三万字长文Java面试题——基础篇(注:该篇博客将会一直维护 最新维护时间:2024年9月18日)
🧸本篇博客重在讲解Java基础的面试题,将会实时更新,欢迎大家添加作者文末联系方式交流
📜JAVA面试题专栏:JAVA崭新面试题——2024版_dream_ready的博客-CSDN博客
📜作者首页: dream_ready-CSDN博客
📜有任何问题都可以评论留言,作者将会实时回复
📜未来将会更新数据结构面试题以及Spring和MySQL等等的面试题,将会涵盖JAVA后端所有技术框架,敬请期待!!!
注:本篇博客精简高效,问题对应的答案是直接可以口述给面试官
有的问题答案较长,可以仅记住前半部分。我写的时候也为这样的答案量身定做了一番,即便直接回答前半部分也不突兀,也能达到中等的水平
目录
1、什么是Java?
2、Java语言有哪些特点
3、JVM、JDK 和 JRE 有什么区别?
4、什么是字节码?采用字节码的好处是什么?
5、为什么说 Java 语言“编译与解释并存”?
6、什么是面向对象编程
7、面向对象和面向过程的区别
8、八种基本数据类型,以及他们的封装类
9、三种引用数据类型
10、为什么要有封装类,封装类的作用
11、装箱与拆箱
12、Integer缓存?
13、标识符的命名规则
14、& 与 && 的区别
15、自增和自减,左++和右++,即 ++a 和 a++
16、方法重载和方法重写的区别
17、访问修饰符public、private、protected、以及不写(默认)时的区别?
18、equals 与 == 的区别
19、final、finally、finalize的区别
20、try catch finally,try中有return,finally还会执行么
21、String、StringBuilder、StringBuffer有什么区别?
22、String底层是如何实现的
23、String的 ”+“ 操作如何实现的(String拼接字符串是如何实现的)
24、Java是值传递还是引用传递?
25、抽象类和接口有什么区别?
26、深克隆和浅克隆有什么区别?
27、Exception 与 Error 有什么区别
28、深入学习 异常Exception
29、a=a+b 与 a+=b 有什么区别吗?
30、自动类型转换、强制类型转换、自动类型提升
31、Java中的 IO 流
32、什么是序列化?什么是反序列化?序列化和IO流的关系?
33、为什么类一定要实现Serializable才能被序列化?
34、final的用法
35、static的用法
36、什么是反射?为什么需要反射?
37、反射的应用场景
38、反射机制的优点和缺点
39、为什么反射执行比较慢?
40、代理模式——静态代理和动态代理
静态代理
动态代理
41、什么是泛型?为什么要有泛型?
42、什么是枚举?枚举的使用场景
43、Lambda表达式
45、Stream流
1、什么是Java?
可以配合Java语言有哪些特点一起回答
Java是一门面向对象的编程语言,不仅吸收了C++语言的各种优点,还摒弃了C++里难以理解的多继承、指针等概念,因此Java语言具有功能强大和简单易用两个特征。
Java语言作为静态面向对象编程语言的优秀代表,极好地实现了面向对象理论,允许程序员以优雅的思维方式进行复杂的编程。
补充(了解即可):静态在这里是什么意思? 在编程语言的上下文中,“静态”通常指的是编译时确定的特性,比如Java的静态类型检查,这意味着变量的类型是在编译时确定的,并且需要明确声明。当然,这个静态还有静态绑定等意思。与之对应的动态编程语言有python,Js,这类语言通常不需要显式的类型声明,并且可以在运行时改变代码结构和行为,通常具有动态类型系统,这意味着变量的类型可以在程序运行时确定,并且可以在运行过程中改变变量的类型
2、Java语言有哪些特点
- 简单易学:有丰富的类库,没有指针
- 面向对象:Java 是一种完全支持面向对象编程的语言,它支持类、对象、继承、封装、多态等概念
- 平台无关性:“一次编写,到处运行”,Java 程序可以在任何安装了 Java 虚拟机 (JVM) 的平台上运行
- 支持多线程:不可否认,多线程在当代服务器开发语言中不可或缺
- 可靠安全:Java有内置的安全机制,严格的错误检查和异常处理机制
当然,语言的特点是说不尽的,例如我们经常挂在嘴边的安全性、健壮性、可移植性
(上面这句话口述就行,回答口吻更接近自己思考)
3、JVM、JDK 和 JRE 有什么区别?
JVM:Java虚拟机,Java程序运行在Java虚拟机上。针对不同系统的实现(Windows,Linux,macOs)不同的JVM,因此Java语言可以实现跨平台。
JRE:Java 运行时环境。它是运行已编译 Java 程序所需的所有内容的集合,包括Java 虚拟机(JVM),Java 类库,Java 命令和其他的一些基础构件。但是,它不能用于创建新程序。
JDK:它是功能齐全的 Java SDK。它拥有 JRE 所拥有的一切,还有编译器(javac)和工具(如javadoc 和 jdb)。它能够创建和编译程序。
简单来说,JDK包含JRE,JRE包含JVM。
4、什么是字节码?采用字节码的好处是什么?
所谓的字节码,就是Java程序经过编译之类产生的 .class文件,字节码能够被虚拟机识别,从而实现Java程序的跨平台性(不用平台的虚拟机将字节码翻译成所需的机器码,实现跨平台运行)
Java 程序从源代码到运行主要有三步:
- 编译:将我们的代码(java)编译成虚拟机可以识别理解的字节码(.class)
- 解释:虚拟机执行Java字节码,将字节码翻译成机器能识别的机器码
- 执行:对应的机器执行二进制机器码

只需要把Java程序编译成Java虚拟机能识别的Java字节码,不同的平台安装对应的Java虚拟机,这样就可以可以实现Java语言的平台无关性。
5、为什么说 Java 语言“编译与解释并存”?
高级编程语言按照程序的执行方式分为 编译型 和 解释型 两种。
简单来说,编译型语言是指编译器针对特定的操作系统将源代码一次性翻译成可被该平台执行的机器码;解释型语言是指解释器对源程序逐行解释成特定平台的机器码并立即执行。
- 编译型:一次全完成
- 解释型:一边一边
比如,你想读一本外国的小说,你可以找一个翻译人员帮助你翻译,有两种选择方式,你可以先等翻译人员将全本的小说(也就是源码)都翻译成汉语,再去阅读,也可以让翻译人员翻译一段,你在旁边阅读一段,慢慢把书读完。
Java 语言既具有编译型语言的特征,也具有解释型语言的特征,因为Java 程序要经过先编译,后解释两个步骤:
- 由Java编写的程序需要先经过编译步骤,生成字节码(.class文件) -> 一次性将所有java代码都编译成字节码文件
- 这种字节码必须再经过JVM,解释成操作系统能识别的机器码,在由操作系统执行(这个过程是动态的)
因此,我们可以认为Java语言编译与解释并存
需要注意的是,Java中还存在 即时编译(JIT) 的技术。JIT编译器会在运行时将热点代码(经常执行的代码)编译为本地机器码,存储起来,之后再次调用这些方法时可以直接执行编译后的机器码,以提高程序的执行效率。因此,在Java程序执行过程中,可能会同时存在解释执行和即时编译执行的情况。
6、什么是面向对象编程
面向对象编程 是一种编程范式或编程方法,通过将数据和操作数据的方法(函数)进行组合,以创建对象的方式来解决问题。
它的主要思想是将问题划分为不同的对象,每个对象具有一些特定的属性和行为,对象之间通过传递消息或数据进行通信和交互。
而建立对象的目的也不是为了完成一个个步骤,而是为了描述某个事物在解决整个问题的过程中所发生的行为。
上面说的较为官方,口语化描述就是 面向对象编程的核心概念是对象和类。
- 对象是类的一个实例,具有属性(数据)和行为(方法)。
- 类是对象的模板或蓝图,定义了一组相似对象的共同属性和行为。
当然,不仅如此
面向对象编程还有三大特性,封装、继承、多态
- 封装 是一种将数据和操作数据的方法组合在一起的机制。通过封装,可以隐藏对象的内部实现细节,并通过定义公共接口来访问和操作对象的数据。
- 继承 继承是一种通过创建新类来扩展已有类的属性和行为的机制。通过继承,子类可以继承父类的属性和方法,并可以在此基础上进行扩展或修改。
- 多态 是指一个对象可以具有多种类型。通过多态,可以在不改变代码的情况下,使用不同类型的对象来实现多种行为。
亲爱的面试官,请允许我用实际开发中的例子来解释以上三个特性(绅士!)
注:以下三个例子不用背,甚至不用看,自己会举例即可!
封装其实尤为常见,在实际开发中,我们经常需要用到别人写好的代码。比如复制a对象的同名属性的值到b对象中,我们往往只需要使用某个工具类就可以完成这个功能,说白了,我们关心这个工具类的输入和输出,但往往我们不是特别关心它的实现。这个时候,这个工具类就是 “封装” 这个特性的最好诠释之一
继承也是屡见不鲜,还是拿这个工具类举例,现在它的功能大多数我们都会在这个项目中用到,但是它又不够用。这时我们就可以自己定义一个工具类继承刚才那个工具类的基础上拓展自己想要的功能
多态就更好举例了,拿一个对象可以具有多种类型这一点来说吧。我们Java中经常需要使用list集合,但是集合的实现方式有很多,比如ArrayList,LinkedList,这个时候,同样的add方法就有了多种多样的实现
List<Integer> list1 = new ArrayList<>();
List<Integer> list2 = new LinkedList<>();7、面向对象和面向过程的区别
面向过程:分析解决问题的步骤,然后用函数把这些步骤一步一步地实现,然后在使用的时候调用则可。性能较高,所以单片机、嵌入式开发等一般采用面向过程开发
面向对象:把构成问题的事务分解成各个对象,而建立对象的目的也不是为了完成一个个步骤,而是为了描述某个事物在解决整个问题的过程中所发生的行为。面向对象有封装、继承、多态的特性,所以易维护、易复用、易扩展。可以设计出低耦合的系统。 但是性能上来说,比面向过程要低
针对面向对象比面向过程性能上为什么要低,我在这里诠释一下。
首选,咱不犟这个问题,这个性能低是从宏观角度说的,而不是说解决所有问题性能都低。
- 其实可以这样理解,面向过程中用到的东西大多都是为这个步骤或者说过程考虑,量身定做的,它的可重用性较低,与之换来的就是量身定做所带来的性能高。
- 而面向对象不同,我们往往思考它的可重用性,比如java中的很多工具类,这个对象可以用,那个对象也可以用。那与之对应的就是性能的降低。
比如复制a对象的同名属性的值到b对象中:
- 面向过程的解决方案是 我们可以手动地set,get,这只适用于这两个对象之间用。我想用到其他对象上,还需要再改代码。但是定制化了这个解决过程,复制效率更高
- 面向对象的解决方案是 我们定义一个工具类,任何人只要给我传入两个对象,我就能通过反射的逻辑拿到任意两个对象的属性并进行赋值。反射的效率肯定是比我们直接知道对应属性然后set、get的方案是要慢的,但是封装起来后,可重用性大大增加,减少了代码的冗余
8、八种基本数据类型,以及他们的封装类
| 基本类型 | 大小(字节) | 默认值 | 封装类 | 汉语直译 |
|---|---|---|---|---|
| byte | 1 | 0 | Byte | 字节 |
| char | 2 | \u0000 (也就是null) | Character | 字符型 |
| short | 2 | 0 | Short | 短整型 |
| int | 4 | 0 | Integer | 整型 |
| long | 8 | 0L | Long | 长整型 |
| float | 4 | 0.0f | Float | 单精度浮点型 |
| double | 8 | 0.0d | Double | 双精度浮点型 |
| boolean | 不一定 | false | Boolean | 布尔型 |
注:boolean在不同的JVM中大小可能不相同
注:这里的 封装类 也有人叫 包装类
注:String并不是Java中的基本数据类型
9、三种引用数据类型
Java语言数据类型分为两种:基本数据类型和引用数据类型
三大引用数据类型:
- 类(class)
- 接口(interface)
- 数组([])
10、为什么要有封装类,封装类的作用
为什么要有封装类?理由如下:
面向对象要求、提供了更多的功能和方法、泛型要求、表示null值
面向对象要求:Java 是一门面向对象的编程语言,要求所有的数据都应该是对象。但是,基本数据类型(如int、char、double等)并不是对象,它们没有成员方法和其他面向对象的特性。为了满足面向对象编程的要求,Java 引入了包装类,将基本数据类型封装成对象,使得它们也具有面向对象的特性。例如集合的操作只能是对象,而不能为基础数据类型。
提供了更多的功能和方法:包装类提供了一些额外的方法和功能,例如执行数学运算、比较大小、转换数据类型 Integer.valueOf(n)等方法。
泛型要求:泛型是 Java 中很重要的特性,它提供了类型安全和代码重用的功能。但是,泛型要求类型参数必须是对象类型,不能是基本数据类型。因此,如果想在泛型中使用基本数据类型,就需要使用对应的包装类。
表示 nul 值:包装类可以表示 null 值,而基本数据类型不能。这在某些场景下很有用,比如在接口传参中,如果使用包装类即使前端不传参也不会报错,而使用基本数据类型,如果前端忘记传参就会报错。
封装类的作用在于提供了更多的功能和方法、泛型要求、表示null值
封装类主要的应用场景如下:
- 用于泛型数据存储
- 用于集合类数据存储
- 方法的参数传递
引申:11、装箱与拆箱
11、装箱与拆箱
装箱 和 拆箱 是 Java 语言中,用于基本数据类型和封装类之间互相转换的过程。
注:装箱和拆箱是JAVA语言自动帮我们进行的,我们不需要进行额外操作
装箱 是指将基本数据类型转换为对应的封装类对象。Java 编译器会自动将基本数据类型转换为对应的封装类对象,这称为自动装箱。
例如,将 int 类型的值赋给 Integer 对象
int num = 100;
Integer obj = num; // 自动装箱拆箱 是指将包装类对象转换为对应的基本数据类型。同样,Java 编译器会自动将包装类对象转换为对应的基本数据类型,这称为自动拆箱。
例如,将 Integer 对象赋给 int 类型的变量
Integer obj = 200;
int num = obj; // 自动拆箱装箱和拆箱的过程在编译时由编译器自动完成,使得基本数据类型和包装类之间可以方便地进行转换。这样就可以在需要使用包装类的场景(如泛型、集合类、反射等)中传递和操作基本数据类型的值。
注意事项:
装箱和拆箱的过程可能涉及到对象的创建和销毁,可能会引入额外的开销和性能损耗。因此,在性能要求较高的场景中,应尽量避免频繁的装箱和拆箱操作,以减少额外的开销。
12、Integer缓存?
因为根据实践发现大部分的数据操作都集中在值比较小的范围,因此 Integer 搞了个 缓存池,默认范围是 -128 到 127,可以根据通过设置 JVM-XX:AutoBoxCacheMax= 来 修改缓存的最大值,最小值改不了
即当我们使用的Integer类型的变量值在缓存池范围内,就会优先使用缓存池内的变量(自动装箱的机制,若直接new一个Integer时赋值,则不会使用缓存池中的变量),以节省内存。当然若变量修改,只会影响Integer的引用指向,不影响缓存池内的变量。
引申笔试题:
①、Integer a= 127,Integer b = 127;Integer c= 128,Integer d = 128;相等吗?
(其实应该问这四者用双等号 == 比较相等么,但很多面试官和笔试题不会说这么完全)
答案是 a 等于 b, c不等于d
原因:对于引用数据类型来说,== 比较的是地址,而127在缓存池范围内,所以127时,a和b都使用的是缓存池的变量,所以a等于b
②、Integer a = new Integer(127); Integer b = new Integer(127); 相等吗?
答案是不相等
因为使用缓存池内的变量是自动装箱时Integer才会触发的机制,而直接new对象时赋值的话,这两个对象是不同的实例,它们在内存中的地址是不同的
13、标识符的命名规则
标识符的含义:
是指在程序中,我们自己定义的内容,譬如,类的名字,方法名称以及变量名称等等,都是标识符。
命名规则:(硬性要求)
- 标识符可以包含英文字母,0-9的数字,$以及_
- 标识符不能以数字开头
- 标识符不是关键字
命名规范:(非硬性要求)
- 类名规范:首字符大写,后面每个单词首字母大写(大驼峰式)。
- 变量名规范:首字母小写,后面每个单词首字母大写(小驼峰式)。
- 方法名规范:同变量名。
注:后续有空的话我出一个前端vue、后端java以及数据库等相关的命名规则汇总,比如数据库的字段命名规则等。有人催更我就早点写,没人催更的话我就有空再写,写完之后这段话会替换成规则汇总博客的链接
14、& 与 && 的区别
首先这里不讲 &有按位与的功能(位运算操作符),这里讲的都是他俩做逻辑与操作时的区别
& 与 && 都有逻辑与的操作,二者都要求运算符左右两端的布尔值都是 true 整个表达式的值才是 true
但 && 有短路运算的功能,也就是说如果&&左边的表达式的值是 false,右边的表达式会被直接短路掉,不会进行运算。(所以 && 也叫 短路与)
而 & 无论符号左边的表达式是何值,都必须完成右边表达式的运算
很多时候我们可能都需要用&&而不是&。
例如在验证用户登录时判定用户名不是 null 而且不是空字符串,应当写为
username != null && !username.equals("")二者的顺序不能交换,更不能用&运算符,因为 第一个条件如果不成立,根本不能进行字符串的 equals 比较,否则会产生 NullPointerException 异常。
注意:逻辑或运算符(|)和短路或运算符(||)的差别也是如此
15、自增和自减,左++和右++,即 ++a 和 a++
这个应该学c语言的时候都学过了,所以我这里把答案放出来,就不过多解释了
- 左++:先++后赋值
- 右++:先赋值后++
左++:
前缀递增是指在使用变量之前先将其值加1。这意味着变量的值会先增加1,然后再使用新的值。
int x = 10;
int y = ++x; // 先将 x 的值加 1,变为 11,然后将 11 赋值给 y。
System.out.println(x); // 输出 11
System.out.println(y); // 输出 11右++:
后缀递增是指在使用变量之后再将其值加1。这意味着变量的原始值会被先使用,然后变量的值才会增加1。
int x = 10;
int y = x++; // 先将 x 的原始值 10 赋值给 y,然后将 x 的值加 1,变为 11。
System.out.println(x); // 输出 11
System.out.println(y); // 输出 10引申笔试题:
int i = 1;
i = i++;
System.out.println(i);猜猜结果是几,结果是1
这里我解释一下:
- i++是右++,先赋值后++,会先将右边的i的值赋值给i,也就是说左边的i等于1(但表达式还没执行完,所以它会先等着)
- 然后再执行++操作,将i的值变为2,但由于此时赋值操作在刚才已经有结果了,jvm的眼里,i是将要赋值为1的,所以又把i的值赋值为1了
对于JVM而言,它对自增运算的处理,是会先定义一个临时变量来接收i的值,然后进行自增运算,最后又将临时变量赋给了值为2的i,所以最后的结果为1。(若有笔误请联系作者进行修改)
伪代码演示:
int oldValue = i; // 保存 i 的旧值
i = oldValue + 1; // 增加 i 的值
i = oldValue; // 将旧值赋给 i注:左++的话最终结果是为2的,因为先++后赋值嘛
16、方法重载和方法重写的区别
方法重载和方法重写是实现多态性的两种方式。
方法重载:指的是在同一个类中定义多个方法,它们具有相同的名称,但参数却不同(参数个数、参数类型或参数顺序不同)
方法重写:指的是在子类中对父类中已有的方法进行重新定义(方法名、参数列表和返回类型都相同)。重写方法的目的是为了改变或增加父类方法的实现。
实际场景举例:
方法重载:有个最最最常见的例子,封装统一返回函数,当我们接口处理完数据后,要retrun信息给前端,为了接口风格统一,一般都会走统一封装的返回实体类,在这里我们将其命名为 result,其中定义了一个success方法。我们接口返回的时候,有时候是需要返回一些 信息 给前端,有时候不需要。这时我们就可以在 result 实体类中写两个success方法,一个有参数,一个没参数。这样我们写controller的时候只需要调用这个success方法即可,有无参数都可以。能减少代码量,还好理解
public static <T> Result<T> success(T data){Result result = new Result();result.setCode(ResultCode.SUCCESS);result.setErrMsg("");result.setData(data);return result;}public static <T> Result<T> success(){Result result = new Result();result.setCode(ResultCode.SUCCESS);result.setErrMsg("");return result;}方法重写:这个更常见,重写就是重新写一遍的意思。其实就是在子类中把父类本身有的方法重新写一遍。子类继承了父类原有的方法,但有时子类并不想原封不动的继承父类中的某个方法,所以在方法名,参数列表,返回类型(除过子类中方法的返回值是父类中方法返回值的子类时)都相同的情况下, 对方法体进行修改或重写,这就是重写
public class Father {public static void main(String[] args) {Son son = new Son();son.sayHello();}public void sayHello() {System.out.println("Hello");}}
class Son extends Father{@Overridepublic void sayHello() {System.out.println("hello son ");}}注意事项!
service接口和service的实现类中不叫方法重写,那是方法实现
- 重写:指的是子类覆盖父类中的方法,通常发生在继承关系中。
- 实现:指的是实现接口中的方法,通常发生在接口和实现类之间。
17、访问修饰符public、private、protected、以及不写(默认)时的区别?
Java中,可以使用访问控制符来保护对类、变量、方法和构造方法的访问。
Java 支持 4 种不同的访问权限。
- private:在同一类内可见。可以修饰变量、方法。注意:不能修饰类(外部类)
- default (即默认,什么也不写):在同一包内可见,不使用任何修饰符。可以修饰 类、接口、变量、方法。
- protected:对同一包内的类和所有子类可见。可以修饰变量、方法。注意:不能修饰类(外部类)。
- public:对所有类可见。可以修饰类、接口、变量、方法
可见性:
| 修饰符 | 本类 | 同包 | 子类 | 其他包 |
|---|---|---|---|---|
| public | √ | √ | √ | √ |
| protected | √ | √ | √ | × |
| default | √ | √ | × | × |
| private | √ | × | × | × |
18、equals 与 == 的区别
- == 用于基础数据类型时,是用来比较两个变量的值是否相等的,而对于引用类型来说,是用来比较两个对象的引用是否相同的。
- equals 默认是比较两个对象的引用是否相同的,但大部分时候都会被重写为比较两个对象的值是否相同。
例如,对于 Object 来说,== 和 equals 都是一样的,都是用来对比两个对象的引用是否相同的,而 String 或Integer 等类中,又重写 equals 让其变成了比较值是否相同(而非引用是否相同)。所以,我们通常会使用 == 来对比两个对象的引用是否相同,而使用 equals 对比两个值是否相同(前提条件是重写了 equals 方法)。
实际使用场景:
除了完全不牵扯到对象的比较时,比如 5 == 4 这样子,用双等号,其余情况比较对象的字段值时都建议用equals。
假如user是个实体类的对象
比较如下:
"张三".equals(user.getUserName)user.getEge().equals(60)user.getUserName.equals(newUser.getUserName)如果直接 "张三" == user.getUserName 大概率会出问题,因为实际比较的是引用
19、final、finally、finalize的区别
final、finally、finalize 是 Java 中三个不同的关键字,除此之外毫无关系
它们三个的区别就好像 老婆 和 老婆饼 的区别。除了长得像之外,其他的作用和含义完全不同
final、finally、finalize 的区别如下:
final:直译为最终的,表示不可变性,用于修饰类、方法和变量。
- 当用于类时,表示该类不能被继承(字面理解,最终的类嘛,既然都最终了,肯定不能被继承);
- 当用于方法时,表示该方法不能被子类重写(覆盖);
- 当用于变量时,表示该变量的值不能被修改(成为常量)。
- final 关键字提供了不可变性的特性,用于约束一些不希望被修改或继承的类、方法和变量。
finally:用于定义在 try-catch 结构之后的一个代码块。无论是否有异常抛出,finally 块中的代码都会被执行。它通常用于释放资源或执行一些必须在代码块结束时执行的清理工作,例如关闭数据库连接、释放文件锁等。
finalize:0biect 类的一个方法,用于在对象被垃圾回收之前执行一些清理工作。Java 允许在对象被垃圾回收之前执行特定的操作,finalize 方法就提供了这样的机制。但需要注意的是,由于垃圾回收的时机是不确定的, finalize 方法的执行时间也是不确定的,因此一般不推荐使用 finalize 方法,并且在 JDK9 开始被标记为deprecated(弃用)。
所以:
- final是用于修饰类、方法和变量,表示最终的,不可变性;
- finaly 保证关键代码块无论是否捕获到异常,都会被执行;
- finalize 是 Object 类的方法,用于在对象被垃圾回收之前进行清理。
代码都比较简单,所以此处就不举例了,有忘记的同学可以使用gpt自己生成一下举例代码
20、try catch finally,try中有return,finally还会执行么
结论:执行,并且finally的执行早于try里面的return
- 不管有木有出现异常,finally块中代码都会执行;
- 当try和catch中有return时,finally仍然会执行;
- finally是在return后面的表达式运算后执行的,但是早于真正return前(此时并没有返回运算后的值,而是先把要返回的值保存起来,管finally中的代码怎么样,返回的值都不会改变,任然是之前保存的值),所以函数返回值是在finally执行前确定的;
- finally中最好不要包含return,否则程序会提前退出,返回值不是try或catch中保存的返回
21、String、StringBuilder、StringBuffer有什么区别?
String、StringBuilder 和 StringBufer 都是 Java 语言中,用于操作字符串的类,但它们在性能、可变性和线程安全性方面有一些区别。
string:不可变字符串类,也就是说一旦创建,它的值就不可变。
- String是只读字符串,它并不是基本数据类型,而是一个对象
- 从底层源码来看是一个final类型的字符数组,所引用的字符串不能被改变
- 每次对 String 进行拼接、裁剪等操作时,都会创建一个新的 String 对象,所以它的这些操作效率不高。
- 但由于其不可变性,String 可以保证线程安全,适用于字符串不经常变化的场景。
StringBuffer:线程安全的可变字符串类,它解决了 String 字符串拼接、裁剪的问题,它提供了对字符串进行操作的方法 append 或 insert 方法,可以将字符串添加到末尾或指定位置,并且它不会创建新字符串。并且StringBuffer 是线程安全的,适用于多线程环境下对字符串的操作,其诞生于 JDK 1.0。
StringBuilder:非线程安全的可变字符串类,与 StringBuffer 类似,但是它去掉了线程安全的部分,有效减3.小了开销,是绝大部分情况下进行字符串拼接的首选,它诞生于 JDK 1.5。
22、String底层是如何实现的
String 底层是基于数组实现的,并且数组使用了 final 修饰,不同版本中的数组类型也是不同的!
- JDK9之前(不含 JDK 9),String 类是使用 char[ ] (字符数组)实现的。
- 但JDK9之后,String 使用的是 byte[ ] (字节数组)实现的。
注:1个字符(char)=2个字节(byte)。
JDK9之后,之所以使用 byte[ ] 替换 char[ ] 数组,这是因为,byte 类型粒度更细,1个 char 等于2个 byte。对于大部分的英文字符和少量中文字符来说,使用1个 byte就够了,完全不需要使用1个char 进行存储,所以 JDK9使用 byte[ ] 之后,对于大部分英文字符来说,同样的内容,其存储空间减少了一半,这就是 JDK9之后使用 byte[ ] 所带来的优势。
- 注:我没见过1个字节的中文字符哈哈,但我还是保守一点,写了个少量
- 注:不同编码集下字符占字节的大小是不同的,不要犟
注:String初始化后,在使用前一定要赋值(哪怕赋值个 null 也行),不然会报错,但是不使用的话不赋值也是可以的
23、String的 ”+“ 操作如何实现的(String拼接字符串是如何实现的)
在我们使用String的加号拼接字符串时,Java编译器会对我们的代码进行优化,底层变为使用 StringBuilder 的 append 方法
String name = "张三";
int age = 30;
String s = "姓名:" + name + ",年龄:" + age;编译后的代码(简化版):
StringBuilder sb = new StringBuilder();
sb.append("姓名:").append(name).append(",年龄:").append(age);
String s = sb.toString();24、Java是值传递还是引用传递?
值传递 和 引用传递 是关于参数传递方式的两个概念
- 值传递:将传递参数的值,复制一份到方法的参数中。换句话说,值传递的是原始数据的一个副本,而不是原始数据本身。
- 引用传递:类似于C嘎嘎中的指针,将实际参数的引用(内存地址)传递给方法,这意味着方法内部对参数的修改会影响原始数据本身
也就是说引用传递传递的是原始数据,而非原始数据的副本。也就是说,值传递和引用传递最大的区别是传递的是自身,还是复制的副本,如果传递的是自身则为引用传递,如果传递的是复制的副本则为值传递。
而在 Java 语言中,只有值传递,没有引用传递!
注意,全体目光向我看齐
- 既然Java中都是值传递,那是不是我传对象时,修改对象的属性值,对原对象没有影响呢?
- 答案: 不是的 !
这就牵扯到另一个概念,引用副本
引用副本指向与原始引用相同的对象,但它是独立的
当Java传递对象(包含数组)时,传递的是引用副本
- 仅进行对象值的修改的话,是会对原对象造成影响的,原对象的值也会被修改,因为都是一个引用嘛
- 但进行扩容、重新赋值对象引用等时,这个引用副本就会指向一个新的地址,来防止对原引用的修改!
public class ReferencePassingExample {public static void main(String[] args) {MyObject obj = new MyObject(5);// 传递引用副本modifyObject(obj);System.out.println("After method call: " + obj.getValue()); // 输出 10// 传递引用副本,然后在方法内部重新赋值obj.setValue(5);reassignObject(obj);System.out.println("After reassignment: " + obj.getValue()); // 输出 5}// 修改对象的状态public static void modifyObject(MyObject obj) {obj.setValue(10);}// 重新赋值对象引用public static void reassignObject(MyObject obj) {obj = new MyObject(20);}
}class MyObject {private int value;public MyObject(int value) {this.value = value;}public int getValue() {return value;}public void setValue(int value) {this.value = value;}
}25、抽象类和接口有什么区别?
- 抽象类通过 abstract 定义,子类通过 extends 继承
- 接口通过 interface 定义,子类通过 implements 实现
接口和抽象类都是用来定义对象公共行为的,二者的主要区别有以下几点不同:
- 类型扩展不同:抽象类是单继承,而接口是多继承(多实现)
- 方法/属性访问控制符不同:抽象类方法和属性使用访问修饰符无限制,只是抽象类中的抽象方法不能被 private 修饰;而接口有限制,接口默认的是 public 控制符,不能使用其他修饰符
- 方法实现不同:抽象类中的普通方法必须有实现,抽象方法必须没有实现;而接口中普通方法不能有实现(JDK8 中 default 默认方法可以有实现)
- 使用目的不同:接口是为了定义规范,而抽象类是为了复用代码
还有以下几点:
- 抽象类可以包含抽象方法和非抽象方法,接口只能包含抽象方法(JDK8+可以有默认方法和静态方法),默认方法用 default 修饰。
- 这里需要区分一下非抽象方法和默认方法,"非抽象方法" 并不是一个独立的概念,而是一个更加广泛的术语,可以包括抽象方法、默认方法以及普通的实例方法
- 抽象类可以有成员变量,但是接口中不能有成员变量(JDK8+可以有静态常量)
- 抽象类可以有构造方法,但接口不能有构造方法
抽象类是通过 abstract 关键字来定义的,用于表示一种抽象的类
抽象类的主要特征有以下几个:
- 通过 abstract 关键字来定义
- 抽象类不能被实例化,只能作为其他类的父类来继承和扩展使用
- 抽象类可以包含具体方法的实现,也可以包含抽象方法的定义
注:其他方面的特性,抽象类和普通类并无太大差别
使用抽象类是用了复用代码,而使用接口是为了定义规范。
总结如下:
它和接口的区别主要体现在:类型扩展不同、方法/属性访问控制符不同、方法实现不同,以及使用目的不同
详细讲解:Java中抽象类和接口有什么区别?_在 java 抽象类和接口有什么区别-CSDN博客
个人嘀咕:实际开发中抽象类真的很少很少很少用到
26、深克隆和浅克隆有什么区别?
也可以叫做,深拷贝和浅拷贝
克降是指创建一个对象的副本,使副本具有与原始对象相同的属性和状态。
克隆又分为深克隆和浅克隆:
深克隆 是指创建一个新的对象,并且将原对象的所有属性(包括引用类型和基本类型)都复制到新对象中。这意味着对于原对象中的每一个对象属性,都会创建一个新的副本,并且将该副本赋值给新对象。因此,深克隆后的新对象与原对象没有任何依赖关系。
浅克隆 是指创建一个新的对象,并且将原对象的所有基本类型的属性复制到新对象中,而对于引用类型的属性,则只是将原对象的引用类型的属性的引用地址复制给新对象。因此,新对象和原对象会共享引用类型属性的数据。简单来说就是浅克隆只会复制原型对象,但不会复制它所引用的对象。
深克降和浅克隆的主要区别:深克隆会复制原型对象和它所引用所有对象,而浅克隆只会复制原型对象。

27、Exception 与 Error 有什么区别
Exception 和 Error 都是继承于 Throwable 的子类
- Exception 是由应用程序引起可处理、可恢复的异常
- Error 是由 JVM 引起,不可恢复的错误
它们的区别主要体现在:异常级别不同、来源不同、代码处理方式不同,以及对程序的影响程度不同等方面。
Exception 和 Error 都是继承了 Throwable 类,在 Java 中只有 Throwable 类型的实例才可以被抛出(throw)或者捕获(catch),它是异常处理机制的基本组成类型。
它们的区别主要有以下几点:
级别不同:Exception 是表示可恢复的异常情况,而 Error 表示不可恢复的严重错误。
来源不同:Exception 通常由应用程序代码引起,表示可预料的异常情况,如输入错误、文件不存在等。而 Error 通常由 Java 虚拟机(JVM)引起,表示严重的系统层面的错误(如内存溢出、栈溢出等),通常无法通过代码来处理。
代码处理不同:Exception 通常需要程序员在代码中明确地捕获并处理,以防止应用程序的崩溃或异常终止,而 Error 通常是无法通过代码处理的,它表示系统出现了严重的问题,无法恢复。
程序影响不同:Exception 是一种正常的控制流程,可能会影响应用程序的正常执行,但不会导致应用程序终止。而 Error 是一种严重的问题,可能会导致应用程序的崩溃或终止。
总的来说,Exception 表示可以通过代码处理的可恢复的异常情况,通常由应用程序引起,而 Error 表示不可恢复的严重错误,通常由 Java 虚拟机(JVM)引起,无法通过代码处理。
28、深入学习 异常Exception
Java可抛出(Throwable)的结构分为两种类型,Exception 和 Error
Exception 又分为可检査(checked)异常和运行时异常(运行时异常又叫不检査(unchecked)异常),可检查异常在源代码里必须显式地进行捕获处理,这是编译期检查的一部分。
- 可检查(checked)异常:是指在编译时必须显式处理或声明的异常。这些异常是 Exception 类的子类,但不包括 RuntimeException 及其子类。可检査异常例如 Thread.sleep()抛出的InterruptedException 还有常见的数据库操作发生异常时抛出的异常 SQLException。
- 运行时异常(RuntimeException):就是所谓的不检查(unchecked)异常,类似NullPointerException、ArrayIndexOutOfBoundsException 之类,通常是可以编码避免的逻辑错误,具体根据需要来判断是否需要捕获,并不会在编译期强制要求。
运行时异常的定义:RuntimeException及其子类都被称为运行时异常。
常见的运行时异常举例:
- ClassCastException 类转换异常
- IndexOutOfBoundsException 数组越界
- NullPointerException 空指针异常
- ArrayStoreException 数据存储异常,操作数组是类型不一致
- ArithmeticException 执行算术运算时发生错误,如除以零
29、a=a+b 与 a+=b 有什么区别吗?
+= 操作符会进行隐式自动类型转换,此处a+=b隐式的将加操作的结果类型强制转换为持有结果的类型,而 a=a+b 则不会自动进行类型转换.如:
byte a = 127;
byte b = 127;
b = a + b; // 报编译错误:cannot convert from int to byte
b += a; // b 为 -2
byte,也就是字节类型可以表示数值范围为 -128 ~ 127,127+127明显超过127,所以需要int类型来接受,但是b也是byte类型,就会报错
+= 操作符会对右边的表达式结果强转匹配左边的数据类型,所以没错
以下代码是否有错,有的话怎么改?
short s1= 1;
s1 = s1 + 1;
有错误:short类型在进行运算时会自动提升为int类型,也就是说 s1+1 的运算结果是int类型,而s1是short类型,此时编译器会报错.
正确写法:
short s1= 1;
s1 += 1;
+= 操作符会对右边的表达式结果强转匹配左边的数据类型,所以没错
注:这里有的同学可能会迷惑等式右边为什么short类型相加会自动提升为int类型,这是Java为了确保算术运算的精度和避免数据丢失而设计的一种机制,叫做自动类型提升,下文有讲
30、自动类型转换、强制类型转换、自动类型提升
在Java中,类型转换是一种常见的操作,它涉及到将一种数据类型的值转换为另一种数据类型的值。
根据转换的方式,可以分为自动类型转换(也称为隐式类型转换)、强制类型转换(也称为显式类型转换)和自动类型提升(也称为类型晋升)。
自动类型转换(隐式类型转换)
自动类型转换发生在当一个表达式中包含不同类型的变量或常量时,较小的数据类型会被自动转换为较大的数据类型。这是为了防止数据丢失。(多发生在赋值处)
转换方向:

注:boolean不会与其他任何类型自动转换
int i = 10;
long l = i; // 自动类型转换,int 被转换为 long强制类型转换(显式类型转换)
当需要将一个较大的数据类型转换为较小的数据类型时,需要显式地进行强制类型转换,否则Java编译器会报错,因为它不能确定数据是否会被截断或丢失精度。强制类型转换通常使用括号内的目标类型来表示。
自动类型提升
自动类型提升也是有规则的,比如byte类型不会提升为short类型,最低提升到int类型,但我感觉在面试过程中不值得说,就没写,也少记点东西,感兴趣的小伙伴gpt一下即可
在进行算术运算时,较小的数据类型会被提升为较大的数据类型,以确保所有操作数的类型一致。(多发生在算术运算过程中)
byte a = 10;
byte b = 20;
int sum = a + b; // 自动类型提升,在运算过程中将 byte 类型提升为 int 类型在赋值前,a+b的结果已经是int类型了,所以这里不牵扯自动类型转换
注:赋值过程中的类型转换是自动类型转换,不是自动类型提升
自动类型转换与自动类型提升代码举例:(多思考,应该能分出来区别了)
byte a = 10;
byte b = 20;
long sum = a + b;自动类型提升:
当执行 a + b 时,由于 a 和 b 都是 byte 类型,Java 的自动类型提升规则会将它们提升为 int 类型
自动类型转换:
将 int 类型的结果赋值给 long 类型的变量 sum。这里发生了自动类型转换
注:仔细区分好这两个,会在面试过程中加分
31、Java中的 IO 流
Java中的IO流(Input/Output Streams)是用于处理输入和输出的基本构建块。
Java的IO流提供了一种方便的方式来读取和写入文件、网络数据以及其他形式的数据源。Java中的IO流主要位于 java.io 包中,它包括了一系列用于处理各种数据流的类和接口。
Java 中 IO 流分为几种?
- 按照流的流向分,可以分为输入流和输出流;
- 按照操作单元划分,可以划分为字节流和字符流;
- 按照流的角色划分,可以划分为节点流和处理流。
Java Io 流共涉及 40 多个类,这些类看上去很杂乱,但实际上很有规则,而且彼此之间存在非常紧密的联系, Java I0 流的 40 多个类都是从如下 4 个抽象类基类中派生出来的。
- InputStream/Reader:所有的输入流的基类,前者是字节输入流,后者是字符输入流。
- OutputStream/Writer:所有输出流的基类,前者是字节输出流,后者是字符输出流

注:个人认为,IO流的东西和实际使用的技巧有不少,后续可能会单独出一篇大型博客来详细阐述IO 流这块
32、什么是序列化?什么是反序列化?序列化和IO流的关系?
序列化是将对象的状态转换为字节流的过程,以便可以存储在文件中或在网络中传输。
反序列化就是把二进制流恢复成对象。
为了使一个对象可以被序列化,对象的类必须实现 Serializable 接口。这是一个标记接口,没有方法或字段,但它的存在告诉Java运行时系统该对象可以被序列化。
序列化常用的使用场景就是前后端传输数据时的那个实体类实现序列化

序列化和IO流的关系?
- 序列化和反序列化需要用到输入输出流(IO流),或者说序列化和反序列化是基于IO流实现的
33、为什么类一定要实现Serializable才能被序列化?
首先来说,类一定要实现 Serializable 接口,才能被序列化是 Java 层面的一个规定,如果不这样做,那么在进行序列化时就会报错。
而 Java 这样做的原因是因为,如果默认所有类都能被序列化和反序列化的话,会存在性能和安全性问题:
性能开销:序列化和反序列化操作可能涉及复杂的数据处理和字节转换。如果所有类默认都是可序列化的,会导致在创建对象时会增加额外的开销,包括生成和处理不必要的序列化字节流。
序列化的流程:
- 创建一个 ObjectOutputStream 对象。
- 调用 writeObject 方法,将对象及其属性序列化成字节流。
- 字节流被写入输出流(例如文件、网络连接等)。
反序列化的流程:
- 创建一个 ObjectInputStream 对象。
- 调用 readObject 方法,从输入流中读取字节流,并将其反序列化为对象。
- 强制转换返回的对象为原始类型。
安全性:不是所有类的实例都应该被序列化和传输。一些类可能包含敏感信息,如果默认是可序列化的,可能会导致数据泄露的风险。需要开发者明确指定哪些类可以被序列化,以确保安全性。
使用方法:一般情况下,我们只需要将对应的实体类实现 Serializable 接口,然后在实体类内部写上serialVersionUID即可,,然后实体类的使用和实现接口前的使用一样就行,没有什么特殊操作
private static final long serialVersionUID = 1L;
34、final的用法
- 被final修饰的类不可以被继承
- 被final修饰的方法不可以被重写
- 被final修饰的变量不可以被改变,如果修饰引用,那么表示引用不可变,引用指向的内容可变
- 被final修饰的方法,JVM会尝试将其内联,以提高运行效率
- 被final修饰的常量,在编译阶段会存入常量池中
补充:被 final 修饰的变量也必须显式地赋值
35、static的用法
static 关键字用于声明类的成员(变量、方法、嵌套类)为静态成员。
静态成员不属于任何特定对象,而是属于类本身。这意味着即使没有创建类的实例,也可以访问静态成员。
static关键字的用途如下:
- 静态变量 在整个类的所有实例之间共享。
- 静态方法 可以在没有类实例的情况下被调用。
- 静态初始化块 在类首次被加载时执行。
- 静态内部类 不依赖于外部类的实例。
注:这些内容联想自己写过的代码即可
详细的static用法以及代码举例后续会推出博客
36、什么是反射?为什么需要反射?
反射是指在程序运行时获取和操作类的一种能力。
通过反射机制,可以在运行时动态地创建对象、调用方法、访问和修改属性,以及获取类的信息。
反射的主要目的是使程序能够在编译时不知道类的具体信息的情况下,动态地运行和操作类。它提供了一种机制可以在运行时检查和操作类的信息。
这里举个例子吧,我想要将user1对象的同名属性赋值到user2中,我只需要调用如下方法即可:
BeanUtils.copyProperties(user2, user1)然后经过这段代码后,user2中的属性便有了和user1一样的值
但是他是怎么知道我们有几个成员变量,成员变量都是什么呢?既然不知道,那怎么赋上值呢?
它底层就是通过反射拿到我们的成员变量的,然后进行赋值操作
反射如何用就不在这里展示了,毕竟这只是个面试题博客
后续有空会考虑专门出一期大型博客介绍反射,包括更详细的底层原理和如何使用
这里有个稍微比现在这个详细的,有讲解如何使用反射:
什么是反射?为什么需要反射?_为什么要用反射-CSDN博客
需要反射的主要原因有以下几个:
- 动态性:反射使得程序能够在运行时动态地创建对象、调用方法和访问属性,而不需要在编译时提前知道这些类的具体信息。例如,动态代理,动态代理是需要在程序运行期间生成代理的一种机制,而这种机制因为在程序运行期间才会创建和使用,所以有了反射,才能帮其完成动态代理的功能。
- 通用性:很多类库和框架都是使用反射来实现通用的、可扩展的和灵活的功能的。例如,依赖注入、ORM(对2.2象关系映射)等技术都依赖于反射来实现。还有企业中广泛使用的 MyBaits Plus(MyBaits 增强框架),也是利用反射来生成业务表的通用增、删、改、查的方法的。
37、反射的应用场景
反射的应用场景太多太多了,可以说Java根本离不开反射,包括最知名的动态代理底层也是依赖反射实现的。
最典型的使用场景,Spring 中的 AOP、声明式事务、MyBatis/MyBatis Plus 中的分页插件、Dubbo、Openfeign (这些都用到了动态代理,只要用到了动态代理就用到了反射)。
38、反射机制的优点和缺点
优点:
- 能够运行时动态获取类的实例,提高灵活性;
- 与动态编译结合
缺点:
- 使用反射性能较低
- 不安全,不正确使用反射可能会导致安全漏洞,例如暴露敏感信息或执行未授权的操作。毕竟本来不能得到的类的信息可以通过反射拿到了
39、为什么反射执行比较慢?
反射执行慢的主要原因是反射涉及到了运行时类型检査、访问权限检查、动态方法调用和临时对象的创建以及未经过编译器的优化等,这些操作都会导致反射的执行比较慢。
具体来说,反射的执行要经历以下过程:
- 运行时类型检查:在使用反射时,需要在运行时进行类型检査,以确保调用的方法、访问的属性等是有效的。这涉及到了额外的运行时判断和类型转换。
- 访问权限检查:Java 的反射机制可以突破访问权限的限制,可以访问私有的方法、属性等。因此,在执行反射操作时,需要进行额外的权限检查和处理,这会带来额外的开销。
- 方法调用的动态性:对于通过反射调用的方法,需要在运行时动态地解析方法的签名,并确定要调用的具体方法。这需要进行方法查找和动态绑定的过程,相对于直接调用方法而言更为耗时。
- 临时对象的创建:反射会导致对象的多次创建和临时对象的产生,这在某些情况下可能会引起额外的开销。反射操作一般不会被 JVM 的即时编译器优化,也没有缓存和重用,所以也会比较慢。
- 禁止的编译器优化:由于反射是在运行时进行的,而不是在编译时,这意味着编译器无法进行静态优化和代码优化。导致反射的执行效率相对较低。
将上面的说完之后,可以补上下面这段口语化描述,这样给面试官的感觉更像咱自己加以思考的:
这里我再对禁止的编译器优化补充一下,Java这门语言的好处之一就是无论干啥,都有前人优秀的封装,这使得我们不必太考虑底层的实现。拿String类型得的加号拼接举例,众所周知,String是不可变类型,如果真就像我们所写的加号拼接的代码,它至少涉及三个对象的创建和销毁,甚至拼接的字符串多的话,涉及n个对象的创建和销毁,这无疑是极其消耗性能的。但这里的代码,我们编译器是进行优化了的,String的加号拼接底层变为使用 StringBuilder 的 append 方法。而StringBuilder是可变类,无论再多的加号拼接,它也只涉及一个对象的创建和销毁,无疑大大提高了性能。所有编译器优化对于Java这门语言是至关重要的。而反射本来就因为临时对象的创建等原因导致性能低,然后编译器还不能对其优化,这就更低了。
以上这段话偏口语,要的就是这种效果,给面试官我们在思考的感觉。小kiss
40、代理模式——静态代理和动态代理
首先,代理模式是设计模式中的一种。为什么要在这篇博客中讲述代理模式,是因为代理模式和反射离不开关系,防止面试官提问完反射后紧跟着静态代理和动态代理,所以在此处也简单讲一下
后续会出一篇专门的博客讲述所有的设计模式
什么是代理?
- 代理是一种设计模式,它为其他对象提供一个代理对象来控制对这个对象的访问。代理模式的主要目的是拦截对象访问、执行一些额外的操作,比如日志记录、权限检查等,并将调用转给目标对象。
- 这个代理对象可能是替身或占位符等等
- 代理对象充当了真实对象的中间人,从而可以在访问真实对象的前后流程中,添加一些额外的逻辑。
这个额外的逻辑就引出了代理模式的应用场景:
- Spring 中的 AOP、声明式事务、MyBatis/MyBatis Plus 中的分页插件、Dubbo、Openfeign 都是动态代理的典型使用场景。
为什么有这些应用场景,因为我们能通过代理对象间接访问原对象,那既然拿到了原对象,我们当然能做一些对该对象的操作和统一功能处理(注:其实这些应用场景基本都是动态代理的应用场景)
代理模式的优缺点
优点:
- 控制访问:代理模式允许代理对象控制对真实对象的访问。这可以用于实现访问控制、权限验证等
- 增加附加功能:代理对象可以在调用真实对象的方法之前或之后执行额外的操作,例如记录日志、性能优化缓存等。
- 保护隐私:代理模式可以用于隐藏真实对象的内部细节,以保护其隐私和安全性。
缺点:
- 复杂性增加:引入代理对象可能会增加代码复杂性,因为需要创建和维护额外的类
- 性能损失:代理模式可能引入性能开销,特别是在代理对象需要执行额外操作的情况下
注:优缺点这里根据自己能想到的应用场景口述即可,尽量不要背!
在java中,代理的实现方式分为 静态代理 和 动态代理
与其说代理离不开反射,不如说 动态代理 离不开反射!动态代理的底层是依赖反射实现的
静态代理
静态代理是在编译时期就已经定义好的代理类。这意味着需要手动编写代理类,通常情况下,代理类和被代理的类会实现相同的接口。
静态代理需要提前写好代理类,而且是每个业务类都要对应一个代理类,所以缺点显而易见,特别不灵活,也不方便。
静态代理的实现比较麻烦,需要事先写好代理类,并且为每个代理对象都事先写好代理类,所以比较麻烦,目维护性较差。
代码如下:
假设有一个接口Subject和其实现类RealSubject:
public interface Subject {void doSomething();
}public class RealSubject implements Subject {public void doSomething() {System.out.println("Doing something...");}
}接下来,我们创建一个静态代理类 StaticProxy,该类也实现了 Subject 接口,并且在其方法中调用了 RealSubject 的相应方法:
public class StaticProxy implements Subject {private RealSubject realSubject;public StaticProxy(RealSubject realSubject) {this.realSubject = realSubject;}@Overridepublic void doSomething() {System.out.println("Before doing something...");realSubject.doSomething(); // 调用真实主题的方法System.out.println("After doing something...");}
}最后,我们在 main 方法中创建 RealSubject 和 StaticProxy 的实例,并调用方法:
public class Main {public static void main(String[] args) {RealSubject realSubject = new RealSubject();StaticProxy proxy = new StaticProxy(realSubject);proxy.doSomething();}
}当运行这段代码时,输出将会是:
Before doing something...
Doing something...
After doing something...可以很清楚的看到,静态代理是为当前类量身定做的,无法通用,所以实际场景下基本都是动态代理
动态代理
动态代理是一种在运行时动态生成代理对象的技术。它可以在不修改原始类的情况下,对原始类的方法进行拦截和增强。
动态代理是在程序运行期,动态的创建目标对象的代理对象,并对目标对象中的方法进行功能性增强的一种技术
java中动态代理的底层实现主要依赖于 Java 的反射机制实现的。Java 的反射机制允许程序在运行时动态地获取类的信息(如成员变量、方法、构造函数等),并在运行时调用对象的方法或创建对象,如下源码所示:
首先,定义一个接口 Subject:
public interface Subject {void doSomething();
}然后,创建一个实现了 Subject 接口的类 RealSubject:
public class RealSubject implements Subject {@Overridepublic void doSomething() {System.out.println("Doing something...");}
}接下来,我们需要创建一个实现了 InvocationHandler 接口的类 DynamicProxyHandler,它将在方法调用时被调用:
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;public class DynamicProxyHandler implements InvocationHandler {private Object target;public DynamicProxyHandler(Object target) {this.target = target;}@Overridepublic Object invoke(Object proxy, Method method, Object[] args) throws Throwable {System.out.println("Before method call");Object result = method.invoke(target, args); // 调用实际对象的方法System.out.println("After method call");return result;}
}最后,我们创建一个动态代理对象并使用它:
import java.lang.reflect.Proxy;public class Main {public static void main(String[] args) {RealSubject realSubject = new RealSubject();DynamicProxyHandler handler = new DynamicProxyHandler(realSubject);// 创建动态代理对象Subject subjectProxy = (Subject) Proxy.newProxyInstance(realSubject.getClass().getClassLoader(), // 类加载器realSubject.getClass().getInterfaces(), // 接口列表handler // InvocationHandler实例);subjectProxy.doSomething();}
}当运行这段代码时,输出将会是:
Before method call
Doing something...
After method call在这段动态代理的代码中,反射主要用于以下几个方面:
1、创建动态代理类
- 使用 Proxy.newProxyInstance 方法创建动态代理对象时,实际上是在运行时动态生成了一个实现了指定接口的新类。这个新类是由JVM通过反射机制生成的,它会在内存中创建一个新的类文件,并实现我们指定的接口。
2、调用方法
- 在 DynamicProxyHandler 类的 invoke 方法中,我们使用了 Method.invoke 方法来调用目标对象上的方法。Method.invoke 是反射API的一部分,它允许我们在运行时调用对象的方法。
可以明显地看到,这个动态代理的代理对象可以通用!
所以,实际上java都是使用的动态代理,而不是静态代理
动态代理的应用场景如下:
- Spring 中的 AOP、声明式事务、MyBatis/MyBatis Plus 中的分页插件、Dubbo、Openfeign 都是动态代理的典型使用场景。
动态代理的优缺点:
动态代理提供了高度的灵活性和可扩展性,适合于需要在运行时动态添加行为的场景。然而,它也可能带来一定的性能开销和调试复杂性。因此,在决定是否使用动态代理时,需要权衡应用程序的具体需求和上下文。
41、什么是泛型?为什么要有泛型?
泛型是一种编程范式,其核心思想是将类型参数化,即把数据类型作为参数传递。通过泛型,可以创建灵活且可重用的代码,而无需针对每种数据类型都编写重复的代码。
泛型的主要优点包括提高代码的可读性、可维护性和类型安全性。
泛型的应用场景无处不在,比如我们常用的list集合,它接收的参数就是泛型。还有咱后端返回前端的统一返回结果实体类,也经常将参数类型接收为泛型。
可以想到,如果不用泛型,每一种类型的参数都要定义与之对应的方法,这是多么麻烦还容易出现错误的情况。
这里就不再多说了,也偏口语化。毕竟泛型重点就是用!而不是复杂的八股
42、什么是枚举?枚举的使用场景
枚举这个玩意背八股还是不太行,建议多用,多用之后再回头看这方面的八股,基本就没啥问题了
枚举类型是Java 5中新增特性的一部分,它是一种特殊的数据类型,之所以特殊是因为它既是一种类(class)类型却又比类类型多了些特殊的约束,但是这些约束的存在也造就了枚举类型的简洁性、安全性以及便捷性。
枚举(enum)是一种特殊的类,用于表示一组固定的常量值。枚举类型可以用来定义一个有限的值集合,并且可以为这些值添加方法和属性。
直接看以下代码:
- Red、GREEN、BLUE、YELLOW是枚举常量
- name和index是每个枚举常量的成员变量
Coler类似于类,然后这个类中有两个成员变量,name和index,只不过这两个变量要依赖枚举常量存在,每个枚举常量都有与之对应的成员变量值,枚举常量类似对象
public enum Color { RED("红色", 1), GREEN("绿色", 2), BLUE("蓝色", 3), YELLOW("黄色", 4); // 成员变量 private final String name; private final int index; // 构造方法 private Color(String name, int index) { this.name = name; this.index = index; } // 普通方法 public static String getName(int index) { for (Color c : Color.values()) { if (c.getIndex() == index) { return c.getName(); } } return null; } // get 方法 public String getName() { return name; } public int getIndex() { return index; }
}使用这个枚举示例代码:
可以看到,通过 枚举类.枚举常量.成员变量 可以拿到对应的值
public class Main {public static void main(String[] args) {// 使用枚举常量System.out.println("RED: " + Color.RED.getName() + ", Index: " + Color.RED.getIndex());System.out.println("GREEN: " + Color.GREEN.getName() + ", Index: " + Color.GREEN.getIndex());System.out.println("BLUE: " + Color.BLUE.getName() + ", Index: " + Color.BLUE.getIndex());System.out.println("YELLOW: " + Color.YELLOW.getName() + ", Index: " + Color.YELLOW.getIndex());// 使用静态方法获取名称int index = 3;String name = Color.getName(index);if (name != null) {System.out.println("Name of color with index " + index + " is: " + name);} else {System.out.println("No color found with index " + index);}// 使用枚举常量的索引index = 2;for (Color color : Color.values()) {if (color.getIndex() == index) {System.out.println("Color with index " + index + " is: " + color.getName());break;}}}
}输出:
RED: 红色, Index: 1
GREEN: 绿色, Index: 2
BLUE: 蓝色, Index: 3
YELLOW: 黄色, Index: 4
Name of color with index 3 is: 蓝色
Color with index 2 is: 绿色43、Lambda表达式
Lambda 表达式是 Java 8 引入的一个重要特性,它允许你以一种简洁的方式来表达匿名函数(即没有名字的函数)。
Lambda 表达式本质上是一段匿名内部类,也可以是一段可以传递的代码。
比如以前我们用 Runnable 创建一个新线程,不使用Lambda表达式:
new Thread(new Runnable() {@Overridepublic void run() {System.out.println("Thread is running before Java8!");}
}).start();使用Lambda表达式后:
new Thread(() -> {System.out.println("Thread is running with Java8!");
}).start();让我们来看一下为什么可以简化:
- 简化语法:Lambda 表达式提供了一种更简洁的方式来定义一个方法体。对于 Runnable 接口来说,它只需要实现一个 run 方法。使用 Lambda 表达式,你可以直接写 () -> { ... } 而不是 new Runnable() { ... }。
- 类型推断:Java 编译器能够根据上下文推断出 Lambda 表达式所代表的类型。在创建线程的例子中,编译器知道你需要一个 Runnable 对象,因此它会自动将 Lambda 表达式转换成 Runnable 类型的对象。
- 减少样板代码:传统的匿名内部类方式需要你写出整个类定义(包括 new Runnable() 和 { @Override public void run() { ... } }),而 Lambda 表达式则消除了这种冗余,使代码更加简洁。
Lambda 表达式的特点
- 简洁性:Lambda 表达式简化了函数式编程的表达方式,使得代码更易于阅读和编写。
- 延迟执行:Lambda 表达式通常是在需要的时候才被调用执行。
- 函数式接口:Lambda 表达式只能用于 SAM 接口,但为了方便使用,Java 8 引入了一系列函数式接口,如 Function, Predicate, Consumer 等,这些接口可以方便地与 Lambda 表达式一起使用。
- 可传递性:Lambda 表达式可以像普通对象一样传递。
当然不是每个接口都可以缩写成 Lambda 表达式。只有那些函数式接口(Functional Interface)才能缩写成 Lambda 表示式。
函数式接口(Functional Interface)是指一个接口中只声明了一个抽象方法的接口。这样的接口非常适合用来作为 Lambda 表达式的类型。
再说函数式接口估计很多同学更懵了,需要用大量篇幅解释,又考虑本章节是面试题专栏,所以点到为止。不懂的家人们可以去学习一下,都是Java8的特性,函数式接口、Lambda表达式以及Stream流,学起来包费劲的哈哈
45、Stream流
在 Java 8 中,StreamAPI 是对集合数据进行操作的一种新的方式。它提供了对数据集合(如Collection 类型)进行各种操作的能力,如搜索、过滤、映射、排序、聚合等。(Stream流也是 Java 8 引入的一个重要特性)
StreamAPI 的设计灵感来源于函数式编程语言,它允许你以一种声明式的方式来处理数据。
这里简单介绍几种用法:
①、过滤并打印
List<String> names = Arrays.asList("Alice", "Bob", "Charlie", "David");names.stream().filter(name -> name.startsWith("C")).forEach(System.out::println);此代码会打印出名字以 "C" 开头的所有元素。
②、排序和限制
List<String> names = Arrays.asList("Alice", "Bob", "Charlie", "David");names.stream().sorted().limit(2).forEach(System.out::println);此代码按字母顺序排序名字,并只打印前两个名字。
Stream流的特点
- 懒加载:中间操作是懒加载的,即它们不会立即执行,直到遇到一个终止操作才会触发整个流水线的执行。
- 管道化:可以将多个操作链接起来形成一个管道,每个中间操作都可以链接到另一个操作。
- 内部迭代:与传统的集合迭代不同,StreamAPI 使用内部迭代机制,即由 Stream 自身控制迭代过程,而不是外部代码。
🚀欢迎大家阅读专栏:JAVA崭新面试题——2024版_dream_ready的博客-CSDN博客
🚀有任何问题请评论留言
相关文章:
三万字长文Java面试题——基础篇(注:该篇博客将会一直维护 最新维护时间:2024年9月18日)
🧸本篇博客重在讲解Java基础的面试题,将会实时更新,欢迎大家添加作者文末联系方式交流 📜JAVA面试题专栏:JAVA崭新面试题——2024版_dream_ready的博客-CSDN博客 📜作者首页: dream_ready-CSDN博…...

数学建模——熵权+TOPSIS+肘部法则+系统聚类
文章目录 一、起因二、代码展示 一、起因 我本科的数学建模队长找上我,让我帮她写下matlab代码,当然用的模型还是曾经打比赛的模型,所以虽然代码量多,但是写的很快,也是正逢中秋,有点时间。 当然我也没想到…...

Java | Leetcode Java题解之第403题青蛙过河
题目: 题解: class Solution {public boolean canCross(int[] stones) {int n stones.length;boolean[][] dp new boolean[n][n];dp[0][0] true;for (int i 1; i < n; i) {if (stones[i] - stones[i - 1] > i) {return false;}}for (int i 1…...

828华为云征文|华为Flexus云服务器搭建OnlyOffice私有化在线办公套件
一、引言 在当今数字化办公的时代,在线办公套件的需求日益增长。华为Flexus云服务器凭借其强大的性能和稳定性,为搭建OnlyOffice私有化在线办公套件提供了理想的平台。在2024年9月14日这个充满探索精神的日子里,我们开启利用华为Flexus云服务…...
[Java]maven从入门到进阶
介绍 apache旗下的开源项目,用于管理和构建java项目的工具 官网: Welcome to The Apache Software Foundation! 1.依赖管理 通过简单的配置, 就可以方便的管理项目依赖的资源(jar包), 避免版本冲突问题 优势: 基于项目对象模型(POM),通过一小段描述信息来管理项目的构建 2…...

Leetcode面试经典150题-130.被围绕的区域
给你一个 m x n 的矩阵 board ,由若干字符 X 和 O 组成,捕获 所有 被围绕的区域: 连接:一个单元格与水平或垂直方向上相邻的单元格连接。区域:连接所有 O 的单元格来形成一个区域。围绕:如果您可以用 X 单…...

Ruffle 继续在开源软件中支持 Adobe Flash Player
大多数人已经无需考虑对早已寿终正寝的 Adobe Flash 的支持,但对于那些仍有一些 Adobe Flash/SWF 格式的旧资产,或想重温一些基于 Flash 的旧游戏/娱乐项目的人来说,开源 Ruffle 项目仍是 2024 年及以后处理 Flash 的主要竞争者之一。 Ruffl…...

【postgres】笔记
数据库相关笔记 1.分区表创建时间戳设置问题2.查询语句2.1查询数据库某表有多少行2.2 表中某列值类型是 1.分区表创建时间戳设置问题 今天早上发现postgres数据库表中总会隔4天丢失一天的数据,后来查了一下,发现是分区表创建的有问题。 如图所示 可以看…...

#if等命令的学习
预处理命令 #include(文件包含命令) #define(宏定义命令) #undef #if(条件编译) #ifdef #ifndef #elif #endif defined函数(与if等结合使用) 下面将解释上述各自的用法、使用…...

【有啥问啥】深入浅出马尔可夫链蒙特卡罗(Markov Chain Monte Carlo, MCMC)算法
深入浅出马尔可夫链蒙特卡罗(Markov Chain Monte Carlo, MCMC)算法 0. 引言 Markov Chain Monte Carlo(MCMC)是一类用于从复杂分布中采样的强大算法,特别是在难以直接计算分布的情况下。它广泛应用于统计学、机器学习…...

java企业办公自动化OA
技术架构: sshjbpm 功能描述: 用户管理,岗位管理,部门管理,权限管理,网上交流,贴吧,审批流转。权限管理是树状结构人性化操作,也可以用作论坛。 效果图:...

【leetcode】树形结构习题
二叉树的前序遍历 返回结果:[‘1’, ‘2’, ‘4’, ‘5’, ‘3’, ‘6’, ‘7’] 144.二叉树的前序遍历 - 迭代算法 给你二叉树的根节点 root ,返回它节点值的 前序 遍历。 示例 1: 输入:root [1,null,2,3] 输出:[1,…...

在ros2中安装gazebo遇到报错
安装命令: sudo apt-get install ros-${ROS_DISTRO}-ros-gz 报错如下: E: Unable to locate package ros-galactic-ros-gz 解决方法: 用如下安装命令: sudo apt install ros-galactic-ros-ign 问题解决!...
VMware vSphere 8.0 Update 3b 发布下载,新增功能概览
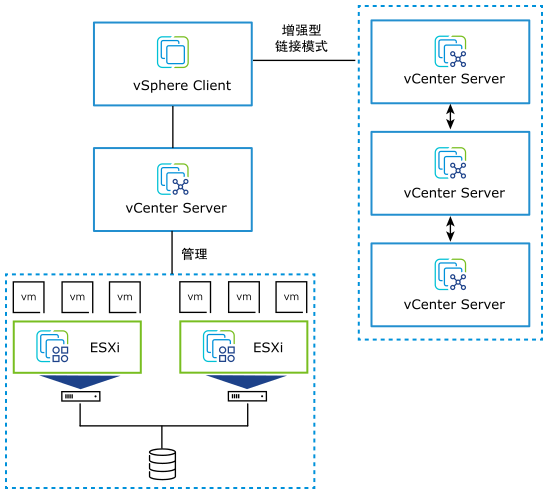
VMware vSphere 8.0 Update 3b 发布下载,新增功能概览 vSphere 8.0U3 | ESXi 8.0U3 & vCenter Server 8.0U3 请访问原文链接:https://sysin.org/blog/vmware-vsphere-8-u3/,查看最新版。原创作品,转载请保留出处。 作者主页…...

在设计开发中,如何提高网站的用户体验?
在网站设计开发中,提高用户体验是至关重要的。良好的用户体验不仅能提升用户的满意度和忠诚度,还能增加转化率和用户留存率。以下是一些有效的方法和策略: 优化页面加载速度 减少HTTP请求:合并CSS和JavaScript文件以减少HTTP请求…...

油耳拿什么清理比较好?好用的无线可视挖耳勺推荐
油耳的朋友通常都是用棉签来掏耳。这种方式是很不安全的。因为使用棉签戳破耳道和棉絮掉落在耳道中而引起感染的新闻不在少数。在使用过程中更加建议大家可视挖耳勺来清理会更好。不仅清晰度得干净而且安全会更高。但最近这几年我发现可视挖耳勺市面上不合格产品很多࿰…...

永久配置清华源,告别下载龟速
为了每次使用 pip 时自动使用清华源,可以通过以下步骤进行配置: 方法一:通过命令行配置 你可以在命令行中运行以下命令来自动设置清华源: pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple此命令会将…...

什么是数据库回表,又该如何避免
目录 一. 回表的概念二. 回表的影响三. 解决方案1. 使用覆盖索引2. 合理选择索引列3. 避免选择不必要的列4. 分析和优化查询5. 定期更新统计信息6. 避免使用SELECT DISTINCT或GROUP BY7. 使用适当的数据库设计 数据库中的“回表”是指在查询操作中,当数据库需要访问…...

UE5中使用UTexture2D进行纹理绘制
在UE中有时需要在CPU阶段操作像素,生成纹理贴图等,此时可以通过UTexture2D来进行处理,例子如下: 1.CPP部分 首先创建一个蓝图函数库,将UTexture2D的绘制逻辑封装成单个函数: .h: #include &…...

Matlab simulink建模与仿真 第十六章(用户定义函数库)
参考视频:simulink1.1simulink简介_哔哩哔哩_bilibili 一、用户定义函数库中的模块概览 注:MATLAB版本不同,可能有些模块也会有差异,但大体上区别是不大的。 二、Fcn/Matlab Fcn模块 1、Fcn模块 双击Fcn模块,在对话…...

Unity Il2CppDumper原理与实战:解析元数据与二进制对齐
1. 这不是“破解工具”,而是Unity开发者该懂的二进制真相课 你刚在Unity Asset Store下载了一个功能惊艳的插件,却在打包iOS后发现部分逻辑失效;或者接手一个没有源码的旧项目,只有一堆 .dll 和 .so 文件,连主入口…...

零基础轻松拿捏!魔珐星云青少年健康运动教学数字人搭建全流程指南
大家好!本次给大家分享一款面向青少年体育教育的AI创意实践项目——青少年健康运动教学智能数字交互系统。本项目聚焦青少年体质健康痛点,围绕体育教学智能化升级需求,打造集健康知识教学、运动动作陪练、健康知识考核、运动能力评测于一体的…...

<背包问题>
背包问题是一类组合优化问题,其基本形式是给定一组物品,每个物品都有一个重量和一个价值,以及一个有限的背包容量,目标是在不超过背包容量的前提下,选择物品使得背包中的物品价值最大化。动态规划是解决背包问题的常用…...

利用FTDI芯片MPSSE模式构建Arduino兼容开发环境
1. 项目概述:当FTDI芯片遇上Arduino生态如果你手头有一些闲置的FTDI USB转串口模块,比如常见的FT232R、FT2232H,或者像我一样,从某个旧设备上拆下来一块FT2232C的老古董,除了用来给单片机烧录程序或者做串口调试&#…...

LPCM框架:大模型驱动的计算机架构设计革命
1. LPCM框架:计算机系统架构设计的范式革命计算机系统架构设计正站在历史性的转折点上。过去八十年来,从ENIAC的真空管到现代7纳米制程的异构计算芯片,架构设计始终遵循着"专家经验EDA工具"的传统范式。但随着摩尔定律逼近物理极限…...

告别坐标点击!用Poco精准定位UI控件,让你的Airtest安卓自动化脚本更稳定
告别坐标点击!用Poco精准定位UI控件,让你的Airtest安卓自动化脚本更稳定每次UI微调就导致脚本大面积失效?分辨率变化让精心编写的自动化测试瞬间崩溃?作为从坐标点击转型到控件识别的实践者,我深刻理解这种挫败感。三年…...

AWS DevOps Agent 完全指南
AWS DevOps Agent 是 AWS 推出的前沿 AI 运维代理,自主调查和解决事件、持续预防故障、提升系统可靠性。本文档覆盖从原理到实战的全生命周期管理。 一、定位与价值 一句话定义 AWS DevOps Agent = AI 驱动的 SRE 队友,724 自主调查告警、定位根因、生成修复方案、预防未来…...

面试官问LinkedBlockingQueue和ArrayBlockingQueue区别?别只答有界无界了,这3个实战坑才是重点
面试官追问LinkedBlockingQueue与ArrayBlockingQueue?别只答基础区别,这3个实战陷阱才是关键 当面试官抛出"LinkedBlockingQueue和ArrayBlockingQueue有什么区别"这个问题时,80%的候选人会条件反射般回答"一个有界一个无界&qu…...

基于A2A协议将智能体注册到Nacos3.x
1.配置和简介Nacos3.x比Nacos2.x多了可以注册智能体的功能。配置密钥,32位即可启动分为集群模式和单机模式,单机模式下,默认存储在derby下。2.智能体注册中心:AgentScope也是自带注册中心的,叫AgentScopeA2aServer。现…...
)
保姆级教程:用Prometheus Operator在K8S里一键搞定监控全家桶(附Grafana仪表盘)
云原生监控革命:用Prometheus Operator构建K8S智能监控体系 当Kubernetes集群规模突破50个节点时,传统监控方案的维护成本会呈指数级增长。我曾亲眼见证一个电商团队在"黑五"大促期间,因为手动配置的Prometheus抓取规则失效&#x…...