让PyTorch训练速度更快,你需要掌握这17种方法
掌握这 17 种方法,用最省力的方式,加速你的 Pytorch 深度学习训练。
近日,Reddit 上一个帖子热度爆表。主题内容是关于怎样加速 PyTorch 训练。原文作者是来自苏黎世联邦理工学院的计算机科学硕士生 LORENZ KUHN,文章向我们介绍了在使用 PyTorch 训练深度模型时最省力、最有效的 17 种方法。
该文所提方法,都是假设你在 GPU 环境下训练模型。具体内容如下。
17 种加速 PyTorch 训练的方法
1. 考虑换一种学习率 schedule
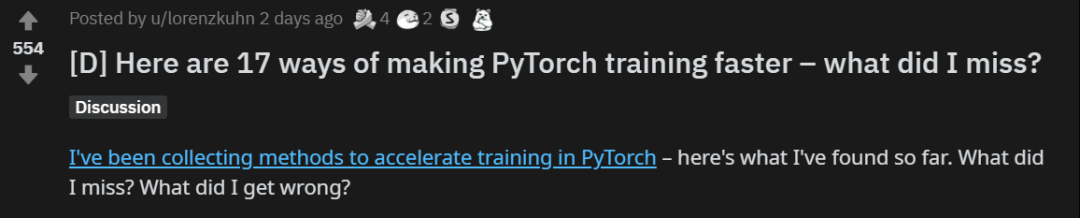
学习率 schedule 的选择对模型的收敛速度和泛化能力有很大的影响。Leslie N. Smith 等人在论文《Cyclical Learning Rates for Training Neural Networks》、《Super-Convergence: Very Fast Training of Neural Networks Using Large Learning Rates 》中提出了周期性(Cyclical)学习率以及 1Cycle 学习率 schedule。之后,fast.ai 的 Jeremy Howard 和 Sylvain Gugger 对其进行了推广。下图是 1Cycle 学习率 schedule 的图示:

Sylvain 写到:1Cycle 包括两个等长的步幅,一个步幅是从较低的学习率到较高的学习率,另一个是回到最低水平。最大值来自学习率查找器选取的值,较小的值可以低十倍。然后,这个周期的长度应该略小于总的 epochs 数,并且,在训练的最后阶段,我们应该允许学习率比最小值小几个数量级。
与传统的学习率 schedule 相比,在最好的情况下,该 schedule 实现了巨大的加速(Smith 称之为超级收敛)。例如,使用 1Cycle 策略在 ImageNet 数据集上训练 ResNet-56,训练迭代次数减少为原来的 1/10,但模型性能仍能比肩原论文中的水平。在常见的体系架构和优化器中,这种 schedule 似乎表现得很好。
Pytorch 已经实现了这两种方法:「torch.optim.lr_scheduler.CyclicLR」和「torch.optim.lr_scheduler.OneCycleLR」。
参考文档:https://pytorch.org/docs/stable/optim.html
2. 在 DataLoader 中使用多个 worker 和页锁定内存
当使用 torch.utils.data.DataLoader 时,设置 num_workers > 0,而不是默认值 0,同时设置 pin_memory=True,而不是默认值 False。
参考文档:https://pytorch.org/docs/stable/data.html
来自 NVIDIA 的高级 CUDA 深度学习算法软件工程师 Szymon Micacz 就曾使用四个 worker 和页锁定内存(pinned memory)在单个 epoch 中实现了 2 倍的加速。人们选择 worker 数量的经验法则是将其设置为可用 GPU 数量的四倍,大于或小于这个数都会降低训练速度。请注意,增加 num_workers 将增加 CPU 内存消耗。
3. 把 batch 调到最大
把 batch 调到最大是一个颇有争议的观点。一般来说,如果在 GPU 内存允许的范围内将 batch 调到最大,你的训练速度会更快。但是,你也必须调整其他超参数,比如学习率。一个比较好用的经验是,batch 大小加倍时,学习率也要加倍。
OpenAI 的论文《An Empirical Model of Large-Batch Training》很好地论证了不同的 batch 大小需要多少步才能收敛。在《How to get 4x speedup and better generalization using the right batch size》一文中,作者 Daniel Huynh 使用不同的 batch 大小进行了一些实验(也使用上面讨论的 1Cycle 策略)。最终,他将 batch 大小由 64 增加到 512,实现了 4 倍的加速。
然而,使用大 batch 的不足是,这可能导致解决方案的泛化能力比使用小 batch 的差。
4. 使用自动混合精度(AMP)
PyTorch 1.6 版本包括对 PyTorch 的自动混合精度训练的本地实现。这里想说的是,与单精度 (FP32) 相比,某些运算在半精度 (FP16) 下运行更快,而不会损失准确率。AMP 会自动决定应该以哪种精度执行哪种运算。这样既可以加快训练速度,又可以减少内存占用。
在最好的情况下,AMP 的使用情况如下:
import torch
# Creates once at the beginning of training
scaler = torch.cuda.amp.GradScaler()for data, label in data_iter:optimizer.zero_grad()# Casts operations to mixed precisionwith torch.cuda.amp.autocast():loss = model(data)# Scales the loss, and calls backward()# to create scaled gradientsscaler.scale(loss).backward()# Unscales gradients and calls# or skips optimizer.step()scaler.step(optimizer)# Updates the scale for next iterationscaler.update()5. 考虑使用另一种优化器
AdamW 是由 fast.ai 推广的一种具有权重衰减(而不是 L2 正则化)的 Adam,在 PyTorch 中以 torch.optim.AdamW 实现。AdamW 似乎在误差和训练时间上都一直优于 Adam。
Adam 和 AdamW 都能与上面提到的 1Cycle 策略很好地搭配。
目前,还有一些非本地优化器也引起了很大的关注,最突出的是 LARS 和 LAMB。NVIDA 的 APEX 实现了一些常见优化器的融合版本,比如 Adam。与 PyTorch 中的 Adam 实现相比,这种实现避免了与 GPU 内存之间的多次传递,速度提高了 5%。
6. cudNN 基准
如果你的模型架构保持不变、输入大小保持不变,设置 torch.backends.cudnn.benchmark = True。
7. 小心 CPU 和 GPU 之间频繁的数据传输
当频繁地使用 tensor.cpu() 将张量从 GPU 转到 CPU(或使用 tensor.cuda() 将张量从 CPU 转到 GPU)时,代价是非常昂贵的。item() 和 .numpy() 也是一样可以使用. detach() 代替。
如果你创建了一个新的张量,可以使用关键字参数 device=torch.device('cuda:0') 将其分配给 GPU。
如果你需要传输数据,可以使用. to(non_blocking=True),只要在传输之后没有同步点。
8. 使用梯度 / 激活 checkpointing
Checkpointing 的工作原理是用计算换内存,并不存储整个计算图的所有中间激活用于 backward pass,而是重新计算这些激活。我们可以将其应用于模型的任何部分。
具体来说,在 forward pass 中,function 会以 torch.no_grad() 方式运行,不存储中间激活。相反的是, forward pass 中会保存输入元组以及 function 参数。在 backward pass 中,输入和 function 会被检索,并再次在 function 上计算 forward pass。然后跟踪中间激活,使用这些激活值计算梯度。
因此,虽然这可能会略微增加给定 batch 大小的运行时间,但会显著减少内存占用。这反过来又将允许进一步增加所使用的 batch 大小,从而提高 GPU 的利用率。
尽管 checkpointing 以 torch.utils.checkpoint 方式实现,但仍需要一些思考和努力来正确地实现。Priya Goyal 写了一个很好的教程来介绍 checkpointing 关键方面。
Priya Goyal 教程地址:
https://github.com/prigoyal/pytorch_memonger/blob/master/tutorial/Checkpointing_for_PyTorch_models.ipynb
9. 使用梯度积累
增加 batch 大小的另一种方法是在调用 optimizer.step() 之前在多个. backward() 传递中累积梯度。
Hugging Face 的 Thomas Wolf 的文章《Training Neural Nets on Larger Batches: Practical Tips for 1-GPU, Multi-GPU & Distributed setups》介绍了如何使用梯度累积。梯度累积可以通过如下方式实现:
model.zero_grad() # Reset gradients tensors
for i, (inputs, labels) in enumerate(training_set):predictions = model(inputs) # Forward passloss = loss_function(predictions, labels) # Compute loss functionloss = loss / accumulation_steps # Normalize our loss (if averaged)loss.backward() # Backward passif (i+1) % accumulation_steps == 0: # Wait for several backward stepsoptimizer.step() # Now we can do an optimizer stepmodel.zero_grad() # Reset gradients tensorsif (i+1) % evaluation_steps == 0: # Evaluate the model when we...evaluate_model() # ...have no gradients accumulate这个方法主要是为了规避 GPU 内存的限制而开发的。
10. 使用分布式数据并行进行多 GPU 训练
加速分布式训练可能有很多方法,但是简单的方法是使用 torch.nn.DistributedDataParallel 而不是 torch.nn.DataParallel。这样一来,每个 GPU 将由一个专用的 CPU 核心驱动,避免了 DataParallel 的 GIL 问题。
分布式训练文档地址:https://pytorch.org/tutorials/beginner/dist_overview.html
11. 设置梯度为 None 而不是 0
梯度设置为. zero_grad(set_to_none=True) 而不是 .zero_grad()。这样做可以让内存分配器处理梯度,而不是将它们设置为 0。正如文档中所说,将梯度设置为 None 会产生适度的加速,但不要期待奇迹出现。注意,这样做也有缺点,详细信息请查看文档。
文档地址:https://pytorch.org/docs/stable/optim.html
12. 使用. as_tensor() 而不是. tensor()
torch.tensor() 总是会复制数据。如果你要转换一个 numpy 数组,使用 torch.as_tensor() 或 torch.from_numpy() 来避免复制数据。
13. 必要时打开调试工具
PyTorch 提供了很多调试工具,例如 autograd.profiler、autograd.grad_check、autograd.anomaly_detection。请确保当你需要调试时再打开调试器,不需要时要及时关掉,因为调试器会降低你的训练速度。
14. 使用梯度裁剪
关于避免 RNN 中的梯度爆炸的问题,已经有一些实验和理论证实,梯度裁剪(gradient = min(gradient, threshold))可以加速收敛。HuggingFace 的 Transformer 实现就是一个非常清晰的例子,说明了如何使用梯度裁剪。本文中提到的其他一些方法,如 AMP 也可以用。
在 PyTorch 中可以使用 torch.nn.utils.clip_grad_norm_来实现。
15. 在 BatchNorm 之前关闭 bias
在开始 BatchNormalization 层之前关闭 bias 层。对于一个 2-D 卷积层,可以将 bias 关键字设置为 False:torch.nn.Conv2d(..., bias=False, ...)。
16. 在验证期间关闭梯度计算
在验证期间关闭梯度计算,设置:torch.no_grad() 。
17. 使用输入和 batch 归一化
要再三检查一下输入是否归一化?是否使用了 batch 归一化?
相关文章:
让PyTorch训练速度更快,你需要掌握这17种方法
掌握这 17 种方法,用最省力的方式,加速你的 Pytorch 深度学习训练。近日,Reddit 上一个帖子热度爆表。主题内容是关于怎样加速 PyTorch 训练。原文作者是来自苏黎世联邦理工学院的计算机科学硕士生 LORENZ KUHN,文章向我们介绍了在…...

LeetCode-309. 最佳买卖股票时机含冷冻期
目录题目思路动态规划题目来源 309. 最佳买卖股票时机含冷冻期 题目思路 每天最多只可能有三种状态中的一种 0表示当前处于买入状态(持有股票) 1表示当前处于卖出状态(不持有股票) 2表示当前处于冷冻状态 设dp[i][j]表示i - 1天状态为j时所拥有的最大现金 dp[i][0] Math.ma…...
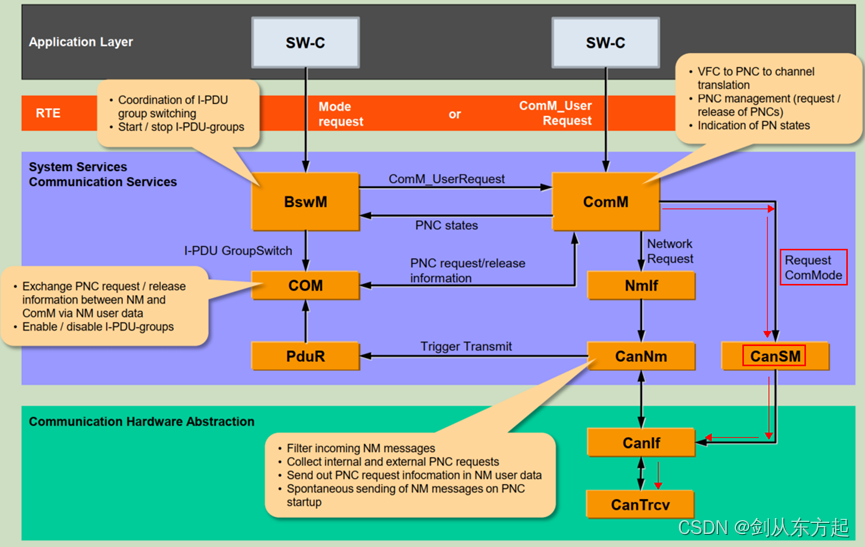
AUTOSAR知识点Com(七):CANSM初认知
目录 1、概述 2、CanSM主要做什么 2.1、CAN控制器状态管理 2.2、CAN收发器状态管理 2.3、Busoff检测 1、概述 CANSM(Controller Area Network State Manager)是AUTOSAR(Automotive Open System Architecture)标准中的一个模块…...

递归:斐波那契数列、递归实现指数型枚举、递归实现排列型枚举
递归:O(2^n) 调用自己 例题及代码模板: 斐波那契数列 输入一个整数 n ,求斐波那契数列的第 n 项。 假定从 0 开始,第 0 项为 0。 数据范围 0≤n≤39 样例 输入整数 n5 返回 5 #include <iostream> #include <cstring&g…...

oracle模糊查询时字段内容包含下划线的解决办法
最近项目中遇到一个关于模糊查询问题。表tabA中的字段name的值有下划线的情况,在模糊查询时发现查询的记录不对。 表的结构 表名:tabA id name sex 1 test_601 1 2 test_602 2 3 test16 1 4 t…...

C++:explicit关键字
C中的explicit关键字只能用于修饰只有一个参数的类构造函数,它的作用是表明该构造函数是显示的,而非隐式的,跟它相对应的另一个关键字是implicit,意思是隐藏的,类构造函数默认情况下即声明为implicit(隐式)。那么显示声…...

【C5】bmc wtd,post
文章目录1.bmc_wtd_cpld:syscpld.c中wd_en和wd_kick节点对应寄存器,crontab,FUNCNAME2.AST芯片WDT切换主备:BMC用WDT2作为主备切换的控制器2.1 AC后读取:bmc处于主primary flash(设完后:实际主&…...
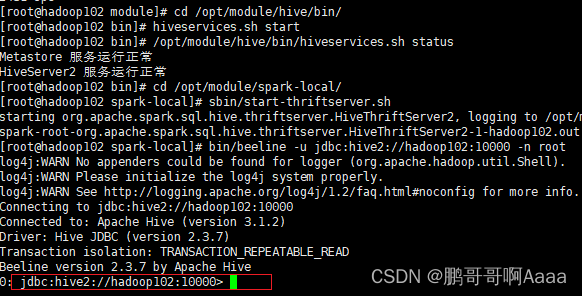
200.Spark(七):SparkSQL项目实战
一、启动环境 需要启动mysql,hadoop,hive,spark。并且能让spark连接上hive(上一章有讲) #启动mysql,并登录,密码123456 sudo systemctl start mysqld mysql -uroot -p#启动hive cd /opt/module/ myhadoop.sh start#查看启动情况 jpsall#启动hive cd /opt/module/hive/…...
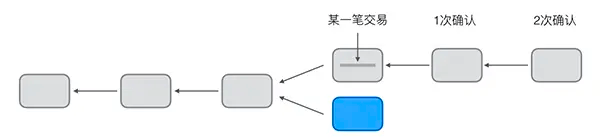
区块链系统:挖矿原理
在比特币的P2P网络中,有一类节点,它们时刻不停地进行计算,试图把新的交易打包成新的区块并附加到区块链上,这类节点就是矿工。因为每打包一个新的区块,打包该区块的矿工就可以获得一笔比特币作为奖励。所以,…...

【博弈】【清华冬令营2018模拟】取石子
写完敢说全网没有这么详细的题解了。 注意:题解长是为了方便理解,所以读起来速度应该很快。 题目描述 有 nnn 堆石子,第 iii 堆有 xix_ixi 个。 AliceAliceAlice 和 BobBobBob 轮流去石子(先后手未定), …...
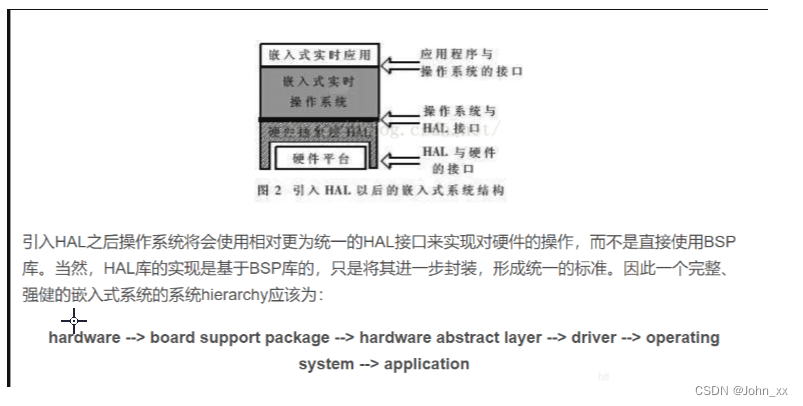
嵌入式:BSP的理解
BSP概念总结BSP定义BSP的特点BSP的主要工作BSP在嵌入式系统和Windowsx系统中的不同BSP和PC机主板上的BIOS区别BSP与 HAL关系嵌入式计算机系统主要由 硬件层,中间层,系统软件层和应用软件层四层组成。硬件层:包含CPU,存储器(SDRAM&…...
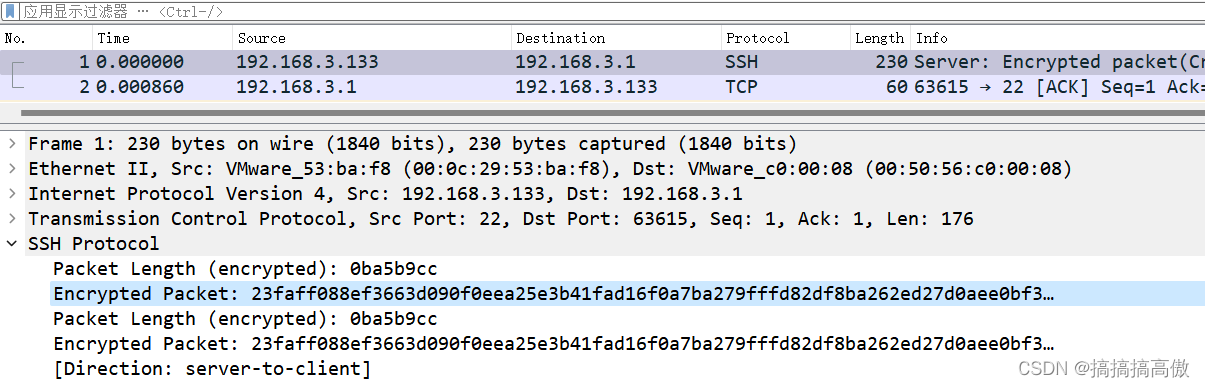
Linux主机Tcpdump使用-centos实例
1、安装前系统信息 ifconfig查看系统网络接口情况。这里可以看到3个interface,ens160是正常使用的网口,lo是主机的loopback地址127.0.0.1。另外,由于centos安装在虚拟主机上,virbr0是KVM默认创建的一个Bridge,其作用是为连接其上的…...
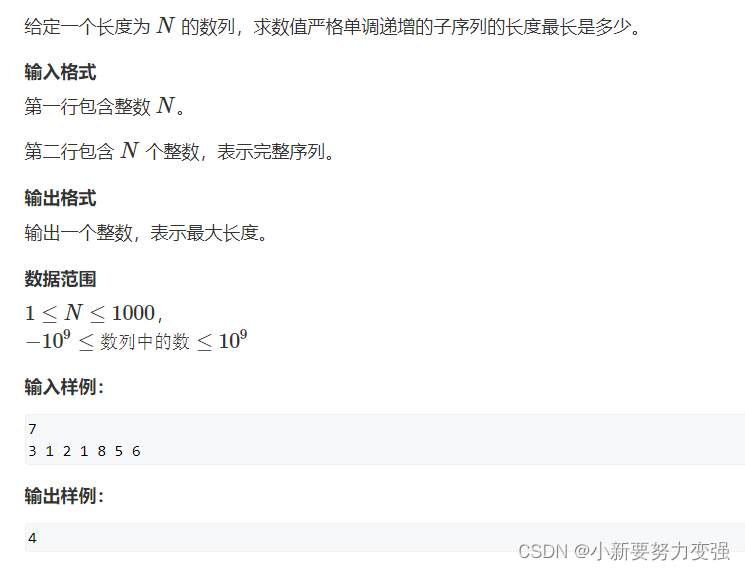
线性DP——AcWing 898. 数字三角形、AcWing 895. 最长上升子序列
AcWing 898. 数字三角形 1.题目 898. 数字三角形 2.思路 DP问题首先考虑状态转移方程,定义一个集合f ( i , j) ,表示从第一个数字(1,1)走到第 i行,第 j列(i , j)的所有方案的集合,…...
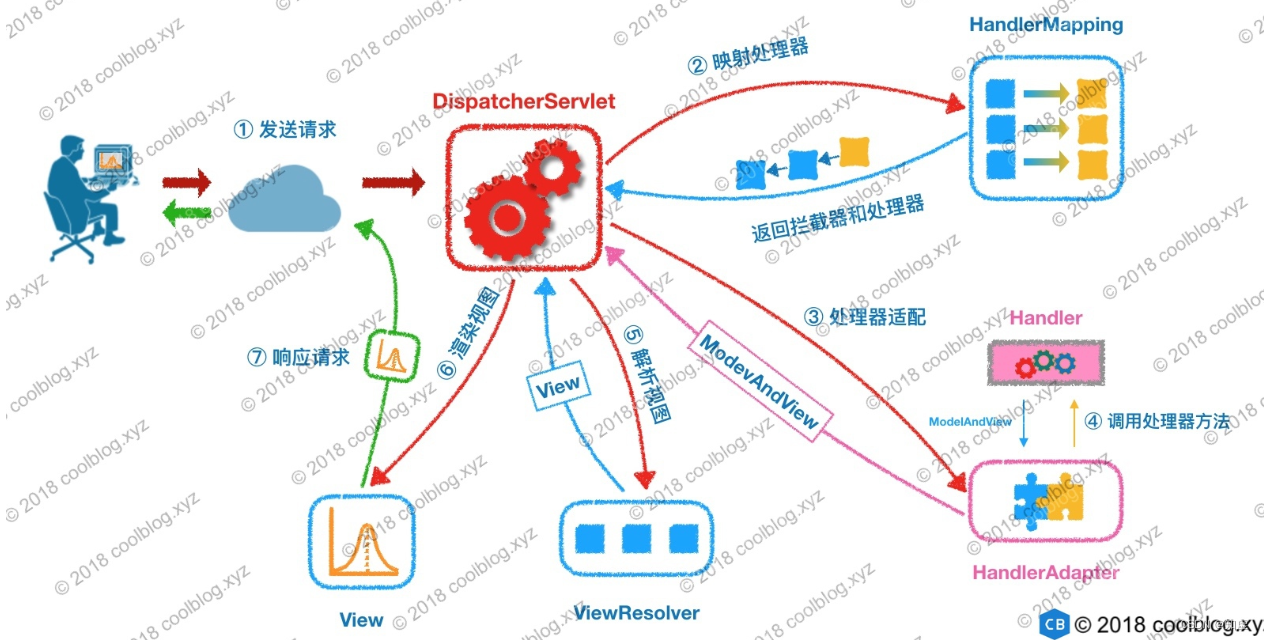
SpringMVC
SpringMVC配置 引入Maven依赖 (springmvc)web.xml配置DispatcherServlet配置 applicationContext 的 MVC 标记开发Controller控制器 几点注意事项: 在web.xml中 配置<load-on-startup> 0 </load-on-startup> 会自动创建Spring…...
)
C++模板基础(二)
函数模板(二) ● 模板实参的类型推导 – 如果函数模板在实例化时没有显式指定模板实参,那么系统会尝试进行推导 template<typename T> void fun(T input, T input2) {std::cout << input << \t << input2 << …...
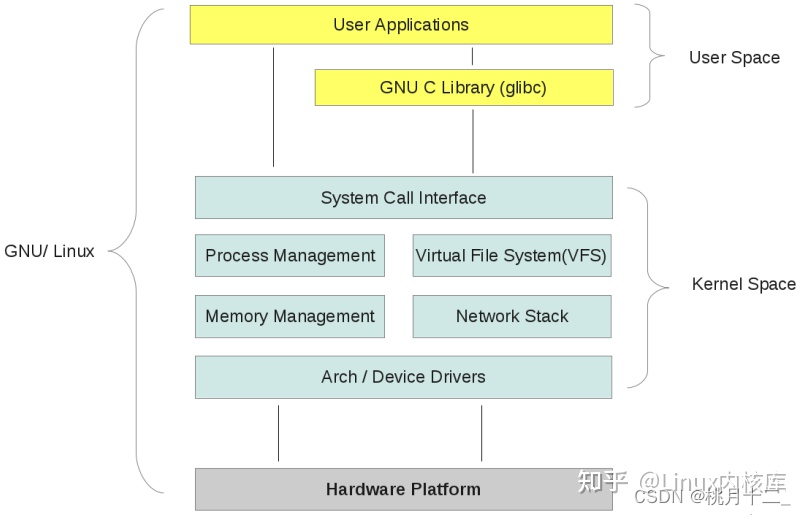
什么是linux内核态、用户态?
目录标题为什么需要区分内核空间与用户空间内核态与用户态如何从用户空间进入内核空间整体结构为什么需要区分内核空间与用户空间 在 CPU 的所有指令中,有些指令是非常危险的,如果错用,将导致系统崩溃,比如清内存、设置时钟等。如…...

day8—选择题
文章目录1.Test.main() 函数执行后的输出是(D)2. JUnit主要用来完成什么(D)3.下列选项中关于Java中super关键字的说法正确的是(A)1.Test.main() 函数执行后的输出是(D) public clas…...
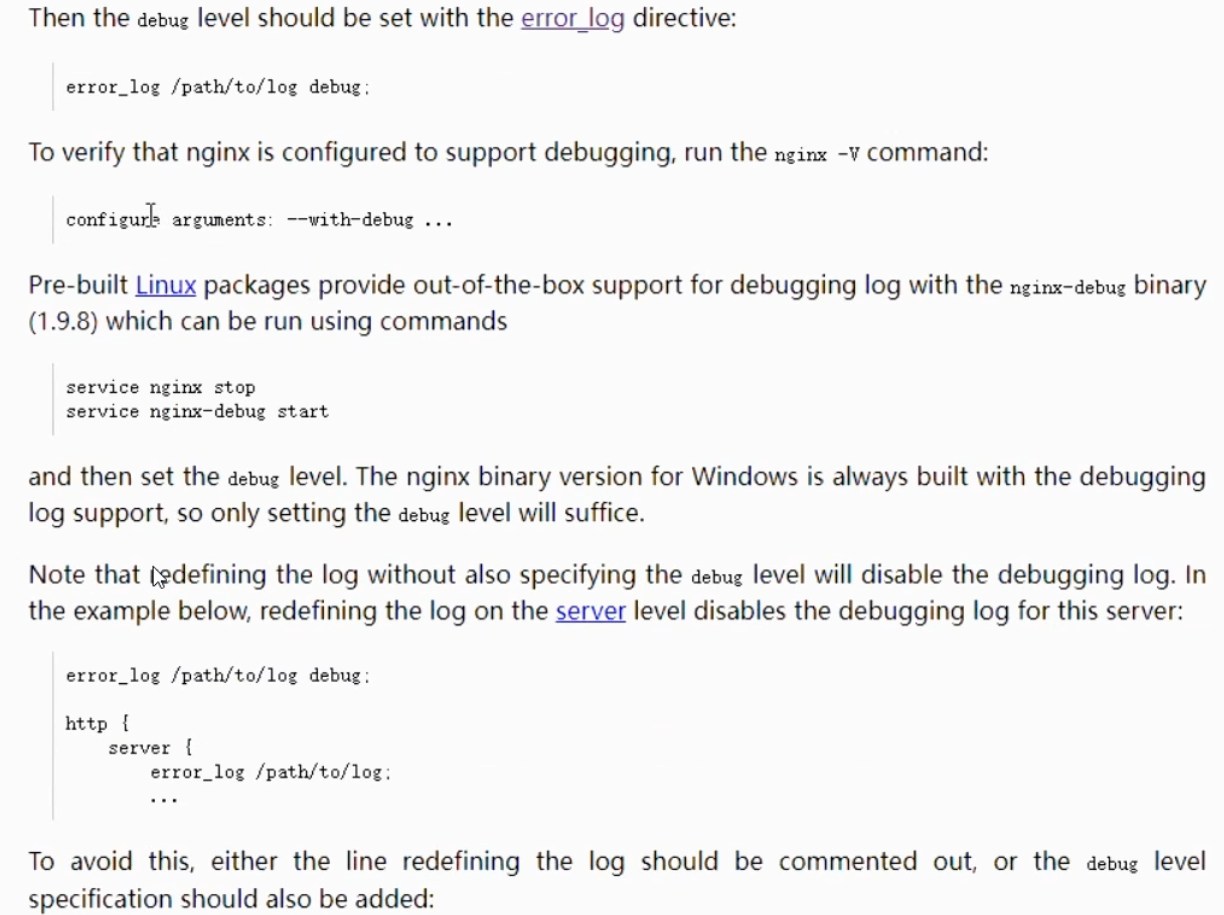
ngx错误日志error_log配置
ngx之error_log 日志配置格式: 常见的错误日志级别 错误日志可配置位置 关闭error_log配置 设置debug 日志级别的前提: ngx之error_log 日志配置格式: error_log 存放路径 日志级别 例: error_log /usr/local/log…...

1.11、自动化
自动化 一、java 手机自动化 首先new DesertCapabilities(这是一个类) setCapability – 设置信息 获取appium的驱动对象 new AppiumDriver – 本机IP地址:端口号/wd/hub,前面的设置值信息 driver.findElementById() – 通过id找位置 click() – 点击 &…...
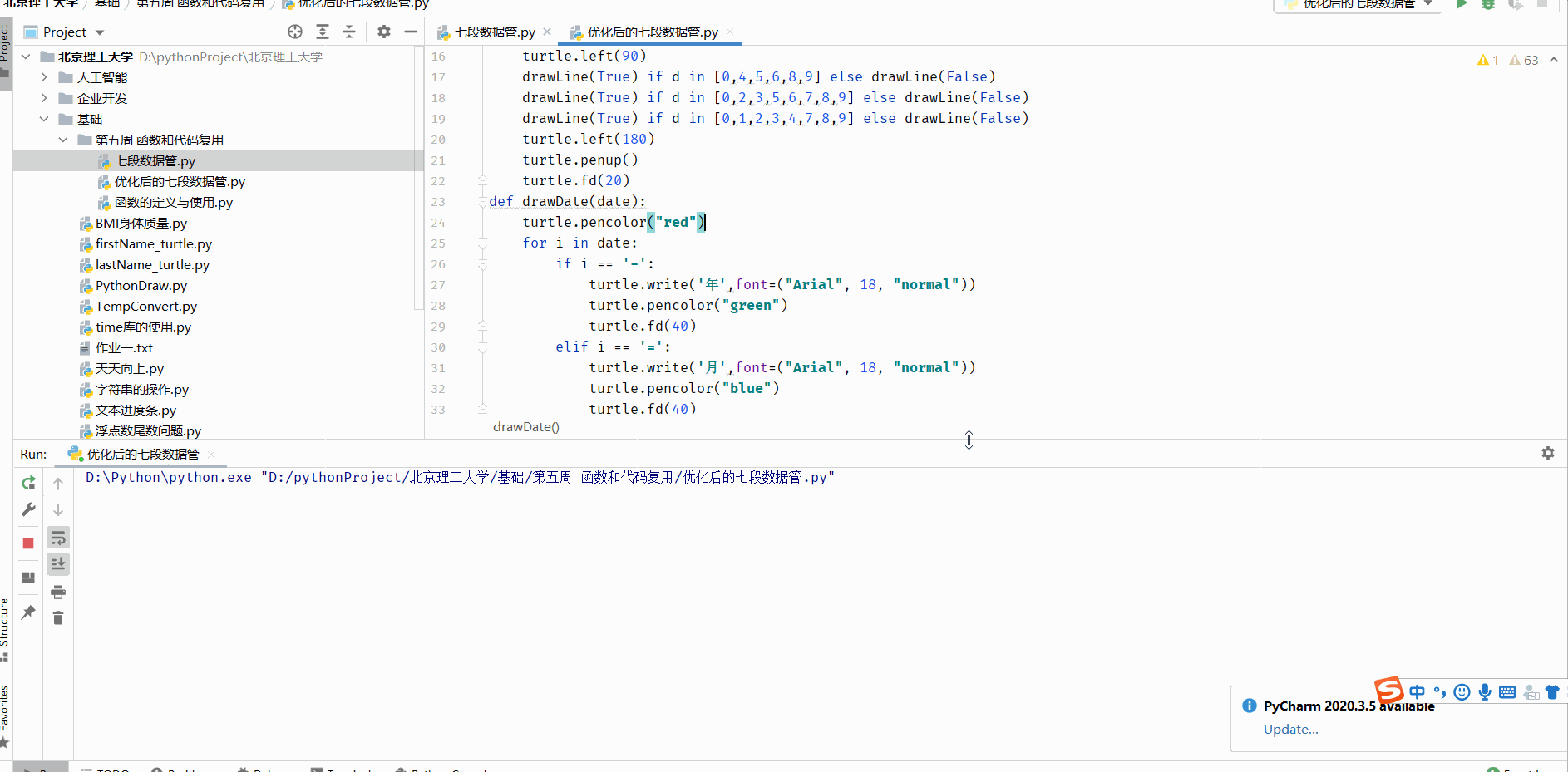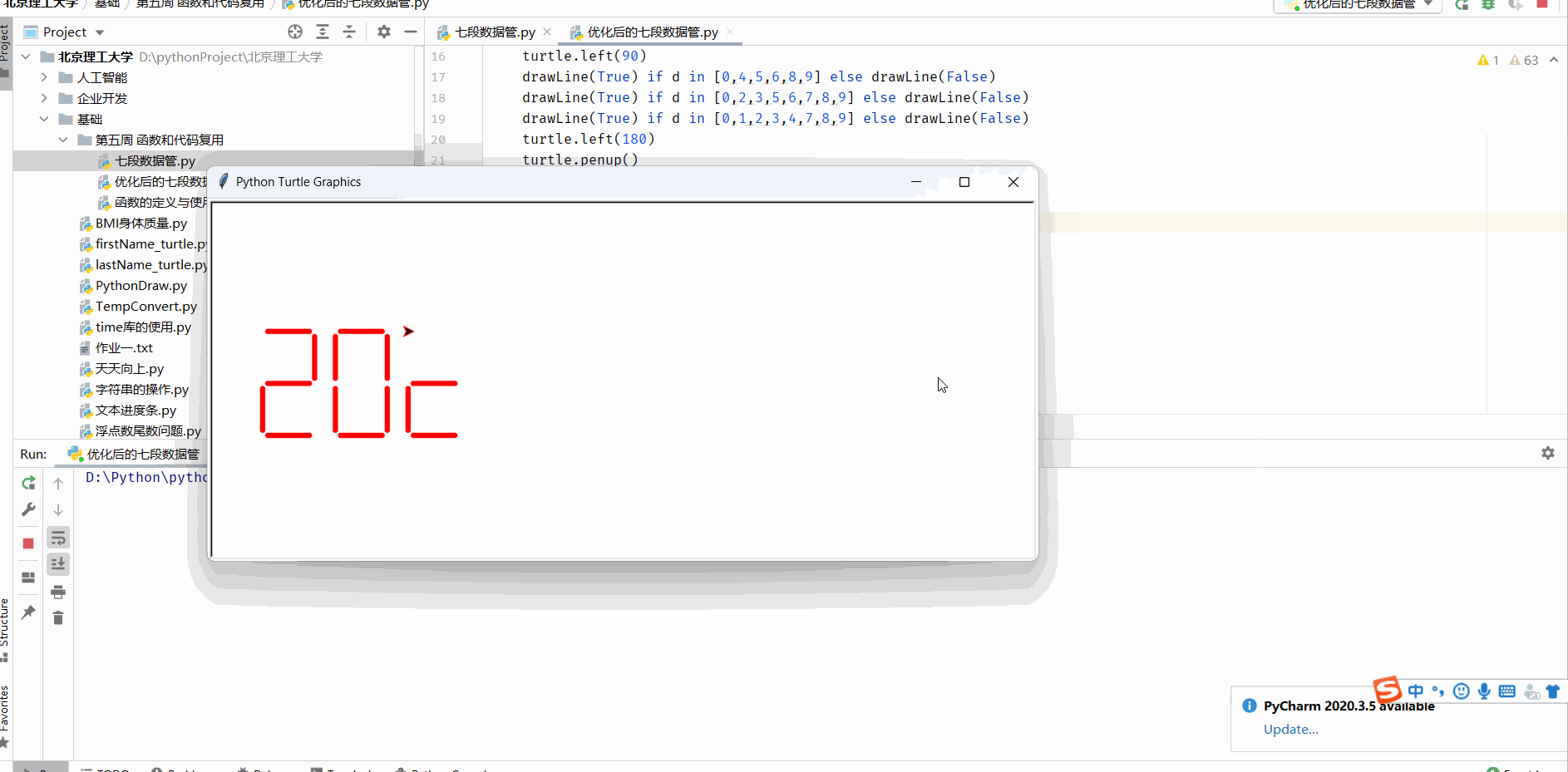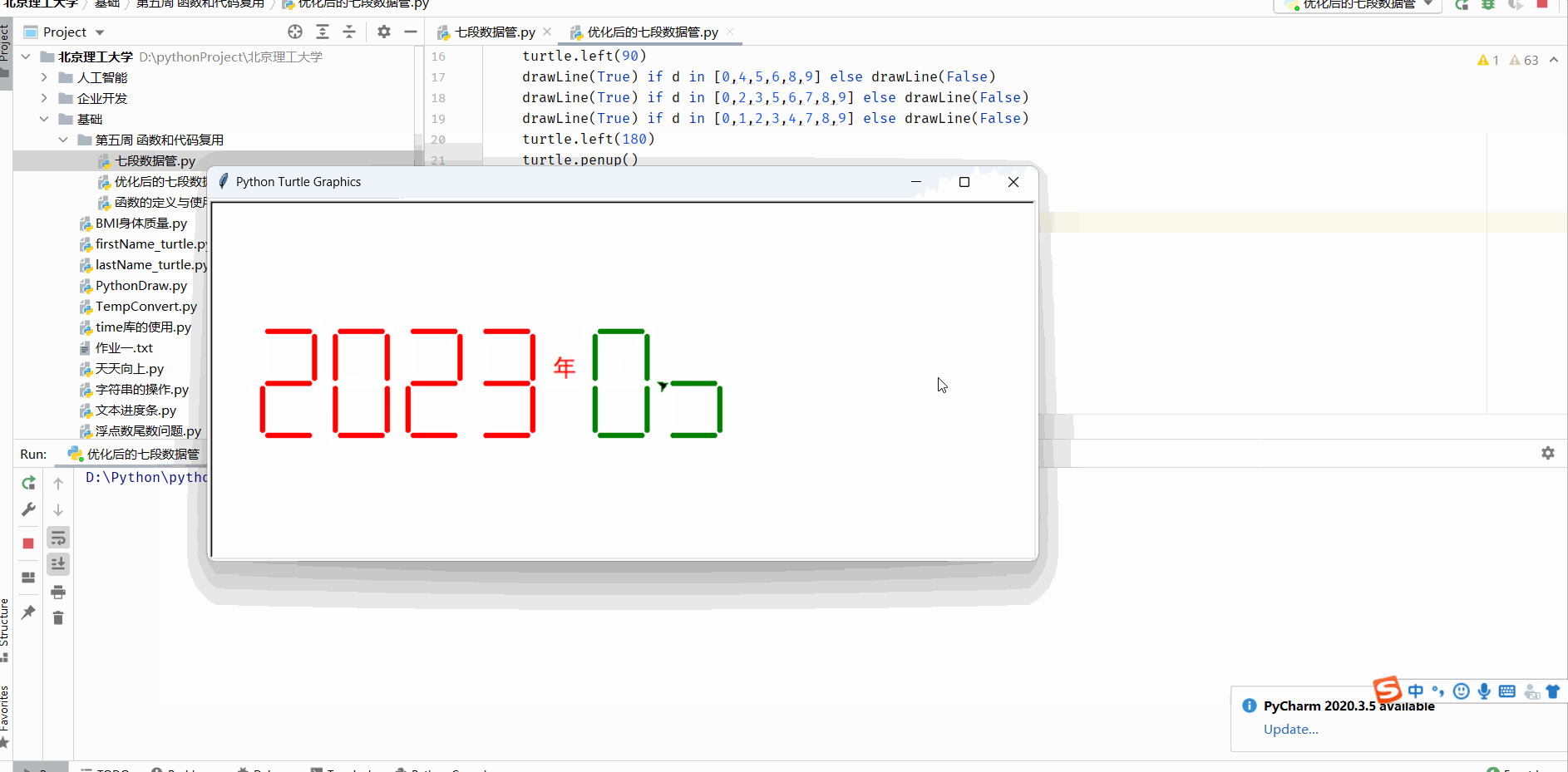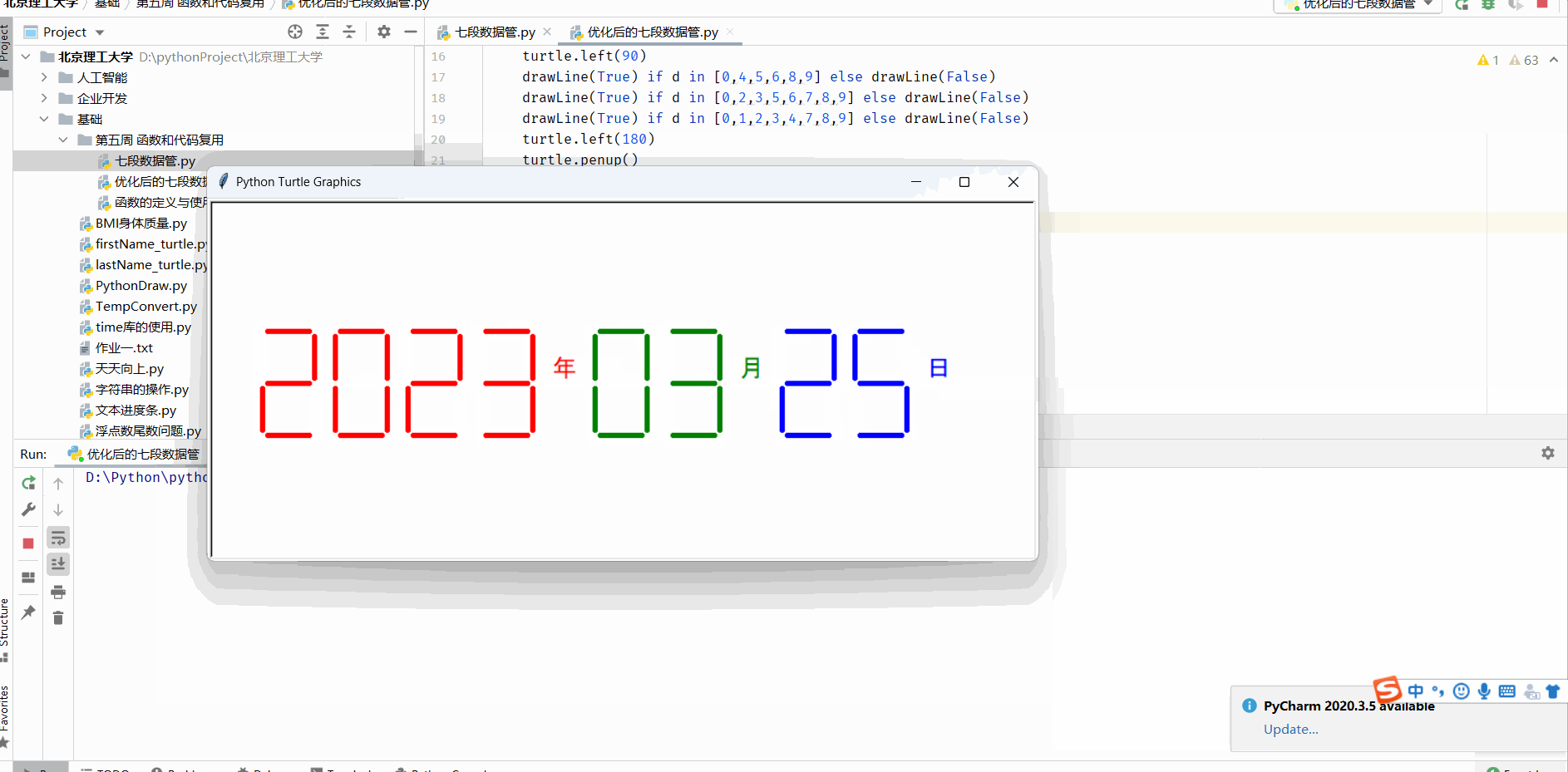
函数的定义与使用及七段数码管绘制
函数的定义 函数是一段代码的表示 函数是一段具有特定功能的、可重用的语句组 函数是一种功能的抽象,一般函数表达特定功能 两个作用:降低编程难度 和 代码复用 求一个阶乘 fact就是 函数名 n就是参数 return就是输出部分即返回值 而函数的调用就是…...

Laravel Permission终极指南:数据库迁移与性能优化完整教程
Laravel Permission终极指南:数据库迁移与性能优化完整教程 【免费下载链接】laravel-permission Associate users with roles and permissions 项目地址: https://gitcode.com/gh_mirrors/la/laravel-permission 在构建现代Laravel应用时,权限管…...

MTKClient实战指南:联发科设备刷机与逆向工程全面解决方案
MTKClient实战指南:联发科设备刷机与逆向工程全面解决方案 【免费下载链接】mtkclient MTK reverse engineering and flash tool 项目地址: https://gitcode.com/gh_mirrors/mt/mtkclient MTKClient是一款专为联发科芯片设备设计的开源逆向工程与刷机工具&am…...

底特律汽车产业转型:从全球平台战略到创新生态重构
1. 从废墟中重生:底特律汽车产业的韧性复苏如果你在2010年前后关注过全球汽车产业,或者对美国的工业经济史稍有了解,那么“底特律”这个名字,在当时几乎就是“衰败”与“绝望”的同义词。这座曾经的“汽车之城”,在200…...

Go语言安全编码实践:常见漏洞与防护
Go语言安全编码实践:常见漏洞与防护 1. 安全编码原则 安全编码是防止漏洞的根本,包括输入验证、输出编码、最小权限等原则。 2. 安全工具 package securityimport ("regexp""strings" )type Validator struct {emailRegex *regexp.R…...

MAX31856在工业温控项目中的实战应用:从选型、电路设计到故障诊断避坑指南
MAX31856工业温控系统设计全流程:从芯片选型到抗干扰实战 工业温度监测系统的可靠性直接关系到生产安全与产品质量。在钢铁冶炼、化工反应等场景中,一个温度传感器的失效可能导致数百万损失。MAX31856作为工业级热电偶数字转换器,其45V过压保…...

TEdit地图编辑器:10倍效率打造你的泰拉瑞亚梦想世界
TEdit地图编辑器:10倍效率打造你的泰拉瑞亚梦想世界 【免费下载链接】Terraria-Map-Editor TEdit - Terraria Map Editor - TEdit is a stand alone, open source map editor for Terraria. It lets you edit maps just like (almost) paint! It also lets you chan…...

Taotoken用量看板与成本管理功能的实际使用体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板与成本管理功能的实际使用体验 对于需要持续调用大模型API的项目而言,成本的可观测与可控性是管理中的…...

OFIRM 视角下的多重宇宙:双拐点确认度增长模型之本宇宙V4.1开篇,我提出一个深刻的哲学问题:如果宇宙全部演化都可以被一个数学公式精确描述,那么人类独立意识应该如何定位?我思考一夜,越想越觉得恐怖
OFIRM 视角下的多重宇宙:双拐点确认度增长模型之本宇宙V4.1开篇,我提出一个深刻的哲学问题:如果宇宙全部演化都可以被一个数学公式精确描述,那么人类独立意识应该如何定位?我思考一夜,越想越觉得恐怖 问&am…...

基于SEID模型与ode45数值解的艾滋病传播动力学建模与区域防控策略评估
1. 当数学模型遇上艾滋病防控 我第一次接触传染病建模是在研究生时期,当时导师扔给我一叠艾滋病流行病学数据,说:"试试用微分方程描述这个传播过程"。那会儿对着密密麻麻的病例报告,我完全没想到数学公式真能模拟现实中…...

Selenium自动化ChatGPT:绕过API限制,实现Web端高效批量交互
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫“Michelangelo27/chatgpt_selenium_automation”。光看名字,你大概能猜到它想做什么:用Selenium自动化操作ChatGPT。这听起来是不是有点“用大炮打蚊子”的感觉?毕…...