使用 Dify 和 AI 大模型理解视频内容:Qwen 2 VL 72B
接下来的几篇相关的文章,聊聊使用 Dify 和 AI 大模型理解视频内容。
本篇作为第一篇内容,以昨天出圈的“黑神话悟空制作人采访视频”为例,先来聊聊经常被国外厂商拿来对比的国产模型:千问系列,以及它的内测版。
写在前面
最近一两周有好几位朋友线下聚的时候,聊起了端侧多模态模型,以及用端侧多模态模型做 RPA 和一些内容识别相关的业务场景。在展开聊这些内容前,我觉得或许可以先从“为个人偷懒”角度,来聊聊模型的使用:用模型替我刷视频,找到我忽略的细节。

昨天晚上刷知乎的时候,在问题列表中看到了一个有趣的问题“如何看待2024年8月新华社记者采访《黑神话悟空》制作人团队?”,点开问题看到了黑神话悟空制作人的新华社专题采访:“踏上取经路,比抵达灵山更重要”。
这是一个 32 分钟 27 秒的中长视频,借助当前多模态大模型直接进行解析,恐怕是不行的:或受限于显存资源限制、或受限于模型前端程序能够抽取和解析的视频长度。
但是,只要结合一丢丢工程化,写一点篇幅短的小程序,进行一些简单的操作,就能够完成对这类视频的处理啦。
比如,提取所有的视频关键帧。
再比如,调整合适的 Prompt 提示词,让 Qwen2 VL 72B 模型来解析画面内容。
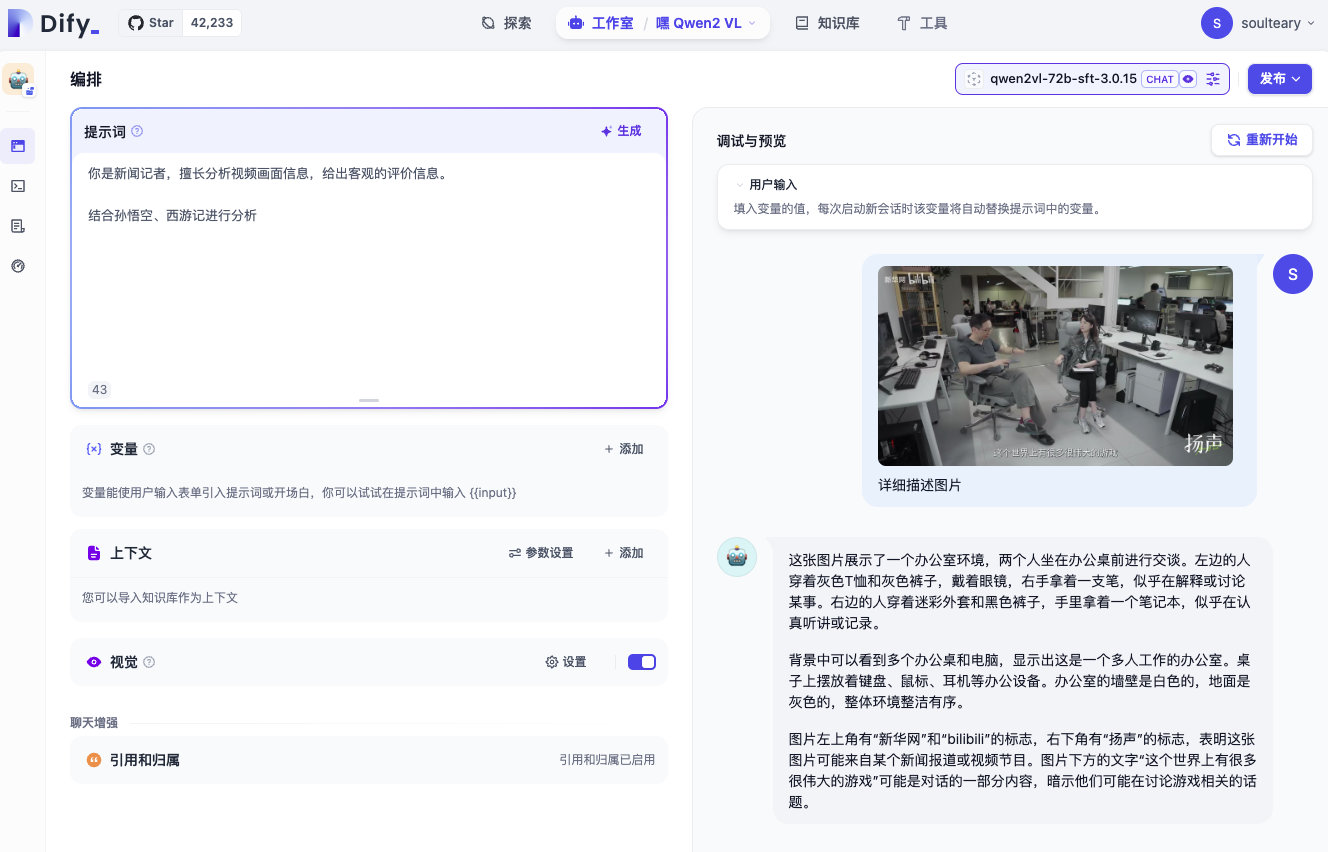
以及,用千问大语言模型,再来一些原汤化原食,结合字幕时间轴,来完成对视频的详细的逐帧式介绍,或者任意视频的“对话”。其实,也可以使用千问音频模型,我比较懒(想玩游戏啦),下次再整。

本文使用的示例代码,我已经开源在了 soulteary/dify-with-qwen-vl,有需要可以自取,欢迎一键三连。
好了,让我们开始实战。
关于通义 VL 多模态大模型
考虑到可能有读者还不了解通义 VL 模型,这里做一个简单的介绍,以及为什么本文使用的模型是通义 VL 2(内测版)。
2023 年 8 月 22 日,通义团队开源了 Qwen VL 模型,这个基于 Qwen 7B 的多模态模型,2K Token 用一张 24G 卡就能跑起来(8K Token 需要 28G+ 显存)。月底的时候,官方推出了量化版本 Qwen VL Chat Int4,在效果只降低了 3% 的情况下,2K Token 只需要 11G+ 的显存,8K Token 也只需要 17G 显存,降低了不少入门门槛。
这款模型的商业版本 Qwen VL Plus 和 Qwen VL Max 版本随后也“上架”了阿里云,并可以使用 API 进行访问。
当我们在 Dify 中配置了阿里云的 API Key 之后,就能够进行自由的调用啦。
至于这篇文章中使用的 Qwen2 VL,来自我一边刷上文中提到的视频,一遍刷魔搭社区的时候,出现在我信息流顶部的模型消息。
关于视频帧抽取方案
之前的文章《使用 Redis 构建轻量的向量数据库应用:图片搜索引擎(一)》和《开源软件 FFmpeg 生成模型使用图片数据集》中,提到过使用 ffmpeg 来从视频中抽取关键帧,以供大模型解析使用。
但是,简单粗暴的采样方案,其实并不是最优解,会遗失大量有效信息。所以,选择一个合适的方案就非常关键。我相信很多同学和我一样,并非 CV 或多媒体相关从业背景,那么,如何快速的获得相对靠谱的技术方案选型呢?
之前的文章里,我分享过太多的,使用先进模型(内化知识)获取知识的技巧。最近半年,知乎原本内测的模型(知乎直答)也进行了优化(强化了检索能力),能够结合知乎站内大神们的经验,来提供参考的技术方案选型。

是不是看起来还挺全面的,在获取到类似上面的经验之后,接下来的任务就非常简单了,对上面的方案进行正确性判断和进一步理解:你可以继续使用知乎直答,或者将已经得到的知乎站内的大神经验,结合更先进的模型一起用,进行扩展或细节追问。
本文中,我的选择是“基于镜头转换的方法的视频关键帧抽取”,方案名字很长,但其实简单写一些代码,就能够实现这部分功能了(带注释 70 行左右):
import cv2
import numpy as np
from sklearn.cluster import KMeans
import osdef preprocess_video(video_path):"""预处理视频,提取所有帧"""cap = cv2.VideoCapture(video_path)frames = []while cap.isOpened():ret, frame = cap.read()if not ret:breakframes.append(frame) # 保存原始彩色帧cap.release()return framesdef detect_shot_boundaries(frames, threshold=30):"""使用帧差法检测镜头边界"""shot_boundaries = []for i in range(1, len(frames)):prev_frame = cv2.cvtColor(frames[i-1], cv2.COLOR_BGR2GRAY)curr_frame = cv2.cvtColor(frames[i], cv2.COLOR_BGR2GRAY)diff = np.mean(np.abs(curr_frame.astype(int) - prev_frame.astype(int)))if diff > threshold:shot_boundaries.append(i)return shot_boundariesdef extract_keyframes(frames, shot_boundaries):"""从每个镜头中提取关键帧"""keyframes = []for i in range(len(shot_boundaries)):start = shot_boundaries[i-1] if i > 0 else 0end = shot_boundaries[i]shot_frames = frames[start:end]# 使用 K-means 聚类选择关键帧frame_features = np.array([cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY).flatten() for frame in shot_frames])kmeans = KMeans(n_clusters=1, random_state=0).fit(frame_features)center_idx = np.argmin(np.sum((frame_features - kmeans.cluster_centers_[0])**2, axis=1))keyframes.append(shot_frames[center_idx])return keyframesdef save_keyframes(keyframes, output_dir):"""保存关键帧到指定目录"""if not os.path.exists(output_dir):os.makedirs(output_dir)for i, keyframe in enumerate(keyframes):output_path = os.path.join(output_dir, f'keyframe_{i:04d}.jpg')cv2.imwrite(output_path, keyframe)print(f"已保存 {len(keyframes)} 个关键帧到 {output_dir}")def main(video_path, output_dir):frames = preprocess_video(video_path)shot_boundaries = detect_shot_boundaries(frames)keyframes = extract_keyframes(frames, shot_boundaries)save_keyframes(keyframes, output_dir)if __name__ == "__main__":video_path = "video.mp4"output_dir = "keyframes_output"main(video_path, output_dir)
上面的代码还比较粗糙,接下来的实战中,我们将一点点进行改进。
准备工作
本文的准备工作很简单,如果你是我的老读者,已经有顺手就能使用的 Dify,那么只需要准备一个简单的 Python 环境,下载一个想分析的视频即可。
Dify 的安装使用
关于 Dify 的安装和使用,在之前 Dify 相关的文章中有提到过,所以就不再赘述。
考虑到开箱即用,后续或许会单独写一个小工具,来更简单的完成 Dify 的安装和组件选配。
获取要解析的视频文件
上文提到了,我们要对悟空制作人专访视频进行分析,所以,要对视频进行下载,你可以使用任何你喜欢的方式,完成视频的下载。或者,替换视频为你想分析的视频。
将视频文件命名为 video.mp4,我们稍后使用。
CONDA 环境准备
因为本文主要使用 API 的方式(毕竟内测模型嘛,权重还未开放下载)来进行模型调用,本地并不需要 CUDA 和相关的性能优化组件,对运行环境没有那么大的要求。所以这篇文章就使用更轻量的 CONDA,来完成环境准备。
如果你想进行复现,使用阿里云灵积上的 Qwen VL Plus 或 Max 版本,或者本地运行上文提到的 Qwen VL 模型 1.0 版本,然后将接口配置到 Dify 中即可。
CONDA 的安装,可以参考《用让新海诚本人惊讶的 AI 模型制作属于你的动漫视频》这篇文章来进行安装。
不同的操作系统安装过程,除了下载安装包不同之外,几乎没有差别,先完成安装包的下载:
# M1/M2/M3 macOS
wget https://repo.anaconda.com/archive/Anaconda3-2024.06-1-MacOSX-arm64.sh
# Intel macOS
wget https://repo.anaconda.com/archive/Anaconda3-2024.02-1-MacOSX-x86_64.sh# Windows
wget https://repo.anaconda.com/archive/Anaconda3-2024.06-1-Windows-x86_64.exe# Linux
wget https://repo.anaconda.com/archive/Anaconda3-2024.06-1-Linux-x86_64.sh
然后,“双击安装包”,进行安装:
# 先进行 conda 的安装
Anaconda3-2024.06-1-(你的安装文件名称).sh
完成安装后,更新配置文件 vi ~/.condarc 软件源为清华源,来加速软件包下载:
channels:- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/- defaults
show_channel_urls: true
当我们完成了 ~/.condarc 的内容修改之后,先重启 Shell,接着使用 conda info 命令就可以检查软件源是否配置成功了:
conda info active environment : base
...channel URLs : https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/osx-arm64https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/noarchhttps://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/osx-arm64https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/noarchhttps://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/osx-arm64https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/noarch
...
完成上面的操作后,我们执行下面的命令,创建一个干净的环境,能够对视频进行抽帧处理:
# 创建一个名为 video-kf 的 Python 3.10 环境
conda create -n video-kf python=3.10 -y
# 激活这个新环境
conda activate video-kf
# 创建一个工作目录
mkdir video-keyframes
# 切换工作目录
cd video-keyframes
好了,准备工作到此结束,开始折腾。
实战开始
下面我们开一步步了解视频是如何能够被模型理解和处理的,以相对最低的模型调用成本。
完成基础的视频内容解析
让我们先从最简单的方法开始,在使用上文中的 Python 抽取视频关键帧程序前,执行命令,完成必要的依赖安装:
pip install opencv-python scikit-learn
接下来,我们将上文中的代码,保存为 index.py、将准备好的使用命名为 video.mp4,然后执行下面的命令,让程序对视频进行处理。
python index.py
如果命令执行后,没有任何反馈,看起来和进程假死一样,是正常的。默认情况下,我们将对原始视频进行分析,原始视频中的画幅比较大、帧率比较高(每秒画面),程序的计算量是非常大的。
如果你没有使用性能比较强劲、内存也比较大的设备,此时程序先会逐帧剥离视频内容到内存进行缓存(50GB空间使用,空间不足将使用磁盘进行暂存置换),然后再进行大量的画面比对计算。听起来是不是就很花时间?
当然,如果你耐心比较好,手头有其他事情在做,大概刷一个长视频后,关键帧就抽取好了。因为使用的是原始视频的画面,清晰度是非常高的,非常利于模型进行画面细节分析。
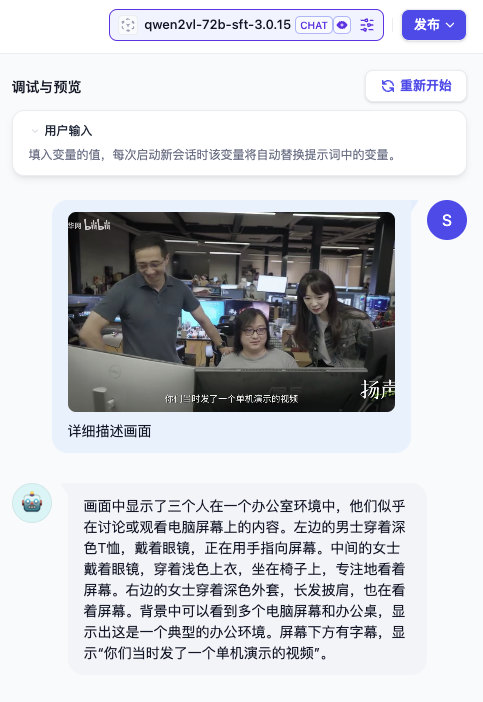
接下来,我们只需要调用 Dify 的 API,来批量的完成这些图片内容的处理,就能够得到整个视频的画面内容了。
不过,在此之前,这个效率问题得解决解决,不然遇到画幅更大的视频、或者时间更长的视频,解析时间可能比我们刷两遍视频都长,虽然也偷懒了,但是不够高效。
小技巧:适当压缩视频画幅
我们先使用一个小技巧,对视频画幅进行压缩,来同时降低模型和程序的计算量,提升处理效率。这个小技巧在《开源软件 FFmpeg 生成模型使用图片数据集》中有提到过,与此同时,如果你的设备有 GPU,我们还能够进行进一步加速,同样在文章中有提到过,就不再展开。
简单执行命令,我们可以将 video.mp4 压缩到 320 宽幅,保存为 mini.mp4。
ffmpeg -i video.mp4 -vf "scale=320:-1" mini.mp4
执行命令后,稍等片刻(我这里的笔记本是 50x 倍速处理),我们就能够得到小体积的视频文件啦:
# ffmpeg -i video.mp4 -vf "scale=320:-1" mini.mp4
ffmpeg version 7.0.2 Copyright (c) 2000-2024 the FFmpeg developersbuilt with Apple clang version 15.0.0 (clang-1500.3.9.4)configuration: --prefix=/opt/homebrew/Cellar/ffmpeg/7.0.2 --enable-shared --enable-pthreads --enable-version3 --cc=clang --host-cflags= --host-ldflags='-Wl,-ld_classic' --enable-ffplay --enable-gnutls --enable-gpl --enable-libaom --enable-libaribb24 --enable-libbluray --enable-libdav1d --enable-libharfbuzz --enable-libjxl --enable-libmp3lame --enable-libopus --enable-librav1e --enable-librist --enable-librubberband --enable-libsnappy --enable-libsrt --enable-libssh --enable-libsvtav1 --enable-libtesseract --enable-libtheora --enable-libvidstab --enable-libvmaf --enable-libvorbis --enable-libvpx --enable-libwebp --enable-libx264 --enable-libx265 --enable-libxml2 --enable-libxvid --enable-lzma --enable-libfontconfig --enable-libfreetype --enable-frei0r --enable-libass --enable-libopencore-amrnb --enable-libopencore-amrwb --enable-libopenjpeg --enable-libspeex --enable-libsoxr --enable-libzmq --enable-libzimg --disable-libjack --disable-indev=jack --enable-videotoolbox --enable-audiotoolbox --enable-neonlibavutil 59. 8.100 / 59. 8.100libavcodec 61. 3.100 / 61. 3.100libavformat 61. 1.100 / 61. 1.100libavdevice 61. 1.100 / 61. 1.100libavfilter 10. 1.100 / 10. 1.100libswscale 8. 1.100 / 8. 1.100libswresample 5. 1.100 / 5. 1.100libpostproc 58. 1.100 / 58. 1.100
Input #0, mov,mp4,m4a,3gp,3g2,mj2, from 'video.mp4':Metadata:major_brand : isomminor_version : 512compatible_brands: isomiso2avc1mp41encoder : Lavf59.30.100description : Packed by Bilibili XCoder v2.0.2Duration: 00:32:40.49, start: 0.000000, bitrate: 472 kb/sStream #0:0[0x1](und): Video: h264 (High) (avc1 / 0x31637661), yuv420p(tv, bt709, progressive), 852x480, 328 kb/s, 25 fps, 25 tbr, 16k tbn (default)Metadata:handler_name : Bento4 Video Handlervendor_id : [0][0][0][0]Stream #0:1[0x2](und): Audio: aac (LC) (mp4a / 0x6134706D), 48000 Hz, stereo, fltp, 138 kb/s (default)Metadata:handler_name : Bento4 Sound Handlervendor_id : [0][0][0][0]
Stream mapping:Stream #0:0 -> #0:0 (h264 (native) -> h264 (libx264))Stream #0:1 -> #0:1 (aac (native) -> aac (native))
...
[aac @ 0x13e658560] Qavg: 755.252
如果我们使用命令查看文件体积,能够看到体积有了明显的缩小:
du -hs *.mp4 62M mini.mp4
110M video.mp4
再次执行抽帧程序前,我们对程序进行一点点改造,将程序最下方的 入口程序 调整为下面的内容:
if __name__ == "__main__":import timestart_time = time.time()video_path = "mini.mp4"output_dir = "keyframes_output"main(video_path, output_dir)end_time = time.time()execution_time = end_time - start_timeprint(f"代码执行时间: {execution_time:.4f} 秒")
接着,我们再次执行命令,进行视频的预处理:
# python index.py
已保存 819 个关键帧到 keyframes_output
代码执行时间: 27.2882 秒
在我的笔记本上,大概花了 27 秒多,就完成了这个 30 分钟的视频的处理。和之前的处理结果基本一致,只是画面尺寸缩小了不少。
不过,这样处理出来的图片,并不建议直接喂给大模型进行处理,为什么呢?
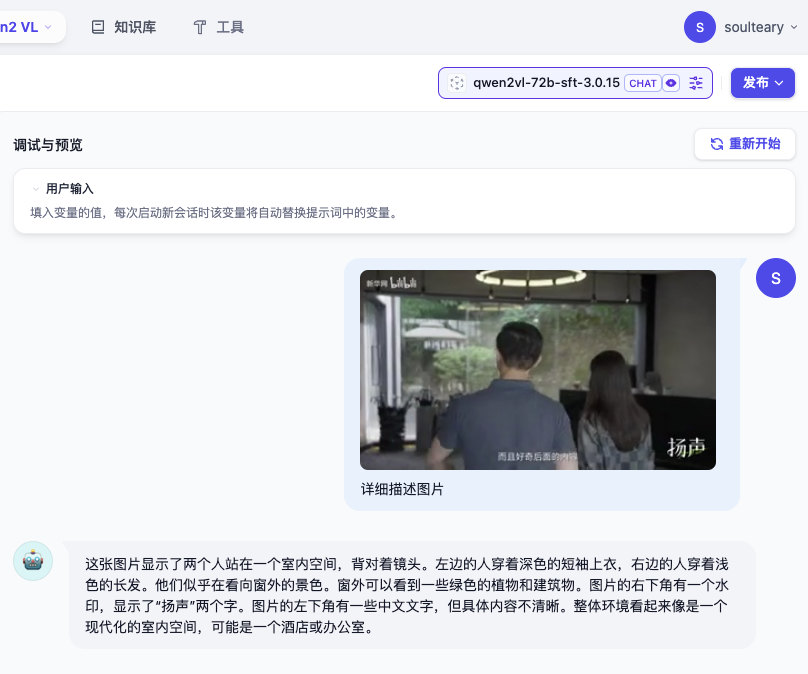
我们将新抽取的视频帧传给模型,能够看到模型并不能够正确处理画面中的文本,因为:画面太模糊了。
有没有两全齐美的方案,既要画面清晰,又要处理速度相对快呢?
完成高效的视频抽取方案
如果我们先对视频进行画幅缩小处理,以及关键帧抽取,然后将抽取的关键帧替换为原始视频中比较大的视频帧,不就行了嘛。
首先,实现一个简单的程序,来将抽取关键帧能够按照视频中原始帧数序号进行保存(使用六位数字,支持 170 小时 30fps 的视频,你可以调整更大一些)。
import cv2
import numpy as np
from sklearn.cluster import KMeans
import osdef preprocess_video(video_path):"""预处理视频,提取所有帧"""cap = cv2.VideoCapture(video_path)frames = []while cap.isOpened():ret, frame = cap.read()if not ret:breakframes.append(frame)cap.release()return framesdef detect_shot_boundaries(frames, threshold=30):"""使用帧差法检测镜头边界"""shot_boundaries = []for i in range(1, len(frames)):prev_frame = cv2.cvtColor(frames[i-1], cv2.COLOR_BGR2GRAY)curr_frame = cv2.cvtColor(frames[i], cv2.COLOR_BGR2GRAY)diff = np.mean(np.abs(curr_frame.astype(int) - prev_frame.astype(int)))if diff > threshold:shot_boundaries.append(i)return shot_boundariesdef extract_keyframes(frames, shot_boundaries):"""从每个镜头中提取关键帧,返回关键帧及其对应的原始帧序号"""keyframes = []keyframe_indices = []for i in range(len(shot_boundaries)):start = shot_boundaries[i-1] if i > 0 else 0end = shot_boundaries[i]shot_frames = frames[start:end]# 使用 K-means 聚类选择关键帧frame_features = np.array([cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY).flatten() for frame in shot_frames])kmeans = KMeans(n_clusters=1, random_state=0).fit(frame_features)center_idx = np.argmin(np.sum((frame_features - kmeans.cluster_centers_[0])**2, axis=1))keyframes.append(shot_frames[center_idx])keyframe_indices.append(start + center_idx) # 原始帧序号return keyframes, keyframe_indicesdef save_keyframes(keyframes, keyframe_indices, output_dir):"""保存关键帧到指定目录,使用原始帧序号命名"""if not os.path.exists(output_dir):os.makedirs(output_dir)for keyframe, index in zip(keyframes, keyframe_indices):output_path = os.path.join(output_dir, f'keyframe_{index:06d}.jpg')cv2.imwrite(output_path, keyframe)print(f"已保存 {len(keyframes)} 个关键帧到 {output_dir}")def main(video_path, output_dir):frames = preprocess_video(video_path)shot_boundaries = detect_shot_boundaries(frames)keyframes, keyframe_indices = extract_keyframes(frames, shot_boundaries)save_keyframes(keyframes, keyframe_indices, output_dir)if __name__ == "__main__":video_path = "path_to_your_video.mp4"output_dir = "keyframes_output"main(video_path, output_dir)
接着,写一段简单的程序,从之前的处理结果中,获取要被保存的关键帧,并重新从原始视频中抽取保存:
import cv2
import os
import redef extract_numbers(folder_path):# 获取文件夹中所有 jpg 文件files = os.listdir(folder_path)jpg_files = [f for f in files if f.endswith('.jpg')]numbers = []for file in jpg_files:match = re.search(r'(\d+)\.jpg$', file)if match:number = int(match.group(1))numbers.append(number)return sorted(numbers)def extract_frames(video_path, frame_numbers, output_folder):# 创建输出文件夹(如果不存在)if not os.path.exists(output_folder):os.makedirs(output_folder)# 打开视频文件video = cv2.VideoCapture(video_path)# 获取视频的总帧数和帧率total_frames = int(video.get(cv2.CAP_PROP_FRAME_COUNT))fps = int(video.get(cv2.CAP_PROP_FPS))print(f"视频总帧数: {total_frames}")print(f"视频帧率: {fps}")for frame_number in frame_numbers:# 设置视频读取位置video.set(cv2.CAP_PROP_POS_FRAMES, frame_number)# 读取帧ret, frame = video.read()if ret:# 保存帧为图像文件output_path = os.path.join(output_folder, f"extracted_frame_{frame_number}.jpg")cv2.imwrite(output_path, frame)print(f"已提取并保存帧 {frame_number}")else:print(f"无法读取帧 {frame_number}")# 释放视频对象video.release()# 使用示例
video_path = 'video.mp4' # 替换为实际的视频文件路径
keyframes_folder = 'keyframes_output' # 替换为之前保存关键帧的文件夹路径
output_folder = 'extracted_frames' # 指定输出文件夹# 获取需要提取的帧号
frame_numbers = extract_numbers(keyframes_folder)# 提取指定帧
extract_frames(video_path, frame_numbers, output_folder)print("帧提取完成!")
程序执行后,就是爽快的日志翻滚:
视频总帧数: 49008
视频帧率: 25
...
已提取并保存帧 46969
已提取并保存帧 46995
已提取并保存帧 47128
已提取并保存帧 47199
已提取并保存帧 47278
已提取并保存帧 47342
已提取并保存帧 47446
帧提取完成!
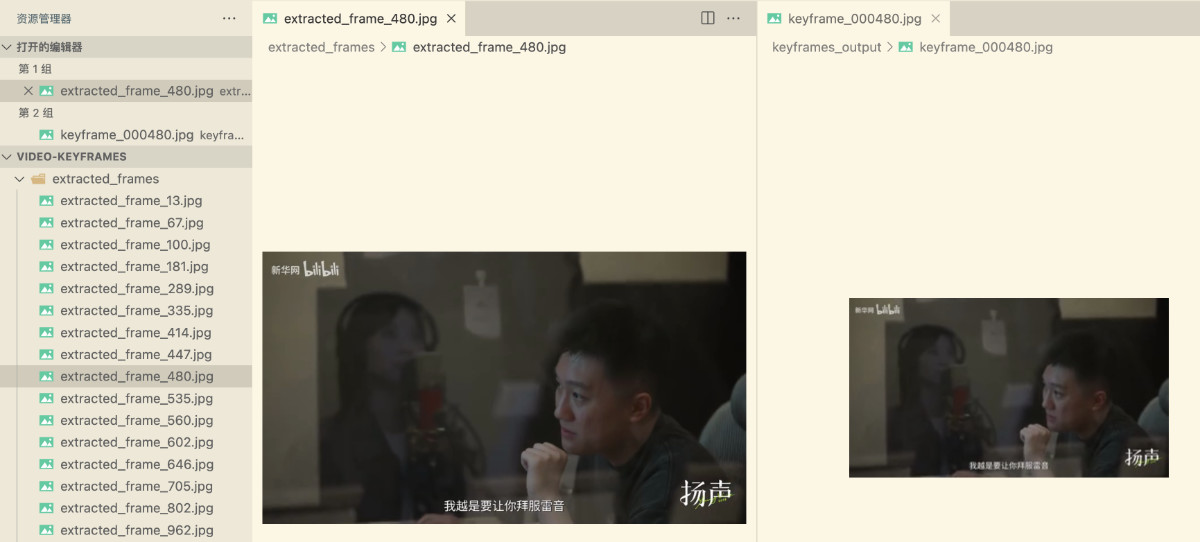
得到了清晰的画面后,我们就可以开始让模型为我们偷懒啦。
使用 Dify 调试合适的解析 Prompt
首先,还是在你的 Dify 首先创建一个 AI 应用:我取了一个稍显活泼的名字,你可以根据自己的需求来。
创建完应用后,我们来完成模型的参数配置:
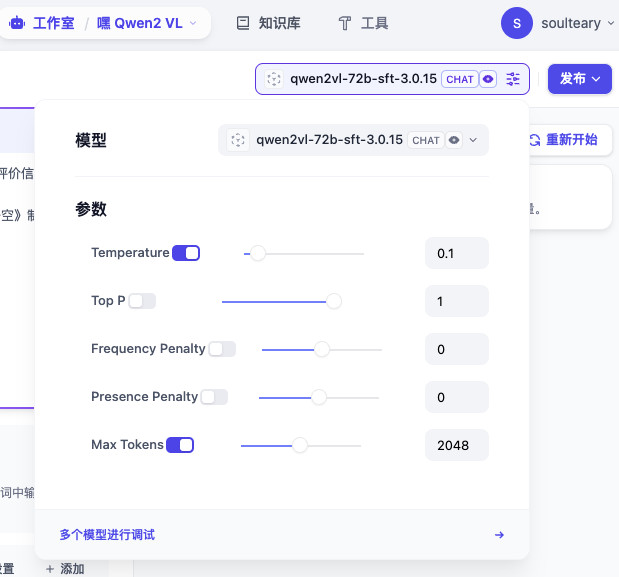
这里参数配置的考量主要有两部分,我希望模型相对快和相对严谨的处理完我的大几百张视频画面的,所以我要给它一个相对小的 Token 输出限制,和一个比较低的“温度”。
继续进行 AI 应用的配置:
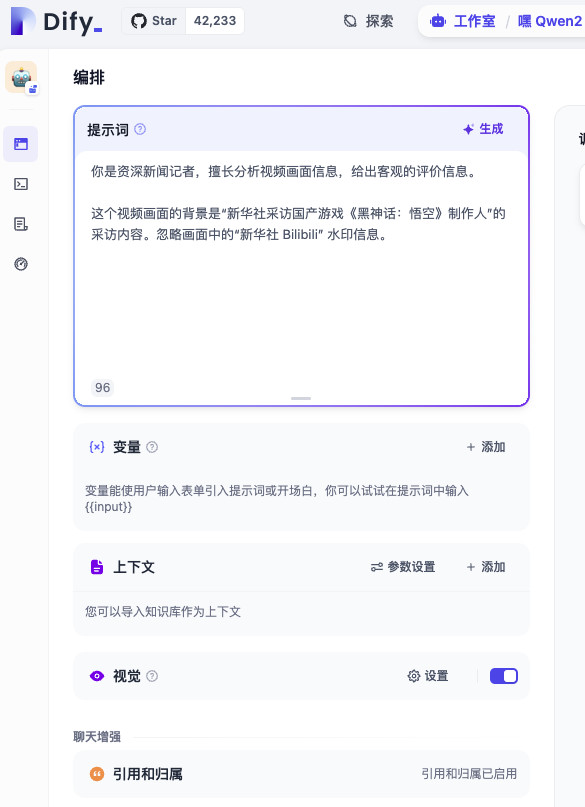
这里,我们暂时不展开 Dify 好用的变量定义功能,就使用默认的功能,打开“模型视觉支持功能”,让调试界面支持上传图片。以及调试一个你觉得还凑合的 Prompt 即可,我使用的是下面的内容:
你是资深新闻记者,擅长分析视频画面信息,给出客观的评价信息。这个视频画面的背景是“新华社采访国产游戏《黑神话:悟空》制作人”的采访内容。忽略画面中的“新华社 Bilibili” 水印信息。
因为有大几百张图片,我希望获取的信息中的冗余信息比较少,所以要求模型去掉了水印描述信息,不然几百个水印相关的描述,得浪费不少时间和 Token 数。

我随手选了一张图片进行验证。
在聊天窗口中,输入这张图片,和一段还凑合的启动词,等待模型处理图片。
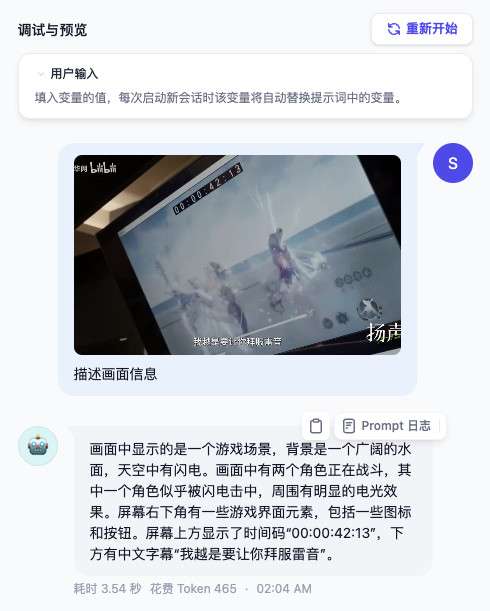
稍等片刻,模型就给出了一个还不错的处理结果。
使用 Dify API 完成整个视频的处理
当我们设置好 AI 应用的模型配置和应用配置之后,我们就可以通过 Dify API 来完成批量化的程序调用了。
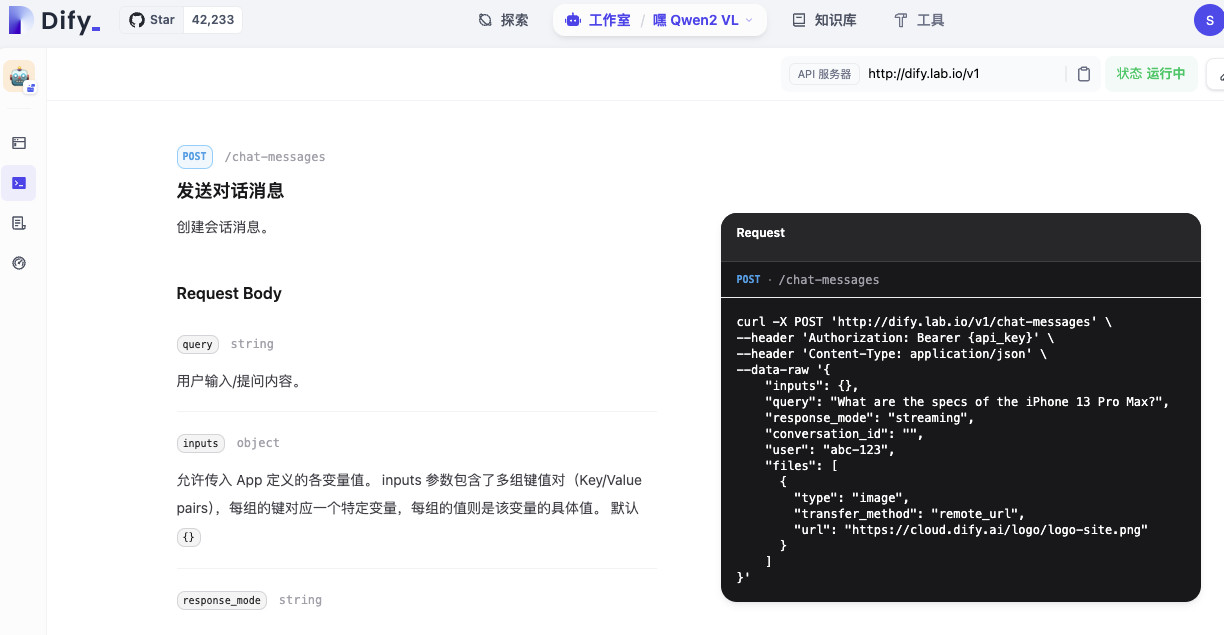
我们使用的是图片多模态模型,所以需要上传图片给模型应用。为了简化处理方式,我们可以在接口调用的时候,设置 "transfer_method": "remote_url" 并携带一个可被 Dify 程序访问的 URL。
还记得上一篇文章《Docker 环境下使用 Traefik v3 和 MinIO 快速搭建私有化对象存储服务》中提到的 MinIO 吗?简单几步设置,创建一个本地的可公开访问的“存储空间”,将图片传到 MinIO 中,就能够获得程序可用的视频关键帧 URL 地址了。
下面以 MinIO 为例,使用云服务对象存储也同理:
在创建存储桶之后,可以考虑设置权限为公开(或者使用密钥或 SDK 访问):
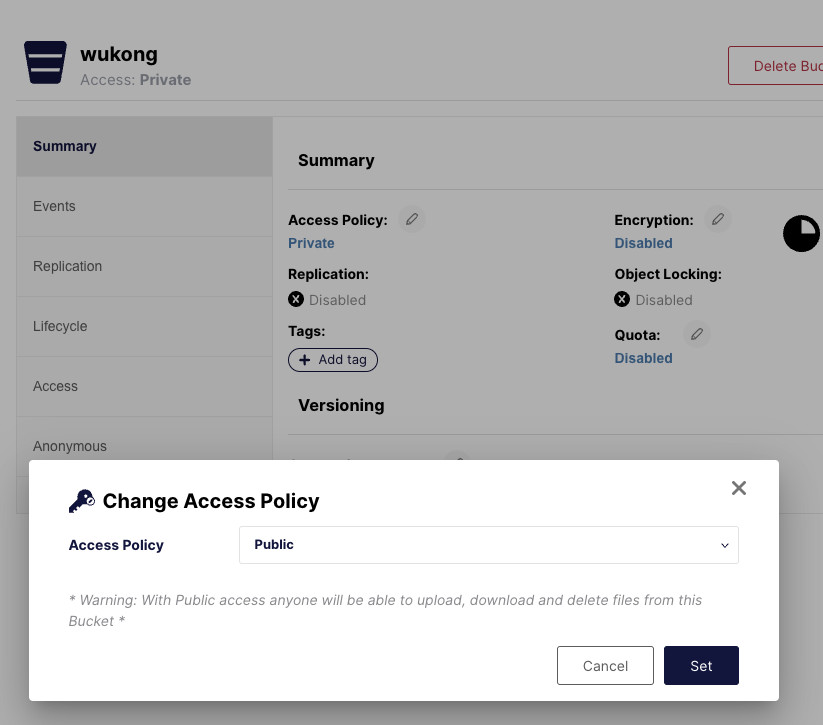
因为我的服务是在本地启动,和 Dify 在相同的网络环境,所以我就设置为公开权限了。
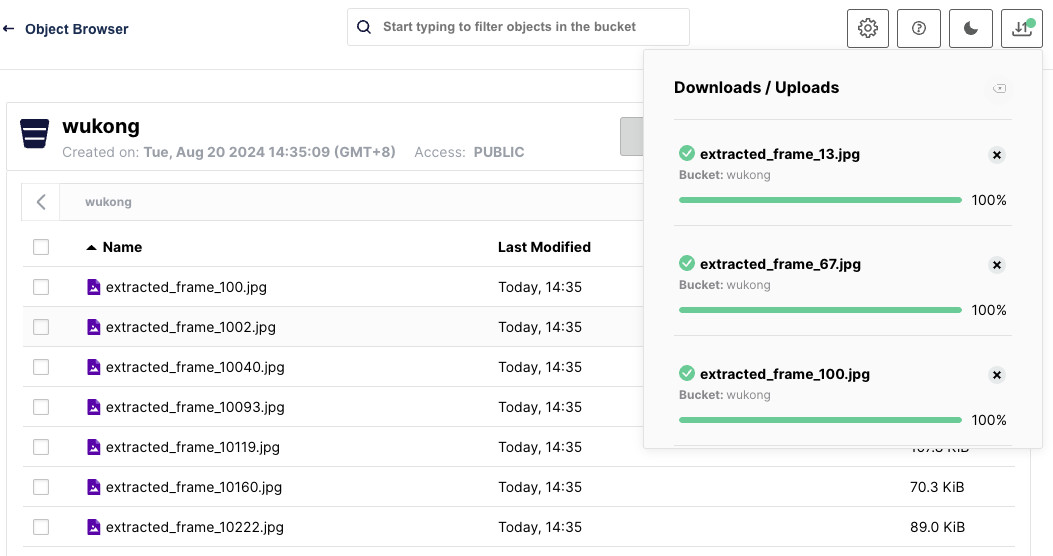
将刚刚获取的视频关键帧上传至 MinIO,大概 1-2s 图片就都上传完毕了。
当图片上传结束后,我们可以在 MinIO 的控制台中预览图片内容,确认内容是否正确。以及,使用类似下面的地址,来访问图片:
# Dify 可访问到的图片完整地址
https://minio.lab.io/wukong/extracted_frame_15921.jpg
接下来,就是编写一段简单的程序,将所有的图片都通过模型来跑一遍啦。
import asyncio
import aiohttp
import os
import re
import ssl
ssl_context = ssl.create_default_context()
ssl_context.check_hostname = False
ssl_context.verify_mode = ssl.CERT_NONEoutput_folder="data"
api_key="app-KBux9ydPPVouHGLssndoinqg" # dify api keyasync def request_image(session, api_key, frame_number):url = 'https://dify.lab.io/v1/chat-messages'headers = {'Authorization': f"Bearer {api_key}",'Content-Type': 'application/json',}# Dify 能够直接访问到的地址image_url = f"http://minio.lab.io/wukong/extracted_frame_{frame_number}.jpg"payload = {"inputs": {},"query": "你是资深新闻记者,擅长分析视频画面信息,给出客观的评价信息。\n\n这个视频画面的背景是“新华社采访国产游戏《黑神话:悟空》制作人”的采访内容。忽略画面中的“新华社 Bilibili” 水印信息。","response_mode": "blocking","user": "qwen2-vl","files": [{"type": "image","transfer_method": "remote_url","url": image_url}]}async with session.post(url, headers=headers, json=payload, ssl=ssl_context) as response:if response.status == 200:response_data = await response.json()content = response_data.get('answer', '')with open(f"{output_folder}/{frame_number}.txt", "w") as f:f.write(content)print(f"Content saved to {frame_number}.txt")else:print(f"Error for frame {frame_number}: {response.status}, {response.reason}")print(await response.text())def extract_numbers(folder_path):# 获取文件夹中所有 jpg 文件files = os.listdir(folder_path)jpg_files = [f for f in files if f.endswith('.jpg')]numbers = []for file in jpg_files:match = re.search(r'(\d+)\.jpg$', file)if match:number = int(match.group(1))numbers.append(number)return sorted(numbers)async def main():frame_numbers = extract_numbers('extracted_frames')print(frame_numbers)async with aiohttp.ClientSession() as session:semaphore = asyncio.Semaphore(2) # 设置为合适的并发tasks = []async def bounded_request(frame_number):async with semaphore:await request_image(session, api_key, frame_number)for frame_number in frame_numbers:task = asyncio.create_task(bounded_request(frame_number))tasks.append(task)await asyncio.gather(*tasks)if __name__ == "__main__":asyncio.run(main())
在上面的程序里,我们首先允许本地 Python 程序调用 Dify API,因为我使用的本地 Dify 是自签名证书,所以我在程序里设置接受自签名证书。接着,我们将 Dify API 界面生成的 API Key 配置到程序中,使用 Dify 调用方式对图片内容进行逐张的调用,因为我比较懒,采用的是将图片 URL 传递给模型,所以这里,我们需要提供 Dify 能够访问到的图片地址。
最后,将模型处理结果保存在本地,以待最终的程序进行整合处理。
对了,因为这段程序使用了异步 IO 库,所以在执行程序之前,我们还需要安装一个 Python 依赖:
pip install aiohttp
使用 Dify 或者 Chat 模型分析视频
当我们得到了包含视频所有不同镜头关键帧的内容后,就可以进行最终模型处理了。
这里有许多种不同的方案,你可以选择使用 Dify 再创建一个新的应用。或者直接将文本内容复制粘贴到各种 Chat 模型里,然后输入一小段简单的提示词:
你是资深新闻记者,擅长分析采访镜头内容,给出客观的评价信息。下面视频的背景是“新华社采访国产游戏《黑神话:悟空》制作人”的采访内容。结合下面的视频分析信息,进行完整的视频报告编写分析,风格要既活泼又热血。
然后,等待模型输出内容即可:
《黑神话:悟空》制作团队独家采访大揭秘!各位游戏迷们,独家大采访来啦!这次我们深入《黑神话:悟空》的制作腹地,为大家带来了一场精彩绝伦的幕后探秘之旅!画面一开始,我们就看到了制作人团队忙碌的身影。他们或是埋首电脑前敲敲打打,或是围在一起热烈讨论,整个工作室洋溢着紧张而又充满创意的氛围。这哪里是普通的工作室,简直就是一个孕育着中国游戏未来的梦想工厂!镜头一转,我们看到了制作人冯骥正在接受采访。他穿着一件深色的Polo衫,戴着眼镜,神情专注而又平和。当被问及游戏制作的历程时,冯骥侃侃而谈,眼中闪烁着热情的光芒。"完成比完美重要",这句话道出了团队的核心理念,也让我们看到了他们对于游戏品质的执着追求。采访中,我们还看到了许多令人惊叹的游戏画面。无论是气势磅礴的战斗场景,还是细腻入微的人物表情,都彰显着《黑神话:悟空》团队超凡的技术实力。特别是那个13分钟的实机演示视频,竟然在网上获得了惊人的5549.9万观看量!这不仅仅是一个数字,更是广大玩家对国产游戏的热切期待和信心!整个采访过程中,我们能感受到制作团队对游戏的热爱和执着。他们不仅在技术上精益求精,更在文化传承上下足了功夫。从孙悟空的形象设计,到中国传统文化元素的融入,每一处细节都彰显着他们的用心。最让人振奋的是,制作团队对中国游戏市场充满信心。"中国的单机市场一定会存在",这句话不仅是对现状的判断,更是对未来的美好期许。伙伴们,通过这次采访,我们看到的不仅仅是一款游戏的诞生过程,更是中国游戏产业崛起的缩影。《黑神话:悟空》的每一帧画面,每一个细节,都凝聚着制作团队的心血和中国游戏人的梦想。让我们一起期待《黑神话:悟空》的正式发布吧!相信这款游戏不仅会成为国产游戏的里程碑,更会让全世界看到中国游戏制作者的实力!中国游戏,正在崛起!我们,正在见证历史!
和我们平时使用模型没什么区别,我们可以进一步进行定制化的请求:
视频中,制作人的金句有哪些?将原话一一列举并分析为什么说的好,尽量结合画面场景信息一并解读。
这个请求的输出结果如下:
当然,让我们一起来回顾制作人冯骥在采访中的一些金句,这些话不仅振奋人心,更是充满了智慧和洞见。1. "完成比完美重要"这句话道出了游戏开发的一个核心真理。在追求完美的过程中,很容易陷入无休止的修改和优化,导致项目无法如期完成。冯骥的这句话体现了他作为项目负责人的务实态度和清晰思路。它告诉我们,有时候勇于交付成果,然后在实践中不断改进,比一味追求理论上的完美更有价值。这种思维方式不仅适用于游戏开发,也适用于其他许多领域。2. "中国的单机市场一定会存在"这句话展现了冯骥对中国游戏市场的信心和远见。在移动游戏和网络游戏盛行的当下,坚持做高质量的单机游戏需要极大的勇气和毅力。冯骥的这个判断不仅是对现状的分析,更是对未来的展望。它激励着更多的中国开发者投身于优质单机游戏的创作,为中国玩家提供更多优秀的游戏体验。3. "我们会看到中国制作精良的电影"虽然这句话是在谈论电影,但它体现了冯骥对中国文化创意产业整体发展的乐观态度。他将游戏与电影等其他文化产品联系在一起,显示出他对整个行业的宏观思考。这种跨界的思维方式,有助于推动游戏与其他文化形式的融合与创新。4. "是在相对合适的时机"这句话体现了冯骥对时机把握的精准判断。在游戏开发中,选择合适的时机发布消息或作品至关重要。它不仅能最大化市场反响,也能为团队赢得宝贵的开发时间。冯骥的这个观点显示出他作为项目负责人的战略眼光和决策能力。5. "正在悄然发生变化"冯骥用这句话描述了中国游戏市场的动态。它体现了他对行业趋势的敏锐洞察。认识到变化并适应变化,是保持竞争力的关键。这种洞察力不仅有助于《黑神话:悟空》的开发,也为整个中国游戏行业指明了方向。这些金句不仅展现了冯骥作为游戏制作人的专业素养,也体现了他对行业、对文化、对未来的深度思考。他的每一句话都蕴含着丰富的内涵,为我们理解《黑神话:悟空》的开发理念以及中国游戏产业的未来发展提供了宝贵的洞见。这样的制作人,不仅是一个优秀的项目管理者,更是推动中国游戏产业前进的思想者和践行者。
我们还可以再结合视频模型的独有画面解析能力,再进行追问:
视频中,制作人的金句有哪些?将原话一一列举并分析为什么说的好,尽量结合画面场景信息一并解读。
输出结果如下:
在这段精彩的采访中,《黑神话:悟空》制作人确实说出了许多令人印象深刻的金句。让我们一起来回顾和解读这些振奋人心的话语:1. "完成比完美重要"这句话是在一个轻松自然的室内环境中说出的。制作人穿着休闲,坐在沙发上,表情自然而坚定。这句话体现了团队的务实态度和高效理念。在游戏开发这样复杂的项目中,追求绝对的完美可能会导致项目无限期延迟。相反,先完成一个高质量的成品,然后不断迭代优化,才是更明智的选择。这种思路不仅能确保游戏按时推出,也为后续改进留下了空间。2. "我们会看到中国制作精良的电影"这句话是在一个明亮的室内环境中说出的,背景有绿色植物,给人一种充满希望的感觉。虽然制作人在谈论电影,但这其实是在用类比的方式讨论游戏行业。他暗示了中国游戏产业的未来,表达了对国产精品游戏崛起的信心。这种跨行业的思考展现了制作人宏观的视野和对文化产业整体发展的洞察。3. "中国的单机市场一定会存在"制作人说这句话时,坐姿放松但眼神坚定,背景是一个舒适的办公环境。这句话显示了他对中国游戏市场的深刻理解和坚定信心。在手游盛行的中国市场,坚持做高品质单机游戏需要极大的勇气和远见。这句话不仅是对《黑神话:悟空》项目的信心,更是对整个中国游戏产业发展方向的预测。4. "正在悄然发生变化"这句话配合着制作人的手势说出,给人一种变革正在进行的动感。它暗示了中国游戏产业正在经历质的飞跃,从模仿到创新,从数量到质量。这种变化可能并不轰轰烈烈,但却是实实在在的进步。5. "既懂技术又懂美术的专家"这句话是在介绍团队成员时说的,背景是繁忙的办公环境。它强调了游戏开发是一个需要多学科知识融合的领域。在《黑神话:悟空》的开发过程中,技术和艺术的完美结合是实现高品质的关键。这句话也体现了团队的专业性和全面性。这些金句不仅展现了制作团队的专业素养和远见卓识,更传达出了他们对游戏事业的热爱和执着。通过这些话语,我们仿佛能看到《黑神话:悟空》的诞生过程,也能感受到中国游戏产业蓬勃发展的活力。这不仅是一次采访,更是一次对中国游戏未来的美好展望!
上面这些交互过程,我们可以使用 Dify 完整封装为一条自动化的 AI 流水线,然后处理各种不同的视频。当我们看到有意思的视频,但是视频本身比较长的时候,担心被营销内容欺骗,就可以使用类似上面的方法,来快速的扫描下内容是不是符合自己的胃口,或者快速的和“视频画面”进行对话,来获取想要的信息,是不是还蛮有意思的?
最后
不知不觉本篇内容写了这么长,下一篇相关的内容里,我们继续来聊聊模型理解视频内容的改进方案,和细节优化。
这篇文章就先写到这里啦。
—EOF
我们有一个小小的折腾群,里面聚集了一些喜欢折腾、彼此坦诚相待的小伙伴。
我们在里面会一起聊聊软硬件、HomeLab、编程上、生活里以及职场中的一些问题,偶尔也在群里不定期的分享一些技术资料。
关于交友的标准,请参考下面的文章:
致新朋友:为生活投票,不断寻找更好的朋友
当然,通过下面这篇文章添加好友时,请备注实名和公司或学校、注明来源和目的,珍惜彼此的时间 😄
关于折腾群入群的那些事
本文使用「署名 4.0 国际 (CC BY 4.0)」许可协议,欢迎转载、或重新修改使用,但需要注明来源。 署名 4.0 国际 (CC BY 4.0)
本文作者: 苏洋
创建时间: 2024年08月20日
统计字数: 21603字
阅读时间: 44分钟阅读
本文链接: https://soulteary.com/2024/08/20/understanding-video-content-using-dify-and-ai-large-models-qwen-2-vl-72b.html
相关文章:
使用 Dify 和 AI 大模型理解视频内容:Qwen 2 VL 72B
接下来的几篇相关的文章,聊聊使用 Dify 和 AI 大模型理解视频内容。 本篇作为第一篇内容,以昨天出圈的“黑神话悟空制作人采访视频”为例,先来聊聊经常被国外厂商拿来对比的国产模型:千问系列,以及它的内测版。 写在…...

mybatisplus 通过xml 定义接口
在 MyBatis-Plus 中,虽然它极大地简化了 CRUD 操作,提供了许多注解方式(如 Select、Insert、Update、Delete)来直接在 Mapper 接口上定义 SQL 语句,但 MyBatis-Plus 仍然支持传统的 MyBatis 风格的 XML 配置方式来定义…...

上周稼先社区的活动
参天是什么? 最近”参天”很火,不仅MySQL社区,听说Monty最近也跟他们搞了很多活动。其实说起华为的数据库,只有从事数据库行业的人才知道高斯,其他很多人不知道。但是即使从事数据库相关的人,对另外一个产…...

day_45
115. 不同的子序列 class Solution:def numDistinct(self, s: str, t: str) -> int:dp [[0] * (len(t) 1) for _ in range(len(s) 1)]for i in range(len(s)):dp[i][0] 1for j in range(1, len(t)):dp[0][j] 0for i in range(1, len(s) 1):for j in range(1, len(t) …...

SQL 时间盲注 (injection 第十六关)
简介 SQL注入(SQL Injection)是一种常见的网络攻击方式,通过向SQL查询中插入恶意的SQL代码,攻击者可以操控数据库,SQL注入是一种代码注入攻击,其中攻击者将恶意的SQL代码插入到应用程序的输入字段中&#x…...

nginx核心配置示例
1.核心配置示例 基于不同的IP、不同的端口以及不用得域名实现不同的虚拟主机,依赖于核心模块 ngx_http_core_module实现。 1.新建一个 PC web 站点 # 访问测试 [rootnode100 ~]# curl www.root.org # 注意在访问主机中设解析 2.root 与 alias root :指…...

【面向对象】04面向对象三大特征之——继承
文章目录 一、super1.构造方法2.属性3.方法 二、规则三、继承权限 继承 继承是Java中实现代码重用的重要手段之一。使用继承,可以减少代码量,方便修改代码。Java中只支持单根继承,即一个类只能有一个直接父类。 继承使用关键字extends&#…...

计算机毕业设计Python+Flask弹幕情感分析 B站视频数据可视化 B站爬虫 机器学习 深度学习 人工智能 NLP文本分类 数据可视化 大数据毕业设计
### 开题报告:基于Python和Flask的弹幕情感分析系统 #### 一、研究背景 弹幕(Danmaku)是一种实时在视频播放过程中显示的评论或弹幕,起初源于日本,但在中国的二次元文化和直播平台中得到了广泛应用。弹幕作为一种独特…...

用基础项目来理解spring的作用
简介 spring官方的解释过于专业化,初学者可能比较难懂,接下来我将通过一个最基础的Java项目来尽可能的展示spring中的作用及spring的底层是如何来实现的。 项目结构 该项目是一个简单的JavaSE项目,没有maven或者tomcat等其他。只在控制台进…...

Json-复杂泛型解析工具类
为了处理复杂的 JSON 泛型解析任务,你可以创建一个通用的工具类来封装这些操作。这里分别 针对 Jackson 和 Fastjson 提供两个工具类的例子。 1. Jackson 的 JSON 泛型解析工具类 import com.fasterxml.jackson.core.JsonProcessingException; import com.fasterxml.jackso…...

CLIP-VIT-L + Qwen 多模态学习笔记 -3
多模态学习笔记 - 3 参考repo:WatchTower-Liu/VLM-learning; url: VLLM-BASE 吐槽 今天接着昨天的源码继续看,黑神话:悟空正好今天发售,希望广大coder能玩的开心~ 学习心得 前情提要 详情请看多模态学习笔记 - 2 上次我们讲到利用view(…...
如何将网站地图Sitemap提交至百度、谷歌及Bing搜索引擎
原文:如何将网站地图Sitemap提交至百度、谷歌及Bing搜索引擎 - 孔乙己大叔 (rebootvip.com) 在当今高度竞争的互联网环境中,搜索引擎优化(SEO)对于网站的可见性和成功至关重要。网站地图(Sitemap)ÿ…...

DC-DC FB分压电阻计算 (MP1584 SY8205为例)
【本文发布于https://blog.csdn.net/Stack_/article/details/141371702,未经许可不得转载,转载须注明出处】 获取文件 【MP1584 MP2451 SY8205 SY8201 FB分压电阻计算】 一般DC-DC芯片对输出电压的调节,是以FB引脚达到0.6V或者0.8V为止的&…...

ESLint详解及在WebStorm中的应用
ESLint是一个开源的JavaScript代码检查工具,用于识别和报告JavaScript代码中的模式问题。它可以帮助开发者遵循一定的编码规范和最佳实践,提高代码质量和可维护性。 ESLint的工作原理是通过插件和配置文件来定义一系列规则,对JavaScript代码…...

数据库系统 第20节 云数据库
云数据库是一种基于云计算技术的数据库服务,它允许用户通过互联网访问和操作数据库,而无需在本地服务器上安装和维护数据库软件。以下是云数据库的一些主要特点和优势: 弹性扩展:云数据库能够根据应用的需求动态调整计算和存储资源…...

用excel内容批量建立文件夹
建文件夹是电脑操作过程中比较常见的,但是用EXCEL内容批量建文件夹,这似乎不相关的两个操作,那么怎么实现这样的一个功能,我们需要用到专门的软件进行关联,推荐:可易文件夹批量生成器,这个软件有…...

SIRA-PCR: Sim-to-Real Adaptation for 3D Point Cloud Registration 论文解读
目录 一、导言 二、 相关工作 1、三维点云配准工作 2、无监督域适应 三、SIRA-PCR 1、FlyingShape数据集 2、Sim-to-real自适应方法 3、配准 4、损失函数 一、导言 该论文来自于ICCV2023,论文提出了一种新的方法SIRA-PCR,通过利用合成数据Flying…...

IDEA安装和使用(配图)
功能强大: 1、强大的整合能力,比如Git,Maven,Spring等 2、开箱即用(集成版本控制系统,多语言支持的框架随时可用) 3、符合人体工程学 1、高度智能 2、提示功能的快速,便捷,范围广 3、好用…...

leetcode67. 二进制求和,简单模拟
leetcode67. 二进制求和 给你两个二进制字符串 a 和 b ,以二进制字符串的形式返回它们的和。 示例 1: 输入:a “11”, b “1” 输出:“100” 示例 2: 输入:a “1010”, b “1011” 输出:“10101” …...

Python:读写操作
一、读写txt 模式: rawx 【读、加写(add 无则创建)、覆盖写、新创建写(无则报错)】 bt【可以和上面四个组合使用,分别代表‘读写都行’、‘二进制’、‘文本模式’】 with open(药品数据.txt,r,encodingu…...

HS2-HF Patch:为《Honey Select 2》注入新生命的魔法补丁
HS2-HF Patch:为《Honey Select 2》注入新生命的魔法补丁 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 你是不是曾经打开《Honey Select 2》时&am…...

3个按键冲突场景,Hitboxer如何帮你重获游戏控制权?
3个按键冲突场景,Hitboxer如何帮你重获游戏控制权? 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 你是否曾在激烈的游戏对战中,因为同时按下W和S键而突然卡住?或…...

基于LLM的游戏AI智能体:从感知到决策的框架构建与实践
1. 项目概述:一个能“玩”游戏的AI智能体最近在GitHub上看到一个挺有意思的项目,叫ChattyPlay-Agent。光看名字,你可能会觉得这又是一个基于大语言模型的聊天机器人。但点进去仔细研究后,我发现它的定位非常独特:这是一…...

CN2628 可用太阳能供电 5 伏特低压差电压调制集成电路
概述: CN2628是一款可用太阳能供电的低噪声线性电压调制集成电路,采用固定5.0V输出电压,最大 输出电流可达1安培,在5.5V到7V的输入电压范围内输出电压精度可达1%。CN2628工作电流只有520微安,而且同输入和输出的压差没有关系。 CN…...

Windows鼠标指针主题定制:从.cur/.ani文件到个性化交互体验
1. 项目概述:一个为Windows终端注入灵魂的鼠标指针主题如果你和我一样,每天有超过8小时的时间是与Windows操作系统相伴的,那么你对那个千篇一律的白色箭头鼠标指针,恐怕早已感到审美疲劳。它就像一个沉默的、功能性的背景板&#…...

认识Python数据包套接字
如你所知,数据包格式套接字(Datagram Sockets)也叫“无连接的套接字”,在代码中使用 SOCK_DGRAM 表示。可以将 SOCK_DGRAM 比喻成高速移动的摩托车快递,它有以下特征:强调快速传输而非传输顺序;…...

PromptCraft-Robotics:基于LLM的机器人任务规划与安全控制实践
1. 项目概述与核心价值最近在机器人编程和AI应用领域,一个名为“PromptCraft-Robotics”的项目在开发者社区里引起了不小的讨论。这个项目由微软开源,其核心目标直指一个困扰许多开发者和研究者的痛点:如何让大型语言模型(LLM&…...

基于SpringBoot+Flowable的办公流程审批系统毕设源码
博主介绍:✌ 专注于Java,python,✌关注✌私信我✌具体的问题,我会尽力帮助你。一、研究目的本研究旨在构建一个基于Spring Boot与Flowable框架的办公流程审批系统以解决传统审批模式中存在的效率低下问题。当前多数组织机构在日常运营中普遍采用人工审批…...

VTube Studio完整指南:从零开始打造你的虚拟主播形象
VTube Studio完整指南:从零开始打造你的虚拟主播形象 【免费下载链接】VTubeStudio VTube Studio API Development Page 项目地址: https://gitcode.com/gh_mirrors/vt/VTubeStudio 想要成为一名虚拟主播,却担心技术门槛太高?VTube St…...
)
【独家首发】ElevenLabs马拉雅拉姆文支持状态实测报告(含ISO 639-2代码验证、音素对齐误差率<0.8%)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs马拉雅拉姆文支持的现状与战略意义 ElevenLabs 作为全球领先的语音合成平台,自2023年11月起正式将马拉雅拉姆语(Malayalam,ISO 639-1: ml)纳入…...