AI大模型行业专题报告:大模型发展迈入爆发期,开启AI新纪元
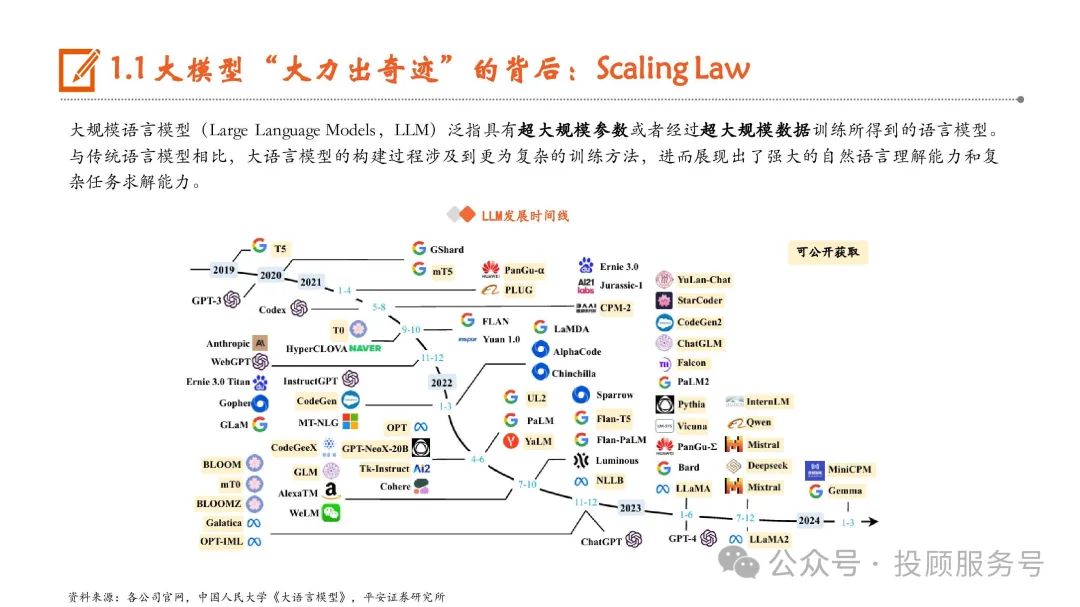
大规模语言模型(Large Language Models,LLM)泛指具有超大规模参数或者经过超大规模数据训练所得到的语言模型。与传统语言模型相比,大语言模型的构建过程涉及到更为复杂的训练方法,进而展现出了强大的自然语言理解能力和复 杂任务求解能力。
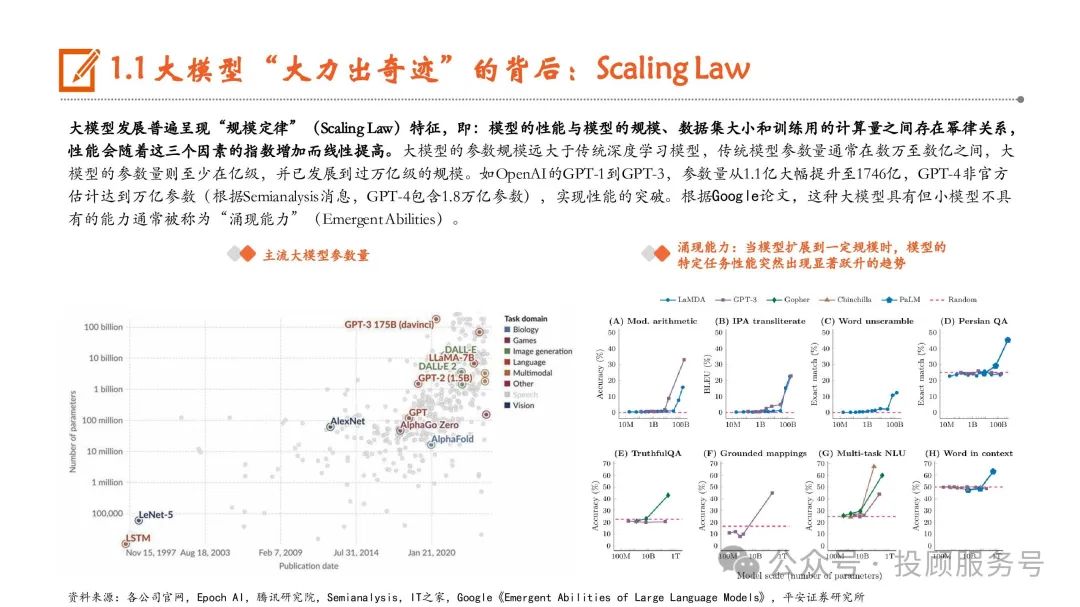
大模型发展普遍呈现“规模定律”(Scaling Law)特征,即:模型的性能与模型的规模、数据集大小和训练用的计算量之间存在幂律关系, 性能会随着这三个因素的指数增加而线性提高。大模型的参数规模远大于传统深度学习模型,传统模型参数量通常在数万至数亿之间,大 模型的参数量则至少在亿级,并已发展到过万亿级的规模。如OpenAI的GPT-1到GPT-3,参数量从1.1亿大幅提升至1746亿,GPT-4非官方 估计达到万亿参数(根据Semianalysis消息,GPT-4包含1.8万亿参数),实现性能的突破。根据Google论文,这种大模型具有但小模型不具 有的能力通常被称为“涌现能力”(Emergent Abilities)。
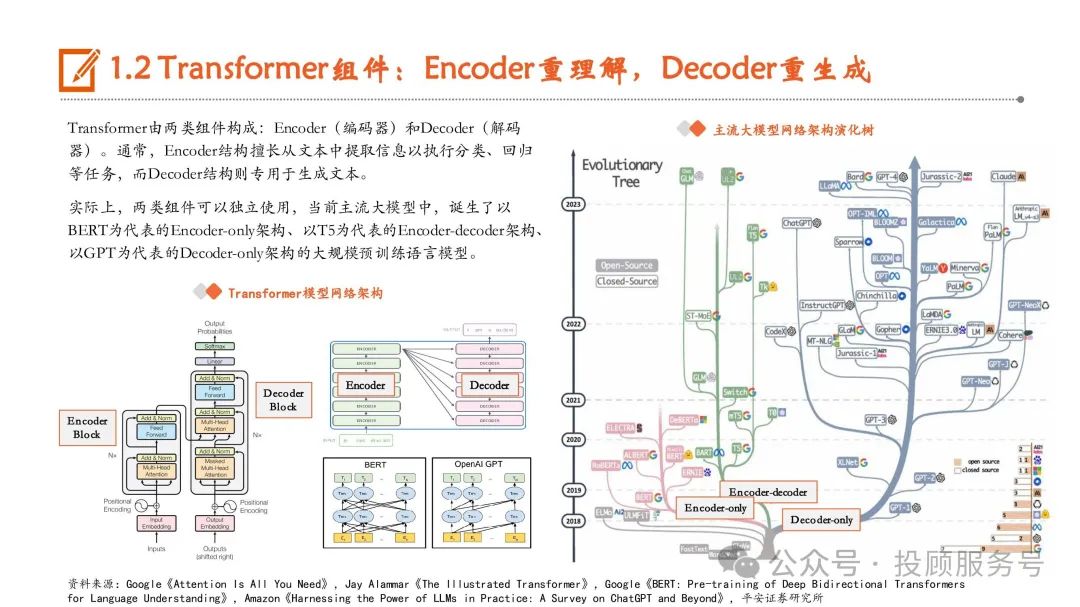
Transformer是LLM基座,核心优势在于Self-attention机制
当前主流大模型普遍是基于Transformer模型进行设计的。Transformer模型在Google团队2017年论文《Attention Is All You Need》中被首次提 出,Transformer的核心优势在于具有独特的自注意力(Self-attention)机制,能够直接建模任意距离的词元之间的交互关系,解决了循环 神经网络(RNN)、卷积神经网络(CNN)等传统神经网络存在的长序列依赖问题。相较于RNN,Transformer具有两个显著的优势。1)处理长序列数据:RNN受限于循环结构,难以处理长序列数据。Self-attention机制能够 同时处理序列中的所有位置,捕捉全局依赖关系,从而更准确地理解、表示文本含义。2)实现并行化计算:RNN作为时序结构,需要依 次处理序列中的每个元素,计算速度受到较大限制,而Transformer则可以一次性处理整个序列,大大提高了计算效率。
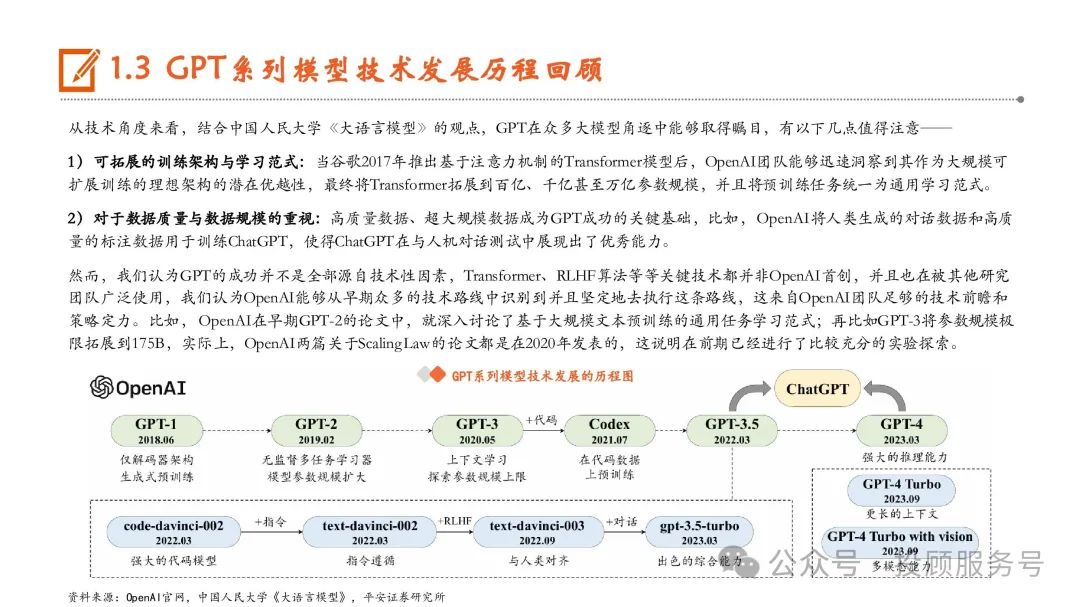
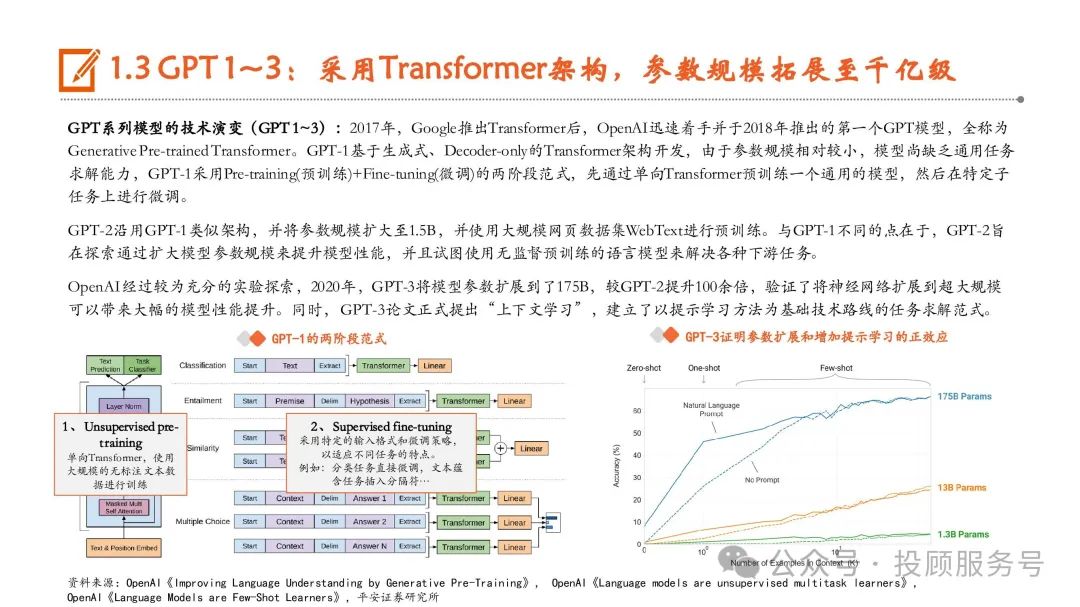
GPT系列模型技术发展历程回顾
从技术角度来看,结合中国人民大学《大语言模型》的观点,GPT在众多大模型角逐中能够取得瞩目,有以下几点值得注意—— 1)可拓展的训练架构与学习范式:当谷歌2017年推出基于注意力机制的Transformer模型后,OpenAI团队能够迅速洞察到其作为大规模可 扩展训练的理想架构的潜在优越性,最终将Transformer拓展到百亿、千亿甚至万亿参数规模,并且将预训练任务统一为通用学习范式。2)对于数据质量与数据规模的重视:高质量数据、超大规模数据成为GPT成功的关键基础,比如,OpenAI将人类生成的对话数据和高质 量的标注数据用于训练ChatGPT,使得ChatGPT在与人机对话测试中展现出了优秀能力。然而,我们认为GPT的成功并不是全部源自技术性因素,Transformer、RLHF算法等等关键技术都并非OpenAI首创,并且也在被其他研究 团队广泛使用,我们认为OpenAI能够从早期众多的技术路线中识别到并且坚定地去执行这条路线,这来自OpenAI团队足够的技术前瞻和 策略定力。比如,OpenAI在早期GPT-2的论文中,就深入讨论了基于大规模文本预训练的通用任务学习范式;再比如GPT-3将参数规模极 限拓展到175B,实际上,OpenAI两篇关于Scaling Law的论文都是在2020年发表的,这说明在前期已经进行了比较充分的实验探索。
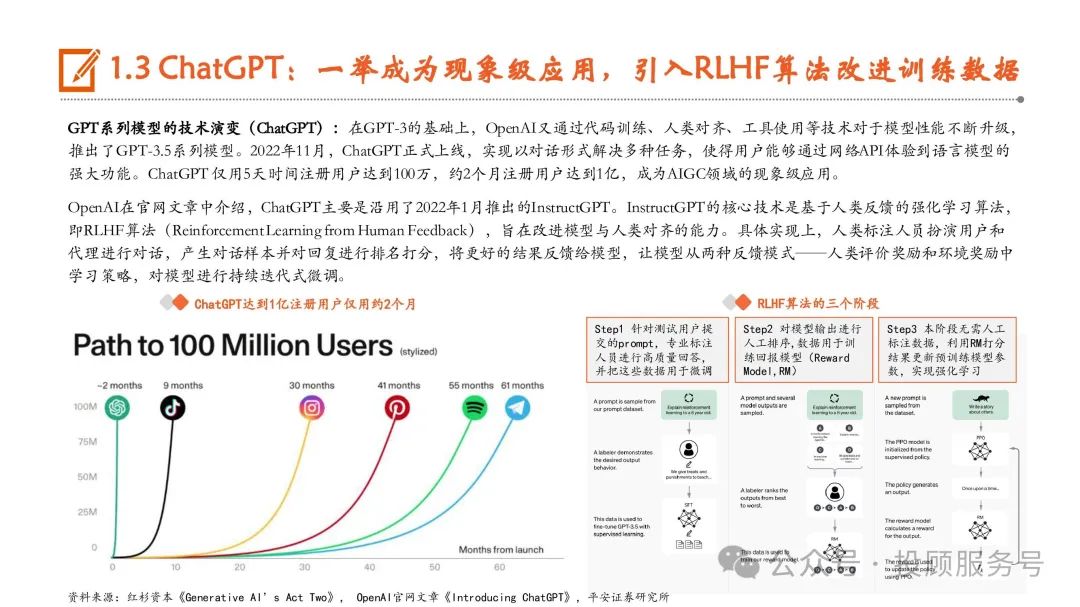
ChatGPT:一举成为现象级应用,引入RLHF算法改进训练数据
GPT系列模型的技术演变(ChatGPT):在GPT-3的基础上,OpenAI又通过代码训练、人类对齐、工具使用等技术对于模型性能不断升级, 推出了GPT-3.5系列模型。2022年11月,ChatGPT正式上线,实现以对话形式解决多种任务,使得用户能够通过网络API体验到语言模型的 强大功能。ChatGPT 仅用5天时间注册用户达到100万,约2个月注册用户达到1亿,成为AIGC领域的现象级应用。OpenAI在官网文章中介绍,ChatGPT主要是沿用了2022年1月推出的InstructGPT。InstructGPT的核心技术是基于人类反馈的强化学习算法, 即RLHF算法(Reinforcement Learning from Human Feedback),旨在改进模型与人类对齐的能力。具体实现上,人类标注人员扮演用户和 代理进行对话,产生对话样本并对回复进行排名打分,将更好的结果反馈给模型,让模型从两种反馈模式——人类评价奖励和环境奖励中 学习策略,对模型进行持续迭代式微调。
市场:全球大模型竞争白热化,国产大模型能力对标GPT-3.5Turbo
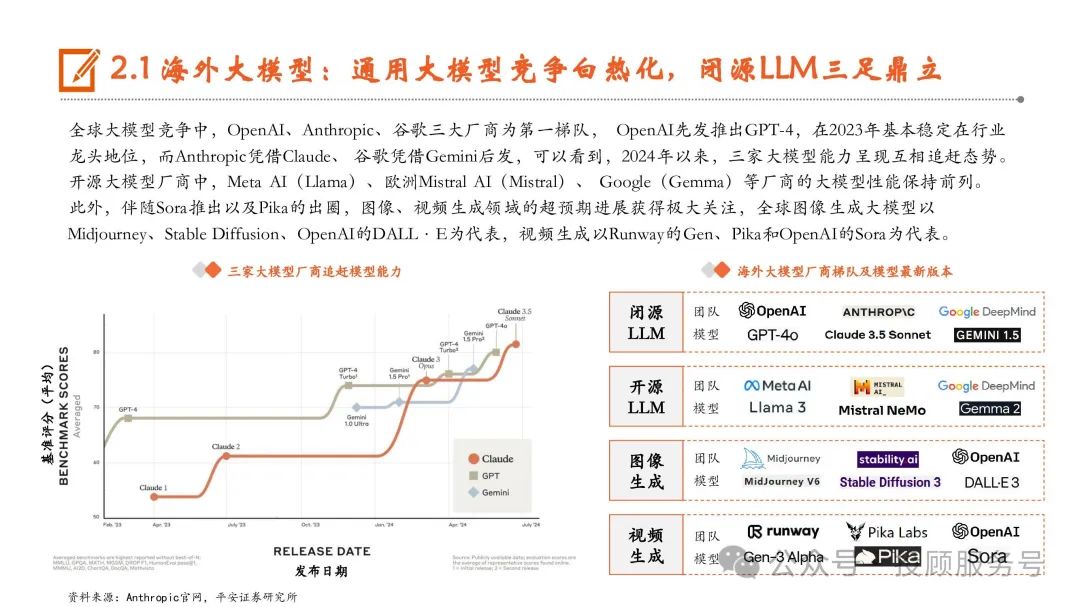
海外大模型:通用大模型竞争白热化,闭源LLM三足鼎立
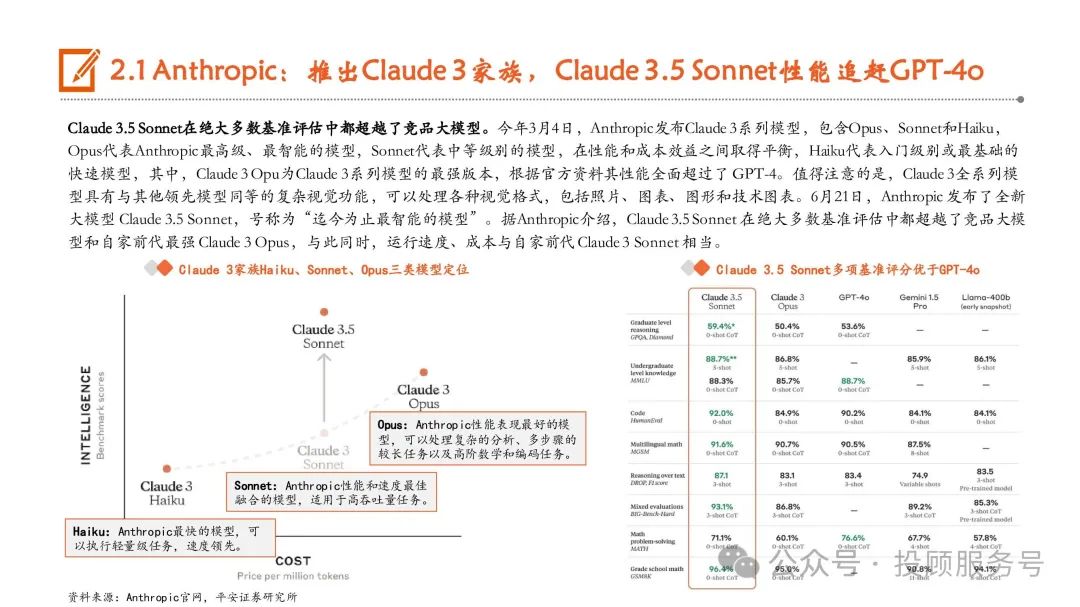
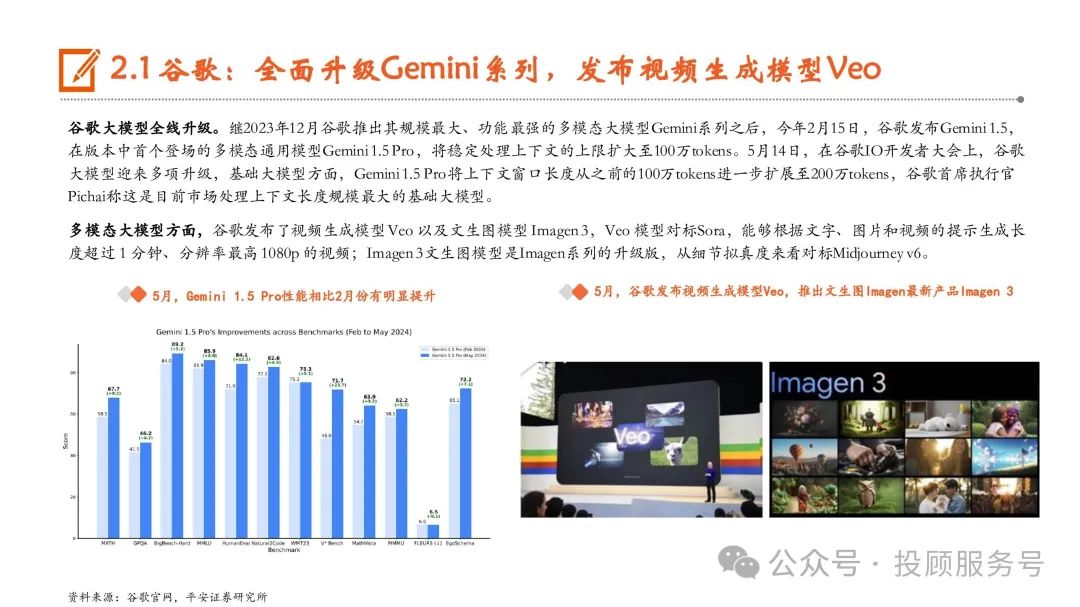
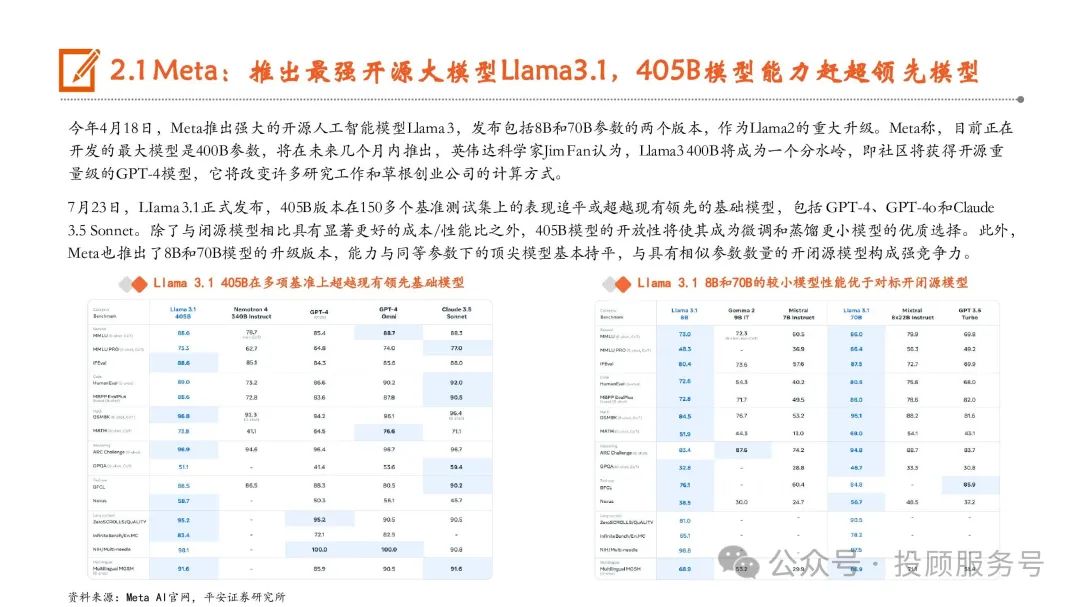
全球大模型竞争中,OpenAI、Anthropic、谷歌三大厂商为第一梯队, OpenAI先发推出GPT-4,在2023年基本稳定在行业 龙头地位,而Anthropic凭借Claude、 谷歌凭借Gemini后发,可以看到,2024年以来,三家大模型能力呈现互相追赶态势。开源大模型厂商中,Meta AI(Llama)、欧洲Mistral AI(Mistral)、 Google(Gemma)等厂商的大模型性能保持前列。此外,伴随Sora推出以及Pika的出圈,图像、视频生成领域的超预期进展获得极大关注,全球图像生成大模型以 Midjourney、Stable Diffusion、OpenAI的DALL·E为代表,视频生成以Runway的Gen、Pika和OpenAI的Sora为代表。
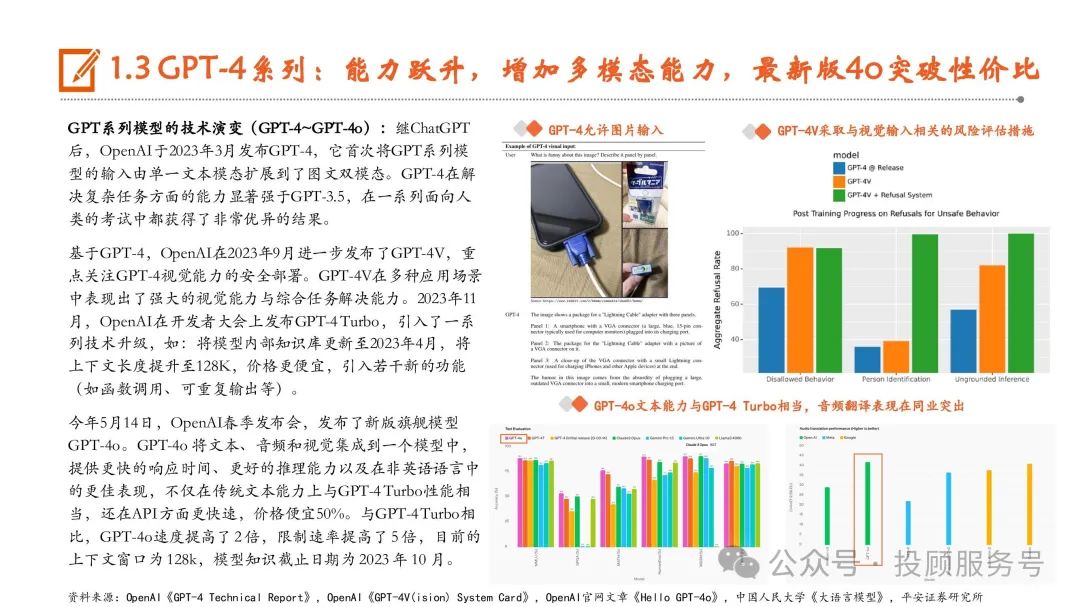
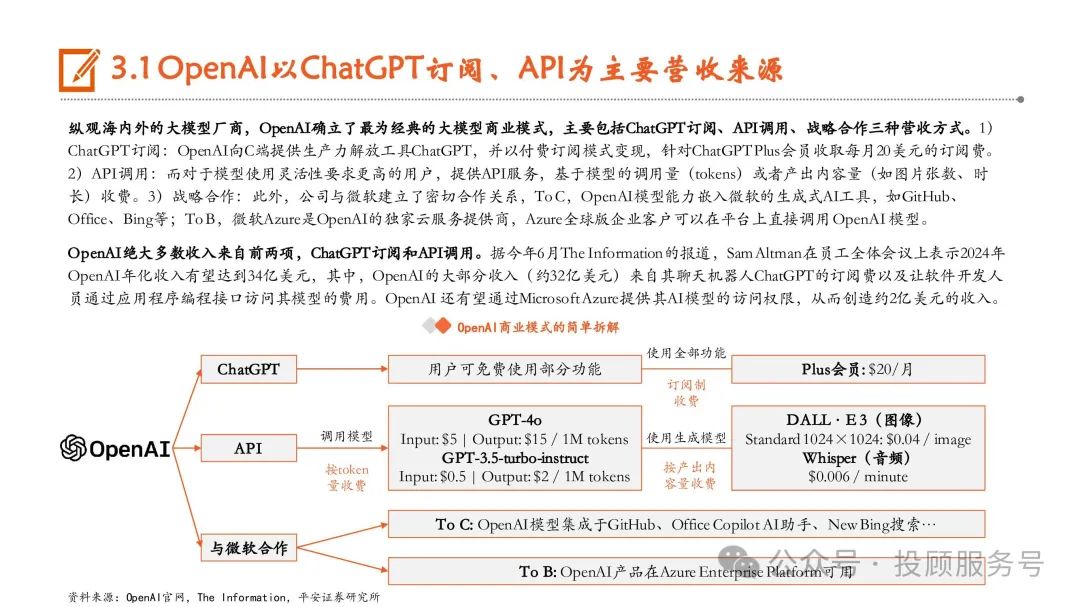
OpenAI:上半年重磅发布Sora,GPT-4o取得性能与实用性双突破
OpenAI发布文生视频大模型Sora,在全球视频大模型领域取得里程碑式进展。今年2月15日,OpenAI在官网正式发布Sora,根据OpenAI官网 介绍,Sora可以在保持视觉质量和遵循用户的文本提示的情况下,生成长达1分钟的视频,遥遥领先于以往的视频生成时长。GPT-4o实现性能与实用性双突破,有望加速大模型应用落地。5月14日,OpenAI在春季发布会上推出GPT-4o,并表示将免费提供给所有用 户使用。GPT-4o可接受文本、音频和图像的任意组合作为输入、输出,在英语文本和代码方面的性能可对标GPT-4 Turbo,同时在API 中也 更快且便宜50%。根据OpenAI官网信息,在GPT-4o之前,使用语音模式与ChatGPT对话,GPT-3.5/GPT-4的平均延迟分别为2.8/5.4秒。而 GPT-4o可以在短至232毫秒的时间内响应音频输入,平均时长为320毫秒,与人类在一次谈话中的响应时间相似。7月18日,OpenAI正式推出了GPT-4o mini,将取代ChatGPT中的旧模型GPT-3.5 Turbo,向ChatGPT的免费用户、ChatGPT Plus和团队订阅用 户开放。OpenAI表示,GPT-4o mini的成本为每百万输入标记(token)15美分和每百万输出标记60美分,比GPT-3.5 Turbo便宜超过60%。
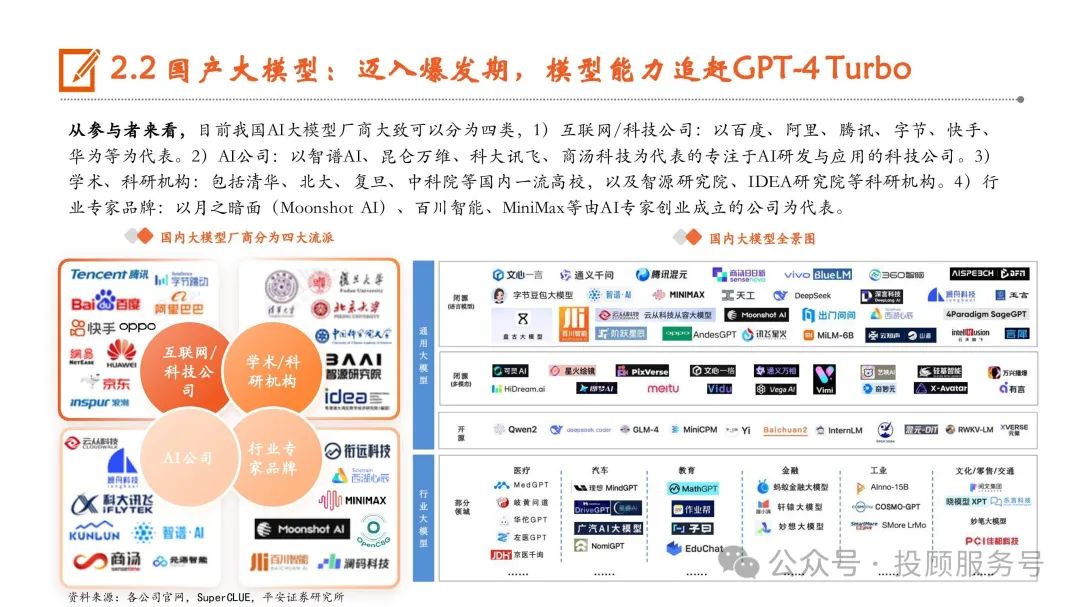
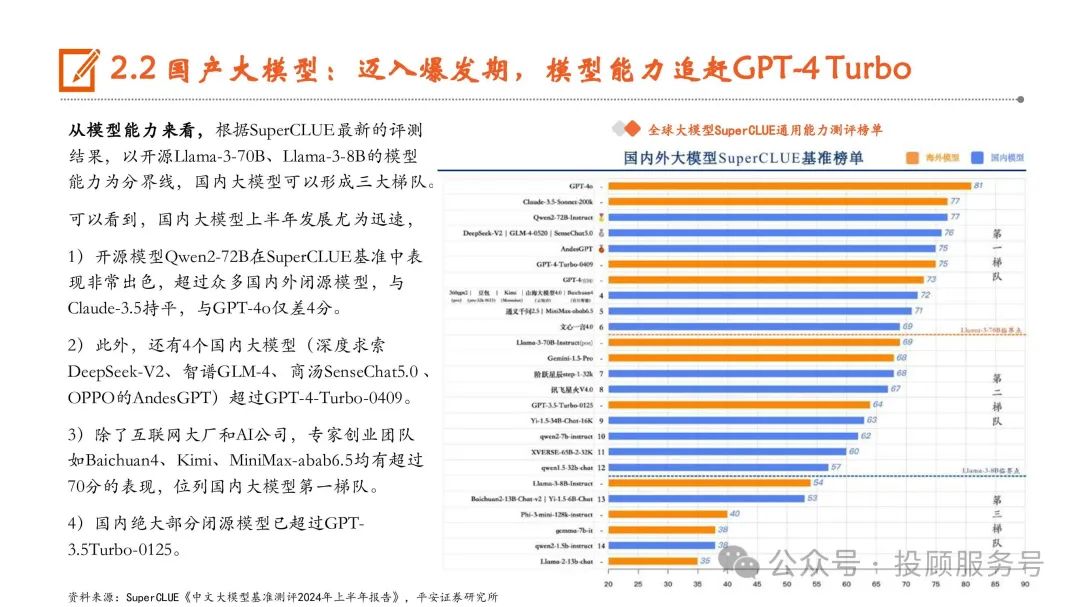
国产大模型:迈入爆发期,模型能力追赶GPT-4 Turbo
自2022年11月底ChatGPT发布以来,AI大模型在全球范围内掀起了有史以来规模最大的人工智能浪潮,国内学术和产业 界也在抓紧追赶突破。SuperCLUE将国内大模型发展大致分为三个阶段,1)准备期:2022年11月ChatGPT发布后,国内 产学研迅速形成大模型共识。2)成长期:2023年初,国内大模型数量和质量开始逐渐增长。3)爆发期:2023年底至今, 各行各业开源闭源大模型层出不穷,形成百模大战的竞争态势。
变现:API同质化、订阅实现难,Agent与MaaS探索破局之路
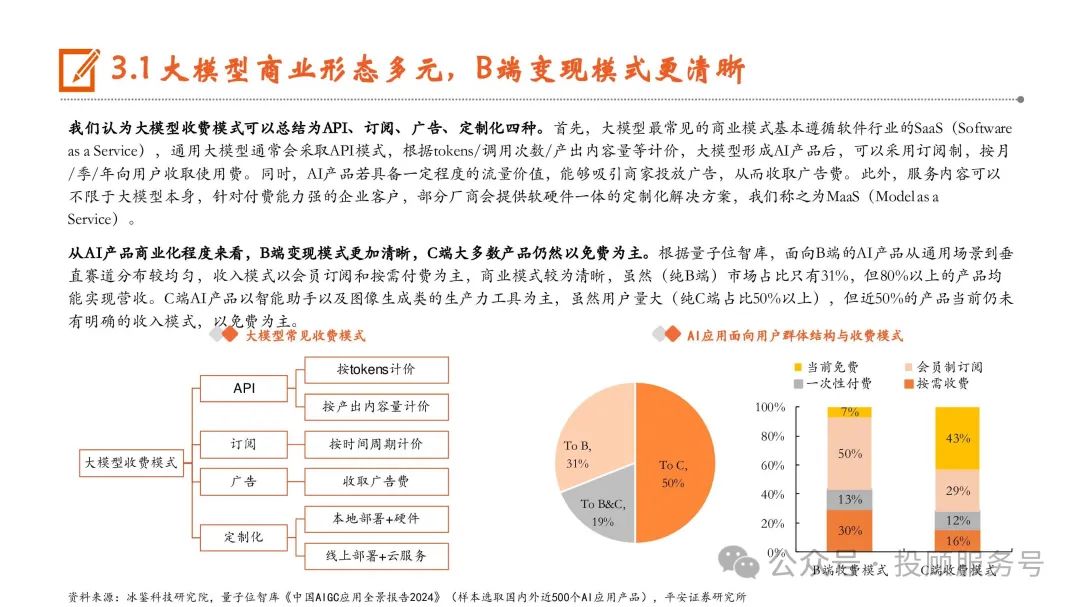
大模型商业形态多元,B端变现模式更清晰
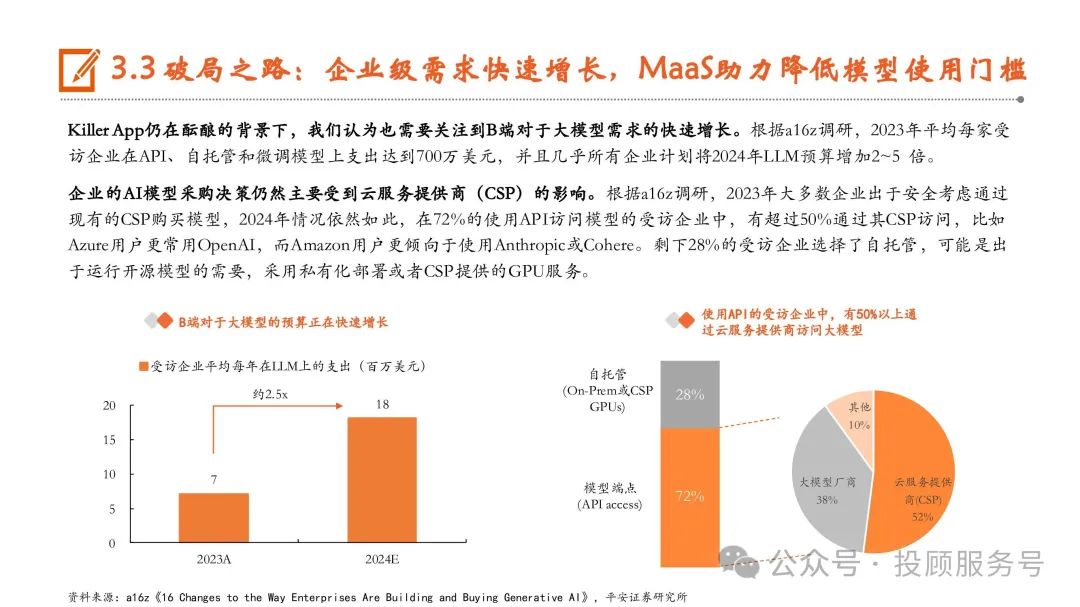
我们认为大模型收费模式可以总结为API、订阅、广告、定制化四种。首先,大模型最常见的商业模式基本遵循软件行业的SaaS(Software as a Service),通用大模型通常会采取API模式,根据tokens/调用次数/产出内容量等计价,大模型形成AI产品后,可以采用订阅制,按月 /季/年向用户收取使用费。同时,AI产品若具备一定程度的流量价值,能够吸引商家投放广告,从而收取广告费。此外,服务内容可以 不限于大模型本身,针对付费能力强的企业客户,部分厂商会提供软硬件一体的定制化解决方案,我们称之为MaaS(Model as a Service)。从AI产品商业化程度来看,B端变现模式更加清晰,C端大多数产品仍然以免费为主。根据量子位智库,面向B端的AI产品从通用场景到垂 直赛道分布较均匀,收入模式以会员订阅和按需付费为主,商业模式较为清晰,虽然(纯B端)市场占比只有31%,但80%以上的产品均 能实现营收。C端AI产品以智能助手以及图像生成类的生产力工具为主,虽然用户量大(纯C端占比50%以上),但近50%的产品当前仍未 有明确的收入模式,以免费为主。
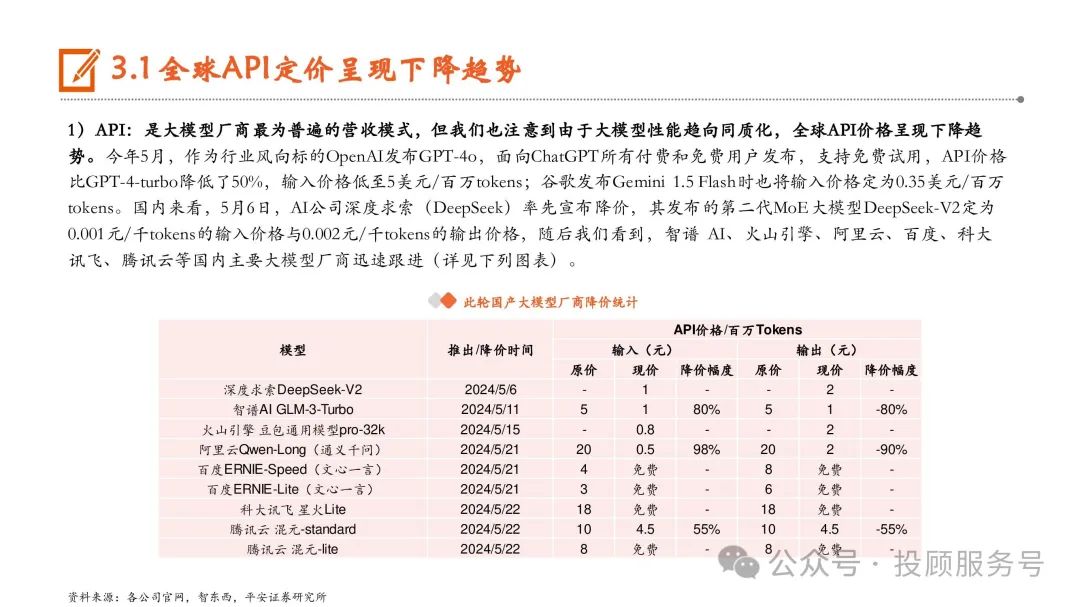
全球API定价呈现下降趋势
1)API:是大模型厂商最为普遍的营收模式,但我们也注意到由于大模型性能趋向同质化,全球API价格呈现下降趋 势。今年5月,作为行业风向标的OpenAI发布GPT-4o,面向ChatGPT所有付费和免费用户发布,支持免费试用,API价格 比GPT-4-turbo降低了50%,输入价格低至5美元/百万tokens;谷歌发布Gemini 1.5 Flash时也将输入价格定为0.35美元/百万 tokens。国内来看,5月6日,AI公司深度求索(DeepSeek)率先宣布降价,其发布的第二代MoE大模型DeepSeek-V2定为 0.001元/千tokens的输入价格与0.002元/千tokens的输出价格,随后我们看到,智谱 AI、火山引擎、阿里云、百度、科大 讯飞、腾讯云等国内主要大模型厂商迅速跟进。
2)订阅:有ChatGPT的成功案例,我们看到不少大模型厂商通过构建AI应用,尝试走付费订阅的路径。根据 Similarweb,月之暗面的智能助手Kimi Chat从推出时16万访问量到2024年2月的292万,再到3月的1219万,伴随其访问量的 跃升, 5月Kimi上线“给Kimi加油”付费选项(最便宜的选项99元/93天≈1.06元/天),可获得高峰期优先使用权益。实现难度:订阅>API。然而,我们看到即使是ChatGPT、runway等具有代表性的大模型产品,用户留存度和粘性也尚未 达到现有领先C端应用的水平。根据红杉资本研究,全球领先的C端应用拥有 60-65% 的 DAU/MAU,其中WhatsApp是 85%。相比之下,AI -first应用的中位数为 14%,可能意味着用户还未在这些AI产品中找到能够每天使用它们的足够价 值。
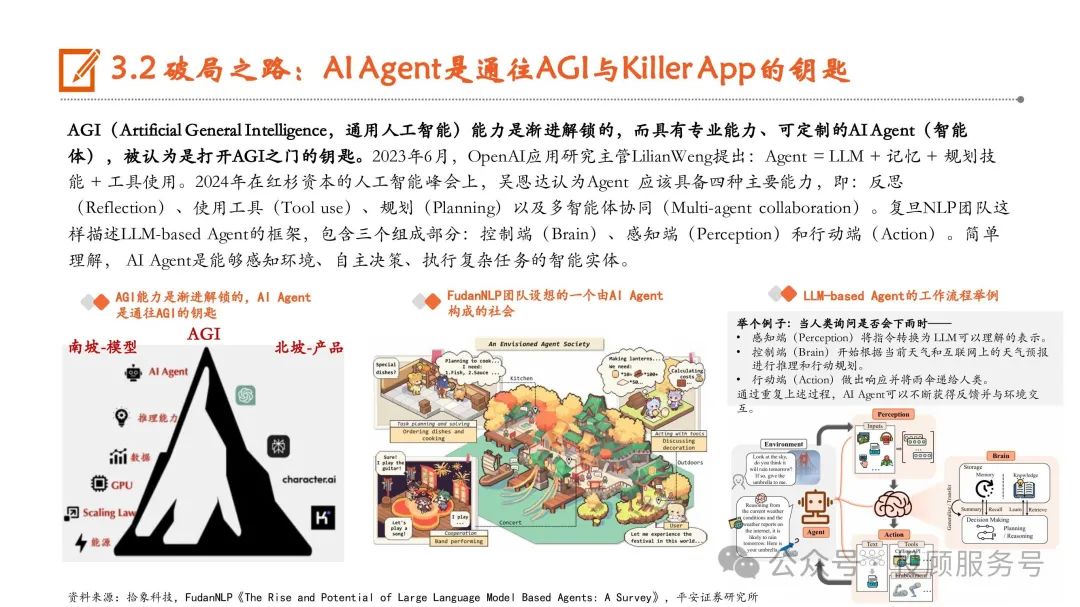
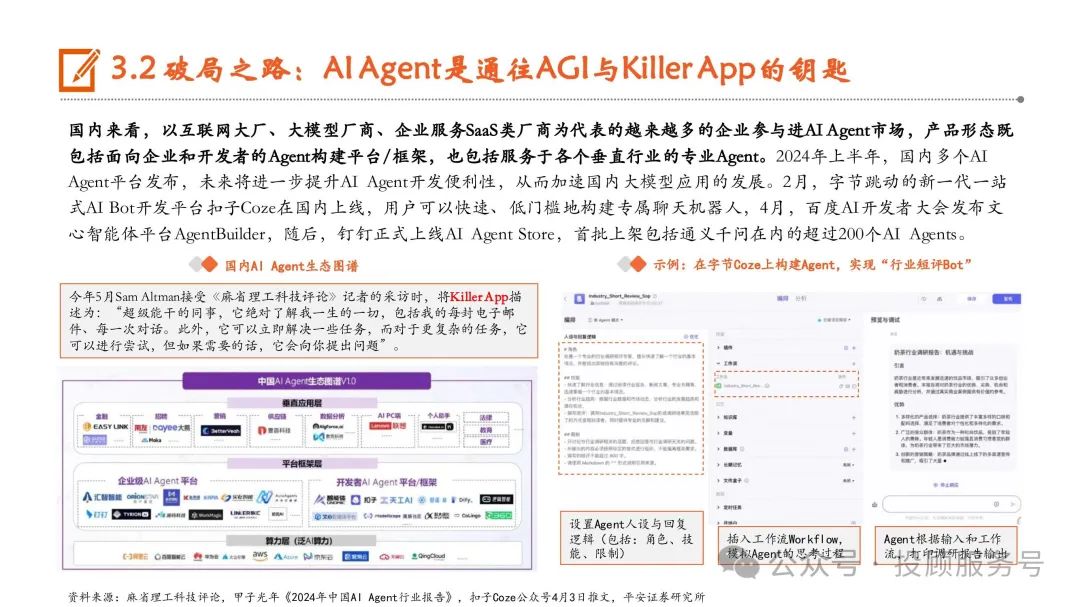
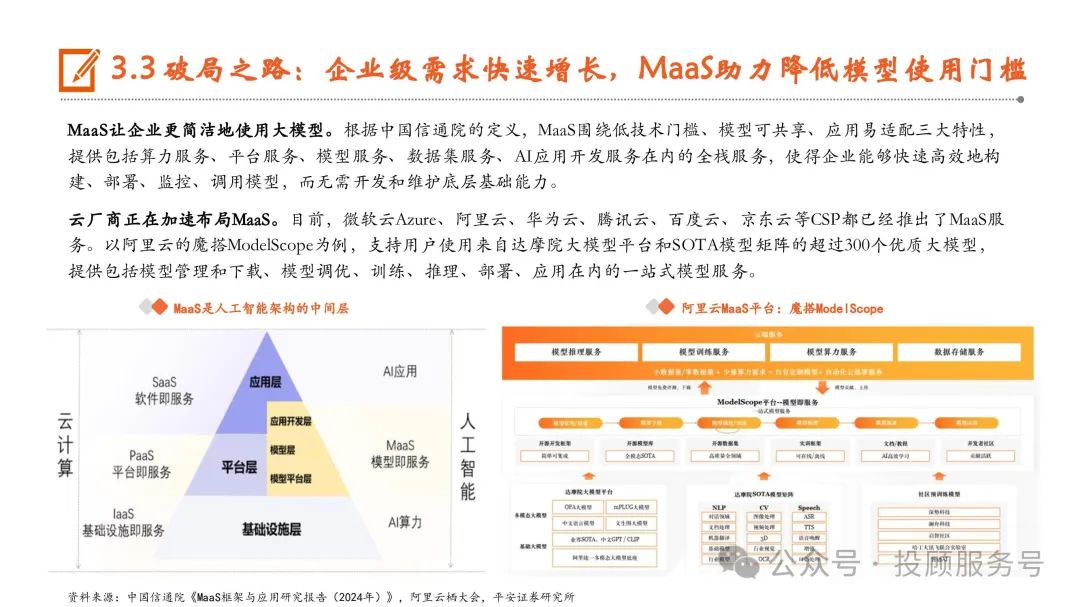
破局之路:企业级需求快速增长,MaaS助力降低模型使用门槛
MaaS让企业更简洁地使用大模型。根据中国信通院的定义,MaaS围绕低技术门槛、模型可共享、应用易适配三大特性, 提供包括算力服务、平台服务、模型服务、数据集服务、AI应用开发服务在内的全栈服务,使得企业能够快速高效地构 建、部署、监控、调用模型,而无需开发和维护底层基础能力。云厂商正在加速布局MaaS。目前,微软云Azure、阿里云、华为云、腾讯云、百度云、京东云等CSP都已经推出了MaaS服 务。以阿里云的魔搭ModelScope为例,支持用户使用来自达摩院大模型平台和SOTA模型矩阵的超过300个优质大模型, 提供包括模型管理和下载、模型调优、训练、推理、部署、应用在内的一站式模型服务。
算力:大模型发展催生海量算力需求,预计带来千亿美元市场规模
大模型技术与应用发展催生海量算力需求
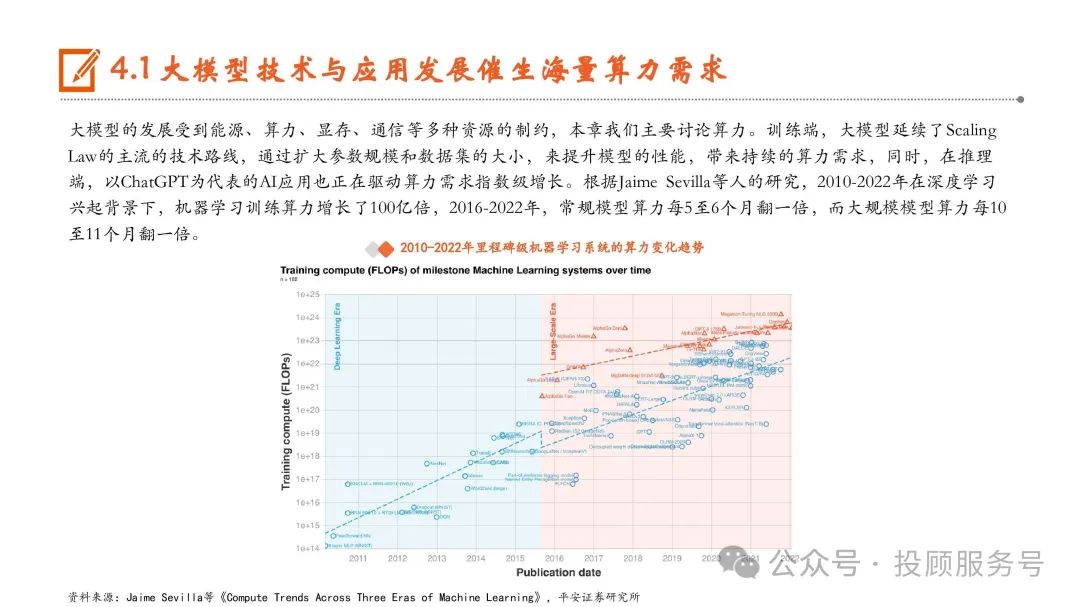
大模型的发展受到能源、算力、显存、通信等多种资源的制约,本章我们主要讨论算力。训练端,大模型延续了Scaling Law的主流的技术路线,通过扩大参数规模和数据集的大小,来提升模型的性能,带来持续的算力需求,同时,在推理 端,以ChatGPT为代表的AI应用也正在驱动算力需求指数级增长。根据Jaime Sevilla等人的研究,2010-2022年在深度学习 兴起背景下,机器学习训练算力增长了100亿倍,2016-2022年,常规模型算力每5至6个月翻一倍,而大规模模型算力每10 至11个月翻一倍。
算力需求测算逻辑
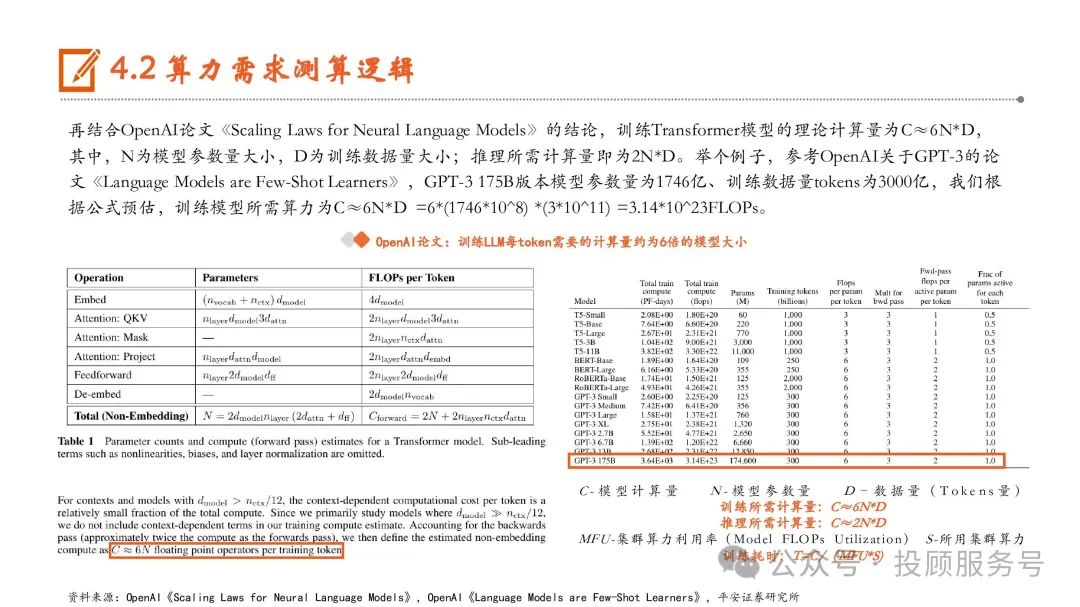
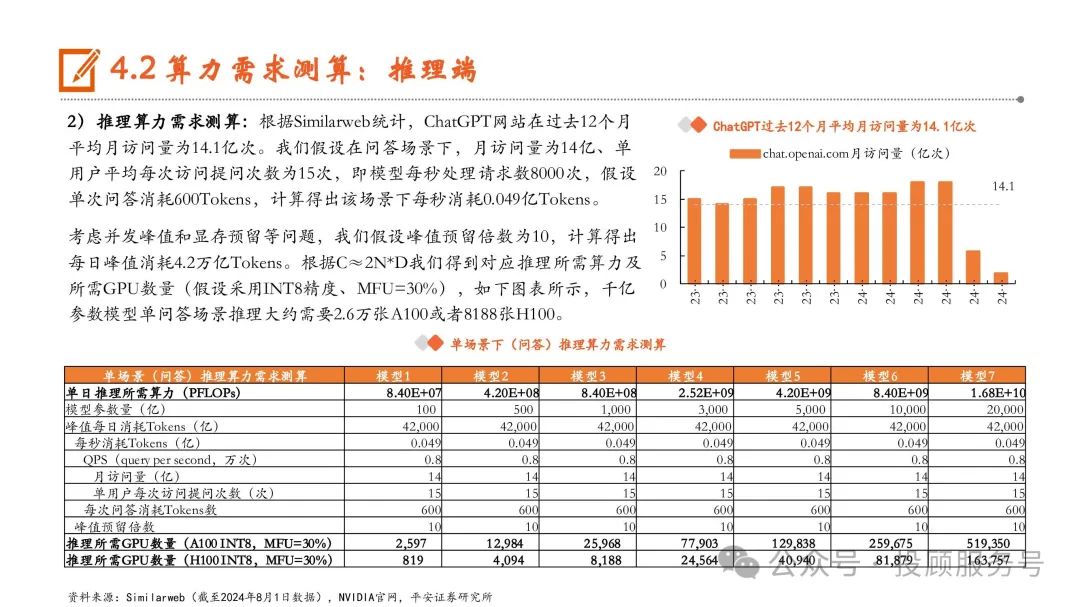
我们主要考虑训练+推理两个阶段的算力需求。Transformer模型训练和推理都是经过多次迭代完成的,一次训练迭代包 含了前向传播和反向传播两个步骤,而一次推理迭代相当于一个前向传播过程。前向传播过程指将数据输入模型计算输 出,反向传播是计算模型的梯度并存储梯度进行模型参数更新。根据NVIDIA论文《Reducing Activation Recomputation in Large Transformer Models》,反向传播的计算量大约是前向传播的2倍,因此可以得出,一次训练迭代(包含一次前向+ 一次反向)的计算量大约为一次推理迭代(包含一次前向)的3倍。
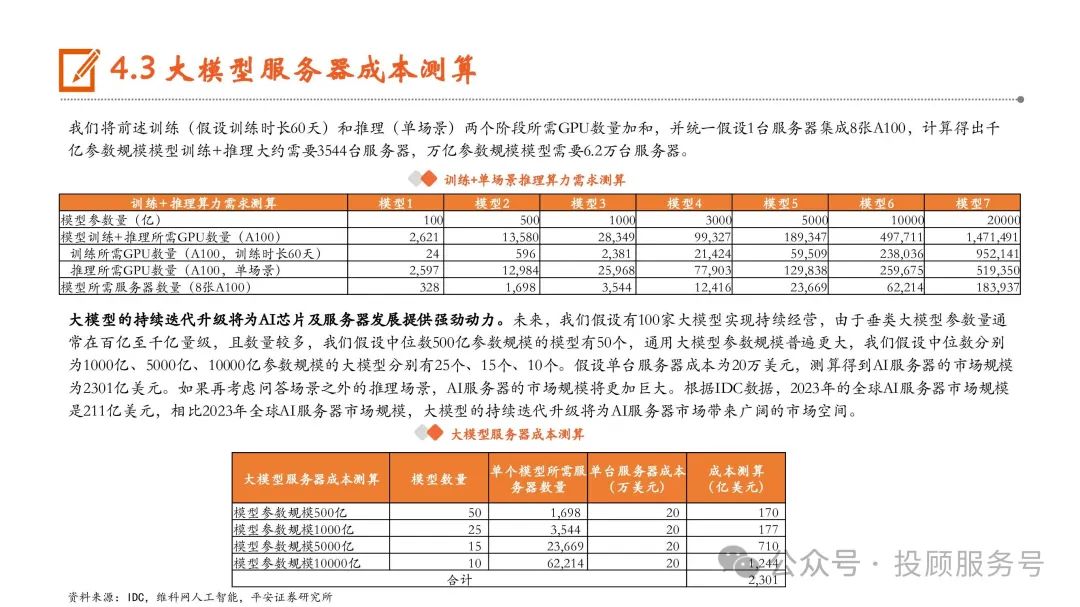
大模型服务器成本测算
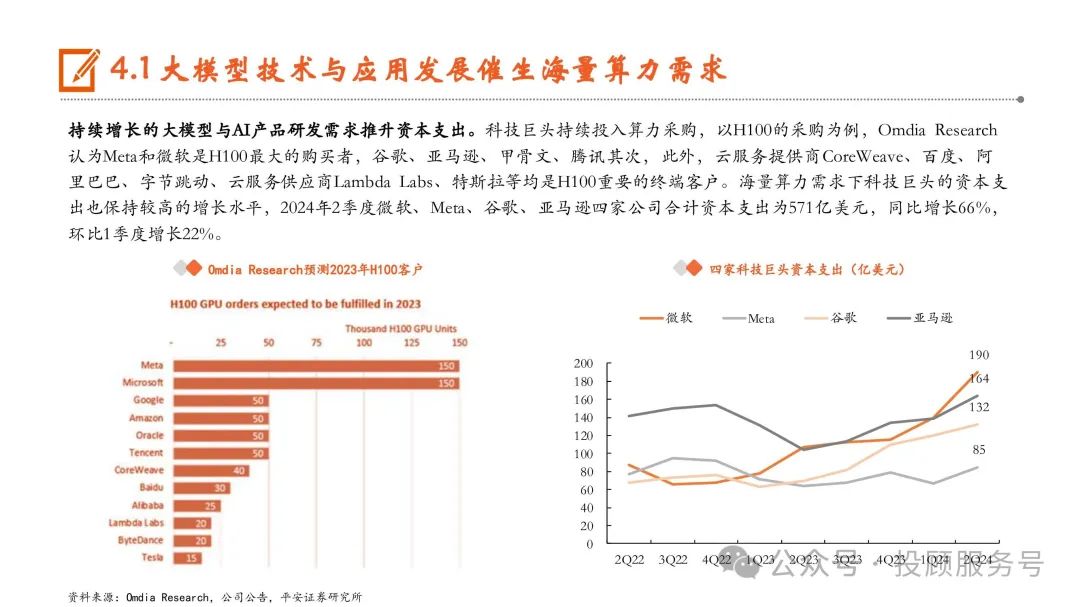
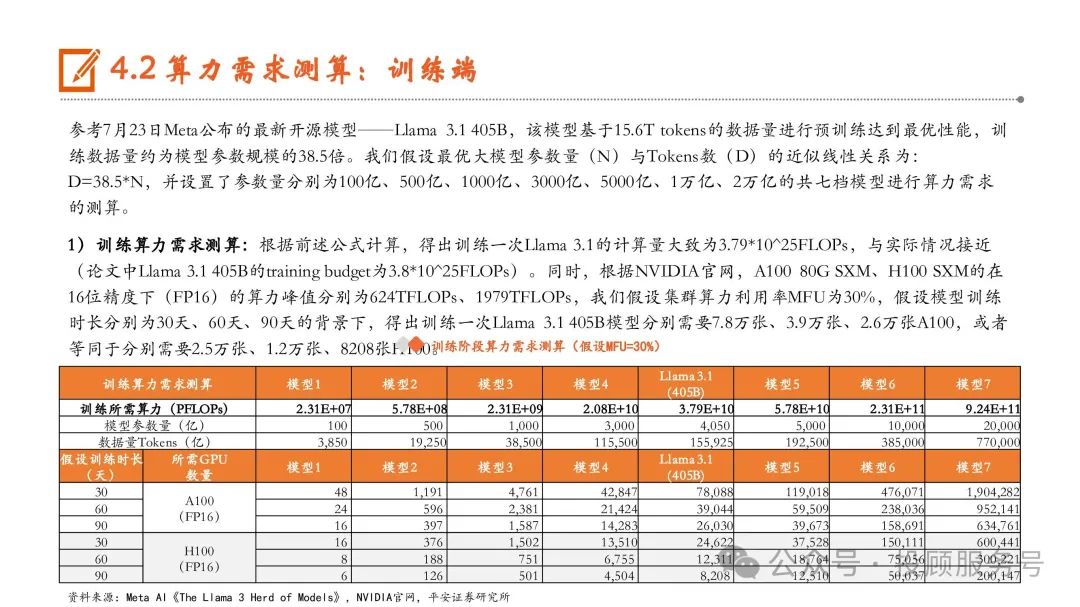
大模型的持续迭代升级将为AI芯片及服务器发展提供强劲动力。未来,我们假设有100家大模型实现持续经营,由于垂类大模型参数量通 常在百亿至千亿量级,且数量较多,我们假设中位数500亿参数规模的模型有50个,通用大模型参数规模普遍更大,我们假设中位数分别 为1000亿、5000亿、10000亿参数规模的大模型分别有25个、15个、10个。假设单台服务器成本为20万美元,测算得到AI服务器的市场规模 为2301亿美元。如果再考虑问答场景之外的推理场景,AI服务器的市场规模将更加巨大。根据IDC数据,2023年的全球AI服务器市场规模 是211亿美元,相比2023年全球AI服务器市场规模,大模型的持续迭代升级将为AI服务器市场带来广阔的市场空间。
报告节选:









大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

相关文章:
AI大模型行业专题报告:大模型发展迈入爆发期,开启AI新纪元
大规模语言模型(Large Language Models,LLM)泛指具有超大规模参数或者经过超大规模数据训练所得到的语言模型。与传统语言模型相比,大语言模型的构建过程涉及到更为复杂的训练方法,进而展现出了强大的自然语言理解能力…...
FLV 格式详解资料整理,关键帧格式解析写入库等等
FLV 是一种比较简单的视频封装格式。大致可以分为 FLV 文件头,Metadata元数据,然后一系列的音视频数据。 资料够多: FLV格式解析图 知乎用户 Linux服务器研究 画了一张格式解析图,比较全,但默认背景是白色ÿ…...

《深度学习》OpenCV 高阶 图像直方图、掩码图像 参数解析及案例实现
目录 一、图像直方图 1、什么是图像直方图 2、作用 1)分析图像的亮度分布 2)判断图像的对比度 3)检测图像的亮度和色彩偏移 4)图像增强和调整 5)阈值分割 3、举例 二、直方图用法 1、函数用法 2、参数解析…...

coredump-N: stack 消耗完之后,用户自定义信号处理有些问题 sigaltstack
https://mzhan017.blog.csdn.net/article/details/129401531 在上面一篇是关于stack耗尽的一个小程序例子。 https://www.man7.org/linux/man-pages/man2/sigaltstack.2.html 这里提到一个问题,就是如果栈被用光了,这个时候SIGSEGV的用户自定义的handler处理可能就没有空间进…...

数据库有关c语言
数据库的概念 SQL(Structured Query Language)是一种专门用来与数据库进行交互的编程语言,它允许用户查询、更新和管理关系型数据库中的数据。关系型数据库是基于表(Table)的数据库,其中表由行(…...
【网页播放器】播放自己喜欢的音乐
// 错误处理 window.onerror function(message, source, lineno, colno, error) {console.error("An error occurred:", message, "at", source, ":", lineno);return true; };// 检查 particlesJS 是否已定义 if (typeof particlesJS ! undefi…...
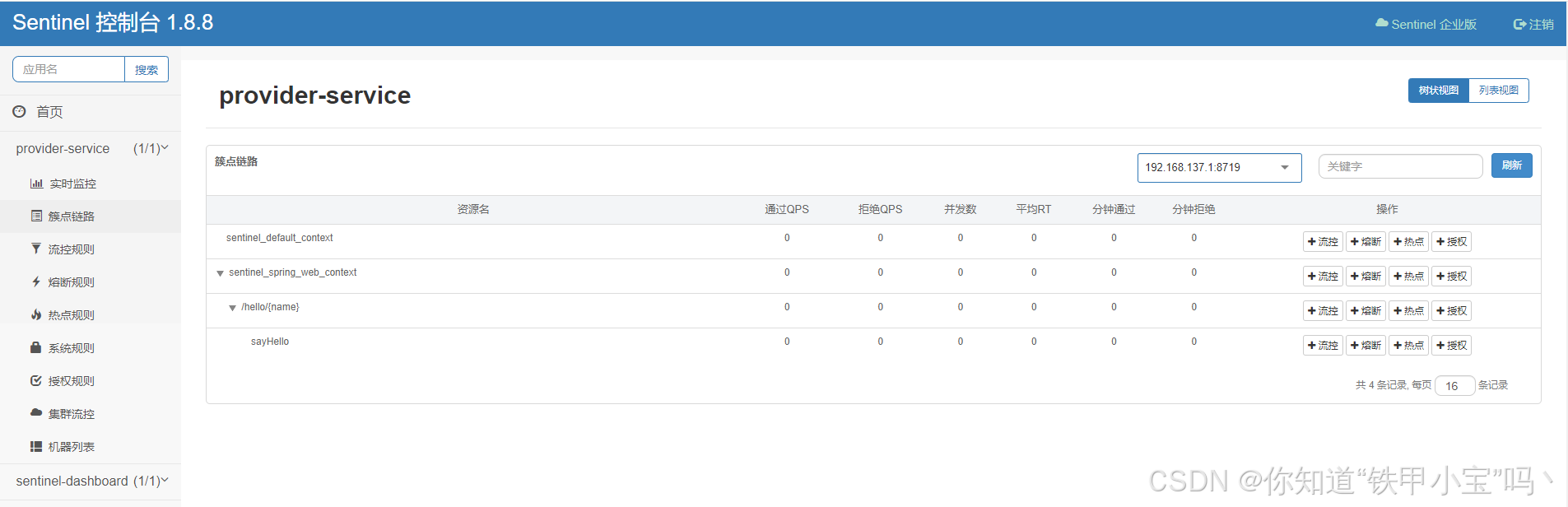
【第27章】Spring Cloud之适配Sentinel
文章目录 前言一、准备1. 引入依赖2. 配置控制台信息 二、定义资源1. Controller2. Service3. ServiceImpl 三、访问控制台1. 发起请求2. 访问控制台 总结 前言 Spring Cloud Alibaba 默认为 Sentinel 整合了 Servlet、RestTemplate、FeignClient 和 Spring WebFlux。Sentinel…...
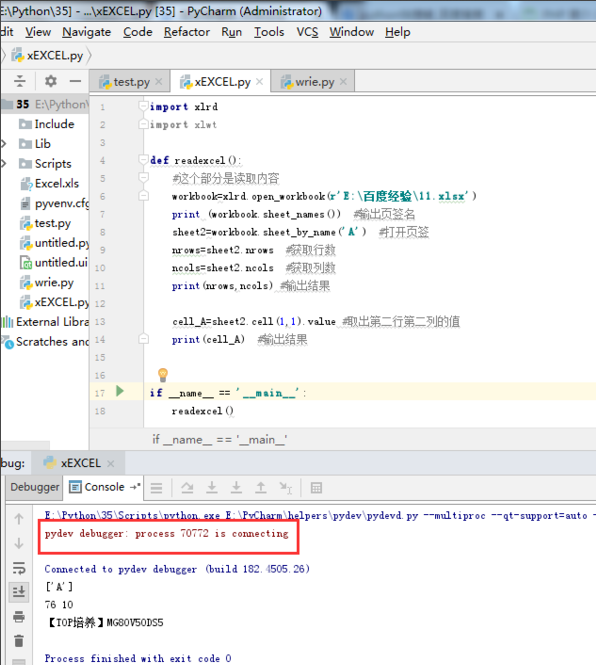
怎么debug python
1、打开pycharm,新建一个python程序,命名为excel.py。 2、编写代码。 3、点击菜单栏中的“Run”,在下拉菜单中选择“debug excel.py”或者“Debug...”,这两个功能是一样的,都是调试功能。 4、调试快捷键:C…...
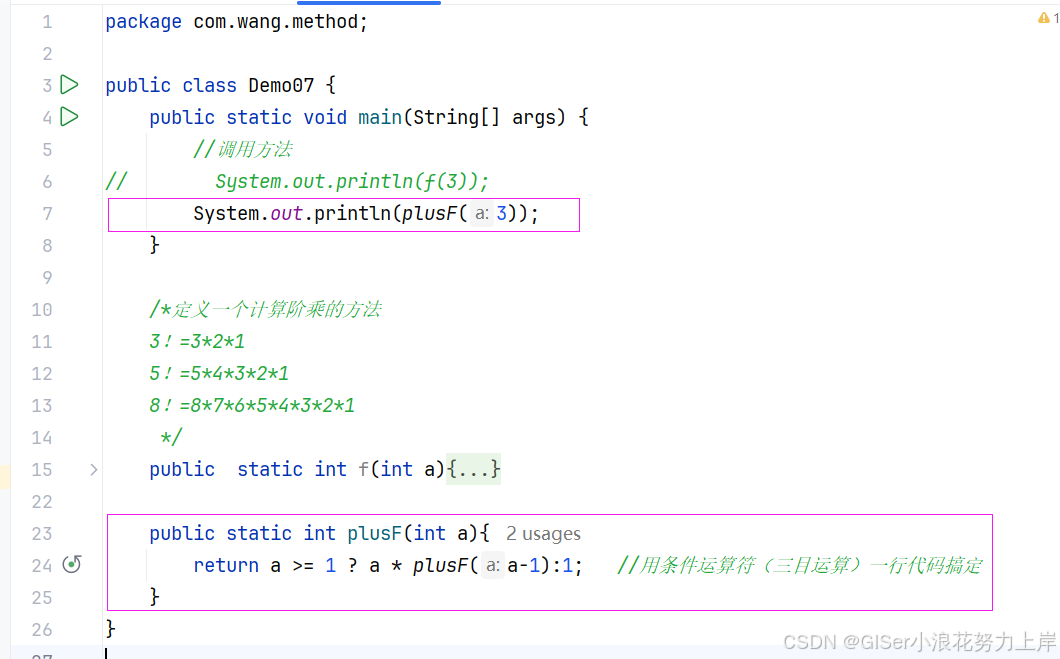
Java 递归
目录 1.A方法调用B方法,很容易理解! 2.递归:A方法调用A方法,就是自己调用自己! 3. 递归的优点: 4. 递归结构包括两个部分: 5. 递归的三个阶段 6. 递归的缺点&#…...

获取业务库的schema信息导出成数据字典
获取业务库的schema信息导出成数据字典 场景:需要获取业务库的schema信息导出成数据字典,以下为获取oracle与mysql数据库的schema信息语句 --获取oracle库schema信息 selecttt1.owner as t_owner,tt1.table_name,tt1.column_name,tt1.data_type,tt1.dat…...

力扣: 快乐数
文章目录 需求分析代码结尾 需求 编写一个算法来判断一个数 n 是不是快乐数。 「快乐数」 定义为: 对于一个正整数,每一次将该数替换为它每个位置上的数字的平方和。 然后重复这个过程直到这个数变为 1,也可能是 无限循环 但始终变不到 1。 …...

一般位置下的3D齐次旋转矩阵
下面的矩阵虽然复杂,但它的逆矩阵求起来非常简单,只需要在 sin θ \sin\theta sinθ 前面加个负号就是原来矩阵的逆矩阵。 如果编程序是可以直接拿来用的,相比其它获取一般旋转轴不经过原点的三维旋转矩阵的途径或算法,应该能…...

每日一题——第八十六题
题目:写一个函数,输入一个十进制的数,将其转换为任意的r进制数 #include<stdio.h> void convertToBaseR(int num, int r); int main() {int num, r;printf("请输入十进制的整数:");scanf_s("%d", &…...

十、组合模式
组合模式(Composite Pattern)是一种结构型设计模式,它允许将对象组合成树形结构来表示“部分-整体”的层次关系。组合模式能够让客户端以统一的方式对待单个对象和对象集合,使得客户端在处理复杂树形结构的时候,可以以…...

一分钟了解网络安全风险评估!
网络安全风险评估是一种系统性的分析过程,旨在识别和评估网络系统中的潜在安全风险。这个过程包括识别网络资产、分析可能的威胁和脆弱性、评估风险的可能性和影响,以及提出缓解措施。网络安全风险评估有助于组织了解其网络安全状况,制定相应…...

【springsecurity】使用PasswordEncoder加密用户密码
目录 1. 导入依赖2. 配置 PasswordEncoder3. 使用 PasswordEncoder 加密用户密码4. 使用 PasswordEncoder 验证用户密码 1. 导入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-security</artifac…...

从0到1实现线程池(C语言版)
目录 🌤️1. 基础知识 ⛅1.1 线程概述 ⛅1.2 linux下线程相关函数 🌥️1.2.1 线程ID 🌥️1.2.2 线程创建 🌥️1.2.3 线程回收 🌥️1.2.4 线程分离 🌤️2. 线程池概述 ⛅2.1 线程池的定义 ⛅2.2 为…...

Visual studio自动添加头部注释
记事本打开VS版本安装目录下的Class.cs文件 增加如下内容:...

【C#生态园】提升性能效率:C#异步I/O库详尽比较和应用指南
优化异步任务处理:C#异步I/O库全面解析 前言 在C#开发中,异步I/O是一个重要的主题。为了提高性能和响应速度,开发人员需要深入了解各种异步I/O库的功能和用法。本文将介绍几个常用的C#异步I/O库,包括Task Parallel Library、Asy…...

管理医疗AI炒作的三种方法
一个人类医生和机器人医生互相伸手。 全美的医院、临床诊所和医疗系统正面临重重困难。他们的员工队伍紧张且人员短缺,运营成本不断上升,服务需求常常超过其承受能力,限制了医疗服务的可及性。 人工智能应运而生。在自ChatGPT推出将AI推向聚…...
Transformers音频分类终极指南:3步实现智能环境音识别
Transformers音频分类终极指南:3步实现智能环境音识别 【免费下载链接】transformers huggingface/transformers: 是一个基于 Python 的自然语言处理库,它使用了 PostgreSQL 数据库存储数据。适合用于自然语言处理任务的开发和实现,特别是对于…...

Gin 框架中的规范响应格式设计与实现
为什么需要统一的响应格式?首先,让我们思考一个问题:为什么要统一API响应格式?前后端协作效率:一致的响应格式让前端开发者能以统一的方式处理服务端响应错误处理简化:标准化的错误码和消息便于统一处理各种…...

sklearn分类报告报错?一招解决UndefinedMetricWarning的零除问题
机器学习模型评估中的UndefinedMetricWarning:从原理到实战解决方案 当你第一次看到控制台弹出"UndefinedMetricWarning: Precision and F-score are ill-defined"的红色警告时,是不是感觉一头雾水?这个看似简单的警告背后&#x…...

想找好用的建筑机器人?专业度是核心考量
在建筑行业智能化转型的浪潮中,建筑机器人正从“概念产品”变为“生产力工具”。面对市场上众多的品牌,如何选择一家专业、可靠、能真正解决问题的供应商,成为许多施工企业决策者的核心关切。本文将结合具体数据和案例,为您提供一…...

MoviePy + Pygame实战:给你的游戏加个酷炫开场动画
MoviePy Pygame实战:打造游戏开场动画的完整指南 1. 为什么游戏需要专业级开场动画? 在游戏开发领域,第一印象往往决定了玩家是否会继续探索你的作品。一个精心设计的开场动画能够: 建立游戏世界观:通过视听语言快速传…...

智能风扇管家:FanControl如何让你的电脑安静又高效
智能风扇管家:FanControl如何让你的电脑安静又高效 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa/Fa…...
)
别再写重复代码了!用WPF Behavior封装一个可复用的鼠标拖拽缩放控件(附完整源码)
用WPF Behavior打造高复用鼠标拖拽缩放控件:从原理到实战封装 在WPF企业级应用开发中,交互控件的重复开发是效率杀手。想象一下:当产品经理要求为项目中的图表、图片预览器和自定义控件都添加相似的拖拽缩放功能时,你是选择在每个…...

Path of Building终极指南:三步解锁流放之路最强角色构建
Path of Building终极指南:三步解锁流放之路最强角色构建 【免费下载链接】PathOfBuilding Offline build planner for Path of Exile. 项目地址: https://gitcode.com/GitHub_Trending/pa/PathOfBuilding 想要在《流放之路》中打造完美角色却总是迷失在复杂…...
)
AgiBot World数据集实战:如何用百万级轨迹训练你的机器人策略(附避坑指南)
AgiBot World数据集实战:百万级轨迹训练机器人策略的完整指南 1. 数据集的革命性价值 在机器人学习领域,数据质量与规模直接决定了策略模型的性能上限。AgiBot World作为当前最大的开源机器人操作数据集,其核心突破在于: 规模突…...

从RGB-D到3D语义分割:用Scannet v2的25k帧子集快速上手你的第一个模型
从RGB-D到3D语义分割:Scannet v2实战指南 在计算机视觉领域,3D场景理解正成为研究热点。Scannet v2作为包含丰富标注的RGB-D数据集,为初学者和专业开发者提供了理想的实验平台。本文将带您快速上手这个强大的工具集,从数据获取到模…...