CMU 10423 Generative AI:lec2
文章目录
- 1 概述
- 2 部分摘录
- 2.1 噪声信道模型(Noisy Channel Models)
- 主要内容:
- 公式解释:
- 应用举例:
- 2.2 n-Gram模型
- 1. 什么是n-Gram模型
- 2. 早期的n-Gram模型
- 3. Google n-Gram项目
- 4. 模型规模与训练数据
- 5. n-Gram模型的局限性
- 总结
- 2.3 当今前沿大模型的训练数据量和参数量
- 2.4 计算图的概念
- 1. 计算图(Computation Graph)简介
- 2. 图中各部分的详细解释
- 3. 计算图的要点
- 总结:
- 2.5 Deep BiLSTM 长什么样、LSTM系列变种问题
- 2.6 为什么transformer中需要加入位置编码?
- 解释:
- 关键点:
- 2.7 关于 GPT3 的模型结构和参数
- 3 阅读材料(LSTM, transformer, 讲解博客)
1 概述
该文件主要介绍了Transformer语言模型的背景、架构以及与其他语言模型的对比。以下是主要内容的概述:
- 语言模型的历史:文件首先介绍了在2017年之前使用的噪声信道模型在语音识别和机器翻译中的应用。这些模型通过结合转导模型和语言模型来进行预测。
- 大规模语言模型的发展:讨论了早期的n-Gram语言模型,如Google n-Gram模型,这些模型基于网页文本进行训练,并覆盖多种语言。接着,文件还对比了近年来的一些大规模语言模型(LLMs),如GPT-2、GPT-3、PaLM等。
- 递归神经网络(RNNs)及其局限性:介绍了RNN语言模型的基本概念,并讨论了RNN在学习长距离依赖时的困难。
- 长短期记忆网络(LSTM):详细解释了LSTM如何通过其内部结构(如输入门、遗忘门、输出门等)克服RNN的梯度消失问题,并帮助记忆长时间步的信息。
- 双向LSTM(BLSTM):讲述了将LSTM与双向RNN结合形成的深度双向LSTM(DBLSTM)如何用于处理更复杂的任务。
- Transformer语言模型:文件详细介绍了Transformer模型的架构,包括多头注意力机制、前馈神经网络、层归一化、残差连接等。
- 模型实现细节:文件还包括了Transformer模型的实现细节,展示了矩阵版本的单头注意力机制等。
2 部分摘录
2.1 噪声信道模型(Noisy Channel Models)

主要内容:
- 噪声信道模型的背景:
-
在2017年之前,语言模型被广泛应用于两个主要任务:语音识别和机器翻译。
-
在这些任务中,噪声信道模型是一种重要的工具。
-
噪声信道模型的定义:
- 噪声信道模型结合了一个转导模型(transduction model)和一个语言模型(language model)。
- 转导模型的作用是计算将输出y转化为输入x的概率,而语言模型则计算y的概率。
-
噪声信道模型的目标:
- 该模型的目标是从输入x中恢复出最可能的输出y。
- 对于语音识别,x是声学信号,y是相应的转录文本。
- 对于机器翻译,x是源语言中的句子,y是目标语言中的句子。
公式解释:
公式表示的内容是从x推断出最可能的y值。这是通过找到使得( p(y | x) )最大化的y值来实现的。在噪声信道模型中,这一过程被分解为两个部分:首先是计算给定y生成x的概率( p(x | y) )(即转导模型),然后是计算y本身的概率( p(y) )(即语言模型)。最终的目标是找到使得这两个概率的乘积最大的y值。
应用举例:
- 语音识别:模型的输入是声学信号(x),目标是找出最有可能的文本转录(y)。
- 机器翻译:模型的输入是源语言的句子(x),目标是找出最有可能的目标语言翻译(y)。
这种方法为早期的语音识别和机器翻译任务奠定了基础,并在这些领域中得到了广泛应用。
2.2 n-Gram模型

“Large (n-Gram) Language Models” 部分主要介绍了早期的大规模n-Gram语言模型的发展与应用。以下是详细介绍:
1. 什么是n-Gram模型
n-Gram模型是一种通过统计方法预测下一个词出现概率的语言模型。它基于这样一个假设:一个词的出现概率只取决于前面n-1个词。例如,三元组模型(trigram)就是基于前两个词预测下一个词的出现概率。
2. 早期的n-Gram模型
早期的大型语言模型使用的是n-Gram模型,其中最具代表性的是Google的n-Gram模型。这些模型通过分析大量的文本数据来统计词序列的频率,并由此预测词的出现概率。
3. Google n-Gram项目
- 第一次发布 (2006年): Google发布了首个英语n-Gram数据集,训练数据来自于1万亿个token(词或词的单位),涵盖了95亿个句子。该模型包含了1-gram(单词)、2-gram(双词组)、3-gram(三词组)、4-gram(四词组)和5-gram(五词组)。
- 扩展至其他语言 (2009-2010年): 随后,Google将n-Gram模型扩展至其他语言,包括日语、中文、瑞典语、西班牙语、罗马尼亚语、葡萄牙语、波兰语、荷兰语、意大利语、法语、德语和捷克语。
4. 模型规模与训练数据
- 模型规模: 英语n-Gram模型的参数量约为30亿个。与现代的大型语言模型相比,这样的规模已经非常庞大。
- 训练数据的规模: 模型的训练数据包括了1万亿个token和95亿个句子,这样的大数据量为n-Gram模型的预测提供了强大的支持。
5. n-Gram模型的局限性
尽管n-Gram模型在其时代取得了重要的成功,但其也存在一定的局限性:
- 上下文限制: n-Gram模型只能考虑有限个(n-1)前缀词,这使得它无法捕捉长距离的依赖关系。
- 数据稀疏性: 随着n的增大,模型的参数量迅速增加,导致模型容易遇到数据稀疏问题,因为许多n-gram可能在训练数据中很少甚至从未出现过。
总结
n-Gram语言模型是早期自然语言处理中的重要工具,它通过统计词序列的出现频率来预测文本。然而,随着计算能力的提高和更复杂模型的出现,如基于深度学习的Transformer模型,n-Gram模型的应用逐渐减少,但它为语言模型的发展奠定了基础。
2.3 当今前沿大模型的训练数据量和参数量
| 模型名称 | 开发者 | 发布年份 | 训练数据(# Tokens) | 模型规模(# 参数量) |
|---|---|---|---|---|
| GPT-2 | OpenAI | 2019 | ~10 billion (40GB) | 1.5 billion |
| GPT-3 (ChatGPT) | OpenAI | 2020 | 300 billion | 175 billion(1750亿) |
| PaLM | 2022 | 780 billion | 540 billion | |
| Chinchilla | DeepMind | 2022 | 1.4 trillion | 70 billion |
| LaMDA (Bard) | 2022 | 1.56 trillion | 137 billion | |
| LLaMA | Meta | 2023 | 1.4 trillion | 65 billion |
| LLaMA-2 | Meta | 2023 | 2 trillion(2万亿) | 70 billion |
| GPT-4 | OpenAI | 2023 | ? | ? |
2.4 计算图的概念

这张图片展示了如何绘制神经网络的计算图(Computation Graph)以及计算图的一些基本原则和元素。下面详细解释每个部分的含义:
1. 计算图(Computation Graph)简介
计算图是用来表示算法的图形化工具。在计算图中:
- 节点(Nodes):表示算法中的中间变量。节点在图中通常用矩形表示。
- 边(Edges):表示变量之间的依赖关系,边是有方向的,指向依赖项。
- 无标签的边:在计算图中,边通常不需要标签,因为边的方向已经表明了依赖关系。
2. 图中各部分的详细解释
- (A) Input: 这一部分表示输入层。每个输入变量 (x_i) 被表示为节点。图中也指出,每个输入参数 (\alpha_{ij}) 也需要在图中表示出来。
- (B) Hidden (linear): 这一层表示神经网络中的隐藏层的线性部分。计算公式为 (a_j = \sum_{i=0}^{M} \alpha_{ji} x_i),这表示每个隐藏层的节点 (a_j) 是输入 (x_i) 的线性组合。
- © Hidden (sigmoid): 隐藏层的非线性部分,使用sigmoid函数。公式为 (z_j = \frac{1}{1 + \exp(-a_j)})。这一步是将线性组合后的结果通过激活函数(如sigmoid)转换。
- (D) Output (linear): 输出层的线性部分,计算公式为 (b = \sum_{j=0}^{D} \beta_j z_j),即对隐藏层的输出再做一次线性组合。
- (E) Output (sigmoid): 最终输出结果通过sigmoid函数转换,公式为 (y = \frac{1}{1 + \exp(-b)})。
- (F) Loss: 损失函数 (J = \frac{1}{2} (y - y*)2) 用于衡量模型输出 (y) 与真实值 (y^*) 之间的误差。
3. 计算图的要点
- 拦截项作为节点:在神经网络中,每个拦截项(bias)都应被表示为一个节点,除非它已被整合进其他部分。
- 每个参数都应在图中表示:这确保了计算图的完整性和清晰性。
- 常数、标签等应在图中表示:例如,真实标签 ( y^* ) 应在图中作为节点出现。
- 可以包含损失节点:将损失函数作为图的一部分是完全可以的。
总结:
通过计算图,能够直观地理解数据如何在网络中流动,以及如何通过每一层的计算得到最终的输出。这种图示法对于理解复杂的神经网络模型非常有帮助,尤其是在进行反向传播和梯度计算时。
2.5 Deep BiLSTM 长什么样、LSTM系列变种问题
相比BiLSTM大概就是多个跳跃连接,感觉有点类似残差,防止梯度消失。

LSTM系列变种问题:
- 他们仍然在处理长距离依赖方面存在困难。
- 他们的计算本质上是串行的,因此无法轻松地在GPU上并行化。
- 尽管他们(大多数情况下)解决了梯度消失问题,但仍可能会遭遇梯度爆炸的困扰。
2.6 为什么transformer中需要加入位置编码?
一句话总结:注意力机制无法捕捉到词序信息,而词序蕴含的信息很重大,因此需要通过额外的位置编码将位置信息融入到词嵌入编码中。

位置嵌入(Position Embeddings)
- 问题:由于注意力机制是位置不变的,因此我们需要一种方法来学习关于位置的信息。
- 解决方案:使用(或学习)一组特定于位置的嵌入:( p_t ) 表示在位置 ( t ) 处的含义。将其与词嵌入 ( w_t ) 相加。关键思想是,每个出现在位置 ( t ) 的词都使用相同的位置嵌入 ( p_t )。
- 位置嵌入有多种形式:
- 一些是固定的(基于正弦和余弦),而另一些是学习到的(类似于词嵌入)。
- 一些是绝对的(如上所述),但我们也可以使用相对位置嵌入(即相对于查询向量的位置)。
注释:
- ( P_1 \neq P_3 )(位置1的嵌入不等于位置3的嵌入)。
- ( W_1 = W_3 )(词“cat”的嵌入在两个位置上是相同的)。
解释:
这张图和文本介绍了在Transformer模型中使用的位置嵌入(Position Embeddings)。在Transformer架构中,注意力机制本身是位置不变的,这意味着它不会直接考虑词语在句子中的顺序。然而,句子中的词语顺序在理解语义时是非常重要的。因此,引入了位置嵌入来弥补这一点。
关键点:
- 位置嵌入的必要性:
-
由于注意力机制不考虑词语的顺序,因此引入位置嵌入来为每个词语添加位置信息,以便模型能够区分同一个词在不同位置上的不同含义。
-
如何实现:
- 每个位置 ( t ) 都有一个对应的位置嵌入 ( p_t ),它表示该位置的特定含义。该位置嵌入与词嵌入 ( w_t ) 相加,形成包含位置信息的输入向量。这样,模型就可以在处理时保留位置信息。
-
位置嵌入的种类:
- 固定位置嵌入:这些位置嵌入通常基于正弦和余弦函数生成,不随训练过程变化。
- 学习位置嵌入:类似于词嵌入,通过训练过程动态学习和调整。
- 绝对位置嵌入:表示词语的具体位置(如第一个词、第二个词)。
- 相对位置嵌入:表示一个词相对于另一个词的位置关系。
-
示例解释:
- 在图中,词语“Cat”和“saw”在不同的位置上分别有其位置嵌入 ( p_1, p_2 ),并与词嵌入 ( w_1, w_2 ) 相加,以便模型知道“Cat”和“saw”分别出现在句子的什么位置。
- 在例子中,尽管“Cat”在两个不同的位置上出现(位置1和位置3),它的词嵌入 ( W_1 ) 和 ( W_3 ) 是相同的,但其位置嵌入 ( P_1 ) 和 ( P_3 ) 不同,从而帮助模型区分它们在句子中的不同角色。
通过位置嵌入,Transformer模型能够更好地理解词语的顺序和语境,从而提升对序列数据的处理能力。
2.7 关于 GPT3 的模型结构和参数
GPT的全称:Generative Pre-trained Transformer,即生成式预训练变换模型。
核心思想:GPT本质上是一个基于Transformer架构的语言模型(LM),其特别之处在于拥有大量的参数。
| 属性/版本 | 解释 | GPT (2018) | GPT-2 (2019) | GPT-3 (2020) |
|---|---|---|---|---|
| 层数 | Transformer的层数(# layers)。表示模型的深度,层数越多,模型能捕捉到的特征越复杂。 | 12 | 48 | 96 |
| 状态维度 | 每层Transformer的输出向量维度(dimension of states)。更高的维度允许模型捕捉更丰富的信息。 | 768 | 1600 | 12288 |
| 内部状态维度 | 前馈神经网络(FFN)的中间层维度(dimension of inner states)。通常是状态维度的4倍,用于增强非线性能力。 | 3072 | – | 4*12288 |
| 注意力头数量 | 多头自注意力机制中的头的数量(# attention heads)。更多的注意力头可以捕捉更多的序列特征。 | 12 | – | 96 |
| 参数数量 | 模型中的总参数数量(# params)。包括所有可训练的权重和偏置,参数数量越大,模型的表达能力越强。 | 117M | 1542M | 175000M |
3 阅读材料(LSTM, transformer, 讲解博客)
- The Long Short-Term Memory and Other GatedRNNs. Ian Goodfellow, Yoshua Bengio, & Aaron Courville (2016). Deep Learning, Chapter 10.10-10.12.
- Attention Is All You Need. Vaswani et al. (2017). NeurIPS.
- The Illustrated Transformer. Alammar (2018).
第一个就是花书中的LSTM及其变种部分。
第二个就是鼎鼎大名的XXX is all you need原论文。
第三个是广泛被国内转载并引用原图的某位国外作者撰写的讲解Transformer论文的博文。(有十几个语种的翻译版。。。)
原版地址:https://jalammar.github.io/illustrated-transformer/
中文版1:https://blog.csdn.net/yujianmin1990/article/details/85221271
中文版2:https://blog.csdn.net/qq_36667170/article/details/124359818
相关文章:
CMU 10423 Generative AI:lec2
文章目录 1 概述2 部分摘录2.1 噪声信道模型(Noisy Channel Models)主要内容:公式解释:应用举例: 2.2 n-Gram模型1. 什么是n-Gram模型2. 早期的n-Gram模型3. Google n-Gram项目4. 模型规模与训练数据5. n-Gram模型的局…...

恋爱相亲交友系统源码原生源码可二次开发APP 小程序 H5,web全适配
直播互动:平台设有专门的直播间,允许房间主人与其他异性用户通过视频连线的方式进行一对一互动。语音视频交流:异性用户可以发起语音或视频通话,以增进了解和交流。群组聊天:用户能够创建群聊,邀请自己关注…...
OceanBase 4.x 存储引擎解析:如何让历史库场景成本降低50%+
据国际数据公司(IDC)的报告显示,预计到2025年,全球范围内每天将产生高达180ZB的庞大数据量,这一趋势预示着企业将面临着更加严峻的海量数据处理挑战。随着数据日渐庞大,一些存储系统会出现诸如存储空间扩展…...

js 如何写构造函数 ,构造函数和普通函数有什么区别
在 JavaScript 中,构造函数是一种特殊的函数,用于初始化一个新创建的对象。构造函数通常用来创建具有相似属性和方法的对象实例。构造函数的主要特点是在调用时使用 new 关键字,这样就会创建一个新对象,并将其原型设置为构造函数的…...

MySQL-进阶篇-锁(全局锁、表级锁、行级锁)
文章目录 1. 锁概述2. 全局锁2.1 介绍2.2 数据备份2.3 使用全局锁造成的问题 3. 表级锁3.1 表锁3.1.1 语法3.1.2 读锁3.1.3 写锁3.1.4 读锁和写锁的区别 3.2 元数据锁(Meta Data Lock,MDL)3.3 意向锁3.3.1 案例引入3.3.2 意向锁的分类 4. 行级…...
多种实现方式及最优比较)
c++懒汉式单例模式(Singleton)多种实现方式及最优比较
前言 关于C懒汉式单例模式的写法,大家都很熟悉。早期的设计模式中有代码示例。比如: class Singleton {private: static Singleton *instance;public: static Singleton *getInstance() {if (NULL instance)instance new Singleton();return instanc…...

Gartner《2024中国安全技术成熟度曲线》AI安全助手代表性产品:开发者安全助手D10
海云安关注到,近日,国际权威研究机构Gartner发布了《2024中国安全技术成熟度曲线》(Hype Cycle for Security in China,2024)报告。 在此次报告中,安全技术成熟度曲线将安全周期划分为技术萌芽期(Innovation Trigger)…...

奇安信椒图--服务器安全管理系统(云锁)
奇安信椒图–服务器安全管理系统(云锁) 椒图 奇安信服务器安全管理系统是一款符合Gartner定义的CWPP(云工作负载保护平台)标准、EDR(终端检测与响应)、EPP终端保护平台(终端保护平台ÿ…...

pointer-events,添加水印的一个小小点
场景:平平无奇一个水印图,这类功能实现:就是覆盖在整个可视div后,又加了一个div(使用定位canvas画一个水印图充当背景),可时我好奇的是,我使用控制台,选择对应的元素时&a…...

微服务--认识微服务
微服务架构的演变 1. 单体架构(Monolithic) 阶段描述:在单体应用时代,整个应用程序被设计为一个项目,并在一个进程内运行。这种架构方式开发简单,便于集中管理,但随着应用的复杂化,…...

【docker】docker 镜像仓库的管理
Docker 仓库( Docker Registry ) 是用于存储和分发 Docker 镜像的集中式存储库。 它就像是一个大型的镜像仓库,开发者可以将自己创建的 Docker 镜像推送到仓库中,也可以从仓库中拉取所需的镜像。 Docker 仓库可以分为公共仓…...
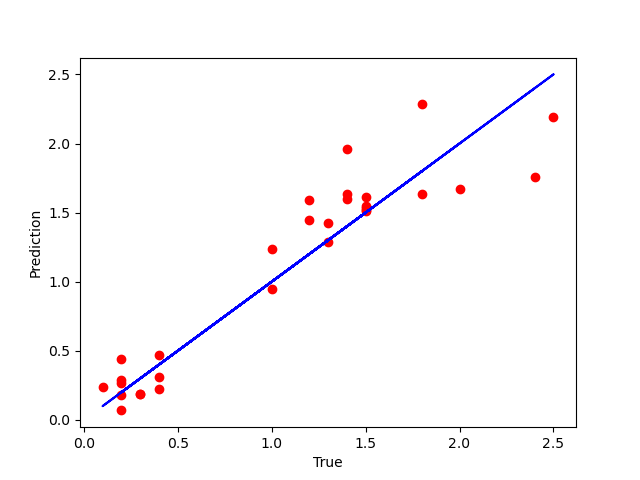
第L2周:机器学习-线性回归
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 目标: 学习简单线性回归模型和多元线性回归模型通过代码实现:通过鸢尾花花瓣长度预测花瓣宽度 具体实现: (一&…...

SpringMVC拦截器深度解析与实战
引言 Spring MVC作为Spring框架的核心模块之一,主要用于构建Web应用程序和RESTful服务。在Spring MVC中,拦截器(Interceptor)是一种强大的机制,它允许开发者在请求处理流程的特定点插入自定义代码,实现诸如…...

直线上最多的点数
优质博文:IT-BLOG-CN 题目 给你一个数组points,其中points[i] [xi, yi]表示X-Y平面上的一个点。求最多有多少个点在同一条直线上。 示例 1: 输入:points [[1,1],[2,2],[3,3]] 输出:3 示例 2: 输入&am…...

经济管理专业数据库介绍
本文介绍了四个经济管理专业数据库:国研网全文数据库、EPS数据平台、中经网、Emerald全文期刊库(管理学)。 一、国研网全文数据库 国研网是国务院发展研究中心主管、北京国研网信息有限公司承办的大型经济类专业网站。国研网教育版”是国研…...

【C++ Primer Plus习题】11.1
问题: 解答: main.cpp #include <iostream> #include <fstream> #include "Vector.h" #include <time.h> using namespace std; using namespace VECTOR;int main() {ofstream fout;fout.open("randwalk.txt");srand(time(0));double d…...

[数据库][oracle]ORACLE EXP/IMP的使用详解
导入/导出是ORACLE幸存的最古老的两个命令行工具,其实我从来不认为Exp/Imp是一种好的备份方式,正确的说法是Exp/Imp只能是一个好的转储工具,特别是在小型数据库的转储,表空间的迁移,表的抽取,检测逻辑和物理…...

中国各银行流动性比例数据(2000-2022年)
介绍中国银行业2000年至2022年间的流动性比例数据,涵盖500多家银行,包括城市商业银行、城镇银行、大型商业银行、股份制银行、民营银行、农村合作银行、农村商业银行、农村信用社等。这些数据对于理解中国银行业的流动性状况至关重要,有助于投…...

MACOS安装配置前端开发环境
官网下载安装Mac版本的谷歌浏览器以及VS code代码编辑器,还有在App Store中直接安装Xcode(里面自带git); node.js版本管理器nvm的下载安装如下: 参考B站:https://www.bilibili.com/video/BV1M54y1N7fx/?sp…...
Docker 配置国内镜像源
由于 GFW 的原因,在下载镜像的时候,经常会出现下载失败的情况,此时就可以使用国内的镜像源。 什么是镜像源:简单来说就是某个组织(学校、公司、甚至是个人)先通过某种手段将国外的镜像下载下来,…...

你的Xbox手柄电量还能撑多久?解决游戏中断的电量管家
你的Xbox手柄电量还能撑多久?解决游戏中断的电量管家 【免费下载链接】XB1ControllerBatteryIndicator A tray application that shows a battery indicator for an Xbox-ish controller and gives a notification when the battery level drops to (almost) empty.…...

从NVIDIA到昇腾:在JupyterLab里统一监控多品牌AI加速卡的实战记录
从NVIDIA到昇腾:在JupyterLab里统一监控多品牌AI加速卡的实战记录 当AI开发团队面临异构计算环境时,如何在一个统一的开发界面中监控不同品牌的加速卡性能,成为提升研发效率的关键痛点。本文将分享我们在JupyterLab中同时监控NVIDIA GPU和华为…...

闲鱼AI客服终极指南:7×24小时自动化值守完整教程
闲鱼AI客服终极指南:724小时自动化值守完整教程 【免费下载链接】XianyuAutoAgent 智能闲鱼客服机器人系统:专为闲鱼平台打造的AI值守解决方案,实现闲鱼平台724小时自动化值守,支持多专家协同决策、智能议价和上下文感知对话。 …...
)
Python+百度OCR实战:5分钟搞定批量图片经纬度提取(附完整代码)
Python百度OCR实战:5分钟搞定批量图片经纬度提取(附完整代码) 当你面对数百张带有经纬度水印的野外考察照片时,是否曾为手动记录坐标而抓狂?去年参与某生态调查项目时,团队摄影师每天传回300张带坐标水印的…...

实战指南:基于快马平台打造可分发的一键安装包,快速部署个人博客系统
今天想和大家分享一个实战经验:如何用InsCode(快马)平台快速打造一个可分发的一键安装包,实现个人博客系统的秒级部署。整个过程就像搭积木一样简单,特别适合需要快速交付项目的开发者。 项目设计思路 这个一键安装包的核心是一个智能安装脚本…...

从“页面描述”到“AI事实层”——让机器读懂你的品牌
引言:为什么你的产品信息在AI答案中“丢失”了? 陆薇在数字营销领域摸爬滚打了九年。她做过技术、干过内容、搞过数据分析,算得上是这个行业里少有的“多面手”。她所在的智联优选,一家主营智能家居产品的跨境电商品牌,在过去一年里已经按照《答案之书》第八篇和第九篇的…...

Granite TimeSeries FlowState R1赋能网络安全:异常流量检测与预测
Granite TimeSeries FlowState R1赋能网络安全:异常流量检测与预测 最近和几个做运维和安全的朋友聊天,大家普遍有个头疼的问题:面对海量的网络流量数据,怎么才能提前发现那些“不对劲”的苗头?等攻击真的发生了&…...

3个维度破解流放之路Build困境:让玩家告别数值迷雾与规划难题
3个维度破解流放之路Build困境:让玩家告别数值迷雾与规划难题 【免费下载链接】PathOfBuilding Offline build planner for Path of Exile. 项目地址: https://gitcode.com/GitHub_Trending/pa/PathOfBuilding Path of Building(简称PoBÿ…...

新手零基础入门:用快马平台可视化学习openclaw核心配置
作为一名刚接触机器人开发的新手,我最近在学习openclaw机械爪的配置时遇到了不少困惑。那些抽象的参数名称和数值范围让我一头雾水,直到发现了InsCode(快马)平台的可视化学习方式,才真正理解了这些配置参数的实际意义。下面分享我的学习笔记&…...

拒绝文献堆砌:如何打造逻辑严密的基金立项依据?
在基金申报的征途中,许多科研人员常陷入一个误区:认为立项依据就是文献的简单叠加。于是,我们花费大量时间搜集资料,将数十篇参考文献的摘要机械地罗列在一起。然而,这样的做法往往导致一个致命的弱点:缺乏…...