用RNN(循环神经网络)预测股票价格
RNN(循环神经网络)是一种特殊类型的神经网络,它能够处理序列数据,并且具有记忆先前信息的能力。这种网络结构特别适合于处理时间序列数据、文本、语音等具有时间依赖性的问题。RNN的核心特点是它可以捕捉时间序列中的长期依赖关系。
RNN的基本结构
RNN由多个重复的单元组成,每个单元可以看作是一个小型的神经网络。这些单元按顺序处理序列中的每个元素,并且每个单元的输出不仅取决于当前的输入,还取决于前一个单元的输出。这种结构使得RNN能够在序列的不同时间点之间传递信息。
RNN的工作原理
-
输入:RNN接收一个序列作为输入,序列中的每个元素在不同的时间步骤被输入到网络中。
-
隐藏层:每个时间步骤,RNN都会计算一个隐藏状态,这个状态是当前输入和前一时间步骤隐藏状态的函数。隐藏状态可以看作是网络对到目前为止所观察到的所有输入的总结。
-
输出:在每个时间步骤,RNN可以产生一个输出,这个输出是基于当前的隐藏状态。对于某些任务,如语言模型或文本生成,输出可能是序列的下一个元素。
-
循环连接:RNN的每个单元都包含一个循环连接,这个连接将当前单元的输出反馈到下一个时间步骤的相同单元的输入中。这种循环连接是RNN能够处理序列数据的关键。
RNN的变体
由于标准的RNN在处理长序列时会遇到梯度消失或梯度爆炸的问题,因此出现了一些改进的RNN结构:
-
LSTM(长短期记忆网络):LSTM通过引入门控机制(输入门、遗忘门、输出门)来解决梯度消失的问题,使得网络能够学习到长期依赖关系。
-
GRU(门控循环单元):GRU是LSTM的一个简化版本,它将LSTM中的三个门减少为两个门(更新门和重置门),并且将细胞状态和隐藏状态合并为一个。
-
双向RNN(Bi-RNN):在双向RNN中,序列的每个元素同时被两个RNN处理,一个处理正向序列,另一个处理反向序列。这允许网络在每个时间步骤同时考虑前后文信息。
RNN的应用
RNN在许多领域都有广泛的应用,包括:
- 自然语言处理:如机器翻译、文本摘要、情感分析、语言模型。
- 语音识别:将语音信号转换为文本。
- 时间序列预测:如股票价格预测、天气预测。
RNN的这些应用通常涉及到序列数据的处理,其中序列中的元素之间存在时间上的依赖关系。通过学习这些依赖关系,RNN能够预测序列的未来走向或理解序列的模式。
要实现一个预测股票价格的循环神经网络(RNN)模型,我们需要考虑以下几个关键步骤:
- 数据收集:获取股票价格历史数据,通常包括开盘价、最高价、最低价、收盘价和成交量等。
- 数据预处理:包括数据清洗、归一化或标准化、序列构造等,以便于模型能够更好地学习和泛化。
- 模型设计:选择合适的RNN架构,如简单RNN、LSTM或GRU,并设计网络层结构。
- 模型训练:使用训练数据对模型进行训练,并调整参数以优化性能。
- 预测与评估:使用测试数据评估模型的预测能力,并选择合适的评估指标,如均方误差(MSE)。
接下来,我将提供一个简化的RNN模型实现案例,用于预测股票价格。
假设已经收集到了股票价格的历史数据,并将其存储在一个名为stock_prices.csv的文件中。数据预处理和模型设计将基于这个假设数据进行。
数据入口:用于学习的财经数据 - 飞书云文档 (feishu.cn)
接下来将使用Python来编写股票价格预测脚本,利用TensorFlow和Keras库构建和训练一个循环神经网络(RNN)模型。
Step1:导入所需的库
import pandas as pd
import numpy as np
from sklearn.preprocessing import MinMaxScaler
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, SimpleRNN
from tensorflow.keras.optimizers import Adam
import numpy as np
这里导入了数据处理(pandas)、数据预处理(MinMaxScaler)、神经网络模型构建(Sequential, Dense, SimpleRNN)和优化器(Adam)相关的库。
Step2:加载数据
data = pd.read_csv('stock_prices.csv')
使用pandas库从CSV文件中读取股票价格数据。
Step3:选择特征和标签
features = data[['Open', 'High', 'Low', 'Volume']]
labels = data['Close']
从数据中提取开盘价、最高价、最低价和成交量作为特征(用于训练模型),收盘价作为标签(模型的预测目标)。
Step4:数据归一化
scaler = MinMaxScaler(feature_range=(0, 1))
scaled_features = scaler.fit_transform(features)
scaled_labels = scaler.fit_transform(labels.values.reshape(-1, 1))
使用MinMaxScaler将特征和标签数据缩放到0和1之间,以帮助神经网络更好地学习。
这里创建了一个MinMaxScaler实例,并指定了特征范围feature_range为(0, 1)。这意味着所有的特征将被缩放到0和1之间。
fit_transform方法执行两个操作:首先,fit方法计算用于缩放数据的参数(即每个特征的最小值和最大值)。然后,transform方法使用这些参数来实际转换数据。features是包含所有特征数据的DataFrame,调用fit_transform后,这些特征将被缩放到0和1之间的范围。
这一步与上一步类似,但是它应用于标签数据。首先,由于labels是一个Series,使用.values将其转换为NumPy数组。然后,.reshape(-1, 1)将数组重塑为一个列向量,这是因为fit_transform期望输入数据的形状为 [n_samples, n_features]。在这个例子中,n_features是1,因为我们只有一个标签(收盘价)。
Step5:构造序列数据
def create_dataset(data, look_back=1):X, Y = [], [] # 初始化两个列表,X用于存储特征,Y用于存储标签for i in range(len(data) - look_back): # 遍历数据,直到长度减去look_backX.append(data[i:(i + look_back), :]) # 将从当前位置到look_back的数据追加到X列表Y.append(data[i + look_back, :]) # 将look_back之后的数据追加到Y列表return np.array(X), np.array(Y) # 将列表转换为NumPy数组并返回look_back = 1
X, Y = create_dataset(scaled_features, look_back)
参数说明:
data: 输入的时间序列数据,通常是二维数组,其中每一行代表一个时间步,每一列代表一个特征。look_back: 一个整数,表示在构造特征序列时回看的历史时间步数。默认值为1,表示只使用前一个时间步的数据作为特征。
函数内部逻辑:
-
初始化两个空列表
X和Y,用于存储特征和标签。 -
使用
for循环遍历数据,循环的范围是len(data) - look_back。这是因为我们需要确保对于每个起始索引i,都有足够的后续数据来构造一个长度为look_back的特征序列和一个对应的标签。 -
在每次循环中,使用切片操作
data[i:(i + look_back), :]来从数据中提取长度为look_back的子序列,并将其追加到X列表中。 -
同时,提取
look_back之后的数据行data[i + look_back, :]作为标签,并将其追加到Y列表中。 -
循环结束后,使用
np.array将X和Y列表转换为 NumPy 数组,并返回这两个数组。
调用 create_dataset 函数:
look_back = 1
X, Y = create_dataset(scaled_features, look_back)
这里,look_back 被设置为 1,表示每个特征序列将只包含一个时间步。然后,create_dataset 函数被调用来处理 scaled_features 数据(假设这是之前已经归一化的特征数据)。函数返回的 X 和 Y 将被用作训练模型的输入和目标数据。
简而言之,这段代码的目的是将原始时间序列数据转换为适合训练序列预测模型的形式,其中 X 包含多个时间步的特征序列,而 Y 是对应的标签数组。
Step6:创建模型
model = Sequential()
model.add(SimpleRNN(units=50, return_sequences=True, input_shape=(look_back, features.shape[1])))
model.add(SimpleRNN(units=50))
model.add(Dense(1))
创建一个序贯模型(Sequential),并添加了两层SimpleRNN和一个输出层(Dense)。第一个SimpleRNN层返回序列,第二个不返回。
Step7:编译模型
model.compile(optimizer=Adam(learning_rate=0.001), loss='mean_squared_error')
使用Adam优化器和均方误差损失函数来编译模型。
Step8:训练模型
model.fit(X, Y, epochs=100, batch_size=32, verbose=1)
使用提供的特征和标签数据训练模型,设置迭代次数为100,批量大小为32,并显示训练过程。
Step9:预测
predicted_prices = model.predict(X)
predicted_prices = scaler.inverse_transform(predicted_prices)
df_predicted = pd.DataFrame(predicted_prices, columns=['Predicted Close Price'])
df_predicted使用训练好的模型进行预测,并将预测结果从归一化后的值转换回原始尺度,结果如下:

以上就是用Python编写的一个股票价格预测脚本,利用了TensorFlow和Keras库来构建和训练一个循环神经网络(RNN)模型来预测股票价格的相对完整的过程。
想要了解更多多元化的数据分析视角,可以关注之前发布的相关内容。
相关文章:
用RNN(循环神经网络)预测股票价格
RNN(循环神经网络)是一种特殊类型的神经网络,它能够处理序列数据,并且具有记忆先前信息的能力。这种网络结构特别适合于处理时间序列数据、文本、语音等具有时间依赖性的问题。RNN的核心特点是它可以捕捉时间序列中的长期依赖关系…...
)
08-图7 公路村村通(C)
很明显聪明的同学已经发现,这是一个稠密图,所以用邻接矩阵。可以很好的表达,比邻接表有优势,所以,采用邻接矩阵破题, 当然也可以用邻接表,仔细观察我的AC,会发现其实都一样,只是存储…...
、wait()、join()、yield()的区别)
Java-sleep()、wait()、join()、yield()的区别
关于线程,作为八股文面试中必问点,我们需要充分了解sleep()、wait()、join()以及yield()的区别。在正式开始之前先让我们了解两个概念:锁池和等待池 1.锁池 所有需要竞争同步锁的线程都会放在锁池当中,比如当前对象的锁已经被其中…...

Linux命令的补全和自动完成完全开启
前言 在安装好RockyLinux8.8后,输入dn后,按下“TAB”能自动提示,但在输入dnf make后,按下“TAB”不能实现自动补全,如果要使Linux的Bash支持完整的自动提示和补全功能,还需要执行一些其它操作。 内容 1、…...

Deep Active Contours for Real-time 6-DoF Object Tracking
这篇论文解决了从RGB视频进行实时6自由度(6-DoF)物体跟踪的问题。此前的基于优化的方法通过对齐投影模型与图像来优化物体姿态,这种方法依赖于手工设计的特征,因此容易陷入次优解。最近的基于学习的方法使用神经网络来预测姿态&am…...

IDEA安装教程配置java环境(超详细)
引言 IntelliJ IDEA 是一款功能强大的集成开发环境(IDE),广泛用于 Java 开发,但也支持多种编程语言,如 Kotlin、Groovy 和 Scala。本文将为你提供一步一步的指南,帮助你在 Windows 系统上顺利安装 Intelli…...

Excel文档的读取(1)
熟悉使用Excel的同学应该都知道,在单个Excel表格里想要分商品计算总销售额,使用数据透视表也可以非常快速方便的获得结果。但当有非常大量的Excel文件需要处理时,每一个Excel文件单独去做数据透视也会消耗大量的时间。就算使用Power Query这样…...

Linux:体系结构和操作系统管理
目录 一、冯诺依曼体系结构 1.问题1 2.问题2 二、操作系统管理 一、冯诺依曼体系结构 本章将会谈论一下对冯诺依曼计算机体系结构的理解。 在2024年,几乎所有的计算机,都遵守冯诺依曼体系结构。 冯诺依曼体系结构是应用在硬件层面的,而硬…...

c++ install boost lib
同步系统上的软件包列表 sudo apt-update 整个库安装: sudo apt-get install libboost-all-dev 安装部分库: sudo apt-get install libboost-thread-dev sudo apt-get install libboost-filesystem-dev 链接时加上: -lboost_filesystem -lboost_system 例如: g -Wall -o bo…...

文件加密最简单的方法有哪些?十个电脑文件加密方法【超详细】
在当今数字化和信息化的时代,数据已成为企业最重要的资产之一。内部数据外泄不仅可能导致商业秘密的丧失,还可能对企业的声誉和财务健康造成严重影响。为了有效防止内部数据外泄,企业需要实施综合的防泄密解决方案。以下是十大最佳防泄密解决…...

IPv6地址的表示方法
IPv6地址总长度为128比特,通常分为8组,每组为4个十六进制数的形式,每组十六进制数间用冒号分隔。 例如:2409:8745:039a:c700:0000:0000:0162,这是IPv6地址的首选格式。 为了书写方便,IPv6还提供了压缩格式…...
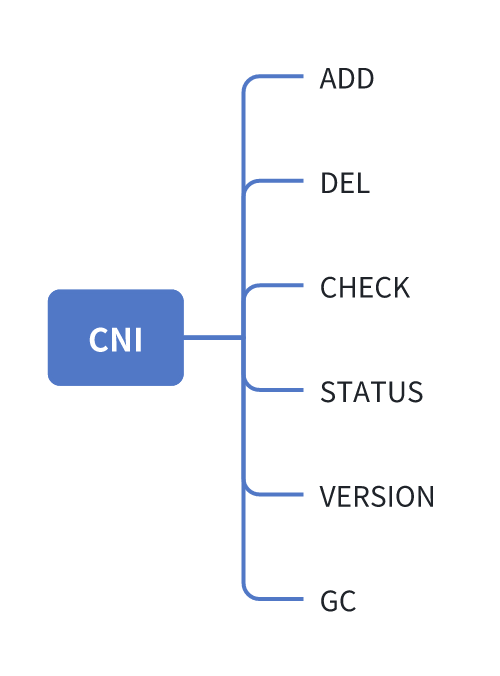
Kubernetes 之 kubelet 与 CRI、CNI 的交互过程
序言 当一个新的 Pod 被提交创建之后,Kubelet、CRI、CNI 这三个组件之间进行了哪些交互? Kubelet -> CRI -> CNI 如上图所示: Kubelet 从 kube-api-server 处监听到有新的 pod 被调度到了自己的节点且需要创建。Kubelet 创建 sandbo…...

【python】OpenCV—Age and Gender Classification
文章目录 1、任务描述2、网络结构2.1 人脸检测2.2 性别分类2.3 年龄分类 3、代码实现4、结果展示5、参考 1、任务描述 性别分类和年龄分类预测 2、网络结构 2.1 人脸检测 输出最高的 200 个 RoI,每个 RoI 7 个值,(xx,xx&#x…...

python安装换源
安装 python 使用演示的是python 3.8.5 安装完成后,如下操作打开命令行:同时按 “WindowsR” > 输入 “cmd” -> 点击确定 python换源 临时换源: #清华源 pip install markdown -i https://pypi.tuna.tsinghua.edu.cn/simple # 阿里…...

JavaScript练手小技巧:利用鼠标滚轮控制图片轮播
近日,在浏览网站的时候,发现了一个有意思的效果:一个图片轮播,通过上下滚动鼠标滚轮控制图片的上下切换。 于是就有了自己做一个的想法,顺带复习下鼠标滚轮事件。 鼠标滚轮事件,参考这篇文章:…...

搭建Eureka高可用集群 - day03
全部代码发出来了 搭建服务提供者 步骤: 1.创建项目,引入依赖 2.添加Eureka相关配置 3.添加EnableEurekaClient注解 4.测试运行 步骤1:创建项目,引入依赖 使用Spring Initializr方式创建一个名称为eureka-provider的Sprin…...

并行程序设计基础——并行I/O(2)
目录 一、显式偏移的并行文件读写 1、阻塞方式 1.1 MPI_FILE_READ_AT 1.2 MPI_FILE_WRITE_AT 1.3 MPI_FILE_READ_AT_ALL 1.4 MPI_FILE_WRITE_AT_ALL 2、非阻塞方式 2.1 MPI_FILE_IREAD_AT 2.2 MPI_FILE_IWRITE_AT 3、两步非阻塞组调用 3.1 MPI_FILE_READ_AT_ALL_BEG…...

Java三种创建多线程的方法
线程是什么: 进程是程序的一次动态执行的过程,线程是进程中执行运算最小单位,一个进程在其执行过程中可以产生多个线程,而线程必须在某个进程内执行。 如果在一个进程中同时运行了多个线程(必须包含一个主线程&#…...

828华为云征文 | 云上私人数据管家,jMalCloud个人网盘在华为云Flexus的Docker化部署实践
华为云服务器Flexus X实例介绍 华为云Flexus云服务器X实例,是由国家科技进步奖获得者、华为公司Fellow、华为云首席架构师顾炯炯牵头研发。它基于擎天QingTian架构、瑶光云脑、盘古大模型等根技术创新,是业界首款应用驱动的柔性算力云服务器,…...

C# 开源教程带你轻松掌握数据结构与算法
目录 前言 项目介绍 项目特点 项目展示 1、内容导图 2、部分目录 3、源码示例 项目地址 最后 前言 在项目开发过程中,理解数据结构和算法如同掌握盖房子的秘诀。算法不仅能帮助我们编写高效、优质的代码,还能解决项目中遇到的各种难题。 给大家…...

深度解析Windows Subsystem for Android:企业级跨平台运行时架构与最佳实践
深度解析Windows Subsystem for Android:企业级跨平台运行时架构与最佳实践 【免费下载链接】WSA Developer-related issues and feature requests for Windows Subsystem for Android 项目地址: https://gitcode.com/gh_mirrors/ws/WSA Windows Subsystem f…...

别再只改IMEI了!深入理解高通基带QCN:从参数结构到软件检测的完整对抗思路
高通基带QCN参数体系解析与多维设备指纹对抗策略 在移动设备安全领域,设备标识参数的修改与检测始终是一场动态博弈。随着安卓系统安全机制的不断升级,简单的IMEI修改早已无法应对现代应用的多维指纹检测体系。理解高通基带QCN参数的组织结构及其在系统中…...

`SaveKeyDataAsync` 重构优化版本
✅ SaveKeyDataAsync 重构优化版本 以下是针对 StationRepository 中 SaveKeyDataAsync 方法的完整重构,包含生产级最佳实践。 1. 重构后的 StationRepository.cs(重点方法) // MaxWell.Repository/StationRepository.cs using Microsoft.Ent…...

用Python实现编译器前端:从Kaleidoscope到LLVM IR的实践指南
1. 项目概述:从“玩具”到“宝藏”的编译器学习之旅如果你对编译原理这门计算机科学的“硬核”课程感到既敬畏又头疼,觉得那些词法分析、语法树、中间代码优化等概念如同天书,那么你很可能已经尝试过一些经典的“龙书”配套项目,比…...

别再手动导数据了!用PostgreSQL FDW把ClickHouse和MongoDB变成你的“超级外挂”数据仓库
异构数据联邦实战:用PostgreSQL FDW构建零延迟数据枢纽 当业务数据散落在多个异构数据库中时,传统ETL方案就像用卡车在不同仓库之间搬运货物——不仅耗时耗力,数据新鲜度也难以保证。想象一下:用户画像在PostgreSQL,行…...

NTN 长距离通信领域亮相
核心蜂窝解决方案亮相并带来Nordic NTN 核心解决方案深度分享。环节将全面解析 nRF9151 模组的核心特性与技术优势,详解卫星星座生态布局及 nRFCloud 平台的应用价值,为参会者勾勒 NTN 技术的整体框架与商业落地前景,为后续内容奠定专业基础。…...

别光看YOLOv5了!从R-CNN到DETR:手把手带你拆解目标检测算法演进史与代码复现
从R-CNN到DETR:目标检测算法演进的技术考古与实战复现 当计算机视觉领域的研究者第一次看到YOLOv5在COCO数据集上达到60FPS的实时检测速度时,很少有人意识到这背后是长达十年的算法范式革命。目标检测作为计算机视觉的基础任务,其发展轨迹完美…...

别再乱设K值了!用sklearn的KFold做交叉验证,这3个参数和5个坑你必须知道
别再乱设K值了!用sklearn的KFold做交叉验证,这3个参数和5个坑你必须知道 交叉验证是机器学习模型评估的黄金标准,而K折交叉验证(KFold)作为其中最常用的方法,看似简单却暗藏玄机。许多数据科学家在Kaggle竞…...
)
【免费下载】 AD7124中文手册(非常完整)
AD7124中文手册(非常完整) 【下载地址】AD7124中文手册非常完整 AD7124-8是一款高性能模拟前端,设计用于在各种苛刻环境中实现精确的数据采集。这款芯片的特点在于其内置的高精度24位Σ-Δ模数转换器(ADC),能够灵活配置以支持8个差…...

【审计领域-监督监管】【信息科学与工程学】【会计领域】第十三篇 云计算业务-财务-会计-审计-税务融合模03
云计算各层服务招投标围标串标审计模型详表(续30项:I-455至I-484) 编号 类型 财务/会计/审计领域 行业类型 产品/服务/其他的财务/会计/审计/税收类型 函数/算法/规则逐步推理思考的数学方程式表达级业务财务-会计-审计融合模型 时序方程式 参数列表及参数的数学特征…...