数模原理精解【9】
文章目录
- 混合高斯分布
- 概述
- 定义
- 性质
- 参数估计
- 计算
- Julia实现
- 详述
- 定义
- 原理
- 核心参数
- 1. 均值(Means)
- 2. 协方差矩阵(Covariance Matrices)
- 3. 权重(Weights)
- 4. 聚类个数(高斯模型个数,K)
- 参数总结
- 实际应用
- 混合高斯随机分布,即高斯混合模型(Gaussian Mixture Model,简称GMM)的算法与实现
- 一、算法原理
- 1. 概率密度函数
- 2. 参数估计
- 二、算法步骤
- 1. E步
- 2. M步
- 三、算法实现
- 四、应用场景
- 混合高斯随机变量参数估计
- 1. 极大似然估计(Maximum Likelihood Estimation, MLE)
- 2. 期望-最大化算法(Expectation-Maximization, EM)
- E步骤(Expectation Step)
- M步骤(Maximization Step)
- 3. 贝叶斯估计(Bayesian Estimation)
- 4. 变分推断(Variational Inference)
- 5. 马尔科夫链蒙特卡洛(Markov Chain Monte Carlo, MCMC)
- 混合高斯随机分布(Gaussian Mixture Model, GMM)的参数估计
- 参数估计步骤
- Julia实现
- 注意事项
- 参考文献
混合高斯分布
概述
是一种概率分布,它由多个高斯分布(也称为正态分布)组成,每个高斯分布对应一个子集或者一个聚类,并且这些高斯分布通过混合系数(或权重)进行加权组合。以下是关于混合高斯随机分布的详细定义、性质、计算及其参数估计,以及如何在Julia中实现这些内容。
定义
混合高斯分布的概率密度函数(PDF)可以表示为:
p ( x ) = ∑ k = 1 K π k N ( x ∣ μ k , Σ k ) p(x) = \sum_{k=1}^K \pi_k \mathcal{N}(x | \mu_k, \Sigma_k) p(x)=k=1∑KπkN(x∣μk,Σk)
其中, K K K 是高斯分布的数量, π k \pi_k πk 是第 k k k 个高斯分布的混合系数(满足 ∑ k = 1 K π k = 1 \sum_{k=1}^K \pi_k = 1 ∑k=1Kπk=1), N ( x ∣ μ k , Σ k ) \mathcal{N}(x | \mu_k, \Sigma_k) N(x∣μk,Σk) 是第 k k k 个高斯分布的概率密度函数,其均值为 μ k \mu_k μk,协方差矩阵为 Σ k \Sigma_k Σk。
性质
- 多模态性:混合高斯分布可以具有多个峰值(模态),这取决于组成它的高斯分布的数量和参数。
- 灵活性:通过调整混合系数、均值和协方差矩阵,混合高斯分布可以近似许多复杂的分布。
- 可解析性:尽管混合高斯分布本身不是单一的高斯分布,但它的每个组成部分都是,这使得在某些计算中可以利用高斯分布的性质。
参数估计
混合高斯分布的参数估计通常使用期望-最大化(EM)算法,特别是其中的一种变体,称为高斯混合模型(GMM)的EM算法。该算法通过迭代地计算责任度(E步骤)和更新参数(M步骤)来最大化观测数据的似然函数。
计算
- E步骤:计算每个数据点来自每个高斯分布的责任度。
- M步骤:使用责任度来更新混合系数、均值和协方差矩阵。
- 重复:直到参数收敛或达到最大迭代次数。
Julia实现
以下是一个使用Julia实现混合高斯分布参数估计的简化示例:
using Distributions
using LinearAlgebra# 定义高斯混合模型的参数
K = 2 # 高斯分布的数量
π = [0.5, 0.5] # 混合系数(初始值)
μ = [[-2.0], [2.0]] # 均值(初始值)
Σ = [diagm([0.5^2]), diagm([0.5^2])] # 协方差矩阵(初始值)# 生成一些示例数据
Random.seed!(0)
n = 300
X = [randn(n) * 0.5 - 2.0; randn(n) * 0.5 + 2.0]# EM算法
max_iter = 100
tol = 1e-6
log_likelihood = -Inf
for iter = 1:max_iter# E步骤:计算责任度γ = zeros(n, K)for k = 1:Kγ[:, k] = π[k] * pdf(Normal(μ[k][1], sqrt(Σ[k][1, 1])), X)endγ ./= sum(γ, dims=2)# M步骤:更新参数N_k = sum(γ, dims=1)π = N_k / nμ = (γ' * X) ./ N_k'for k = 1:Kdiff = X - μ[k]'Σ[k] = (γ[:, k]' * (diff .* diff')) / N_k[k]end# 计算新的对数似然new_log_likelihood = sum(log(sum(γ, dims=2)))# 检查收敛if abs(new_log_likelihood - log_likelihood) < tolbreakendlog_likelihood = new_log_likelihood
end# 输出估计的参数
println("混合系数: ", π)
println("均值: ", μ)
println("方差: ", [Σ[k][1, 1] for k in 1:K])
注意:这个示例假设数据是一维的,并且为了简化,只使用了对角协方差矩阵。对于多维数据和/或非对角协方差矩阵,需要相应地调整代码。
在实际应用中,通常会使用专门的库(如scikit-learn、MLlib、TensorFlow等)来执行这些计算,因为它们提供了更优化和更健壮的实现。在Julia中,也可以使用MixtureModels等包来更方便地处理混合高斯模型。
详述
混合高斯随机分布,通常被称为高斯混合模型(Gaussian Mixture Model,简称GMM),是一种在统计学和机器学习中广泛使用的概率模型。它通过组合多个高斯分布(也称为正态分布)来模拟数据的复杂分布特性。以下是对混合高斯随机分布的定义和原理的详细解释:
定义
高斯混合模型是一种参数化模型,它假设所有的观测数据点都是从有限个高斯分布的混合中生成的。这些高斯分布被称为模型的“分量”或“组件”。每个分量都有其自己的均值(mean)、协方差矩阵(covariance matrix)和混合权重(mixture weight)。混合权重表示从每个分量中生成观测数据的相对概率。
原理
-
数据生成过程:
- 在高斯混合模型中,每个观测数据点都被视为是从K个高斯分量中的一个中随机抽取的。首先,根据混合权重随机选择一个分量,然后从被选中的分量中生成观测数据点。
-
概率密度函数:
- 高斯混合模型的概率密度函数是所有分量高斯分布概率密度函数的加权和。具体来说,对于D维观测数据点x,其概率密度函数可以表示为:
p ( x ) = ∑ k = 1 K π k N ( x ∣ μ k , Σ k ) p(x) = \sum_{k=1}^{K} \pi_k \mathcal{N}(x | \mu_k, \Sigma_k) p(x)=k=1∑KπkN(x∣μk,Σk)
其中,(\pi_k) 是第k个分量的混合权重,满足 (\sum_{k=1}^{K} \pi_k = 1);(\mathcal{N}(x | \mu_k, \Sigma_k)) 是第k个分量的高斯分布概率密度函数,(\mu_k) 是均值向量,(\Sigma_k) 是协方差矩阵。
- 高斯混合模型的概率密度函数是所有分量高斯分布概率密度函数的加权和。具体来说,对于D维观测数据点x,其概率密度函数可以表示为:
-
参数估计:
- 高斯混合模型的参数包括每个分量的均值、协方差矩阵和混合权重。这些参数通常通过极大似然估计法来估计,但由于直接计算极大似然函数可能非常困难,因此常采用期望最大化(Expectation Maximization,简称EM)算法进行迭代求解。
- EM算法包括两个步骤:E步(Expectation step)和M步(Maximization step)。在E步中,根据当前的参数估计,计算每个观测数据点属于各个分量的后验概率(即隐变量的期望);在M步中,根据这些后验概率,更新分量的参数以最大化观测数据的似然函数。
-
应用:
- 高斯混合模型具有广泛的应用,包括但不限于数据聚类、密度估计、异常检测、生成模型等。在聚类任务中,每个分量可以视为一个簇,观测数据点根据其后验概率被分配到最可能的簇中。在密度估计任务中,高斯混合模型可以用来估计数据的概率密度函数,进而进行各种统计分析和推断。
核心参数
包括以下几个方面:
1. 均值(Means)
- 定义:每个高斯分量的均值向量,表示该分量在特征空间中的中心位置。
- 作用:均值决定了分量在数据空间中的定位,是描述数据分布特性的重要参数之一。
2. 协方差矩阵(Covariance Matrices)
- 定义:每个高斯分量的协方差矩阵,描述了分量在不同特征上的变化关系和数据的形状和方向。
- 作用:协方差矩阵决定了分量数据的分散程度和形状,是控制数据分布宽度和方向的关键参数。
3. 权重(Weights)
- 定义:每个高斯分量的混合权重,表示该分量在生成观测数据时的相对贡献概率。
- 作用:权重决定了各个分量在混合模型中的重要性,是平衡各分量影响的关键因素。
4. 聚类个数(高斯模型个数,K)
- 定义:模型中包含的高斯分量个数,即聚类的类别数。
- 作用:聚类个数是模型复杂度的直接体现,它决定了模型能够描述的数据分布复杂程度。
参数总结
混合高斯随机分布的核心参数主要包括均值、协方差矩阵、权重以及聚类个数。这些参数共同定义了模型的分布特性,使得模型能够灵活地拟合各种复杂的数据分布。
实际应用
在实际应用中,这些参数通常需要通过数据学习和优化算法来确定。例如,可以使用期望最大化(Expectation Maximization,简称EM)算法来迭代求解这些参数的最优值,使得模型能够最好地拟合观测数据。
混合高斯随机分布,即高斯混合模型(Gaussian Mixture Model,简称GMM)的算法与实现
主要涉及模型的参数估计和数据的聚类或拟合过程。以下是对GMM算法与实现的详细介绍:
一、算法原理
GMM的核心思想是通过多个高斯分布的线性组合来近似任意形状的概率分布。每个高斯分布称为一个“分量”或“组件”,每个分量都有其自己的均值、协方差矩阵和混合权重。
1. 概率密度函数
GMM的概率密度函数是所有分量高斯分布概率密度函数的加权和,公式如下:
p ( x ∣ θ ) = ∑ k = 1 K α k ϕ ( x ∣ θ k ) p(x|\theta) = \sum_{k=1}^{K} \alpha_k \phi(x|\theta_k) p(x∣θ)=k=1∑Kαkϕ(x∣θk)
其中, θ \theta θ 代表所有混合成分的参数集合,包括均值、协方差矩阵和混合权重; α k \alpha_k αk 是第k个分量的混合权重,满足 ∑ k = 1 K α k = 1 \sum_{k=1}^{K} \alpha_k = 1 ∑k=1Kαk=1; ϕ ( x ∣ θ k ) \phi(x|\theta_k) ϕ(x∣θk) 是第k个分量的高斯分布概率密度函数。
2. 参数估计
GMM的参数估计通常使用极大似然估计法,但由于直接计算极大似然函数可能非常困难,因此常采用期望最大化(Expectation Maximization,简称EM)算法进行迭代求解。
二、算法步骤
EM算法包括两个主要步骤:E步(Expectation step)和M步(Maximization step)。
1. E步
在E步中,根据当前的参数估计,计算每个观测数据点属于各个分量的后验概率(即隐变量的期望)。后验概率的公式如下:
γ j k = α k ϕ ( x j ∣ θ k ) ∑ k = 1 K α k ϕ ( x j ∣ θ k ) \gamma_{jk} = \frac{\alpha_k \phi(x_j|\theta_k)}{\sum_{k=1}^{K} \alpha_k \phi(x_j|\theta_k)} γjk=∑k=1Kαkϕ(xj∣θk)αkϕ(xj∣θk)
其中, γ j k \gamma_{jk} γjk 表示观测数据点 x j x_j xj 属于第k个分量的后验概率。
2. M步
在M步中,根据E步计算得到的后验概率,更新分量的参数以最大化观测数据的似然函数。更新公式如下:
- 均值更新:
μ k = ∑ j = 1 N γ j k x j ∑ j = 1 N γ j k \mu_k = \frac{\sum_{j=1}^{N} \gamma_{jk} x_j}{\sum_{j=1}^{N} \gamma_{jk}} μk=∑j=1Nγjk∑j=1Nγjkxj
- 协方差矩阵更新:
Σ k = ∑ j = 1 N γ j k ( x j − μ k ) ( x j − μ k ) T ∑ j = 1 N γ j k \Sigma_k = \frac{\sum_{j=1}^{N} \gamma_{jk} (x_j - \mu_k)(x_j - \mu_k)^T}{\sum_{j=1}^{N} \gamma_{jk}} Σk=∑j=1Nγjk∑j=1Nγjk(xj−μk)(xj−μk)T
- 权重更新:
α k = 1 N ∑ j = 1 N γ j k \alpha_k = \frac{1}{N} \sum_{j=1}^{N} \gamma_{jk} αk=N1j=1∑Nγjk
其中,N是观测数据点的总数。
三、算法实现
GMM的算法实现可以通过各种编程语言和机器学习库来完成。以下是一个简化的实现步骤:
-
初始化参数:随机初始化每个分量的均值、协方差矩阵和混合权重。
-
E步:根据当前参数计算每个观测数据点属于各个分量的后验概率。
-
M步:根据E步计算得到的后验概率,更新分量的参数。
-
迭代收敛:重复E步和M步,直到参数的变化小于某个预设的阈值或达到最大迭代次数。
-
输出结果:输出最终的参数估计结果,包括每个分量的均值、协方差矩阵和混合权重。
在实际应用中,可以使用Python的Scikit-learn库中的GaussianMixture类来方便地实现GMM算法。该库提供了丰富的参数设置和灵活的使用方式,可以满足大多数应用场景的需求。
四、应用场景
GMM具有广泛的应用场景,包括但不限于数据聚类、密度估计、异常检测、图像分割和图像生成等。在聚类任务中,GMM可以视为一种软聚类方法,能够给出每个样本属于每个簇的概率;在密度估计任务中,GMM可以用来估计数据的概率密度函数;在异常检测任务中,GMM可以识别出与大多数数据点分布显著不同的异常点。
混合高斯随机变量参数估计
混合高斯模型(Gaussian Mixture Model, GMM)是一种用于描述由多个高斯分布组成的混合分布的统计模型。参数估计的目标是从观测数据中推断出这些高斯分布的参数(均值、方差和混合系数)。以下是混合高斯随机变量参数估计的常用方法:
1. 极大似然估计(Maximum Likelihood Estimation, MLE)
直接对混合高斯模型的似然函数进行最大化通常是很困难的,因为似然函数中包含了对隐变量(即每个数据点来自哪个高斯分布)的求和,这使得直接优化变得复杂。
2. 期望-最大化算法(Expectation-Maximization, EM)
EM算法是处理含有隐变量的统计模型参数估计的一种常用方法。对于混合高斯模型,EM算法的具体步骤如下:
E步骤(Expectation Step)
- 计算每个数据点来自每个高斯分布的概率(即后验概率)。这些概率被称为责任度(responsibilities)。
- 对于每个数据点 x i x_i xi和每个高斯分布 k k k,责任度 γ ( z i k ) \gamma(z_{ik}) γ(zik)定义为:
γ ( z i k ) = π k N ( x i ∣ μ k , Σ k ) ∑ j = 1 K π j N ( x i ∣ μ j , Σ j ) \gamma(z_{ik}) = \frac{\pi_k \mathcal{N}(x_i | \mu_k, \Sigma_k)}{\sum_{j=1}^K \pi_j \mathcal{N}(x_i | \mu_j, \Sigma_j)} γ(zik)=∑j=1KπjN(xi∣μj,Σj)πkN(xi∣μk,Σk)
其中, π k \pi_k πk是第 k k k个高斯分布的混合系数, N ( x ∣ μ , Σ ) \mathcal{N}(x | \mu, \Sigma) N(x∣μ,Σ)是高斯分布的概率密度函数。
M步骤(Maximization Step)
-
使用责任度来更新每个高斯分布的参数:
- 混合系数 π k \pi_k πk:
π k = 1 N ∑ i = 1 N γ ( z i k ) \pi_k = \frac{1}{N} \sum_{i=1}^N \gamma(z_{ik}) πk=N1i=1∑Nγ(zik) - 均值 μ k \mu_k μk:
μ k = ∑ i = 1 N γ ( z i k ) x i ∑ i = 1 N γ ( z i k ) \mu_k = \frac{\sum_{i=1}^N \gamma(z_{ik}) x_i}{\sum_{i=1}^N \gamma(z_{ik})} μk=∑i=1Nγ(zik)∑i=1Nγ(zik)xi - 协方差矩阵 Σ k \Sigma_k Σk:
Σ k = ∑ i = 1 N γ ( z i k ) ( x i − μ k ) ( x i − μ k ) T ∑ i = 1 N γ ( z i k ) \Sigma_k = \frac{\sum_{i=1}^N \gamma(z_{ik}) (x_i - \mu_k)(x_i - \mu_k)^T}{\sum_{i=1}^N \gamma(z_{ik})} Σk=∑i=1Nγ(zik)∑i=1Nγ(zik)(xi−μk)(xi−μk)T
- 混合系数 π k \pi_k πk:
-
重复E步骤和M步骤直到参数收敛。
3. 贝叶斯估计(Bayesian Estimation)
贝叶斯估计方法可以考虑参数的先验分布,并通过贝叶斯推断来得到参数的后验分布。这种方法通常涉及到更复杂的计算,但可以提供参数的不确定性估计。
4. 变分推断(Variational Inference)
对于复杂的模型,变分推断是一种近似贝叶斯推断的方法,它通过优化一个下界来逼近真实的后验分布。
5. 马尔科夫链蒙特卡洛(Markov Chain Monte Carlo, MCMC)
MCMC方法是一种通过模拟随机过程来估计参数后验分布的方法。虽然它在某些情况下可能计算量较大,但它可以提供非常灵活的模型推断。
混合高斯随机分布(Gaussian Mixture Model, GMM)的参数估计
通常使用期望最大化(Expectation Maximization, EM)算法。在Julia中,我们可以借助一些数值计算和机器学习的库来实现GMM。以下是一个关于GMM参数估计的详细步骤以及Julia实现的示例。
参数估计步骤
-
初始化:
- 随机初始化每个高斯分量的均值(means)、协方差矩阵(covariances)和混合权重(weights)。
-
E步(Expectation Step):
- 根据当前参数,计算每个观测数据点属于各个高斯分量的后验概率,这些概率也被称为责任度(responsibilities)。
-
M步(Maximization Step):
- 使用E步计算得到的责任度来更新每个高斯分量的参数:
- 更新均值:为每个分量计算所有观测数据点的加权平均。
- 更新协方差矩阵:为每个分量计算加权后的协方差。
- 更新混合权重:为每个分量计算责任度的总和并归一化。
- 使用E步计算得到的责任度来更新每个高斯分量的参数:
-
迭代:
- 重复E步和M步,直到参数的变化小于某个预设的阈值或达到最大迭代次数。
-
收敛:
- 当参数收敛时,算法结束,输出最终的参数估计。
Julia实现
以下是一个使用Julia实现GMM的简化示例。在实际应用中,你可能需要更复杂的代码来处理初始化、收敛判断、数值稳定性等问题。
using Distributions # 用于高斯分布的计算
using LinearAlgebra # 用于矩阵运算# 定义GMM模型结构
struct GMMmeans::Matrix{Float64} # 均值矩阵,每行是一个分量的均值covariances::Array{Float64, 3} # 协方差矩阵数组,每个分量一个矩阵weights::Vector{Float64} # 混合权重向量n_components::Int # 高斯分量个数
end# 初始化GMM模型
function initialize_gmm(data, n_components)d = size(data, 2) # 数据维度means = data[randperm(size(data, 1))[1:n_components], :] # 随机选择初始均值covariances = Array{Float64, 3}(undef, d, d, n_components) # 初始化协方差矩阵数组for k in 1:n_componentscovariances[:, :, k] = cov(data) # 初始化为数据协方差,实际中应使用更合理的初始化方法endweights = ones(n_components) / n_components # 初始化权重为均匀分布GMM(means, covariances, weights, n_components)
end# E步:计算责任度
function e_step(gmm, data)n = size(data, 1)k = gmm.n_componentsresponsibilities = zeros(n, k)for i in 1:nfor j in 1:kresponsibilities[i, j] = gmm.weights[j] * pdf(MultivariateNormal(gmm.means[j, :], gmm.covariances[:, :, j]), data[i, :])endresponsibilities[i, :] = responsibilities[i, :] / sum(responsibilities[i, :]) # 归一化endresponsibilities
end# M步:更新参数
function m_step(gmm, data, responsibilities)n = size(data, 1)d = size(data, 2)k = gmm.n_componentsnew_means = zeros(k, d)new_covariances = zeros(d, d, k)new_weights = zeros(k)for j in 1:kresp_sum = sum(responsibilities[:, j])new_weights[j] = resp_sum / nfor i in 1:nnew_means[j, :] += responsibilities[i, j] * data[i, :]endnew_means[j, :] /= resp_sumfor i in 1:ndiff = data[i, :] - new_means[j, :]new_covariances[:, :, j] += responsibilities[i, j] * (diff' * diff)endnew_covariances[:, :, j] /= resp_sumendGMM(new_means, new_covariances, new_weights, k)
end# EM算法主循环
function em_algorithm(data, n_components, max_iter=100, tol=1e-4)gmm = initialize_gmm(data, n_components)for iter in 1:max_iterresponsibilities = e_step(gmm, data)new_gmm = m_step(gmm, data, responsibilities)# 收敛判断(可省略或根据实际需要实现)# if ... break endgmm = new_gmm # 更新模型endgmm
end# 示例数据
data = [randn(100, 2) + 2; randn(100, 2) - 2] # 两个高斯分量的混合数据# 训练GMM模型
gmm_model = em_algorithm(data, 2)# 输出结果
println("Means:")
println(gmm_model.means)
println("Covariances:")
println(gmm_model.covariances)
println("Weights:")
println(gmm_model.weights)
注意事项
-
初始化:在实际应用中,初始化的选择对算法的收敛速度和结果有很大影响。常用的初始化方法包括K-means聚类或随机选择数据点作为初始均值。
-
数值稳定性:在计算协方差矩阵时,需要确保矩阵是正定的。如果数据点很少或分布非常集中,可能会导致协方差矩阵接近奇异或不稳定。可以通过添加小的正则项或使用其他数值稳定技术来解决这个问题。
-
收敛判断:在EM算法的迭代过程中,需要判断参数是否已经收敛。常用的收敛判据包括参数变化量的小于某个阈值或似然函数的变化量小于某个阈值。
-
模型选择:在实际应用中,可能需要选择合适的高斯分量个数。这可以通过交叉验证、似然函数值比较或领域知识等方法来实现。
-
库函数:在实际应用中,建议使用成熟的机器学习库(如scikit-learn、TensorFlow、PyTorch等)中的GMM实现,这些库通常提供了更稳定、高效的算法和更多的功能选项。在Julia中,也可以考虑使用
MixtureModels或其他相关库。
参考文献
- 文心一言
- 《多元统计分析》
相关文章:

数模原理精解【9】
文章目录 混合高斯分布概述定义性质参数估计计算Julia实现 详述定义原理 核心参数1. 均值(Means)2. 协方差矩阵(Covariance Matrices)3. 权重(Weights)4. 聚类个数(高斯模型个数,K&a…...

Java中的linkedList类及与ArrayList的异同
继承实现关系 public class LinkedList<E>extends AbstractSequentialList<E>implements List<E>, Deque<E>, Cloneable, java.io.Serializable 由于涉及的类过多,画起来过于繁琐,这里只展示最外层的继承实现关系 可以看到它是…...

【精选】文件摆渡系统:跨网文件传输的安全与效率之选
文件摆渡系统可以解决哪些问题? 文件摆渡系统(File Shuttle System)主要是应用于不同网络、网段、区域之间的文件数据传输流转场景, 用于解决以下几类问题: 文件传输问题: 大文件传输:系统可…...

tkinter 电子时钟 实现时间日期 可实现透明 无标题栏
下面是一个使用tkinter库实现的简单电子时钟的例子,可以显示当前的日期和时间,并且可以设置窗口为透明且无标题栏。 import tkinter as tk import timedef update_time():current_time time.strftime("%Y-%m-%d %H:%M:%S")label.config(text…...

【hot100-java】【除自身以外数组的乘积】
R8-普通数组篇 印象题,计算前缀,计算后缀,计算乘积。 class Solution {public int[] productExceptSelf(int[] nums) {int n nums.length;int[] prenew int[n];pre[0]1;for (int i1;i<n;i){pre[i]pre[i-1]*nums[i-1];}int[] sufnew int[…...

【Python机器学习】循环神经网络(RNN)——审察模型内部情况
Keras附带了一些工具,比如model.summary(),用于审察模型内部情况。随着模型变得越来越复杂,我们需要经常使用model.summary(),否则在调整超参数时跟踪模型内部的内容的变化情况会变得非常费力。如果我们将模型的摘要以及验证的测试…...

智能语音交互:人工智能如何改变我们的沟通方式?
在科技飞速发展的今天,人工智能(AI)已经渗透到我们生活的方方面面。其中,智能语音交互作为AI技术的一个重要分支,正以前所未有的速度改变着我们的沟通方式。从智能家居的控制到办公自动化的应用,再到日常交…...

vue3中动态引入本地图片的两种方法
方法一 <img width"10" height"10":src"/src/assets/nncs2/jiantou${index 1}.png" alt"" /> 推荐 简单好用 方法二 const getImg index > {const modules import.meta.glob(/assets/nncs2/**/*.{png,svg,jpg,jpeg}, { …...

Linux网络——socket编程与UDP实现服务器与客户机通信
文章目录 端口号TCP/UDP网络字节序socket的常见APIUDP实现服务器与客户机通信服务器客户机运行效果如下 端口号 我们说即便是计算机网络,他们之间的通信也仍然是进程间通信 那么要如何在这么多计算机中,找到你想要的那个进程呢 在网络中标识的唯一的计…...

大型语言模型中推理链的演绎验证
大语言模型(LLMs)在执行各种推理任务时,由于引入了链式推理(Chain-of-Thought,CoT)提示,显著受益。尽管CoT使模型产生更全面的推理过程,但其对中间推理步骤的强调可能会无意中引入幻…...

openharmony 应用支持常驻和自启动
本文环境: devEco studio 版本 4.0.0.600 SDK版本:3.2.12.5 full SDK 应用模型:Stage 功能简介: OpenHarmony支持包含ServiceExtensionAbility类型模块的应用配置常驻和自启动。 关于ServiceExtensionAbility其他的介绍可以参考官网:ServiceExtensionAbility(仅对…...

Winform中引入WPF控件后键盘输入无响应
引言 Winform中如何引入WPF控件的教程很多,对于我们直接通过ElementHost引入的直接显示控件,它是可以响应键盘输入消息的,但对于在WFP中弹出的窗体来说,此时是无法响应我们的键盘输入的。我们需要给它使能键盘输入。 1、使能键盘…...

多线程——死锁
死锁 在Java中使用多线程,就会有可能导致死锁问题。死锁会让程序一直卡住,程序不再往下执行。 我们只能通过中止并重启的方式来让程序重新执行。 这是我们非常不愿意看到的一种现象,我们要尽可能避免死锁的情况发生! 死锁的原因…...
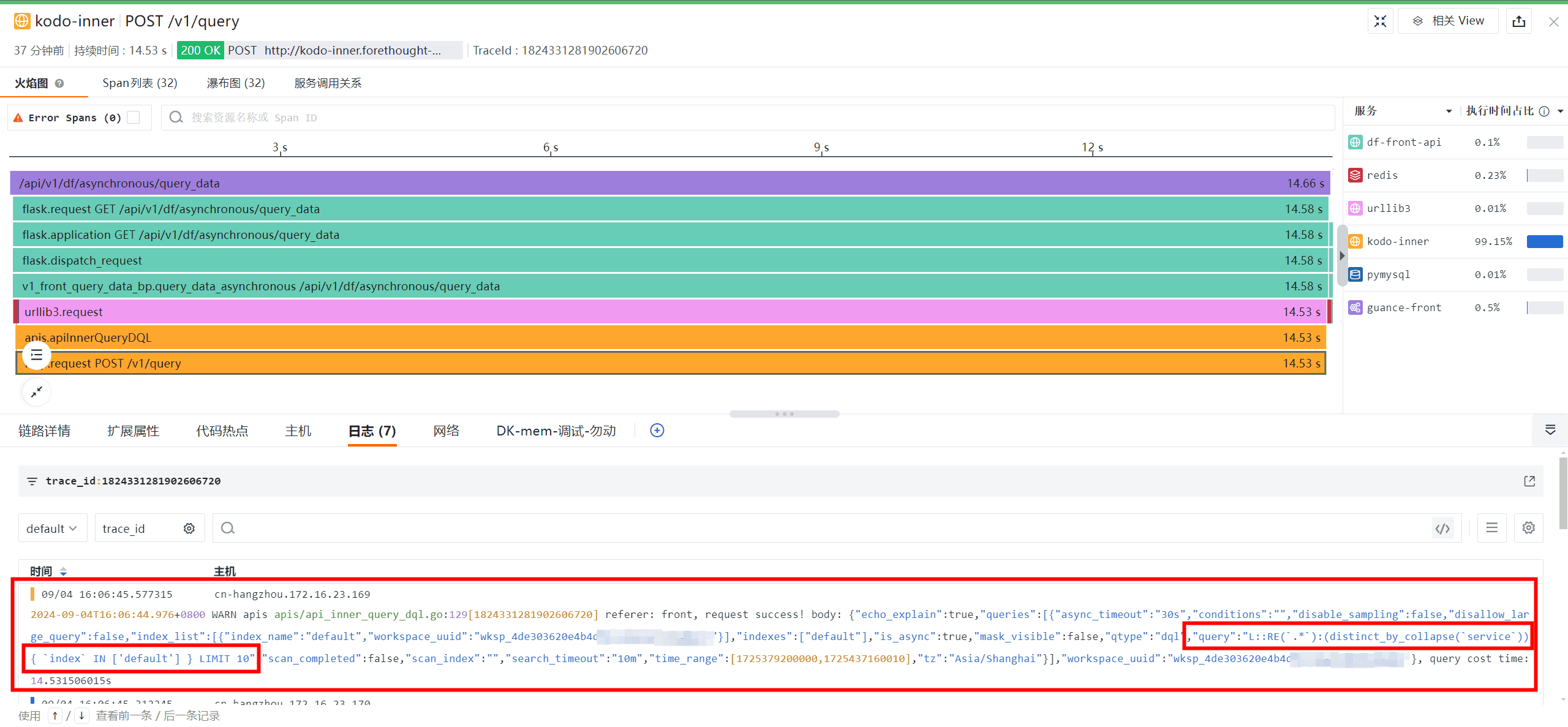
链路追踪可视化利器之火焰图
随着现代化技术的发展,为了能够保证 IT 系统的稳定性、高扩容性,企业往往采用分布式的方式来构建 IT 系统。但也正因为如此,IT 系统中涉及到的服务和组件可能被分布在不同的服务器、数据中心甚至不同的地理位置,这导致应用发生故障…...

C语言 ——— 条件编译指令实际用途
目录 前言 头文件被包含的方式 嵌套文件包含 使用条件编译指令规避头文件多次包含 还有一个编译指令,同样能做到以上功能 前言 条件编译指令多用于对头文件的定义和判断以及删除 头文件被包含的方式 本地文件包含(也就是自己创建的头文件ÿ…...
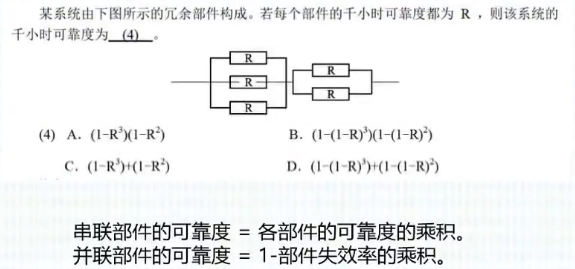
备战软考Day01-计算机系统
1.数值及其转化 1.数值转化(十进制) 2.十进制推广 3.进制转化 4.数据表示 1.原码 2.反码 3.补码 4.移码 5.定点数 就是小数点的位置固定不变的数。小数点的位置通常有两种约定方式:定点整数(纯整数,小数点在最低有效数值位之后…...

从C语言过渡到C++
📔个人主页📚:秋邱-CSDN博客☀️专属专栏✨:C 🏅往期回顾🏆:单链表实现:从理论到代码-CSDN博客🌟其他专栏🌟:C语言_秋邱的博客-CSDN博客 目录 …...

Docker 的安装和使用
参考资料: 通俗易懂了解什么是docker?Docker 教程 | 菜鸟教程Ubuntu 22.04 安装 DockerDocker 超详细基础教程WSL2 支持 systemctl 命令systemd 和 systemctl 是什么?使用正确的命令重启 WSL 子系统Ubuntu 修改源镜像方法Docker 中出现 ‘/etc/resolv.…...

鸿蒙轻内核A核源码分析系列七 进程管理 (2)
往期知识点记录: 鸿蒙(HarmonyOS)应用层开发(北向)知识点汇总 轻内核A核源码分析系列一 数据结构-双向循环链表 轻内核A核源码分析系列二 数据结构-位图操作 轻内核A核源码分析系列三 物理内存(1࿰…...

关于TypeScript使用讲解
TypeScript讲解 安装环境 1.安装node js 配置环境变量 2.在终端中 运行 npm i -g typescript typescript: 用于编译ts代码 提供了 tsc命令 实现了将 TS>>>> JS转换 验证: tsc -v 编译并运行 TS代码 1.创建ts文件(TS文件为后缀名的文件࿰…...

用Python实战脑电分析:手把手教你计算PLV、MVL、MI跨频耦合指标
Python脑电分析实战:PLV、MVL、MI跨频耦合指标全流程解析 神经振荡的跨频耦合(Cross-Frequency Coupling, CFC)分析正在成为探索大脑信息处理机制的重要工具。想象一下,当你面对一组EEG数据时,如何从复杂的波形中提取出…...

从信号处理到AI:卷积的含参积分本质,如何帮你理解PyTorch中的Conv1d层?
从信号处理到AI:卷积的含参积分本质,如何帮你理解PyTorch中的Conv1d层? 在信号处理领域,卷积操作早已是工程师们耳熟能详的工具。但当我们踏入深度学习的殿堂,面对PyTorch中的nn.Conv1d层时,是否曾疑惑过&a…...

【Perplexity诗词歌赋搜索黑科技】:20年NLP专家首度公开5大语义对齐技巧,让古诗检索准确率飙升至98.7%
更多请点击: https://kaifayun.com 第一章:Perplexity诗词歌赋搜索黑科技全景透视 Perplexity 并非专为古籍设计的搜索引擎,但其基于大语言模型的实时语义理解与多源交叉验证机制,意外地在诗词歌赋领域展现出颠覆性能力——它不依…...

告别Resources.Load!Unity动态加载材质资源的最佳实践与性能优化指南
Unity材质资源动态加载:从基础实现到架构级优化方案 在AR涂鸦、实时换装、用户自定义皮肤等现代游戏交互场景中,动态材质加载已成为核心需求。传统Resources.Load虽简单直接,但在大型项目中常引发资源管理混乱、内存泄漏和热更新障碍。本文将…...

CrapFixer深度解析:为什么这个7年老工具依然是Windows优化的首选
CrapFixer深度解析:为什么这个7年老工具依然是Windows优化的首选 【免费下载链接】Crapfixer Cr*ap Fixer 项目地址: https://gitcode.com/gh_mirrors/cr/Crapfixer 在Windows 11和Windows 10系统中,你是否厌倦了无处不在的广告、烦人的数据收集和…...

通过 curl 命令快速测试 Taotoken 大模型接口连通性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过 curl 命令快速测试 Taotoken 大模型接口连通性 在接入大模型服务时,直接使用 curl 命令进行接口测试是一种高效且…...

Perplexity翻译查询功能实测对比:比DeepL快3.7倍、准确率提升22%的关键配置参数曝光
更多请点击: https://intelliparadigm.com 第一章:Perplexity翻译查询功能实测对比总览 Perplexity 作为一款以实时网络检索与推理能力见长的AI问答工具,其内置翻译查询功能并非独立模块,而是深度集成于自然语言理解流程中。在实…...

四旋翼无人机深度强化学习控制框架与实战优化
1. 四旋翼无人机端到端深度强化学习框架解析四旋翼无人机的自主飞行控制一直是机器人学领域的核心挑战。传统PID控制虽然稳定可靠,但在复杂动态环境中表现受限。深度强化学习(DRL)通过模拟环境交互实现智能决策,为无人机控制带来了…...

Bee 蜂群效应智能体架构
第一章 绪论 1.1 研究背景与问题提出 在通用人工智能(AGI)发展的演进脉络中,传统单体大模型的“规模即智能”范式正面临算力瓶颈、泛化能力受限以及系统脆弱性等多重挑战。这种中心化架构在面对动态、开放的复杂环境时,其自适应与持续学习能力显得尤为不足。在此背景下,…...

研究生你的救星来了
为了找一个研究方向的核心文献,我要同时打开知网、Web of Science、IEEE Xplore三个数据库,翻几十篇顶刊摘要,还要手动整理每个文献的研究方法、核心结论,熬到凌晨两点,结果还是理不清整个领域的研究脉络。直到上个月朋…...