阿里声音项目Qwen2-Audio的部署安装,在服务器Ubuntu22.04系统——点动科技
阿里声音项目Qwen2-Audio的部署安装,在服务器Ubuntu22.04系统——点动科技
- 一、ubuntu22.04基本环境配置
- 1.1 更换清华Ubuntu镜像源
- 1.2 更新包列表:
- 2. 安装英伟达显卡驱动
- 2.1 使用wget在命令行下载驱动包
- 2.2 更新软件列表和安装必要软件、依赖
- 2.2 卸载原有驱动
- 2.3 安装驱动
- 2.4 安装CUDA
- 2.5 环境变量配置
- 二、安装miniconda环境
- 1. 下载miniconda3
- 2. 安装miniconda3
- 3. 切换到bin文件夹
- 4. 输入pwd获取路径
- 5. 打开用户环境编辑页面
- 6. 重新加载用户环境变量
- 7. 初始化conda
- 8.验证是否安装成功
- 9.conda配置
- 三、安装Qwen2-Audio
- 1.克隆仓库
- 1.1 github克隆
- 1.2 国内github镜像克隆
- 1.3. 进入目录
- 2.创建虚拟环境
- 2.1 进入虚拟环境
- 3. 安装依赖
- 3.1设置清华源、更新pip
- 3.2安装torch 12.4cuda版本
- 3.3安装依赖文件
- 3.4安装webui界面及其他未安装依赖
- 3.5安装魔搭库准备下载模型文件:
- 3.6下载相关模型
- 3.7执行代码,启动webui界面
- 3.8加入声音驱动,实现真正的语音聊天
- 四、成功实现语音交互
- 4.1 找不到录音机问题
一、ubuntu22.04基本环境配置
1.1 更换清华Ubuntu镜像源
- 删除原来的文件
rm /etc/apt/sources.list
- 开始编辑新文件
vim /etc/apt/sources.list
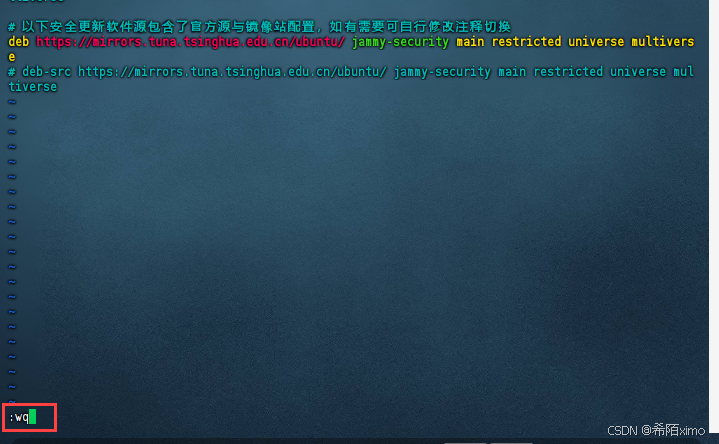
- 先按i键,粘贴以下内容
# 默认注释了源码镜像以提高 apt update 速度,如有需要可自行取消注释
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy-updates main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy-updates main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy-backports main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy-backports main restricted universe multiverse# 以下安全更新软件源包含了官方源与镜像站配置,如有需要可自行修改注释切换
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy-security main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy-security main restricted universe multiverse

-
确保内容跟上述图片一致
-
按esc键,再输入冒号+wq保存
1.2 更新包列表:
- 打开终端,输入以下命令:
sudo apt-get update
sudo apt upgrade
- 更新时间较长,请耐心等待
2. 安装英伟达显卡驱动
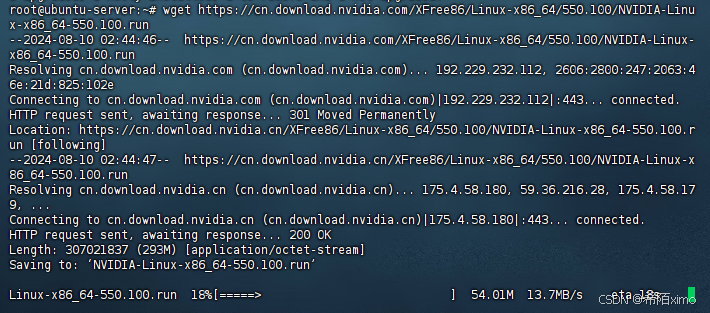
2.1 使用wget在命令行下载驱动包
wget https://cn.download.nvidia.com/XFree86/Linux-x86_64/550.100/NVIDIA-Linux-x86_64-550.100.run
2.2 更新软件列表和安装必要软件、依赖
sudo apt-get install g++
点击回车enter即可

sudo apt-get install gcc
sudo apt-get install make


点击回车enter即可
成功安装
2.2 卸载原有驱动
sudo apt-get remove --purge nvidia*
- 1.使用vim修改配置文件
sudo vim /etc/modprobe.d/blacklist.conf
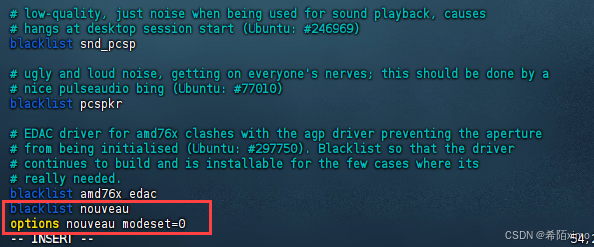
- 2.按i键进入编辑模式,在文件尾增加两行:
blacklist nouveau
options nouveau modeset=0
-
3.按esc键退出编辑模式,输入:wq保存并退出
-
4.更新文件
sudo update-initramfs -u
这里等待时间较久

- 5.重启电脑:
sudo reboot
这里需要等一会才能连上
2.3 安装驱动
- 1.授予执行权限
sudo chmod 777 NVIDIA-Linux-x86_64-550.100.run
- 2.执行安装命令
sudo ./NVIDIA-Linux-x86_64-550.100.run
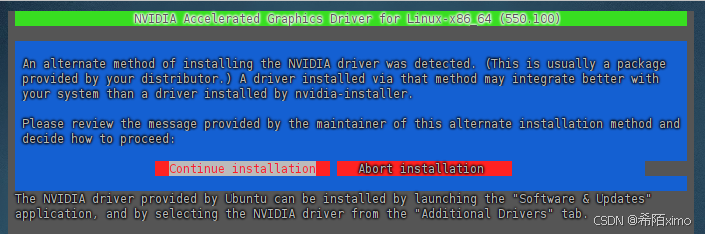
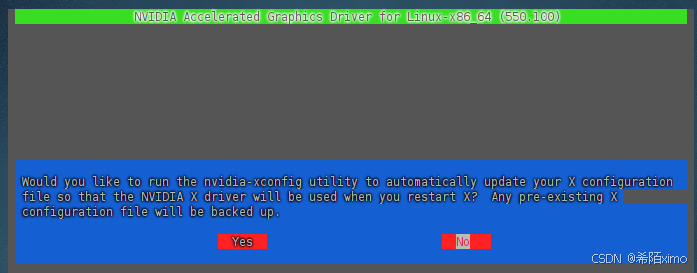
这里一直按回车就行,默认选择


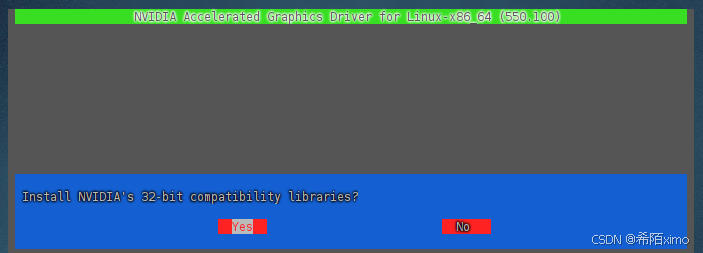
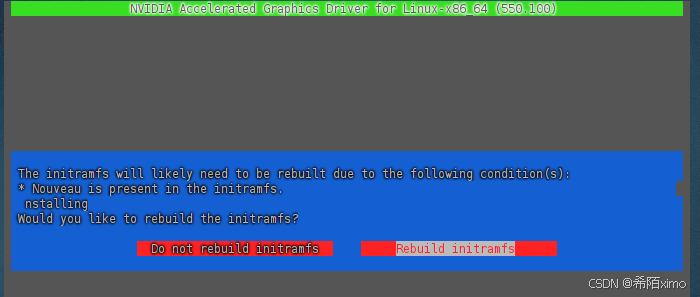
一直按回车enter键,直到安装成功
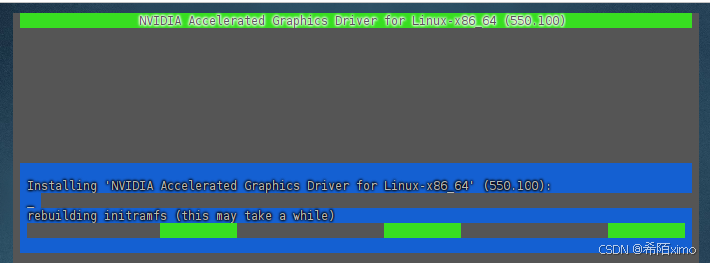
- 3.检测显卡驱动是否安装成功
nvidia-smi
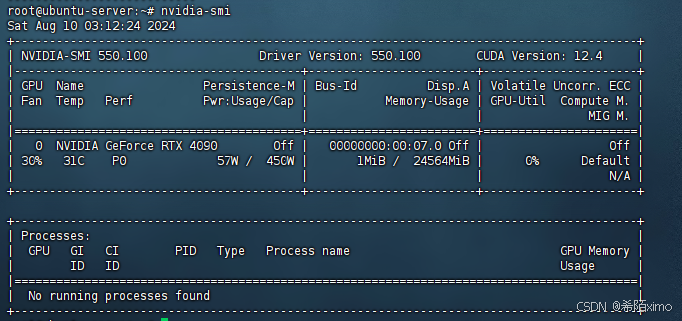
2.4 安装CUDA
wget https://developer.download.nvidia.com/compute/cuda/12.4.0/local_installers/cuda_12.4.0_550.54.14_linux.run
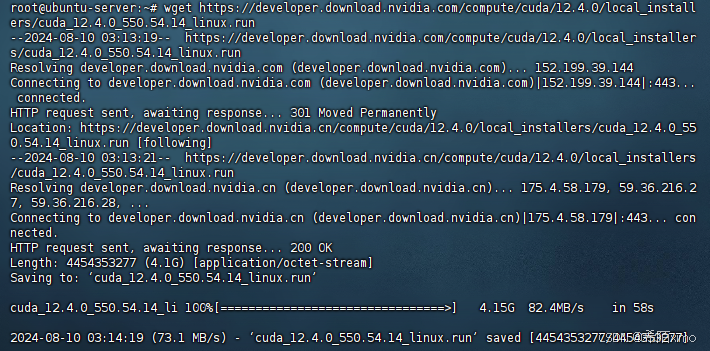
执行安装命令
sudo sh ./cuda_12.4.0_550.54.14_linux.run
- 1.输出accept开始安装

- 2.然后注意这里要按enter取消勾选第一个选项,因为之前已经安装了驱动
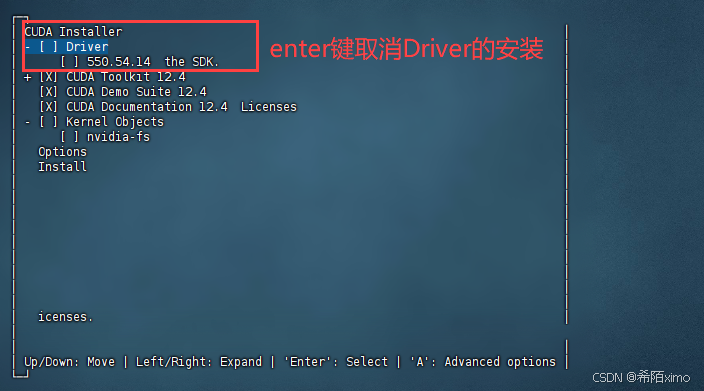
- 3.接着选择Install开始安装
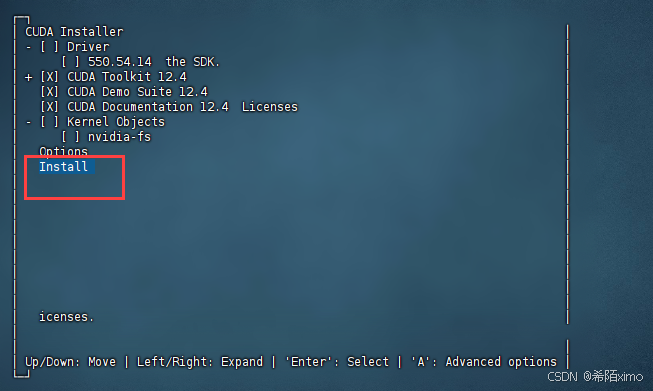
- 4.安装完成
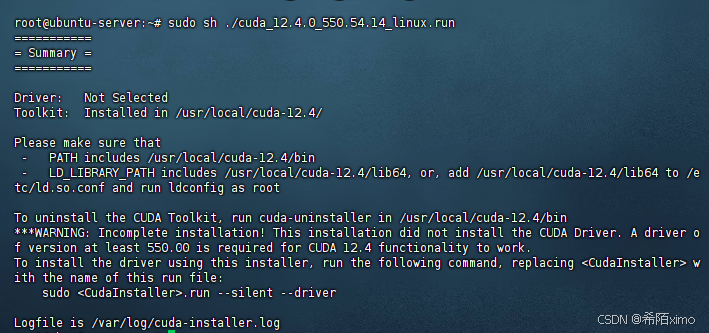
2.5 环境变量配置
- 1.以vim方式打开配置文件
sudo vim ~/.bashrc
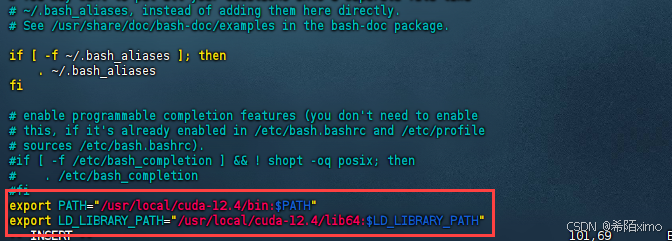
- 2.按i键进入编辑模式,在文件尾增加下面内容:
export PATH="/usr/local/cuda-12.4/bin:$PATH"
export LD_LIBRARY_PATH="/usr/local/cuda-12.4/lib64:$LD_LIBRARY_PATH"
-
按esc键退出编辑模式,输入:wq保存并退出
-
3.更新环境变量
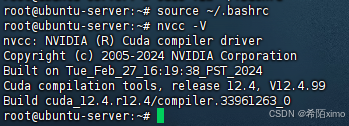
source ~/.bashrc
- 4.检测CUDA是否安装成功
nvcc -V
二、安装miniconda环境
1. 下载miniconda3
wget https://mirrors.cqupt.edu.cn/anaconda/miniconda/Miniconda3-py310_23.10.0-1-Linux-x86_64.sh
2. 安装miniconda3
bash Miniconda3-py310_23.10.0-1-Linux-x86_64.sh -u
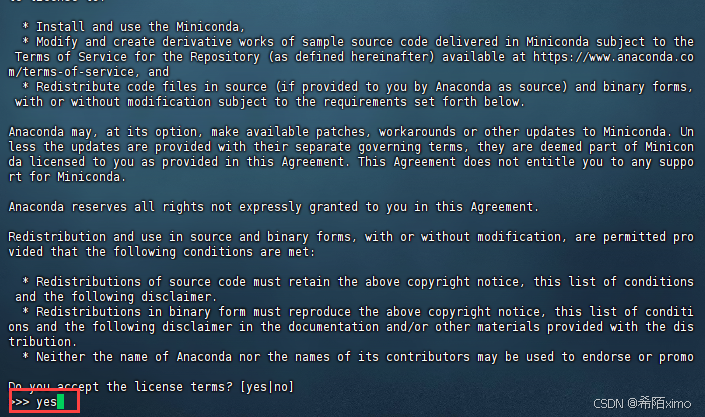
直接一直enter键,到输入路径和yes
这边建议路径为:miniconda3
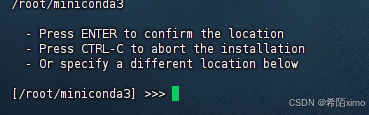
直接回车enter即可,再次输入yes
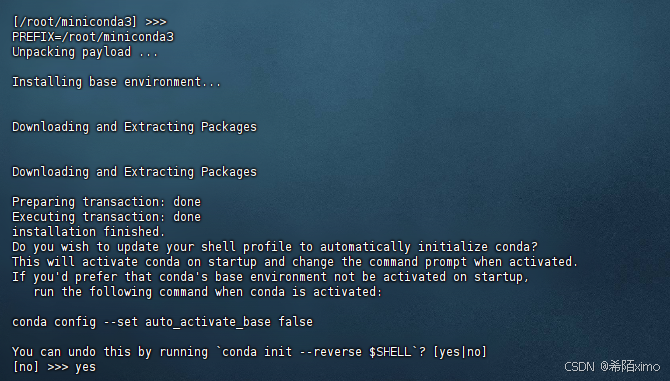
成功安装
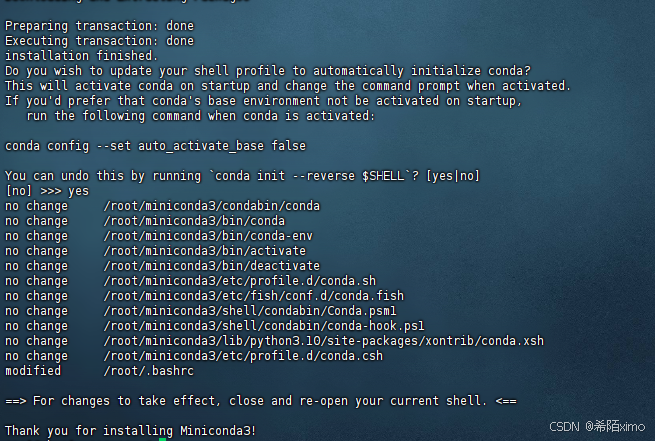
3. 切换到bin文件夹
cd miniconda3/bin/
4. 输入pwd获取路径
pwd
复制这里的路径
5. 打开用户环境编辑页面
vim ~/.bashrc
- 点击键盘I键进入编辑模式,在最下方输入以下代码
export PATH="/root/miniconda3/bin:$PATH"
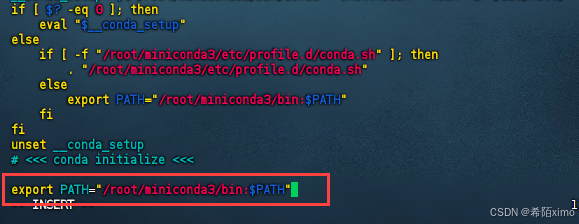
按esc键退出编辑模式,输入:wq保存并退出
6. 重新加载用户环境变量
source ~/.bashrc

7. 初始化conda
conda init bash
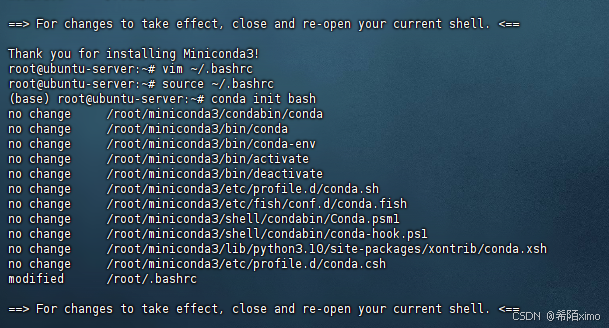
8.验证是否安装成功
conda -V
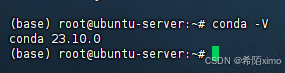
9.conda配置
-
1.配置清华镜像源
代码如下:
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/

- 2.设置搜索时显示通道地址
conda config --set show_channel_urls yes

- 3.配置pip 镜像源
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple

三、安装Qwen2-Audio
1.克隆仓库
1.1 github克隆
git clone https://github.com/QwenLM/Qwen2-Audio.git
1.2 国内github镜像克隆
git clone https://mirror.ghproxy.com/https://github.com/QwenLM/Qwen2-Audio.git
1.3. 进入目录
cd Qwen2-Audio/
2.创建虚拟环境
conda create -n qwen2 python=3.10
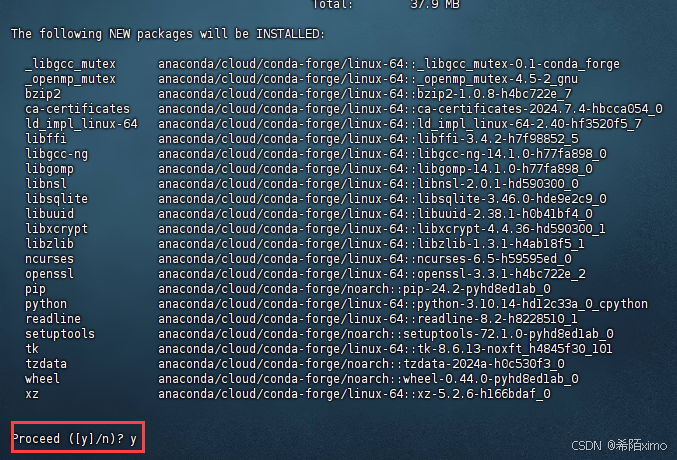
- 输入y回车即可
2.1 进入虚拟环境
conda activate qwen2

3. 安装依赖
3.1设置清华源、更新pip
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simplepython -m pip install --upgrade pip
3.2安装torch 12.4cuda版本
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124
3.3安装依赖文件
cd demo
pip install -r requirements_web_demo.txt
3.4安装webui界面及其他未安装依赖
pip install librosa
pip install --upgrade "accelerate>=0.21.0"
pip install django
pip install git+https://mirror.ghproxy.com/https://github.com/huggingface/transformers
3.5安装魔搭库准备下载模型文件:
pip install modelscope
3.6下载相关模型
cd ..
modelscope download --model qwen/qwen2-audio-7b-instruct --local_dir './Qwen/Qwen2-Audio-7B-Instruct'
3.7执行代码,启动webui界面
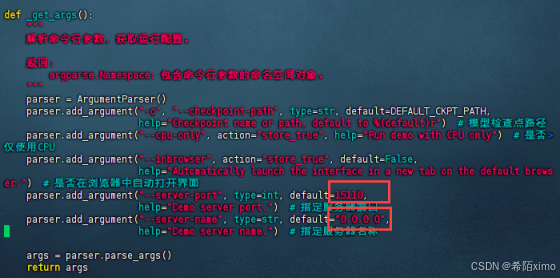
- 改端口
vim demo/web_demo_audio.py
按i进行编辑,完成后再按esc,冒号,wq退出
- 成功进入
3.8加入声音驱动,实现真正的语音聊天
cd demo
- 创建一个新的webui界面的文件
touch test_audio.py
vim test_audio.py
输入以下内容
import gradio as gr
import modelscope_studio as mgr
import librosa
from transformers import AutoProcessor, Qwen2AudioForConditionalGeneration
from argparse import ArgumentParser
import requests
import os
from django.http import HttpResponse# 默认的模型检查点路径
DEFAULT_CKPT_PATH = 'Qwen/Qwen2-Audio-7B-Instruct'def text_to_speech(text2):data = {"text": text2,"text_language": "zh",}# 注意 URL 中的单引号应该是 URL 的一部分,需要正确转义response = requests.post('http://服务器IP:端口', json=data)if response.status_code == 200:audio_file_path = "/root/project/Qwen2-Audio/demo/output.mp3"with open(audio_file_path, "wb") as f:f.write(response.content)return audio_file_pathelse:print(f"错误:请求失败,状态码为 {response.status_code}")return Nonedef _get_args():"""解析命令行参数,获取运行配置。返回:argparse.Namespace: 包含命令行参数的命名空间对象。"""parser = ArgumentParser()parser.add_argument("-c", "--checkpoint-path", type=str, default=DEFAULT_CKPT_PATH,help="Checkpoint name or path, default to %(default)r") # 模型检查点路径parser.add_argument("--cpu-only", action="store_true", help="Run demo with CPU only") # 是否仅使用CPUparser.add_argument("--inbrowser", action="store_true", default=False,help="Automatically launch the interface in a new tab on the default browser.") # 是否在浏览器中自动打开界面parser.add_argument("--server-port", type=int, default=15110,help="Demo server port.") # 指定服务器端口parser.add_argument("--server-name", type=str, default="0.0.0.0",help="Demo server name.") # 指定服务器名称args = parser.parse_args()return argsdef add_text(chatbot, task_history, input):"""将用户输入的文本内容添加到聊天记录中,并更新聊天机器人界面。参数:chatbot (gr.components.Chatbot): 聊天机器人组件。task_history (list): 任务历史记录。input (gr.inputs): 用户输入内容。返回:tuple: 更新后的聊天机器人界面和任务历史记录,以及重置后的用户输入框。"""text_content = input.text # 获取文本输入内容content = []if len(input.files) > 0: # 如果用户上传了音频文件for i in input.files:content.append({'type': 'audio', 'audio_url': i.path}) # 将音频文件添加到内容列表中if text_content: # 如果用户输入了文本content.append({'type': 'text', 'text': text_content}) # 将文本内容添加到内容列表中task_history.append({"role": "user", "content": content}) # 更新任务历史记录# 更新聊天机器人界面,添加用户输入chatbot.append([{"text": input.text,"files": input.files,}, None])return chatbot, task_history, None
'''
def add_file(chatbot, task_history, audio_file_path):"""将音频文件添加到聊天记录中。参数:chatbot (gr.components.Chatbot): 聊天机器人组件。task_history (list): 任务历史记录。audio_file_path (str): 音频文件的路径。返回:tuple: 更新后的聊天机器人界面和任务历史记录。"""# 确保任务历史记录中的音频条目是正确的格式task_history.append({"role": "user", "content": [{"type": "audio", "audio_url": audio_file_path}]})# 更新聊天记录,直接使用 audio_file_path 而不是 gr.Audio 组件chatbot.append((None, {"type": "audio", "audio_url": audio_file_path}))return chatbot, task_history
'''
import osdef add_file(chatbot, task_history, audio_path):if not os.path.isfile(audio_path):print(f"Error: The file {audio_path} does not exist.")return chatbot, task_history# 将音频文件信息添加到任务历史task_history.append({"role": "user","content": [{"type": "audio", "audio_url": audio_path}]})# 假设 chatbot 组件可以接受字典格式的输入chatbot_state = [{"text": f"[Audio file: {os.path.basename(audio_path)}]","files": [audio_path] # 直接使用文件路径而不是 gr.File}, None]chatbot.append(chatbot_state) # 更新 chatbot 状态return chatbot, task_historydef reset_user_input():"""重置用户输入字段。返回:gr.update: 将文本框的值重置为空。"""return gr.Textbox.update(value='')def reset_state(task_history):"""重置聊天记录和任务历史。参数:task_history (list): 当前的任务历史记录。返回:tuple: 清空的聊天记录和任务历史。"""return [], []def regenerate(chatbot, task_history):"""重新生成最后的机器人响应。参数:chatbot (gr.components.Chatbot): 聊天机器人组件。task_history (list): 任务历史记录。返回:tuple: 更新后的聊天机器人界面和任务历史记录。"""# 如果最后一条消息是助手生成的,则移除它if task_history and task_history[-1]['role'] == 'assistant':task_history.pop()chatbot.pop()# 如果任务历史记录不为空,重新生成响应if task_history:chatbot, task_history = predict(chatbot, task_history)return chatbot, task_historydef predict(chatbot, task_history):"""根据当前任务历史记录生成模型响应,并将响应转换为音频文件添加到聊天记录中。参数:chatbot (gr.components.Chatbot): 聊天机器人组件。task_history (list): 任务历史记录。返回:tuple: 更新后的聊天机器人界面和任务历史记录。"""print(f"{task_history=}")print(f"{chatbot=}")# 使用处理器将任务历史记录格式化为模型输入text = processor.apply_chat_template(task_history, add_generation_prompt=True, tokenize=False)audios = []# 遍历任务历史,查找音频内容并加载for message in task_history:if isinstance(message["content"], list):for ele in message["content"]:if ele["type"] == "audio":audios.append(librosa.load(ele['audio_url'], sr=processor.feature_extractor.sampling_rate)[0])if len(audios) == 0: # 如果没有音频,则设置为 Noneaudios = Noneprint(f"{text=}")print(f"{audios=}")# 使用处理器生成模型输入inputs = processor(text=text, audios=audios, return_tensors="pt", padding=True)if not _get_args().cpu_only: # 如果支持 GPU,则将输入数据移动到 CUDA 设备inputs["input_ids"] = inputs.input_ids.to("cuda")# 生成响应generate_ids = model.generate(**inputs, max_length=256)generate_ids = generate_ids[:, inputs.input_ids.size(1):]# 解码生成的文本响应# 假设其他参数已经正确设置response = processor.batch_decode(generate_ids, skip_special_tokens=True)[0]task_history.append({'role': 'assistant', 'content': response})chatbot.append((None, response)) # 添加文本响应# 将文本响应转换为语音audio_file_path = text_to_speech(response)if audio_file_path:chatbot, task_history = add_file(chatbot, task_history, audio_file_path)return chatbot, task_historydef _launch_demo(args):"""启动Gradio的Web用户界面,展示Qwen2-Audio-Instruct模型的聊天功能。参数:args (argparse.Namespace): 从命令行解析的参数。"""with gr.Blocks() as demo:# 添加页面标题和描述gr.Markdown("""<p align="center"><img src="https://qianwen-res.oss-cn-beijing.aliyuncs.com/assets/blog/qwenaudio/qwen2audio_logo.png" style="height: 80px"/><p>""")gr.Markdown("""<center><font size=8>Qwen2-Audio-Instruct Bot</center>""")gr.Markdown("""\<center><font size=3>This WebUI is based on Qwen2-Audio-Instruct, developed by Alibaba Cloud. \(本WebUI基于Qwen2-Audio-Instruct打造,实现聊天机器人功能。)</center>""")gr.Markdown("""\<center><font size=4>Qwen2-Audio <a href="https://modelscope.cn/models/qwen/Qwen2-Audio-7B">🤖 </a> | <a href="https://huggingface.co/Qwen/Qwen2-Audio-7B">🤗</a>  | Qwen2-Audio-Instruct <a href="https://modelscope.cn/models/qwen/Qwen2-Audio-7B-Instruct">🤖 </a> | <a href="https://huggingface.co/Qwen/Qwen2-Audio-7B-Instruct">🤗</a>  |  <a href="https://github.com/QwenLM/Qwen2-Audio">Github</a></center>""")# 创建聊天机器人组件chatbot = mgr.Chatbot(label='Qwen2-Audio-7B-Instruct', elem_classes="control-height", height=750)# 创建用户输入组件,支持文本、麦克风和文件上传user_input = mgr.MultimodalInput(interactive=True,sources=['microphone', 'upload'],submit_button_props=dict(value="🚀 Submit (发送)"),upload_button_props=dict(value="📁 Upload (上传文件)", show_progress=True),)task_history = gr.State([]) # 初始化任务历史状态with gr.Row(): # 创建清除历史和重试按钮empty_bin = gr.Button("🧹 Clear History (清除历史)")regen_btn = gr.Button("🤔️ Regenerate (重试)")# 当用户提交输入时,调用add_text函数,然后调用predict函数生成响应user_input.submit(fn=add_text,inputs=[chatbot, task_history, user_input],outputs=[chatbot, task_history, user_input]).then(predict, [chatbot, task_history], [chatbot, task_history], show_progress=True)# 清除历史按钮的点击事件处理,重置聊天记录和任务历史empty_bin.click(reset_state, outputs=[chatbot, task_history], show_progress=True)# 重试按钮的点击事件处理,重新生成最后的响应regen_btn.click(regenerate, [chatbot, task_history], [chatbot, task_history], show_progress=True)# 启动Gradio界面demo.queue().launch(share=False, # 不共享URLinbrowser=args.inbrowser, # 是否自动在浏览器中打开server_port=args.server_port, # 指定服务器端口server_name=args.server_name, # 指定服务器名称ssl_certfile="/root/project/cert.pem", ssl_keyfile="/root/project/key.pem", ssl_verify=False)if __name__ == "__main__":args = _get_args() # 获取命令行参数if args.cpu_only:device_map = "cpu" # 如果指定了仅使用CPU,设置设备映射为CPUelse:device_map = "auto" # 否则自动选择设备# 加载模型model = Qwen2AudioForConditionalGeneration.from_pretrained(args.checkpoint_path,torch_dtype="auto", # 自动选择数据类型device_map=device_map, # 设置设备映射resume_download=True, # 断点续传).eval()model.generation_config.max_new_tokens = 2048 # 设置最大生成token数,用于长对话print("generation_config", model.generation_config)processor = AutoProcessor.from_pretrained(args.checkpoint_path, resume_download=True) # 加载处理器_launch_demo(args) # 启动演示界面- 运行上面代码之前先到4.1配置ssl
四、成功实现语音交互

4.1 找不到录音机问题
- 创建ssl
openssl req -x509 -newkey rsa:4096 -keyout key.pem -out cert.pem -sha256 -days 365 -nodes
一直按enter键默认选择即可
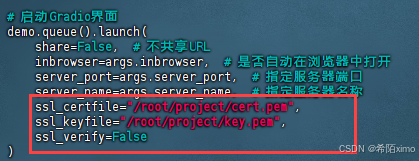
- 修改launch
vim demo/web_demo_audio.py
加入ssl参数,注意替换路径
demo.queue().launch(share=False, # 不共享URLinbrowser=args.inbrowser, # 是否自动在浏览器中打开server_port=args.server_port, # 指定服务器端口server_name=args.server_name, # 指定服务器名称ssl_certfile="/root/project/cert.pem", ssl_keyfile="/root/project/key.pem", ssl_verify=False)
- 注意用https访问
https://服务器ip:端口
相关文章:
阿里声音项目Qwen2-Audio的部署安装,在服务器Ubuntu22.04系统——点动科技
阿里声音项目Qwen2-Audio的部署安装,在服务器Ubuntu22.04系统——点动科技 一、ubuntu22.04基本环境配置1.1 更换清华Ubuntu镜像源1.2 更新包列表:2. 安装英伟达显卡驱动2.1 使用wget在命令行下载驱动包2.2 更新软件列表和安装必要软件、依赖2.2 卸载原有…...
)
RAG(检索增强生成)
RAG (Retrieval-Augmented Generation) 是一种自然语言处理的模型架构,主要用于生成性任务,如文本生成、对话系统等。RAG 将检索和生成两个任务结合起来,以提高生成结果的质量和相关性。 RAG 模型的主要思想是通过检索阶段获取相关的上下文信…...

AcWing848有向图的拓扑排序
拓扑排序的流程: 插入(a,b),表示a->b的关系,调用add(a,b),每次吧b的入度1,d[b]; 然后调用topsort,返回1表示存在拓扑序列,返回0表示不存在拓扑序列。判断是否存在拓扑…...

猫咪掉毛很严重,家中猫毛该如何清理?快来看资深铲屎官经验分享
想必铲屎官们都见识过换毛季的威力。拿我家举例,养了一只长毛,一只短毛,打扫完不用半天,家里就能重新出现不少猫毛。严重的时候,每天都要扫地机器人扫三次,拖一次。 最近两天外出,回来给它们梳…...

Midjourney进阶-反推与优化提示词(案例实操)
Midjourney中提示词是关键,掌握提示词的技巧直接决定了生成作品的质量。 当你看到一张不错的图片,想要让Midjourney生成类似的图片,却不知道如何描述画面撰写提示词,这时候Midjourney的/describe指令,正是帮助你推…...

大公报发表欧科云链署名文章:发行港元稳定币,建Web3.0新生态
欧科云链研究院资深研究员蒋照生近日与香港科技大学副校长兼香港Web3.0协会首席科学顾问汪扬、零壹智库创始人兼CEO柏亮,在大公报发布联合署名文章 ——《Web3.0洞察 / 发行港元稳定币,建Web3.0新生态》,引发市场广泛讨论。 文章就香港稳定币…...
)
Mybatis的一些常用知识点(面试)
什么是MyBatis? Mybatis 是⼀个半 ORM(对象关系映射)框架,它内部封装了 JDBC。 它让开发者在开发时只需要关注 SQL 语句本身,不需要花费精⼒去处理加载驱动、创建连接等繁杂的过程 缺点: SQL语句的编写⼯作量较⼤ SQ…...

stm32—ADC
1. 什么是ADC 生活中我们经常会用到ADC这种器件,比如说,当我们在使用手机进行语音通信时,ADC器件会将我们的声信号转换为电信号 (模拟信号 ---> 数字信号) 模拟信号: 模拟信号是指用连续变化的物理量表示的信息,其信…...

【微信小程序】吐槽生态之云开发服务端能力不足
回想起来,笔者开发小程序的经历也有4年多了,以前因为技术积累接触不到比较深层次的东西,也不理解软件生态这个概念,现在开发小程序的过程中,越来越觉得很多生态微信的进步空间很大。 问题引入 比如说,在迭…...

AnimateDiff论文解读
GitHub - Kosinkadink/ComfyUI-AnimateDiff-Evolved: Improved AnimateDiff for ComfyUI and Advanced Sampling Support 视频编码 定义: 首先,将视频数据转换为一系列的潜变量代码(latent codes)。这是通过一个预训练的自动编码器(auto-encoder)来完成的。操作: …...

C/C++控制台贪吃蛇游戏的实现
🚀欢迎互三👉:程序猿方梓燚 💎💎 🚀关注博主,后期持续更新系列文章 🚀如果有错误感谢请大家批评指出,及时修改 🚀感谢大家点赞👍收藏⭐评论✍ 一、…...

Linux 升级安装 Weblogic-补丁!
版本: RedHat 6.5 Weblogic 10.3.6.0 ----------------------------------------------------------------- 1.查看当前 weblogic 补丁版本 cd /weblogic/utils/bsu/ ./bsu.sh -prod_dir/weblogic/wlserver_10.3/ -statusapplied -verbose -view 2.卸载旧补丁…...

苍鹰来啦!快来看呀!NGO-BiTCN-BiGRU-Attention北方苍鹰算法优化多重双向深度学习回归预测
苍鹰来啦!快来看呀!NGO-BiTCN-BiGRU-Attention北方苍鹰算法优化多重双向深度学习回归预测 目录 苍鹰来啦!快来看呀!NGO-BiTCN-BiGRU-Attention北方苍鹰算法优化多重双向深度学习回归预测效果一览基本介绍程序设计参考资料 效果一览 基本介绍 1.Matlab实…...

关于WebSocket必知必会的知识点
什么是WebSocket WebSocket是一种网络传输协议,可以在单个TCP连接上进行全双工通信,位于OSI模型的应用层。 WebSocket使得客户端和服务器之间的数据交换变得更加简单,服务器可以主动向客户端发送消息。在WebSocket API中,浏览器和…...

Go 1.19.4 Sort排序进阶-Day 12
1. 结构体(切片)排序 结构体返回的是切片。 之前学习了sort.Ints()和sort.Strings(),使用这两个sort库下面的方法,可以对int和strings进行排序。 那如果我要对自定义类型进行排序,怎么办,sort库没提供&…...
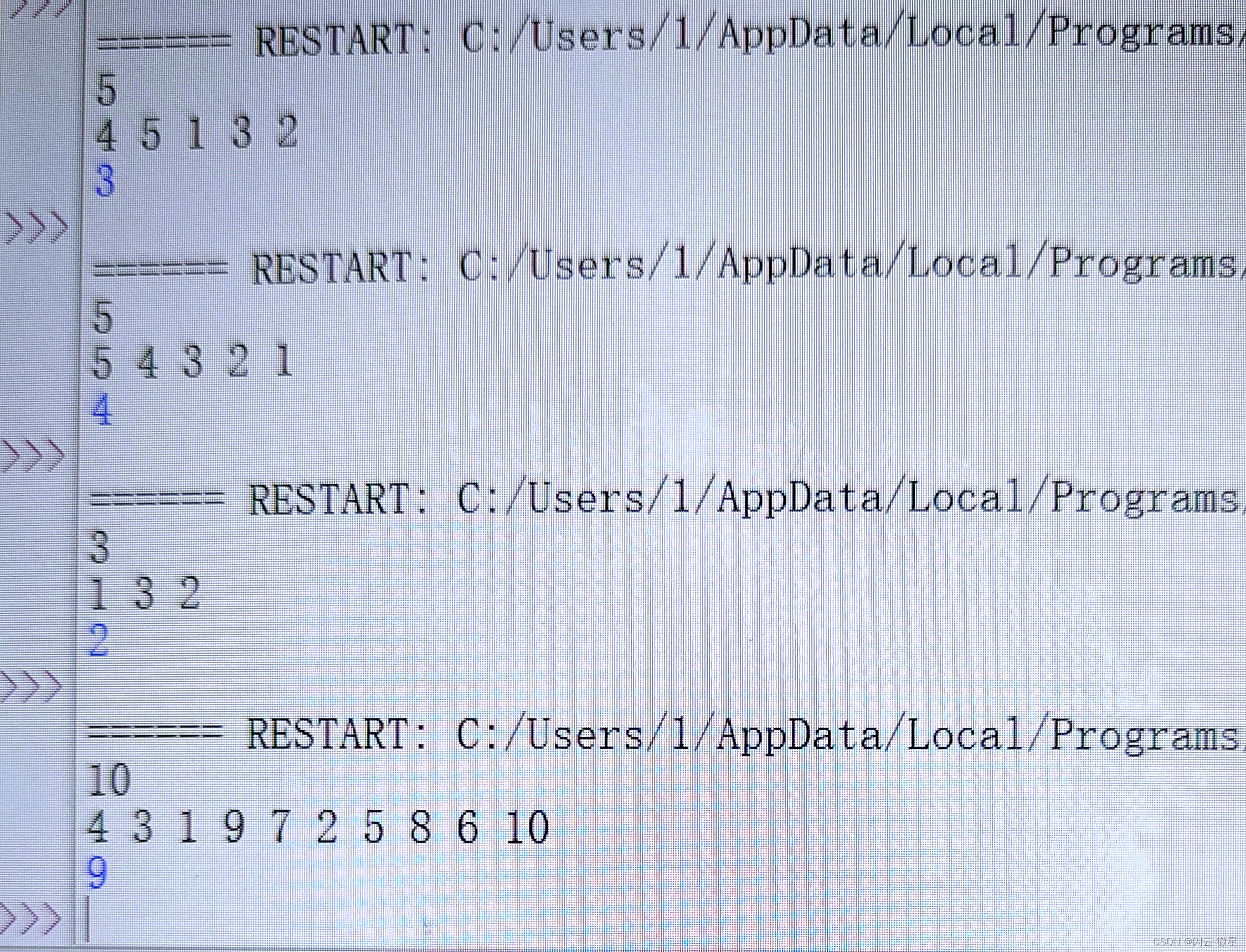
python-求距离(赛氪OJ)
[题目描述] 给你一个 1−>n 的排列,现在有一次机会可以交换两个数的位置,求交换后最小值和最大值之间的最大距离是多少?输入格式: 输入共两行。 第一行一个数 n 。 第二行 n 个数表示这个排列。输出格式: 输出一行一…...

《第二十一章 传感器与定位 - 传感器应用》
《第二十一章 传感器与定位 - 传感器应用》 在当今的移动应用开发中,充分利用设备的传感器能够为用户带来更加智能和便捷的体验。本章将重点探讨加速度传感器、方向传感器和光线传感器的应用。 一、传感器应用的重要性 随着智能手机和移动设备的普及,传感…...

Windows系统命令
Windows系统命令 Windows 系统中的命令行工具是指令式编程语言,可以用来执行各种任务、管理文件和目录、监控系统状态等。下面是一个 Windows 命令应用实例: 1. 文件操作 cd:用于改变当前目录。例如,cd Documents 将当前目录更…...

C语言函数递归
前言与概述 本文章将通过多个代码并赋予图示,详细讲解C语言函数递归的定义和函数递归的运算过程。 函数递归定义 程序调用自身的编程技巧称为递归。递归作为一种算法在程序设计语言中广泛应用。一个过程或函数在其定义或说明中有直接或间接调用自身的一种方法。它…...

【python数据分析11】——Pandas统计分析(分组聚合进行组内计算)
分组聚合进行组内计算 前言1、groupby方法拆分数据2、agg方法聚合数据3、apply方法聚合数据4、transform方法聚合数据5 小案例5.1 按照时间对菜品订单详情表进行拆分5.2 使用agg方法计算5.3 使用apply方法统计单日菜品销售数目 前言 依据某个或者几个字段对数据集进行分组&…...

ComfyUI Video Combine节点3个核心技巧:解决视频合并常见问题
ComfyUI Video Combine节点3个核心技巧:解决视频合并常见问题 【免费下载链接】ComfyUI-VideoHelperSuite Nodes related to video workflows 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-VideoHelperSuite 在AI动画创作中,ComfyUI的Vi…...

【技术解析】基于主成分分析与神经网络的航空安全风险建模:从QAR数据预处理到实时预警仿真
1. 航空安全风险建模的技术背景 每次坐飞机时,你可能都好奇过:机长是如何确保飞行安全的?其实背后有一整套数据驱动的安全体系在支撑。QAR(快速存取记录器)就像飞机的"黑匣子",记录了上百项飞行参…...

Go语言实现跨平台系统更新检查器:自动化运维与安全监控实践
1. 项目概述:一个被低估的系统运维“哨兵”在服务器和桌面系统的日常运维中,有一个场景大家一定不陌生:某天,你管理的服务器突然因为一个已知漏洞被攻击,事后排查发现,相关的安全补丁其实在几周前就已经发布…...

Shell脚本加固实战:用shellguard提升脚本健壮性与安全性
1. 项目概述:一个为Shell脚本穿上“防弹衣”的守护者 在运维开发、自动化部署乃至日常的系统管理工作中,Shell脚本是我们最忠实、最高效的伙伴。从简单的日志清理到复杂的CI/CD流水线,Shell脚本无处不在。然而,脚本的安全性、健壮…...
)
别再拷贝exe到NXBIN了!用批处理文件搞定NX二次开发外部exe的环境变量(附VS2015/NX12配置)
告别手动拷贝:用批处理智能管理NX二次开发环境变量 每次修改完NX二次开发的外部exe程序,都要手动拷贝到NXBIN目录?这种重复劳动不仅低效,还容易导致版本混乱。其实只需一个简单的批处理脚本,就能彻底解决环境变量配置问…...

嵌入式事件驱动框架Curtroller:模块化设计提升开发效率
1. 项目概述与核心价值最近在嵌入式开发社区里,一个名为“Curtroller”的项目引起了我的注意。这个项目由开发者KenWuqianghao在GitHub上开源,名字本身就是一个巧妙的组合——“Curt”(可能是“Current”电流的缩写或“Control”控制的变体&a…...

Deep Lake:AI数据湖与向量数据库一体化管理实践
1. 项目概述:当数据湖遇上深度学习如果你正在构建一个AI应用,无论是图像识别、自然语言处理还是多模态模型,数据管理绝对是你绕不开的“硬骨头”。数据分散在各个文件夹、云存储、数据库里,格式五花八门,加载速度慢&am…...

Linux内核升级C11标准:从C89到现代C语言的演进与实战解析
1. 项目概述:一次内核语言的“心脏移植”最近Linux内核社区的一个决定,在开发者圈子里激起了不小的波澜:计划将内核的C语言标准从使用了超过十年的C89/C90,逐步迁移到C11。这听起来可能像是一个枯燥的技术规范更新,但对…...

基于视觉语言模型的智能体框架:让AI看懂界面并自动操作
1. 项目概述:当AI学会“看”与“想”最近在探索AI与视觉结合的领域时,我深度体验了landing-ai团队开源的vision-agent项目。这不仅仅是一个工具库,它更像是一个为大型语言模型(LLM)装上了“眼睛”和“手”的智能体框架…...

BeagleBone Black设备树覆盖层实战:从原理到自定义SPI/UART配置
1. 项目概述:为什么BeagleBone Black开发者必须掌握设备树?如果你正在使用BeagleBone Black(BBB)进行嵌入式开发,并且已经不止一次地困惑于为什么某个外设(比如UART、SPI或者某个GPIO)无法按预期…...