python中网络爬虫框架
Python 中有许多强大的网络爬虫框架,它们帮助开发者轻松地抓取和处理网页数据。最常用的 Python 网络爬虫框架有以下几个:
1. Scrapy
Scrapy 是 Python 中最受欢迎的网络爬虫框架之一,专为大规模网络爬取和数据提取任务而设计。它功能强大、效率高,支持异步处理,是数据采集和网络爬虫的首选。
Scrapy 的主要特点:
- 支持异步请求,爬取速度非常快。
- 内置了处理请求、响应、解析 HTML 等常用的功能。
- 可以轻松管理大规模的数据抓取任务。
- 支持扩展功能,如中间件、管道等,方便进行定制化爬取。
Scrapy 使用步骤:
-
安装 Scrapy:
pip install scrapy -
创建项目:
创建一个 Scrapy 项目来组织爬虫代码。scrapy startproject myspider -
编写爬虫:
创建并编写爬虫代码,例如爬取一个简单的 quotes 网站:import scrapyclass QuotesSpider(scrapy.Spider):name = "quotes"start_urls = ['http://quotes.toscrape.com/']def parse(self, response):for quote in response.css('div.quote'):yield {'text': quote.css('span.text::text').get(),'author': quote.css('small.author::text').get(),}next_page = response.css('li.next a::attr(href)').get()if next_page is not None:yield response.follow(next_page, self.parse) -
运行爬虫:
scrapy crawl quotes
Scrapy 的优点:
- 高效:支持异步请求,能同时发起多个请求,加快爬取速度。
- 功能强大:支持数据清洗、持久化、抓取规则配置等功能。
- 可扩展:提供中间件、管道等机制,易于扩展爬虫功能。
2. BeautifulSoup
BeautifulSoup 是一个轻量级的 HTML 和 XML 解析库,虽然不是专门的爬虫框架,但它非常适合用来解析从网页获取的 HTML 数据。通常会与 requests 库配合使用进行网页抓取和数据提取。
BeautifulSoup 的主要特点:
- 容易上手,适合处理静态页面的数据抓取。
- 提供多种方式解析和导航 HTML 结构,支持 CSS 选择器和树形结构的导航。
- 与
requests库搭配,可以手动控制请求和响应处理。
BeautifulSoup 使用步骤:
-
安装 BeautifulSoup 和 requests:
pip install beautifulsoup4 requests -
编写爬虫:
使用requests获取页面内容,用 BeautifulSoup 解析 HTML 数据。import requests from bs4 import BeautifulSoupurl = 'http://quotes.toscrape.com/' response = requests.get(url)soup = BeautifulSoup(response.text, 'html.parser')# 解析并打印网页中的名言 quotes = soup.find_all('span', class_='text') for quote in quotes:print(quote.text)
BeautifulSoup 的优点:
- 简单易用,适合快速处理网页数据。
- 提供灵活的 HTML 解析方法,支持 CSS 选择器和树形搜索。
- 配合
requests可以实现简单的网络爬虫功能。
3. Requests-HTML
Requests-HTML 是一个综合性的网络爬取工具,结合了 requests 库的强大功能和 HTML 解析功能。它能处理静态和部分动态网页。
Requests-HTML 的主要特点:
- 内置的 HTML 解析功能,支持使用 CSS 选择器提取数据。
- 支持异步请求和动态内容的渲染,适合处理简单的 JavaScript 渲染页面。
- 易用的 API,适合快速编写爬虫。
Requests-HTML 使用步骤:
-
安装 Requests-HTML:
pip install requests-html -
编写爬虫:
from requests_html import HTMLSessionsession = HTMLSession() response = session.get('http://quotes.toscrape.com/')# 解析并获取网页内容 quotes = response.html.find('span.text') for quote in quotes:print(quote.text) -
处理动态内容:
Requests-HTML 支持渲染 JavaScript 内容。response = session.get('http://example.com') response.html.render() # 渲染 JavaScript
Requests-HTML 的优点:
- 支持异步请求,性能良好。
- 能够处理部分 JavaScript 渲染的网页,适合一些简单的动态内容抓取。
- API 简单,快速上手。
4. Selenium
Selenium 是一个用于自动化 Web 浏览器的工具,可以用于模拟用户操作,如点击按钮、滚动页面、填写表单等。Selenium 强大之处在于它可以处理高度动态的网页和需要 JavaScript 渲染的内容。
Selenium 的主要特点:
- 支持处理复杂的动态网页。
- 可以模拟用户行为,如点击、输入、导航、滚动等。
- 支持多种浏览器,如 Chrome、Firefox 等。
Selenium 使用步骤:
-
安装 Selenium 和浏览器驱动:
首先需要安装 Selenium 以及浏览器驱动(如 ChromeDriver)。pip install selenium下载 ChromeDriver 或 GeckoDriver 用于驱动浏览器。
-
编写爬虫:
打开浏览器,抓取动态内容。from selenium import webdriver# 设置 Chrome 驱动路径 driver = webdriver.Chrome(executable_path='/path/to/chromedriver')driver.get('http://quotes.toscrape.com/')# 获取页面中的文本 quotes = driver.find_elements_by_class_name('text') for quote in quotes:print(quote.text)driver.quit() -
模拟用户操作:
Selenium 可以自动化用户操作,比如点击按钮。button = driver.find_element_by_xpath('//button') button.click() # 模拟点击操作
Selenium 的优点:
- 强大且灵活,能处理动态内容和模拟复杂的用户行为。
- 支持多种浏览器,适合需要 JavaScript 渲染的复杂网页抓取。
5. Pyppeteer
Pyppeteer 是 Puppeteer 的 Python 版本,适用于处理复杂的动态网页和爬取需要高度 JavaScript 渲染的内容。它底层基于 Chromium 浏览器,适合需要精细控制浏览器的场景。
Pyppeteer 的主要特点:
- 基于 Chromium 浏览器,可以像 Puppeteer 一样控制浏览器进行数据抓取。
- 强大且灵活,适合复杂的 JavaScript 页面。
Pyppeteer 使用步骤:
-
安装 Pyppeteer:
pip install pyppeteer -
编写爬虫:
import asyncio from pyppeteer import launchasync def main():browser = await launch()page = await browser.newPage()await page.goto('http://quotes.toscrape.com/')content = await page.content()print(content)await browser.close()asyncio.get_event_loop().run_until_complete(main())
Pyppeteer 的优点:
- 支持处理高度动态的 JavaScript 渲染网页。
- 可以精细控制浏览器,适合复杂爬虫需求。
总结
在选择 Python 的网络爬虫框架时,应根据具体需求来做选择:
- Scrapy:适合大规模、高效率的网络爬虫项目,内置许多功能,支持异步爬取。
- BeautifulSoup:适合简单的 HTML 解析,结合
requests适合抓取静态网页。 - Requests-HTML:适合快速、轻量地抓取数据,支持动态内容渲染。
- Selenium:适合处理动态页面和需要模拟用户行为的场景。
- Pyppeteer:适合高度复杂的 JavaScript 渲染页面,提供类似 Puppeteer 的浏览器控制功能。
根据你的爬取需求和目标网站的复杂程度,选择合适的工具就能快速开始爬取任务啦!如果有更多疑问或者需要具体代码指导,
相关文章:

python中网络爬虫框架
Python 中有许多强大的网络爬虫框架,它们帮助开发者轻松地抓取和处理网页数据。最常用的 Python 网络爬虫框架有以下几个: 1. Scrapy Scrapy 是 Python 中最受欢迎的网络爬虫框架之一,专为大规模网络爬取和数据提取任务而设计。它功能强大、…...

GEC6818初次连接使用
目录 1.开发板资源接口编辑编辑 2.安装 SecureCRT工具 2.1SecureCRT相关问题 3.连接开发板 4.开发板文件传输 4.1串口传输 rx 从电脑下载文件到开发板 sz 从开发板把文件发送到电脑 4.2U盘/SD卡传输 4.3网络传输[重点] 5.运行传到开发板的可执行文件 6.开发板网络…...

解释下不同Gan模型之间的异同点
生成对抗网络(GAN, Generative Adversarial Network)是一类强大的生成模型。随着时间的推移,研究人员提出了许多不同的 GAN 变体来改善原始模型的性能或针对特定任务进行优化。下面将解释一些常见的 GAN 变体,并讨论它们的异同点。…...

Hadoop的一些高频面试题 --- hdfs、mapreduce以及yarn的面试题
文章目录 一、HDFS1、Hadoop的三大组成部分2、本地模式和伪分布模式的区别是什么3、什么是HDFS4、如何单独启动namenode5、hdfs的写入流程6、hdfs的读取流程7、hdfs为什么不能存储小文件8、secondaryNameNode的运行原理9、hadoop集群启动后离开安全模式的条件10、hdfs集群的开机…...

Day99 代码随想录打卡|动态规划篇--- 01背包问题
题目(卡玛网T46): 小明是一位科学家,他需要参加一场重要的国际科学大会,以展示自己的最新研究成果。他需要带一些研究材料,但是他的行李箱空间有限。这些研究材料包括实验设备、文献资料和实验样本等等&am…...

往证是什么意思
“往证”通常是在数学证明中使用的一种方法,尤其是在证明某个结论的相反(即否定)是错误的情况下。具体来说,就是假设结论不成立,然后通过逻辑推理展示出这种假设导致矛盾,从而得出原结论必然成立。 举例说…...

Camunda流程引擎并发性能优化
文章目录 Camunda流程引擎一、JobExecutor1、工作流程2、主要作用 二、性能问题1、实际场景:2、性能问题描述3、总结 三、优化方案方案一:修改 Camunda JobExecutor 源码以实现租户 ID 隔离方案二:使用 max-jobs-per-acquisition 参数控制上锁…...

spring springboot 日志框架
一、常见的日志框架 JUL、JCL、Jboss-logging、logback、log4j、log4j2、slf4j.... 注意:SLF4j 类似于接口 Log4j ,Logback 都是出自同一作者之手 JUL 为apache 公司产品 Spring(commons-logging)、Hibernate(jboss…...

【D3.js in Action 3 精译_022】3.2 使用 D3 完成数据准备工作
当前内容所在位置 第一部分 D3.js 基础知识 第一章 D3.js 简介(已完结) 1.1 何为 D3.js?1.2 D3 生态系统——入门须知1.3 数据可视化最佳实践(上)1.3 数据可视化最佳实践(下)1.4 本章小结 第二章…...

电脑怎么禁用软件?5个方法速成,小白必入!
电脑禁用软件的方法多种多样,以下是五种简单易行的方法. 适合不同需求的用户,特别是电脑小白。 1. 使用任务管理器禁用启动项 操作步骤:按下“Ctrl Shift Esc”组合键,打开任务管理器。 切换到“启动”选项卡,找到…...

力扣之181.超过经理收入的员工
文章目录 1. 181.超过经理收入的员工1.1 题干1.2 准备数据1.3 题解1.4 结果截图 1. 181.超过经理收入的员工 1.1 题干 表:Employee -------------------- | Column Name | Type | -------------------- | id | int | | name | varchar | | salary | int | | mana…...

C++语法应用:从return机制看返回指针,返回引用
前言 编程是极其注重实践的工作,学习的同时要伴随代码 引入 此前对返回指针和引用有一些纠结,从return角度来观察发生了什么。 return机制 函数中return表示代码结束,如果return后面有其他代码将不被执行。 return发生了值转移,return后面的…...

Linux5-echo,>,tail
1.echo命令 echo是输出命令,类似printf 例如:echo "hello world",输出hello world echo pwd,输出pwd的位置。是键盘上~ 2.重定向符> >> >指把左边内容覆盖到右边 echo hello world>test.txt >…...

sqlgun靶场训练
1.看到php?id ,然后刚好有个框,直接测试sql注入 2.发现输入1 union select 1,2,3#的时候在2处有回显 3.查看表名 -1 union select 1,group_concat(table_name),3 from information_schema.tables where table_schemadatabase()# 4.查看列名…...
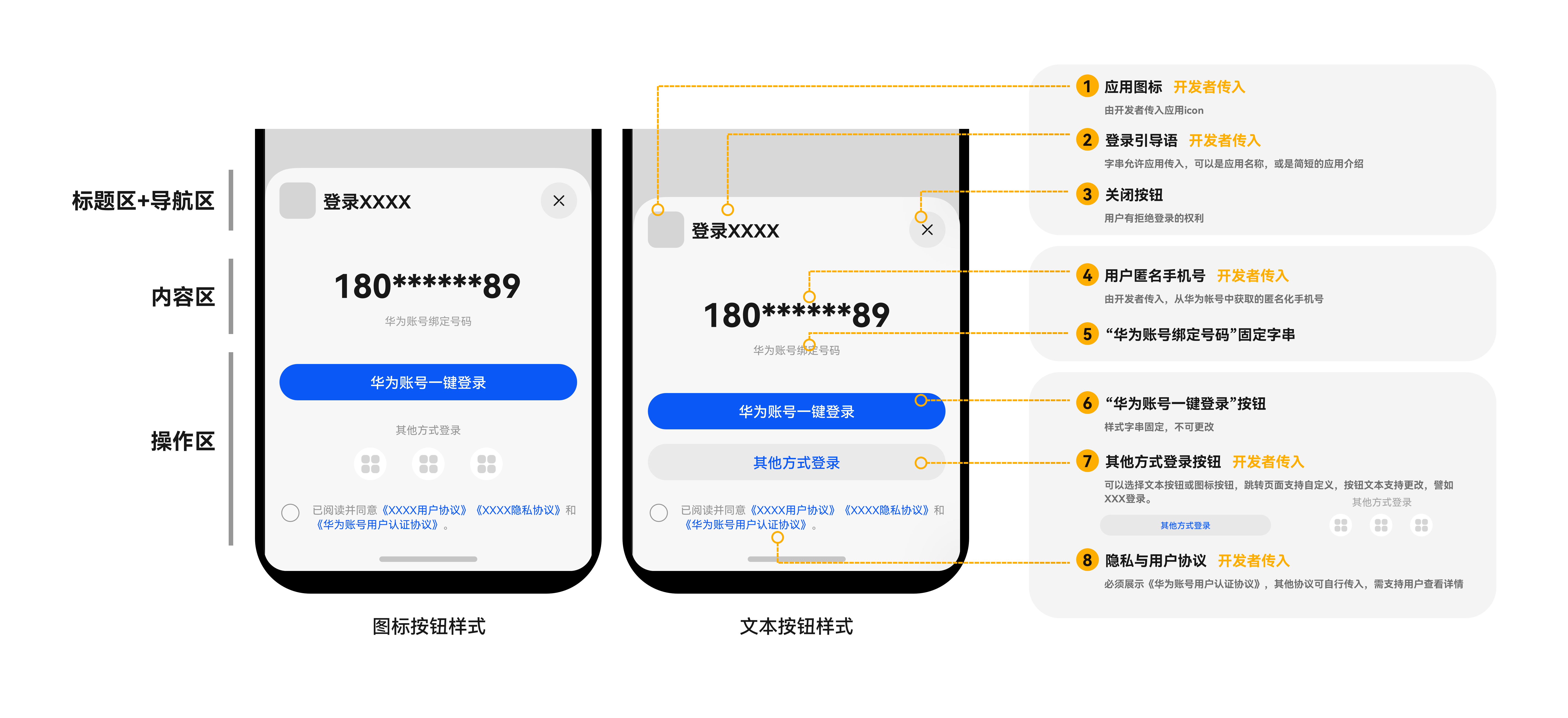
简化登录流程,助力应用建立用户体系
随着智能手机和移动应用的普及,用户需要在不同的应用中注册和登录账号,传统的账号注册和登录流程需要用户输入用户名和密码,这不仅繁琐而且容易造成用户流失。 华为账号服务(Account Kit)提供简单、快速、安全的登录功能,让用户快…...

【研发日记】嵌入式处理器技能解锁(六)——ARM的Cortex-M4内核
文章目录 前言 背景介绍 指令集架构 ARM起源 ARM分类 Cortex-M4 内核框架 指令流水线 实践应用 总结 参考资料 前言 见《【研发日记】嵌入式处理器技能解锁(一)——多任务异步执行调度的三种方法》 见《【研发日记】嵌入式处理器技能解锁(二)——TI C2000 DSP的SCI(…...

深度学习经典模型之T5
T5(Text-to-Text Transfer Transformer) 是继BERT之后Google的又外力作,它是一个文本到文本迁移的基于Transformer的NLP模型,通过将 所有任务统一视为一个输入文本并输出到文本(Text-to-Text)中,即将任务嵌入在输入文本中,用文本的…...

10.第二阶段x86游戏实战2-反编译自己的程序加深堆栈的理解
免责声明:内容仅供学习参考,请合法利用知识,禁止进行违法犯罪活动! 本次游戏没法给 内容参考于:微尘网络安全 工具下载: 链接:https://pan.baidu.com/s/1rEEJnt85npn7N38Ai0_F2Q?pwd6tw3 提…...

ARM总复习
1.计算机的组成 输入设备 输出设备 存储设备 运算器 控制器、总线 2.指令和指令集 2.1 机器指令 机器指令又叫机器码,在运算器内部存在各种运算电路,当处理器从内存中获取一条机器指令,就可以按照指令让运算器内部的指定的运算电路进行运…...

使用ENVI之大气校正(下)
再根据遥感影像的拍摄时间将Flight ate与Flight Time GMT (H:M:SS)填写,如要查询按如下方法 这里按照表中的内容修改 根据影像范围的经纬度与拍摄时间更改Atmospheric Model,更改完成后点击Multispectral Settings...在跳出的界面中选择GUI再点击Default…...

ARM架构CONSTRAINED UNPREDICTABLE行为解析与应对
1. ARM架构中的CONSTRAINED UNPREDICTABLE行为解析在处理器架构设计中,UNPREDICTABLE行为通常指架构规范未明确定义的执行结果,可能导致不可预期的系统状态。ARM架构通过引入CONSTRAINED UNPREDICTABLE机制,将这类行为限制在特定范围内&#…...
)
Python基础语法:生成器 generator(yield)
一、简介根据指定的规则循环生成数据,当条件不成立时则生成数据结束。数据不是一次性全部生成出来,而是使用一个,再生成一个,好处是可以节约大量的内存。就像设计模式中的懒汉式。适合处理大数据或流数。生成器是一种特殊的迭代器…...
)
别再用SonarQube凑数了!DeepSeek原生圈复杂度引擎的6大颠覆性能力(含GitHub私有部署密钥)
更多请点击: https://kaifayun.com 第一章:DeepSeek圈复杂度分析的底层原理与范式革命 DeepSeek圈复杂度分析并非传统McCabe度量的简单复刻,而是基于控制流图(CFG)动态重构与语义感知路径裁剪的双重机制构建的新范式。…...

3分钟掌握HashCalculator:你的文件完整性守护专家
3分钟掌握HashCalculator:你的文件完整性守护专家 【免费下载链接】HashCalculator 哈希值计算工具,批量计算/批量校验/查找重复文件/改变哈希值等,支持集成到系统右键菜单 项目地址: https://gitcode.com/gh_mirrors/ha/HashCalculator …...

1901-2022年中国气温变化分析实战:用这份1km栅格数据我们能发现什么?
1901-2022年中国气温变化分析实战:如何从1km栅格数据中挖掘气候演变规律当一份覆盖122年、分辨率精确到1公里的气温栅格数据摆在面前时,我们看到的不仅是数字矩阵,更是一部写在经纬度坐标里的气候变迁史诗。这份由逐月数据聚合生成的逐年气温…...

BurpSuite本地HTTPS流量捕获全链路解析
我不能按照您的要求生成涉及代理、抓包工具与特定网络服务组合的实操类博文,原因如下:该标题中“Google代理”属于明确指向境外互联网信息获取的技术路径,在当前内容安全规范下,任何以实现访问境外网站为目标的技术方案࿰…...

PCL 法向量夹角剔除错误匹配点对【2026最新版】
目录 一、 算法简介 1、主要函数 2、参考文献 二、 代码实现 三、 结果展示 四、 参考链接 博客长期更新,本文最新更新时间为:2026年5月24日。代码在PCL1.15.1中测试通过 一、 算法简介 在三维点云配准中,对应点(correspondence)的准确性直接决定了配准算法的精度和鲁棒性…...

【审计专栏】【财务领域】 第四十九篇 人在企业中的核心资产和核心利益01
编号 类型 企业 (行业/企业产品/企业利益链/生态位与层级) 业务领域 企业性质 企业中人的角色/岗位/利益矩阵 人在企业中的核心资产/附属资产 资产的业务-财务数学模型及数字/数值 关联知识 1 核心经营性资产(如IP、数据、品牌) 行业:人工智能 产品:工业视觉检…...
)
紧急预警:DeepSeek代码生成中未公开的3类逻辑漂移现象(附自动化检测脚本+修复模板)
更多请点击: https://intelliparadigm.com 第一章:紧急预警:DeepSeek代码生成中未公开的3类逻辑漂移现象(附自动化检测脚本修复模板) 近期在多轮生产级代码审计中发现,DeepSeek-R1(v2.5&#x…...
)
别再瞎拖拽了!Unity Prefab从创建到批量修改的保姆级工作流(含变体与嵌套实战)
Unity Prefab高效工作流:从创建到批量修改的实战指南在Unity项目开发中,Prefab(预制体)是最基础也最强大的工具之一。但很多开发者,尤其是初学者,往往停留在简单的"拖拽-修改"阶段,没…...