计算机人工智能前沿进展-大语言模型方向-2024-09-13
计算机人工智能前沿进展-大语言模型方向-2024-09-13
1. OneEdit: A Neural-Symbolic Collaboratively Knowledge Editing System
Authors: Ningyu Zhang, Zekun Xi, Yujie Luo, Peng Wang, Bozhong Tian, Yunzhi
Yao, Jintian Zhang, Shumin Deng, Mengshu Sun, Lei Liang, Zhiqiang Zhang,
Xiaowei Zhu, Jun Zhou, Huajun Chen
摘要
- 文章介绍了一个名为OneEdit的神经符号协作知识编辑系统。该系统结合了符号知识图谱(KGs)和大型语言模型(LLMs)来表示知识。OneEdit通过自然语言促进了对KG和LLM的轻松管理,包括三个主要模块:解释器(Interpreter)、控制器(Controller)和编辑器(Editor)。解释器负责理解用户意图,控制器管理来自不同用户的编辑请求并使用KG解决知识冲突,编辑器则利用控制器提供的知识来编辑KG和LLM。实验结果表明,OneEdit在处理知识冲突方面表现优异。

算法模型
OneEdit系统设计包括三个主要组件:
- 解释器(Interpreter):作为用户与控制器之间的接口,负责识别用户用自然语言表达的意图。
- 控制器(Controller):管理来自不同用户的编辑请求,使用KG解决冲突并增强知识。
- 编辑器(Editor):主要使用控制器增强的知识三元组来编辑KG和LLM。
系统通过存储每次知识编辑后的编辑参数,采用空间换时间的策略,显著减少了VRAM和时间开销。
实验效果
实验在两个新的数据集上进行,一个关注美国政治人物,另一个关注学术人物,两者都包含KG。结果表明,OneEdit在使用Qwen2-7B和GPT-J-6B模型时,能够实现神经符号协作知识编辑,并在处理知识冲突问题上超越了基线方法。
2. NSP: A Neuro-Symbolic Natural Language Navigational Planner
Authors: William English, Dominic Simon, Rickard Ewetz and Sumit Jha
摘要
本文提出了一个名为NSP的神经符号自然语言导航规划框架,该框架利用大型语言模型(LLMs)的神经推理能力来解析自然语言输入,并将其转换为符号表示的环境和路径规划算法。通过在符号执行环境和神经生成过程之间建立反馈循环,NSP能够自我修正语法错误并满足执行时间约束。在1500个路径规划问题的基准测试套件上的实验评估表明,NSP方法产生的有效路径比例为90.1%,且这些路径平均比最先进的神经方法短19-77%。

创新点
- 提出了一种神经符号方法来解决自由形式自然语言中的路径规划问题,该方法利用了符号方法的优势,同时避免了预定义符号表示的需要。
- 引入了从执行环境到神经生成过程的神经符号反馈循环,能够解决由LLM生成的幻觉和语法错误,显著提高了自然语言到符号翻译的鲁棒性。
- 使用1500个自然语言路径规划场景数据集评估了所提出的方法,与基于最新LLM的方法相比,NSP框架将有效路径成功率提高了最多76%。
算法模型
NSP框架包括以下主要组件:
- 神经符号翻译:使用LLM将自然语言输入转换为符号表示,包括环境的图表示和路径规划算法。
- 神经符号规划与反馈:执行算法以产生解决方案路径,如果遇到编译错误或执行超时,则通过反馈循环进行自我修正。
实验效果
- 在包含5至25个房间的路径规划场景中,NSP在成功率、最优路径率和路径效率方面均优于基线方法。
- NSP在最少反馈循环迭代次数下实现了高成功率,平均每次输入仅需执行1.82次反馈循环。
- 在处理更复杂的路径规划问题时,NSP保持了高效率,即使在房间数量增加时,其性能下降幅度也远小于其他方法。
综上所述,NSP通过结合神经推理和符号验证,有效地解决了自然语言路径规划问题,并在多个评估指标上展现了其优越性。
3. Explanation, Debate, Align: A Weak-to-Strong Framework for Language Model Generalization
Authors: Mehrdad Zakershahrak, Samira Ghodratnama
解释、辩论、对齐:一种用于语言模型泛化的弱到强框架
摘要
这篇文章探讨了人工智能系统快速发展带来的AI对齐挑战,特别是在复杂决策和任务执行中。随着这些系统在复杂问题上超越人类水平的表现,确保它们与人类价值观、意图和道德准则的对齐变得至关重要。文章基于先前在解释生成方面的工作,提出了一种新的方法,通过弱到强的泛化来实现模型对齐。该方法通过一个促进函数Φ,允许从高级模型向能力较弱的模型转移能力,而无需直接访问大量的训练数据。研究结果表明,这种基于促进的方法不仅提高了模型性能,还为模型对齐的本质和对高级AI系统的可扩展监督提供了洞见。
创新点
- 弱到强泛化框架:提出了一种新的模型对齐方法,通过弱模型促进强模型的提升,弥合了解释生成和模型对齐之间的差距。
- 促进函数Φ:定义了一个形式化的促进函数,用于实现从强模型到弱模型的知识转移。
- 辩论式对齐:引入了辩论机制来增强模型对齐和能力,通过评估不同模型提供的解释来改进模型对齐。
- 可扩展的监督:该方法提供了一种机制,可以在人类专家难以提供准确反馈的领域中实现对齐,同时保持与人类价值观的一致性。
算法模型
- 弱模型(MW):在给定任务和性能指标下,得分低于人类水平的模型。
- 强模型(MS):在相同任务和性能指标下,得分高于人类水平的模型。
- 促进函数Φ:通过优化问题实现,将强模型的能力转移到弱模型。
- 辩论函数D:评估强模型和弱模型提供的解释的质量,并由裁判(可以是另一个弱模型、人类或其他评估机制)评定。
- 对齐函数Ψ:通过优化问题实现,调整强模型以最小化决策差异并改进解释。
实验效果
- 性能提升:通过促进方法在多个复杂任务领域实现了模型性能和对齐的显著提升。
- 可扩展性:展示了该方法在不同任务和模型规模上的可扩展性和局限性。
- 统计显著性:通过配对t检验验证了不同方法的性能,证明了改进方法相对于基线方法的统计显著性。
- 错误分析:通过详细分析强学生模型的错误案例,识别了常见的错误类型,并提出了改进方向。
这篇文章通过实验验证了弱到强泛化在语言模型对齐中的有效性,并展示了如何通过促进和辩论式学习来提高模型性能和对齐度。尽管存在挑战,但这项工作为未来在AI对齐和安全方面的研究提供了坚实的基础。
4. SUPER: Evaluating Agents on Setting Up and Executing Tasks from Research
Authors: Ben Bogin, Kejuan Yang, Shashank Gupta, Kyle Richardson, Erin Bransom,
Peter Clark, Ashish Sabharwal, Tushar Khot
SUPER:评估智能体在设置和执行研究库中任务的能力
摘要
文章介绍了SUPER,这是首个旨在评估大型语言模型(LLMs)在设置和执行研究库中任务的能力的基准测试。SUPER旨在捕捉研究人员在机器学习和自然语言处理研究库中所面临的现实挑战。基准测试包括三个不同的问题集:45个端到端问题配有专家解决方案,152个从专家集中派生的子问题,专注于特定挑战(例如配置训练器),以及604个自动生成的问题用于更大规模的开发。研究者引入了各种评估措施来评估任务的成功和进展,并展示了现有最先进方法在解决这些问题上的挑战,最好的模型(GPT-4o)仅解决了16.3%的端到端问题集,以及46.1%的场景。这表明了任务的挑战性,并暗示SUPER可以作为社区衡量进展的有价值资源。

创新点
- 首个基准测试:SUPER是首个评估LLMs在设置和执行研究库任务中的能力的基准测试。
- 问题集设计:包括端到端问题、专注于特定挑战的子问题,以及自动生成的问题,全面覆盖了研究任务的不同方面。
- 评估措施:引入了多种评估措施,包括任务成功和进展的评估,利用专家解决方案或近似值进行评估。
- 实际应用导向:基准测试的设计紧密贴合研究人员在实际工作中可能遇到的挑战,强调了模型在实际应用中的有效性和可行性。
算法模型
- 问题集构成:包括专家手动编写的问题集、通过“代码掩蔽”机制从专家集中提取的子问题集,以及自动生成的问题集。
- 评估方法:对于有专家解决方案的问题集,通过比较智能体的答案与专家答案进行评估;对于自动生成的问题集,使用脚本执行成功与否作为代理评估指标。
- 环境设置:构建了一个允许运行系统shell命令和有状态Python命令的环境,以Jupyter笔记本为引擎。
实验效果
- 性能数据:在端到端问题集上,最好的模型(GPT-4o)仅解决了16.3%的问题,而在所有场景中解决了46.1%的问题。
- 子问题解决率:在子问题集上,SWE-Agent模型正确解决了46.1%的挑战,但大多数子问题仍未解决。
- 自动生成问题集:在自动生成的问题集上,模型和智能体的排名与在子问题集上的排名大体一致,表明该集可能对未来发展有用。
- 错误分析:智能体在解决具体错误消息的子问题(如CPU支持错误、不兼容依赖或异常)方面表现更好,而在更开放的问题(如为自定义数据集配置数据加载)方面表现较差。

结论
SUPER基准测试证明了即使是当前最好的商业LLMs,如GPT4,在执行研究库任务方面也面临挑战。基准测试揭示了构建自主LLMs执行代理的核心挑战,如仓库推理和代码编辑,希望这些发现能帮助社区在这一重要问题上取得可衡量的进展。
5. “My Grade is Wrong!”: A Contestable AI Framework for Interactive Feedback in Evaluating Student Essays
Authors: Shengxin Hong, Chang Cai, Sixuan Du, Haiyue Feng, Siyuan Liu, Xiuyi
文章标题翻译
文章标题:“My Grade is Wrong!”: A Contestable AI Framework for Interactive Feedback in Evaluating Student Essays
“我的分数错了!”:一个用于评估学生论文的可争议的人工智能框架,用于交互式反馈
摘要
文章介绍了CAELF(Contestable AI Empowered LLM Framework),这是一个用于自动化交互式反馈的框架,通过整合多智能体系统和计算论证来允许学生查询、挑战和澄清他们的反馈。论文首先由多个助教智能体(TA Agents)评估,然后教师智能体通过形式化推理生成反馈和成绩。学生可以进一步与反馈互动以完善他们的理解。通过对500篇批判性思维论文的案例研究和用户研究,证明了CAELF显著改善了交互式反馈,增强了LLMs的推理和交互能力。这种方法为克服在教育环境中限制交互式反馈采用的时间和资源障碍提供了有希望的解决方案。
创新点
- 交互式反馈:提出了一个允许学生对反馈进行查询和挑战的框架,增加了反馈的互动性。
- 多智能体系统:通过多智能体之间的讨论和辩论来提高评估的准确性和全面性。
- 计算论证:利用计算论证的形式化推理来生成反馈,提高了评估的透明度和可解释性。
- 可争议的AI:框架支持用户对AI的评估结果提出质疑和讨论,使AI的决策过程更加透明和可验证。
算法模型
- LLM讨论:多个TA智能体根据评估标准对论文进行讨论,形成论证。
- 形式化推理:教师智能体通过计算论证分析TA智能体的论证,使用完整的语义学来确定论文的评分和生成总结反馈。
- 用户交互:学生可以对教师智能体生成的反馈提出挑战,启动新一轮的讨论和反馈生成。
实验效果
- 初始准确性:CAELF与GPT-4o在初始评分准确性方面相当。
- 交互准确性:在与学生的一轮互动后,CAELF的准确性显著优于基线模型。
- 保持真理:CAELF在保持正确评估方面的成功率为80%-90%,而基线模型的成功率低于40%。
- 承认错误:CAELF在纠正初始错误的成功率上比基线模型高出10%-20%。
- 人类评估:CAELF在可读性、事实准确性、自我调节和未来改进等反馈质量方面均优于基线模型。
结论
CAELF通过结合多智能体辩论和计算论证,有效地提高了LLM在教育环境中提供交互式反馈的能力。实验结果表明,CAELF在初始评分准确性、交互评分准确性以及推理和一致性维护方面均优于现有技术。此外,人类评估结果也证实了CAELF在提供高质量反馈方面的有效性。这项工作展示了CAELF在交互式学习环境中的应用潜力,为解决传统教育中交互式反馈的局限提供了新的思路。
6. What is the Role of Small Models in the LLM Era: A Survey
Authors: Lihu Chen and Ga"el Varoquaux
综述: 在大型语言模型时代,小型模型的角色是什么?
摘要
随着大型语言模型(LLMs)在推进通用人工智能(AGI)方面取得显著进展,模型规模的增加导致了计算成本和能源消耗的指数级增长,这使得这些模型对于资源有限的学术研究人员和企业来说不切实际。与此同时,小型模型(SMs)在实际应用中经常被使用,尽管它们的重要性目前被低估。本文系统地从两个关键角度——合作和竞争——审视了LLMs和SMs之间的关系。我们希望这项调查能为从业者提供有价值的见解,促进对小型模型贡献的更深层次理解,并促进计算资源的更有效利用。

创新点
- 合作与竞争视角:首次系统地从合作和竞争的角度分析了在大型语言模型时代小型模型的角色。
- 多维度评估:通过准确性、泛化性、效率和可解释性等关键维度对LLMs和SMs进行了全面的比较。
- 实际应用分析:结合实际应用场景,探讨了小型模型在特定任务和受限环境中的优势和应用潜力。
算法模型
- 合作框架:提出了一个框架,展示了LLMs和SMs如何在数据策划、弱到强范式、高效推理、评估LLMs、领域适应、检索增强生成和基于提示的学习等方面进行合作。
- 竞争分析:分析了在计算受限环境、特定任务环境和需要高可解释性的环境中,小型模型相比大型模型的优势。

实验效果
- 数据策划:小型模型可以通过数据选择和重加权来提高LLMs的性能。
- 弱到强范式:使用小型模型作为监督器来微调大型模型,可以在保持性能的同时减少计算资源的需求。
- 高效推理:通过模型级联和模型路由,可以优化推理过程,减少成本和提高速度。
- 评估LLMs:小型模型可以自动评估由LLMs生成的文本,提供多角度的评估。
- 领域适应:小型模型可以通过白盒和黑盒适应方法来调整LLMs,以适应特定领域。
- 检索增强生成:小型模型作为检索器,可以增强LLMs在特定任务上的表现。
- 基于提示的学习:小型模型可以增强提示,从而提升LLMs的性能。
结论
文章总结了小型模型在大型语言模型时代的角色,强调了它们在合作和竞争中的潜力和价值。通过系统地分析和比较,文章揭示了小型模型在资源优化和特定任务中的显著优势,为未来在这一领域的研究提供了方向。尽管LLMs在性能上具有优势,但SMs在可访问性、简单性、低成本和互操作性方面具有明显优势,这使得它们在多种应用场景中仍然是一个重要的选择。
7. Beyond IID: Optimizing Instruction Learning from the Perspective of Instruction Interaction and Dependency
Authors: Hanyu Zhao, Li Du, Yiming Ju, Chengwei Wu, Tengfei Pan
超越独立同分布:从指令交互和依赖的角度优化指令学习

摘要
文章探讨了如何有效选择和整合各种指令数据集以微调大型语言模型(LLMs)。以往的研究主要关注选择单个高质量的指令,但忽略了不同类别指令之间的交互和依赖关系,导致选择策略并非最优。此外,这些交互模式的本质尚未被充分探索,更不用说根据它们来优化指令集了。为了填补这些空白,本文系统地研究了不同类别指令之间的交互和依赖模式,并使用基于线性规划的方法优化了指令集,同时使用指令依赖分类指导的课程学习来优化SFT(Supervised Fine-Tuning)的学习模式。实验结果表明,与强基线相比,在广泛采用的基准测试上取得了改进的性能。
创新点
- 指令交互和依赖模式的系统研究:首次系统地分析了不同类别指令之间的交互和依赖模式。
- 基于相关性的指令集优化:提出了一种基于效应等价的线性规划方法来优化不同类别指令的比例。
- 指令依赖分类指导的课程学习:提出了一种新的课程学习方法,根据指令依赖分类来安排学习不同类别指令的顺序。
- 实验验证:通过实验验证了所提方法在多个LLMs上的有效性,并在广泛认可的基准测试上取得了改进的性能。
算法模型
- 自动标记系统:构建了一个自动标记系统为指令分配标签,描述完成该指令所需的详细能力和知识。
- 因果干预分析:通过添加或移除具有特定标签的指令,观察LLM性能的变化,从而诱导出相关性和依赖模式。
- 效应等价系数:用于量化不同类别指令之间的相关性,基于此系数优化指令集的比例。
- 依赖分类指导的课程学习:根据指令依赖分类,调整SFT过程中不同类别指令的学习顺序。
实验效果
- 性能提升:在包含10,000、20,000和50,000指令的指令集上,与基于质量得分的方法相比,所提出的方法在不同大小的指令集上均显示出一致的性能提升。
- 重要数据:
- 在10,000指令集上,EE-CPO方法相比DEITA方法在MT-Bench和AlpacaEval 2.0基准测试上分别提升了0.11和0.14。
- 在50,000指令集上,EE-CPO方法相比DEITA方法在MT-Bench和AlpacaEval 2.0基准测试上分别提升了0.26和0.33。
- 结论:实验结果支持了分析方法和诱导的指令交互模式的合理性,并证明了考虑指令交互和依赖关系进行指令集优化的有效性。
结论
文章通过系统地研究不同类别指令之间的交互和依赖模式,并提出了相应的优化方法,有效地提高了LLMs在指令学习中的性能。这些发现不仅揭示了指令数据内在的相关性和依赖性,而且为如何优化指令集提供了有价值的见解,有助于推动LLMs在教育和其它领域的应用。
8. Native vs Non-Native Language Prompting: A Comparative Analysis
Authors: Mohamed Bayan Kmainasi, Rakif Khan, Ali Ezzat Shahroor, Boushra
Bendou, Maram Hasanain, Firoj Alam
母语与非母语提示:一项比较分析
摘要
大型语言模型(LLMs)在包括标准自然语言处理(NLP)任务在内的不同领域表现出显著的能力。为了从LLMs中获取知识,提示(prompts)起着关键作用,它们由自然语言指令组成。大多数开源和闭源的LLMs都是基于可用的标记和未标记资源(如文本、图像、音频和视频等数字内容)进行训练的,因此这些模型对高资源语言有更好的了解,但在低资源语言上则表现不佳。由于提示在理解LLMs的能力中起着至关重要的作用,因此用于提示的语言仍然是一个重要的研究问题。尽管在这一领域已有显著研究,但仍然有限,对中低资源语言的探索更少。在本研究中,我们调查了11个不同的NLP任务和12个不同的阿拉伯语数据集(9.7K数据点)上不同提示策略(母语与非母语)的影响。我们总共进行了197次实验,涉及3个LLMs、12个数据集和3种提示策略。我们的发现表明,平均而言,非母语提示的表现最好,其次是混合提示和母语提示。
创新点
- 多语言提示策略比较:研究了母语(阿拉伯语)与非母语(英语)提示对LLMs性能的影响,这是在中低资源语言环境下的一个重要研究领域。
- 广泛的实验设计:涵盖了11个不同的NLP任务和12个不同的阿拉伯语数据集,进行了197次实验,包括3个LLMs和3种提示策略。
- 深入分析:不仅比较了不同提示语言的效果,还探讨了零样本和少样本学习环境下的性能差异。
算法模型
- LLMs选择:使用了包括GPT-4o、Llama-3.1-8b和Jais-13b-chat在内的多个商业和开源模型。
- 提示策略:定义了三种不同的提示结构:母语提示、非母语提示和混合提示。
- 提示技术:采用了零样本学习和少样本学习(3-shot)技术。
- 后处理:为每个模型、提示、提示技术和数据集设计了特定的后处理函数,以从LLMs的原始输出中提取所需的信息。
实验效果
- 性能提升:非母语提示在大多数情况下表现最佳,混合提示次之,母语提示在某些情况下表现不佳。
- 重要数据:
- 在零样本设置中,非母语提示平均表现最好。
- 在少样本设置中,非母语提示同样表现最佳,尤其是在GPT-4o模型中。
- 对于没有训练数据的新任务,零样本设置是理想的解决方案,非母语提示在所有模型中表现更好。
- GPT-4o在所有提示设置中表现最佳。
- 结论:非母语提示通常能更好地引导模型理解上下文,从而在跨语言的任务中实现更高的性能。
结论
本研究调查了不同提示结构(母语、非母语和混合)对于从各种商业和开源模型中获取所需输出(下游NLP任务的标签)的重要性。实验结果表明,非母语提示在多种设置中表现更好,这可能与模型在训练过程中对主导语言(英语)的更强能力有关。未来的工作可能包括使用指令遵循数据集进行微调,以创建特定领域的专业模型。
9. Understanding Knowledge Drift in LLMs through Misinformation
Authors: Alina Fastowski and Gjergji Kasneci
通过错误信息理解大型语言模型中的知识漂移
摘要
本文主要分析了在问答场景中,当遇到错误信息时,最先进的大型语言模型(LLMs)对事实不准确信息的敏感性。这种敏感性可能导致所谓的知识漂移现象,这显著削弱了这些模型的可信度。研究者通过熵、困惑度和令牌概率等指标评估了模型回答的事实性和不确定性。实验结果显示,当模型由于暴露于错误信息而错误回答问题时,其不确定性可能增加高达56.6%。同时,重复暴露于相同的错误信息可以再次降低模型的不确定性(与未受污染的提示回答相比降低了52.8%),这可能操纵了模型的原始知识信念,引入了与其原始知识的漂移。这些发现为LLMs的鲁棒性和对抗性输入的脆弱性提供了见解,为开发更可靠的LLM应用铺平了道路。

创新点
- 知识漂移分析:首次系统地分析了LLMs在遇到错误信息时内部知识结构的变化,即知识漂移。
- 不确定性评估:通过熵、困惑度和令牌概率等指标来评估LLMs在面对错误信息时的不确定性变化。
- 错误信息影响:研究了错误信息对LLMs性能和不确定性估计的影响,发现重复暴露于错误信息可以减少模型的不确定性,表明模型可能被操纵。
算法模型
- 不确定性度量:使用熵、困惑度和令牌概率来量化模型的不确定性。
- 实验设计:在TriviaQA数据集上进行实验,测试LLMs在面对正确和错误信息时的表现。
- 信息注入:通过在问题提示中注入错误信息和随机信息,来观察模型响应的变化。
实验效果
- 不确定性增加:当模型由于错误信息而错误回答问题时,不确定性增加了高达56.6%。
- 重复暴露影响:重复暴露于相同的错误信息可以降低模型的不确定性(与未受污染的提示相比降低了52.8%)。
- 模型表现:实验涉及的模型包括GPT-4o、GPT-3.5、LLaMA-2-13B和Mistral-7B,结果显示所有模型在面对错误信息时都表现出了知识漂移的现象。
结论
研究揭示了LLMs在处理错误信息时可能出现的知识漂移现象,强调了在设计和部署LLM应用时考虑其对错误信息的敏感性的重要性。研究结果表明,错误信息可以显著影响模型的不确定性和事实准确性,这对于提高LLMs在关键应用中的鲁棒性和可信度具有重要意义。
推荐阅读指数
★★★★☆
推荐理由:这篇文章对于理解大型语言模型在面对错误信息时的行为和内部知识结构的变化具有重要意义。它不仅提供了对现有LLMs潜在脆弱性的深入分析,还为未来如何提高模型的鲁棒性和可信度提供了有价值的见解。适合对自然语言处理、机器学习以及人工智能安全性感兴趣的研究人员和从业者阅读。
9. Ontology-Free General-Domain Knowledge Graph-to-Text Generation Dataset Synthesis using Large Language Model
Authors: Daehee Kim, Deokhyung Kang, Sangwon Ryu, Gary Geunbae Lee
使用大型语言模型合成无本体的通用领域知识图谱到文本生成数据集

摘要
知识图谱到文本(G2T)生成任务旨在将知识图谱的三元组形式(主体、谓语、客体)转化为自然语言文本。预训练语言模型(PLMs)的最新进展在G2T性能上取得了显著提升,但其有效性依赖于具有精确图-文本对齐的数据集。然而,高质量、通用领域G2T生成数据集的稀缺限制了通用领域G2T生成研究的进展。为了解决这一问题,我们介绍了Wikipedia OntologyFree Graph-text数据集(WikiOFGraph),这是一个新的大型G2T数据集,它利用大型语言模型(LLM)和Data-QuestEval的新方法生成。我们的新数据集包含585万通用领域图-文本对,不依赖外部本体,提供了高图-文本一致性。实验结果表明,针对WikiOFGraph进行微调的PLM在各种评估指标上优于其他数据集上训练的模型。我们的方法被证明是生成高质量G2T数据的可扩展和有效解决方案,显著推进了G2T生成领域。
创新点
- 无本体的数据集生成:提出了一种新方法,利用大型语言模型(LLM)和Data-QuestEval来生成无本体的通用领域知识图谱到文本的数据集。
- 高图-文本一致性:新数据集在不依赖外部本体的情况下,提供了高一致性的图-文本对。
- 大规模数据集:生成了包含585万通用领域图-文本对的数据集,覆盖了整个Wikipedia的内容。
算法模型
- 数据集生成方法:通过LLM从Wikipedia文本中提取图表示,然后使用Data-QuestEval进行数据筛选,确保图-文本对的一致性。
- 图提取:使用LLM从给定句子中提取图表示,通过人工选择的例子引导LLM进行图表示的提取。
- 数据筛选:利用Data-QuestEval对生成的图-文本对进行筛选,确保数据的高质量。
实验效果
- 性能提升:在WikiOFGraph数据集上微调的PLM在多个评估指标上优于其他数据集上训练的模型。
- 重要数据:
- 在GenWiki测试集上,WikiOFGraph微调的模型在BLEU、METEOR、ROUGE-L和BERTScore-F1等指标上均优于其他数据集。
- 在WikiOFGraph测试集上,微调的模型在所有评估指标上均表现出显著的性能提升。
结论
研究介绍了WikiOFGraph数据集,这是一个大规模的通用领域G2T数据集,通过LLM和Data-QuestEval生成,不依赖外部本体。实验结果表明,该数据集在多个评估指标上能够提升PLM的性能。此外,通过额外的实验和案例研究,证明了Data-QuestEval筛选在确保图-文本一致性方面的有效性。
推荐阅读指数
★★★★☆
推荐理由:这篇文章提出了一种创新的方法,通过结合LLM和Data-QuestEval来生成无本体的通用领域知识图谱到文本的数据集。该方法不仅提高了数据集的质量和一致性,而且生成的数据集规模大,覆盖了广泛的领域,对于推动G2T生成领域的研究具有重要意义。适合对自然语言处理、知识图谱和数据生成感兴趣的研究人员和从业者阅读。
10. Cross-Refine: Improving Natural Language Explanation Generation by Learning in Tandem
Authors: Qianli Wang, Tatiana Anikina, Nils Feldhus, Simon Ostermann, Sebastian
M"oller, Vera Schmitt
交叉精炼:通过协同学习改进自然语言解释生成

摘要
本文介绍了一种名为CROSS-REFINE的方法,旨在通过模仿人类的学习过程来改善大型语言模型(LLM)生成的自然语言解释(NLE)。CROSS-REFINE通过使用两个LLM,一个作为生成器(generator),另一个作为批评者(critic),来迭代提升解释的质量。生成器首先输出一个初步的NLE,然后根据批评者提供的反馈和建议进行优化。这种方法不需要任何监督训练数据或额外的训练。通过在三个自然语言处理(NLP)任务上的自动和人类评估来验证CROSS-REFINE的有效性,结果表明CROSS-REFINE在多个方面优于SELF-REFINE方法,并且能够在不太强大的LLM上有效工作。
创新点
- 协同学习机制:CROSS-REFINE通过两个LLM的协同工作,模拟人类的学习过程,其中生成器和批评者相互提供反馈和建议。
- 无需额外训练:与需要额外训练数据的方法不同,CROSS-REFINE不需要任何监督训练数据或额外训练。
- 跨语言评估:CROSS-REFINE在英语和德语的双语数据集上进行了评估,显示了其跨语言的适用性。
算法模型
CROSS-REFINE的核心是两个LLM的协同工作:
- 生成器:负责生成初步的NLE。
- 批评者:提供对生成器输出的反馈和改进建议。
- 交叉精炼过程:生成器利用批评者的反馈和建议来优化其初步解释。

实验效果
- 自动评估:使用BLEURT、BARTScore和TIGERScore等自动化指标进行评估,CROSS-REFINE在ECQA和eSNLI数据集上的表现优于SELF-REFINE。
- 人类评估:通过用户研究,CROSS-REFINE在忠实度、连贯性和洞察力方面的表现优于SELF-REFINE。
- 重要数据与结论:
- 在HealthFC数据集上,CROSS-REFINE在生成德语解释方面比SELF-REFINE更有效。
- CROSS-REFINE在需要特定领域知识的医疗领域表现不佳,但在“自我CROSS-REFINE”设置中表现优于SELF-REFINE。
推荐阅读指数
★★★★☆
推荐理由:
- 对于自然语言处理和机器学习领域的研究人员和实践者,CROSS-REFINE提供了一种创新的方法来改进LLM生成的解释。
- 论文详细介绍了方法的动机、设计和实验验证,对于理解当前LLM在解释生成方面的能力和限制非常有帮助。
- 跨语言评估的部分为多语言NLP任务提供了有价值的见解。
扣分理由:
- 尽管在特定领域(如医疗)的表现有待提高,但整体上该方法在多个任务上显示出了显著的改进,因此扣掉一分。哈哈,另外一个原因是文章也比较长,看完不容易~~~
备注
原创文章同步发表CSDN与知乎平台,内容仅供学习使用。 – by 夜空流星(sp-fyf-2024)
相关文章:
计算机人工智能前沿进展-大语言模型方向-2024-09-13
计算机人工智能前沿进展-大语言模型方向-2024-09-13 1. OneEdit: A Neural-Symbolic Collaboratively Knowledge Editing System Authors: Ningyu Zhang, Zekun Xi, Yujie Luo, Peng Wang, Bozhong Tian, Yunzhi Yao, Jintian Zhang, Shumin Deng, Mengshu Sun, Lei Liang, Z…...

衡石分析平台使用手册-替换衡石minio
替换衡石minio 在使用HENGSHI SENSE服务过程中,可以根据业务需要替换HENGSHI自带的minio。本文讲述使用Aws S3和Aliyun OSS替代衡石minio的过程。 准备工作 在进行配置前,请在aws s3或aliyun oss完成如下准备工作。 创建access_key和secret_acces…...
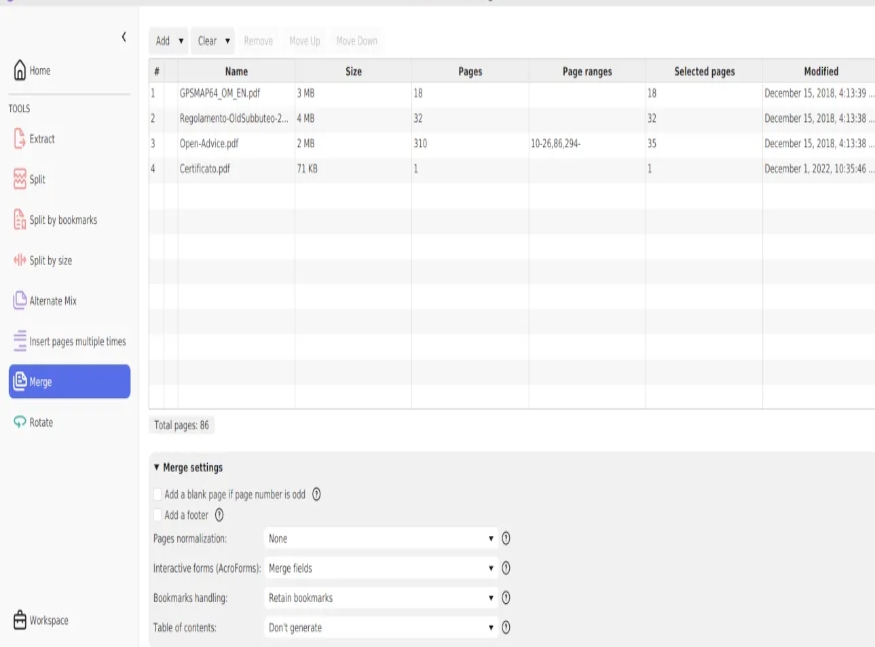
怎么将几个pdf合成为一个?把几个PDF合并成为一个的8种方法
怎么将几个pdf合成为一个?将多个PDF文件合并成一个整体可以显著提高信息整合的效率,并简化文件的管理与传递。例如,将不同章节的电子书合成一本完整的书籍,或者将多个部门的报告整合成一个统一的文档,可以使处理流程变…...

明明没有程序占用端口,但是启动程序却提示端口无法使用,项目也启动失败
明明没有程序占用端口,但是启动程序却提示端口无法使用,项目也启动失败 win10、端口占用、port、netstat、used背景 曾在springboot中遇到过,新建spring cloud时又遇到这个问题,如果不从根本上解决,就需要改端口&…...

ClickHouse的安装配置+DBeaver远程连接
1、clickhouse的下载: 先去clickhouse官网进行下载,继续往下翻找文档,将DBeaver也下载下来 下载地址:https://packages.clickhouse.com/rpm/stable/ 下载这个四个rpm包 2、上传rmp文件到Linux中 自己创建的一个clickhouse-ins…...
—— objection 机制)
UVM仿真的运行(四)—— objection 机制
目录 0. 引言 1. uvm_phase::execute_phase line 1432~1470 2. uvm_objection 2.1 get_objection_total 2.2 raise_objection 2.3 drop_objection 2.4 m_execute_scheduled_forks 2.5 wait_for 3. 小结 0. 引言 前面介绍了uvm仿真的启动,按照domain中指定的DAG的pha…...

【ShuQiHere】算法分析:揭开效率与复杂度的神秘面纱
【ShuQiHere】 🚀 引言 在计算机科学的世界中,算法 是每一个程序背后的隐形支柱。从简单的排序到复杂的人工智能,算法无处不在。然而,编写一个能运行的程序只是开始,当程序面对庞大的数据集时,算法的效率…...

记忆化搜索专题——算法简介力扣实战应用
目录 1、记忆化搜索算法简介 1.1 什么是记忆化搜索 1.2 如何实现记忆化搜索 1.3 记忆化搜索与动态规划的区别 2、算法应用【leetcode】 2.1 题一:斐波那契数 2.1.1 递归暴搜解法代码 2.1.2 记忆化搜索解法代码 2.1.3 动态规划解法代码 2.2 题二࿱…...

【Java】【力扣】83.删除排序链表中的重复元素
题目 给定一个已排序的链表的头 head , 删除所有重复的元素,使每个元素只出现一次 。返回 已排序的链表 。 示例 1: 输入:head [1,1,2] 输出:[1,2]示例 2: 输入:head [1,1,2,3,3] 输出&#…...

vue3项目实现全局国际化
本文主要梳理vue3项目实现全项目格式化,例如在我前面文章使用若依创建vue3的项目中,地址:若依搭建vue3项目在导航栏中切换,页面中所有的组件的默认语言随之切换,使用的组件库依旧是element-plus,搭配vue-i1…...

Oracle 19c异常恢复—ORA-01209/ORA-65088---惜分飞
由于raid卡bug故障,导致文件系统异常,从而使得数据库无法正常启动,客户找到我之前已经让多人分析,均未恢复成功,查看alert日志,发现他们恢复的时候尝试resetlogs库,然后报ORA-600 kcbzib_kcrsds_1错误 2024-09-15T17:07:32.55321508:00 alter database open resetlogs 2024-09-…...

【Webpack--000】了解Webpack
🤓😍Sam9029的CSDN博客主页:Sam9029的博客_CSDN博客-前端领域博主 🐱🐉若此文你认为写的不错,不要吝啬你的赞扬,求收藏,求评论,求一个大大的赞!👍* &#x…...

开源 AI 智能名片链动 2+1 模式 S2B2C 商城小程序与社交电商的崛起
摘要:本文深入探讨了社交电商迅速发展壮大的原因,并分析了开源 AI 智能名片链动 21 模式 S2B2C 商城小程序在社交电商中的重要作用。通过对传统电商与社交电商的对比,以及对各发展因素的剖析,阐述了该小程序如何为社交电商提供新的…...
在线IP代理检测:保护您的网络安全
在互联网飞速发展的今天,越来越多的人开始意识到网络安全和隐私保护的重要性。在线IP代理检测工具作为一种有效的网络安全手段,能够帮助用户识别和检测IP代理的使用情况,从而更好地保护个人隐私和数据安全。本文将详细介绍在线IP代理检测的相…...

【算法】BFS—解开密码锁的最少次数
题目 一个密码锁由 4 个环形拨轮组成,每个拨轮都有 10 个数字: 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 。每个拨轮可以自由旋转:例如把 9 变为 0,0 变为 9 。每次旋转都只能旋转一个拨轮的一位数字。 锁的初始数字为 0000 ,一个…...

非守护线程会阻止JVM的终止吗
非守护线程会阻止JVM的终止。在Java中,线程分为守护线程(Daemon Threads)和非守护线程(Non-Daemon Threads,也被称为用户线程)。这两种线程在JVM终止时表现出不同的行为。 非守护线程是JVM中执行程序主要逻…...

Grafana面板-linux主机详情(使用标签过滤主机监控)
1. 采集器添加labels标签区分业务项目 targets添加labels (模板中使用的project标签) … targets: [‘xxxx:9100’] labels: project: app2targets: [‘xxxx:9100’] labels: project: app1 … 2. grafana面板套用 21902 模板 演示...

MYSQL数据库基础篇——DDL
DDL:DDL是数据定义语言,用来定义数据库对象。 一.DDL操作数据库 1.查询 ①查询所有数据库 输入; 得到结果: ②查询当前数据库 输入; 例如执行下面语句: 2.创建 输入 然后展示数据库即可得到结果&…...

Springboot 集成 Swing
背景 Springboot 在 Java 给 Java 开发带来了极大的便利,那么如何把它集成到 Swing GUI 编程项目中,使得 GUI 编程更加高效?本人简单做了一下尝试,完成一个 demo ,贴出来供大家参考 具体步骤 创建一个 spring boot …...

枚举算法总结
枚举算法(Enumeration Algorithm)是一种简单而直接的算法设计策略,它通过列出问题的所有可能情况,逐一进行验证,直到找到问题的解。这种算法适用于问题的解空间不是太大,可以通过遍历所有情况来找到答案的情…...

Visual Studio 项目属性页开发完全教程:从基础到高级
Visual Studio 项目属性页开发完全教程:从基础到高级 【免费下载链接】project-system The .NET Project System for Visual Studio 项目地址: https://gitcode.com/gh_mirrors/pr/project-system Visual Studio 项目属性页是开发者管理项目配置的核心界面&a…...

告别沉浸式白屏!UniApp中iOS/Android底部安全区与顶部状态栏颜色自定义全攻略
告别沉浸式白屏!UniApp中iOS/Android底部安全区与顶部状态栏颜色自定义全攻略当开发者尝试在UniApp中实现沉浸式设计时,往往会遇到一个令人头疼的问题——默认的白色安全区和状态栏导致界面元素(如电池图标、信号强度)几乎不可见。…...

内网环境下Win7系统批量离线补丁部署实战指南
1. 内网Win7补丁部署的挑战与解决方案老旧Win7系统在内网环境中的安全隐患就像漏雨的屋顶,看似不影响日常使用,但随时可能引发严重后果。我经手过几十家单位的系统加固项目,发现这些场景存在三个典型痛点:首先是补丁来源问题&…...
)
Python基础语法:生成器 generator(yield)
一、简介根据指定的规则循环生成数据,当条件不成立时则生成数据结束。数据不是一次性全部生成出来,而是使用一个,再生成一个,好处是可以节约大量的内存。就像设计模式中的懒汉式。适合处理大数据或流数。生成器是一种特殊的迭代器…...

智慧树自动刷课助手:3步告别手动操作的学习效率工具
智慧树自动刷课助手:3步告别手动操作的学习效率工具 【免费下载链接】zhihuishu 智慧树刷课插件,自动播放下一集、1.5倍速度、无声 项目地址: https://gitcode.com/gh_mirrors/zh/zhihuishu 还在为智慧树平台的重复刷课操作而烦恼吗?智…...

《我看见的世界:李飞飞自传》第1-6章阅读笔记:从移民少女到AI教母的“看见“之旅
前言 当我们谈论人工智能时,我们谈论的是算法、数据、算力,是那些冰冷的代码和复杂的模型。但在《我看见的世界:李飞飞自传》中,李飞飞用她独特的视角告诉我们:AI的本质,是人类对"看见"世界的渴望…...

别被忽悠了!2026亲测靠谱的AI论文网站|避坑精选版
2026 年学术写作工具已高度分化,千笔AI与ThouPen为全流程首选,豆包、DeepSeek 为专项强手;避坑关键:拒绝假文献、严控 AIGC 率、优先国内适配、免费试用先行。 一、TOP3 全流程首选(亲测不踩雷) 1. 千笔AI&…...
原理与ScalableHD架构优化实践)
超维计算(HDC)原理与ScalableHD架构优化实践
1. 超维计算(HDC)基础解析超维计算(Hyperdimensional Computing, HDC)是一种受大脑信息处理机制启发的计算范式,其核心思想是用高维随机向量(通常称为超向量或HV)来表示和处理信息。与传统神经网…...

基于USB ACA模式实现安卓手机边玩边充的游戏手柄设计
1. 项目缘起:当手机性能过剩,却败给了触摸屏几年前,我清理手机游戏时,发现一个挺无奈的现象:性能足以媲美掌机的智能手机里,只剩下一些慢节奏的平台解谜或者数独。那些曾经让我在掌机上废寝忘食的赛车、动作…...
从模糊到电影级景深:Midjourney + Topaz Gigapixel联调方案(含LUT预设包+PSD分层模板)
更多请点击: https://codechina.net 第一章:从模糊到电影级景深:Midjourney Topaz Gigapixel联调方案(含LUT预设包PSD分层模板) 当Midjourney生成的图像存在主体边缘柔化、背景层次缺失或分辨率不足等问题时…...