目标检测-RT-DETR
RT-DETR (Real-Time Detection Transformer) 是一种结合了 Transformer 和实时目标检测的创新模型架构。它旨在解决现有目标检测模型在速度和精度之间的权衡问题,通过引入高效的 Transformer 模块和优化的检测头,提升了模型的实时性和准确性。RT-DETR 可以直接用于端到端目标检测,省去了锚框设计,并且在推理阶段具有较高的速度。
RT-DETR 的主要特点
-
基于 Transformer 的高效目标检测
RT-DETR 利用 Transformer 结构来处理特征提取和目标检测任务,能够通过自注意力机制捕捉到全局的上下文信息。Transformer 的并行计算能力使得 RT-DETR 能够在大型数据集上保持较高的推理速度和检测精度。 -
实时性能优化
与传统的基于 CNN 的目标检测模型相比,RT-DETR 采用了轻量化的设计,减少了计算复杂度,优化了推理时间。通过减少多余的特征提取层和非必要的卷积运算,RT-DETR 在实时检测任务中的表现非常出色。 -
无锚框设计
RT-DETR 不依赖于锚框(anchor boxes),通过直接预测物体的边界框和类别,提高了模型的灵活性和检测效率。这种 Anchor-Free 的检测方式不仅减少了超参数调优的工作量,还提升了小目标检测的性能。 -
高效的多尺度特征融合
RT-DETR 集成了多尺度特征融合模块,使模型能够同时处理大中小不同尺寸的目标。在检测小目标时,模型的表现尤其优异。 -
端到端训练
RT-DETR 采用了端到端的训练方式,不需要像传统的检测方法那样经过复杂的后处理步骤,如非极大值抑制(NMS)。这不仅提高了训练的效率,还减少了推理的复杂度。
RT-DETR 核心代码展示
以下是 RT-DETR 的简化核心代码示例,包含了 Transformer 的实现和检测头的设计。
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn import TransformerEncoder, TransformerEncoderLayer# 1. 基本的 RT-DETR Backbone
class Backbone(nn.Module):def __init__(self):super(Backbone, self).__init__()# 一个简单的卷积层模拟主干网络特征提取self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3)self.bn1 = nn.BatchNorm2d(64)self.relu = nn.ReLU(inplace=True)def forward(self, x):x = self.conv1(x)x = self.bn1(x)return self.relu(x)# 2. Transformer 编码器部分
class TransformerEncoderModule(nn.Module):def __init__(self, d_model=256, nhead=8, num_layers=6):super(TransformerEncoderModule, self).__init__()encoder_layer = TransformerEncoderLayer(d_model=d_model, nhead=nhead)self.transformer_encoder = TransformerEncoder(encoder_layer, num_layers=num_layers)def forward(self, x):# Transformer 输入前需要展平x = x.flatten(2).permute(2, 0, 1) # [batch_size, channels, h, w] -> [h*w, batch_size, channels]x = self.transformer_encoder(x)return x.permute(1, 2, 0).view(x.size(1), -1, int(x.size(0)**0.5), int(x.size(0)**0.5))# 3. 检测头部分
class DetectionHead(nn.Module):def __init__(self, num_classes, d_model=256):super(DetectionHead, self).__init__()self.num_classes = num_classes# 分类预测self.class_head = nn.Linear(d_model, num_classes)# 边界框预测self.bbox_head = nn.Linear(d_model, 4)def forward(self, x):# 对每个特征图位置进行分类和边界框回归class_logits = self.class_head(x)bbox_reg = self.bbox_head(x)return class_logits, bbox_reg# 4. RT-DETR 总体结构
class RTDETR(nn.Module):def __init__(self, num_classes=80):super(RTDETR, self).__init__()self.backbone = Backbone()self.transformer = TransformerEncoderModule()self.detection_head = DetectionHead(num_classes)def forward(self, x):# 1. 特征提取features = self.backbone(x)# 2. Transformer 编码transformer_out = self.transformer(features)# 3. 目标检测头进行分类和边界框预测class_logits, bbox_reg = self.detection_head(transformer_out)return class_logits, bbox_reg
代码解析
-
Backbone:模型的主干网络,用于提取输入图像的特征。在这个简单示例中,使用了一个卷积层模拟特征提取的过程,实际实现中,RT-DETR 的 Backbone 可以是 ResNet、Swin Transformer 等网络。
-
Transformer 编码器:RT-DETR 的核心模块,负责将提取到的特征输入 Transformer 编码器,通过自注意力机制捕捉全局的上下文信息。在实际应用中,编码器的层数可以根据需求调整,默认情况下为 6 层。
-
Detection Head:检测头负责对 Transformer 的输出进行处理,包括目标的类别分类和边界框的回归。RT-DETR 的检测头设计为 Anchor-Free,即不依赖锚框,直接预测目标的位置和类别。
在RT-DETR模型中,TransformerEncoder和TransformerEncoderLayer是 Transformer 的核心模块。它们用于在序列数据(如特征图或文本)中捕获全局的上下文信息。Transformer 结构最初由 Vaswani 等人在《Attention is All You Need》论文中提出,广泛应用于自然语言处理、目标检测和图像分类等任务。
1. TransformerEncoderLayer
TransformerEncoderLayer 是 Transformer 编码器的基本组成单元,它包含两个主要部分:
-
多头自注意力机制(Multi-Head Self-Attention, MHSA):这是 Transformer 的核心机制,它允许模型在每个时间步(或特征点)上关注输入序列中的所有其他时间步(或特征点),以获得全局的信息。这种机制通过加权平均处理输入序列中的各个位置,使模型能够捕捉到序列中的长距离依赖关系。
-
前馈神经网络(Feedforward Neural Network, FFN):每个 Transformer 编码器层中还包含一个独立的前馈神经网络,通常由两层线性变换和非线性激活函数组成。前馈网络在每个输入位置独立地处理经过自注意力模块后的特征。
此外,TransformerEncoderLayer 使用残差连接(Residual Connection)和层归一化(Layer Normalization)来确保梯度稳定并提高模型的收敛性。
核心组成:
- Self-Attention Layer(自注意力层):用于计算输入序列中每个元素相对于其他元素的重要性。
- Feedforward Network(前馈网络):对经过注意力机制处理的结果进行进一步非线性转换。
- Layer Normalization(层归一化):在每个注意力和前馈网络之后应用,以稳定训练。
- Residual Connections(残差连接):跳跃连接用于避免梯度消失问题,确保深层网络的训练稳定。
代码示例:
import torch.nn as nnclass TransformerEncoderLayer(nn.Module):def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1):super(TransformerEncoderLayer, self).__init__()# 多头自注意力层self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)# 前馈神经网络self.linear1 = nn.Linear(d_model, dim_feedforward)self.dropout = nn.Dropout(dropout)self.linear2 = nn.Linear(dim_feedforward, d_model)# 层归一化self.norm1 = nn.LayerNorm(d_model)self.norm2 = nn.LayerNorm(d_model)# Dropoutself.dropout1 = nn.Dropout(dropout)self.dropout2 = nn.Dropout(dropout)def forward(self, src):# 自注意力机制src2 = self.self_attn(src, src, src)[0]# 残差连接和归一化src = src + self.dropout1(src2)src = self.norm1(src)# 前馈网络src2 = self.linear2(self.dropout(F.relu(self.linear1(src))))# 残差连接和归一化src = src + self.dropout2(src2)src = self.norm2(src)return src
2. TransformerEncoder
TransformerEncoder 是由多个 TransformerEncoderLayer 叠加组成的整体编码器。它负责处理输入序列,将其转换为一个更高层次的表示。编码器中的每一层都会逐步对输入数据中的依赖关系进行建模,从而产生富有语义的全局特征表示。
关键特性:
- 多层堆叠:编码器可以包含多个
TransformerEncoderLayer,通常设置为 6 层或更多,以捕捉输入序列的复杂依赖关系。 - 并行计算:Transformer 通过自注意力机制能够并行处理整个输入序列,使其在处理长序列时非常高效。
代码示例:
import torch.nn as nnclass TransformerEncoder(nn.Module):def __init__(self, encoder_layer, num_layers):super(TransformerEncoder, self).__init__()# 堆叠多层 Transformer 编码器层self.layers = nn.ModuleList([encoder_layer for _ in range(num_layers)])self.num_layers = num_layersdef forward(self, src):# 依次通过每一层 Transformer 编码器层output = srcfor layer in self.layers:output = layer(output)return output
工作流程:
- 输入数据经过
TransformerEncoderLayer中的多头自注意力机制,每个时间步/特征点在整个输入序列的上下文中进行信息交流。 - 每层的输出被送入前馈神经网络进行进一步处理。
- 多个
TransformerEncoderLayer叠加起来,逐层细化输入的全局表示。
Transformer 的核心优势
-
捕捉长距离依赖:自注意力机制可以直接建模序列中任意位置之间的依赖关系,无需像 RNN 那样逐步传播信息,因此能够更高效地捕捉长距离依赖。
-
并行处理:Transformer 能够并行处理整个序列,而不像 RNN 需要按顺序处理每个时间步。这使得 Transformer 在处理大规模数据时具有更高的效率。
-
全局信息建模:通过多头自注意力机制,模型能够在不同的子空间中关注序列的不同部分,建模全局上下文关系。
TransformerEncoderLayer 和 TransformerEncoder 是 Transformer 结构的核心部分。它们利用自注意力机制与前馈网络相结合的方式,能够高效地处理序列数据中的全局上下文信息,使得 RT-DETR 这样的目标检测模型可以更好地进行端到端的检测,尤其是在复杂的场景中表现尤为出色。
nn.MultiheadAttention 是 PyTorch 中实现多头自注意力机制的模块,它是 Transformer 的核心组件。多头注意力机制允许模型在多个不同的子空间中计算注意力,从而使模型能够捕捉到序列中不同层次和不同位置的信息。
多头注意力的原理
多头自注意力机制的目标是让模型能够关注输入序列中不同位置的相关性。在每个头中,输入序列通过线性投影映射到 query(查询)、key(键)和 value(值)三个向量空间,然后计算注意力得分。多个头可以并行计算,通过不同的权重来关注序列中的不同部分,最后将所有头的输出拼接起来进行进一步处理。
公式上,Scaled Dot-Product Attention 计算如下:

其中:
- ( Q )(Query):查询向量
- ( K )(Key):键向量
- ( V )(Value):值向量
- ( d_k ):键向量的维度,用于缩放点积的结果,避免梯度消失
对于多头注意力机制,多个注意力头可以并行计算:

每个头的计算为:

nn.MultiheadAttention 的实现
在 PyTorch 中,nn.MultiheadAttention 封装了上述的多头自注意力机制,并支持批量处理序列数据。
关键步骤:
-
输入线性变换:输入的特征会通过线性层投影,生成
query、key和value三个矩阵。每个矩阵有多个头,分别用不同的权重矩阵进行线性变换。 -
Scaled Dot-Product Attention:对于每个头,计算
query和key的点积,应用缩放和softmax,然后将结果与value相乘,得到注意力输出。 -
多头拼接:所有头的输出被拼接在一起,并通过最后的线性变换得到最终的多头注意力结果。
-
残差连接:注意力的输出与输入序列通过残差连接结合,保持信息的稳定性。
PyTorch 中 nn.MultiheadAttention 的核心代码结构:
import torch
import torch.nn.functional as F
from torch import nnclass MultiheadAttention(nn.Module):def __init__(self, embed_dim, num_heads, dropout=0.0):super(MultiheadAttention, self).__init__()self.embed_dim = embed_dimself.num_heads = num_headsself.dropout = dropout# 确保嵌入维度能被头的数量整除assert embed_dim % num_heads == 0, "Embedding dimension must be divisible by the number of heads"# 每个头的维度self.head_dim = embed_dim // num_heads# 定义 Q、K、V 的线性投影层self.q_proj = nn.Linear(embed_dim, embed_dim)self.k_proj = nn.Linear(embed_dim, embed_dim)self.v_proj = nn.Linear(embed_dim, embed_dim)# 最终的输出投影层self.out_proj = nn.Linear(embed_dim, embed_dim)def forward(self, query, key, value):# 1. 线性投影 Q、K、VQ = self.q_proj(query) # [batch_size, seq_len, embed_dim]K = self.k_proj(key) # [batch_size, seq_len, embed_dim]V = self.v_proj(value) # [batch_size, seq_len, embed_dim]# 2. 将 Q、K、V 分成多头Q = self._split_heads(Q) # [batch_size, num_heads, seq_len, head_dim]K = self._split_heads(K) # [batch_size, num_heads, seq_len, head_dim]V = self._split_heads(V) # [batch_size, num_heads, seq_len, head_dim]# 3. 计算每个头的自注意力attn_output = self._scaled_dot_product_attention(Q, K, V)# 4. 将多头的输出拼接起来attn_output = self._combine_heads(attn_output)# 5. 最终的线性投影output = self.out_proj(attn_output) # [batch_size, seq_len, embed_dim]return outputdef _split_heads(self, x):# 将输入按照头的数量进行分割,batch_size 和 seq_len 保持不变,embed_dim 分成 num_heads * head_dimbatch_size, seq_len, embed_dim = x.size()x = x.view(batch_size, seq_len, self.num_heads, self.head_dim)return x.permute(0, 2, 1, 3) # [batch_size, num_heads, seq_len, head_dim]def _combine_heads(self, x):# 将多头的输出重新组合成一个张量batch_size, num_heads, seq_len, head_dim = x.size()x = x.permute(0, 2, 1, 3).contiguous()return x.view(batch_size, seq_len, num_heads * head_dim)def _scaled_dot_product_attention(self, Q, K, V):# Q 和 K 的点积,然后缩放scores = torch.matmul(Q, K.transpose(-2, -1)) / self.head_dim ** 0.5 # [batch_size, num_heads, seq_len, seq_len]attn_weights = F.softmax(scores, dim=-1) # 注意力权重attn_output = torch.matmul(attn_weights, V) # 通过权重加权的 Vreturn attn_output
代码解释:
-
初始化 (
__init__):embed_dim:输入的嵌入维度,即每个序列元素的特征长度。num_heads:多头注意力中的头数,embed_dim必须能被num_heads整除。q_proj、k_proj、v_proj:分别是对query、key和value进行线性变换的投影层。
-
前向传播 (
forward):- 将输入的
query、key、value分别通过线性层投影到Q、K、V向量。 - 使用
_split_heads将它们分割成多头。 - 计算缩放的点积注意力 (
_scaled_dot_product_attention)。 - 将多头的结果拼接起来 (
_combine_heads)。 - 最后通过
out_proj投影到最终的输出。
- 将输入的
-
注意力计算 (
_scaled_dot_product_attention):- 通过矩阵乘法计算
Q和K的点积,得到每个位置之间的相似度得分。 - 使用
softmax将这些得分归一化为注意力权重。 - 用这些权重对
V进行加权求和,得到注意力的输出。
- 通过矩阵乘法计算
-
多头处理 (
_split_heads和_combine_heads):_split_heads:将Q、K和V分解为多个头,以便并行计算每个头的自注意力。_combine_heads:将每个头的输出重新组合为一个完整的张量,供后续处理。
总结
nn.MultiheadAttention 模块实现了多头自注意力机制,它通过并行计算多个注意力头来捕获输入序列中不同位置和不同层次的依赖关系。每个头可以学习不同的注意力模式,最终将这些模式结合起来,生成更加丰富的特征表示。这一机制在 Transformer 中的应用,使模型具备了捕捉长距离依赖关系和并行处理的能力,大大提高了计算效率。
结论
RT-DETR 是一种结合 Transformer 和目标检测的新型模型,具有实时检测的能力,并且在精度上比传统的目标检测模型有显著提升。通过自注意力机制和高效的特征提取设计,RT-DETR 在检测大中小目标时均有出色的表现,同时减少了复杂的后处理步骤,使其更加适用于实际应用场景,如自动驾驶、监控、机器人视觉等。
相关文章:
目标检测-RT-DETR
RT-DETR (Real-Time Detection Transformer) 是一种结合了 Transformer 和实时目标检测的创新模型架构。它旨在解决现有目标检测模型在速度和精度之间的权衡问题,通过引入高效的 Transformer 模块和优化的检测头,提升了模型的实时性和准确性。RT-DETR 可…...

业务资源管理模式语言09
示例: 图13 表示了QuoteTheMaintenance 模式的一个实例,在汽车修理店系统中,其中“Vehicle”扮演“Resource”,“Repair Quotation”扮演“Maintenance Quotation”,“Repair shop branch”扮演“Source-party”&…...

Spring Boot + Vue 多级目录的构建详解
1. 背景介绍 1.1 为何选择 Spring Boot Vue? 在现代 Web 开发中,前后端分离已成为一种标准实践。Spring Boot 提供了强大的后端开发能力,尤其在构建企业级应用时,其轻量级、高效性和丰富的生态系统让开发者如虎添翼。而 Vue.js…...

Android的Launch
看了一下资料,其实差别并不像一般的bootloader之类那么大。基本上还是和普通的APK程序差不多,基本上是AMS启动的第一个带界面的程序,这个界面也是常规的开发模式。可以设置各种view,可以设置背景。 然后在这个程序中,…...

Deep Ocr
1.圈出内容,文本那里要有内容.然后你保存,并导出数据集. 2.找出deep_ocr_recognition_training_workflow.hdev 文件.修改“DatasetFilename : Test.hdict” 310行 write_deep_ocr (DeepOcrHandle, BestModelDeepOCRFilename) 3.推理test.hdev 但发现很慢,没有mlp…...

图片验证码
导入依赖 <dependencies><dependency><groupId>cn.hutool</groupId><artifactId>hutool-all</artifactId><version>5.8.25</version></dependency> </dependencies> 代码 Service public class ValidateCodeServi…...
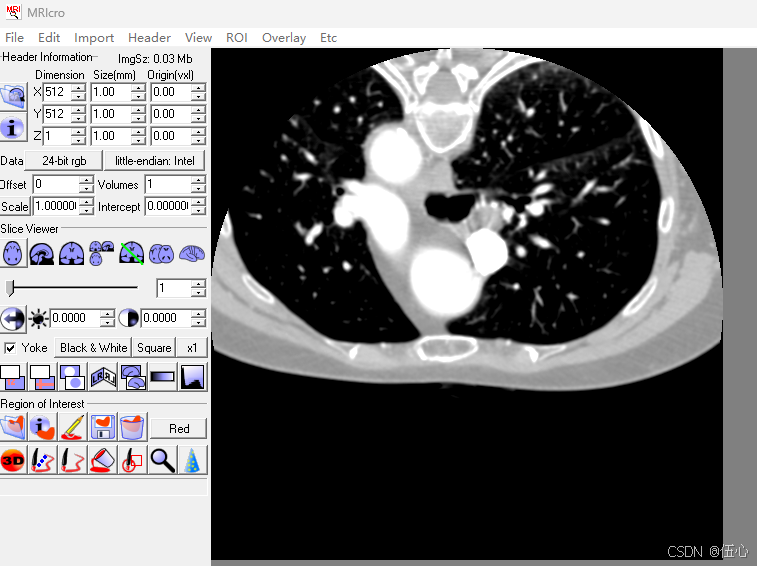
004: VTK读入数据---vtkImageData详细说明
VTK医学图像处理---vtkImageData类 目录 VTK医学图像处理---vtkImageData类 简介: 1 Mricro软件的安装和使用 (1) Mricro安装 (2) Mricro转换DICOM为裸数据 2 从硬盘读取数据到vtkImageData 3 vtkImageData转RGB或RGBA格式 4 练习 总结 简介:…...

分割千万级,将大文件分割为小件 csv
依赖 <dependency><groupId>commons-io</groupId><artifactId>commons-io</artifactId><version>2.9.0</version></dependency> package com.topnet.controller;import com.topnet.utils.R; import lombok.extern.slf4j.Slf4…...
 函数深入解析)
SQL COUNT() 函数深入解析
SQL COUNT() 函数深入解析 SQL(Structured Query Language)是一种用于管理关系数据库管理系统(RDBMS)的标准编程语言。在SQL中,COUNT() 函数是一个常用的聚合函数,用于计算数据表中的行数或特定列的值数量…...

vue3和vue2的双向绑定原理
Vue 的双向绑定是其核心特性之一,允许数据和视图之间保持同步。在 Vue 2 和 Vue 3 中,双向绑定的实现原理有所不同。以下是两者的原理对比: Vue 2 的双向绑定原理 在 Vue 2 中,双向绑定是通过以下机制实现的: 响应式…...

[C++]刷题
作者主页: 作者主页 本篇博客专栏:C 创作时间 :2024年6月20日 最后: 十分感谢你可以耐着性子把它读完和我可以坚持写到这里,送几句话,对你,也对我: 1.一个冷知识: …...

职称评审中,论文发表要求?
无论是医生、教师或其他等职业,职称评审无疑是一个非常重要的环节。而职称评审中的论文发表则是评定我们专业能力的重要一环,可如何才能让自己辛苦撰写的的论文被发表,达到论文发表都有哪些要求呢? 一、选题要新颖 编辑和审稿人…...

连续信号的matlab表示
复习信号与系统以及matlab 在matlab中连续信号使用较小的采样间隔来表四 1.单位阶跃信号 阶跃信号:一个理想的单位阶跃信号在时间 t 0 之前值为0,在 t 0 及之后值突然变为常数 A(通常取 A 1) %matlab表示连续信号,是让信号的采样间隔很小…...

centos7.9搭建mysql5.6主从
mysql5.6 搭建数据库配置主从 搭建数据库 官网下载软件包后上传 基于centos7.9搭建mysql5.6.42 [rootmysql02 ~]# ls anaconda-ks.cfg init.sh MySQL-5.6.42-1.el7.x86_64.rpm-bundle.tar解压 tar -xf MySQL-5.6.42-1.el7.x86_64.rpm-bundle.tar -C /opt/[rootmysql02 ~]…...

C#通过ACE OLEDB驱动程序访问 Access和 Excel
ACE 代表 Access Connectivity Engine。它是 Microsoft 提供的一组组件,用于访问和操作 Microsoft Access 数据库以及其他类似的文件格式,如 Excel 工作簿。ACE 主要包括以下几部分: ACE OLEDB 驱动程序:用于通过 OLE DB 提供程序…...

智能新纪元:GPT-Next引领的AI革命及其跨领域应用
GPT-Next:性能的百倍提升 在当今这个科技日新月异的时代,人工智能(AI)无疑是最具活力和变革性的领域之一。最近,OpenAI在KDDI峰会上宣布了一项激动人心的消息:他们即将推出名为“GPT-Next”的新一代语言模…...

Nexus配置npm私服
1,配置npm-hub 2,配置proxy-npm 3,配置group-npm 4,配置local-npm 5,配置淘宝...

《OpenCV计算机视觉》—— 图像轮廓检测与绘制
文章目录 一、轮廓的检测二、轮廓的绘制图像轮廓检测与绘制的代码实现 三、轮廓的近似 一、轮廓的检测 轮廓检测是指在包含目标和背景的数字图像中,忽略背景和目标内部的纹理以及噪声干扰的影响,采用一定的技术和方法来实现目标轮廓提取的过程注意:做轮…...

Spark-Yarn模式如何配置历史服务器
在Spark程序结束之后我们也想看到运行过程怎么办? Yarn模式下,通过以下步骤配置历史服务器即可: mv spark-defaults.conf.template spark-defaults.conf修改spark-default.conf 文件,配置日志存储路径 spark.eventLog.enabled true spark.…...

Maven的安装
一、安装 压缩包解压完的目录如下所示(此处为绿色免安装版): (其余三个文件是针对Maven版本,第三方软件等简要介绍) 二、环境变量 前提: jdk最低版本为JAVA7(即jdk17)…...

别再乱算相似度了!用Python实战二元变量聚类:从Jaccard系数到病人分组
医疗数据分析实战:用Python实现基于Jaccard系数的病人症状聚类在医疗数据分析领域,如何从海量病人症状数据中发现潜在规律一直是临床研究的难点。传统方法往往依赖医生经验或简单统计,而现代数据挖掘技术为我们提供了更科学的解决方案。本文将…...
)
双系统Ubuntu磁盘告急?别重装!用GParted无损扩容保姆级教程(附U盘启动盘制作)
双系统Ubuntu磁盘告急?别重装!用GParted无损扩容保姆级教程(附U盘启动盘制作)当你在Windows和Ubuntu双系统环境下工作时,是否遇到过这样的窘境:当初安装时给Ubuntu分配的空间捉襟见肘,而Windows…...

基于ESP32的智能电池充电器设计:多化学体系支持与模块化架构
1. 项目概述:打造一台全能的“电池医生”手头攒了一堆不同化学体系的电池,从航模用的4S锂聚合物电池,到应急灯里的12V铅酸电池,再到各种工具里的镍氢、锂离子电池,每次充电都得翻出好几个不同的充电器,桌面…...

基于MAX78000的医疗紧急呼叫系统:边缘AI与低功耗设计实战
1. 项目概述与核心价值大家好,我是Victor Hugo,一名电子工程师。今天我想和大家分享一个我最近完成并参与设计竞赛的项目:一个基于MAX78000 FTHR开发板的医疗紧急呼叫辅助系统。这个项目的核心,不是从零开始造一个新轮子ÿ…...

PCB的常规机械通孔与HDI工艺钻孔差异
结合常规 4 层通孔 PCB(非 HDI) 标准制程,分步骤讲清钻孔时机、先后顺序,区分机械通孔与板件结构,专业且贴合工厂实际流程。一、先明确 4 层通孔板基础结构4 层板结构:L1 → PP 半固化片 → L2/L3ÿ…...
的原理、演进与未来)
车载诊断系统(OBD)的原理、演进与未来
本文约8,167字,建议收藏阅读 作者 | 北湾南巷 出品 | 汽车电子与软件 引 言 在现代汽车中,越来越多的故障不再表现为明显的机械损坏,而是以“亮灯”“报码”“性能异常”等电子信号的形式出现。发动机为什么亮起故障灯?排放是否达…...

【审计专栏】【财务领域】 第四十九篇 人在企业中的核心资产和核心利益01
编号 类型 企业 (行业/企业产品/企业利益链/生态位与层级) 业务领域 企业性质 企业中人的角色/岗位/利益矩阵 人在企业中的核心资产/附属资产 资产的业务-财务数学模型及数字/数值 关联知识 1 核心经营性资产(如IP、数据、品牌) 行业:人工智能 产品:工业视觉检…...

Android Root检测绕过:从逆向分析到Frida分层Hook实战
1. 这不是“绕过root检测”,而是理解检测逻辑后的精准干预在安卓逆向工程的实际工作中,“过root检测”这个说法本身就容易引发误解——它听起来像某种黑箱魔法,仿佛只要套用某个脚本、加载某个插件,就能让App对设备状态“视而不见…...

通用物联网开发板设计:基于ESP8266的硬件集成与开发实践
1. 项目概述:为什么我们需要一块“通用”的物联网开发板?在捣鼓了几年物联网项目之后,我发现自己桌面上堆满了各种开发板:ESP8266、ESP32、Arduino Uno、STM32 Nucleo……每个项目都要重新连线、配置电源、焊接传感器接口…...

如何快速定制Office界面:终极开源工具使用指南
如何快速定制Office界面:终极开源工具使用指南 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/gh_mirrors/of/office-ribbonx-editor O…...