RTX AI PC 和工作站上部署多样化 AI 应用支持 Multi-LoRA

今天的大型语言模型(LLMs)在许多用例中都取得了前所未有的成果。然而,由于基础模型的通用性,应用程序开发者通常需要定制和调整这些模型,以便专门针对其用例开展工作。
完全微调需要大量数据和计算基础设施,从而更新模型权重。此方法需要在GPU显存上托管和运行模型的多个实例,以便在单个设备上提供多个用例。
示例用例包括多语言翻译助手,用户需要同时获得多种语言的结果。这可能会给设备上的 AI 带来挑战,因为内存限制。
在设备显存上同时托管多个LLM几乎是不可能的,尤其是在考虑运行合适的延迟和吞吐量要求以与用户进行交互时另一方面,用户通常在任何给定时间运行多个应用和任务,在应用之间共享系统资源。
低秩适配(LoRA)等高效的参数微调技术可帮助开发者将自定义适配器连接到单个 LLM,以服务于多个用例。这需要尽可能减少额外的内存,同时仍可提供特定于任务的 AI 功能。该技术使开发者能够轻松扩展可在设备上服务的用例和应用程序的数量。
NVIDIA RTX AI 工具包的一部分 NVIDIA TensorRT-LLM 现已提供 Multi-LoRA 支持。这项新功能使 NVIDIA RTX AI PC 和工作站能够在推理期间处理各种用例。
LoRA 简介
LoRA 是一种热门的参数高效微调技术,可以调节少量参数。其他参数称为 LoRA 适配器,表示网络密集层中变化的低秩分解。
只有这些低级别的附加适配器是自定义的,而在此过程中,模型的剩余参数会被冻结。经过训练后,这些适配器将在推理期间通过合并到基础模型进行部署,从而在推理延迟和吞吐量方面尽可能减少,甚至不增加任何开销。
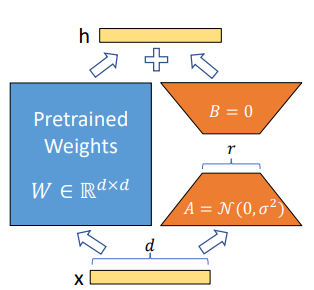
图 1. A 和 B 中的参数表示可训练的参数,以展示 LoRA 技术(来源:LoRA:大型语言模型的低阶适应)
图 1 展示了有关 LoRA 技术的更多详细信息。
- 在自定义期间,预训练模型的权重 (W) 将被冻结。
- 我们不会更新 W,而是注入两个较小的可训练矩阵(A 和 B)来学习特定于任务的信息。矩阵乘法 B*A 会形成一个与 W 具有相同维度的矩阵,因此可以将其添加到 W (= W + BA) 中。
A 和 B 矩阵的秩是 8、16 等较小的值。此秩 (r) 参数可在训练时自定义。更大的秩值使模型能够捕获与下游任务相关的更多细微差别,通过更新模型中的所有参数来接近完全监督式微调的能力。
缺点是,在内存和计算要求方面,更大的秩用于训练和推理的成本也更高。在实践中,使用小至 8 的秩值进行 LoRA 微调已经非常有效,并且是许多下游任务的良好起点。
如今,RTX AI 工具包支持量化和低排名自适应 (QLoRA) (LoRA 技术的变体),以在 RTX 系统上执行参数高效的微调。这项技术经过调整可减少内存占用。
在反向传播过程中,梯度通过冻结的 4 位量化预训练模型传递到低秩适配器。QLoRA 算法可有效节省内存,同时不会牺牲模型性能。有关 QLoRA 的更多信息,请参阅以下论文。
TensorRT-LLM 中的 Multi-LORA 支持
借助 TensorRT-LLM 中的最新更新,RTX AI 工具包现在能够在本地支持在推理时通过单个量化碱基检查点为多个 LoRA 适配器提供服务。这项新技术能够通过 INT4 量化碱基模型检查点为多个 FP16 LoRA 适配器提供服务。
混合精度部署在 Windows PC 环境中非常有用,因为它们的内存有限,必须在应用之间共享。混合精度部署可以减少模型存储和推理所需的内存,而不会影响模型质量或使用自定义模型为多个客户端提供服务的能力。
开发者可以通过多种方法在其应用中部署多个 LoRA 网卡,其中包括以下内容。
单 LoRA 网卡部署
在这个设置中,开发者选择针对每个请求激活哪个 LoRA 适配器,以便更好地提供专门内容。例如,语言学习应用程序可以在针对不同语言进行微调的适配器之间进行切换,从而根据用户当前的需求提供集中练习。
适用于单个请求的并发 LoRA 适配器(批量模式)
在此方法中,单个输入提示会生成多个不同的响应,每个响应均由不同的 LoRA 适配器在批量模式下生成。这对于多语种虚拟助理等复杂应用程序非常有用,其中一个查询可以同时生成英语、西班牙语和日语的响应,每个响应都由特定的适配器定制。
用于多个请求的并发 LoRA 适配器(批量模式)
此方法同时处理多个输入提示。每个提示都与不同的 LoRA 适配器配对,并生成多个输出提示。例如,多个 PC 应用程序向同一模型发送推理请求,并根据请求选择不同的适配器,以确保每个应用程序都收到特定于其需求的定制响应。
详细了解 TensorRT-LLM 对多个 LoRA 适配器检查点的支持。
在 RTX PC 上展示 Multi-LoRA 的强大功能
为了展示多 LoRA 支持的强大功能,我们开发了一个示例应用程序,该应用程序专为故事创建和插图而设计,只需一个提示即可完成,该过程分为两个关键步骤展开。
- 用户输入一个故事的基本思路,然后Llama 3模型完善了这个概念,扩展了最初的想法,提供了详细的基础。
- 该应用程序使用相同的 Llama 3 模型(现已通过两个不同的 LoRA 适配器进行增强),以进一步优化故事并生成相应的图像。一个 LoRA 适配器生成 Stable Diffusion 提示,用于通过本地部署的 Stable Diffusion XL 模型以直观方式说明故事。另一个经过微调,可用于编写故事,并制作结构化良好且引人入胜的叙事。
此方法可确保流程所需的空间不会显著增加,因为两个通道都使用相同的模型。第二个通道涉及文本和图像生成,使用批量推理执行,从而使流程快速高效。用户可以快速迭代不同版本的故事,轻松优化叙事和插图。
通过在此简化的两步流程中使用 multi-LoRA 支持,我们展示了如何通过单个提示最大限度地提高创意和计算效率。以下是一组输入-输出对示例。
User Prompt:Generated Story:
*The Whispering Woods*In the heart of the Whispering Woods, a legend whispered among the ancient trees spoke of a green giant, said to possess the secrets of the forest. The giant, named Eira, was rumored to be able to communicate with the trees themselves, and its presence was said to bring balance and harmony to the forest. One day, a young adventurer named Lyra stumbled upon the clearing where Eira was said to reside. As she approached the giant, she felt an eerie silence fall over the clearing, as if the trees themselves were holding their breath in anticipation. Eira's massive form loomed before her, its skin a deep, mossy green that seemed to blend seamlessly into the surrounding foliage. The giant's eyes, like ancient pools of wisdom, gazed down at Lyra with a gentle intensity.As she drew closer, Lyra noticed that the trees around her were indeed communicating with Eira, their leaves rustling softly to convey ancient secrets and whispers of the forest. The air was thick with the scent of damp earth and decaying leaves, and Lyra felt the weight of the forest's history bearing down upon her.Eira's voice, like a gentle breeze, whispered secrets to the trees, and they responded with soft murmurs and creaks. Lyra felt a sense of wonder wash over her as she realized that the giant was indeed the keeper of the forest's secrets. She reached out a trembling hand, and to her surprise, Eira's massive fingers wrapped around hers, like a gentle giant's grasp.In that moment, Lyra felt the forest's balance and harmony flow through her, and she knew that she had stumbled upon something much greater than a mere legend. As she stood there, surrounded by the ancient trees and the whispers of the forest, Lyra felt a sense of belonging wash over her, as if she had finally found her true home.
图 2. 提示中生成的角色 Eira 图像。
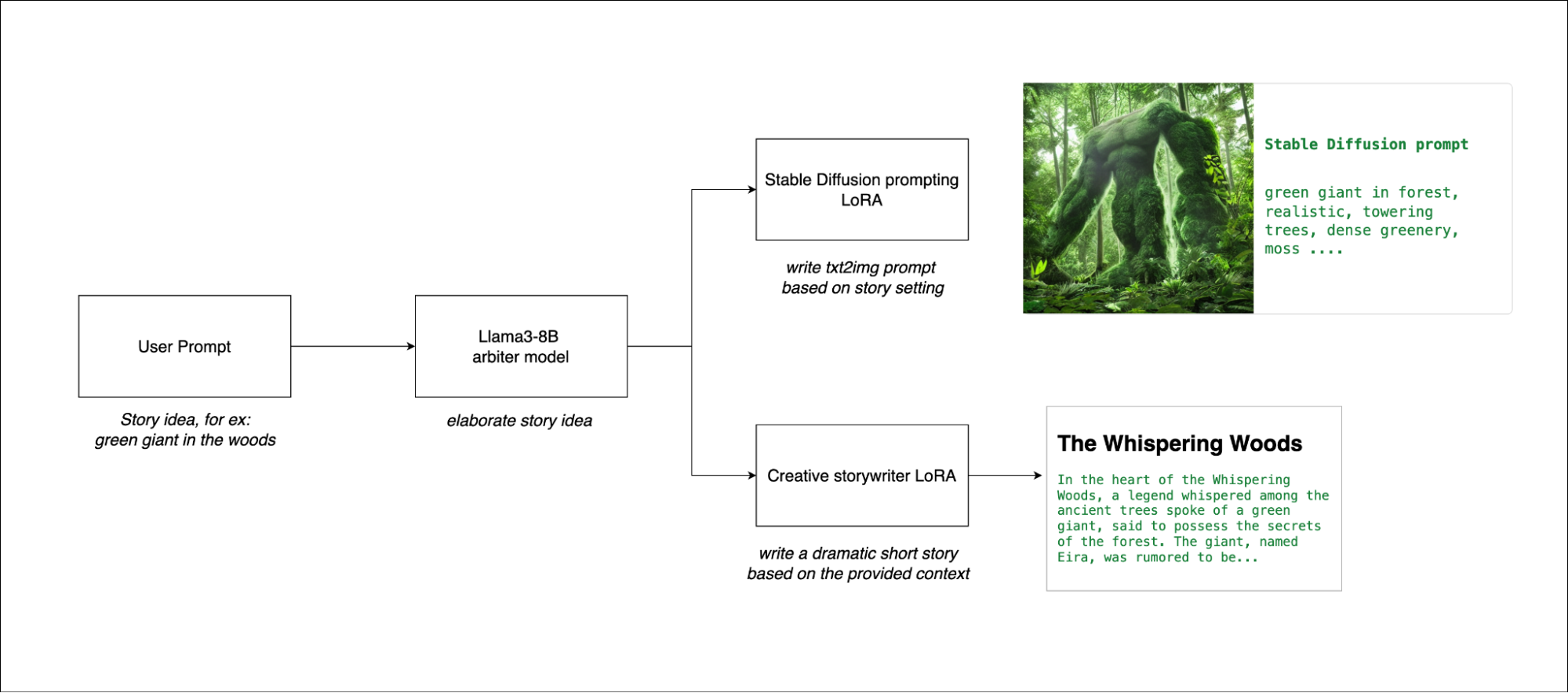
图 3. 使用 Llama3-8B 和 LoRA 的稳定扩散图像。
使用 TensorRT-LLM 在 Windows PC 上加速多 LoRA 用例
下图显示了 NVIDIA 内部测量结果,其中展示了使用 Llama-3-8B 模型的 NVIDIA GeForce RTX 4090 的吞吐量性能,以及使用 TensorRT-LLM 的基础模型和不同批量大小的多个 LoRA 适配器。
结果显示,在输入序列长度为 43、输出序列长度为 100 个令牌时的吞吐量。当批量大小大于 1 时,每个样本都使用唯一的 LoRA 适配器,最大引擎排名为 64。
吞吐量越高,我们发现当运行多个 LoRA 网卡时,性能会降低 3%。
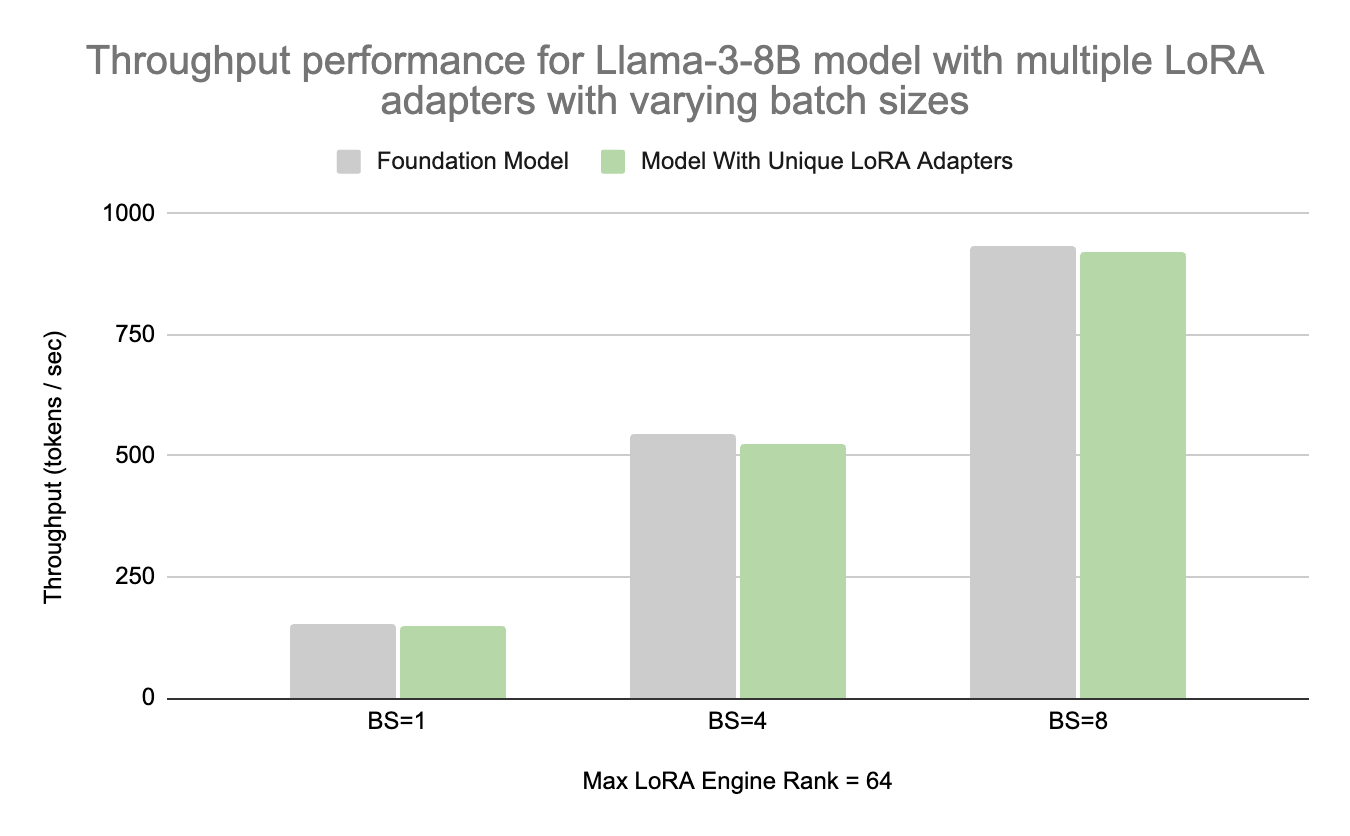
图 4. NVIDIA 内部吞吐量性能测量结果在 RTX 4090 PC 上
图 5 显示了在 RTX 4090 PC 上使用 Llama-3-8B 模型以及使用 TensorRT-LLM 0.11 的预训练基础模型和不同批量大小的多个 LoRA 适配器测量的 NVIDIA 延迟性能。
结果展示了输入序列长度为 43、输出序列长度为 100 个令牌时的延迟。在批量大小大于 1 时,每个样本使用唯一的 LoRA 适配器,最大引擎 rank 为 64。更低的延迟更好,我们看到运行多个 LoRA 适配器时性能降低了约 3%。

图 5. NVIDIA 延迟性能测量结果在 RTX 4090 PC 上
图 4 和图 5 显示,在推理时使用多个 LoRA 适配器时,TensorRT-LLM 0.11 可提供出色的性能,同时尽可能减少不同批量大小的吞吐量和延迟降低。与运行基础模型相比,在使用多个独特的 LoRA 适配器和 TensorRT-LLM 0.11 时,我们发现不同批量大小的吞吐量和延迟性能平均降低了 3%。
后续步骤
借助最新更新,开发者可以在设备上使用 LoRA 技术自定义模型,并在 NVIDIA RTX AI PC 和工作站上使用多 LoRA 支持部署模型,以服务于多个用例。
开始在 TensorRT-LLM 上用 multi-LoRA。
相关文章:
RTX AI PC 和工作站上部署多样化 AI 应用支持 Multi-LoRA
今天的大型语言模型(LLMs)在许多用例中都取得了前所未有的成果。然而,由于基础模型的通用性,应用程序开发者通常需要定制和调整这些模型,以便专门针对其用例开展工作。 完全微调需要大量数据和计算基础设施࿰…...

C++ STL-deque容器入门详解
1.1 deque容器基本概念 功能: 双端数组,可以对头端进行插入删除操作 deque与vector区别: vector对于头部的插入删除效率低,数据量越大,效率越低deque相对而言,对头部的插入删除速度回比vector快vector访…...

数据结构之折半查找
折半查找(Binary Search),也称为二分查找,是一种在有序数组中查找特定元素的搜索算法。其工作原理是,通过不断将待查找的区间分成两半,并判断待查找的元素可能存在于哪一半,然后继续在存在可能性…...

linux高级学习12
24.9.9学习目录 一.条件变量 一.条件变量 通常条件变量和互斥锁同时使用; 条件变量是用来阻塞线程,其本身并不是锁,直到达到特定的要求; (1)条件变量初始化 #include <pthread.h> int pthread_con…...
)
leetcode:3174 清除数字 使用栈,时间复杂度O(n)
3174 清除数字 题目链接 题目描述 给你一个字符串 s 。 你的任务是重复以下操作删除 所有 数字字符: 删除 第一个数字字符 以及它左边 最近 的 非数字 字符。 请你返回删除所有数字字符以后剩下的字符串。 示例 1: 输入:s "abc…...

神经网络卷积操作
文章目录 一、nn.Conv2d二、卷积操作原理三、代码实现卷积操作 一、nn.Conv2d nn.Conv2d 是 PyTorch 中的一个类,它代表了一个二维卷积层,通常用于处理图像数据。在深度学习和计算机视觉中,卷积层是构建卷积神经网络(CNN…...

专题二_滑动窗口_算法专题详细总结
目录 滑动窗口,引入: 滑动窗口,本质:就是同向双指针; 1.⻓度最⼩的⼦数组(medium) 1.解析:给我们一个数组nums,要我们找出最小子数组的和target,首先想到的…...

【机器学习-三-无监督学习】
无监督学习 什么是无监督学习分类聚类降维 有监督和无监督学习的区别 上一节介绍了监督学习,下面来介绍无监督学习,这也是最广泛应用的算法。 什么是无监督学习 上一节中,我们知道了监督学习是通过 对算法,**输入一对数据&#x…...
)
JAVA基础:Lambda表达式(上)
前言 Lambda表达式是jdk1.8的一个新特性,他属于一种语法堂主要作用是对匿名内部类语法简化 lambda基本应用 lambda表达式想要优化匿名内部类是有前提条件,首先必须是一个接口,而且要求接口中只能有1个抽象方法,称之为函数式接口…...

Vue使用fetch获取本地数据
(1)使用get test.json文件 { "list":[111,222,333] } <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initi…...

《酒饮真经》秘籍4,让你的酒场技巧更上一层楼!
在酒桌这一独特的舞台上,每个人都扮演着不同的角色,或攻或守,尽显智慧与风度。对于不擅长喝酒的人来说,如何在推杯换盏间既保护自己又不失礼节,是值得我们仔细研究的。下面是酱酒亮哥为您整理的一系列实用的酒桌攻防秘…...

回车符与快捷键记录
一.在Windows和Linux操作系统中,回车符(或称为换行符)的处理方式区别 1.Windows下的回车符 在Windows系统中,回车符通常是由两个字符组成的序列:回车符(Carriage Return,简称CR,AS…...
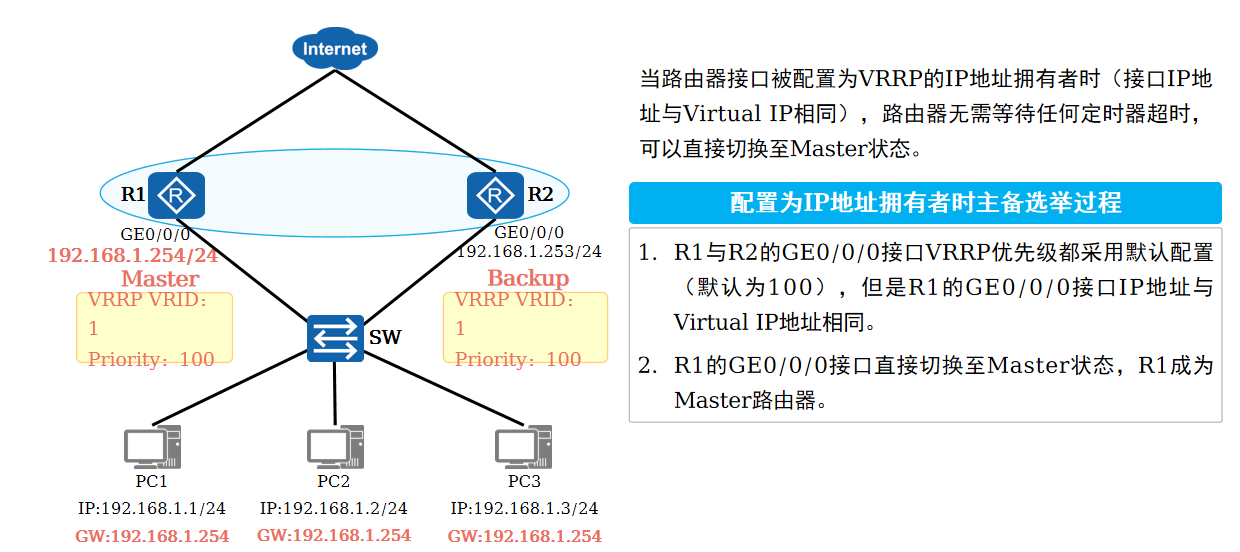
计算机网络-VRRP工作原理
一、VRRP工作原理 前面我们大概了解了VRRP的一些基础概念,现在开始学习VRRP的技术原理。VRRP的选举及工作步骤: 确定网关地址 选举主备 主设备发送VRRP报文通知Backup设备 主设备响应终端ARP并维持在Master状态 终端正常发送报文到网关进行转发 因为我们…...

6.5椒盐噪声
在OpenCV中联合C给一张图片加上椒盐噪声(Salt and Pepper Noise)可以通过随机选择像素点并将其置为黑色(0)或白色(255)来实现。椒盐噪声是一种随机噪声,通常表现为图像中的孤立黑点(…...

CSS样式的引用方式以及选择器使用
1. CSS 引用方式 CSS 可以通过三种方式引用到 HTML 文件中: 行内样式(Inline Styles):直接在 HTML 元素中定义样式。内部样式表(Internal CSS):在 HTML 文档的 <head> 部分使用 <sty…...

Python Flask_APScheduler定时任务的正确(最佳)使用
描述 APScheduler基于Quartz的一个Python定时任务框架,实现了Quartz的所有功能。最近使用Flask框架使用Flask_APScheduler来做定时任务,在使用过程当中也遇到很多问题,例如在定时任务调用的方法中需要用到flask的app.app_context()时&#…...

Linux命名管道
通信的前提是让不同的进程看到同一份资源,因为路径是具有唯一性的,所以我们可以使用路径文件名来唯一的让不同进程看到同一份资源,实现没有血缘关系的两个进程进行管道通信 1.指令级 mkfifio(FILENAME,0666) …...
Xinstall助力App全渠道统计,参数传递下载提升用户体验!
在移动互联网时代,App已成为我们日常生活中不可或缺的一部分。然而,对于App开发者来说,如何有效地推广和运营自己的应用,却是一个不小的挑战。尤其是在面对众多渠道、复杂的数据统计和用户需求多样化的情况下,如何精准…...
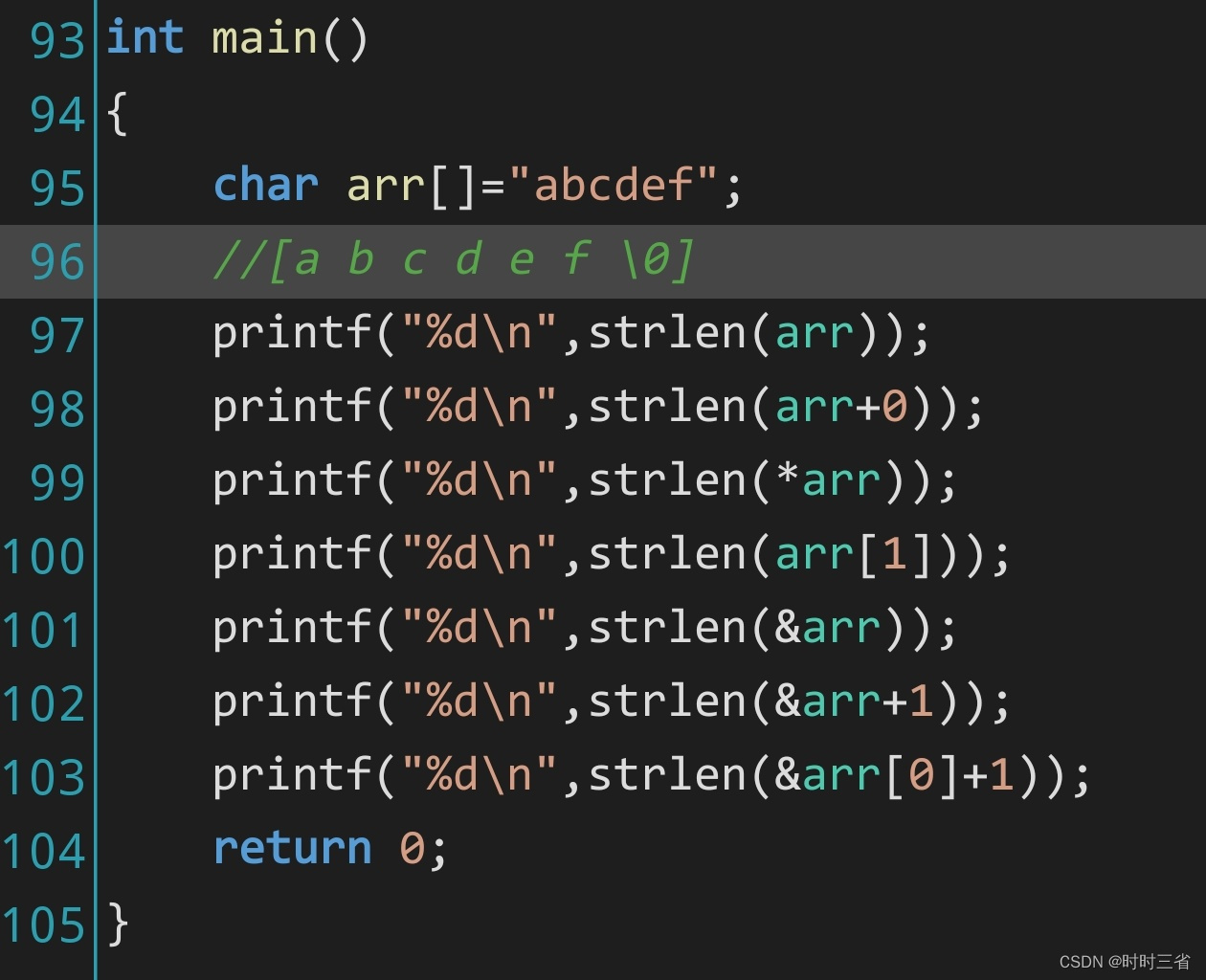
【时时三省】(C语言基础)指针进阶 例题4
山不在高,有仙则名。水不在深,有龙则灵。 ----CSDN 时时三省 strlen是求字符串长度 这个需要算上\0 第一个arr 是打印6 因为它加上\0是有六个元素 第二个arr0 数组名相当于首元素的地址 a的地址加0还是a的地址 所以这个地方还是…...

k8s的配置管理
一、配置管理分为两种: 1. 加密配置:用来保存密码和token密钥对以及其它敏感的k8s资源。 2.应用配置:我们需要定制化的给应用进行配置,我们需要把定制好的配置文件同步到pod当中的容器。 二、加密配置 1.secret三种类型…...

OBS直播教程:OBS多路推流在哪里设置?如何安装?OBS多路推流教程
OBS直播教程:OBS多路推流在哪里设置?如何安装?OBS多路推流教程 具体如何下载?如何安装?如何使用?我写了一个保姆级教程,请往下看,步骤很详细的,你一定看得懂 第一步&…...

免费AI搜索工具怎么选?2026年实测TOP8工具性能、响应速度与隐私合规性深度评测
更多请点击: https://codechina.net 第一章:免费AI搜索工具推荐2026 2026年,开源与社区驱动的AI搜索工具生态迎来爆发式增长。得益于大语言模型轻量化部署、RAG(检索增强生成)架构普及以及WebAssembly在浏览器端的成熟…...

FTP明文传输风险与Wireshark抓包实证分析
1. 这不是危言耸听:FTP 的“裸奔”现状每天都在发生你有没有在公司内网用过 FTP 上传一份财务报表?有没有在校园网里用 FileZilla 向老师提交课程设计源码?有没有在运维后台用 ftp 命令同步过网站静态资源?如果答案是肯定的&#…...

别再硬扛了!书匠策AI把毕业论文拆成了“填空题“,2025届必看科普
各位被毕业论文逼到怀疑人生的朋友们,今天这期内容,我想用一种你从没听过的方式,给你拆解一个工具——书匠策AI( 官网直达:www.shujiangce.com微信搜一搜"书匠策AI"可关注公众号)。 先抛一个扎心…...

为什么你的NotebookLM中文摘要总漏关键信息?3个被官方文档忽略的语言标记陷阱,90%用户正在踩坑
更多请点击: https://kaifayun.com 第一章:NotebookLM多语言支持 NotebookLM 原生支持多种语言的文档理解与对话生成,其底层模型经过多语言语料联合训练,可无缝处理中、英、日、韩、法、德、西等 20 种语言的混合输入。用户上传非…...
3步掌握Windows字体优化:Better ClearType Tuner完整使用指南
3步掌握Windows字体优化:Better ClearType Tuner完整使用指南 【免费下载链接】BetterClearTypeTuner A better way to configure ClearType font smoothing on Windows 10. 项目地址: https://gitcode.com/gh_mirrors/be/BetterClearTypeTuner 你是否曾经在…...

歌词滚动姬:5分钟掌握专业级歌词制作的艺术
歌词滚动姬:5分钟掌握专业级歌词制作的艺术 【免费下载链接】lrc-maker 歌词滚动姬|可能是你所能见到的最好用的歌词制作工具 项目地址: https://gitcode.com/gh_mirrors/lr/lrc-maker 歌词滚动姬(LRC Maker)是一款完全免费…...

ApnsPHP高级应用:自定义消息与批量推送功能全解析
ApnsPHP高级应用:自定义消息与批量推送功能全解析 【免费下载链接】ApnsPHP ApnsPHP: Apple Push Notification & Feedback Provider 项目地址: https://gitcode.com/gh_mirrors/ap/ApnsPHP ApnsPHP是一款强大的Apple Push Notification & Feedback …...

英特尔现代代码开发挑战:实战性能优化与工具链应用指南
1. 项目概述:一场面向开发者的实战演练最近深度参与并复盘了英特尔举办的“现代代码开发挑战”网络研讨会,感触颇深。这远不止是一场普通的技术分享会,而是一个精心设计的、让开发者亲手“触摸”现代硬件性能潜力的实战沙盒。如果你是一名C/C…...
一套代码搞定 App/小程序/H5/PC,私域流量神器)
别再重复造轮子了!这个开源论坛小程序(Java+Uniapp)一套代码搞定 App/小程序/H5/PC,私域流量神器
你是否有过这些想法? 我想做个类似“知识星球”的圈子小程序,但外包报价动辄 5 万起…… 公司要做私域社区,需要同时支持微信小程序和 App,难道要养两个开发团队? 想靠“付费帖子 会员 打赏”变现,去哪…...