论文学习——Tune-A-Video
Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation
Abstract
本文提出了一种方法,站在巨人的肩膀上——在大规模图像数据集上pretrain并表现良好的 text to image 生成模型——加入新结构并进行微调,训练出一套 one shot 的 text to video 生成器。这样做的优点在于利用已经非常成功、风格多样的图像扩散生成模型,在其基础上进行扩展,同时其训练时间很短,大大降低了训练开销。作为one shot 方法,tune a video还需要额外信息,一个文本-视频对儿作为demo。
作者对于T2I(text to image)模型得到了两个观察:
(1)T2I模型可以生成·展示动词项效果的·静止图像
(2)扩展T2I模型同时生成的多张图像展现出了良好的内容一致性。
有了这两个观察作为基础,其实生成视频的关键就在于如何保证一致的物体的连续运动。
为了更进一步,学习到连贯的动作,作者设计出one shot 的 Tune-A-Video模型。这个模型涉及到一个定制的时空注意力机制,以及一个高效的one shot 调整策略(tuning strategy)。在推理阶段,使用DDIM的inversion过程(我个人理解是DDIM的扩散阶段,待我读完后文再确定)来为采样过程提供结构性的引导。
1. Introduction
为在T2V领域赋值T2I生成模型的成果经验,有许多模型[30,35,6,42,40]也尝试将空间领域的T2I生成模型拓展到时空领域。它们通常在大规模的text-video数据集上采取标准的训练范式,效果很好,但计算开销太大太耗时。
本模型的思路:在大规模text-image数据集上完成预训练的T2I模型以及有了开放域概念的许多知识,那简单给它一个视频样例,它是否能够自行推理出其他的视频呢?
One-Shot Video Tuning,仅使用一个text-video对儿来训练T2V生成器,这个生成器从输入视频中捕获基础的动作信息,然后根据修改提示(edited prompts)生成新颖的视频。

上面abstract提到,生成视频的关键就在于如何保证一致的物体的连续运动。下面,作者从sota的T2I扩散模型中进行如下观察,并依此激励我们的模型。
(1)关于动作:T2I模型能够很好地根据包括动词项在内的文本生成的图片。这表明T2I模型在静态动作生成上,可以通过跨模态的注意力来考虑到文本中的动词项。
(2)关于一致的物体:简单的将T2I模型中的空间自注意力进行扩展,使之从生成一张图片变为生成多张图片,足可以生成内容一致的不同帧,如图2第1行是内容和背景不同的多张图像,而图2第2行是相同的人和沙滩。不过动作仍不是连续的,这表明T2I中的自注意力层只关注空间相似性而不关注像素点的位置。
Tune A Video方法是在sota 的T2I模型在时空维度上的简单膨胀。为避免计算量的平方级增长,对于帧数不断增多的任务来说,这种方案显然是不可行的。另外,使用原始的微调方法,更新所有的参数可能会破坏T2I模型已有的知识,并阻碍新概念视频的生成。为解决这个问题,作者使用稀疏的时空注意力机制而非full attention,仅使用视频的第一帧和前一帧,至于微调策略,只更新attention 块儿中的投影矩阵。以上操作只保证视频帧中的内容的一致性,但并不保证动作的连续性。
因此,在推理阶段,作者通过DDIM的inversion过程,从输入视频中寻求structure guidance。将该过程得到的逆转潜向量作为初始的噪音,这样来产生时间上连贯、动作平滑的视频帧。
作者贡献:
(1)为T2V生成任务提出了一类新的模型One-Shot Video Tuning,这消除了模型在大尺度视频数据集上训练的负担
(2)这是第一个使用T2I实现T2V生成任务的框架
(3)使用高效的attention tuning和structural inversion来显著提升时序上的联系性
3.2 网络膨胀
先说T2I模型,以LDM模型为例,使用U-Net,先使用孔家下采样再使用上采样,并保持跳联。U-Net由堆叠的2d残差卷积和transformer块儿们组成。每个transformer块儿都有一个空间自注意力层,一个交叉注意力层,一个前馈网络组成。空间自注意力层利用feature map中的像素位置寻找相似关系;交叉注意力则考虑像素和条件输入之间的关系。
zvi表示video的第vi帧,空间自注意力可以表示为如下形式
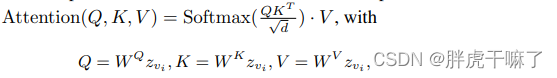
下面讲怎么改:
- 将二维的LDM转换到时空域上:
(1)将其中的2d卷积层膨胀为伪3d卷积层,3x3变为1x3x3这样;
(2)对于每个transformer块儿加入时序的自注意力层(,以完成时间建模);
(3)(为增强时序连贯性,)将空间自注意力机制转为时空自注意力机制。转换的方法并不是使用full attention 或者causal attention,它们也能捕获时空一致性。但由于在introduction中提到的开销问题,显然并不适用。本文采用的是系数的causal attention,将计算量从O((mN)2)转为了O(2mN2),其中m为帧数,N为每帧中的squence数目。需要注意的是,这种自注意力机制里,计算query的向量是zvi,计算key和value使用的向量则是v1和vi-1的拼接。
4.4 微调和推理
模型微调
为获得时序建模能力,使用输入视频微调网络。
由于时空注意力机制通过查询之前帧上的相关位置来建模其时序一致性。因此固定ST-Attn layers中的WK和WV,仅更新投影矩阵WQ。
而对于新加入的时序自注意力层,则更新所有参数,因为新加入层的参数不包含先验。
对于交叉注意力Cross-Attn,则通过更新Query的投影矩阵(query projection)来完善text-video的对应关系。
这样的微调,相对于完全调整来说更节约计算开销,并且也有助于保持原有T2I预训练所得到的的原有性质。下图中标亮了所有需要更新参数的模块。
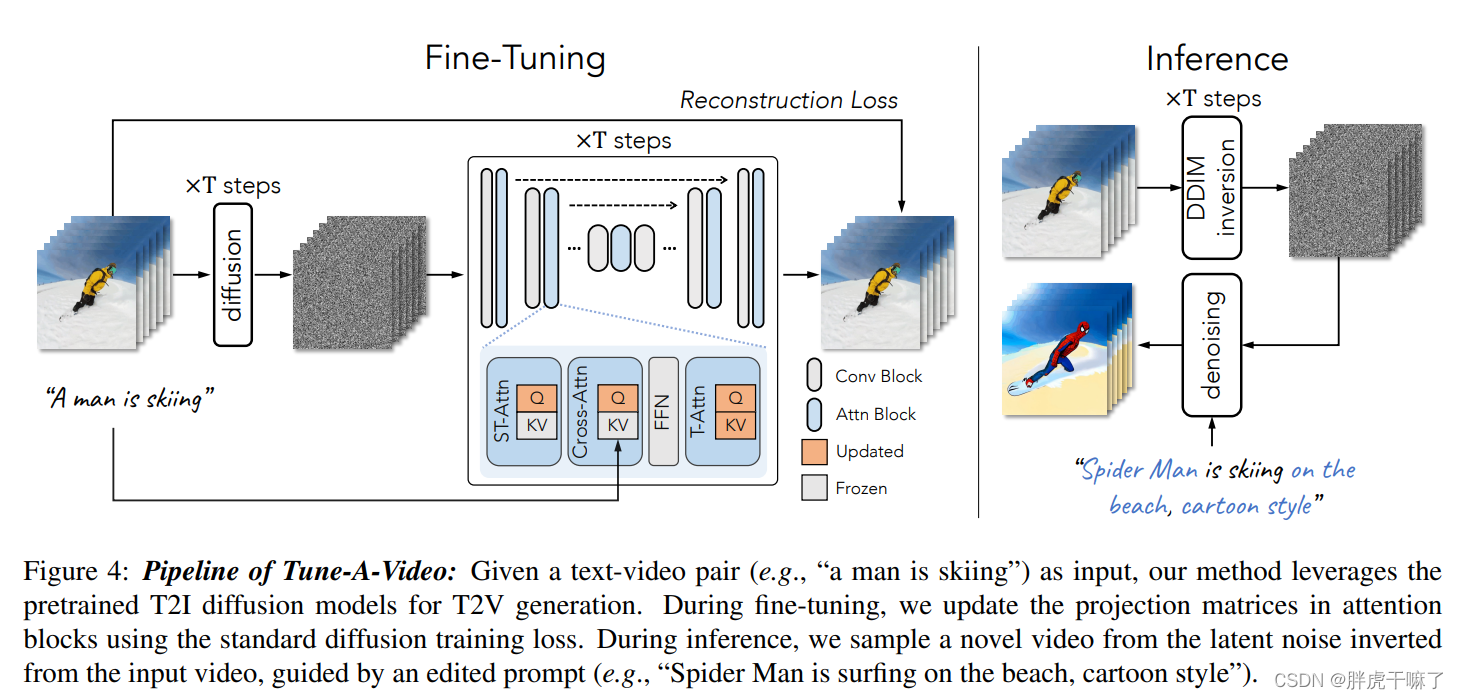
通过DDIM的inversion获得结构上的指导
为了更好地确保不同帧之间的像素移动,在推理阶段,本模型从原视频中引入结构的指导。具体来说,通过DDIM的inversion过程,从没有文本条件的原视频中能够提取出潜向量噪音。这种噪音作为DDIM采样过程的起点,同时受到编辑提示edited prompt T*的引导,进入DDIM的采样过程,输出视频可以表示如下
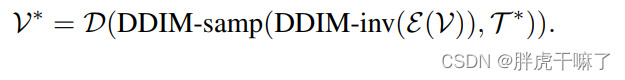
相关文章:
论文学习——Tune-A-Video
Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation Abstract 本文提出了一种方法,站在巨人的肩膀上——在大规模图像数据集上pretrain并表现良好的 text to image 生成模型——加入新结构并进行微调,训练出一套 …...

C++类与对象part1
目录 1.类的6个默认函数 2.构造函数(相当于init) 3.析构函数 (相当于destroy) 4.拷贝构造函数 赋值运算符重载 运算符重载 赋值运算符重载 引入: 你知道为什么cout可以自动识别类型吗? 其实cout是一…...

记一次抓取网页内容
已打码 // UserScript // name --------- // namespace http://tampermonkey.net/ // version 0.1 // description https://---------oups/{id}/topics?scopeall&count20&begin_time2022-09-01T00%3A00%3A00.000%2B0800&end_time2022-10-01T00%…...
parasoft帮助史密斯医疗通过测试驱动开发提供安全、高质量的医疗设备
parasoft是一家专门提供软件测试解决方案的公司,Parasoft通过其经过市场验证的自动化软件测试工具集成套件,帮助企业持续交付高质量的软件。Parasoft的技术支持嵌入式、企业和物联网市场,通过将静态代码分析和单元测试、Web UI和API测试等所有…...

SpringBoot整合Oauth2开放平台接口授权案例
<!-- SpringBoot整合Web组件 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.projectlombok</groupId>&l…...

Linux_创建用户
创建一个名为hello的用户,并指定/home/hello为根目录useradd -d /home/hello -m hello 设置密码 ,密码会输入两次,一次设置密码,一次确认密码,两次密码要输入的一样passwd hellouseradd的常用参数含义-d指定用户登入时的主目录&am…...

RDD(弹性分布式数据集)总结
文章目录一、设计背景二、RDD概念三、RDD特性四、RDD之间的依赖关系五、阶段的划分六、RDD运行过程七、RDD的实现一、设计背景 1.某些应用场景中,不同计算阶段之间会重用中间结果,即一个阶段的输出结果会作为下一个阶段的输入。如:迭代式算法…...

服务器版RstudioServer安装与配置详细教程
Docker部署Rstudio server 背景:如果您想在服务器上运行RstudioServer,可以按照如下方法进行操作,笔者测试时使用腾讯云服务器(系统centos7),需要在管理员权限下运行 Rstudio 官方提供了使用不同 R 版本的 …...

如何在Java中将一个列表拆分为多个较小的列表
在Java中,有多种方法可以将一个列表拆分为多个较小的列表。在本文中,我们将介绍三种不同的方法来实现这一目标。 方法一:使用List.subList()方法 List接口提供了一个subList()方法,它可以用来获取列表中的一部分元素。我们可以使…...

TryHackMe-Inferno(boot2root)
Inferno 现实生活中的机器CTF。该机器被设计为现实生活(也许不是?),非常适合刚开始渗透测试的新手 “在我们人生旅程的中途,我发现自己身处一片黑暗的森林中,因为直截了当的道路已经迷失了。我啊…...

微信原生开发中 JSON配置文件的作用 小程序中有几种JSON配制文件
关于json json是一种数据格式,在实际开发中,JSON总是以配制文件的形式出现,小程序与不例外,可对项目进行不同级别的配制。Q:小程序中有几种配制文件A:小程序中有四种配制文件分别是:project.config.json si…...

【python】为什么使用python Django开发网站这么火?
关注“测试开发自动化” 弓中皓,获取更多学习内容) Django 是一个基于 Python 的 Web 开发框架,它提供了许多工具和功能,使开发者可以更快地构建 Web 应用程序。以下是 Django 开发中的一些重要知识点: MTV 模式&#…...

Java设计模式(五)—— 责任链模式
责任链模式定义如下:使多个对象都有机会处理请求,从而避免请求的发送者与接收者之间的耦合关系。将这些对象连成一条链,并沿着这条链传递该请求,知道有一个对象处理它为止。 适合使用责任链模式的情景如下: 有许多对…...

VMLogin:虚拟浏览器提供的那些亮眼的功能
像VMLogin这样的虚拟浏览器具有多种功能,如安全的浏览环境、可定制的设置、跨平台的兼容性、更快的浏览速度、广告拦截等等。 虚拟浏览器的不同功能可以为您做什么? 使用虚拟浏览器是浏览互联网和完成其他任务的安全方式,没有风险。您可以在…...

第一个错误的版本
题目 你是产品经理,目前正在带领一个团队开发新的产品。不幸的是,你的产品的最新版本没有通过质量检测。由于每个版本都是基于之前的版本开发的,所以错误的版本之后的所有版本都是错的。 假设你有 n 个版本 [1, 2, …, n],你想找出…...

2023爱分析·AIGC市场厂商评估报告:拓尔思
AIGC市场定义 市场定义: AIGC,指利用自然语言处理技术(NLP)、深度神经网络技术(DNN)等人工智能技术,基于与人类交互所确定的主题,由AI算法模型完全自主、自动生成内容,…...

MobTech|场景唤醒的实现
什么是场景唤醒? 场景唤醒是moblink的一项核心功能,可以实现从打开的Web页面,一键唤醒App,并恢复对应的场景。 场景是指用户在App内的某个特定页面或状态,比如商品详情页、活动页、个人主页等。每个场景都有一个唯一…...
不在路由器上做端口映射,如何访问局域网内网站
假设现在外网有一台ADSL直接拨号上网的电脑,所获得的是公网IP。然后它想访问局域网内的电脑上面的网站,那么就需要在路由器上做端口映射。在路由器上做端口映射的具体规则是:将所有发向自己端口的数据,都转发到内网的计算机。 访…...

ChatGPT 辅助科研写作
前言 总结一些在科研写作中 ChatGPT 的功能,以助力提升科研写作的效率。 文章目录前言一、ChatGPT 简介1. ChatGPT 普通版与 Plus 版的区别1)普通账号2)Plus账号二、New Bing 简介1. 快速通过申请三、辅助学术写作1. 改写论文表述2. 语言润色…...
MySQL最大建议行数 2000w,靠谱吗?
本文已经收录到Github仓库,该仓库包含计算机基础、Java基础、多线程、JVM、数据库、Redis、Spring、Mybatis、SpringMVC、SpringBoot、分布式、微服务、设计模式、架构、校招社招分享等核心知识点,欢迎star~ Github地址 1 背景 作为在后端圈开车的多年…...

忘记压缩包密码怎么办?5分钟学会用ArchivePasswordTestTool找回密码
忘记压缩包密码怎么办?5分钟学会用ArchivePasswordTestTool找回密码 【免费下载链接】ArchivePasswordTestTool 利用7zip测试压缩包的功能 对加密压缩包进行自动化测试密码 项目地址: https://gitcode.com/gh_mirrors/ar/ArchivePasswordTestTool 你是否曾经…...

ARM架构ID_ISAR4寄存器详解与应用
1. ARM架构中的ID_ISAR4寄存器概述在ARMv8架构体系中,系统寄存器扮演着处理器功能特性的关键角色。作为指令集属性寄存器家族的重要成员,ID_ISAR4(Instruction Set Attribute Register 4)专门用于描述处理器在AArch32执行状态下支…...

雷达系统原理与脉冲测量技术详解
1. 雷达系统基础原理与核心方程雷达(RADAR)是Radio Detection And Ranging的缩写,其基本原理是通过发射电磁波并接收目标反射信号来实现探测和测距。雷达方程是理解雷达系统性能的基础数学表达式:Pr (Pt * G * λ * σ) / ((4π)…...

基于LLM的AI新闻智能体:自动化信息采集与周报生成实战
1. 项目概述:一个能自动追踪AI新闻的智能体 最近在GitHub上看到一个挺有意思的项目,叫 ai-news-weekly-agent 。光看名字,你大概能猜到它是个和AI新闻相关的自动化工具。没错,它的核心目标就是扮演一个“AI新闻周刊编辑”的角色…...
、GELU激活函数与数据预处理那些事儿)
BERT PyTorch实现避坑指南:torch.gather()、GELU激活函数与数据预处理那些事儿
BERT PyTorch实现避坑指南:torch.gather()、GELU激活函数与数据预处理那些事儿 当你第一次尝试在PyTorch中实现BERT模型时,可能会遇到一些令人困惑的技术细节。本文将从实际调试的角度,深入解析三个最容易卡住开发者的关键点:torc…...

山东反向旅游推荐“小众秘境古村落”
假期不想挤热门景区,只想寻一处安静古村放空散心?给大家整理山东4 个小众秘境古村落,全程 1-2.5 小时车程,适合近郊自驾、短途出游,原生态氛围拉满,人少景美超适合避峰出行。一、济南长清|方峪古…...

FAST开发方法在系统分析中四个阶段
在系统分析师考试中,被频繁考查的FAST(Framework for the Application of Systems Thinking)方法,是一个聚焦于系统分析阶段的框架。 它的核心是将复杂的分析工作拆解为四个环环相扣的阶段:初始研究、问题分析、需求分析和决策分析。 📊 四个阶段速览 阶段 核心任务 1…...
)
2026年山东大学软件学院创新项目实训博客(五)
2026年山东大学软件学院创新项目实训博客(五) 一、工作进展 本阶段 Agent 架构模块的核心推进是将父级编排从「单次补全加强制工具调用」升级为有界多轮循环,并同步完成系统提示词的多步能力声明、意图分类器的域关键词防误路由、以及 SSE 事…...

如何3分钟精准定位Windows热键冲突:Hotkey Detective深度技术解析
如何3分钟精准定位Windows热键冲突:Hotkey Detective深度技术解析 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective …...

IDM激活脚本:3分钟解锁完整版下载功能的终极指南
IDM激活脚本:3分钟解锁完整版下载功能的终极指南 【免费下载链接】IDM-Activation-Script-ZH IDM激活脚本汉化版 项目地址: https://gitcode.com/gh_mirrors/id/IDM-Activation-Script-ZH 还在为Internet Download Manager(IDM)的30天…...