MySql基础-单表操作
1. MYSQL概述
1.1 数据模型
关系型数据库
关系型数据库(RDBMS):建立在关系模型基础上,由多张相互连接的二维表组成的数据库。
特点:
使用表存储数据,格式统一,便于维护
使用SQL语言操作,标准统一,使用方便,可用于复杂查询
MYSQL数据模型

1.2 SQL简介
SQL:一门操作关系型数据库的编程语言,定义操作所有关系型数据库的统一标准。
通用语法:
SQL语句可以单号或多行书写,以分号结尾。
SQL语句可以使用空格/缩进来增强语句的可读性。
MYSQL数据库的SQL语句不区分大小写。
注释:
1. 单行注释:-- 注释内容 或 # 注释内容(MYSQL特有)
2. 多行注释:/* 注释内容 */
SQL分类
| 分类 | 全称 | 说明 |
|---|---|---|
| DDL | Data Definiton Language | 数据定义语言,用来定义数据库对象(数据库,表,字段) |
| DML | Data Manipulation Language | 数据操作语言,用来对数据库表中的数据进行增删改 |
| DQL | Data Query Language | 数据查询语言,用来查询数据库中表的记录 |
| DCL | Data Control Language | 数据控制语言,用来创建数据库用户、控制数据库的访问权限 |
2. 数据库设计
2.1 DDL
DDL 英文全称是 Data Definition Language,数据定义语言,用来定义数据库对象(数据库、表)。
2.1.1 数据库操作
查询
查询所有数据库:show databases;
查询当前数据库:select database();
创建
创建数据库:create database [if not exists] 数据库名;
使用
使用数据库:use 数据库名;
创建
创建数据库:create database [if not exists] 数据库名;
删除
删除数据库:drop database [if exists] 数据库名;
注意: 上述语法中的database ,也可以替换称schema。如:create schema db01;
MYSQL客户端工具 - 图形化工具
DataGrip
介绍:DataGrip 是JetBrains 旗下的一款数据库管理工具,是管理和开发MySQL、Oracle、PostgreSQL 的理想解决方案。
官网:DataGrip: The Cross-Platform IDE for Databases & SQL by JetBrains
2.1.2 表的操作(创建、查询、修改、删除)
创建

create table tb_user (id int comment 'ID, 唯一标识',username varchar(20) comment '用户名',name varchar(10) comment '姓名',age int comment '年龄',gender char(1) comment '性别'
) comment '用户表';约束
概念:约束是作用于表中字段上的规则,用于限制存储在表中的数据。
目的:保证数据库中数据的正确性、有效性和完整性。
| 约束 | 描述 | 关键字 |
|---|---|---|
| 非空约束 | 限制该字段值不能为null | not null |
| 唯一约束 | 保证字段的所有数据都是唯一、不重复的 | unique |
| 主键约束 | 主键是一行数据的唯一标识,要求非空且唯一 | primary key(auto_increment自增) |
| 默认约束 | 保存数据时,如果未指定该字段值,则采用默认值 | default |
| 外键约束 | 让两张表的数据建立连接,保证数据的一致性和完整性 | foreign key |
create table tb_user (id int primary key auto_increment comment 'ID,唯一标识',username varchar(20) not null unique comment '用户名',name varchar(10) not null comment '姓名',age int comment '年龄',gender char(1) default '男' comment '性别'
) comment '用户表';数值类型

查询
查询当前数据库所有表: show tables;
查询表结构:desc 表名;
查询建表语句:show create table 表名;
修改
添加字段:alter table 表名 add 字段名 类型(长度) [comment 注释] [约束];
修改字段类型:alter table 表名 modify 字段名 新数据类型(长度);
修改字段名和字段类型:alter table 表名 change 旧字段名 新字段名 类型(长度) [comment 注释] [约束];
删除字段:alter table 表名 drop column 字段名;
修改表名:rename table 表名 to 新表名;
删除
删除表:drop table [if exists] 表名;
2.2 DML
DML 英文全称是Data Manipulation Language(数据操作语言),用来对数据库中表的数据记录惊醒增、删、改操作。
添加数据(INSERT)
指定字段添加数据:insert into 表名(字段名1,字段名2) values(值1,值2);
全部字段添加数据:insert into 表名 values (值1,值2...);
批量添加数据(指定字段): insert into 表名 (字段名1,字段名2) values (值1,值2),(值1,值2);
批量添加数据(全部字段):insert into 表名 values(值1,值2...),(值1,值2...);
注意事项:
1. 插入数据时,指定的字段顺序需要与值的顺序是一一对应的。
2. 字符串和日期型数据应该包括在引号中。
3. 插入的数据大小,应该在字段的规定范围内。
修改数据(UPDATE)
Update 语法
修改数据:update 表名 set 字段名1 = 值1,字段名2 = 值2,.......[where 条件];
注意事项
修改语句的条件可以有,也可以没有,如果没有条件,则会修改整张表的所有数据。
删除数据(DELETE)
delete语法
删除数据:delete from 表名 [where 条件];
注意事项
1. DELETE 语句的条件可以有,也可以没有,如果没有条件,则会删除整张表的所有数据。
2. DELETE 语句不能删除某一个字段的值(如果要操作,可以使用UPDATE,将该字段的值置为NULL)。
2.2DQL
DQL英文全称是Data Query Language (数据查询语言),用来查询数据库表中的记录。
关键字:SELECT
语法

DQL-基本查询
查询多个字段:select 字段1,字段2,字段3 from 表名;
查询所有字段(通配符):select * from 表名;
设置别名:select 字段1 [as 别名1],字段2 [as 别名2] from 表名;
去除重复记录:select distinct 字段列表 from 表名;
注意
* 号代表查询所有字段,在实际开发中尽量少用(不直观、影响效率)。
-- 查询指定字段 name,entrydate 并返回
select name as 姓名,entrydate as 入职日期
from tb_emp;
-- 查询返回所有字段
-- 推荐
select id, username, password, name, gender, image, job, entrydate, create_time, update_time
from tb_emp;
-- 不推荐(不直观,性能低)
select *
from tb_emp;
-- 查询所有员工的 name,entrydate,并起别名(姓名,入职日期);
select name as 姓名,entrydate as 入职日期
from tb_emp;
select name as '姓 名',entrydate as 入职日期
from tb_emp;
-- 查询已有的员工关联了哪些职位(不重复)
select distinct job
from tb_emp;DQL-条件查询
select 字段列表 from 表名 where 条件列表;


-- =====================================DQL:条件查询 ===============================
-- 1. 查询姓名为 杨逍 的员工
select id, username, password, name, gender, image, job, entrydate, create_time, update_time
from tb_emp where name = '杨逍';
-- 2. 查询 id小于等于5的员工信息
select *
from tb_emp where id <= 5;
-- 3. 查询没有分配职位的员工信息
select *
from tb_emp where job is null;
-- 4. 查询有职位的员工信息
select *
from tb_emp where job is not null;
-- 5. 查询密码不等于'123456' 的员工信息
select *
from tb_emp where password != 123456;
-- 6. 查询入职日期在 '2000-01-01' (包含) 到 '2010-01-01'(包含)之间的员工信息
select *
from tb_emp where entrydate >= '2000-01-01' && entrydate <= '2010-01-01';select *
from tb_emp where entrydate between '2000-01-01' and '2010-01-01';
-- 7. 查询入职日期在 '2000-01-01' (包含) 到 '2010-01-01'(包含)之间 且性别为女的员工信息
select *
from tb_emp where entrydate >= '2000-01-01' && entrydate <= '2010-01-01' && gender = 2;
-- 8. 查询 职位是 2(讲师),3 (学工主管),4 (教研助管) 的员工信息
select *
from tb_emp where job in (1,2,3);
-- 9. 查询姓名为两个字的员工信息
select *
from tb_emp where name like '__';
-- 10. 查询 姓'张'的员工信息
select *
from tb_emp where name like '张%';DQL-聚合函数
语法:select 聚合函数(字段列表) from 表名;
聚合函数:将一列数据作为一个整体,进行纵向计算。
| 函数 | 功能 |
|---|---|
| count | 统计数量 |
| max | 最大值 |
| min | 最小值 |
| avg | 平均值 |
| sum | 求和 |
注意事项
null 值不参与所有聚合函数运算。
统计数量可以使用:count(*) count(字段) count(常量) 推荐使用 count(*)。
-- =========================== 聚合函数 ===============================
-- 聚合函数
-- 1. 统计该企业员工数量
-- A. count(字段) 不对null 值进行运算
select count(*) as 员工数量
from tb_emp;
-- B. count(常量)
select count(1)
from tb_emp;
-- C. count(*)
select count(*)
from tb_emp;
-- 2. 统计该企业最早入职的员工
select min(entrydate)
from tb_emp;
-- 3. 统计该企业最迟入职的员工 - max
select max(entrydate)
from tb_emp;
-- 4. 统计该企业员工ID的平均值
select avg(id)
from tb_emp;
-- 5. 统计该企业员工的 ID 之和
select sum(id)
from tb_emp;DQL - 分组查询
语法:
select 字段列表 from 表名 [where 条件] group by 分组字段名 [having 分组后过滤条件];
where 与 having 区别
1. 执行时机不同:where是分组之前进行过滤,不满足where条件,不参与分组;而having是分组之后对结果进行过滤。
2. 判断条件不同:where不能对聚合函数进行判断,而having可以。
-- 分组
-- 1. 根据性别分组,统计男性和女性员工的数量 - count
select gender,count(*)
from tb_emp group by gender;
-- 2. 先查询入职时间在'2015-01-01'(包含)以前的员工,并对结果根据职位分组,获取员工数量大于等于2的职位
select job,count(*)
from tb_emp where entrydate < '2015-01-01' group by job having count(*) >= 2;DQL-排序查询
条件查询:select 字段列表 from 表名 [where 条件列表][group by 分组字段] order by 字段1 排序方式1,字段2 排序方式2...;
排序方式:
ASC:升序(默认值)
DESC:降序
注意事项
如果是多字段排序,当第一个字段值相同时,才会根据第二个字段进行排序。
-- 排序查询
-- 1. 根据入职时间,对员工进行升序排序 - asc
select *
from tb_emp order by entrydate asc ;
-- 2. 根据入职时间,对员工进行降序排序
select *
from tb_emp order by entrydate desc ;
-- 3. 根据入职时间 对公司的员工进行 升序排序, 入职时间相同,再按照 更新时间,进行降序排序
select *
from tb_emp order by entrydate asc ,update_time desc ;DQL-分页查询
语法
select 字段列表 from 表名 limit 起始索引,查询记录数;
注意事项
1. 起始索引从0开始,起始索引 = (查询页码 - 1) * 每页显示记录数
2. 分页查询是数据库的方言,不同的数据库有不同的实现,MYSQL中是LIMIT。
3. 如果查询的是第一页数据,起始索引可以省略,直接简写为limit 10。
-- 分页查询
-- 1. 从 起始 索引0 开始查询员工数据,每页展示5条记录
select *
from tb_emp limit 0,5;
-- 2. 查询 第1页 员工数据,每页展示5条记录
select *
from tb_emp limit 0,5;
-- 3. 查询 第2页 员工数据,每页展示5条数据
select *
from tb_emp limit 5,5;
-- 4. 查询 第三页
select *
from tb_emp limit 10,5;函数:
if(表达式,tvalue,fvalue):当表达式为true时,取值tvalue,当表达式为false时,取值fvalue
case expr when value1 then result1 [when value2 then value2 ...][else result]end;
综合练习
-- 实例1:按需求完成员工管理的条件分页查询 - 根据输入条件,查询第一页数据,每页展示10条数据
-- 输入条件
-- 姓名:张
-- 性别:男
-- 入职时间:2000-01-01 2015-12-31
-- 根据输入的员工姓名、员工性别、入职时间 搜索满足条件的员工信息
-- 其中员工姓名支持模糊匹配;性别进行精确查询,入职时间进行范围查询
-- 支持分页查询
-- 并对查询的结果,根据最后修改时间进行倒序排序
select *
from tb_emp where name like '%张%' and gender = 1 and entrydate between '2000-01-01' and '2015-12-31' order by entrydate desc ;
-- 实例2:根据需求,完成员工性别信息的统计 -count(*)
-- if(表达式,true取值,false取值)
select if(gender = 1,'男性员工','女性员工') 性别,count(*) 员工数量
from tb_emp group by gender;
-- 实例3:case 表达式 when 值1 then 结果1 when 值2 then 结果2 ... else ... end
select case job when 1 then '班主任' when 2 then '讲师' when 3 then '学工主管' when 4 then '教研助管' else '未分配职位' end 职位,count(*)
from tb_emp group by job;小结

相关文章:
MySql基础-单表操作
1. MYSQL概述 1.1 数据模型 关系型数据库 关系型数据库(RDBMS):建立在关系模型基础上,由多张相互连接的二维表组成的数据库。 特点: 使用表存储数据,格式统一,便于维护 使用SQL语言操作,标准统一&…...

【STM32系统】基于STM32设计的SD卡数据读取与上位机显示系统(SDIO接口驱动、雷龙SD卡)——文末资料下载
基于STM32设计的SD卡数据读取与上位机显示系统 演示视频: 基于STM32设计的SD卡数据读取与上位机显示系统 简介:本研究的主要目的是基于STM32F103微控制器,设计一个能够读取SD卡数据并显示到上位机的系统。SD卡的数据扇区读取不仅是为了验证存…...

SpringBoot开发——整合Redis
文章目录 1、创建项目,添加Redis依赖2、创建实体类Student3、创建Controller4、配置application.yml5、整合完成 Redis ( Remote Dictionary Server )是一个开源的内存数据库,遵守 BSD 协议,它提供了一个高性能的键值(…...
判断轮廓是否为凸多边形的函数isContourConvex()的使用)
OpenCV结构分析与形状描述符(17)判断轮廓是否为凸多边形的函数isContourConvex()的使用
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 测试轮廓的凸性。 该函数测试输入的轮廓是否为凸的。轮廓必须是简单的,即没有自相交。否则,函数的输出是不确定的。 cv:…...
P5425 [USACO19OPEN] I Would Walk 500 Miles G
*原题链接* 很离谱的题。首先可以想到暴力连边,整个图为一个完全图,将所有的边选出来,然后从小到大一条条加入,当剩下集合数量 <K 的时候就结束。答案为加入的最后一条边的大小。如果用prim算法的话时间复杂度为。足以通过此题…...

Java高级Day41-反射入门
115.反射 反射机制 1.根据配置文件re.properties指定信息,创建Cat对象并调用hi方法 SuppressWarnings({"all"}) public class ReflectionQuestion {public static void main(String[] args) throws IOException {//根据配置文件 re.properties 指定信息…...

在Linux系统上使用Docker部署java项目
一.使用Docker部署的好处: 在Linux系统上使用Docker部署项目通常会大大简化部署流程,因为Docker可以将应用程序及其依赖打包到一个独立的容器中。 Docker打包应用程序时会将其与所有依赖项(操作系统、库等)一起打包。这样&#…...

【C++】标准库IO查漏补缺
【C】标准库 IO 查漏补缺 文章目录 系统I/O1. 概述2. cout 与 cerr3. cerr 和 clog4. 缓冲区5. 与 printf 的比较 系统I/O 1. 概述 标准库提供的 IO 接口,包含在 iostream 文件中 输入流: cin输出流:cout / cerr / clog。 输入流只有一个 cin&#x…...

python简单易懂的lxml读取HTML节点及常用操作方法
python简单易懂的lxml读取HTML节点及常用操作方法 1. 初始化和基本概念 lxml 是一个强大的pyth库,用于处理XML和HTML文档。它提供了类似BeautifulSoup的功能,但性能更高。在使用lxml时,通常会先解析HTML或XML文档,得到一个Eleme…...

Java | Leetcode Java题解之第406题根据身高重建队列
题目: 题解: class Solution {public int[][] reconstructQueue(int[][] people) {Arrays.sort(people, new Comparator<int[]>() {public int compare(int[] person1, int[] person2) {if (person1[0] ! person2[0]) {return person2[0] - perso…...

安卓获取apk的公钥,用于申请app备案等
要申请app的icp备案等场景,需要app的 证书MD5指纹和公钥,示例如下: 步骤1:使用keytool从APK中提取证书 1. 打开命令行,cd 到你的apk目录,如:app/release 2. 解压APK文件: unzip yo…...
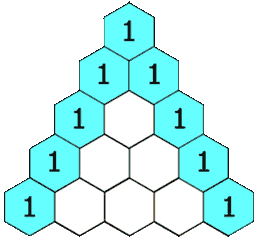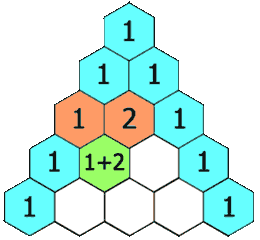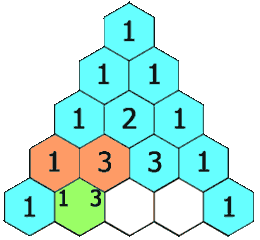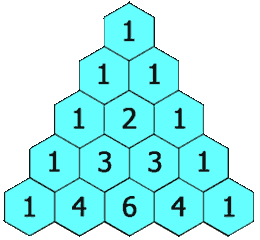
【leetcode_python】杨辉三角
给定一个非负整数 numRows,生成「杨辉三角」的前 numRows 行。 在「杨辉三角」中,每个数是它左上方和右上方的数的和。 示例 1: 输入: numRows 5 输出: [[1],[1,1],[1,2,1],[1,3,3,1],[1,4,6,4,1]]示例 2: 输入: numRows 1 输出: [[1]] 方案&#…...

Parallels Desktop 20 for Mac中文版发布了?会哪些新功能
Parallels Desktop 20 for Mac 正式发布,完全支持 macOS Sequoia 和 Windows 11 24H2,并且在企业版中引入了全新的管理门户。 据介绍,新版本针对 Windows、macOS 和 Linux 虚拟机进行了大量更新,最大的亮点是全新推出的 Parallels…...

SpringBoot整合SSE-灵活管控连接
SpringBoot整合SSE(管控连接) 1、sse单向通信整成逻辑双向通信。 2、轻量级实现端对端信息互通。 3、避免繁琐配置学习。 核心点通过记录连接码和心跳检测实现伪双向通道,避免无效连接占用过多内存。 服务器推送(Server Push)技术允许网站和应用在有新内容可用时主动向用户…...

挖矿木马-Linux
目录 介绍步骤 介绍 1、挖矿木马靶机中切换至root用户执行/root目录下的start.sh和attack.sh 2、题目服务器中包含两个应用场景,redis服务和hpMyAdmin服务,黑客分别通过两场景进行入侵,入侵与后续利用线路路如下: redis服务&…...

【leetcode——415场周赛】——python前两题
3289. 数字小镇中的捣蛋鬼 数字小镇 Digitville 中,存在一个数字列表 nums,其中包含从 0 到 n - 1 的整数。每个数字本应 只出现一次,然而,有 两个 顽皮的数字额外多出现了一次,使得列表变得比正常情况下更长。 为了…...

【CSS in Depth 2 精译_029】5.2 Grid 网格布局中的网格结构剖析(上)
当前内容所在位置(可进入专栏查看其他译好的章节内容) 第一章 层叠、优先级与继承(已完结) 1.1 层叠1.2 继承1.3 特殊值1.4 简写属性1.5 CSS 渐进式增强技术1.6 本章小结 第二章 相对单位(已完结) 2.1 相对…...
 TCP函数学习)
ZYNQ LWIP(RAW API) TCP函数学习
1 LWIP TCP函数学习 tcp_new()–新建控制块 这个函数用于分配一个TCP控制块,它通过tcp_alloc()函数分配一个TCP控制块结构来存储TCP控制块的数据信息, 如果没有足够的内容分配空间,那么tcp_alloc()函数就会尝试释放一些不太重要的TCP控制块, 比如就会释放处于TIME_WAIT、C…...

Spring Boot,在应用程序启动后执行某些 SQL 语句
在 Spring Boot 中,如果你想在应用程序启动后执行某些 SQL 语句,可以利用 spring.sql.init 属性来配置初始化脚本。这通常用于在应用启动时创建数据库表、索引、视图等,或者填充默认数据。data-locations 和 schema-locations 指定了 SQL 脚本…...

【SQL】百题计划:SQL最基本的判断和查询。
[SQL]百题计划 Select product_id from Products where low_fats "Y" and recyclable "Y";...

贪吃蛇游戏开发实战:从基础架构到错误监控与性能优化
1. 项目概述:一个“会说话”的贪吃蛇游戏最近在GitHub上看到一个挺有意思的项目,叫“BugSplat-Git/snake-game”。初看标题,你可能觉得这不就是个经典的贪吃蛇游戏吗?从诺基亚时代玩到现在的玩意儿,还能有什么新花样&a…...

AI智能体安全沙箱agentguard:为LLM代码执行筑起防火墙
1. 项目概述与核心价值 最近在开源社区里,一个名为 A386official/agentguard 的项目引起了我的注意。乍一看这个标题,你可能会联想到网络安全、代理防护或者某种守护进程。没错,这个项目正是为了解决一个在AI应用开发,特别是基于…...

Windows驱动管理专业解决方案:Driver Store Explorer完全指南
Windows驱动管理专业解决方案:Driver Store Explorer完全指南 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer Driver Store Explorer(简称Rapr)是一款…...

ncmdump终极指南:3步快速解锁网易云音乐NCM加密文件的完整免费解决方案
ncmdump终极指南:3步快速解锁网易云音乐NCM加密文件的完整免费解决方案 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为网易云音乐下载的歌曲只能在特定客户端播放而烦恼吗?ncmdump这款强大的NCM解密工…...
、GELU激活函数与数据预处理那些事儿)
BERT PyTorch实现避坑指南:torch.gather()、GELU激活函数与数据预处理那些事儿
BERT PyTorch实现避坑指南:torch.gather()、GELU激活函数与数据预处理那些事儿 当你第一次尝试在PyTorch中实现BERT模型时,可能会遇到一些令人困惑的技术细节。本文将从实际调试的角度,深入解析三个最容易卡住开发者的关键点:torc…...

国货视光标杆|欧普康视企业实力与DreamVision SL巩膜镜产品详解
一、企业简介欧普康视科技股份有限公司成立于2000年,由留美工程博士陶悦群创立,是国内深耕眼视光医疗器械领域的高新技术企业。企业专注于眼视光产品的自主研发、智能化生产与合规销售,同时配套全周期专业化眼健康服务,业务覆盖屈…...


用Monster M4SK打造可穿戴互动眼睛:从硬件拆解到凯皮帽子制作
1. 项目概述:当马里奥的帽子“活”了过来如果你和我一样,既是任天堂游戏的粉丝,又对嵌入式硬件和可穿戴设备着迷,那么把游戏里的角色带到现实中来,绝对是一件充满乐趣的事。这次我们要“复活”的,是《超级马…...

FPGA开发板GT远端环回测试:原理、配置与调试实战指南
1. 项目概述:为什么我们需要在开发板上做GT远端环回测试?如果你是一位硬件工程师或者FPGA开发者,最近正在调试一块带有高速串行收发器(比如Xilinx的GTX/GTH/GTY,或者Intel的Transceiver)的开发板࿰…...
AIGC面试指南:从Transformer到扩散模型,系统掌握核心技术与实战
1. 项目概述:一本面向AIGC求职者的实战指南最近几年,AI生成内容(AIGC)领域的热度可以说是“肉眼可见”地飙升。从文本生成、图像创作到视频合成,相关岗位如雨后春笋般涌现,吸引了大量开发者和研究者的目光。…...