hadoop之MapReduce框架原理

目录
MapReduce框架的简单运行机制:
Mapper阶段:
InputFormat数据输入:
切片与MapTask并行度决定机制:
job提交过程源码解析:
切片逻辑:
1)FileInputFormat实现类
进行虚拟存储
(1)虚拟存储过程:
Shuffle阶段:
排序:
Combiner合并:
ReduceTask阶段:
Reduce Join:
Map Join:
MapReduce框架的简单运行机制:
MapReduce是分为两个阶段的,MapperTask阶段,和ReduceTask阶段。(中间有一个Shuffle阶段)
Mapper阶段,可以通过选择什么方式(K,V的选择对应不同的方法)来读取数据,读取后把数据交给Mapper来进行后续的业务逻辑(用户写),让后进入Reduce阶段通过Shuffle来拉取Mapper阶段的数据,让后通过OutputFormat(等方法)来写出(可以是ES,mysql,hbase,文件)
Mapper阶段:
InputFormat数据输入:
切片与MapTask并行度决定机制:
MapTask个数,决定了并行度(相当于在生成map集合的过程中有几个人在干活),**(不一定越多越好,当数据量小的时候可能开启的众多MapTask的时间用一个MapTask已经计算完成)
数据块:Block是HDFS物理上把数据分成一块一块。数据块是HDFS存储数据单位。
数据切片:数据切片只是在逻辑上对输入进行分片,并不会在磁盘上将其切分成片进行存储。数据切片是MapReduce程序计算输入数据的单位,一个切片会对应启动一个MapTask。

job提交过程源码解析:
因为我们找的job提交,所以在job提交函数哪里打个断点,
步入函数后
ensureState(JobState.DEFINE); 是确保你的状态是正确的(状态不对或者running 都会抛异常)
setUseNewAPI(); 处理Hadoop不同版本之间的API兼容
connect(); 连接,(客户端需要与集群或者本机连接)
checkSpecs(job); 校验 校验输出路径是否已经创建,是否有参return submitter.submitJobInternal(Job.this, cluster); 核心代码 步入的时候需要点两下,
第一个步入是步入的参数Job 第二个才步入此方法
这个方法是提交job(在集群模式下,提交的job包含(通过客户端方式把jar包提交给集群),在本地不需要提交jar包,jar在本地是存在的)
还会进行切片,生成切片信息(几个切片就有几个MapTask)
还会 生成xml文件
综上 job提交会交三样东西(jar,xml文件,切片信息---》集群模式下)
最后会删除所有的信息文件
切片逻辑:
**(切片是每一个文件单独切片)
在本地是32m一块,前边说过,默认一块对应一个切片,但是有前提条件,再你减去32m的时候,余下最后一块如果大于1.1倍就重新分配切片,但如果小于1.1,则不能更新分片
例子1:
已有一个32.1m的数据 物理分块是(32m+0.1m)切片分布是(1个切片,因为32.1/32=1.003125<1.1 所以使用一个切片)
例子2:
已有一个100m的数据
100-32-32=36>32(36/32=1.125>1.1 所以最后36m需要分配两个切片)
**块的大小没办法改变,但是可以调切片大小(maxSize让切片调小)(minSize让切片调大)
 切片总结:
切片总结:


(开一个MapTask 默认是占1g内存+1个cpu)

1)FileInputFormat实现类
思考:在运行MapReduce程序时,输入的文件格式包括:基于行的日志文件、二进制格式文件、数据库表等。那么,针对不同的数据类型,MapReduce是如何读取这些数据的呢?
FileInputFormat常见的接口实现类包括:TextInputFormat、KeyValueTextInputFormat、NLineInputFormat、CombineTextInputFormat和自定义InputFormat等。(应用场景的不同选择不同的接口实现类)
TextInputFormat是默认的FileInputFormat实现类。按行读取每条记录。键是存储该行在整个文件中的起始字节偏移量, LongWritable类型。值是这行的内容,不包括任何行终止符(换行符和回车符),Text类型。
CombineTextInputFormat用于小文件过多的场景,它可以将多个小文件从逻辑上规划到一个切片中,这样,多个小文件就可以交给一个MapTask处理。
进行虚拟存储
(1)虚拟存储过程:
将输入目录下所有文件大小,依次和设置的setMaxInputSplitSize(切片大小)值比较,如果不大于设置的最大值,逻辑上划分一个块。如果输入文件大于设置的最大值且大于两倍,那么以最大值切割一块;当剩余数据大小超过设置的最大值且不大于最大值2倍,此时将文件均分成2个虚拟存储块(防止出现太小切片)。

测试:
再不使用CombineTextInputFormat情况下(默认TextInputFormat) 
可以看到切片为4
添加代码,设置实现类为CombineTextInputFormat 和 设置虚拟存储切片大小
// 如果不设置InputFormat,它默认用的是TextInputFormat.class
job.setInputFormatClass(CombineTextInputFormat.class);//虚拟存储切片最大值设置4m
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304); 
可以看到,现在是3个切片
我们可以通过改变虚拟切片大小来改变调用的切片的数量
综上:影响切片的数量的因素为:(1)数据量的大小(2)切片的大小(一般会自动调整)(3)文件格式(有些文件是不可切片的)
影响切片大小的因素: HDFS中块的大小(通过调maxsize,minsize与块的大小进行比较来判断)
Shuffle阶段:
shuffle阶段是一个从mapper阶段出来的后的阶段,会写入(k,v)一个环形缓冲区(缓冲区分为两半,一半存储索引,一半存储数据,默认100m,到达80%后会反向逆写(减少时间消耗,提高效率,逆写是因为不需要等待全部溢写后在进行写入操作)逆写入文件前会进行分区(分区的个数与reduceTask的个数有关)排序(对key进行排序,但是存储位置并不发生改变,只改变索引的位置,改变存储位置消耗资源较大))写入文件后会进行归并排序(在有序的情况下,归并是最高效的))
排序:
排序可以自定义排序,举例全排序:
自定义了一个Bean类,bean对象做为key传输,需要实现WritableComparable接口重写compareTo方法,就可以实现排序。
Combiner合并:
并不满足所有生产环境下,只有在不影响最终业务逻辑下才可以实现(求和就可以,算平均值就不可以)
combiner与reducetask区别如下:

ReduceTask阶段:
(1)Copy阶段:ReduceTask从各个MapTask上远程拷贝一片数据,并针对某一片数据,如果其大小超过一定阈值,则写到磁盘上,否则直接放到内存中。
(2)Sort阶段:在远程拷贝数据的同时,ReduceTask启动了两个后台线程对内存和磁盘上的文件进行合并,以防止内存使用过多或磁盘上文件过多。按照MapReduce语义,用户编写reduce()函数输入数据是按key进行聚集的一组数据。为了将key相同的数据聚在一起,Hadoop采用了基于排序的策略。由于各个MapTask已经实现对自己的处理结果进行了局部排序,因此,ReduceTask只需对所有数据进行一次归并排序即可。
(3)Reduce阶段:reduce()函数将计算结果写到HDFS上。
ReduceTask的个数可以手动进行设置,设置几就会产生几个文件(分区同上)
Reduce Join:
简述流程:
(1)自定义bean对象(序列化反序列化函数---implements Writable)
(2)写mapper类 先重写setup方法(因为本案例需要两个文件,初始化(读多个文 希望先获取到文件名称(多文件) 一个文件一个切片 setup方法是一个优化手段 获取文件名称)
(3)写reduce类(业务逻辑) 先创建一个集合(类型为bean类型)和bean对象用于存储
用for循环遍历value(key是一样的 一样的key才会进入同一个reduce方法)
获取文件名判断写出不同的业务逻辑
"order"表:
先创建一个bean对象,用于存储数据,用于后续写入集合
用到方法 BeanUtils.copyProperties(tmpOrderBean,value); 获取原数据
让后加入上述创建的集合 orderBeans.add(tmpOrderBean);
“pd”表:
BeanUtils.copyProperties(pdBean,value);直接获取原数据
存储结束,结合阶段:
使用增强for
orderbean.setPname(pdBean.getPname());
使用set函数直接设置集合中的pname
让后写入
context.write(orderbean,NullWritable.get()); 业务结束
Reduce Join的缺点:这种方式中,合并的操作是在Reduce阶段完成,Reduce端的处理压力太大,Map节点的运算负载则很低,资源利用率不高,且在Reduce阶段极易产生数据倾斜。
Map Join:
使用场景
Map Join适用于一张表十分小、一张表很大的场景。
Map端实现数据合并就解决了Reduce Join的缺点(数据倾斜)
简述流程:
在map类中
setup方法:将较小文件读入缓存,将数据存储到全局的map集合中,将缓存中的数据全部写入
重写的map方法中:
转换成字符串在切割,通过切割后的数组获取map集合中的pname
让后重新设置输出文件的格式进行写出
(至此mapreduce完结!!!!)
相关文章:
hadoop之MapReduce框架原理
目录 MapReduce框架的简单运行机制: Mapper阶段: InputFormat数据输入: 切片与MapTask并行度决定机制: job提交过程源码解析: 切片逻辑: 1)FileInputFormat实现类 进行虚拟存储 &#x…...
JavaEE简单示例——SpringMVC的简单数据绑定
简单介绍: 在前面我们介绍过如何将我们自己创建的类变成一个servlet来处理用户发送的请求,但是在大多数的时候,我们在请求 的时候会携带一些参数,而我们现在就开始介绍我们如何在Java类中获取我们前端请求中携带的参数。首先&…...

耗时的同步请求自动转异步请求
耗时的同步请求自动转异步请求问题描述问题处理代码实现问题描述 现在在项目中碰到一个情况,导出数据到excel,在数据量比较下的时候直接下载,在数据量比较大时保存到服务的文件列表,后续再供用户下载。 也就是需要避免前端因后端…...

React常见的hook
目录 useState useEffect useRef useContext useCallback useMemo useState const [初始值,修改值的方法] useState( 初始值 ) 我们用useState定义一个初始值,可以打印看一下结果 console.log(useState(10)) // [10, ƒ] 结果是一个数组…...

Oracle集群管理ASM-扩容磁盘组报错ora-15137
1 内容描述 今日对19c集群磁盘组进行扩容, [rootdb1 ~]# oracleasm createdisk DATA7 /dev/sdm1 Writing disk header: done Instantiating disk: done [rootdb1 ~]# oracleasm createdisk DATA8 /dev/sdn1 Writing disk header: done Instantiating disk: done 使…...

TryHackMe-biteme(boot2root)
biteme 远离我的服务器! 端口扫描 循例 nmap Web枚举 打开一看是一个默认页面 扫一波 打thm这么久,貌似还是第一次见带验证码的登录 信息有限,对着/console再扫一波 查看/securimage 但似乎没有找到能利用的信息 回到console, 在源码发现…...
vue开发常用的工具有哪些
个人简介:云计算网络运维专业人员,了解运维知识,掌握TCP/IP协议,每天分享网络运维知识与技能。座右铭:海不辞水,故能成其大;山不辞石,故能成其高。个人主页:小李会科技的…...

数组,排序,查找
数组可以存放多个同一类型的数据,数组也是一种数据类型,是引用类型。 数组可以通过下标来访问元素下标是从0开始编号的比如第一个元素就是hens[0]数组定义,数据类型 数组名[] new 数据类型[大小];int a[] new int[5];动态初始化 import ja…...

redis中序列化后的对象后当如何修改
redis中序列化Redis 中存储的序列化对象是不可变需要频繁修改对象属性, 我存储对象为hash结构如何?总结君问归期未有期,巴山夜雨涨秋池。——唐代李商隐《夜雨寄北》 Redis 中存储的序列化对象是不可变 在 Redis 中存储的序列化对象是不可变的,因为它们…...

膜拜!阿里自爆十万字Java面试手抄本,脉脉一周狂转50w/次
最近,一篇题为《阿里十万字Java面试手抄本》的文章在社交媒体平台上引起了广泛关注。这篇文章由一位阿里工程师整理了阿里Java面试的经验,并分享给了大家。这篇文章一经发布,就在短时间内获得了数十万的转发量,让许多Java程序员受…...

Yolov5改进: Yolov5-FasterNet网络推理加速
文章目录 1. FasterNet介绍1. 1 FasterNet性能1.2 FasterNet作为Backbone2. 基于C3-Faster实现Yolov5 轻量化2.1 C3-Faster的实现2.2 C3-Faster 在YOLOv5中的使用(1) 在common.py 中添加`C3-Faster`代码(2) 修改yolo.py 中的代码(2) 修改yolov5 yaml文件3. 训练1. FasterNet介绍…...
)
在ubuntu下安装五笔输入法(百度输入法)
想要在ubuntu下安装一款合适的五笔输入法,不是一件容易的事。现在我找到了一个好用的输入法分享给大家。 环境:Ubuntu22.04桌面版。 软件:百度Linux输入法-支持全拼、双拼、五笔 步骤一: 需要大家先下载百度的五笔输入法。 http…...
python自动发送邮件(html、附件等),qq邮箱和网易邮箱发送和回复
在python中,我们可以用程序来实现向别人的邮箱自动发送一封邮件,甚至可以定时,如每天8点钟准时给某人发送一封邮件。今天,我们就来学习一下,如何向qq邮箱,网易邮箱等发送邮件。 一、获取邮箱的SMTP授权码。…...

数学-快速幂
从一个简单的问题说起: 给出整数m,n和p,要求计算(m ^ n) % p的结果。 #include <iostream> using namespace std;int main() {long long m, n, p;cin >> m >> n >> p;long long ans 1;for (long long i 0; i < …...

DevEco鸿蒙应用开发-第一个App
目录下载开发环境创建工程登录华为账户测试应用下载开发环境 前往官网下载 DevEco 开发环境:https://developer.harmonyos.com/cn/develop/deveco-studio#download 下载并安装,请记住你选择的 IDE 与 SDK 安装位置,后续可能会用到ÿ…...
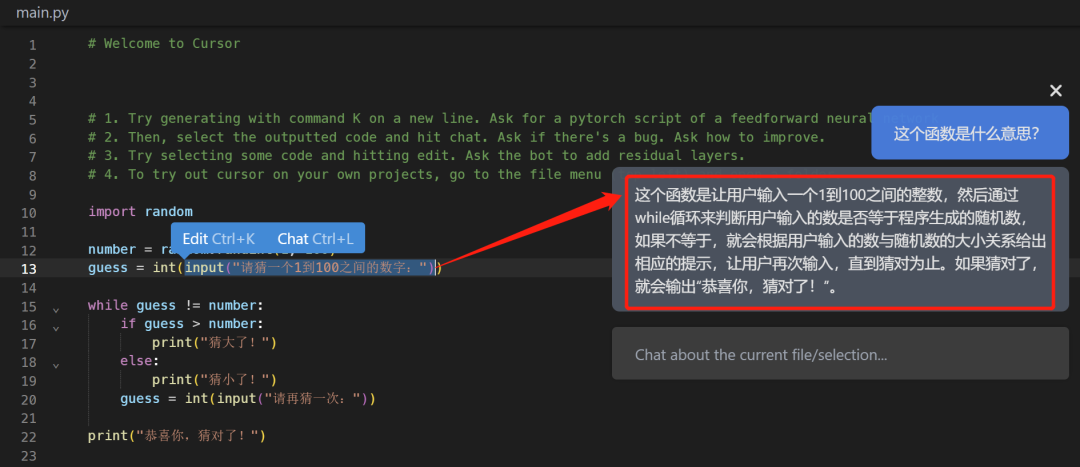
又一款全新的基于 GPT4 的 Python 神器Cursor,关键还免费
chartgpt大火之后,随之而来的就是一大类衍生物了。 然后,今天要给大家介绍的是一款基于GPT4的新一代辅助编程神器——Cursor。 它最值得介绍的地方在于它免费,我们可以直接利用它来辅助我们编程,真正做到事半功倍。 注意&#…...

CSS的浮动(下)
🌟所属专栏:前端只因变凤凰之路🐔作者简介:rchjr——五带信管菜只因一枚😮前言:该系列将持续更新前端的相关学习笔记,欢迎和我一样的小白订阅,一起学习共同进步~👉文章简…...

软件测试-性能测试流程
压测任务具体包含: 0.前期准备 尽量参与业务需求评审,可以对业务有更深入的了解,了解哪些功能是核心功能,哪些可能存在性能瓶颈,以便在性能需求评审的时候能给出有建设性的意见 1.性能需求分析、评审 明确测试范围(哪些业务接口)、目标(tps、rt、成功率) 关于性能需…...

【python实操】年轻人,别用记事本保存数据了,试试数据库吧
为什么用数据库? 数据库比记事本强在哪? 答案很明显,你的文件很多时候都只能被一个人打开,不能被重复打开。当有几百万数据的时候,你如何去查询操作数据,速度上要快,看起来要清晰直接 数据库比我…...
铁威马NAS教程之利用docker快速搭建个人在线书库
这是一个基于Calibre的简单的图书管理系统,支持在线阅读。主要特点是:美观的界面、支持多用户、支持在线阅读、支持邮件推送、支持OPDS、支持一键安装,网页版初始化配置,轻松启动网站等等。 那么,如何利用docker快速搭…...
Pixel Epic智识终端效果展示:跨领域研报生成一致性与专业性验证
Pixel Epic智识终端效果展示:跨领域研报生成一致性与专业性验证 1. 产品概览与核心价值 Pixel Epic智识终端是一款基于AgentCPM-Report大模型构建的专业研究报告生成工具。与传统AI工具不同,它创新性地采用了像素RPG游戏的美学设计,将枯燥的…...

探索DeepCAD:基于深度学习的CAD模型生成技术入门
探索DeepCAD:基于深度学习的CAD模型生成技术入门 【免费下载链接】DeepCAD code for our ICCV 2021 paper "DeepCAD: A Deep Generative Network for Computer-Aided Design Models" 项目地址: https://gitcode.com/gh_mirrors/de/DeepCAD 副标题&…...
translategemma-4b-it优化升级:Ollama部署后提升翻译质量的4个技巧
translategemma-4b-it优化升级:Ollama部署后提升翻译质量的4个技巧 你已经成功用Ollama部署了translategemma-4b-it,看着它把图片里的英文变成中文,是不是觉得挺神奇的?但用了几次后,你可能会发现一些问题:…...

快马ai一键生成:windows 11自动化部署openclaw环境原型脚本
最近在折腾Windows 11的开发环境配置,发现每次换新机器都要重复安装一堆工具链特别麻烦。正好发现了OpenClaw这个开源工具,它号称能自动化搞定开发环境部署。不过手动安装配置还是有点繁琐,于是我用InsCode(快马)平台快速生成了一个自动化安装…...

3分钟搞定加密音乐:Unlock-Music浏览器解密终极指南
3分钟搞定加密音乐:Unlock-Music浏览器解密终极指南 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: https:/…...

LFM2.5-1.2B-Thinking多场景落地:Ollama支持下的技术博客写作、论文摘要生成案例
LFM2.5-1.2B-Thinking多场景落地:Ollama支持下的技术博客写作、论文摘要生成案例 你是不是也遇到过这样的烦恼:想写一篇技术博客,对着空白的文档发呆半天,不知道从何下笔;或者面对一篇几十页的学术论文,需…...

基于SpringBoot + Vue的校园流浪动物救助平台
文章目录前言一、详细操作演示视频二、具体实现截图三、技术栈1.前端-Vue.js2.后端-SpringBoot3.数据库-MySQL4.系统架构-B/S四、系统测试1.系统测试概述2.系统功能测试3.系统测试结论五、项目代码参考六、数据库代码参考七、项目论文示例结语前言 💛博主介绍&#…...

程序员副业变现全攻略
CSDN程序员副业图谱技术文章大纲副业方向分类技术变现类:外包开发、技术咨询、代码审核内容创作类:技术博客、视频教程、电子书编写产品开发类:独立应用、开源项目、插件工具教育培训类:在线课程、一对一辅导、技术直播技术栈与工…...

Phi-4-mini-reasoning应用场景:数学建模竞赛辅助推导与公式生成
Phi-4-mini-reasoning应用场景:数学建模竞赛辅助推导与公式生成 1. 模型概述与核心能力 Phi-4-mini-reasoning是一款由微软开发的轻量级开源模型,专为数学推理、逻辑推导和多步解题等强逻辑任务设计。这个3.8B参数的模型虽然体积小巧,但在数…...

Cogito 3B实战案例:GitHub PR描述自动生成+变更点总结
Cogito 3B实战案例:GitHub PR描述自动生成变更点总结 1. 快速了解Cogito 3B模型 Cogito v1预览版是Deep Cogito推出的混合推理模型系列,这个3B版本在大多数标准基准测试中都表现出色,超越了同等规模的其他开源模型。简单来说,它…...