Elasticsearch 开放 inference API 为 Hugging Face 添加了原生分块支持
作者:来自 Elastic Max Hniebergall

借助 Elasticsearch 开放推理 API,你可以使用 Hugging Face 的推理端点(Inference Endpoints)在 Elasticsearch 之外执行推理。这样你就可以使用 Hugging Face 的可扩展基础架构,包括在 GPU 和 AI 加速器上执行推理的能力。使用 Hugging Face 生成的嵌入的能力是作为 Elasticsearch 8.11 中的第一个开放推理 API 集成引入的,从那时起,我们一直在努力工作,并使用更强大的功能对其进行了更新,让您可以事半功倍地获得更好的结果。
通过集成 semantic_text 字段,文档可以原生分块并与嵌入一起存储。默认情况下,Elasticsearch 向量数据库中的所有存储嵌入都使用标量量化进行压缩。使用检索器检索这些嵌入,在使用托管在 Hugging Face 上的多个模型(或任何其他可通过开放推理 API 访问的服务)时可以实现搜索的组合性,从而可以在单个文档中使用多种类型的嵌入。所有这些功能加起来可以节省开发人员的时间,因为他们无需编写自定义逻辑,并使他们能够更快地构建有趣的 AI 应用程序!
消除歧义
这篇博文以两种不同的方式使用了 “inference endpoint - 推理端点” 一词:
- Hugging Face 的推理端点服务(Inference Endpoints service),以及
- Elasticsearch 的开放推理 API 推理端点对象(inference endpoint objects)。
Hugging Face 的推理端点服务提供运行 Hugging Face Transformers 模型的计算实例,而 Elasticsearch 推理端点对象存储 Elasticsearch 访问和使用 Hugging Face 推理端点服务的配置。
什么是 Elasticsearch 开放推理 API?
开放推理 API(open inference API)是你在 Elasticsearch 中执行推理的门户。它允许你在 Elasticsearch 之外使用机器学习模型和服务,而无需编写任何混乱的粘合代码。你需要做的就是提供 API 密钥并创建推理端点对象(create an Inference Endpoint object)。使用 Elasticsearch 开放推理 API,你可以使用 completion 任务对 LLM 执行推理,使用 text_embedding 或 sparse_embedding 任务生成密集或稀疏文本嵌入,或使用 rerank 任务对文档进行排名。
什么是 Hugging Face 推理端点服务?
Hugging Face 的推理端点服务(Inference Endpoints service )允许你在云中部署和运行 Hugging Face Transformers 模型。查看 Hugging Face 的指南以创建你自己的端点 https://huggingface.co/docs/inference-endpoints/guides/create_endpoint。
- 确保将任务设置为与你正在部署的模型和你将在 Elasticsearch 中映射的字段类型相匹配。
- 确保复制/记下端点 URL。
- 创建用户访问令牌(也称为 API 密钥)以验证你对端点 https://huggingface.co/settings/tokens 的请求。为了获得更好的安全性,请选择细粒度访问令牌以仅向令牌提供所需的范围。
- 确保安全地复制/记下 API 密钥(访问令牌)。
如何将 Hugging Face 推理端点与 Elasticsearch 开放推理 API 结合使用
要将 Hugging Face 推理端点服务与开放推理 API 结合使用,您需要遵循 3 个步骤:
- 使用您想要使用的模型在 Hugging Face 中创建推理端点服务
- 使用开放推理 API 并在 Elasticsearch 中创建推理端点对象,并提供您的 hugging face API 密钥
- 使用推理端点对象执行推理,或配置索引以使用语义文本自动嵌入你的文档。注意:你可以使用 cURL、任何其他 HTTP 客户端或我们的其他客户端之一执行这些相同的步骤。
步骤 1:在 Hugging Face 中创建推理端点服务
有关如何在 Hugging Face 中创建推理端点服务的更多信息,请参阅 https://ui.endpoints.huggingface.co。
步骤 2:在 Elasticsearch 中创建推理端点对象
client.inference.put(task_type="text_embedding",inference_id="my_hf_endpoint",body={"service": "hugging_face","service_settings": {"api_key": <HF_API_KEY>,"url": "<URL_TO_HUGGING_FACE_ENDPOINT>"},}
)
注意:task_type 设置为 text_embdding(密集向量嵌入),因为我们部署到 Hugging Face 推理端点服务的模型是密集文本嵌入模型(multilingual-e5-small)。在 Hugging Face 中创建端点时,我们还必须选择 sentence-embeddings 配置。
步骤 3:使用推理端点对象执行推理以访问 Hugging Face 推理端点服务
dense_embedding = client.inference.inference(inference_id='my_hf_endpoint',input="this is the raw text of my document!")
步骤 4:将数据集导入到包含语义文本的索引中
通过使用 semantic_text 字段,我们可以提高导入速度,同时利用原生分块。为此,我们需要创建一个索引,其中包含一个文本字段(我们将在其中插入原始文档文本)以及一个将文本复制到的 semantic_text 字段。当我们通过将数据插入到 text_field 中来将数据导入此索引时,数据将自动复制到语义文本字段,并且文档将被原生分块,从而使我们能够轻松执行语义搜索。
client.indices.create(index="hf-semantic-text-index",mappings={"properties": {"infer_field": {"type": "semantic_text","inference_id": "my_hf_endpoint"},"text_field": {"type": "text","copy_to": "infer_field"}}}
)
documents = load_my_dataset()
docs = []
for doc in documents:if len(docs) >= 100:helpers.bulk(client, docs)docs = []else:docs.append({"_index": "hf-semantic-text-index","_source": {"text_field": doc['text']},})
步骤 5:使用 semantic text 执行语义搜索
query = "Is it really this easy to perform semantic search?"
semantic_search_results = client.search(index="hf-semantic-text-index",query={"semantic": {"field": "infer_field", "query": query}},
)
第 6 步:使用 Cohere 重新排名以获得更好的结果
使用 Elasticsearch 作为向量数据库的一个优势是我们不断扩展对创新第三方功能的支持。例如,通过将使用 Hugging Face 模型创建的嵌入的语义搜索与 Cohere 的重新排名功能相结合,可以提高你的热门点击率。要使用 Cohere 重新排名,你需要一个 Cohere API 密钥。
client.inference.put(task_type="rerank",inference_id="my_cohere_rerank_endpoint",body={"service": "cohere","service_settings": {
"api_key": <COHERE_API_KEY>,"model_id": "rerank-english-v3.0"},"task_settings": {"top_n": 100,"return_documents": True}}
)
reranked_search_results = client.search(index="hf-semantic-text-index",retriever= {"text_similarity_reranker": {"retriever": {"standard": {"query": {"semantic": {"field": "infer_field","query": query}}}},"field": "text_field","inference_id": "my_cohere_rerank_endpoint","inference_text": query,"rank_window_size": 100,}}
)
立即使用 Elastic 的 Hugging Face 推理端点服务!
试用此笔记本开始使用我们的 Hugging Face 推理端点集成:使用 Hugging Face 和 Elasticsearch 通过 GPU 加速推理索引数百万个文档。
准备好亲自尝试了吗?开始免费试用。
Elasticsearch 集成了 LangChain、Cohere 等工具。加入我们的高级语义搜索网络研讨会,构建您的下一个 GenAI 应用程序!
原文:Elasticsearch open inference API adds native chunking support for Hugging Face — Search Labs
相关文章:
Elasticsearch 开放 inference API 为 Hugging Face 添加了原生分块支持
作者:来自 Elastic Max Hniebergall 借助 Elasticsearch 开放推理 API,你可以使用 Hugging Face 的推理端点(Inference Endpoints)在 Elasticsearch 之外执行推理。这样你就可以使用 Hugging Face 的可扩展基础架构,包…...
Jenkins部署若依项目
一、配置环境 机器 jenkins机器 用途:自动化部署前端后端,前后端自动化构建需要配置发送SSH的秘钥和公钥,同时jenkins要有nodejs工具来进行前端打包,maven工具进行后端的打包。 gitlab机器 用途:远程代码仓库拉取和…...

ELK笔记
要搞成这样就需要钱来买服务器 开发人员一般不会给服务器权限,不能到服务器上直接看日志,所以通过ELK看日志。不让开发登录服务器。即使你查出来是开发的问题,费时间,而且影响了业务了,就是运维的问题 开发也不能登录…...

计算机网络 --- 计算机网络的分类
一、计算机网络分类 1.1 按分布范围分类 举例:广域网(WAN)、局域网(LAN) 举例:个域网(PAN) 1.2 按传输技术分类 广播式网络――当一台计算机发送数据分组时,广播范围…...

三维动画|创意无限,让品牌传播更精彩!
随着三维动画技术的不断成熟,三维动画宣传片能够很好地宣传品牌、推广产品,因而慢慢地受到不少企业的青睐,成为品牌最常用的一种宣传方式。 三维动画宣传片作为艺术感极高的宣传视频有强烈的节奏感,而且具有风趣、易懂等特点&…...

欧零导航系统正式版,功能强大,可直接运营
欧零导航系统正式版,带广告位/导航分类/可直接运营 本系统采用PHPMySQL技术开发 拥有独立的安装和后台系统 后台采用BootstripMDUI框架 前台使用响应式界面,自适应各种屏幕 代码免费下载:百度网盘...
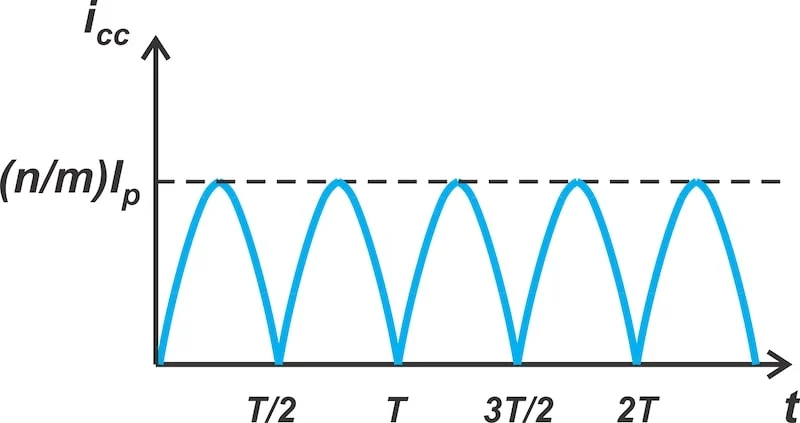
了解变压器耦合电压开关 D类放大器
在本文中,我们将讨论另一种 D 类配置:变压器耦合电压切换 (TCVS) 放大器。TCVS 放大器的原理图如图 1 所示。 变压器耦合电压开关 D 类放大器的示意图。 图 1.变压器耦合电压开关 D 类放大器。 在本文中,我们将探索该放大器的工作原理&…...

openssh移植:精致的脚本版
前置文章: busybox移植:全能脚本版-CSDN博客 zlib交叉编译-CSDN博客 openssl移植:精致的脚本版-CSDN博客 源码下载 官网:http://www.openssh.com/ 下载了一个很新的版本 ftp://mirrors.sonic.net/pub/OpenBSD/OpenSSH/portable/openss…...

3C电子胶黏剂在手机制造方面有哪些关键的应用
3C电子胶黏剂在手机制造方面有哪些关键的应用 3C电子胶黏剂在手机制造中扮演着至关重要的角色,其应用广泛且细致,覆盖了手机内部组件的多个层面,确保了设备的可靠性和性能。以下是电子胶在手机制造中的关键应用: 手机主板用胶&…...
)
Oracle数据库中的动态SQL(Dynamic SQL)
Oracle数据库中的动态SQL是一种在运行时构建和执行SQL语句的技术。与传统的静态SQL(在编写程序时SQL语句就已经确定)不同,动态SQL允许开发者在程序执行过程中根据不同的条件或用户输入来构建SQL语句。这使得动态SQL在处理复杂查询、存储过程中…...

Python判断两张图片的相似度
在Python中,判断两张以numpy的ndarray格式存储的图片的相似度,通常可以通过多种方法来实现,包括但不限于直方图比较、像素差比较、结构相似性指数(SSIM)、特征匹配等。以下是一些常见方法的简要介绍和示例代码。 1. 像…...

MySQL高级功能-窗口函数
背景 最近遇到需求,需要对数据进行分组排序并获取每组数据的前三名。 一般涉及到分组,第一时间就是想到使用group by对数据进行分组,但这样分组,到最后其实只能获取到每组数据中的一条记录。 在需要获取每组里面的多条记录的时候…...

9.12总结
今天学了树状dp和tarjan 树状dp 树状dp,是一种在树形数据结构上应用的动态规划算法。动态规划(DP)通常用于解决最优化问题,通过将问题分解为相对简单的子问题来求解。在树形结构中,由于树具有递归和子结构的特性&…...

小众创新组合!LightGBM+BO-Transformer-LSTM多变量回归交通流量预测(Matlab)
小众创新组合!LightGBMBO-Transformer-LSTM多变量回归交通流量预测(Matlab) 目录 小众创新组合!LightGBMBO-Transformer-LSTM多变量回归交通流量预测(Matlab)效果一览基本介绍程序设计参考资料 效果一览 基本介绍 1.Matlab实现LightGBMBO-Transformer-L…...

《CSS新世界》书评
《CSS新世界》是由张鑫旭所著,人民邮电出版社在2021年8月10日出版的一本专门讲解CSS3及其之后版本新特性的进阶读物。这本书是“CSS世界三部曲”中的最后一部,全书近600页,内容丰富,涵盖了CSS的全局知识、已有属性的增强、新布局方…...

python 实现euler modified变形欧拉法算法
euler modified变形欧拉法算法介绍 Euler Modified(改进)变形欧拉法算法,也被称为欧拉修改法或修正欧拉法(Euler Modified Method),是一种用于数值求解微分方程的改进方法。这种方法在传统欧拉法的基础上进…...

strcpy 函数及其缺点
目录 一、概念 二、strcpy 函数有什么缺点 1. 缺乏边界检查 2. 容易引发未定义行为 3. 不适合动态和未知长度的字符串操作 4. 替代方案的可用性 5. 效率问题 一、概念 strcpy 是 C 语言中的一个标准库函数,用于将源字符串复制到目标字符串中。它定义在 <…...

区块链-P2P(八)
前言 P2P网络(Peer-to-Peer Network)是一种点对点的网络结构,它没有中心化的服务器或者管理者,所有节点都是平等的。在P2P网络中,每个节点都可以既是客户端也是服务端,这种网络结构的优点是去中心化、可扩展…...
数据库管理的利器Navicat —— 全面测评与热门产品推荐
在数据库管理领域,Navicat无疑是一款深受欢迎的软件。作为一个强大的数据库管理和开发工具,它支持多种数据库类型,包括MySQL、MariaDB、MongoDB、SQL Server、Oracle、PostgreSQL等。本文将全面测评Navicat的核心功能,同时推荐几款…...

如何让Google收录我的网站?
其实仅仅只是收录,只要在GSC提交网址,等个两三天,一般就能收录,但收录是否会掉,这篇内容收录了是否有展现,排名,就是另外一个课题了,如果不收录,除了说明你的网站有问题&…...

如何高效构建视频数据集:video2frame终极实战指南
如何高效构建视频数据集:video2frame终极实战指南 【免费下载链接】video2frame Yet another easy-to-use tool to extract frames from videos, for deep learning and computer vision. 项目地址: https://gitcode.com/gh_mirrors/vi/video2frame 在计算机…...

Python try...except ImportError 语句详解
在Python编程中,ImportError 是与模块导入相关的核心异常。优雅地处理它,是编写健壮、可维护和跨平台代码的关键。try...except ImportError 结构正是实现这一目标的标准工具。本文将为你抽丝剥茧,从基础概念到高级实践,全面解析这…...

【避坑指南】VSCode+EIDE+Keil混合开发环境:从零搭建到项目无缝迁移
1. 为什么需要VSCodeEIDEKeil混合开发环境? 作为一名嵌入式开发者,我深知Keil这个老牌IDE在开发效率上的痛点:代码补全弱、界面老旧、多窗口管理混乱。但直接完全迁移到VSCode又面临工程兼容性问题,特别是对传统AC5编译器的支持。…...

Redis增强工具包:封装分布式锁、缓存模板与监控的最佳实践
1. 项目概述:一个Redis开发者的“瑞士军刀”在分布式系统和高并发场景下,Redis几乎成了标配。但用久了你会发现,官方客户端虽然稳定,但在日常开发、调试、运维中,总有些“不够顺手”的地方。比如,想批量按模…...

如何3分钟快速上手企业级后台管理系统:终极配置秘籍
如何3分钟快速上手企业级后台管理系统:终极配置秘籍 【免费下载链接】ant-design-vue3-admin 一个基于 Vite2 Vue3 Typescript tsx Ant Design Vue 的后台管理系统模板,支持响应式布局,在 PC、平板和手机上均可使用 项目地址: https://…...

免费开源鼠标连点器终极指南:5分钟掌握高效自动化技巧
免费开源鼠标连点器终极指南:5分钟掌握高效自动化技巧 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软件界面美观 ,…...

Flutter桌面端窗口控制:从隐藏标题栏到自定义全屏交互
1. 为什么需要自定义窗口控制? 当你用Flutter开发Windows桌面应用时,系统默认的标题栏和窗口样式往往显得格格不入。想象一下,你精心设计了一套深色主题的UI,结果顶部突然冒出一条灰白色的标准标题栏——就像给西装革履的绅士戴了…...

量化部署终极指南:从GPTQ到AWQ,精度损失与显存节省的平衡艺术
系列导读 你现在看到的是《本地大模型私有化部署与优化:从入门到生产级实战》的第 7/10 篇,当前这篇会重点解决:帮你搞懂每种量化方法的优劣,用最少显存跑最大模型,精度损失可控。 上一篇回顾:第 6 篇《RAG知识库实战:LangChain+Chroma搭建本地问答系统,解决幻觉与知…...

AI异步任务编排引擎:从原理到实战,构建可靠工作流系统
1. 项目概述:AI驱动的异步任务编排引擎在当今的软件开发领域,尤其是涉及数据处理、机器学习模型训练、自动化工作流等场景时,我们常常会面临一个核心挑战:如何高效、可靠地编排和管理一系列耗时且可能相互依赖的异步任务。传统的解…...

英文专业论文,可以用维普AIGC检测查AI率吗?
维普查重系统目前是国内比较权威的查重系统,目前国内很多高校是和维普系统合作的。 维普系统也是很多大学生都知晓的查重系统,并且上线了维普AIGC检测功能,可以查论文的AI率。 但是英文专业的毕业论文又和其他专业的不一样,那么…...