大话LLM之向量数据库
向量数据库是一种专门设计的存储系统,旨在高效处理和查询高维向量数据,通常用于人工智能和机器学习应用中,以实现快速准确的数据检索。

好的,今天我们就来聊聊人工智能和向量数据库的事儿。现在人工智能发展得特别快,特别是那些大型的语言模型,它们真是创新的前沿。但不管这些模型有多厉害,它们都得有个核心的东西,那就是能够处理大量的数据。这些数据得被理解、被整理,还得能被搜索,这样我们才能从中找到真正有意义的信息。
说到生成性人工智能,无论是正在处理的还是正在开发的,它们都离不开一种叫做向量嵌入的技术。这就像是给人工智能提供了一种语义上的数据类型,让它能够像我们人类一样,有长期记忆的能力,处理那些复杂的任务时,能够回忆起需要的信息。
向量嵌入其实就是人工智能模型用来做决策的一种数据表达方式。就像我们大脑里的记忆一样,它们包含了复杂性、不同的维度、模式和各种关系。所有这些信息都得被妥善地存储和表现出来,这可不简单,管理起来挺费劲的。
所以,这就是为什么我们需要一种特别为人工智能设计的数据库,我们就叫它向量数据库吧。这种数据库就是用来存储和查找那些高维的向量数据的。向量嘛,你可以想象成在很多维度上都能表示出一个物体或者数据点的数学形式,每个维度都代表了不同的特征或属性。

向量数据库的厉害之处就在于,它能够把一大堆数据以向量的形式存起来,然后在我们需要的时候再找出来。这就像是在很多个不同的方向上,找到了一个空间里头的数据点。当我们用向量搜索的时候,就相当于是在这片多维的空间里头,根据数学上的那种编码或者叫嵌入,来找出和我们要找的东西最接近的那些数据。
想象一下,你在用一个视频流服务看剧,比如说你正在追一个科幻西部片。这时候,向量搜索就能派上用场了,它能够在所有的视频库里,迅速找到和你看的这个剧主题相近的其他剧或者电影推荐给你。这个过程不需要给每个视频打上标签说这是什么类型的,向量搜索自己就能搞定,而且它还能找到一些你可能没特意去找,但是根据你的观看习惯,可能也会感兴趣的其他类型的内容。
向量数据库和那种只提升搜索效率的向量索引不一样,它不仅能处理大规模的数据,还特别擅长处理向量嵌入这种复杂的东西。它结合了传统数据库的优点,并且对存储向量嵌入做了特别的优化,还提供了高性能的数据访问,这是那些普通的标量数据库和关系数据库做不到的。简单来说,向量数据库就是让存储和检索大量数据,进行向量搜索变得可能的一个强大工具。
为什么向量数据库很重要?
数据库在开发应用程序时特别有用,它就像是一个超级能干的助手,能帮我们把数据整理得井井有条,让应用程序用起来更顺手。就像我们之前聊到的,向量数据库对于搞生成性人工智能的那些应用来说,简直就是基石一样的存在,因为它们能做向量搜索,这是找数据的一种高级方式。
想当初,机器学习刚起步的时候,用到的数据量其实挺小的。但是呢,现在生成性人工智能火起来了,要训练和提高这些智能系统,数据量那是噌噌地往上涨,简直就是爆发式增长。所以说,向量数据库就显得特别重要了,它们能帮我们把大量的数据按照生成性人工智能需要的方式存起来,这样在用的时候就能更加得心应手。
-
语义搜索的优化: 生成性人工智能应用,它们需要用到高维向量这种数据表达方式。向量数据库就能帮大忙,不仅能存这些向量,还能飞快地找出和你要搜索的内容差不多的向量。不管你是在找文本、图片还是其他什么,向量数据库都能帮你快速地用数学的方法存和找信息,这对于开发这种智能应用来说超级关键。
-
动态数据探索: 有了向量数据库,生成性人工智能的输出就不再局限于一次性的交互了。它们可以被存起来,反复使用,这样应用就能在整个向量空间里穿梭,找出可能的替代方案、异常或者变化,甚至是不同的匹配标准,这样一来,用户体验就能大大提升,内容的生成和发现也更加动态。
-
可扩展性: 随着生成性人工智能应用越做越大,需要提供给用户的数据量也越来越大,这就对存储和检索数据提出了更高的要求。向量数据库就是专门为了应对这种数据集增长的情况设计的,能够提供优化的数据访问方式。
-
检索增强生成: 随着这些智能应用不断进步,人们发现使用像检索增强生成(RAG)这样的架构模式来构建应用,会变得更加灵活和可扩展。向量数据库在这里就起到了粘合剂的作用,它允许我们存储和检索大量的数据集,这些数据集可以在多个生成过程中被增强和利用。
总之,向量数据库的好处多多,最关键的是它们能让我们在存储、检索和使用生成性人工智能应用所需的大型数据集时,变得更加自然和高效。
向量数据库如何工作?
生成性人工智能要想真正发挥作用,它得有个超级大脑,能实时快速地访问所有的嵌入数据,这样它才能形成深刻的见解,进行复杂的数据分析,还能对提出的问题做出生成性的预测。就像我们人脑处理信息和记忆一样,我们经常是通过比较记忆和发生的其他事情来处理记忆的。比如我们知道不能伸手进沸水,因为以前被烫过;或者知道不要吃某种食物,因为记得它对我们不好。向量数据库的工作原理也类似,它把数据(也就是记忆)排好,然后进行快速的数学比较,这样通用的人工智能模型就能找到最有可能的结果。像chatGPT这样的工具,就需要能够快速高效地比较所有给定查询的选项,然后给出一个非常准确和及时的答案,来逻辑上完成一个想法或句子。
挑战在于,生成性人工智能不能依赖传统的标量和关系数据库方法,因为那些方法太慢、太死板、视野太窄。生成性人工智能需要的是一个专门为它设计的数据库,这个数据库要能够存储它的大脑处理的数学表示,并且提供极高的性能、可扩展性和适应性,充分利用它拥有的所有数据。它需要的数据库要像人脑一样,有存储记忆印迹的能力,并且能够根据需要快速访问、关联和处理这些印迹。
有了向量数据库,我们就有能力快速地加载和存储事件作为嵌入,用我们的向量数据库作为大脑,为我们的AI模型提供动力,提供上下文信息、长期记忆检索、类似语义的数据相关性等等。这就像是给人工智能装上了一个超级大脑,让它能够更聪明、更快速地理解和处理信息。

向量数据库要干的活儿,就是得特别快地找出那些长得像的数据。为了做到这一点,它们用了一些特别聪明的索引技巧和算法,比如树形结构的k-d树、图结构的k-最近邻图,或者像局部敏感哈希这样的哈希技术。这些方法就像是给数据排排队,让它们更容易被找到。
在这个数据库里,每个向量都不是光杆司令,它们都带着自己的小标签和信息,比如标签、编号之类的。这样,数据库就能根据向量之间的相似性或者距离,特别高效地存数据、找数据和查数据。
向量数据库的工作方式可以分成三个步骤:
-
索引: 这就像是给数据贴标签,好让它们更容易被找到。就像我们的大脑会根据不同的情况用不同的方式记忆信息一样,向量数据库也会用不同的算法来组织数据,让搜索变得更快。
-
查询: 这就是我们用大脑回忆信息的时候。如果我们以前被烫过,下次看到热平底锅就会小心。向量数据库也是,它会根据我们提供的信息,找出最接近的向量,也就是最相似的数据。
-
后处理: 这就像是我们在大脑里再次检查我们的决定。比如,我们看到热平底锅,大脑不仅会告诉我们它可能是热的,还会迅速提醒我们不要碰,因为可能会受伤。
总之,向量数据库就像是个超级大脑,它用特别的方法来存储和快速找到那些我们需要的、相似的数据。
向量数据库和检索增强生成(RAG)
向量数据库之所以这么重要,主要是因为它们能让生成性人工智能模型变得更强大,尤其是在用到检索增强生成(RAG)架构的时候。简单来说,RAG架构就像是给生成性AI应用打开了一扇大门,不仅能创造新内容,还能把已有的大量数据集合并起来,用它们的上下文信息来丰富AI的见识。
向量数据库在RAG架构中扮演的角色可不小,它能简化很多RAG需要做的事情:
-
高效的相似性搜索: 向量数据库天生就擅长快速找出和给定的输入相似的内容。对于RAG架构来说,能迅速从数据库里找到相关的上下文信息非常关键,向量数据库就能提供这样的能力,让信息存储和检索都变得高效。
-
内容扩展和多样性: 任何成功的生成性AI应用都需要不断吸收新的观点、信息和上下文。AI最怕的就是走偏了,或者只看到事情的一面。防止这种情况发生的最好办法就是确保用的数据是最新的、经过验证的,而且是多角度的。如果AI应用只用有限的数据,不吸收新信息,就容易产生偏见或走偏。向量数据库就能帮AI应用检索和利用过去、现在甚至未来的信息,让它们的行为和输出更加丰富和准确。
-
动态多模态数据检索: RAG架构的厉害之处在于,它能结合不同的内容生成方法,把预测性AI和生成性AI的差距给弥补上。有了向量数据库的支持,生成性AI应用可以同时处理多种类型的数据,比如文本、音频、图像等,然后在不同的领域里生成相关的输出。
总之,向量数据库就像是给生成性AI应用提供了一个强大的后盾,让它们能够更聪明、更灵活地处理和创造信息。
向量数据库与传统数据库之间的区别是什么?
向量数据库和我们平时用的那种传统数据库大不一样。传统数据库就像是个图书馆,所有的书(数据)都按照类型和编号(行和列)整齐地放在书架上,你要找什么书,直接按照分类号(索引或键值对)就能找到。它们擅长找那些完全对得上的书,比如你要找的是一本特定的数学书,它就能精确地给你那一本。
但是向量数据库呢,它更像是个智能助手,不仅能帮你找到那本数学书,还能找出其他和这本数学书主题相近的书。它不用传统的行和列来存储数据,而是用向量这种新的形式。向量就是一堆数字,它们可以表示很多东西的特征。向量数据库就是专门优化来快速存这些向量,找这些向量,还能找出和你要查的东西最相近的那些向量。
在传统数据库里,我们通常要的是精确匹配,比如精确找到某个客户的信息。但向量数据库不是这样,它更灵活,它存的是一串数字(浮点数),找的时候也不是非得完全一样,而是找最接近的结果。它用很多不同的算法来干这个活,这些算法都擅长做近似最近邻(ANN)搜索,能快速找到一大堆和查询差不多的相关信息。
传统数据库在处理高维数据时就有点力不从心了,因为数据量大了,维度多了,它们就不容易扩展。但是AI应用就需要这样的能力,它们要存很多数据,要能快速找到想要的数据,还要能在分散在不同地方的数据中找到联系。向量数据库就是为这个目的设计的,它们提供了一种高度分布式、灵活的解决方案,特别适合用来支持AI应用。
向量数据库如何帮助提升AI
向量数据库给人工智能带来的好处,就像是给AI装上了一个超级记忆力。它们让AI能够快速地访问和检索大型数据集,就像是用现有的模型来进行实时操作一样。这就像是在我们自己的大脑中使用记忆一样,向量数据库提供了记忆回忆的基础。
有了向量数据库,人工智能的工作就被分成了几个部分:有负责思考的大型语言模型,有负责记忆的向量数据库,还有专门存储信息的向量嵌入,以及像神经途径一样的数据管道。
这些部分一起工作,让人工智能能够顺畅地学习新东西、成长,还能获取信息。向量数据库里保存了所有的记忆印迹,就像我们大脑中存储的记忆一样,能够在需要的时候回忆起来,触发类似的体验和情感。
向量数据库让生成性AI能够接触到大量的数据,并且能够高效地把这些数据联系起来,用它们来做决策。当这些数据库连接到数据管道,就像是接入了一个神经系统,新的记忆就能被存储和访问,就像是在它们形成的时候一样。这样,AI模型就能够根据提供的历史、分析或实时信息,适应性地学习和成长。简单来说,向量数据库就是让AI更聪明、反应更快的秘密武器。

相关文章:
大话LLM之向量数据库
向量数据库是一种专门设计的存储系统,旨在高效处理和查询高维向量数据,通常用于人工智能和机器学习应用中,以实现快速准确的数据检索。 好的,今天我们就来聊聊人工智能和向量数据库的事儿。现在人工智能发展得特别快,特…...

EmguCV学习笔记 C# 2.2 Matrix类
版权声明:本文为博主原创文章,转载请在显著位置标明本文出处以及作者网名,未经作者允许不得用于商业目的。 EmguCV学习笔记目录 Vb.net EmguCV学习笔记目录 C# 笔者的博客网址:VB.Net-CSDN博客 教程相关说明以及如何获得pdf教…...

[Windows CMD] 查看网络连接状态 netstat -na | findstr “TCP“
在 Windows 系统中,我们可以使用 netstat 命令来查看网络连接状态,并使用 findstr 命令来过滤出 TCP 和 UDP 的连接。 查看所有网络连接的状态 netstat -na netstat -na: 显示所有网络连接的状态,-n 表示显示数字地址而非域名,…...
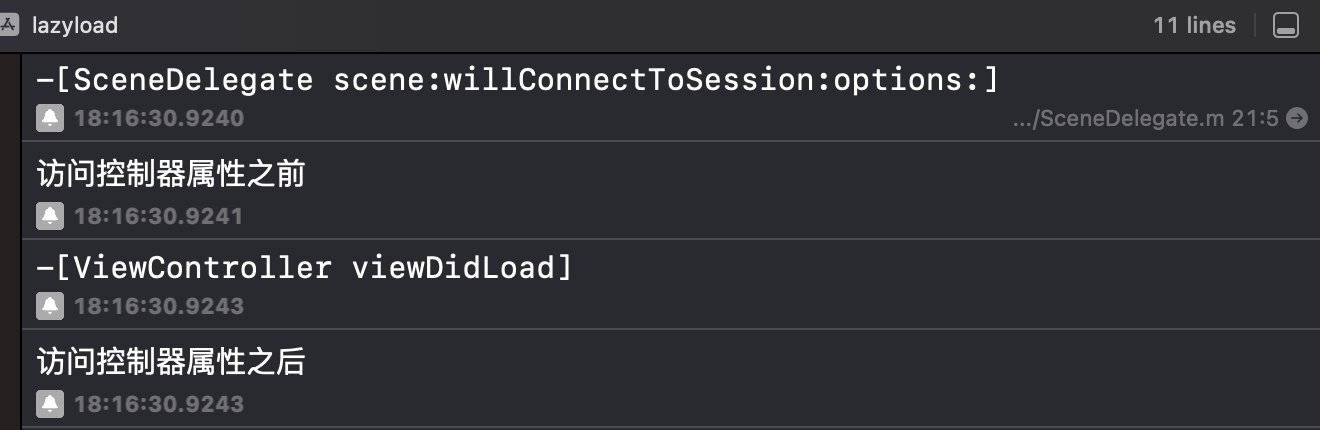
「OC」视图控制器的懒加载策略
「OC」视图控制器的懒加载策略 文章目录 「OC」视图控制器的懒加载策略懒加载懒加载的优点常见的懒加载实现方法使用懒加载的注意事项 控制器的懒加载参考资料 懒加载 懒加载(Lazy Loading)是一种设计模式,其核心思想是在需要时才进行对象的…...

android studio 中 .gitignore 文件改动后 忽略的文件夹或文件无效
问题原因:已跟踪文件的缓存问题: 如果之前已经跟踪了这些文件(即它们已经被 Git 加入到版本控制中),即使你在 .gitignore 文件中添加了忽略规则,Git 仍然会显示这些文件。你需要先从 Git 中移除这些文件&am…...
)
鸿蒙 next 实现摄像头视频预览编码(一)
鸿蒙 next 即将发布,让我们先喊3遍 遥遥领先~ 遥遥领先~ 遥遥领先~ 作为一门新的系统,本人也是刚入门学习中,如果对于一些理解有问题的,欢迎即使指出哈 首先这里要讲一下,在鸿蒙 next 中,要实现摄像头预览…...

YOLO-V3
一、概述 最大的改进就是网络结构,使其更适合小目标检测特征做的更细致,融入多持续特征图信息来预测不同规格物体先验框更丰富了,3种scale,每种3个规格,一共9种softmax改进,预测多标签任务 先验框…...

golang提案,内置 Go 错误检查函数
先来狠狠吐个槽 要吐槽 Go1 的 error ,那咱得先整明白大家为啥都猛喷它的错误处理做得不咋地。在 Go 语言里头,error 本质上其实就是个 Error 的接口: type error interface {Error() string }实际的应用场景如下: func main()…...
)
零售业务产品系统应用架构设计(三)
智慧物业依据《住房和城乡建设部等部门关于推动物业服务企业加快发展线上线下生活服务的意见建房〔2020〕99号》,推动物业管理公司广泛运用5G、互联网、物联网、云计算、大数据、区块链和人工智能等技术,建设智慧物业管理服务平台,对接城市信息模型(CIM)和城市运行管理服务…...

【GD32】从零开始学GD32单片机 | PMU电源管理单元+深度睡眠和待机例程(GD32F470ZGT6)
1. 简介 PMU电源管理单元通俗讲就是用来管理MCU的电源域的,它主要有两个功能——电压监测和低功耗管理。在GD32中一共有3个电源域——VDD/VDDA域、1.2V域和备份域。 VDD/VDDA域主要供PMU控制器、ADC、DAC等外设使用;1.2V域就是大部分外设都会使用的电源域…...

公司员工电脑桌面太乱如何解决?桌面管理软件一招解决!
“工欲善其事,必先利其器。” 在数字化管理的时代背景下,选择合适的桌面管理软件就如同为企业网络管理装上了一双慧眼。 员工的电脑桌面往往因为长时间的使用而变得杂乱无章,这不仅影响了工作效率,还可能给企业信息安全带来隐患。…...

leetcode:2119. 反转两次的数字(python3解法)
难度:简单 反转 一个整数意味着倒置它的所有位。 例如,反转 2021 得到 1202 。反转 12300 得到 321 ,不保留前导零 。 给你一个整数 num ,反转 num 得到 reversed1 ,接着反转 reversed1 得到 reversed2 。如果 reverse…...

5.vue中axios封装工程化
vue工程化中axios封装 视频演示地址:https://www.bilibili.com/video/BV121egeQEHg/?vd_source0f4eae2845bd3b24b877e4586ffda69a 通常我们封装需要封装request.js基础的发送请求工具类,再根据业务封装service类,service类是具体业务的接口…...

实验六:动态数码管实验
实验结果图,从右到左0-7,从左到右7-0,来回滚动。 硬件接线图: 具体看图,不说了,前面讲过,自己查资料就可以,资料得慢慢查,熟练就好了,不浪费时间和版面了 main.c代码 #include<reg52.h>typedef unsigned int u16; typedef unsigned char u8;#define SMG P0 …...
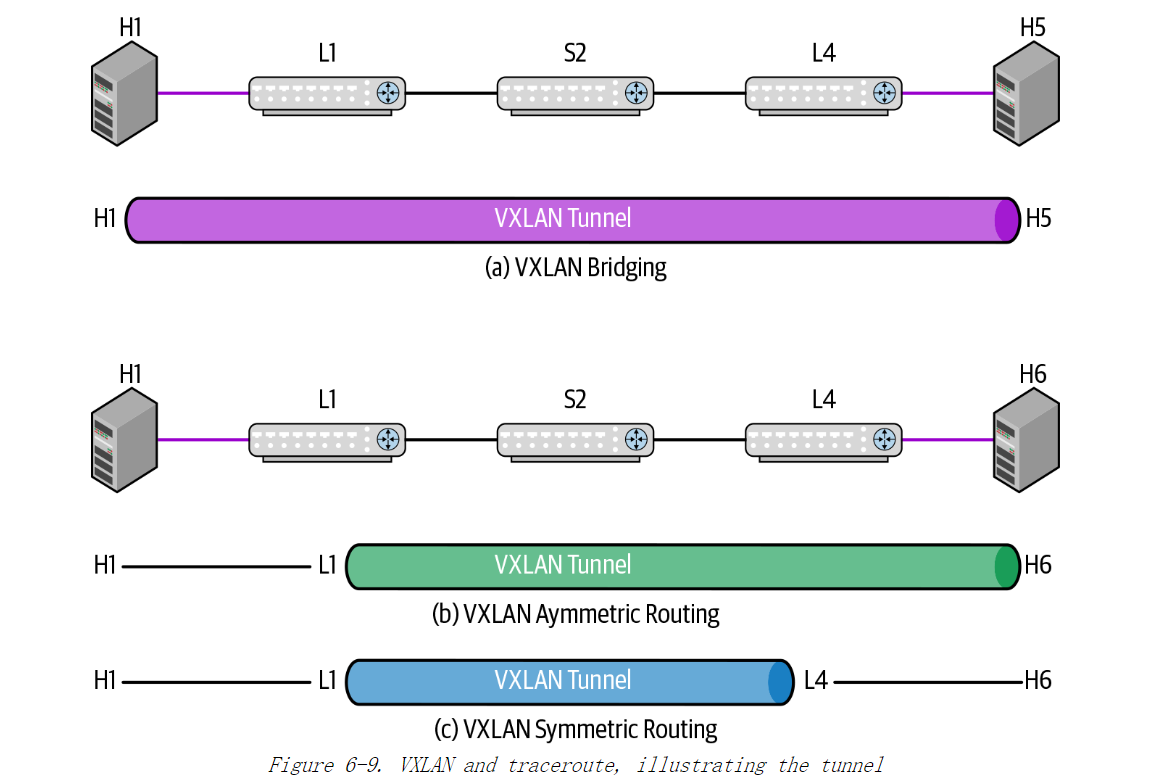
《Cloud Native Data Center Networking》(云原生数据中心网络设计)读书笔记 -- 05网络虚拟化
本章帮助网络工程师或架构师回答如下问题: 什么是网络虚拟化?网络虚拟化有哪些用途?网络虚拟化领域内有哪些不同的技术方向?网络虚拟化的控制面有哪些选择?当使用 VXLAN 时如何进行桥接和路由? 什么是网络虚拟化? 网络虚拟化可以让网络…...

奥威BI数据可视化展示:如何充分发挥数据价值
奥威BI数据可视化展示:如何充分发挥数据价值 在大数据时代,数据已成为企业最宝贵的资产之一。然而,仅仅拥有海量数据并不足以带来竞争优势,关键在于如何有效地挖掘、分析和展示这些数据,从而转化为有价值的洞察和决策…...

jenkins工具配置
上一篇(https://blog.csdn.net/abc666_666/article/details/141207741)文章我们介绍了基于docker安装jenkins的过程,本文将介绍如何配置jenkins的相关全局工具如maven、 jdk以及git等 配置的页面如下: 打开后的页面如下ÿ…...
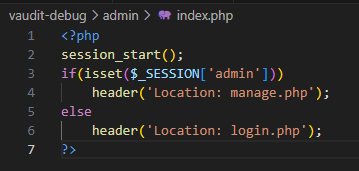
VAuditDemo文件漏洞
目录 VAuditDemo文件漏洞 一、首页文件包含漏洞 包含图片马 利用伪协议phar:// 构造shell.inc被压缩为shell.zip,然后更改shell.zip 为 shell.jpg上传 二、任意文件读取漏洞 avatar.php updateAvatar.php logCheck.php 任意文件读取漏洞利用 VAuditDemo文件…...
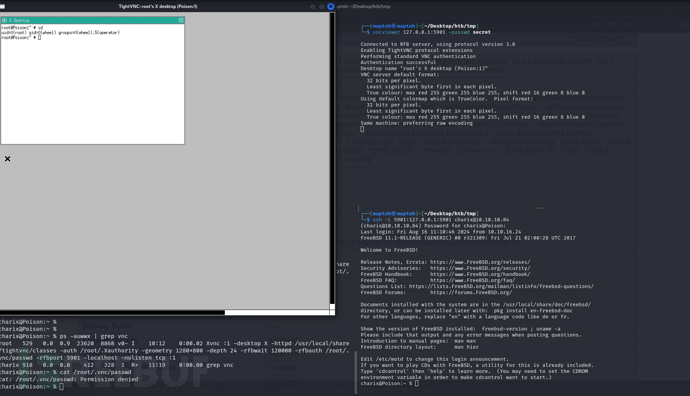
[Meachines] [Medium] poison LFI+日志投毒+VNC权限提升
信息收集 IP AddressOpening Ports10.10.10.84TCP:22,80 $ nmap -p- 10.10.10.84 --min-rate 1000 -sC -sV 22/tcp open ssh OpenSSH 7.2 (FreeBSD 20161230; protocol 2.0) | ssh-hostkey: | 2048 e3:3b:7d:3c:8f:4b:8c:f9:cd:7f:d2:3a:ce:2d:ff:bb (RSA) | 256 …...

EtherCAT运动控制器上位机开发之Python+Qt(三):PDO配置与SDO读写
ZMC408CE控制器硬件介绍 ZMC408CE是正运动推出的一款多轴高性能EtherCAT总线运动控制器,具有EtherCAT、EtherNET、RS232、CAN和U盘等通讯接口,ZMC系列运动控制器可应用于各种需要脱机或联机运行的场合。 ZMC408CE支持8轴运动控制,最多可扩展…...

【NotebookLM移动端避坑白皮书】:上线首月超12万用户踩中的3类权限陷阱与2种文档同步丢失根因分析
更多请点击: https://intelliparadigm.com 第一章:NotebookLM移动端避坑白皮书导论 NotebookLM 是 Google 推出的基于用户上传文档构建个性化 AI 助手的实验性工具,其移动端(iOS/Android)虽提供便捷访问入口ÿ…...

突然想写一些东西
---title: blogdate: 2026-05-15 02:18:57tags: ["chitchat"]about: 突然想写一些东西---马上毕业了,在写致谢的时候发现好像想写的东西挺多的,但是不知道怎么写出来了,可能是因为很久没写东西了?也可能是AI用多了自己深…...

高性能缓冲管理中的数组翻译技术解析
1. 高性能缓冲管理中的数组翻译技术解析在现代数据库系统中,缓冲管理器是连接内存与持久化存储的关键组件,其核心任务是将逻辑页ID映射到物理内存帧。传统方案如哈希表或指针交换存在三个根本性缺陷:内存开销随数据集线性增长、并行访问时的锁…...

低延时RS译码器优化设计【附代码】
✨ 长期致力于RS码、低延时、功耗优化、译码器研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)改进型RiBM迭代展开算法加速关键方程求解: …...

LinkSwift:九大网盘直链下载助手的终极技术解析与实践指南
LinkSwift:九大网盘直链下载助手的终极技术解析与实践指南 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / …...

免费Windows风扇控制神器:FanControl让你的电脑静音又凉爽
免费Windows风扇控制神器:FanControl让你的电脑静音又凉爽 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trendin…...

电路设计效率革命:Draw.io电子工程库的专业绘图方案
电路设计效率革命:Draw.io电子工程库的专业绘图方案 【免费下载链接】Draw-io-ECE Custom-made draw.io-shapes - in the form of an importable library - for drawing circuits and conceptual drawings in draw.io. 项目地址: https://gitcode.com/gh_mirrors/…...

Revelation光影包:物理渲染与启发式算法的视觉革命
Revelation光影包:物理渲染与启发式算法的视觉革命 【免费下载链接】Revelation An explorative shaderpack for Minecraft: Java Edition 项目地址: https://gitcode.com/gh_mirrors/re/Revelation Revelation不仅仅是一个Minecraft光影包——它是基于物理渲…...

开源灵巧手OpenClaw:从机械设计到AI抓取的完整实现指南
1. 项目概述:当开源机械爪遇上AI大脑 最近在机器人开源社区里,一个名为“OpenClaw”的项目引起了我的注意。这个由Turbo Labs团队发布的项目,其核心目标非常明确:打造一个低成本、高性能、且完全开源的机器人灵巧手(或…...

浏览器扩展开发实战:光标交互防火墙的设计与实现
1. 项目概述与核心价值最近在折腾浏览器插件开发,偶然在GitHub上看到了一个名为“Raidu Firewall Cursor Extension”的项目。光看这个名字,就让我这个对网络安全和效率工具都感兴趣的老码农眼前一亮。这玩意儿本质上是一个浏览器扩展,但它把…...