文生视频算法
文生视频
- Sora
- 解决问题:
- 解决思路:
- CogVideoX
- 解决问题:
- 解决思路:
- Stable Video Diffusion(SVD)
- 解决问题:
- 解决思路:
主流AI视频技术框架:

Sora
Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models
参考文章
解决问题:
模拟物理现实世界,生成逼真视频
解决思路:
Sora模型的核心架构图示

Sora主要包括三个部分:
3D VAE模型:3D VAE Encoder能在时间和空间维度上将输入的原始视频映射到Latent空间中。同时3D VAE Decoder能将扩散模型生成的视频Latent特征进行重建,获得像素级视频内容。
基于DiT的扩散模型架构:使用类似于ViT(视觉转换器)的处理方式将视频的Latent特征进行Patch化,并进行扩散过程输出去噪后的视频Latent特征。
一个类似CLIP模型架构的条件接收机制:接收经过大型语言模型(LLM)增强的用户输入Prompt和视觉信息的Prompt,用以引导扩散模型生成具有特定风格或者主题的视频内容。
3D VAE架构:

其中先使用一个Visual Encoder模型将视频数据(空间和时间维度)压缩编码到Latent特征空间,获得一个3D visual patch array,接着将整个Latent特征分解成spacetime patches,最后再排列组合成为一个visual patches向量。
CogVideoX
CogVideoX
参考文章
解决问题:
模拟物理现实世界,生成逼真视频
解决思路:
CogVideoX-2B模型的完整架构:

CogVideoX主要包括三个部分:
3D Causal VAE模型: 3D Causal VAE Encoder能在时间和空间维度上将输入的原始视频映射到Latent空间中。同时3D Causal VAE Decoder能将扩散模型生成的视频Latent特征进行重建,获得像素级视频内容。
DiT Expert模型: 将视频信息的Latent特征和文本信息的Embeddings特征进行Concat后,再Patch化,并进行扩散过程输出去噪后的视频Latent特征。
Text Encoder模型: Text Encoder模型将输入的文本Prompt编码成Text Embeddings,作为条件注入DiT Expert模型中。CogVideoX中选用T5-XXL作为Text Encoder,Text Encoder具备较强的文本信息提取能力。
3D VAE架构


主要包括一个Encoder(编码器)、一个Decoder(解码器)以及一个Latent Space Regularizer(潜在空间正则器):
编码器: 用于将输入视频数据转换为Latent Feature。这一过程中,编码器会通过四个下采样阶段逐步减少视频数据的空间和时间分辨率。
解码器: 将视频数据的Latent Feature转换成原始的像素级视频。解码器也包含四个对称的上采样阶段,用于恢复视频数据的空间和时间分辨率。
潜在空间正则化器: 通过KL散度来约束高斯Latent空间,对编码器生成的Latent Feature进行正则化。这对于AI视频大模型的生成效果和稳定性至关重要。
3D Expert Transformer的完整结构图

Text Encoder部分(T5-xxl):



GELU、ReLU、Sigmoid三大激活函数之间的数值对比:
从上图可以看出:
- ReLU激活函数在输入为正数时,输出与输入相同;在输入为负数时,输出为0。它非常简单但会完全忽略负值的输入
- Sigmoid激活函数输出在 0 到 1 之间平滑过渡,适合在某些分类任务中使用,但可能会导致梯度消失问题。
- GELU激活函数比ReLU 更平滑,并且在负值附近不会直接剪切到 0。它让负值小幅保留,避免了完全忽略负输入,同时保留了 ReLU 在正值区间的主要优点。
总的来说,GELU是一种更平滑的激活函数,能更好地保留输入的细微信息,尤其是在处理负值时。通过结合多种非线性运算(如 tanh 和多项式),GELU 提供了比 ReLU 更平滑和复杂的输出,有助于AI模型在训练过程中更好地捕捉数据中的复杂特征与模式。
Stable Video Diffusion(SVD)
SVD
参考文章
解决问题:
模拟物理现实世界,生成逼真视频
解决思路:
目前开源的Stable Video Diffusion模型是两个图生视频的版本,都是基于Stable Diffusion V2.1进行训练的,一个生成14帧(SVD),一个生成25帧(SVD-XT),从人工评测结果看,效果超过runaway的GEN2和Pika Labs的免费模型。
超大训练集
StabilityAI使用了一个包含5.8亿个视频剪辑的巨大数据集,来训练SVD模型。为了筛选高质量数据,我们首先检测每个视频中的不同镜头和转场,并且评估每个镜头中的运动信息,然后为每个镜头自动生成描述文字和每个镜头的美学效果等。
SVD的数据筛选具体方法如下:
级联切换检测: 采用级联的切换检测方法识别视频中的场景转场。
运动信息提取: 基于稠密光流估计每个视频片段的运动信息。
文本描述生成: 为每个视频片段自动生成三种形式的文字描述。
质量评估: 使用CLIP等方法评估每个片段的视觉质量、文本匹配度等。
过滤去噪: 根据上述评估指标过滤掉质量较差的视频片段。
经过层层筛选,最后保留了一个约1.5亿视频片段的超高质量数据集,为后续的SVD模型训练奠定重要基础。
多阶段训练
SVD模型在模型训练方面也与传统方法不同,其采用了一个三层训练架构。
第一阶段 是进行图像预训练,初始化一个图像生成模型。第二阶段 是在已经构建的大规模视频数据集上进行视频预训练,学习运动表征。第三阶段是在一个小规模的高质量视频数据集上进行微调。
这种分阶段的训练策略可以让模型更好地生成高保真视频。
同时SVD在模型框架上也进行了大量创新。例如,设计了专门的时间卷积和注意力结构,明显提高了视频时序信息的捕捉和学习能力。
多任务微调
在训练好后,我们需要对SVD模型进一步微调,可用于多模式的视频生成任务。
文本描述生成视频: 文本提示可以直接作为条件生成视频。
图像生成视频: 可以使用一张图像作为条件,生成这张图像的后续运动镜头。
多视角渲染: 可以生成同一个物体的多个前后左右观察角度的视频镜头,这样可以生成3D 效果视频。
插入视频帧: 可以将两张图像作为条件,生成插入在它们中间的额外镜头,实现视频帧率的提升。
相关文章:
文生视频算法
文生视频 Sora解决问题:解决思路: CogVideoX解决问题:解决思路: Stable Video Diffusion(SVD)解决问题:解决思路: 主流AI视频技术框架: Sora Sora: A Review on Backg…...

LoRA: Low-Rank Adaptation Abstract
LoRA: Low-Rank Adaptation Abstract LoRA 论文的摘要介绍了一种用于减少大规模预训练模型微调过程中可训练参数数量和内存需求的方法,例如拥有1750亿参数的GPT-3。LoRA 通过冻结模型权重并引入可训练的低秩分解矩阵,减少了10,000倍的可训练参数…...

正点原子阿尔法ARM开发板-IMX6ULL(二)——介绍情况以及汇编
文章目录 一、裸机开发(21个)二、嵌入式Linux驱动例程三、汇编3.1 处理器内部数据传输指令3.2 存储器访问指令3.3 压栈和出栈指令3.4 跳转指令3.5 算术运算指令3.6 逻辑运算指令 一、裸机开发(21个) 二、嵌入式Linux驱动例程 三、…...
(一))
Unreal Engine——AI生成高精度的虚拟人物和环境(虚拟世界构建、电影场景生成)(一)
一、Unreal Engine 介绍 Unreal Engine(虚幻引擎)是由Epic Games开发的强大3D游戏开发引擎,自1998年首次发布以来,已经历了多个版本的迭代。虚幻引擎主要用于制作高品质的3D游戏,但也广泛用于电影、建筑、仿真等其他领…...

Emlog程序屏蔽用户IP拉黑名单插件
插件介绍 在很多时候我们需要得到用户的真实IP地址,例如,日志记录,地理定位,将用户信息,网站数据分析等,其实获取IP地址很简单,感兴趣的可以参考一下。 今天给大家带来舍力写的emlog插件:屏蔽…...
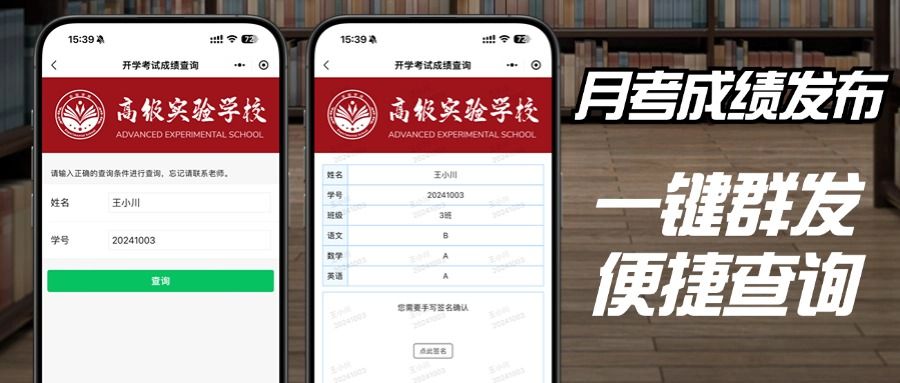
发送成绩的app或小程序推荐
老师们,新学期的第一次月考马上开始,是不是还在为如何高效、便捷地发布成绩而头疼呢?别担心,都2024年了,我们有更智能的方式来解决这个问题! 给大家安利一个超级实用的工具——易查分小程序。这个小程序简…...

51单片机-AT24C02(IIC总线介绍及其时序编写步骤)-第一节(下一节实战)
IIC开始通信(6大步) 我以前的文章也有对基本常用的通信协议讲解,如SPI UART IIC RS232 RS485 CAN的讲解,可前往主页查询,(2024.9.12,晚上20:53,将AT24C02存储芯片,掉电不…...

<<编码>> 第 11 章 逻辑门电路--或非门, 与非门, 缓冲器 示例电路
继电器或非门 info::操作说明 鼠标单击开关切换开合状态 闭合任意一个开关可使电路断开 primary::在线交互操作链接 https://cc.xiaogd.net/?startCircuitLinkhttps://book.xiaogd.net/code-hlchs-examples/assets/circuit/code-hlchs-ch11-19-nor-gate-by-relay.txt 或非门 i…...

股票api接口程序化报备,程序化交易监管对个人量化交易者有何影响
炒股自动化:申请官方API接口,散户也可以 python炒股自动化(0),申请券商API接口 python炒股自动化(1),量化交易接口区别 Python炒股自动化(2):获取…...

如何自己搭建一个网站?
今天的文章总结适合0基础,网站搭建的技巧和流程,哪怕你是小白,不会编程,也可以制作非常漂亮且实用的企业网站,如果想做个人博客更是不在话下。希望我的经验能帮助更多没有过多的经费、没有建站基础的朋友。用户跟着我的…...

虚拟化数据恢复—断电导致虚拟机目录项被破坏的数据恢复案例
虚拟化数据恢复环境: 某品牌服务器(部署VMware EXSI虚拟机)同品牌存储(存放虚拟机文件)。 虚拟化故障: 意外断电导致服务器上某台虚拟机无法正常启动。查看虚拟机配置文件发现这台故障虚拟机除了磁盘文件以…...

[机器学习]聚类算法
1 聚类算法简介 # 导包 from sklearn.datasets import make_blobs import matplotlib.pyplot as plt from sklearn.cluster import KMeans from sklearn.metrics import calinski_harabasz_score # 构建数据 x,ymake_blobs(n_samples1000,n_features2,centers[[-1,-1],[0,0],[1…...

JVM面试真题总结(七)
文章收录在网站:http://hardyfish.top/ 文章收录在网站:http://hardyfish.top/ 文章收录在网站:http://hardyfish.top/ 文章收录在网站:http://hardyfish.top/ 解释GC的引用计数算法及其局限性 引用计数算法是一种非常直观、简…...

深入理解CASAtomic原子操作类详解
1.CAS介绍 什么是 CAS CAS(Compare And Swap,比较与交换),是非阻塞同步的实现原理,它是CPU硬件层面的一种指令,从CPU层面能保证"比较与交换"两个操作的原子性。CAS指令操作包括三个参数&#x…...

C51单片机-单按键输入识别,键盘消抖
【实验目的】 独立按键的识别方法、键盘消抖等。 【实验现象】 每按一次独立键盘的S2键,与P1口相连的八个发光二极管中点亮的一个往下移动一位。 【实验说明】 关于按键去抖动的解释,我们在手动按键的时候,由于机械抖动或是其它一些非人为的因…...

基于CNN卷积神经网络迁移学习的图像识别实现
基于CNN卷积神经网络迁移学习的图像识别实现 基于CNN卷积神经网络迁移学习的图像识别实现写在前面一,原理介绍迁移学习的基本方法1.样本迁移(Instance based TL)2.特征迁移(Feature based TL)3.模型迁移(Pa…...

【iOS】push和present的区别
【iOS】push和present的区别 文章目录 【iOS】push和present的区别前言pushpop presentdismiss简单小demo来展示dismiss和presentdismiss多级 push和present的区别区别相同点 前言 在iOS开发中,我们经常性的会用到界面的一个切换的问题,这里我们需要理清…...

在Linux服务器上添加用户并设置自动登录
需要在Linux服务器上添加一个新用户,可以使用以下命令 # 这个命令会创建一个新的用户账户,默认情况下不会设置密码,不会在 /home 目录下为新用户创建home目录: # sudo useradd 用户名 # # 如果希望同时为新用户创建家目录&#…...

网站被爬,数据泄露,如何应对不断强化的安全危机?
近年来,众多传统零售商和互联网企业借助大数据、人工智能等先进技术手段,通过场景化设计、优化客户体验、融合线上线下渠道,推动了网络电商行业的消费方式变革,成为电商领域新的增长动力。 但值得注意的是,网络电商带来…...

为什么HTTPS会引入SSL/TLS协议
这时我面试遇到过的问题,整理了一下,希望对大家有帮助! 祝大家秋招顺利! 首先 SSL/TLS 协议通过使用数字证书来实现服务器身份认证, 当用户访问一个 HTTPS 网站时,浏览器会验证服务器的数字证书, 1.首先他对验证整证书是否在有效期 2.其次他会看证书中的服务器域名…...

突破存储限制:群晖DSM7下Synology Photos自定义文件夹挂载实战
1. 为什么需要自定义文件夹挂载 很多群晖用户升级到DSM7后都会遇到一个头疼的问题:Synology Photos默认把所有个人照片都存放在/home/Photos目录下,而这个目录实际上位于/homes共享文件夹中。随着照片数量不断增加,/homes所在存储空间很快就会…...

为开源项目OpenClaw配置Taotoken作为后端模型供应商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为开源项目OpenClaw配置Taotoken作为后端模型供应商 OpenClaw是一个功能强大的开源智能体(Agent)框架&…...

Excel MCP Server终极指南:3步实现无界面Excel自动化处理
Excel MCP Server终极指南:3步实现无界面Excel自动化处理 【免费下载链接】excel-mcp-server A Model Context Protocol server for Excel file manipulation 项目地址: https://gitcode.com/gh_mirrors/ex/excel-mcp-server 你是否厌倦了手动操作Excel的繁琐…...

迪拜塔幕墙设计
迪拜塔幕墙设计 【作 者】:罗永增 【关键词】:迪拜塔,幕墙,设计,系统。 前言:...

地下态势智能研判,拔高硐室深部安全透明管控等级技术白皮书
地下态势智能研判,拔高硐室深部安全透明管控等级技术白皮书 副标题:全要素三维动态重建井下场景,融合井下无感坐标解算、跨断面跨镜轨迹串联、身体指纹人员轨迹存档,井下风险前置感知、动态全程透明追溯 前言 矿山井下深部硐室与纵…...

Windows Terminal 预览版:从安装到深度配置,打造现代化命令行工作流
1. 项目概述:为什么我们需要一个现代化的Windows终端?如果你和我一样,在Windows上敲了十几年命令行,从古老的cmd.exe到后来的PowerShell,一个绕不开的痛点就是:这终端工具,用起来总感觉差点意思…...

ESP-SR深度解析:嵌入式语音识别系统的架构设计与性能优化实战指南
ESP-SR深度解析:嵌入式语音识别系统的架构设计与性能优化实战指南 【免费下载链接】esp-sr Speech recognition 项目地址: https://gitcode.com/gh_mirrors/es/esp-sr 在物联网设备智能化浪潮中,语音交互已成为人机交互的重要入口。ESP-SR作为乐鑫…...

基于CircuitPython的巨型机械键盘:从嵌入式开发到定制输入设备实践
1. 项目概述:当机械键盘遇上“巨无霸”如果你和我一样,对机械键盘那清脆的段落感和扎实的敲击感着迷,同时又是个喜欢动手折腾的硬件爱好者,那么这个项目绝对能让你眼前一亮。我们这次要做的,不是常规的60%或87键键盘&a…...
)
不止于统计:用ArcGIS Model Builder自动化你的土地利用转移矩阵(附模型下载与修改教程)
从手动到智能:ArcGIS Model Builder在土地利用分析中的高阶自动化实践 当规划师面对十年间的土地利用变化数据时,传统的手工操作流程往往成为效率瓶颈。每增加一个研究时段,就需要重复执行数据融合、空间相交、表格导出和矩阵制作等标准化操作…...

工业智能化落地实践:从边缘AI到预测性维护的ST方案整合
1. 项目概述:一场工业智能化的深度对话最近刚参加完ST(意法半导体)的工业峰会回来,感触颇深。这场活动与其说是一场展会,不如说是一场关于“工业智能化如何落地”的深度行业对话。作为一家长期深耕工业通讯、物联网与嵌…...