大数据-128 - Flink 并行度设置 细节详解 全局、作业、算子、Slot
点一下关注吧!!!非常感谢!!持续更新!!!
目前已经更新到了:
- Hadoop(已更完)
- HDFS(已更完)
- MapReduce(已更完)
- Hive(已更完)
- Flume(已更完)
- Sqoop(已更完)
- Zookeeper(已更完)
- HBase(已更完)
- Redis (已更完)
- Kafka(已更完)
- Spark(已更完)
- Flink(正在更新!)
章节内容
上节我们完成了如下的内容:
- ManageOperatorState
- StateBackend
- Checkpoint

简单介绍
一个Flink程序由多个Operator组成(Source、Transformation、Sink)。
一个Operator由多个并行的Task(线程)来执行,一个Operator的并行Task(线程)数目就被称为该Operator(任务)并行度(Paralle)
并行度可以有如下几种指定方式。
Flink 中的并行度(Parallelism)是指每个算子(Operator)在任务执行时可以同时处理数据的并发实例数。Flink 的核心优势之一就是能够通过并行处理大规模数据来提高效率和性能。通过正确设置并行度,你可以在充分利用集群资源的同时,实现高效的数据处理。接下来详细介绍 Flink 并行度的概念、设置方法及其优化策略。
并行度的概念
在 Flink 中,并行度主要决定每个操作符在作业中被分配多少个并发实例来处理数据。操作符的并行实例越多,任务就能够越快完成。通常,Flink 作业中的每个操作符都会以并行实例的形式执行在集群中的不同 TaskManager 上,这样可以充分利用集群的计算资源。
Flink 中的并行度可以分为以下几个层级:
全局并行度(Global Parallelism)
全局并行度是指 Flink 集群默认为所有作业和操作符分配的并行度。在配置文件 flink-conf.yaml 中,你可以通过以下配置来设置 Flink 集群的默认全局并行度:
parallelism.default: 4
这个配置将为每个没有指定并行度的操作符分配默认的 4 个并行实例。如果你没有在代码中或任务提交时明确设置并行度,Flink 将使用这个默认值。
作业并行度(Job-level Parallelism)
在提交 Flink 作业时,你可以为整个作业设置并行度,覆盖全局默认值。例如,在命令行使用 flink run 提交作业时可以通过 -p 参数来设置并行度:
flink run -p 10 your-job.jar
此命令将作业的并行度设置为 10,作业中的每个操作符都会被分配 10 个并行实例。这个设置的优先级高于全局并行度。
算子并行度(Operator-level Parallelism)
你可以在代码中为每个具体的算子设置不同的并行度。Flink 提供了灵活的算子级别并行度控制,可以根据数据处理逻辑的需要对不同的算子设定不同的并行度。例如:
DataStream<String> stream = env.readTextFile("input.txt").map(new MyMapper()).setParallelism(5);
在这段代码中,map 操作的并行度被设置为 5,这意味着 map 操作会启动 5 个并发任务来处理数据。其他没有显式设置并行度的算子将使用默认的作业级别并行度。
Slot 并行度(Slot-level Parallelism)
Flink 中的 TaskManager 是执行并行任务的工作节点,每个 TaskManager 中可以包含多个任务槽(Slot)。每个 Slot 对应一个并发任务实例,并可以同时运行多个任务实例。Slot 并行度是 Flink 资源分配中的重要概念,如果作业的并行度超过了集群中可用的 Slot 数,Flink 会进行资源调度,这可能会导致性能下降。
每个 TaskManager 可以配置 Slot 数,例如:
taskmanager.numberOfTaskSlots: 4
Operator Level
算子级别,一个算子,数据源和Sink并行度可以通过调用setParalleism()方法来指定
actions.filter(new FilterFunction<UserAction>() {@Overridepublic boolean filter(UserAction value) throws Exception {return false;}
}).setParallelism(4);
Execution Environment Level
Env级别
执行环境(任务)的默认并行度可以通过调用setParallelism()方法指定,为了并行度3来执行所有的算子、数据源的DataSink,可以通过如下的方式设置执行环境的并行度:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(4);
Client Level
客户端级别,推荐使用。
并行度可在客户端将Job提交到Flink时设定,对于CLI客户端,可以通过-p参数指定并行度。
System Level
系统默认级别,尽量不使用。在系统级可以通过设置 flink-conf.yaml中的parallism.default属性来执行环境的默认并行度。


如何设置 Flink 并行度
Flink 提供了几种方法来设置并行度:
在 Flink 配置文件中设置全局并行度
parallelism.default: 4
在提交作业时设置并行度
这里的 -p 20 设置作业的并行度为 20。
flink run -p 20 your-job.jar
在代码中为算子设置并行度
DataStream<String> dataStream = env.readTextFile("input.txt").map(new MyMapper()).setParallelism(10);
并行度的优化策略
合理设置并行度可以有效提高 Flink 作业的性能,但并行度的设置需要根据数据量、任务复杂度、集群资源等多个因素综合考虑。以下是一些优化策略:
根据数据量设置合理的并行度
对于大数据量的任务,可以通过增加并行度来提高处理速度,但并不是并行度越高越好。过高的并行度会导致资源浪费和任务调度开销。一般来说,建议作业的并行度不要超过 TaskManager 可用 Slot 的总数。
合理分配操作符的并行度
某些操作符,比如 keyBy() 后的 reduce 或 aggregate,其并行度受键值数量的限制,因此为这些操作符设置过高的并行度并不会提高性能。你可以通过数据的特性和操作符的逻辑来合理分配不同操作符的并行度。
利用资源监控进行动态调优
在任务运行时,可以使用 Flink 的 Web UI 来监控作业的运行状态。如果发现某些算子的处理速度慢、资源利用率低,可以考虑调整这些算子的并行度。此外,Flink 允许通过 REST API 或 Web UI 动态调整并行度,而无需重新提交作业。
考虑网络和 I/O 限制
Flink 作业的性能不仅取决于 CPU 和内存,还受限于网络带宽和 I/O 速度。在处理大数据时,如果作业需要频繁地进行网络传输或者 I/O 操作(如读取和写入 HDFS、Kafka),应避免过高的并行度导致网络或磁盘 I/O 的瓶颈。
并行度与容错性
Flink 支持容错机制,当任务失败时,Flink 会根据保存点(checkpoint)进行恢复。高并行度的作业通常会生成更多的 checkpoint 数据,在某些情况下会增加作业恢复时的开销。因此,在设置高并行度时,要同时考虑到 Flink 容错机制可能带来的性能影响。
代码实例
假设有一个作业需要从 Kafka 读取数据,经过 map 转换后将处理结果写入 HDFS。在这种场景下,你可以根据任务的负载和集群资源设置不同算子的并行度:
假设我们有一个 Flink 作业,该作业的任务是:
- 从 Kafka 读取实时的交易数据流。
- 对每一条交易数据进行清洗和转换。
- 将清洗后的数据写入 HDFS 进行存储。
这个任务需要根据各个操作的特性设置不同的并行度,以实现性能和资源的最佳利用。
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import org.apache.flink.streaming.connectors.kafka.KafkaDeserializationSchema;
import org.apache.flink.streaming.connectors.kafka.KafkaSerializationSchema;
import org.apache.flink.streaming.connectors.kafka.KafkaSink;
import org.apache.flink.core.fs.Path;import java.util.Properties;public class FlinkParallelismExample {public static void main(String[] args) throws Exception {// 1. 创建流处理环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 设置全局并行度(默认并行度)env.setParallelism(8); // 全局默认并行度为8// 2. 配置 Kafka 消费者Properties kafkaProps = new Properties();kafkaProps.setProperty("bootstrap.servers", "localhost:9092");kafkaProps.setProperty("group.id", "transaction-group");FlinkKafkaConsumer<String> kafkaSource = new FlinkKafkaConsumer<>("transaction-topic", new SimpleStringSchema(), kafkaProps);// 设置 Kafka 源的并行度DataStream<String> transactionStream = env.addSource(kafkaSource).setParallelism(6); // 从 Kafka 读取数据时的并行度为 6// 3. 数据转换操作DataStream<String> cleanedData = transactionStream.map(value -> cleanTransactionData(value)).setParallelism(12); // 数据清洗的并行度为 12// 4. 将清洗后的数据写入 HDFScleanedData.writeAsText("hdfs://namenode:8020/flink/cleaned_transactions/").setParallelism(4); // 写入 HDFS 的并行度为 4// 5. 启动任务env.execute("Flink Parallelism Example");}// 数据清洗的逻辑public static String cleanTransactionData(String transaction) {// 假设清洗逻辑包括去除不必要的字段,格式化数据等return transaction.trim(); // 简单清洗逻辑示例}
}代码说明
- 全局并行度:我们在代码中通过 env.setParallelism(8) 设置了全局的并行度为 8。这意味着,除非显式设置,所有的算子默认都会使用 8 个并行实例运行。
- Kafka 消费并行度:通过 setParallelism(6) 为从 Kafka 读取数据的操作设置了并行度为 6。也就是说,Flink 将会启动 6 个并行任务来从Kafka 的 transaction-topic 主题中消费数据。这个并行度可以根据 Kafka 分区的数量调整。如果 Kafka 有 6 个分区,那么设置并行度为 6 是合理的,这样可以保证每个分区都有一个并发实例进行处理。
- 数据转换并行度:数据从 Kafka 读取后,进入 map 操作进行清洗和转换。这里的并行度被设置为 12(setParallelism(12)),即清洗任务将启动 12 个并行实例来同时处理数据。这可以提高数据处理速度,但也需要确保集群中有足够的计算资源支持这个并行度。
- HDFS 写入并行度:在数据清洗完成后,将数据写入 HDFS 文件系统。这里我们设置了写入 HDFS 的并行度为 4(setParallelism(4))。这意味着将有 4 个并发任务负责将数据写入到 HDFS。由于 HDFS 的写入通常涉及磁盘 I/O 操作,设置较低的并行度可以避免 I/O 争用。


注意
- 并行度优先级:算计级别 > env级别 > Client 级别 > 系统默认级别
- 如果Source不可以被并行执行,即使指定了并行度为多个,也不会生效
- 尽可能的规避算子的并行度的设置,因为并行度的改变会造成Task的重新划分,带来Shuffle问题
- 推荐使用任务提交的时候动态的指定并行度
- slot是静态的概念,是指TaskManager具有的并发执行能力:parallelism是动态的概念,是指定程序运行时实际使用的并发能力
相关文章:
大数据-128 - Flink 并行度设置 细节详解 全局、作业、算子、Slot
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完)HDFS(已更完)MapReduce(已更完&am…...
图新地球-将地图上大量的地标点批量输出坐标到csv文件【kml转excel】
0.序 有很多用户需要在卫星影像、或者无人机航测影像、倾斜模型上去标记一些地物的位置(如电线杆塔、重点单位、下水盖等) 标记的位置最终又需要提交坐标文本文件给上级单位或者其他部门使用,甚至需要转为平面直角坐标。 本文的重点是通过of…...

Git提交有乱码
服务器提交记录如图 可知application.properties中文注释拉黄线 ,提示Unsupported characters for the charset ISO-8859-1 打开settings - Editor - File Encodings 因为我们项目的其他文件都是UTF-8,所以,我们将默认值都改成UTF-8 然后…...

leetcode hot100_part4_子串
2024/4/20—4/21 560.和为K的子数组 前缀和哈希表,做二叉树的时候也有这个套路。注意细节,遍历到当前前缀和的时候是先找结果个数还是先加入哈希?应该先找结果个数,不然的话,当前位置也算上了(因为是前缀和…...

Spring Cloud之三 网关 Gateway
1:Intellij 新建项目 spring-cloud-gateway 2:pom.xml <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLoca…...

Linux 进程1
进程 在linux系统中,触发任何一个事件时系统会将其定义为一个进程(一个程序开始执行),系统会给这个进程分配一个进程ID统称为PID。 程序:通常是二进制文件,放置于存储媒介如硬盘中。 进程:当存…...
)
LeetCode: 2552. 统计上升四元组 动态规划 时间复杂度O(n*n)
2552. 统计上升四元组 today 2552. 统计上升四元组 题目描述 给你一个长度为n下标从 0 开始的整数数组 nums ,它包含1到n的所有数字,请你返回上升四元组的数目。 如果一个四元组 (i, j, k, l) 满足以下条件,我们称它是上升的:…...

Unity 编辑器设置中文
在 Unity 编辑器中,你可以按照以下步骤将语言设置为中文: 步骤: 1. 打开 Unity 编辑器。 2. 在顶部菜单栏,依次点击 Edit > Preferences(在 macOS 上是 Unity > Preferences)。 3. 在弹出的 Preferen…...

springboot-创建连接池
操作数据库 代码开发步骤: pom.xml文件配置依赖properties文件配置连接数据库信息(连接池用的是HikariDataSource)数据库连接池开发 configurationproperties和value注解从properties文件中取值bean方法开发 service层代码操作数据库 步骤&am…...

matlab绘制不同区域不同色彩的图,并显示数据(代码)
绘图结果如下: 代码如下: A为绘图的数据,每个数据对应着上图中的一个区域,数据大小决定区域的颜色 % 假设有一系列的数据点 Arand(5,6); %A为绘图的数据,数据大小决定颜色 wei_shu%.3f; %代表数据保留三位小…...

Docker Desktop 的安装与汉化指南
前言 Docker Desktop 是一款非常流行的开发工具,它使得开发者能够在自己的计算机上轻松地构建、运行和调试 Docker 容器。然而,默认情况下,Docker Desktop 的界面是英文的,对于中文用户来说,有时候会觉得不够友好。幸…...

前端form表单+ifarme方式实现大文件下载
// main.jsimport Vue from vue; import App from ./App.vue; import { downloadTokenFile } from /path/to/your/function; // 替换为您的函数路径// 将 downloadTokenFile 添加到 Vue 原型上 Vue.prototype.$downloadTokenFile downloadTokenFile;new Vue({el: #app,render:…...

Leetcode面试经典150题-141.环形链表
题目比较简单,重点是理解思想 解法都在代码里,不懂就留言或者私信 /*** Definition for singly-linked list.* class ListNode {* int val;* ListNode next;* ListNode(int x) {* val x;* next null;* }* }*/ public…...

sh文件执行提示语法错误: 未预期的文件结尾
在执行sh文件时总是提示:语法错误: 未预期的文件结尾,尝试删除最后的空格也不对 最后发现在notepad中转换的问题 需要把windows换成unix就行了...

基于SpringBoot的甜品店管理系统
作者:计算机学姐 开发技术:SpringBoot、SSM、Vue、MySQL、JSP、ElementUI等,“文末源码”。 专栏推荐:前后端分离项目源码、SpringBoot项目源码、SSM项目源码 系统展示 【2025最新】基于JavaSpringBootVueMySQL的蛋糕甜品店管理系…...

动态规划-不同的子序列
题目描述 给你两个字符串 s 和 t ,统计并返回在 s 的 子序列 中 t 出现的个数,结果需要对 109 7 取模。 示例: 输入:s "babgbag", t "bag" 输出:5 解释: 如下所示, 有 5 种可以从…...
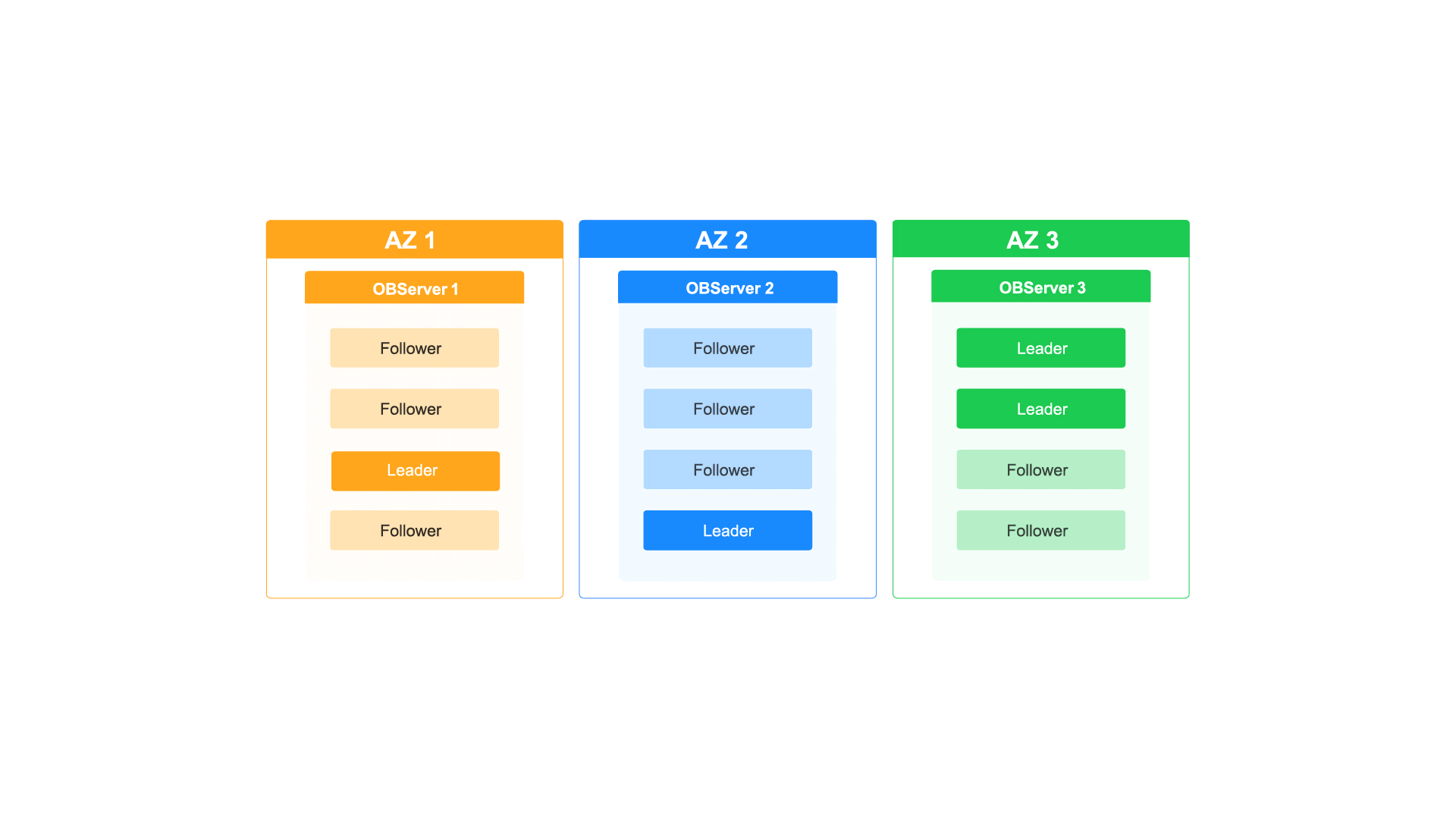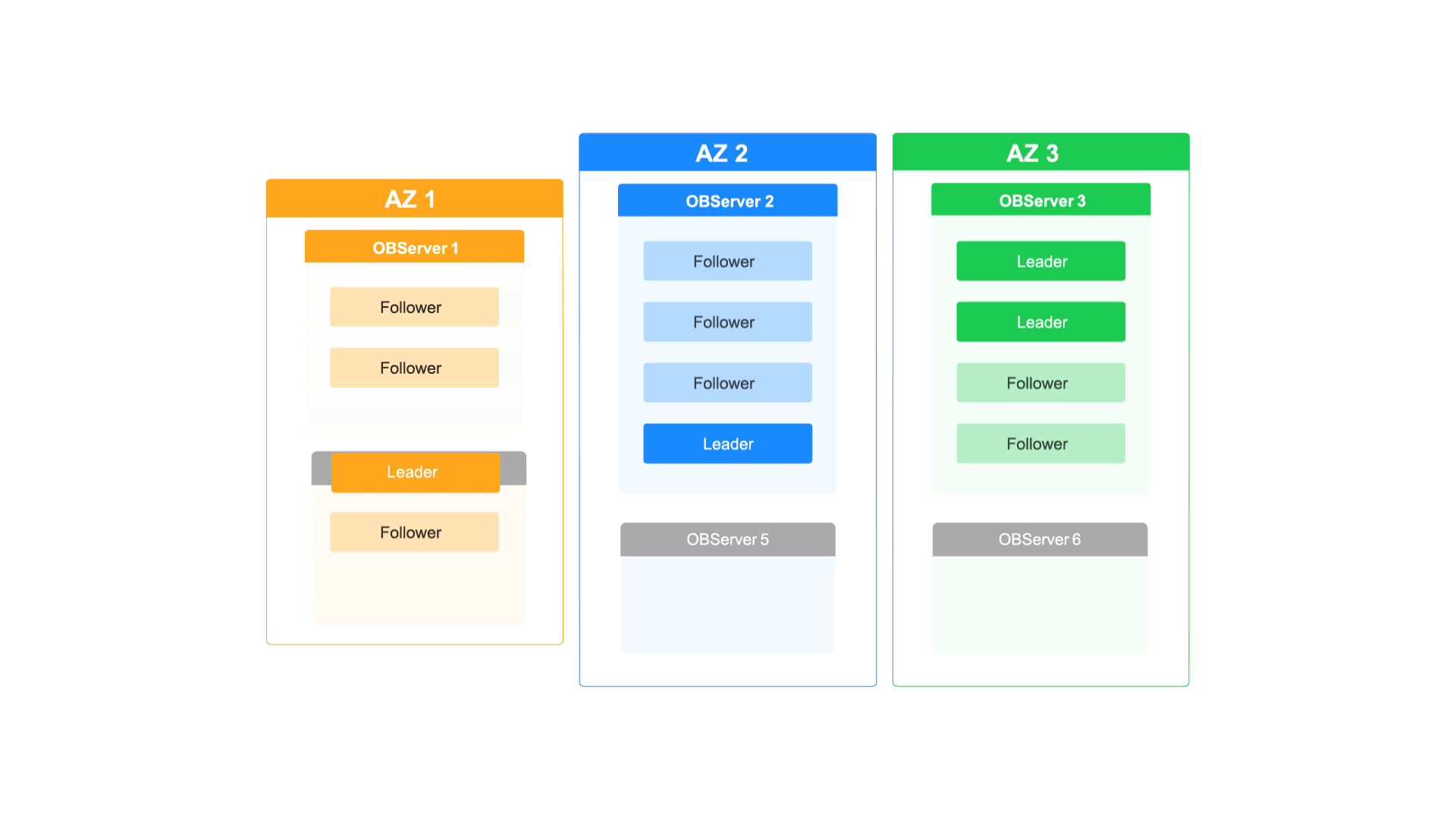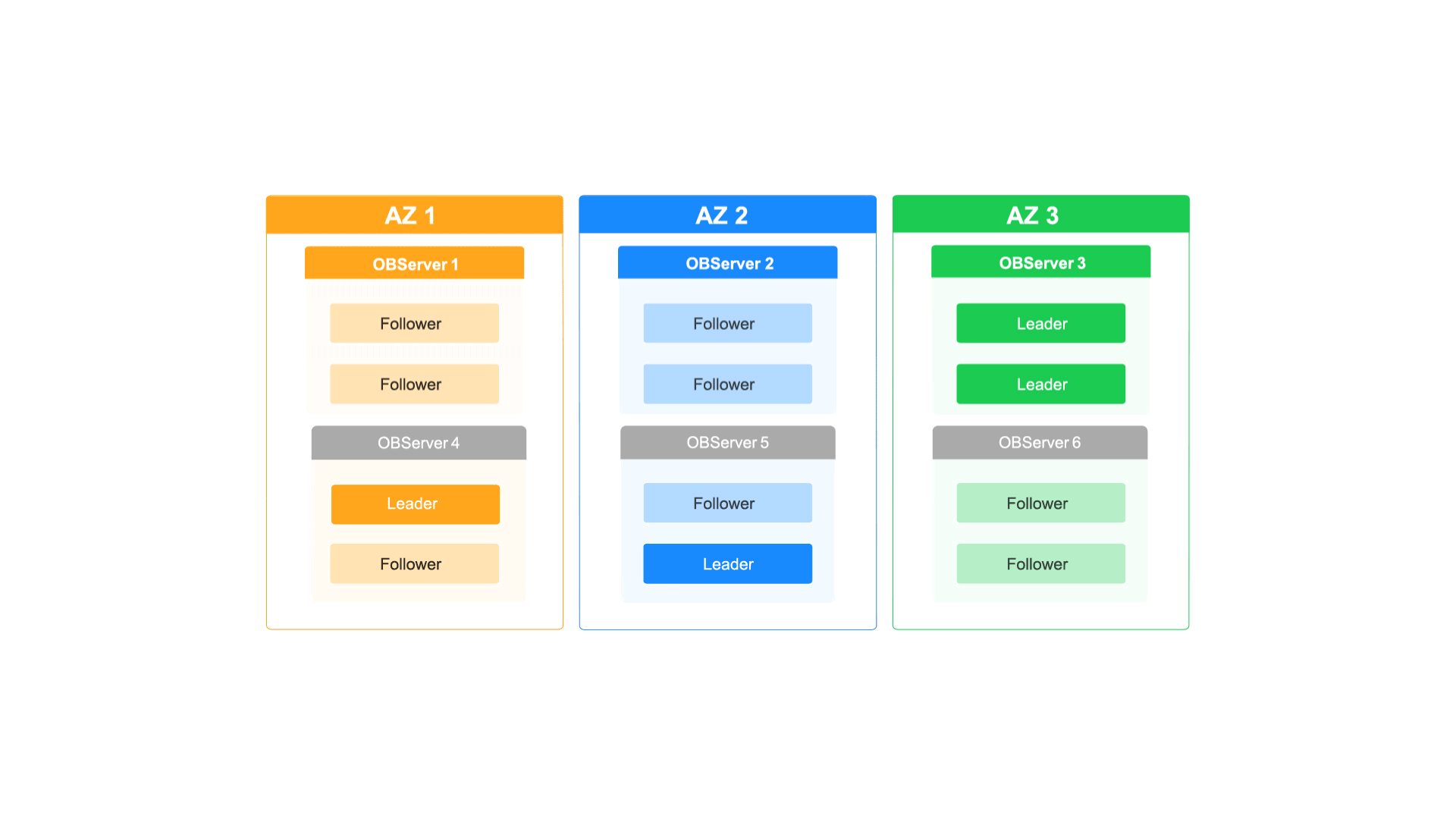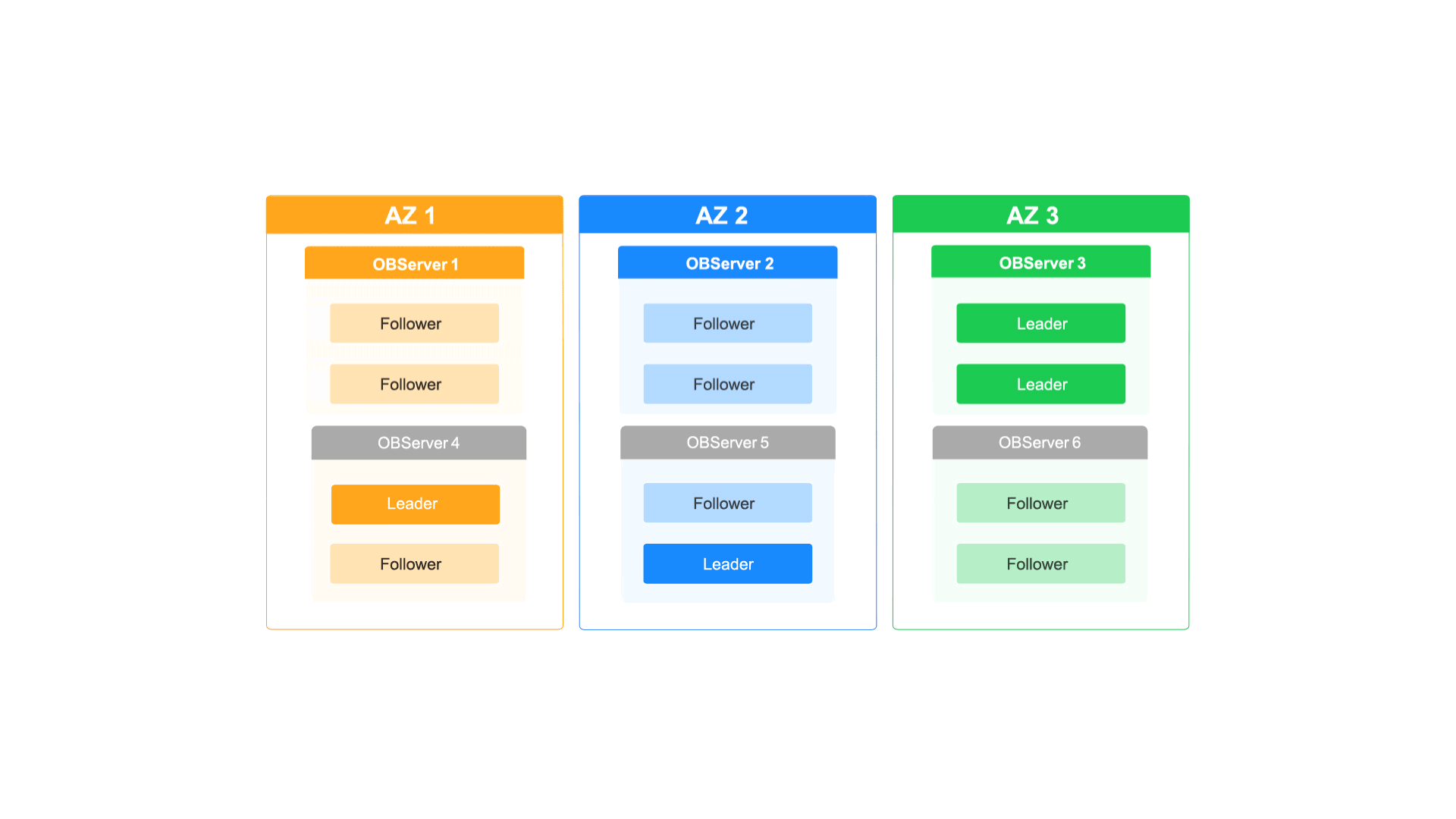
如何通过OceanBase的多级弹性扩缩容能力应对业务洪峰
每周四晚上的10点,都有近百万的年轻用户进入泡泡玛特的抽盒机小程序,共同参与到抢抽盲盒新品的活动中。瞬间的并发流量激增对抽盒机小程序的系统构成了巨大的挑战,同时也对其数据库的扩容能力也提出了更高的要求。 但泡泡玛特的工程师们一点…...

D - 1D Country(AtCoder Beginner Contest 371)
题目链接: D - 1D Country (atcoder.jp) 题目描述: 数据范围: 输入输出: 题目分析: 典型的l, r 区间问题,即是前缀和问题,但是注意到数据范围, 数据范围1e-9 到 1e9 数据范围,要是从最小到最大直接for循环去模拟的话,时间复杂度…...
怎么很多张图片拼接成一张?试试这几种图片拼接方法!
怎么很多张图片拼接成一张?在繁忙的现代生活中,我们不断地捕捉和累积着各式各样的图像,它们如同记忆的珍珠,串联起生活的每一个瞬间,然而,随图片数量的激增,管理它们成为了一项挑战,…...

Python实现优化的分水岭算法
目录 优化分水岭算法的博客1. 分水岭算法优化概述2. 优化分水岭算法的步骤3. Python实现优化后的分水岭算法4. 实例:优化分水岭算法在图像分割中的应用5. 总结 优化分水岭算法的博客 分水岭算法是一种强大的图像分割方法,特别适用于分离不同的对象和区域…...

如何用Python爬虫将知识星球内容制作成PDF电子书:完整指南
如何用Python爬虫将知识星球内容制作成PDF电子书:完整指南 【免费下载链接】zsxq-spider 爬取知识星球内容,并制作 PDF 电子书。 项目地址: https://gitcode.com/gh_mirrors/zs/zsxq-spider 知识星球作为优质内容社区,汇集了大量付费专…...

手把手教你用三菱FX3U PLC的RS指令和RS2指令与电脑串口调试助手‘对话’
三菱FX3U PLC串口通信实战:从零搭建RS485数据收发系统 第一次接触工业控制系统的串口通信时,我被那些密密麻麻的接线和晦涩的协议参数弄得晕头转向。直到在自动化生产线上亲眼看到PLC通过两根电线与十几台设备稳定通信,才意识到串口技术的精妙…...

3个高效方法:免费获取百度网盘高速下载直链的完整指南
3个高效方法:免费获取百度网盘高速下载直链的完整指南 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 当我们面对百度网盘缓慢的下载速度时,常常感到无…...

UEFITool终极指南:轻松解析和编辑UEFI固件的开源利器
UEFITool终极指南:轻松解析和编辑UEFI固件的开源利器 【免费下载链接】UEFITool UEFI firmware image viewer and editor 项目地址: https://gitcode.com/gh_mirrors/ue/UEFITool 你是否曾好奇计算机启动时底层发生了什么?想要深入了解UEFI固件的…...

Python与ChatGPT构建智能办公自动化:从任务分解到智能体系统
1. 项目概述:用Python与ChatGPT联手,让办公自动化“开口说话”如果你每天还在重复着打开Excel、复制粘贴数据、手动写邮件、整理报告这些枯燥的活儿,那这个项目可能就是你的“数字员工”入职通知书。Sven-Bo/automate-office-tasks-using-cha…...

Windows Cleaner终极指南:三步告别C盘爆红,让电脑运行如飞!
Windows Cleaner终极指南:三步告别C盘爆红,让电脑运行如飞! 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 还在为Windows系统…...

Arm Morello平台模型与CHERI安全扩展开发指南
1. Arm Morello平台模型概述Morello是Arm公司推出的实验性处理器架构,基于CHERI(Capability Hardware Enhanced RISC Instructions)安全扩展技术。这个平台模型本质上是一个功能准确的虚拟硬件环境,允许开发者在物理芯片问世前18-…...

Seraphine终极指南:英雄联盟智能助手如何提升您的游戏胜率
Seraphine终极指南:英雄联盟智能助手如何提升您的游戏胜率 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine 在英雄联盟的激烈对局中,错过对局接受、BP阶段犹豫不决、缺乏队友对手信息&a…...

WipperSnapper+Adafruit IO:无代码物联网开发实战,从传感器到云端自动化
1. 项目概述与核心价值如果你和我一样,在物联网(IoT)项目初期,常常被复杂的嵌入式编程、网络协议和云平台对接搞得焦头烂额,那么今天分享的这个实战项目,或许能让你眼前一亮。我们这次不谈复杂的代码&#…...

Claude API钩子框架设计:非侵入式中间件与生命周期管理实践
1. 项目概述与核心价值最近在折腾一些AI应用开发,发现一个挺有意思的现象:很多开发者想给Claude API的调用过程加点“料”,比如在请求发出前或收到响应后,自动执行一些自定义逻辑。可能是为了日志记录、数据清洗、请求重试&#x…...