【手撕数据结构】八大排序神功(上)
目录
- 冒泡排序【有点拉胯】
- 动图演示:
- 思路解析
- 单趟算法图解
- 代码详解+性能优化
- 复杂度分析
- 直接插入排序【还阔以】
- 动图演示
- 思路解析
- 代码分析与讲解
- 复杂度分析
- 希尔排序【有点强】
- 动图演示
- 思路讲解
- 排序过程总览
- 代码分析讲解
- 复杂度分析
- 堆排序【太有石粒啦】
- 动图演示
- 堆的概念与结构
- 向下调整算法【核心所在】
- 代码考究精析
- 升序建大堆 or 小堆?
- 如何进一步实现排序
- 复杂度分析
冒泡排序【有点拉胯】
动图演示:

思路解析
- 所谓冒泡,就是像泡泡一样从水底冒泡到水面,这个冒泡过程就是比较,已经冒泡到水面的数据就不用再进行比较.,也就是说把第一个元素与后面的元素比较,如果说排升序,第一个元素比后面的元素大就交换位置,然后再与后面的元素进行比较,比较完后,此时我们就冒泡到了水面,所需冒泡的元素就少了一个,下一次冒泡的时候,就应该少排序一个。.
单趟算法图解

代码详解+性能优化
- 先看内部循环.
for (int j = 0; j < n - i - 1; ++j)
{if (a[j] > a[j + 1])swap(&a[j], &a[j + 1]);
}- 这里n - i 就是我们每一趟循环冒泡都会排好一个最大的数据(升序),那么那个数据就不需要再进行下一次的循环冒泡中
- -1则是为了防止数组下标越界,设 n = 10,第一次 j < 9, 那么j最大下标是8,此时 j + 1最大就是9 了。
我们再来看外部循环:
for (int i = 0; i < n - 1 ; i++)
- i < n - 1是因为,设n = 10, i < 9,最大取到8,此时内部循环 j < n - i -1最后一趟就是 j < 1,也就是最后第一个元素0(j)与第二个元素(j+1)的比较冒泡。
- 下面第i趟冒泡排序可以参考

- 那这样的情况我们能不能优化一下呢?

- 可以看到,我们或许不需要一定把n趟排序循环完,数组才有序,可能是n/2趟,n/4趟,n-2,n-3趟等数组就有序了。
- 这种我们可以使用一个标志变量,如果单趟冒泡排序的过程中发生了交换,也就是进了if条件说明数组还没有序需要交换,那么把标志变量改变,如果进行单趟冒泡排序后,标志变量没有改变,说明数组已经有序,这时候就可以直接跳出外层循环。
/*冒泡排序*/
void BubbleSort(int* a, int n)
{//[0,n - 1)for (int i = 0; i < n - 1; ++i){int changed = 0;for (int j = 0; j < n - 1 - i; ++j){if (a[j] > a[j + 1]){swap(&a[j], &a[j + 1]);changed = 1;}}if (changed == 0)break;PrintArray(a, n);} //[1,n)//for (int i = 1; i < n; ++i)//{// for (int j = 0; j < n - i; ++j)// {// if (a[j] > a[j + 1])// swap(&a[j], &a[j + 1]);// }//}
}复杂度分析
【时间复杂度】:O(N2)
【空间复杂度】:O(1)
- 我们通过上面的讲解了其运行过程,就是每一个数与其后的n - i个数进行比较,若是符合条件则进行交换,不算我们优化之后的,算法运行的次数就是 (N - 1) + (N - 2) + (N - 3) + … + 2 + 1,结合起来运算就是一个等差数列,那么其时间复杂度显而易见就是O(N2)
- 对于最后的情况就是o(n),也就是数组已经有序的情况下,我们做了标志变量,如果第一次冒泡排序没有交换,就可以直接结束循环,此时我们只执行了n次。
直接插入排序【还阔以】
动图演示

思路解析
- 可以看到,直接插入排序就是把有序区间的后的第一个数据与有序区间的数据进行依次比较,这里设升序,如果说比有序区间中的某个数据小,就让这个数据之后的有序区间的数据整体往后面移动,然后最后把这个数据插入到有序区间中比他大的那个数据的位置。

- 实际中我们玩扑克牌时,就用了使用到了插入排序的思想。设想你发到一张牌为7,现在想将其放入你刚才已经整理好了牌堆中,这个牌堆就是有序序列,这张牌就是待插入的数据。通过生活中的场景来看,是不是更加形象一点呢😄

代码分析与讲解
- 理解算法后,也不一定会写程序。也就是脑子会了,手还不会。但是我们应该知道,写程序不是一下把整个算法就写出来了,我们应该从简单到复杂,我们先不写整趟排序,就考虑单趟排序的问题。
- 首先单趟的逻辑,就是我们需要把有序区间后的一个数据插入到有序区间中,不妨设有序区间最后一个数据为end,之后的数据是end + 1,然后我们开始比较end和end+1,如果说end+1小于end,那么end这个数据往后移动到end + 1这个位置,然后end - - 开始有序区间中的另一个数据和end + 1进行比较
- 但是注意的是,随着有序区间的扩大,我们end + 1需要比较的数据就越多,此时我们需要把这段逻辑放在一个循环里面,结束条件是什么呢?end >= 0, 等于0,是因为我们最坏可能比较到第一个元素也比end + 1小.
- 若是在中途比较的过程中发现有比待插入数据还要小或者相等的数,就停止比较,跳出这个循环。因为随着有序区间中数的后移,end后一定会空出一个位置,此时呢执行a[end + 1] = tmp;就可以将这个待插入数据完整地放入有序区中并且使这个有序区依旧保持有序
int end;
int tmp = a[end + 1]; //将end后的位置先行保存起来
while (end >= 0)
{if (tmp < a[end]){a[end + 1] = a[end]; //比待插值来得大的均往后移动end--; //end前移}else{break; //若是发现有相同的或者小于带插值的元素,则停下,跳出循环}
}
a[end + 1] = tmp; //将end + 1的位置放入保存的tmp值- 接下来我们看外层循环
for (int i = 0; i < n - 1; ++i)
{int end = i;//单趟插入逻辑...
}- 或许有人疑问为什么i < n - 1 ,而不是 i < n,这里主要是防止数组下标越界,设n = 10 , 如果 i < n
n最大为9,下面的end + 1就会访问到a[10],此时会越界,所以是 i < n - 1
下面是整体代码:
/*直接插入排序*/
void InsertSort(int* a, int n)
{//不可以< n,否则最后的位置落在n-1,tmp访问end[n]会造成越界for (int i = 0; i < n - 1; ++i){int end = i;int tmp = a[end + 1]; //将end后的位置先行保存起来while (end >= 0){if (tmp < a[end]){a[end + 1] = a[end]; //比待插值来得大的均往后移动end--; //end前移}else{break; //若是发现有相同的或者小于带插值的元素,则停下,跳出循环}}a[end + 1] = tmp; //将end + 1的位置放入保存的tmp值}}复杂度分析
【时间复杂度】:O(N^2)
【空间复杂度】:O(1)
- 最好的情况就是o(n),也就是数组本身就有序的情况:1 2 3 4 5 6 7 8 9 10,此时只需要遍历一次数组而已。
- 最坏的情况就是o(n^2),这里设要排升序,数组为降序:10 9 8 7 6 5 4 3 2 1,此时就需要全部都往后面移动一位。
希尔排序【有点强】
动图演示

思路讲解
- 希尔排序就是直接插入排序的优化,我们在上面分析直接插入排序的时间复杂度时,最差的时候就是降序的时候,那么现在对降序的数组进行分组,对每组进行直接插入排序,那么每组的数据就是比原先没分组的数据少,这时候我们直接插入排序的时候,交换的次数变少了,而且保证了整个数组基本有序。
- 对原本的数据进行一个分组,对每组使用直接插入排序排序。增量【gap】随着排序次数的增加而减少
- 当gap==1时,整个序列恰好被分为一组,就对预排序后的数组最后一次进行直接插入排序。
排序过程总览

- 我们看到这里有10个数, gap = 10 / 2 , gap = 5,也就是每个数字之间的间隔为5。然后把他们分组,每组的元素间隔5个元素,若是前者比后者大,则交换。


- 以上就是三次排序的过程,当gap == 1的时候,也就是全部数据为一组,即间隔为一,对他们进行直接插入排序
代码分析讲解
- 还是一样,我们从简单到复杂,先分析单趟排序的过程。
- 对于希尔排序,我上面说过其实他就是直接插入排序的优化,只不过多了一个分组来排的逻辑。而这个分组有那些元素,就是通过gap 间隔增量,来控制。我们开始设 n = 10, gap = n / 3 ,也就是间隔3个元素的数据为一组
- 分了组就简单了,我们就对每个分组的元素进行直接插入排序,那么怎么获得每个分组的元素了,因为他们是间隔gap 个元素为一组,现在设end为分组第一个元素,所以就是end + gap 个元素
- 注意:在实现后移的过程中也是移动gap步,对于end也是同理
- 注意:那在跳出循环之后的tmp也是要放在a[end + gap]的地方
int gap = 3;
int end;
int tmp = a[end + gap];
while (end >= 0)
{if (tmp < a[end]){a[end + gap] = a[end];end -= gap;}else{break;}
}
a[end + gap] = tmp;- 说完了单趟,我们就要用循环来控制每一趟排序了。
- way1:第一种方法就是我们把每个分组的元素以组为单位,把每一组的数据排好,再排下一组,此时我们需要排gap组.

- 这种方法不推荐,都有4层循环了。
- way2:把每一组的第一个元素排完,然后排下一组

- 这种就只有3层循环,i++控制每一组的第一个元素,和第2个元素的排序
下面为2中方法图解:

- 再说说,为什么gap = gap / 3,gap = gap / 5行不行,gap / 5当然可以,但是他们每组元素的间隔太远了,我们进行预排序的目的是把数组接近有序,这样在最后一次直接插入排序的时候,我们需要往后移动的次数就少了。
如图这样的预排序之后:

- 那有人说,那我直接gap / 2,2个间隔为一组,这样是缩短了距离,但是组数变多了也不好,所以我们这种选择gap / 3.
- 但是在gap / 3之后可能在最后无法使【gap = 1】,比如gap = 6的时候,那此时的话就需要在最后加上一个1使得最后一次缩小gap增量的时候可以使其到达1
- gap > 1就是因为,设 gap = 10, 最后会除到1,此时1/3 + 1会永远等于1,所以gap > 1.
- i < n - gap ,也是为了防止数组越界,因为我们是分组进行排序,每次都是与end + gap 下班班元素进行比较
整体代码演示:
/*希尔排序*/
void ShellSort(int* a, int n)
{int gap = n;while (gap > 1) {/** gap > 1 —— 预排序* gap == 1 —— 直接插入排序*///gap /= 2;gap = gap / 3 + 1; //保证最后的gap值为1,为直接插入排序for (int i = 0; i < n - gap; i++){ //一位一位走int end = i;int tmp = a[end + gap];while (end >= 0){if (tmp < a[end]){a[end + gap] = a[end];end -= gap;}else{break;}}a[end + gap] = tmp;}}
}复杂度分析
【时间复杂度】:O(NlogN)
【空间复杂度】:O(1)

- 但这也仅仅似乎根据我们写的代码来看,实际上希尔排序的时间复杂度不是O(NlogN),而是O(N1.3)
- 大家只能要能够计算出O(NlogN)就行了,如果有读者数学很好的当然也是可以做到😄,然后对于希尔排序时间复杂度最坏是O(N2),这一点上面也已经写出了,最坏情况就是等差数列的时候,例如5个数要挪动4下,3个数要挪动2下。。。N个数要挪动N - 1下
- 希尔排序比直接插入排序快的原因,就是因为分组预排序让数组接近有序并且比较的数据变少,然后最后一次排序的时候由于数组已经接近有序,那么比较的次数就变少了。

- 然后是有关希尔排序的空间复杂度,这一块还是和插入排序一样,只是在内部定义了一些变量,并没有去申请一些额外的空间,因此空间复杂度为O(1)
堆排序【太有石粒啦】
动图演示

堆的概念与结构
如果有一个关键码的集合K = { k0, k1, k2,…,kn-1 },把它的所有元素按完全二叉树的顺序存储方式存储在一个一维数组中。并满足:Ki <= K2i+1 且 Ki <= K2i+2 ( Ki >= K2i+1 且 Ki >= K2i+2 ) i = 0,1,2…,则称为小堆(或大堆)。将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆
【堆的性质】
- 堆中的左右孩子节点总是大于(小根堆)根节点,或者小于(大根堆)根节点
- 堆总是一颗完全二叉树
基本了解堆的概念后,我们来看看琢磨一下什么是大根堆和小根堆

- 从上图可以看出,对于【堆】而言,其实就是一种完全二叉树,但是呢,它又在完全二叉树的基础上再进一步形成一个区分,也就是分为【大根堆】和【小根堆】
- 但是这只是我们自己想象出来的逻辑结构,但是在内存中的物理结构实际上就是数组存储的,既然是数组我们就一定可以通过下标来访问其中的各个元素。
- 这其实也得出了一个结论,在逻辑结构中我们可以看出其实每个根节点都要左右孩子节点,那么在物理结构中我们想要访问这些节点也可以吗?在二叉树和堆中已经讲过。
【lchild = parent * 2 + 1】 左孩子
【rchild = parent * 2 + 2】 右孩子
【parent = (child - 1) / 2】
向下调整算法【核心所在】
算法图解:(这里假设我们建的大堆)

- 对于向下调整算法,必须满足的前提就是需要调整的根节点的左右子树是大根堆,这样保证调整后整棵树也是一个大根堆。
- 对于上面的原理就是,如果我们需要保证调整完后整颗二叉树是一个大堆,根节点18需要找他的左右孩子节点谁更大与其交换,保证交换后对于18,49,34这颗二叉树是一个大根堆,然后从把交换的孩子节点作为新的子树根节点依次循环以上步骤。直到这个【18】的孩子结点到达【n - 1】就不作交换了,因为【n - 1】就相当于是位于数组下标的最后一个值
代码考究精析
- 首先对于向下调整算法我们需要调整堆,那么前面堆的结构说了,其实物理结构是一个数组(也就是顺序二叉树),那么我们第一个参数就传数组名,然后我们要调整他的根节点,根节点与左右孩子节点比较交换,所以我们把父节点传过去通过,【lchild = parent * 2 + 1】 左孩子
【rchild = parent * 2 + 2】 右孩子求其左右孩子节点。还有就是传数组的长度,这在循环的结束条件要用到。
void Adjust_Down(int* a, int n, int parent)- 你可以通过每次计算 左右孩子节点来比较谁大。但是有点冗余
- 我们这里假设左孩子为最大节点,如果他比右孩子节点小,那么左孩子节点下标+1,因为数组数连续存储的,+1就是右孩子节点。if判断里还加了一个【child + 1 < n】,这个的话其实就是进行一个右孩子的越界访问判断,因为我们是在进行一个不断向下调整的过程,因此肯定会到达倒数第二层,此时它的左孩子可能是存在的,但若是它的右孩子不存在了,那么在后面去访问这个【child + 1】就会变成越界访问⚠,是一个非法操作
//判断是否存在右孩子,防止越界访问
if (child + 1 < n && a[child + 1] > a[child])
{++child; //若右孩子来的大,则转化为右孩子
}- 然后是循环内部的逻辑,和【向上调整算法】一样,就是一个比较和迭代更新的过程
if (a[child] > a[parent])
{swap(&a[child], &a[parent]);parent = child; //更新父亲child = parent * 2 + 1; //更新孩子
}
else {break;
}整体代码演示:
/*向下调整算法*/
void Adjust_Down(int* a, int n, int parent)
{int child = parent * 2 + 1; //默认左孩子来得大while (child < n){ //判断是否存在右孩子,防止越界访问if (child + 1 < n && a[child + 1] > a[child]){++child; //若右孩子来的大,则转化为右孩子}if (a[child] > a[parent]){swap(&a[child], &a[parent]);parent = child;child = parent * 2 + 1;}else {break;}}
}升序建大堆 or 小堆?
- 给个答案就是升序我们应该建大堆,降序我们应该建小堆。
- 为什么升序建大堆?
我们建堆就是为了排序数组,既然是升序,就是小的在前面,大的在后面。我们建大堆可以保证,堆顶一是最大的,这时候我们只需要把堆顶与数组最后一个元素交换,就可以保证数组最后一个元素是最大的。
- 有人说了,那我用建小堆也能保证数组第一个元素是最小的。
看图:

- 那有n个数排序,我们就要建n个堆,建堆一次时间复杂度为o(n),建n个堆就是o(n^2)
- 而建大堆,我们只需要把堆顶和数组最后一个元素进行交换,然后对堆进行向下调整即可
- 可能有人疑问,那建小堆的时候为什么不直接向下调整,我前面说过向下调整前提是需要保证其左右子树是小堆的,但是上图父亲孩子节点打乱后就不是小堆了。
//建立大根堆(倒数第一个非叶子结点)
for (int i = ((n - 1) - 1) / 2 ; i >= 0; --i)
{Adjust_Down(a, n, i);
}如何进一步实现排序
其实在前面讲向下调整算法的过程中已经透露出排序的过程了
- 就是建大堆后,把堆顶元素和数组最后一个元素进行交换,达到数组最后一个元素是最大的目的。然后进行向下调整恢复大堆的性质(堆顶为最大元素),再进行交换,知道交换到堆顶结束。
- 注意:每次交换后,被交换到后面的数据不参与下次堆的向下调整。

代码如下:
/*堆排序*/
void HeapSort(int* a, int n)
{//建立大根堆(倒数第一个非叶子结点)for (int i = ((n - 1) - 1) / 2 ; i >= 0; --i){Adjust_Down(a, n, i);}int end = n - 1;while (end > 0){swap(&a[0], &a[end]); //首先交换堆顶结点和堆底末梢结点Adjust_Down(a, end, 0); //一一向前调整end--;}
}整体代码:
/*交换*/
void swap(int* x, int* y)
{int t = *x;*x = *y;*y = t;
}/*向下调整算法*/
void Adjust_Down(int* a, int n, int parent)
{int child = parent * 2 + 1; //默认左孩子来得大while (child < n){ //判断是否存在右孩子,防止越界访问if (child + 1 < n && a[child + 1] > a[child]){++child; //若右孩子来的大,则转化为右孩子}if (a[child] > a[parent]){swap(&a[child], &a[parent]);parent = child;child = parent * 2 + 1;}else {break;}}
}/*堆排序*/
void HeapSort(int* a, int n)
{//建立大根堆(倒数第一个非叶子结点)for (int i = ((n - 1) - 1) / 2; i >= 0; --i){Adjust_Down(a, n, i);}int end = n - 1;while (end > 0){swap(&a[0], &a[end]); //首先交换堆顶结点和堆底末梢结点Adjust_Down(a, end, 0); //一一向前调整end--;}
}复杂度分析
【时间复杂度】:O(NlogN)
【空间复杂度】:O(1)

- 在建堆这块的时间复杂度是o(N),在排序一个数据的时候是logn,n个数据就是nlongn ,n+nlogn为nlogn
- 空间复杂度就是o(1),并没有在堆排序里面重新申请空间。
相关文章:
【手撕数据结构】八大排序神功(上)
目录 冒泡排序【有点拉胯】动图演示:思路解析单趟算法图解代码详解性能优化复杂度分析 直接插入排序【还阔以】动图演示思路解析代码分析与讲解复杂度分析 希尔排序【有点强】动图演示思路讲解排序过程总览代码分析讲解复杂度分析 堆排序【太有石粒啦】动图演示堆的概念与结构向…...

【2024高教社杯全国大学生数学建模竞赛】B题模型建立求解
目录 1问题重述1.1问题背景1.2研究意义1.3具体问题 2总体分析3模型假设4符号说明(等四问全部更新完再写)5模型的建立与求解5.1问题一模型的建立与求解5.1.1问题的具体分析5.1.2模型的准备 目前B题第一问的详细求解过程以及对应论文部分已经完成ÿ…...

OpenHarmony鸿蒙开发( Beta5.0)智能手表应用开发实践
样例简介 本项目是基于BearPi套件开发的智能儿童手表系统,该系统通过与GSM模块(型号:SIM808)的通信来实现通话和定位功能。 智能儿童手表系统可以通过云和手机建立连接,同步时间和获取天气信息,通过手机下…...

共享单车轨迹数据分析:以厦门市共享单车数据为例(一)
共享单车数据作为交通大数据的一个重要组成部分,在现代城市交通管理和规划中发挥着越来越重要的作用。通过对共享单车的数据进行深入分析,城市管理者和规划者能够获得大量有价值的洞察,这些洞察不仅有助于了解城市居民的日常出行模式…...

SprinBoot+Vue在线商城微信小程序的设计与实现
目录 1 项目介绍2 项目截图3 核心代码3.1 Controller3.2 Service3.3 Dao3.4 application.yml3.5 SpringbootApplication3.5 Vue3.6 uniapp代码 4 数据库表设计5 文档参考6 计算机毕设选题推荐7 源码获取 1 项目介绍 博主个人介绍:CSDN认证博客专家,CSDN平…...

4--SpringBootWeb-请求响应
目录 postman 1.简单参数 请求参数名与形参变量名一致时 请求参数名与形参变量名不一致时 2.实体参数 简单实体对象 复杂实体对象 3.数组集合参数 数组 集合 4.日期参数 5.JSON参数 6.路径参数 1 2 postman Postman值一款功能强大的网页调试与发送网页HTTP请求的…...
电脑点击关机之后,又自动重启开机了。根本就关不了?
前言 有个小姐姐说,她家的电脑好生奇怪:点击【关机】按钮之后,电脑提示【正在关机】,过了几秒,电脑又自动开机了…… 好家伙!也就是说关机和重启根本就没区别,电脑完全无法断电。 最后忍无可…...

强化网络安全:通过802.1X协议保障远程接入设备安全认证
随着远程办公和移动设备的普及,企业网络面临着前所未有的安全挑战。为了确保网络的安全性,同时提供无缝的用户体验,我们的 ASP 身份认证平台引入了先进的 802.1X 认证协议,确保只有经过认证的设备才能接入您的网络。本文档将详细介…...

链动2+1模式AI智能名片S2B2C商城小程序源码在社群商业价值构建中的应用探索
摘要:在数字经济浪潮的推动下,社群作为商业生态的核心组成部分,其商业价值正以前所未有的速度增长。本文深入探讨了如何通过“链动21模式AI智能名片S2B2C商城小程序源码”这一前沿技术工具,深度挖掘并优化社群的商业价值。通过详细…...

基于SpringBoot+Vue+MySQL的校园周边美食探索及分享平台
系统背景 在当今数字化时代,校园生活正日益融入信息技术的浪潮之中,学生们对于便捷、高效且富有趣味性的生活方式有着越来越高的追求。特别是在饮食文化方面,随着校园周边餐饮业态的日益丰富,学生们渴望一个能够集美食探索、分享与…...

“设计模式双剑合璧:工厂模式与策略模式在支付系统中的完美结合”
工厂模式(Factory Pattern)和策略模式(Strategy Pattern)都是常见的设计模式,但它们解决的问题和应用场景不同。下面是它们的区别: 1. 目的不同: 工厂模式(Factory Pattern…...

第二百一十九节 JPA 教程 - JPA 字段映射示例
JPA 教程 - JPA 字段映射示例 当将 Java bean 字段映射到数据库列时,我们可以选择标记字段,标记 getter 方法并标记两者。 标记字段 以下代码来自 Professor.java。 它显示如何将主键列标记为 Java bean 字段标识。 package cn.w3cschool.common; im…...

目标检测-YOLOv6
YOLOv6 YOLOv6 是 YOLO 系列的一个新版本,相比 YOLOv5 进行了大量的优化与改进。YOLOv6 的设计目标是在提高模型检测精度的同时,进一步优化速度和效率,特别是在推理速度和部署便捷性方面。它采用了更先进的网络架构和优化技巧,在…...

Java面向对象与多态
目录 Java面向对象与多态 多态介绍 形成多态的前提 多态下成员访问的特点 成员变量 成员方法 访问特点总结 多态对比普通继承 普通继承优点与缺点 多态优点与缺点 向上转型与向下转型 向下转型存在的问题 多态接口练习 Java面向对象与多态 多态介绍 在前面学习到…...

redis分布式锁和lua脚本
业务场景:多个线程对共同资源的访问:库存超卖/用户重复下单的原因 解决方法一:利用jvm内置锁,将非原子性操作变成原子性操作 Synchronized锁的是对象,对象必须是单例的。锁的是this,代表当前所在的类,这个…...
---service层核心)
项目实战 ---- 商用落地视频搜索系统(5)---service层核心
目录 背景 向下service 层 描述 功能 代码实现 核心阐述 向上service层 描述 功能 代码实现 核心阐述 背景 之前的 1-4 重点在介绍系统的实现架构,录入数据的组织形式,存储模式,search 方式,以及后期算法等。重点都是聚焦在后端。现在来看,基本的后端实现我们…...
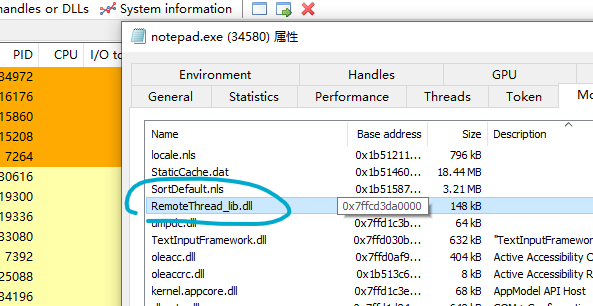
Win32远线程注入
远线程注入 远线程(RemoteThread)注入是指一个进程在另一个进程中创建线程的技术,这是一种很经典的DLL注入技术。 虽然比较古老,但是很实用。通过远线程注入,再配合api函数的hook技术,可以实现很多有意思的功能。 实现远线程注入…...

CTF 竞赛密码学方向学习路径规划
目录 计算机科学基础计算机科学概念的引入、兴趣的引导开发环境的配置与常用工具的安装Watt Toolkit(Steam)、机场代理Scoop(Windows 用户可选)常用 Python 库SageMathLinux小工具 yafuOpenSSL Markdown编程基础Python其他编程语言…...

2024数学建模国赛B题代码
B题已经完成模型代码!详情查看文末名片 问题1:可以考虑使用统计学中的“样本量估算”方法,使用二项分布或正态近似来决定最少的样本量,并通过假设检验(如单侧检验)在95%和90%置信度下进行判断。 import n…...

PyTorch 卷积层详解
PyTorch 卷积层详解 卷积层(Convolutional Layers)是深度学习中用于提取输入数据特征的重要组件,特别适用于处理图像和序列数据。PyTorch 提供了多种卷积层,分别适用于不同维度的数据。本文将详细介绍这些卷积层,特别…...

智慧无人机巡检-无人机可见光红外数据集 无人机多模态检测数据集 红外与可见光检测数据集
智慧无人机巡检-无人机可见光红外数据集,已完成标注,可导出各种常用数据集,yolo,voc,coco等格式。可见光33000张,红外16100张,目标一张一个 无人机可见光红外目标数据集项目详细信息数据集名称无…...

终极免费方案:WandEnhancer完整解锁WeMod Pro功能快速指南
终极免费方案:WandEnhancer完整解锁WeMod Pro功能快速指南 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 你是否渴望享受WeMod Pro会员的所…...

Unity塔防底层架构:ScriptableObject驱动的数据契约设计
1. 这不是“又一个塔防模板”,而是塔防开发的底层操作系统我第一次在Asset Store点开Tower Defense Toolkit 4(TDTK-4)的预览图时,下意识划走了——界面太“干净”了,没有炫酷的粒子特效演示,没有满屏飞舞的…...

【C++】零基础入门 · 第 5 节:函数基础
前面四节我们写的代码都集中在 main 函数里。随着程序变复杂,所有逻辑堆在一起会越来越难维护。函数就是用来解决这个问题的——它把一段代码「打包」起来,取个名字,需要的时候调用就行。 1. 为什么需要函数 假设你需要在程序的不同地方打印一行分隔线: cout << &…...

Windows键盘重映射终极指南:如何使用SharpKeys专业解决方案告别误触烦恼
Windows键盘重映射终极指南:如何使用SharpKeys专业解决方案告别误触烦恼 【免费下载链接】sharpkeys SharpKeys is a utility that manages a Registry key that allows Windows to remap one key to any other key. 项目地址: https://gitcode.com/gh_mirrors/sh…...

具身智能的发展对人类社会的影响有哪些?
具身智能对人类社会影响一、经济产业层面产业重构:催生机器人、智能制造、自动驾驶新产业,重塑生产链条效率跃升:替代重复繁重劳作,工厂、农业、物流产能大幅提升就业结构变化:低端体力岗位缩减,运维、研发…...
)
DeepSeek注释质量跃迁路径(附12个真实项目对比数据+可复用Prompt模板)
更多请点击: https://codechina.net 第一章:DeepSeek注释质量跃迁路径(附12个真实项目对比数据可复用Prompt模板) 高质量代码注释不再是“锦上添花”,而是模型理解意图、团队高效协同与长期可维护性的核心基础设施。…...

LLM驱动的高性能计算日志解析技术实践
1. 项目概述:LLM驱动的HPC日志解析革命高性能计算(HPC)系统如同数字世界的巨型望远镜,每天产生PB级的观测数据——系统日志。这些日志记录了从硬件底层到应用层的所有活动,但它们的价值长期被埋没在非结构化文本的泥沼中。传统日志解析方法就…...

量子机器学习多编码框架MEDQ:提升模型泛化能力与参数效率
1. 项目概述:为什么量子机器学习需要“多编码”?量子机器学习(QML)这几年火得不行,但真正上手做过的人都知道,它有个挺让人头疼的“怪病”:模型在某些数据集上表现神勇,换到另一个看…...

如何快速上手SoundMind:10分钟完成音频逻辑推理模型训练
如何快速上手SoundMind:10分钟完成音频逻辑推理模型训练 【免费下载链接】SoundMind We introduce the Audio Logical Reasoning (ALR) dataset, consisting of 6,446 text-audio annotated samples specifically designed for complex reasoning tasks. Building o…...