2个孩子,那么就进行2次关键字对比,1个孩子就进行1次关键字对比。
7.归并排序Merge Sort
8.5_1_归并排序_哔哩哔哩_bilibili
归并排序与上述基于交换、选择等排序的思想不一样,“归并"的含义是将两个或两个以上的有序表组合成一个新的有序表。
归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列。即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为2-路归并。
2路归并排序:假定待排序表含有n个记录,则可将其视为n个有序的子表,每个子表的长度为1,然后两两归并,得到 ⌈ n/2 ⌉ 个长度为2或1的有序表;继续两两归并…如此重复,直到合并成一个长度为n的有序表为止,这种排序方法称为2路归并排序。
【总结】m路归并,每选出一个元素需要对比关键字m-1次。

动图:
7.1算法

int *B=(int *)malloc(nksizeof(int));//辅助数组B
//A[low..mid]和A[mid+1...high]各自有序,将两个部分归并
void Merge(int A[],int low,int mid,int high){int i,j,k;for(k=low; k<=high ; k++)B[k]=A[k]; //将A中所有元素复制到B中for(i=low,j=mid+1,k=i; i<=mid && j<=high; k++){if(B[i]<=B[j])A[k]=B[i++]; //将较小值复制到A中elseA[k]=B[j++];}//forwhile(i<=mid) A[k++]=B[i++];while(j<=high) A[k++]=B[j++];
}//对整个数组进行拆分,然后归并排序
void MergeSort(int A[],int low,int high){if(low<high){int mid=(low + high)/2; //从中间划分MergeSort(A,low,mid); //对左半部分归并排MergeSort(A,mid+1,high); //对右半部分归并排Merge(A,low,mid,high); //归并}//if
}
7.2性能分析
- 空间复杂度:O(n)
Merge()操作中,辅助空间刚好为n个单元,所以算法的空间复杂度为O(n)。
- 时间复杂度: O ( n l o g 2 n ) O(nlog_2n) O(nlog2n)
2路归并的“归并树”―一形态上就是一棵倒立的二叉树。
根据二叉树的性质:二叉树的第h层最多有2h-1个结点。
若树高为h,则应满足n个结点 < 2h-1,即 h-1 = ⌈log2n⌉ 。
结论:n个元素进行2路归并排序,归并趟数 = ⌈log2n⌉ 。
每趟归并的时间复杂度为 O(n),共需进行 ⌈log2n⌉ 趟归并,所以算法的时间复杂度为 O(nlog2n)。
- 稳定性:稳定
由于Merge()操作不会改变相同关键字记录的相对次序,所以2路归并排序算法是一种稳定的排序方法。
8.基数排序Counting Sort
8.5_2_基数排序_哔哩哔哩_bilibili
基数排序不是基于“比较"的排序算法。
基数排序得到递增序列的过程如下:
初始化:设置 r 个空队列Q0, Q1, … Qr-1(这里是Q9, …, Q1, Q0十位)
按照各个关键字位权重递增的次序 (个、十、百),对 d 个关键字位分别做“分配”和“收集”:
分配:顺序扫描各个元素,若当前处理的关键字位=x,则将元素插入 Qx 队尾
收集:把Q0, Q1, … Qr-1各个队列中的结点依次出队并链接
【注意】如果是递增,那么每次个十百千位…排序时候,就是大数在前面;如果是递减,那么就是小数在前面。


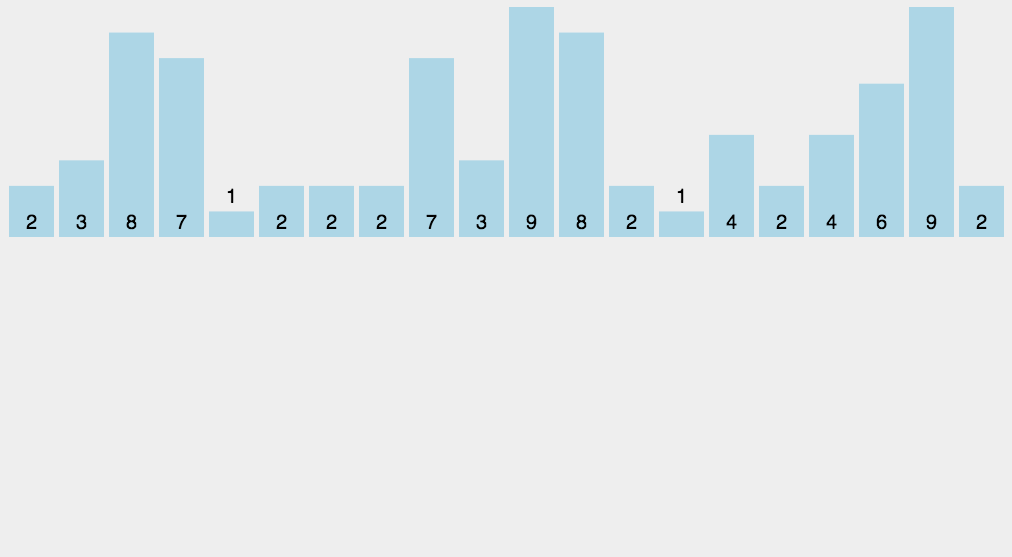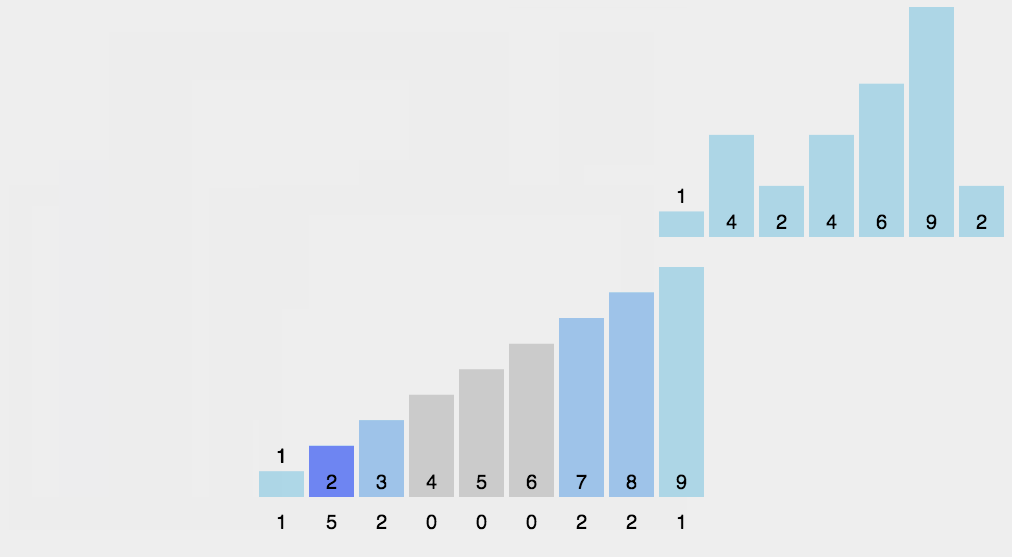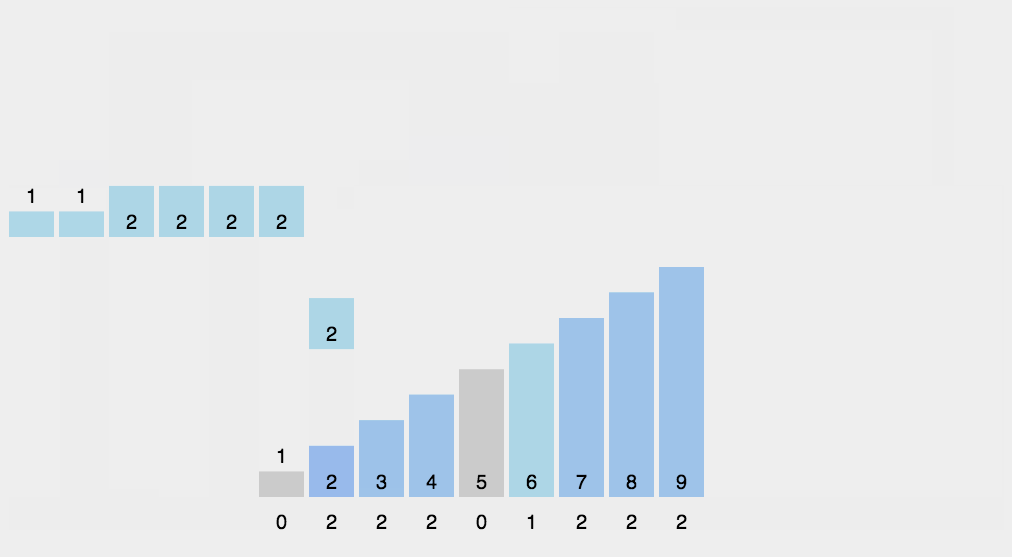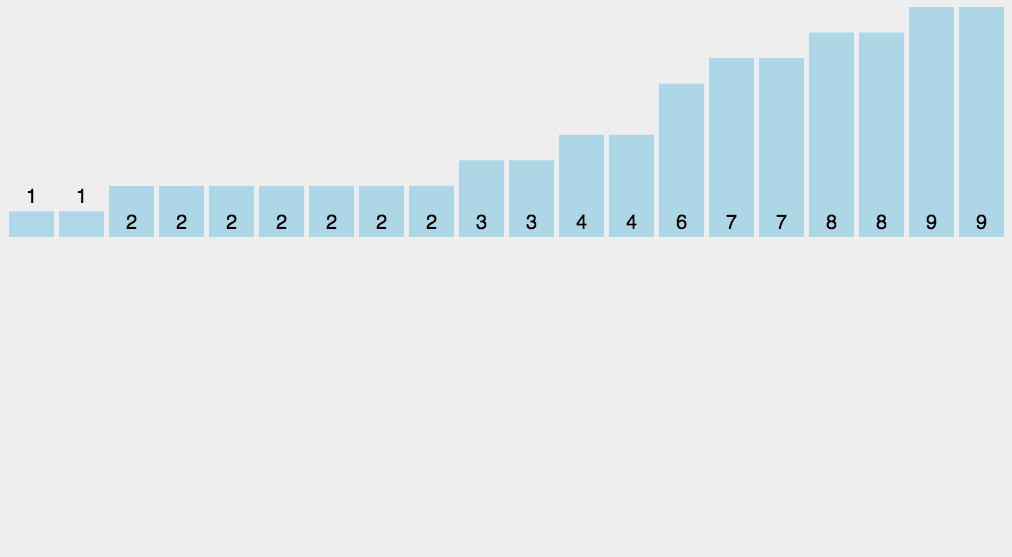
8.1性能分析
- 空间复杂度:O®
需要r个辅助队列,空间复杂度=O®
- 时间复杂度:O( d(n+r) )
一趟分配O(n),一趟收集O®,总共 d 趟分配、收集,总的时间复杂度=O(d(n+r))。
- 稳定性:稳定
基你太稳~
8.2应用

基数排序擅长解决的问题:
-
数据元素的关键字可以后便地拆分为 d 组,即 d 较小。
反例:给5个人的身份证排序,身份证18位,d=18有点多
-
每组关键字的取值范围不大,即 r 较小。
反例:给中文人名排序,人名汉字太多了,取值范围极广
-
数据元素个数n较大。
9.外部排序
9.1外存与内存之间的数据交换

9.2外部排序的原理
使用明并排席的方法,最少只需在内存中分配3块大小的缓冲区即可对任意一个大文件进行排序。
这里就是在外存中包含16块磁盘块,每一块中包含3个记录。

9.3影响外部排序效率的因素
进行归并过程中:
- 先生成初始化归并段(对每一段进行内部排序)
- 2路归并进行多次
外部排序时间开销 = 读写外存的时间+内部排序所需时间+内部归并所需时间
读写磁盘的次数 = 2*块数 + 2*块数 * 归并的趟数
因为块数是确定的,所有可以通过减少归并的趟数进行优化。
9.4优化思路
- 方法一:增加归并路数 k,进行多路平衡归并。
那么就把 之前的2路归并转换为多路归并。
也就需要多个内存缓冲区。
- 优点
采用多路归并可以减少归并趟数,从而减少磁盘IO(读写)次数。
归并路越多,效率越高。
- 负面影响
- k路归并时,需要开k个输入缓冲区,内存开销增加。
- 每挑选一个关键字需要对比关键字(k-1)次,内部归并所需时间增加。(可用“败者树"减少关键字对比次数)
- 方法二:减少初始归并段数量 r。
对r个初始归并段,做k路归并,则归并树可用k叉树表示。
若树高为h,则归并趟数 = h-1 = ⌈ log k r ⌉
可以看出:k越大,r越小,归并趟数越少,读写磁盘次数越少。
【结论】若能增加初始归并段的长度,则可减少初始归并段数量r。
按照本节介绍的方法生成的初始归并段,若共 N 个记录,内存工作区可以容纳 L 个记录,则初始归并段数量r= ⌈ N/L ⌉ 。(可用“置换-选择排序”进—步减少初始归开段数量)
10.败者树
败者树:可视为一棵完全二叉树(多了一个头头)。
k个叶结点分别是当前参加比较的元素,非叶子结点用来记忆左右子树中的“失败者”,而让胜者往上继续进行比较,一直到根结点。
败者树在多路平衡归并中的应用
8.7_2_败者树_哔哩哔哩_bilibili

对比次数:
k 路平衡归并,第一次构造败者树需要对比关键字k-1次。
当有了败者树,选出最小元素,只需对比关键字 ⌈ log 2 k ⌉ 次。
8路归并,第一次需要对比7次,以后每次对比新元素,只需要 ⌈ log 2 8 ⌉ = 3次(23=8)。
11.置换-选择排序
老办法:按照本节介绍的方法生成的初始归并段,若共 N 个记录,内存工作区可以容纳 L 个记录,则初始归并段数量r= ⌈ N/L ⌉ 。(可用“置换-选择排序”进—步减少初始归开段数量)
有24个记录,用于内部排序的工作区可以容纳3个记录,那么归并段有 24/3 = 8个归并段。
8.7_3_置换-选择排序_哔哩哔哩_bilibili
- 放入工作区之后,依次拿出最小的元素,并且记录这个元素大小
- 之后依次继续拿出小元素
- 但是这个小元素不能比记录的值还要小
- 因为是放在后面的,所以比记录还要小的元素会被冻结,大的拿出来放到最后
- 最后如果工作区全部被冻结,那么就重启一行归并段
12.最佳归并树

归并过程中磁盘I/O的次数 = 读磁盘次数 + 写磁盘次数
= 归并树WPL *2
所以要I/O次数最少,那么就是WPL最小,那么就是哈夫曼树
【注意】对于k叉归并,若初始归并段的数量无法构成严格的 k 叉归并树则需要补充几个**长度为0的“虚段”**再进行k叉哈夫曼树的构造。
严格的 k 叉归并树:比如3路归并,如果3路归并到最后剩下两个结点,那么就不合理,必须最后归并的时候也是3个结点。
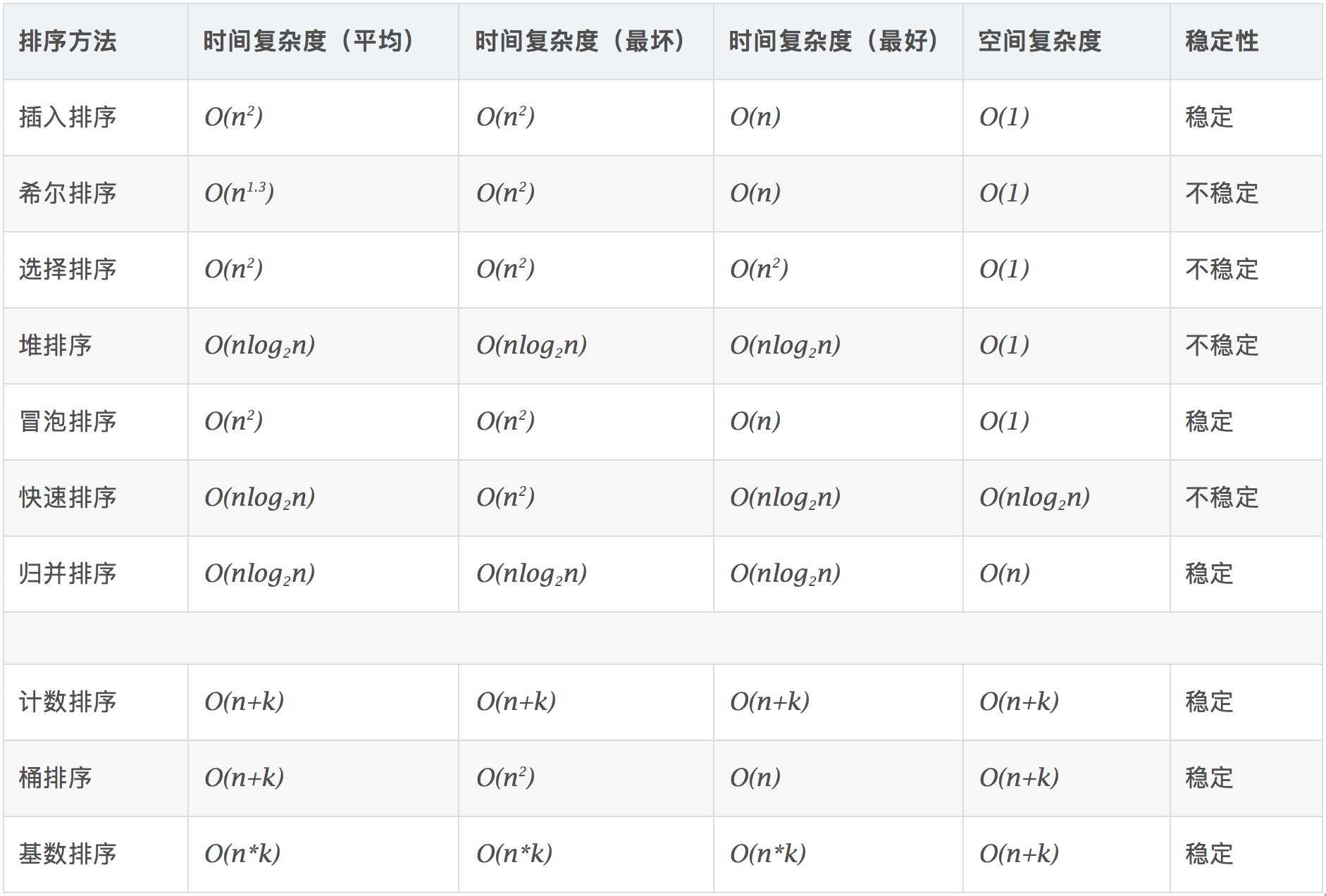
各种排序算法的比较
参考
数据结构:排序(Sort)【详解】_sort结构体排序-CSDN博客
十大经典排序算法(动图演示) - 一像素 - 博客园 (cnblogs.com)
相关文章:
【数据结构】汇总八、排序算法
排序Sort 【注意】本章是 排序 的知识点汇总,全文1万多字,含有大量代码和图片,建议点赞收藏(doge.png)!! 【注意】在这一章,记录就是数据的意思。 排序可视化网站: D…...

Java-分割list并执行多线程任务的工具类
要创建一个用于分割列表并执行多线程任务的工具类,你可以使用 Java 的 ExecutorService 和 ThreadPoolExecutor 来实现。下面是一个详细的示例,展示了如何创建这样一个工具类。 步骤 1: 创建线程池 首先,创建一个线程池来执行任务。 步骤 2: 分割列表 接着,定义一个方…...

Springboot-从服务器获取一个输入流,转成视频文件存到oss
要在Spring Boot应用中从服务器获取一个输入流,然后将该流转换为视频文件并存储到阿里云 OSS中,你可以遵循以下步骤: 设置阿里云OSS客户端:首先,你需要配置阿里云OSS客户端,以便能够上传文件到OSS。 获取输入流:使用HTTP客户端(如RestTemplate或WebClient)从服务器…...
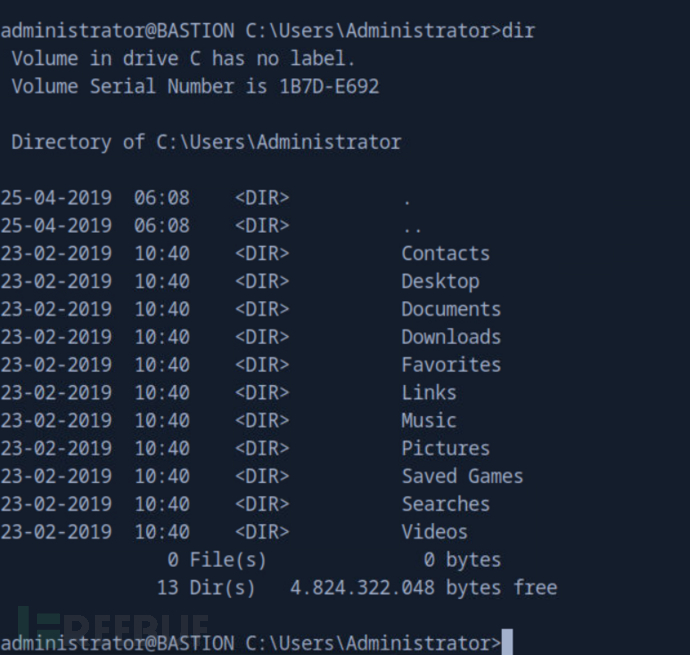
[Meachines] [Easy] Bastion SMB未授权访问+VHD虚拟硬盘挂载+注册表获取NTLM哈希+mRemoteNG远程管理工具权限提升
信息收集 IP AddressOpening Ports10.10.10.134TCP:22, 135, 139, 445, 5985, 47001, 49664, 49665, 49666, 49667, 49668, 49669, 49670 $ nmap -p- 10.10.10.134 --min-rate 1000 -sC -sV PORT STATE SERVICE VERSION 22/tcp open ssh OpenSSH fo…...

STM32标准库学习笔记-9.DMA 直接存储器存取
参考教程:【STM32入门教程-2023版 细致讲解 中文字幕】 DMA(Direct Memory Access) DMA(Direct Memory Access)直接存储器存取DMA可以提供外设和存储器或者存储器和存储器之间的高速数据传输,无须CPU干预…...

ubuntu VCS+verdi安装遇到的一些问题
主体流程:https://blog.51cto.com/u_15346322/4995147 我的是Ubuntu22.4 安装目录问题 执行 ./installer -gui 只能安装到home 或者 sudo ./setup.sh -install_as_root 能安装到/usr/ 目录 运行 vcs 出现 bin/sh: Illegal option -h sudo rm -f /bin/sh sudo…...

使用Poi-tl对word模板生成动态报告
一、pom依赖问题: <dependency> <groupId>com.deepoove</groupId> <artifactId>poi-tl</artifactId> <version>1.12.2</version> </dependency> 使用 poi-tl 的 1.12.2版本,如果使用了poi依赖&#x…...

day45-dynamic programming-part12-8.16
tasks for today: 1. 115.不同的子序列 2. 583.两个字符串选的删除操作 3. 72.编辑距离 4. 总结编辑两个序列关系的问题 ------------------------------------------------------------------- 1. 115.不同的子序列 In this practice, it is necessary to compare with t…...

C# String的方法
目录 #region 知识点九 字符串切割 #region 知识点一 字符串指定位置获取 #region 知识点二 字符串拼接 #region 知识点三 正向查找字符位置 #region 知识点四 反向查找指定字符串位置 #region 知识点五 移除指定位置后的字符 #region 知识点六 替换指定字符串 #region 知识点七…...

Oracle RAC vs Clusterware vs ASM
Oracle RAC vs Clusterware vs ASM Oracle RACCache FusionRAC后台进程自动负载管理DBA管理工具Oracle ClusterwareCRS组件HAS组件管理工具Oracle ASMASM实例ASM磁盘组镜像和故障组ASM磁盘ASM文件Oracle RAC RAC即Real Application Clusters,是一种Oracle高可用部署架构。Orac…...

“华为杯”第十五届中国研究生数学建模竞赛-F题:机场新增卫星厅对中转旅客影响的研究
目录 摘 要: 一、 问题重述 1.1 研究背景 1.2 已知信息 1.3 需要解决的问题 二、 模型假设 三、 符号说明 四、 问题一模型的建立与求解 4.1 问题描述与分析 4.2 模型的求解 4.3 求解结果与分析 五、 问题二模型的建立与求解 5.1 问题描述与分析 5.2 模型的求解 5.3 求解结果与…...

正点原子linux开发板 qt程序交叉编译执行
1.开发板光盘 A-基础资料->5、开发工具->1、交叉编译器->fsl-imx-x11-glibc-x86_64-meta-toolchain-qt5-cortexa7hf-neon-toolchain-4.1.15-2.1.0.sh 拷贝到 Ubuntu 虚拟机 用文件传输系统或者共享文件夹传输到linux虚拟机 用ls -l查看权限,如果是白色的使…...
聚星文社和虹猫哪个好
聚星文社和虹猫是两个不同的公司,各有各的特点。下面是它们各自的优点: 聚星文社:Docshttps://docs.qq.com/doc/DRU1vcUZlanBKR2xy 聚星文社是一家传媒公司,专注于出版漫画、动画、小说等内容,拥有丰富的IP资源和创作…...

三十八、【人工智能】【机器学习】【监督贝叶斯网络(Bayesian Networks)学习】- 算法模型
系列文章目录 第一章 【机器学习】初识机器学习 第二章 【机器学习】【监督学习】- 逻辑回归算法 (Logistic Regression) 第三章 【机器学习】【监督学习】- 支持向量机 (SVM) 第四章【机器学习】【监督学习】- K-近邻算法 (K-NN) 第五章【机器学习】【监督学习】- 决策树…...

[书生大模型实战营][L0][Task1] Linux 远程连接 InternStudio
[书生大模型实战营][Task1] Linux 远程连接 InterStudio 1. 申请 InterStudio 账号 https://studio.intern-ai.org.cn/console/dashboard 2. ssh 生成公匙与密匙 使用 ssh-gen 生成公匙与密匙 # 1. ssh-gen ssh-gen# 2. 查看生成的文件 ls ~/.ssh# 3. 打开生成的公匙&#…...
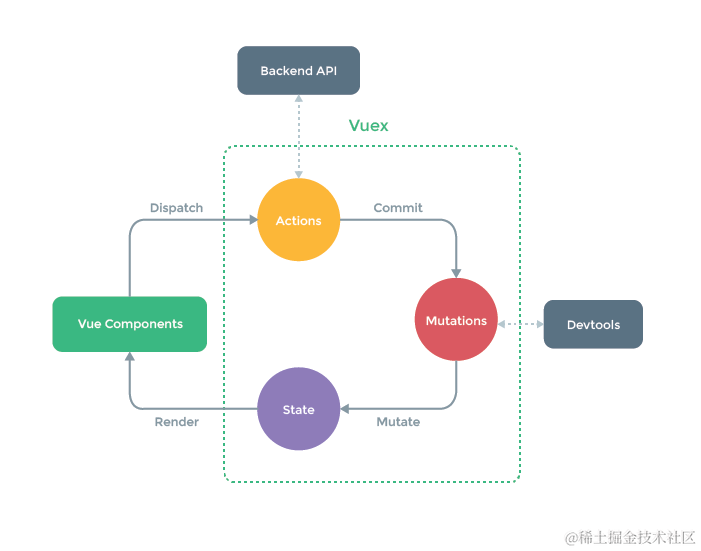
【vue教程】六. Vue 的状态管理
目录 往期列表本章涵盖知识点回顾Vuex 的基本概念什么是 Vuex?为什么需要 Vuex? Vuex 的核心概念stategettersmutationsactionsmodules Vuex 的安装和基本使用安装 Vuex创建 store在 Vue 应用中使用 store在组件中访问和修改状态 Vuex 的模块化模块化的好…...

无人机电子调速器详解!!!
电子调速器是无人机动力系统中的关键组件,主要负责将电池提供的直流电转换为交流电,并精确控制电机的转速,从而实现对无人机飞行状态的精确控制。以下是对无人机电子调速器的详细解析: 一、基本功能与原理 功能: 直…...
)
Clichouse数据导出导入(数据迁移)
背景:因为clickhouse数据持续增加,导致服务器磁盘不够使用,云服务器的系统盘不能扩容,所以只能进行迁移 连接clickhouse查看要迁移那些数据库 rootjcdata:~/buckup/clickhouse# clickhouse-client -udefault --password 123456…...
 源码剖析及使用)
Java基础——IService.class 中查询数据方法list() 源码剖析及使用
下面详细介绍Mybatis-plus 的默认服务IService.class 中的查询数据的方法及使用。 方法定义及其详细介绍 default List<T> list(Wrapper<T> queryWrapper) default List<T> list(Wrapper<T> queryWrapper) {return this.getBaseMapper().selectList(q…...

MySQL库表的基本操作
目录 1.库的操作1.1 创建数据库1.2字符集和校验规则①查看系统默认字符集以及校验规则②查看数据库支持的字符集③查看数据库支持的字符集校验规则④校验规则对数据库的影响 1.3操纵数据库①查看数据库②显示创建的数据库的语句③修改数据库④数据库删除⑤备份和恢复⑥还原注意…...

探索三维流固耦合中岩石试样孔隙度变化的奇妙世界
三维流固耦合,考虑岩石试样孔隙度变化在工程和科学研究领域,三维流固耦合问题一直是备受关注的焦点,而当考虑到岩石试样孔隙度变化时,这个问题更是增添了不少复杂性与趣味性。 三维流固耦合基础概念 简单来说,流固耦合…...

【Git】TortoiseGit无法push远程仓库
问题 无法使用TortoiseGit push远程仓库,但是使用Git Bash命令正常,提示如下错误。 TortoiseGitPlink Fatal Error No supported authentication methods available(server sent: publickey) 原因 这个问题的核心原因在于:TortoiseGit 默认…...

Xamarin.Macios性能优化终极指南:10个让你的应用运行如飞的技巧
Xamarin.Macios性能优化终极指南:10个让你的应用运行如飞的技巧 【免费下载链接】xamarin-macios .NET for iOS, Mac Catalyst, macOS, and tvOS provide open-source bindings of the Apple SDKs for use with .NET managed languages such as C# 项目地址: http…...

智能化磁盘空间革命:CleanMyWechat如何一键释放微信PC端数十GB存储空间
智能化磁盘空间革命:CleanMyWechat如何一键释放微信PC端数十GB存储空间 【免费下载链接】CleanMyWechat 自动删除 PC 端微信缓存数据,包括从所有聊天中自动下载的大量文件、视频、图片等数据内容,解放你的空间。 项目地址: https://gitcode…...

GHelper:华硕笔记本的终极开源性能控制解决方案
GHelper:华硕笔记本的终极开源性能控制解决方案 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, Strix, Scar, an…...

go语言里面实现并发安全扣减库存的几种方式
一、基本数据准备 1、数据表的创建 -- ---------------- -- 库存表 -- ---------------- DROP TABLE IF EXISTS inventory; CREATE TABLE inventory (id int NOT NULL AUTO_INCREMENT primary key COMMENT 主键id,goods_id int(11) default 1 comment 商品id,stocks int(11) de…...

Mybatis @MapKey注解:高效实现List到Map的转换技巧
1. 为什么需要List转Map? 在实际开发中,我们经常会遇到这样的场景:从数据库查询出一批数据后,需要根据某个字段快速查找对应的记录。比如查询用户列表后,需要根据用户ID快速获取用户信息。这时候,把List转换…...

终极指南:3个阶段让旧款Mac免费升级到最新macOS系统
终极指南:3个阶段让旧款Mac免费升级到最新macOS系统 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 你是否拥有一台2012-2017年的旧款Mac…...

数据仓库实战:数据分层设计全面解析——如何大幅提升数据可用性与性能
数据仓库实战:数据分层设计全面解析——如何大幅提升数据可用性与性能摘要一、基础认知:数据仓库为什么必须做数据分层?1.1 核心定义1.2 不做分层的严重问题1.3 数据分层核心目标二、标准架构:数据仓库经典 5 层设计(企…...

Vue大屏自适应实战指南:v-scale-screen深度解析与完整方案
Vue大屏自适应实战指南:v-scale-screen深度解析与完整方案 【免费下载链接】v-scale-screen Vue large screen adaptive component vue大屏自适应组件 项目地址: https://gitcode.com/gh_mirrors/vs/v-scale-screen 在当今数据驱动的时代,大屏数据…...