数据结构(14)——哈希表(1)
欢迎来到博主的专栏:数据结构
博主ID:代码小豪
文章目录
- 哈希表的思想
- 映射方法(哈希函数)
- 除留余数法
- 哈希表
- insert
- 闭散列
- 负载因子
- 扩容
- find和erase
哈希表的思想
在以往的线性表中,查找速度取决于线性表是否有序,如果是无序的线性表,我们就要从表头开始匹配key值是否相同,因此时间复杂度取决于线性表的元素个数,为O(N)。
如果线性表有序,则可以通过二分查找法大大的减少查找时间,时间复杂度为O(logN),这个时间复杂度看起来让人满意,但是我们要考虑到一点,那就是保持线性表的有序性是要付出代价的,使用排序算法也有O(N*logN)的时间复杂度。
即使是使用关联式容器,它的查找速度也是O(logN),但是好处在于插入和删除元素并不会破坏查找速度。但是查找的速度就局限于此了吗?
已现实为例,如果我们想要在城里找到大舅妈,肯定不会遍历整个城的街道,从街道口走到街道尾去找大舅妈的家,我们会先知道大舅妈的住址,直接去这个住址就能找到大舅妈。
这就是哈希表的查找的方式了,将key值放在映射的地址处,这样查找key值就不用从头开始遍历了。举个例子,假设现在有一个能容纳十个元素的哈希表。我们规定key值的个位数就是映射的地址值,即让1位于1号,2位于2号。以此类推,而10则放在0号。

假设我们要查找13,那么去3号处就能找到对应值,查找速度为O(1)。这就是哈希表查找的优势。
映射方法(哈希函数)
哈希表中的映射方法叫做哈希函数,以上表为例,其哈希函数为F(key)=key%10。于是F(13)=3,F(25)=5。一个好的哈希函数很重要。这将决定哈希表的查找,插入,删除的速率(最主要还是查找)。哈希函数需要能将key值的数据转换成整形的能力。
但是并非所有类型都可以和整形转换。比如string就不能通过F(key)=key%10的方式获得映射值,此时我们就需要设计一个使用于string的哈希函数,比如可以设计让string的所有元素相加为映射值的哈希函数,即F(string)={a1+a2+……+an}。实际上字符串的哈希函数设计绝没这么简单,感兴趣可以在网上搜索。
那么自定义类型当然也要依靠自定义的哈希函数才能获得其映射值,通常哈希函数的设计需要考虑一下几点:
(1)选取的key值的独特性,比如我们在数据库中查找一个人,如果选择“姓名”作为映射值,那么肯定效率不佳,因为全国同名同性的人是在太多了,如果我们选择“生日+姓名”作为映射值就会好很多。
(2)哈希函数的结果要尽可能的分散,假设现在有N个元素要插入到哈希表,那么它们的映射值越分散在哈希表就越好,如果N个元素经过哈希函数的运算结果的映射值都是1,那么肯定是毫无效率可言的。
(3)哈希函数的计算结果要包含在哈希表的域中,如果一个哈希表能容纳100个元素(即可容纳映射值0-99的元素),那么如果一个key值计算出映射值为101,那么肯定是没法插入的。
在c++标准库中的unordered_map,就是用哈希表为底层的容器,其允许我们传入自定义的哈希函数,已适配那些自定义的类型的映射值计算。
template < class Key, // unordered_map::key_typeclass T, // unordered_map::mapped_typeclass Hash = hash<Key>, //可以传入自定义的哈希函数// unordered_map::hasherclass Pred = equal_to<Key>, // unordered_map::key_equalclass Alloc = allocator< pair<const Key,T> > // unordered_map::allocator_type> class unordered_map;
除留余数法
除留余数法是一个比较通用,而且简单的哈希函数。其主要方法为:
设哈希表可容纳最大地址数为m,取一个不超过m的值p作为除数,其哈希函数为:hash(key)=key%p。
比如当前哈希表的最大地址数为50,待插入的key的哈希值为313,则其映射值为313%50=13。
在后续哈希表的底层设计中,博主将采用这个方法。
哈希表
hash表的底层可以用序列式容器vector,或者deque,因为哈希表的映射值与下标很适配。
template<class key,class value>
class hash_tab
{
public:hash_tab(){_tab.resize(10);_n = 0;}typedef pair<key, value> value_type;private:vector<hash_data<value_type>> _tab;size_t _n;//当前有效数据
};
而哈希表每个元素都要存储两个数据,分别是data,以及状态state。由于vector一次性开了十个元素的空间,因此有些空间是没有有效数据的。这些没有有效数据的元素的状态记为空(empty),如果元素具有有效数据则记为有(exist),如果元素的有效数据被删除,则记为删除(delete)。
enum state
{EXIST,//存在映射DELETE,//删除映射EMPTY//空的映射
};template<class T>
struct hash_data
{hash_data(){_state = EMPTY;}hash_data(const T& data,state state){_data = data;_state = state;}const hash_data& operator=(const hash_data& hashdata){_data = hashdata._data;_state = hashdata._state;return *this;}T _data;state _state;
};
insert
insert的方式如下:
(1)先通过hash函数计算出key值的映射地址处。博主采用除留余数法。
(2)将元素插入到映射值对应的地方。
比如现在插入的元素key值为60,由于当前哈希表的最大空间为10(默认构造函数),因此除留余数法为hash(60)=60%10=0。插入在0下标处。

ok,现在我们来面临第一个问题,如果我们现在插入30,那么它该插入在什么位置呢?根据哈希函数hash(30)=30%10=0。那么它应该插入在映射值为0的下标处,但是0下标处已经存在60这个数据了,那么该如何处理呢?
这种情况被称为“哈希冲突”,即不同的key值(30与60),但是经过哈希函数计算后,得到了相同的映射值(0)。如果想要减少哈希冲突,优化哈希函数是一个不错的选择,但是这并不能解决哈希冲突,通常我们会用两种方法解决哈希冲突,闭散列和开散列。这篇文章我们先来了解闭散列的哈希表,在下一篇中博主再谈谈开散列的哈希表如何实现。
闭散列
闭散列:也称开放地址法,当发生哈希冲突时。探测哈希表的空位置,将key值插入在冲突位置的下一个空位置处。探测方法也分为多种
方法(1)线性探测
线性探测:从冲突位置开始,依次往后探测,直到找到下一个新位置为止。以上例为例,由于30插入的位置与60发生了哈希冲突,那么30从0下标开始线性探测后续位置,直到遇到第一个空位置(EMPTY),DELETE也算作空位置。

如果此时在插入一个20,与60依然发生了哈希冲突,根据线性探测的方法,20应该插入在下标2的位置。

假如这个哈希表满了,那么再次插入一个key值会发生什么事呢?

根据线性探测的规则,插入2的位置会陷入一个死循环,因为在这个哈希表中已经不存在空位置了,在这个哈希表中无论探测多少次都找不到位置。
实际上,当哈希表中的元素占比整个空间越来越多时,哈希冲突发生的几率会越来越高,而每次发生哈希冲突时,都会带来额外的时间开销(线性探测)。因此,最好的解决方法是控制元素与空间之间的占比。
负载因子
我们将哈希表中元素与空间之间的占比成为负载因子。即:
负载因子=元素个数÷哈希表的总容量
负载因子与元素个数成正比,与哈希表的总容量成反比,当负载因子小时,发生哈希冲突的几率低,插入效率高,但是空间利用率也低。当负载因子大时,发生哈希冲突的几率大,插入效率低,但是空间利用率高。因此控制负载因子在一定的数值内也是很重要的。
通常来说,采取线性探测的哈希表,其负载因子应该控制到0.7~0.8。如果负载因子超过这个区间,就要对哈希表进行扩容。以降低哈希表的负载因子。
扩容
哈希表的扩容策略是异地扩容,即先构造一个新的哈希表,这个新的哈希表是原哈希表的二倍,然后再讲原哈希表的元素重新插入在新哈希表当中。最后交换新旧两个哈希表。那么为什么要这样做呢?与其说异地扩容的好处,不如讲讲原地扩容的坏处。
假如我们将上例中的哈希表扩容两倍,即新哈希表的容量为20.

由于哈希表的最大容量发生了变化,那么哈希函数也会随之变化,因为我们设定的哈希函数为
hash(key)=key%size
由于size从10变成了20,那么哈希函数就变成了key%20。那么哈希表中17的映射值为
hash(17)=17%20=17,这个插入位置就不对。因此更好的方式是新建一个新哈希表。将旧表的内容插入至新表当中。

bool insert(const value_type& kv){//负载因子过多,需要扩容 负载因子等于size%_nif (double(_n) / _tab.size() >= 0.7){hash_tab new_tab;new_tab._tab.resize(_tab.size() * 2);//建立新表for (auto& e : _tab){if (e._state == EXIST)//只插入有效值{new_tab.insert(e._data);//将旧表的值插入到新表当中}}_tab.swap(new_tab._tab);//交换新旧两表}size_t hashnum = kv.first % _tab.size();//哈希函数——除留余数法while (_tab[hashnum]._state ==EXIST )//线性探测{hashnum++;hashnum %= _tab.size();}_tab[hashnum] = hash_data<value_type>(kv, EXIST);//插入新值_n++;return true;}
find和erase
find函数的方法如下:
通过哈希函数计算出映射值,找到映射的位置,然后线性检测找到正确的key值,然后返回节点,如果线性检测到空节点(DELETE不算空节点,仅EMPTY)。就说明哈希表中不存在对应key值,返回nullptr。

hash_data<value_type>* find(const key& key){size_t hashnum = key % _tab.size();while (_tab[hashnum]._state != EMPTY){if (key == _tab[hashnum]._data.first&&_tab[hashnum]._state!=DELETE){return &_tab[hashnum];}hashnum++;hashnum %= _tab.size();}return nullptr;}
erase的实现就更简单,我们先通过find查找到待删除的元素,然后将该元素的状态调整成DELETE就可以了,因为对这个元素的data进行修改不是一个明智的选择。这会影响到映射关系。
bool erase(const key& key)
{size_t hashnum = key % _tab.size();hash_data<value_type>* ptr=find(key);if (ptr == nullptr)return false;ptr->_state = DELETE;_n--;return true;
}
相关文章:
数据结构(14)——哈希表(1)
欢迎来到博主的专栏:数据结构 博主ID:代码小豪 文章目录 哈希表的思想映射方法(哈希函数)除留余数法 哈希表insert闭散列负载因子扩容find和erase 哈希表的思想 在以往的线性表中,查找速度取决于线性表是否有序&#…...

K近邻算法_分类鸢尾花数据集
import numpy as np import pandas as pd from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score1.数据预处理 iris load_iris() df pd.DataFrame(datairis.data, columnsiris.featur…...

nacos和eureka的区别详解
Nacos 和 Eureka 都是服务发现和注册中心的解决方案,但它们在功能、设计和使用场景上有所不同。以下是它们的详细区别: 1. 基本概念 Eureka:是由 Netflix 开发的服务发现工具。它主要用于 Java 微服务架构中的服务注册与发现。Eureka 通过 R…...

AI大模型包含哪些些技术?
Prompt Prompt提示是模型接收以生成响应或完成任务的初始文本输入。 我们给AI一组Prompt输入,用于指导模型生成响应以执行任务。这个输入可以是一个问题、一段描述、一组关键词,或任何其他形式的文本,用于引导模型产生特定内容的响应。 Tra…...

分布式技术概览
文章目录 分布式技术1. 分布式数据库(Distributed Databases)2. 分布式文件系统(Distributed File Systems)3. 分布式哈希表(Distributed Hash Tables, DHTs)4. 分布式缓存(Distributed Caching…...

动手学习RAG: moka-ai/m3e 模型微调deepspeed与对比学习
动手学习RAG: 向量模型动手学习RAG: moka-ai/m3e 模型微调deepspeed与对比学习动手学习RAG:迟交互模型colbert微调实践 bge-m3 1. 环境准备 pip install transformers pip install open-retrievals注意安装时是pip install open-retrievals,但调用时只…...

Nacos rce-0day漏洞复现(nacos 2.3.2)
Nacos rce-0day漏洞复现(nacos 2.3.2) NACOS是 一个开源的服务发现、配置管理和服务治理平台,属于阿里巴巴的一款开源产品。影像版本:nacos2.3.2或2.4.0版本指纹:fofa:app“NACOS” 从 Github 官方介绍文档可以看出国…...

yjs04——matplotlib的使用(多个坐标图)
1.多个坐标图与一个图的折线对比 1.引入包;字体(同) import matplotlib.pyplot as plt import random plt.rcParams[font.family] [SimHei] plt.rcParams[axes.unicode_minus] False 2.创建幕布 2.1建立图层幕布 一个图:plt.fig…...

MOS管和三极管有什么区别?
MOS管是基于金属-氧化物-半导体结构的场效应晶体管,它的控制电压作用于氧化物层,通过调节栅极电势来控制源漏电流。MOS管是FET中的一种,现主要用增强型MOS管,分为PMOS和NMOS。 MOS管的三个极分别是G(栅极),D(漏极)&…...
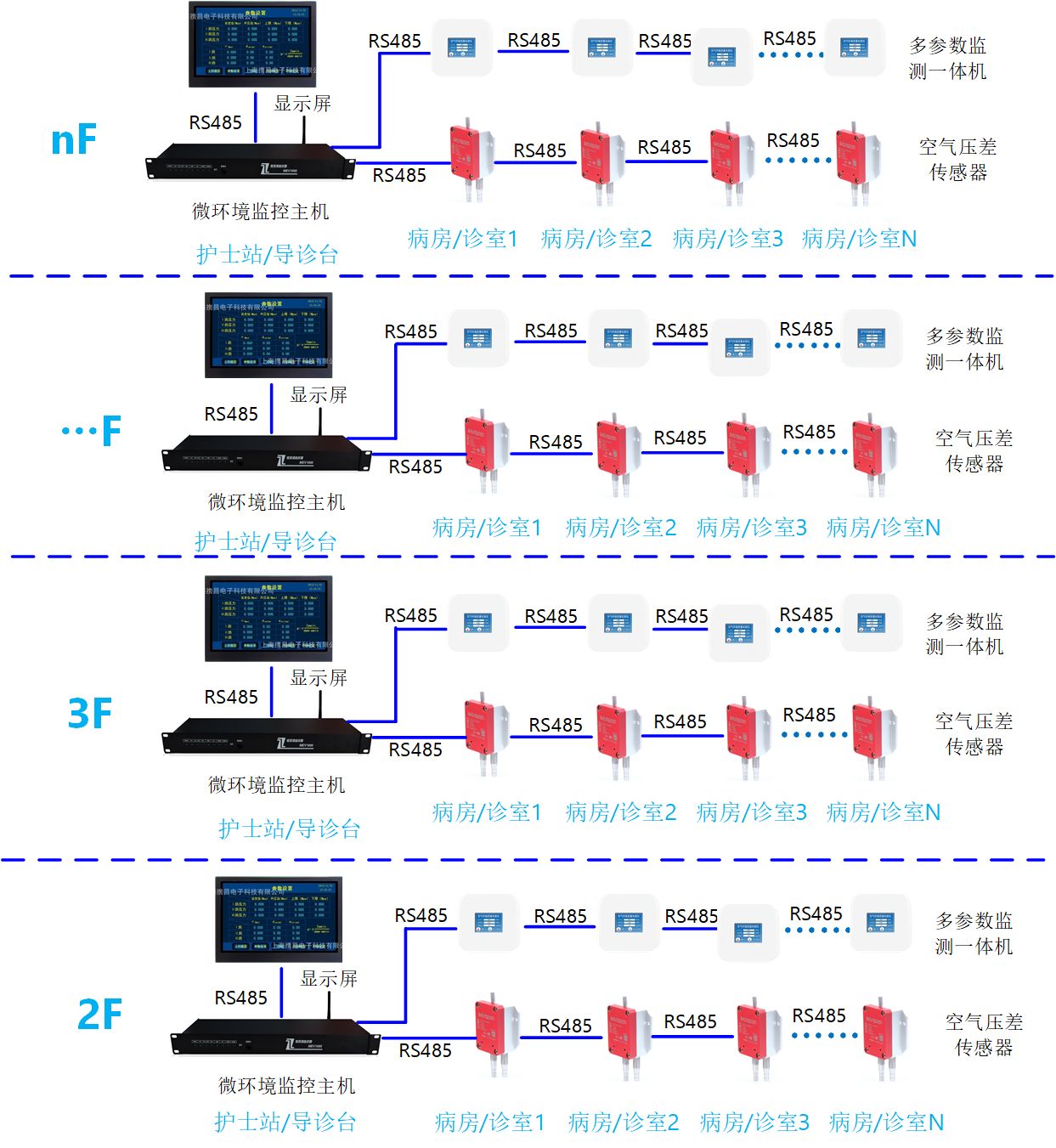
医院多参数空气质量监控和压差监测系统简介@卓振思众
在现代医院管理中,确保患者和医疗人员的健康与安全是首要任务。为实现这一目标,医院需要依赖高科技设施来维持最佳的环境条件。特别是,多参数空气质量监测系统和压差监测系统在这一方面发挥了不可替代的作用。【卓振思众】多参数空气质量监测…...

[项目实战]EOS多节点部署
文章总览:YuanDaiMa2048博客文章总览 EOS多节点部署 (一)环境设计(二)节点配置(三)区块信息同步(四)启动节点并验证同步EOS单节点的环境如何配置 (一…...
 vs setTimeout() 在 JavaScript 中的区别)
setImmediate() vs setTimeout() 在 JavaScript 中的区别
setImmediate() vs setTimeout() 在 JavaScript 中的区别 在 JavaScript 中,setImmediate() 和 setTimeout() 都用于调度任务,但它们的工作方式不同。 JavaScript 的异步特性 JavaScript 以其非阻塞、异步行为而闻名,尤其是在 Node.js 环境…...

【Java文件操作】文件系统操作文件内容操作
文件系统操作 常见API 在Java中,File类是用于文件和目录路径名的抽象表示。以下是一些常见的方法: 构造方法: File(String pathname):根据给定的路径创建一个File对象。File(String parent, String child):根据父路径…...

关于若依flowable的安装
有个项目要使用工作流功能,在网上看了flowable的各种资料,最后选择用若依RuoYi-Vue-Flowable这个项目来迁移整合。 一、下载项目代码: 官方项目地址:https://gitee.com/shenzhanwang/Ruoyi-flowable/ 二、新建数据库ÿ…...
)
猜数字困难版(1-10000)
小游戏,通过提示每次猜高或猜低以及每次猜中的位数,10次内猜中1-10000的一个数。 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthde…...

ASPICE术语表
术语来源描述活动Automotive SPICE V4.0由利益相关方或参与方执行的任务用参数Automotive SPICE V4.0应用参数是包含了在系统或软件层级可被更改的数据的软件变量,他们影响系统或软件的行为和属性。应用参数的概念有两种表达方式:规范(分别包括变量名称、值域范围、…...

Knife4j:打造优雅的SpringBoot API文档
1. 为什么需要API文档? 在现代软件开发中,API文档的重要性不言而喻。一份清晰、准确、易于理解的API文档不仅能够提高开发效率,还能降低前后端沟通成本。今天,我们要介绍的Knife4j正是这样一款强大的API文档生成工具,它专为Spring Boot项目量身打造,让API文档的生成…...
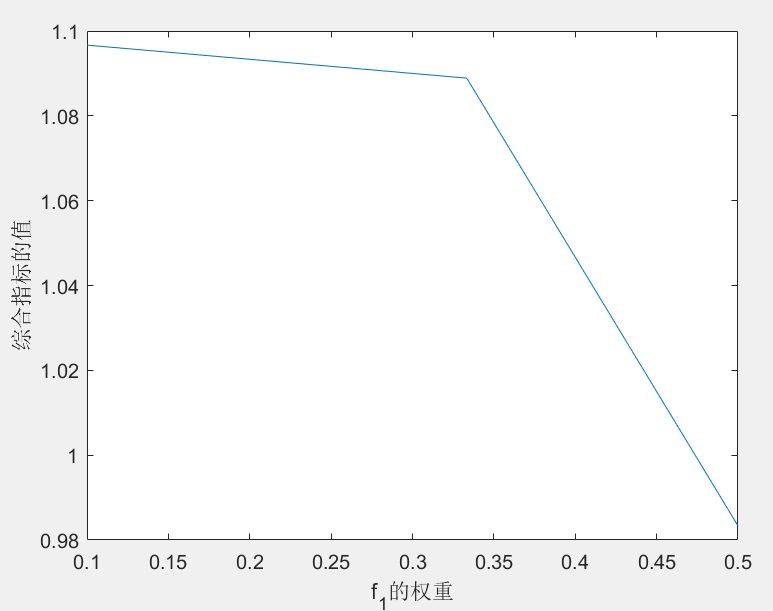
数学建模笔记—— 多目标规划
数学建模笔记—— 多目标规划 多目标规划1. 模型原理1.1 多目标规划的一般形式1.2 多目标规划的解1.3 多目标规划的求解 2. 典型例题3. matlab代码实现 多目标规划 多目标规划是数学规划的一个分支。研究多于一个的目标函数在给定区域上的最优化。又称多目标最优化。通常记为 …...

【鸿蒙HarmonyOS NEXT】页面之间相互传递参数
【鸿蒙HarmonyOS NEXT】页面之间相互传递参数 一、环境说明二、页面之间相互传参 一、环境说明 DevEco Studio 版本: API版本:以12为主 二、页面之间相互传参 说明: 页面间的导航可以通过页面路由router模块来实现。页面路由模块根据页…...

SonicWall SSL VPN曝出高危漏洞,可能导致防火墙崩溃
近日,有黑客利用 SonicWall SonicOS 防火墙设备中的一个关键安全漏洞入侵受害者的网络。 这个不当访问控制漏洞被追踪为 CVE-2024-40766,影响到第 5 代、第 6 代和第 7 代防火墙。SonicWall于8月22日对其进行了修补,并警告称其只影响防火墙的…...

开发者专属提示词库:提升AI协作效率的实战指南
1. 项目概述:一个为开发者量身定制的提示词宝库如果你是一名开发者,无论是前端、后端、运维还是算法工程师,我相信你都或多或少地接触过像 ChatGPT 这类大型语言模型。它们能写代码、解 Bug、解释概念,甚至帮你设计架构。但很多时…...

当Windows 11 LTSC失去应用商店时,如何轻松找回完整的应用生态?
当Windows 11 LTSC失去应用商店时,如何轻松找回完整的应用生态? 【免费下载链接】LTSC-Add-MicrosoftStore Add Windows Store to Windows 11 24H2 LTSC 项目地址: https://gitcode.com/gh_mirrors/ltscad/LTSC-Add-MicrosoftStore 你是否曾经为W…...

AI驱动代码审查:Cursor与Git工作流融合实践
1. 项目概述:当AI代码助手遇上代码审查最近在GitHub上看到一个挺有意思的项目,叫guinacio/cursor-review。光看名字,你可能会觉得这又是一个普通的代码审查工具,但点进去仔细研究,你会发现它的核心思路非常巧妙&#x…...

基于MCP协议构建AI数据连接器:从原理到SQL查询服务器实践
1. 项目概述:一个连接AI与数据源的“翻译官”最近在折腾AI应用开发,特别是想让大语言模型(LLM)能直接、安全地访问我自己的数据库、API或者文件系统时,遇到了一个普遍难题:怎么让AI理解并操作这些外部数据源…...

Midjourney像素艺术提示词工程:98%新手忽略的4个隐藏权重指令,实测提升风格还原度320%
更多请点击: https://intelliparadigm.com 第一章:Midjourney像素艺术提示词工程的底层逻辑重构 像素艺术在 Midjourney 中并非天然适配的生成模态,其高精度、低分辨率、强风格约束的特性与扩散模型默认的连续性渲染范式存在根本张力。要实现…...
)
保姆级教程:INCA 7.2.3 从新建工程到观测标定的完整流程(附A2L文件处理技巧)
INCA 7.2.3 全流程实战指南:从工程搭建到参数标定的深度解析 在汽车电子开发领域,标定工具链的掌握程度直接影响开发效率。作为行业标准的INCA软件,其7.2.3版本在工程管理、实时观测和参数标定方面提供了更完善的解决方案。本文将采用"操…...

AI原生编程语言Reia:为LLM设计的编程范式变革
1. 项目概述:Reia,一个面向未来的AI原生编程语言最近在AI和编程语言交叉领域,一个名为Reia的项目引起了我的注意。它来自Quaint-Studios,定位是“AI原生”的编程语言。这听起来有点抽象,但简单来说,Reia试图…...

从零构建Next.js全栈应用:实战解析服务端渲染与API路由
1. 项目概述与核心价值最近在社区里看到不少朋友在讨论一个叫“panaverse/learn-nextjs”的项目,作为一个在Web开发领域摸爬滚打了十多年的老码农,我立刻来了兴趣。这个项目名直译过来就是“Panaverse的Next.js学习项目”,听起来像是一个学习…...

云端生信分析:从零部署RStudio Server避坑指南
1. 为什么需要云端RStudio Server? 做生物信息分析的朋友们肯定深有体会,单细胞测序、转录组这些数据动辄几十GB,用自己电脑跑分析简直是折磨。我去年处理一个肝癌单细胞项目时,光是读取数据就卡了半小时,更别说后续的…...

AI科技热点日报 | 2026年5月16日
文章目录AI科技热点日报 | 2026年5月16日一、大模型与基础技术《人工智能终端智能化分级》系列国家标准发布"九章四号"量子计算原型机刷新世界纪录二、AI政策与监管人工智能科技伦理审查与服务先导计划启动工信部部署高质量行业数据集建设三、Agent与应用"AI教育…...