大模型从失败中学习 —— 微调大模型以提升Agent性能
人工智能咨询培训老师叶梓 转载标明出处
以往的研究在微调LLMs作为Agent时,通常只使用成功的交互轨迹,而丢弃了未完成任务的轨迹。这不仅造成了数据和资源的浪费,也可能限制了微调过程中可能的优化路径。论文《Learning From Failure: Integrating Negative Examples when Fine-tuning Large Language Models as Agents》提出了负面感知训练(Negative-Aware Training, NAT)方法,通过适当的数据清洗和微调策略,使大模型能够从失败中学习,旨在提高模型在数学推理、多跳问答和策略性问答任务中的性能。
方法

图1为先前的方法和作者的NAT范式。在数据收集阶段,收集了LLMs与环境(工具)之间的交互。在数据处理阶段,先前的方法简单地过滤掉负面样本,而NAT通过在任务查询中添加提示来重新格式化轨迹,根据它们是正面还是负面。图1(c)给出了重格式化的正面和负面轨迹的示例。这里省略了系统提示,以简化说明。
如图1所示,Agent框架中任务解决过程被详细划分。首先,LLM被提供了一个系统提示,概述了(a)要解决的具体任务(例如,“解决一个数学问题”),(b)任务执行允许使用的工具,以及(c)预期的动作空间和输出格式(例如,finish[N]表示N是最终答案)。其次,引入一个查询实例。以ReAct格式提示模型回答查询,包括推理文本(称为“thoughts”)和“actions”。最后,在互动阶段,系统使用预定义的工具执行LLM生成的动作,将结果观察返回给LLM,并提示后续动作,直到生成任务的完成动作,或交互轮次超过预定义阈值。
对于数学任务,作者设计了一个由SymPy实现的计算器,它接受数学表达式作为输入并输出结果。对于两个问答任务,作者设计了一个搜索工具,使用Serper 2 API。它接受搜索查询作为输入并返回谷歌搜索结果。他们进一步使用MPNet和DPR对搜索结果进行重新排名。
负面感知训练范式的流程包括数据收集、数据清洗、负面感知重格式化和微调四个阶段。其中负面感知重格式化是范式的核心部分,使Agent调整得更好。
-
数据收集:对于每个任务,获得初始问题和相应的真实答案作为种子数据。然后使用GPT-3.5生成三次轨迹,每次使用不同的温度(0.2、0.5和0.7)。这能够收集多样化的正面和负面样本。通过比较预测答案和真实答案,可以将每个轨迹标记为正面或负面。
-
负面感知重格式化:在Agent调整过程中区分正面样本和负面样本有助于教模型辨别成功和不成功的结果。附加一个字符串后缀,告诉模型训练样本是正面还是负面。对于正面样本,附加“Please generate a solution that correctly answers the question.” 对于负面样本,附加“Please generate a solution that incorrectly answers the question。”
-
微调和推理:使用重格式化后的轨迹对LLMs进行微调。损失只计算LLM生成的文本部分,这与微调聊天模型类似。在推理过程中,只使用正面样本的提示来提示微调后的Agent。

表格1展示了作者的方法与其他论文方法的比较。通过这些结果,可以看出NAT方法在不同任务上相较于其他方法有显著的性能提升。
想要掌握如何将大模型的力量发挥到极致吗?叶老师带您深入了解 Llama Factory —— 一款革命性的大模型微调工具。9月22日晚,实战专家1小时讲解让您轻松上手,学习如何使用 Llama Factory 微调模型。
加下方微信或评论留言,即可参加线上直播分享,叶老师亲自指导,互动沟通,全面掌握Llama Factory。关注享粉丝福利,限时免费录播讲解。
LLaMA Factory 支持多种预训练模型和微调算法。它提供灵活的运算精度和优化算法选择,以及丰富的实验监控工具。开源特性和社区支持使其易于使用,适合各类用户快速提升模型性能。
实验
作者在数学推理、多跳问答和策略性问答任务上进行了实验。对于数学任务,他们使用GSM8k作为种子数据,并在GSM8k、ASDiv、SVAMP和MultiArith上测试性能。对于问答任务,他们在HotpotQA和StrategyQA上分别收集轨迹并测试性能。
主要将NAT与两个基线进行比较。"Vanilla"设置仅使用正面样本对LLMs进行微调,这是之前研究的做法。第二个设置是"Negative-Unaware Training (NUT)",它在未添加任何前缀或后缀的情况下纳入负面样本。
在LLaMA-2-Chat 7B和13B模型上进行实验,所有模型均微调2个epoch,批量大小为64。使用余弦调度器,总步骤的3%作为预热。最大学习率设置为5×10^-5。使用4×A100 GPU和DeepSpeed ZeRO 3阶段进行模型训练。

表2展示了数学任务的总体结果,观察到:(1) 纳入负面样本可以提高模型性能;(2) 采用负面感知训练(NAT)的模型不仅优于仅使用正面样本训练的相应模型(Vanilla),而且也优于直接纳入负面样本训练的相同模型(NUT);(3) 当正面样本较少或模型较小时,NAT的改进更为显著。具体来说,使用2k正面样本的7B模型,NAT实现了8.74%的性能提升,而使用5k正面样本的13B模型,性能提升为0.52%。

表3和表4展示了在HotpotQA和StrategyQA上的结果。在这里,NAT-2是NAT的一个变体,它将负面数据分为两类,并为每类使用不同的提示。在HotpotQA上,NAT-2在EM和f1分数上分别比没有负面样本提高了2%和6%。与NUT相比,NAT在EM和f1上仍然分别提高了约1%。在StrategyQA上,NAT比没有负面样本和NUT分别提高了8%和3%。
表格2到4展示了LLMs在微调为Agent时从负面样本中学习的能力。作者深入探讨了可能影响负面感知训练有效性的各种因素。他们试图回答以下问题:(1) 给定固定数量的正面样本,应该使用多少负面数据?(2) 模型从负面轨迹中学到了什么?(3) 所有类型的负面样本都有益吗?(4) 哪些因素促成了负面感知训练(NAT)优于负面无感知训练(NUT)?
训练样本数量的影响:初步分析关注负面样本数量的影响。保持正面样本数量恒定在2k和5k,同时将负面样本从0调整到12k。结果显示,随着负面数据量的增加,性能得到提升,当负面样本数量约为11k时性能趋于平稳。
数据质量的重要性:从不同模型中获取负面数据,以研究负面数据质量在NAT中的影响。具体来说,将来自GPT-3.5的数据视为高质量示例。相比之下,使用微调后的LLaMA-2-7B模型生成了10k负面样本作为低质量数据的代表。实验结果强调了数据质量在NAT中的关键作用。

模型通过NAT学到了什么:分析了由LLaMA-2-7B训练的GSM8K测试集的轨迹,这些模型分别使用正面样本(Vanilla)、NUT和NAT。表6显示了不同训练策略下模型的准确性、动作错误率(错误调用工具的百分比)和平均回合数。纳入负面样本也引入了更多的动作错误,这可能导致微调模型与Vanilla相比有更多的动作错误。然而,在纳入负面样本后,NUT和NAT的准确性都提高了。这表明负面样本主要通过教授模型更好的“思想”(即推理和规划)来起作用。
负面样本与正面样本的相似作用:为了进一步探索模型是否像从正面轨迹中学习一样从负面轨迹中学习,作者随机抽取了100个成功的轨迹作为开发集,并测量了使用2k正面样本(不与开发集重叠)和不同数量负面样本训练的模型的困惑度。图4显示了随着负面数据量的增加,困惑度的变化。随着更多负面数据的纳入,困惑度降低,这表明模型学会用失败轨迹的知识来适应成功的轨迹。然而,这条曲线在最后似乎是水平的,并且与4k和5k正面样本的曲线之间仍然存在很大差距,这表明一些来自成功轨迹的属性或知识永远无法从失败的轨迹中学到。

添加提示的选择:已经有不同的研究表明,提示对LLM性能至关重要。在这里,作者探索了添加提示的可解释性。具体而言是提示的内容使LLMs能够从成功和失败的轨迹中不同地学习,还是仅仅区分这些轨迹?他们提出了两组提示。一组是具有可解释性的提示,例如让模型生成正确或错误的轨迹。另一组是没有可解释性的提示。例如,可以为查询添加不同的字母作为前缀。表7显示了使用可解释和不可解释提示训练的模型的结果。不同的提示在性能上没有显示出大的差异,这表明NAT的性能提升来自于简单地区分正面和负面数据。
 实验结果表明,与传统的仅使用正面样本或简单地结合正面和负面样本的方法相比,NAT方法在多个任务和模型尺寸上都显示出了优越的性能。特别是在数据稀缺的场景下,NAT的性能提升更为显著。
实验结果表明,与传统的仅使用正面样本或简单地结合正面和负面样本的方法相比,NAT方法在多个任务和模型尺寸上都显示出了优越的性能。特别是在数据稀缺的场景下,NAT的性能提升更为显著。
论文链接:https://arxiv.org/pdf/2402.11651
代码链接:https://github.com/Reason-Wang/NAT
相关文章:
大模型从失败中学习 —— 微调大模型以提升Agent性能
人工智能咨询培训老师叶梓 转载标明出处 以往的研究在微调LLMs作为Agent时,通常只使用成功的交互轨迹,而丢弃了未完成任务的轨迹。这不仅造成了数据和资源的浪费,也可能限制了微调过程中可能的优化路径。论文《Learning From Failure: Integ…...

10.web应用体系以及windows网络常见操作应用
一、Dos命令 1.启动方式:winR,输入cmd 2.切换盘符/路径:盘符名称: (C:) cd 目录 (cd B111)(目录名按table键自动补全) 3.查看目录:dir dir /p 分页展示目录及…...
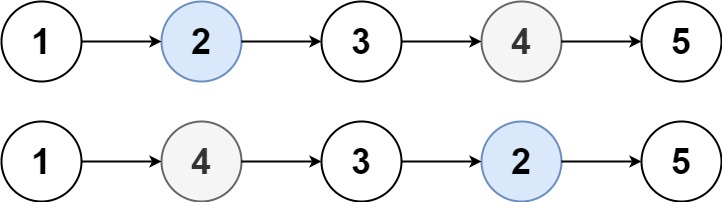
【数据结构与算法 | 灵神题单 | 前后指针(链表)篇】力扣19, 61,1721
1. 力扣19:删除链表的倒数第N个节点 1.1 题目: 给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。 示例 1: 输入:head [1,2,3,4,5], n 2 输出:[1,2,3,5]示例 2: …...

机器学习之实战篇——MNIST手写数字0~9识别(全连接神经网络模型)
机器学习之实战篇——Mnist手写数字0~9识别(全连接神经网络模型) 文章传送MNIST数据集介绍:实验过程实验环境导入模块导入MNIST数据集创建神经网络模型进行训练,测试,评估模型优化 文章传送 机器学习之监督学习&#…...

ICLR2024: 大视觉语言模型中对象幻觉的分析和缓解
https://arxiv.org/pdf/2310.00754 https://github.com/YiyangZhou/LURE 背景 对象幻觉:生成包含图像中实际不存在的对象的描述 早期的工作试图通过跨不同模式执行细粒度对齐(Biten et al.,2022)或通过数据增强减少对象共现模…...

数据库系统 第54节 数据库优化器
数据库优化器是数据库管理系统(DBMS)中的一个关键组件,它的作用是分析用户的查询请求,并生成一个高效的执行计划。这个执行计划定义了如何访问数据和执行操作,以最小化查询的执行时间和资源消耗。以下是数据库优化器的…...

微服务杂谈
几个概念 还是第一次听说Spring Cloud Alibaba ,真是孤陋寡闻了,以前只知道 SpringCloud 是为了搭建微服务的,spring boot 则是快速创建一个项目,也可以是一个微服务 。那么SpringCloud 和 Spring boot 有什么区别呢?S…...

【Pandas操作2】groupby函数、pivot_table函数、数据运算(map和apply)、重复值清洗、异常值清洗、缺失值处理
1 数据清洗 #### 概述数据清洗是指对原始数据进行处理和转换,以去除无效、重复、缺失或错误的数据,使数据符合分析的要求。#### 作用和意义- 提高数据质量:- 通过数据清洗,数据质量得到提升,减少错误分析和错误决策。…...

如何分辨IP地址是否能够正常使用
在互联网的日常使用中,无论是进行网络测试、网站访问、数据抓取还是远程访问,一个正常工作的IP地址都是必不可少的。然而,由于各种原因,IP地址可能无法正常使用,如被封禁、网络连接问题或配置错误等。本文将详细介绍如…...

Sqoop 数据迁移
Sqoop 数据迁移 一、Sqoop 概述二、Sqoop 优势三、Sqoop 的架构与工作机制四、Sqoop Import 流程五、Sqoop Export 流程六、Sqoop 安装部署6.1 下载解压6.2 修改 Sqoop 配置文件6.3 配置 Sqoop 环境变量6.4 添加 MySQL 驱动包6.5 测试运行 Sqoop6.5.1 查看Sqoop命令语法6.5.2 测…...

【数据结构】排序算法系列——希尔排序(附源码+图解)
希尔排序 算法思想 希尔排序(Shell Sort)是一种改进的插入排序算法,希尔排序的创造者Donald Shell想出了这个极具创造力的改进。其时间复杂度取决于步长序列(gap)的选择。我们在插入排序中,会发现是对整体…...

c++(继承、模板进阶)
一、模板进阶 1、非类型模板参数 模板参数分类类型形参与非类型形参。 类型形参即:出现在模板参数列表中,跟在class或者typename之类的参数类型名称。 非类型形参,就是用一个常量作为类(函数)模板的一个参数,在类(函数)模板中…...

【机器学习】从零开始理解深度学习——揭开神经网络的神秘面纱
1. 引言 随着技术的飞速发展,人工智能(AI)已从学术研究的实验室走向现实应用的舞台,成为推动现代社会变革的核心动力之一。而在这一进程中,深度学习(Deep Learning)因其在大规模数据处理和复杂问题求解中的卓越表现,迅速崛起为人工智能的最前沿技术。深度学习的核心是…...
WebLogic 笔记汇总
WebLogic 笔记汇总 一、weblogic安装 1、创建用户和用户组 groupadd weblogicuseradd -g weblogic weblogic # 添加用户,并用-g参数来制定 web用户组passwd weblogic # passwd命令修改密码# 在文件末尾增加以下内容 cat >>/etc/security/limits.conf<<EOF web…...

leetcode:2710. 移除字符串中的尾随零(python3解法)
难度:简单 给你一个用字符串表示的正整数 num ,请你以字符串形式返回不含尾随零的整数 num 。 示例 1: 输入:num "51230100" 输出:"512301" 解释:整数 "51230100" 有 2 个尾…...

Python GUI入门详解-学习篇
一、简介 GUI就是图形用户界面的意思,在Python中使用PyQt可以快速搭建自己的应用,自己的程序看上去就会更加高大上。 有时候使用 python 做自动化运维操作,开发一个简单的应用程序非常方便。程序写好,每次都要通过命令行运行 pyt…...

QT5实现https的post请求(QNetworkAccessManager、QNetworkRequest和QNetworkReply)
QT5实现https的post请求 前言一、一定要有sslErrors处理1、问题经过2、代码示例 二、要利用抓包工具1、问题经过2、wireshark的使用3、利用wireshark查看服务器地址4、利用wireshark查看自己构建的请求报文 三、返回数据只能读一次1、问题描述2、部分代码 总结 前言 QNetworkA…...

vscode 使用git bash,路径分隔符缺少问题
window使用bash --login -i 使用bash时候,在系统自带的terminal里面进入,测试conda可以正常输出,但是在vscode里面输入conda发现有问题 bash: C:\Users\marswennaconda3\Scripts: No such file or directory实际路径应该要为 C:\Users\mars…...
F12抓包10:UI自动化 - Elements(元素)定位页面元素
课程大纲 1、前端基础 1.1 元素 元素是构成HTML文档的基本组成部分之一,定义了文档的结构和内容,比如段落、标题、链接等。 元素大致分为3种:基本结构、自闭合元素(self-closing element)、嵌套元素。 1、基本结构&…...

android 删除系统原有的debug.keystore,系统运行的时候,重新生成新的debug.keystore,来完成App的运行。
1、先上一个图:这个是keystore无效的原因 之前在安装这个旧版本android studio的时候呢,安装过一版最新的android studio,然后通过模拟器跑过测试的demo。 2、运行旧的项目到模拟器的时候,就报错了: Execution failed…...
)
ElevenLabs语音克隆效果翻倍秘技(实测SSML+声纹嵌入+噪声抑制三重优化)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs语音克隆效果翻倍秘技(实测SSML声纹嵌入噪声抑制三重优化) ElevenLabs 的语音克隆能力虽强,但原始 API 调用常因语调扁平、背景干扰与韵律失真导致真实感不…...

【技术解析】从点测量到全场感知:DIC三维应变测量如何革新传统应变片测试范式
1. 从点到面的技术革命:为什么我们需要全场应变测量? 记得我第一次接触材料力学测试时,导师让我用传统应变片测量一块铝合金板的拉伸变形。我花了整整三天时间,在试样上贴了二十多个应变片,结果数据还是支离破碎。那时…...

【深度解析】Hermes Agent 0.14:OpenAI 兼容本地代理、按需依赖加载与 AI Coding 工作流升级
摘要 Hermes Agent 0.14 是一次偏“基础设施”的重要更新:安装更简单、启动更轻量,并引入 OpenAI 兼容本地代理能力,使其更适合作为模型订阅、代码工具与本地工作流之间的 Agent 路由层。背景介绍 在 AI Coding 生态中,开发者常常…...
)
告别IDE切换!在VS2022里用上C++ Builder的智能提示(保姆级路径配置)
在VS2022中无缝集成C Builder智能提示的终极指南 对于长期使用C Builder进行Windows桌面开发的工程师来说,Visual Studio 2022的现代化界面和强大调试功能一直是个诱人的存在。但频繁在两个IDE之间切换不仅打断工作流,还会显著降低开发效率。本文将揭示如…...

2026届必备的五大AI科研神器实际效果
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 人工智能技术迅猛发展,论文AI工具在学术研究领域正慢慢变成重要辅助,…...

失落大陆建模:亚特兰蒂斯数字重建的结构验证
一、项目背景与目标设定在数字孪生与虚拟考古技术飞速发展的当下,亚特兰蒂斯这一传说中失落大陆的数字重建,不仅是对古老神话的技术致敬,更是对复杂场景建模与结构验证能力的极致考验。本项目旨在依托Blender等3D建模工具,结合最新…...
)
深入浅出:STM32 USB BOS描述符与WCID配置详解(以WinUSB免驱为例)
STM32 USB BOS描述符与WCID配置实战解析:从协议到代码实现 在嵌入式开发领域,USB设备与主机系统的无缝对接一直是开发者关注的重点。传统USB设备在Windows平台上通常需要安装专用驱动程序,这不仅增加了用户使用门槛,也提高了开发维…...

开源自动化工具用例集:从网页监控到GUI自动化的实践指南
1. 项目概述:一个中文开源“利爪”用例集最近在整理一些自动化脚本和工具链时,我一直在思考一个问题:一个真正好用的、能解决实际问题的自动化工具,它的价值边界到底在哪里?是仅仅完成一个预设的、简单的任务ÿ…...

CursorLearn2API:基于AI辅助编程的本地代码自动化部署为云端API实践
1. 项目概述:从本地代码到云端API的自动化桥梁最近在折腾一个挺有意思的项目,叫gmh5225/cursorlearn2api。乍一看这个标题,可能有点摸不着头脑,但如果你是一个经常在本地用 Cursor 这类 AI 辅助编程工具写代码,同时又想…...

如何通过Xiaomusic开源项目解锁小爱音箱的完整音乐播放功能
如何通过Xiaomusic开源项目解锁小爱音箱的完整音乐播放功能 【免费下载链接】xiaomusic 使用小爱音箱播放音乐,音乐使用 yt-dlp 下载。 项目地址: https://gitcode.com/GitHub_Trending/xia/xiaomusic Xiaomusic是一款开源智能音乐播放器,专为小米…...