自然语言处理(NLP)大模型
自然语言处理(NLP)大模型
自然语言处理(NLP)领域中的一种重要技术,具有强大的语言理解和生成能力。以下是对NLP大模型的详细介绍:
一、定义与背景
NLP大模型是指通过大规模预训练和自监督学习技术构建的深度学习模型,旨在提高计算机对自然语言的理解和生成能力。这类模型通常具有数以亿计的参数,能够处理复杂的语言任务。其起源可以追溯到2017年,当时Google发布了Transformer模型,该模型为后续的NLP大模型发展奠定了基础。

二、自然语言处理(NLP)大模型的核心技术
涵盖了多个方面,这些技术共同推动了NLP领域的发展,使计算机能够更深入地理解和处理人类语言。以下是对NLP大模型核心技术的详细阐述:
1. 预训练技术
预训练是NLP大模型的重要基础,它通过在大规模语料库上进行训练,使模型学习到丰富的语言知识和上下文信息。这一过程极大地提高了模型的语言理解和生成能力。
大规模语料库:使用包含海量文本数据的语料库进行训练,确保模型能够接触到各种语言现象和表达方式。
自监督学习:通过自监督学习的方式,模型能够自动发现输入序列中的规律和模式,从而无需人工标注即可完成训练。
2. Transformer模型架构
Transformer模型是近年来NLP领域的一项重大突破,它采用自注意力机制(Self-Attention Mechanism)来处理文本数据,显著提高了模型的性能。
自注意力机制:使模型能够同时关注输入序列中的多个位置,捕捉序列内部的依赖关系。
编码器-解码器结构:Transformer模型由编码器和解码器两部分组成,编码器负责将输入序列转换成高维向量表示,解码器则根据这些向量表示生成输出序列。
3. 掩码语言模型(Masked Language Model, MLM)
掩码语言模型是一种预训练任务,它通过随机掩盖输入序列中的部分单词,然后要求模型预测这些被掩盖的单词。这种任务迫使模型在训练过程中学习上下文信息,从而提高其语言理解能力。
BERT模型:谷歌的BERT模型就是采用MLM任务的典型代表,它在多个NLP任务上取得了显著成效。
4. 多任务学习
NLP大模型通常被设计为能够处理多种NLP任务,通过多任务学习的方式,模型能够在不同任务之间共享知识,进一步提高其泛化能力。
GPT系列模型:OpenAI的GPT系列模型就是典型的例子,它们通过预训练学习到丰富的语言知识,然后可以通过微调(Fine-tuning)的方式适应不同的NLP任务。
5. 深度学习技术
NLP大模型利用深度学习技术,通过多层神经网络和大量的训练数据来学习语言的表示和生成。这种学习方式使得模型能够自动发现语言中的规律和模式,并用于处理各种NLP任务。
神经网络层数:随着技术的发展,NLP大模型的神经网络层数不断增加,从而能够捕捉更复杂的语言现象和语义信息。
训练数据规模:大规模的训练数据是深度学习模型取得成功的关键,NLP大模型通常需要在包含数十亿甚至数千亿个单词的语料库上进行训练。
6. 模型优化技术
为了提高NLP大模型的性能和效率,研究人员还开发了一系列模型优化技术。
参数共享:通过跨层参数共享来减少模型参数数量,提高训练速度和泛化能力。
注意力解耦机制:通过改进注意力机制来提高模型对复杂语言现象的处理能力。
增强的掩码解码器:在解码过程中引入掩码机制来提高模型的生成质量。
- 自然语言处理(NLP)大模型的原理
主要基于深度学习技术,特别是通过大规模预训练和自监督学习来提高模型的语言理解和生成能力。以下是NLP大模型原理的详细阐述:
一、预训练与自监督学习
预训练:NLP大模型在构建之初,会在大规模的无标注文本数据集上进行预训练。这个过程使模型能够学习到语言的通用表示和上下文信息,为后续的任务提供坚实的基础。预训练通常包括语言模型预测(如掩码语言模型MLM)等任务,通过这些任务,模型能够学习到语言的统计规律和结构特征。
自监督学习:在预训练过程中,模型不需要人工标注的数据,而是通过自动生成的监督信号进行学习。这种学习方式使模型能够充分利用大规模语料库中的信息,而无需依赖昂贵的人工标注成本。

二、Transformer模型架构
NLP大模型通常采用Transformer模型架构,该架构通过自注意力机制(Self-Attention Mechanism)来处理文本数据。Transformer模型由编码器和解码器两部分组成:
编码器:负责将输入序列转换成高维向量表示。编码器中的每一层都包含自注意力机制和前馈神经网络,通过多层堆叠,模型能够捕捉到文本中的长期依赖关系和上下文信息。
解码器:根据编码器的输出和已生成的序列来预测下一个单词。解码器也包含自注意力机制,但增加了对编码器输出的关注(Encoder-Decoder Attention),以便在生成过程中考虑到整个输入序列的信息。
三、多任务学习与迁移学习
NLP大模型通常被设计为能够处理多种NLP任务,通过多任务学习的方式,模型能够在不同任务之间共享知识,提高泛化能力。此外,预训练完成后的大模型可以通过迁移学习的方式,在特定任务上进行微调(Fine-tuning),以适应不同的应用场景和需求。
四、深度学习技术
NLP大模型利用了深度学习技术中的多层神经网络和大量的训练数据来学习语言的表示和生成。深度学习技术使模型能够自动发现语言中的规律和模式,而无需依赖人工设计的规则和特征。通过不断迭代和优化,模型能够不断提高其语言理解和生成能力。
五、应用场景与优势
NLP大模型具有广泛的应用场景,如文本分类、情感分析、问答系统、机器翻译、文本生成等。这些模型以其强大的语言理解和生成能力,为自然语言处理技术的发展和应用提供了强有力的支持。相比传统的NLP方法,NLP大模型具有更高的准确率和更好的泛化能力,能够更好地适应复杂多变的语言环境和任务需求。
四、自然语言处理(NLP)大模型的代表性模型
主要包括BERT系列和GPT系列。以下是这些代表性模型的详细介绍:
BERT系列
BERT(Bidirectional Encoder Representations from Transformers)
发布时间:由谷歌在2018年研究发布。
特点:BERT是一种基于Transformer的双向编码器表示学习模型。它通过预训练任务(如掩码语言模型和下一句预测)学习了大量的语言知识,并在多个NLP任务上刷新了记录。BERT的双向编码器结构使其能够同时考虑上下文信息,从而提高了模型的性能。
应用场景:BERT模型被广泛应用于各种NLP任务中,如文本分类、情感分析、问答系统等。Google搜索、Google文档、Google邮件辅助编写等应用都采用了BERT模型的文本预测能力。
GPT系列
GPT(Generative Pre-trained Transformer)
GPT-1:发布于2018年,是GPT系列的开山之作,参数规模为1.17亿。
GPT-2:发布于2019年,参数规模提升至15亿。GPT-2在文本翻译、QA问答、文章总结、文本生成等NLP任务上可以达到人类的水平,但其生成的文本在长度增加时可能会变得重复或无意义。
GPT-3:发布于2020年,参数规模达到惊人的1750亿,是迄今为止最大的NLP模型之一。GPT-3在自然语言处理方面的表现十分出色,可以完成文本自动补全、将网页描述转换为相应代码、模仿人类叙事等多种任务。此外,GPT-3还具备零样本学习的能力,即在没有进行监督训练的情况下,可以生成合理的文本结果。
GPT-4:发布于2023年,是一个大型多模态模型,支持图像和文本输入,再输出文本回复。GPT-4在多个专业和学术测试中表现出色,甚至在某些测试中达到了专业人士的水平。
其他代表性模型
除了BERT和GPT系列外,还有一些其他NLP大模型也值得关注,如:
RoBERTa:由Meta AI在2019年发布,基于BERT模型优化得到。RoBERTa通过改进掩码语言建模目标和训练过程,在多个NLP任务上取得了更好的性能。
ALBERT:谷歌在2020年初发布的BERT模型的精简版本,主要用于解决模型规模增加导致训练时间变慢的问题。ALBERT采用了参数简化方法,如因子嵌入和跨层参数共享,以提高模型的效率和性能。
XLNet:由CMU和Google Brain团队在2019年发布,是一种通用的自回归预训练方法。XLNet在多个NLP任务上超过了BERT的表现,并展示了其强大的性能。

- 自然语言处理(NLP)大模型在多个领域都有广泛的应用
这些应用不仅提高了工作效率,还促进了智能化和自动化的发展。以下是NLP大模型主要的应用领域:
1. 机器翻译
机器翻译是NLP大模型的一个重要应用领域。它利用计算机自动将一种语言的文本翻译成另一种语言,为全球化的沟通提供了极大的便利。例如,谷歌翻译和百度翻译等翻译工具就是使用机器翻译技术实现的。这些工具通过深度学习算法和大规模语料库的训练,能够实现高质量的翻译效果。
2. 语音识别
语音识别技术将人类的语音转换为计算机可理解的文本形式。这项技术在智能手机、智能音箱、自动语音识别系统等领域得到了广泛应用。例如,苹果的Siri、亚马逊的Alexa和Google Assistant等语音助手都使用了语音识别技术。这些系统通常使用深度学习技术,如循环神经网络(RNN)和长短时记忆网络(LSTM),来实现高精度的语音识别。
3. 文本分类
文本分类技术将文本分配到预定义的类别中。这项技术在垃圾邮件过滤、情感分析、主题分类等领域发挥着重要作用。通过机器学习算法和深度学习模型,如支持向量机(SVM)、朴素贝叶斯(Naive Bayes)、卷积神经网络(CNN)和循环神经网络(RNN),文本分类系统能够自动处理和分析大量文本数据,提高分类的准确性和效率。
4. 情感分析
情感分析技术用于识别和提取文本中的情感倾向。它在市场调查、产品评论分析、社交媒体监控等领域有着广泛的应用。通过分析文本中的词汇、短语和语气,情感分析系统能够判断文本所表达的情感是积极、消极还是中性,从而为企业决策提供有价值的信息。
5. 问答系统
问答系统是一种能够回答用户问题的计算机程序。在在线客服、智能助手、教育辅导等领域,问答系统发挥着重要作用。这些系统通常使用知识图谱、搜索引擎和机器学习算法来实现,能够准确理解用户的问题并给出相应的答案。例如,IBM的Watson和谷歌的Duplex都是问答系统的典型应用。
6. 聊天机器人
聊天机器人是一种能够与人类进行自然语言对话的计算机程序。它们被广泛应用于在线客服、社交媒体、教育辅导等领域。聊天机器人通过自然语言理解(NLU)和自然语言生成(NLG)技术实现与人类的对话,帮助企业提高客户满意度并降低人力成本。例如,微软的小冰和Facebook的M都是聊天机器人的典型应用。
7. 摘要生成
摘要生成技术将长篇文章或文档压缩成简短摘要。在新闻摘要、学术论文摘要、报告摘要等领域,摘要生成技术为用户提供了快速了解文章主要内容的便捷方式。通过机器学习算法,如提取式摘要和生成式摘要,摘要生成系统能够自动生成高质量的摘要。
8. 机器写作
机器写作利用计算机自动生成文本的过程。在新闻写作、报告生成、创意写作等领域,机器写作技术提高了写作效率并降低了人力成本。例如,路透社的News Tracer和Automated Insights的Wordsmith都是机器写作的典型应用。
9. 语音合成
语音合成技术将计算机生成的文本转换为语音信号。在语音助手、有声读物、电话客服等领域,语音合成技术为用户提供了更加便捷的信息获取方式。例如,谷歌的Text-to-Speech和亚马逊的Polly都是语音合成的典型应用。
10. 知识图谱
知识图谱是一种结构化的知识表示方法,用于存储和组织大量的实体和关系。在搜索引擎、推荐系统、问答系统等领域,知识图谱帮助计算机更好地理解文本中的实体和关系。例如,谷歌的知识图谱和Facebook的Graph Search都是知识图谱的典型应用。
六、自然语言处理(NLP)大模型的发展趋势与挑战
主要体现在以下几个方面:
发展趋势
技术深化与模型优化:
预训练语言模型的进步:从BERT、GPT系列到更先进的模型,预训练语言模型已成为NLP的主流。这些模型通过在大规模文本数据上预训练,能捕捉丰富的语言规律和知识,并在特定任务上进行微调,未来模型可能会有更深层次的理解能力和更广泛的知识覆盖。
多模态和跨模态学习:NLP开始与视觉和听觉等其他模态结合,进行多模态学习。例如,视觉问答(VQA)和图像字幕生成等任务需要模型同时理解文本和图像内容。跨模态学习在未来有望实现更自然的人机交互。
应用领域的拓展:
更多元化的应用场景:NLP大模型将不仅限于传统的文本处理任务,还将拓展到更多领域,如智能客服、机器翻译、文本分类、情感分析、问答系统、聊天机器人等。
行业深度融合:NLP技术将更深入地融入教育、医疗、金融、法律等行业,为这些行业提供智能化解决方案,提高工作效率和服务质量。
技术融合与创新:
与其他技术的结合:NLP将与机器学习、深度学习、图像识别等技术深度融合,进一步提升处理复杂语言任务的能力。
创新技术的引入:如小样本学习、元学习、可解释性增强等技术将推动NLP大模型在数据匮乏和模型透明度方面的改进。
挑战
数据质量与多样性:
数据收集的困难:大规模数据收集的困难和数据清洗的复杂性是NLP大模型面临的重要挑战。
数据多样性:确保数据多样性以避免模型偏见是另一个重要问题。需要开发更智能的数据收集和清洗工具,构建多样化的预训练语料库。
模型的可解释性与透明度:
模型决策过程的不透明性:随着模型变得越来越复杂,其决策过程变得难以解释。这可能导致用户对模型的不信任,并限制其在某些领域的应用。
提高可解释性:需要开发新的可视化技术、构建探测数据集以及研究基于注意力机制的解释方法,以提高模型的可解释性和透明度。
计算资源与能耗:
高昂的训练和部署成本:大规模语言模型的训练和部署需要巨大的计算资源和数据集,这导致高昂的成本。
能源消耗和环境影响:模型推理的实时性要求和能源消耗也是需要考虑的问题。需要开发更高效的训练算法和架构,研究模型压缩和知识蒸馏技术,以及探索低能耗的神经网络硬件。
数据隐私与安全:
隐私信息泄露风险:训练数据中的隐私信息泄露是一个严重的问题。需要研究联邦学习等隐私保护训练方法,确保数据的安全。
有害内容生成:模型可能被用于生成有害内容,如虚假信息、歧视性言论等。需要开发内容过滤和安全检查机制,增强模型对对抗性样本的鲁棒性。
模型偏见与伦理问题:
模型偏见:模型可能继承和放大训练数据中的偏见,导致生成内容的公平性和中立性受到质疑。需要开发偏见检测和缓解技术,构建多样化和平衡的训练数据集。
伦理边界定义:随着NLP技术的广泛应用,需要制定AI伦理准则和监管框架,明确模型使用的伦理边界。
综上所述,NLP大模型在发展过程中既面临诸多挑战,也展现出广阔的发展前景。通过不断的技术创新、跨学科合作以及解决伦理和社会问题,我们有望推动NLP大模型向更加智能化、高效化和安全化的方向发展。
相关文章:
自然语言处理(NLP)大模型
自然语言处理(NLP)大模型 自然语言处理(NLP)领域中的一种重要技术,具有强大的语言理解和生成能力。以下是对NLP大模型的详细介绍: 一、定义与背景 NLP大模型是指通过大规模预训练和自监督学习技术构建的…...

融合创新趋势:Web3时代的跨界融合
随着互联网技术的飞速发展,Web3时代的到来正引领着一场深刻的技术与社会变革。Web3,作为下一代互联网技术的代表,不仅仅是一种技术创新,更是一种跨界融合的趋势。通过去中心化、智能合约和区块链技术的应用,Web3正在重…...

面临新时代的机遇与挑战,联想凌拓将如何破局?
近年来,IT行业的技术进步日新月异,云计算、大数据、人工智能……各种新兴技术犹如雨后春笋般层出不穷,并且正在给千行百业带来全面的变革甚至重塑。 然而以上提到的所有新兴技术,都离不开数据的存储与管理。那么作为中国乃至全球领…...

2024.8.21
作业: 运行1个服务器和2个客户端 实现效果: 服务器和2个客户端互相聊天,服务器和客户端都需要使用select模型去实现 服务器要监视2个客户端是否连接,2个客户端是否发来消息以及服务器自己的标准输入流 客户端要监视服务器是否发来…...

在Ubuntu16.04里安装ROS Kinetic
1.设置apt的source list sudo sh -c echo "deb http://packages.ros.org/ros/ubuntu$(lsb_release -sc) main" > /etc/apt/sources.list.d/ros-latest.list 2.设置gpd keys sudo apt-key adv --keyserver hkp://ha.pool.sks-keyservers.net:80 --recv-key 421C365…...
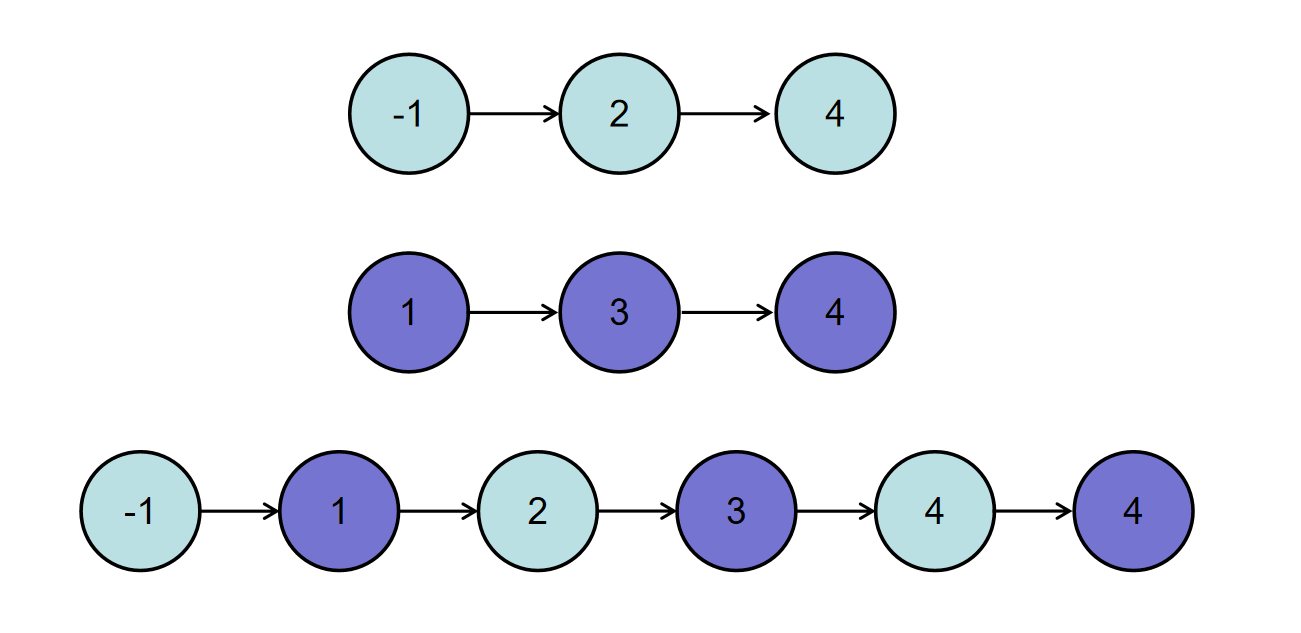
后端开发刷题 | 合并两个排序的链表
描述 输入两个递增的链表,单个链表的长度为n,合并这两个链表并使新链表中的节点仍然是递增排序的。 数据范围: 0≤n≤1000,−1000≤节点值≤1000 如输入{1,3,5},{2,4,6}时,合并后的链表为{1,2,3,4,5,6},…...

JAVA_7
JAVA_7 JAVA面向对象编程1. 抽象方法和抽象类 JAVA面向对象编程 1. 抽象方法和抽象类 使用abstract修饰的方法,没有方法体,只有声明。定义的是一种“规范”,就是告诉子类必须要给抽象方法提供具体的实现。包含抽象方法的类就是抽象类。通过…...
)
最大连续1的个数 III(LeetCode)
题目 给定一个二进制数组 nums 和一个整数 k,如果可以翻转最多 k 个 0 ,则返回 数组中连续 1 的最大个数 。 解题 def longestOnes(nums, k):left 0max_len 0zero_count 0for right in range(len(nums)):# 如果遇到0,统计当前窗口内0的个…...

Vue之前端批量下载文件并以压缩包形式存储
后端返回一个文件链接的数组,前端处理下载逻辑,并且将这些文件存储在压缩包内部,这用的jszip 和 file-saver 这两个库。 步骤说明 1.使用 npm 或 yarn 安装 jszip 和 file-saver。 npm install jszip file-saver 2.获取文件内容:…...

【AI学习】LLaMA模型的微调成本有几何?
在前面文章《LLaMA 系列模型的进化(二)》中提到了Stanford Alpaca模型。 Stanford Alpaca 基于LLaMA (7B) 进行微调,通过使用 Self-Instruct 方法借助大语言模型进行自动化的指令生成,Stanford Alpaca 生成了 52K 条指令遵循样例数…...

【专题】2024全数驱动 致胜未来-数字化敏捷银行白皮书报告合集PDF分享(附原数据表)
原文链接: https://tecdat.cn/?p37404 政策明确发展使命,新时代商业银行应坚持党建引领,秉持高质量发展理念。数字经济已成大势,商业银行需构建数字基础设施能力,强化顶层战略规划。当前商业银行数字化发展面临诸多挑…...

280Hz显示器哪家强
280Hz显示器哪家强?今天就给大家带来6大品牌和型号的280Hz显示器一起对比对比! 1.280Hz显示器 - HKC G27H3显示器 HKC G27H3是一款高性价比的电竞显示器,以下是它的一些特点: - **高刷新率与快速响应**: - 拥有280H…...

ROUTE_STATUS
ROUTE_STATUS是一个只读属性,由Vivado路由器分配给网络 反映网络上路由的当前状态。 该属性可以由单个网络或一组网络使用 get_property或report_property命令。该物业由 report_route_status命令返回整个设计的route_status。 架构支持 所有架构。 适用对象 •网络…...
 yuyv(yuv422)、MJPEG、H.264)
v4l2(video4linux2) yuyv(yuv422)、MJPEG、H.264
V4L2(Video4Linux2)是Linux内核中的视频设备接口框架,专门用于捕获和输出视频数据。V4L2广泛应用于各种视频设备的驱动程序开发,如网络摄像头、电视调谐器、视频采集卡、以及其他视频输入/输出设备。 ### V4L2的主要功能 1. **视…...

.Net插件开发开源框架
在.NET开发中,有许多开源框架可以用于插件开发,以下是一些最常见的框架: MEF(Managed Extensibility Framework) MEF是一个用于创建可插拔软件应用程序的库,它可以在不修改原始应用程序的情况下扩展应用程…...

基于Spark实现大数据量的Node2Vec
基于Spark实现大数据量的Node2Vec Node2Vec 是一种基于图的学习算法,用于生成图中节点的低维度、高质量的向量表示。这种算法基于 word2vec 模型,将自然语言处理中的词嵌入技术应用于图结构的节点,以捕捉节点之间的复杂关系。Node2Vec 特别强…...

[VMware]VMware-Esxi 6.7 厚置备转为精简置备
背景:创建了一个win10 60G的厚置备磁盘,现在想改为精简置备。 先关闭win10系统,并删除快照 1、开启shell 2、登录到虚拟存放的目录 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 [rootxxx:~] cd /vmfs/volumes/5fea055e-458157d3-c8f8-8cec4ba51c4…...

vue面试题十八
一、Vue 3中的样式绑定有哪些新特性? Vue 3中的样式绑定保持了与Vue 2相似的灵活性和强大功能,同时引入了一些新的特性和改进,主要集中在响应式系统和Composition API上。以下是Vue 3中样式绑定的主要新特性及其说明: 1. 响应式…...
)
windows C++-windows C++/CX简介(三)
^类型 (^) 是 C/CX 最突出的功能之一——当人们第一次看到 C/CX 代码时,很难不注意到它。那么,^ 类型到底是什么?这是类型是一种智能指针类型,它自动管理 Windows 运行时对象的生命周期,也 提供自动类型转换功能以简化…...

《黑神话.悟空》:一场跨越神话与现实的深度探索
《黑神话.悟空》:一场跨越神话与现实的深度探索 在国产游戏日益崛起的今天,《黑神话.悟空》以其独特的剧情、丰富的人物设定和深刻的主题,成为了无数玩家翘首以盼的国产3A大作。这款游戏不仅是一次对传统故事的创新演绎,更是一场对…...

如何在10分钟内搭建AI与Figma双向通信系统:TalkToFigma MCP完整指南
如何在10分钟内搭建AI与Figma双向通信系统:TalkToFigma MCP完整指南 【免费下载链接】cursor-talk-to-figma-mcp TalkToFigma: MCP integration between AI Agent (Cursor, Claude Code) and Figma, allowing Agentic AI to communicate with Figma for reading des…...

PromethAI-Backend:构建标准化AI智能体后端框架的工程实践
1. 项目概述与核心价值最近在折腾AI应用开发,特别是想搞一个能处理复杂工作流的智能体系统,发现了一个挺有意思的开源项目——PromethAI-Backend。这名字听着就有点“普罗米修斯”盗火种给人类的意思,挺形象的,它本质上就是一个为…...

从标注工具到AI流水线:在Windows上搭建CVAT,并连接Label Studio与Jupyter Notebook
从标注工具到AI流水线:在Windows上构建CVAT与生态工具的协同工作流 当计算机视觉项目从实验室走向生产环境时,数据标注往往成为制约迭代速度的关键瓶颈。传统孤立使用的标注工具如同信息孤岛,而现代MLOps实践需要的是能够无缝衔接数据标注、质…...

手机上的Linux:用Termux 0.118.0打造Python 3.10.4爬虫环境,实测下载‘拷贝漫画’全流程
在安卓手机上构建Python爬虫环境:Termux实战指南 你是否遇到过这样的场景:在地铁上突然想到一个绝妙的爬虫点子,但手边只有一部手机?或者想在平板上直接下载漫画却苦于没有合适的工具?Termux正是解决这些痛点的神器。这…...

基于MCP协议构建AI智能体记忆系统:mnemo-mcp实战指南
1. 项目概述:一个为AI记忆而生的开源工具最近在折腾AI应用开发,特别是围绕大语言模型(LLM)构建智能体(Agent)时,一个绕不开的痛点就是“记忆”。模型本身没有持久化记忆,每次对话都是…...

openclaw-route-check:多协议路由诊断工具的原理、安装与实战应用
1. 项目概述与核心价值最近在折腾一些需要跨地域、跨网络环境访问的服务时,路由问题总是最让人头疼的环节。你可能也遇到过类似情况:明明服务部署在A地,从B地访问时延迟高得离谱,或者干脆时通时不通,排查起来像大海捞针…...

别再手动对比了!用Beyond Compare 4在Ubuntu上5分钟搞定文件同步与合并
高效文件管理利器:Beyond Compare 4在Ubuntu中的深度应用指南 在当今快节奏的开发与运维工作中,文件比较与同步已成为日常工作中不可或缺的环节。无论是代码合并、配置同步还是日志分析,传统的手动对比方式不仅效率低下,还容易出错…...
)
用HFSS仿真一个简单的波导:不只是S参数,教你如何动态可视化电场分布(Animate功能详解)
HFSS波导仿真进阶:从S参数到电场动态可视化的深度解析 1. 理解波导仿真中的场可视化价值 在微波工程领域,仿真工具的价值不仅在于获取S参数这样的量化指标,更在于揭示电磁场在结构中的真实分布与动态行为。HFSS作为行业标准的全波电磁仿真软件…...

【C/C++】libusb实战:从零构建ADB USB通信框架
1. 为什么需要自己实现ADB USB通信? 很多开发者第一次接触ADB时,都是直接使用官方提供的adb命令行工具。这个工具确实方便,但当你需要深度定制Android设备调试流程,或者开发自动化测试框架时,官方工具就显得不够灵活了…...

JetBrains IDE试用期重置终极指南:如何免费获得30天完整试用期
JetBrains IDE试用期重置终极指南:如何免费获得30天完整试用期 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 你是否正在使用JetBrains IDE进行开发,却面临试用期到期的困扰?无…...